这里写自定义目录标题
- 一、JAVA基础
- 1.ArrayList
- 2.HashMap
- 3.Concurrenthashmap
- 4.Stream
- 5.synchronized
- 6.线程池
- 7.CompletableFuture
- 8.Fork/join
- 9.数组与链表的区别
- 10.单例模式
- 1.饿汉模式
- 2.懒汉模式
- 10.1、 为啥使用synchronized?
- 10.2、 又为啥使用volatile?
- 10.3、 那又又为啥用两个if (lazyMan == null)
- 11.单例模式中,双重检查锁是干什么用的
- 12.volatile [`禁止指令重排`]
- 13.接口和类的区别
- 14.项目中反射是如何应用的
- 15.为什么重写hashcode一定要重写equals?
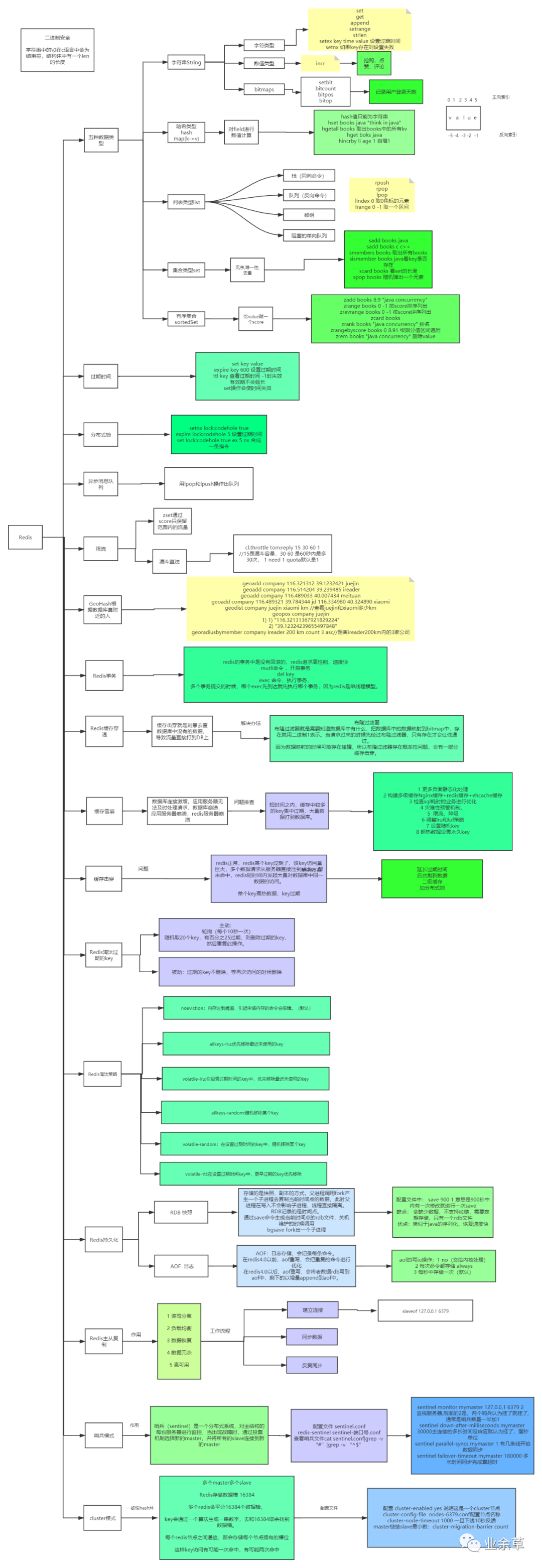
- 二、Redis
- 1、Redis 的回收策略(淘汰策略)?
- 2、Redis 过期键的删除策略?
- 3、Redis 的持久化机制是什么?各自的优缺点?
- 4、说说 Redis 哈希槽的概念?
- 5、Redis 集群的主从复制模型是怎样的?
- 6、Redis 集群会有写操作丢失吗?为什么?
- 7、Redis 集群之间是如何复制的?
- 8、Redis 集群最大节点个数是多少?
- 9、Redis 集群如何选择数据库?
- 10、 Redis击穿、穿透、雪崩
- 三,RabbitMQ 【消息队列】
- 2. 如何确保消息正确地发送至RabbitMQ?如何确保消息接收方消费了消息?
- 3、如何避免消息重复投递或重复消费?
- 4、消息基于什么传输?
- 5、消息怎么路由?
- 6、如何确保消息不丢失?
- 7、死信队列
- 8、消息优先级【VIP插队】
- 9、顺序消费
- 保证循序消费的方案【URL跳转】
- 四、MYSQL
- 1.SQL执行流程
- 2.索引
- 索引的优点
- 索引的缺点
- 应该创建索引的列
- 不该创建索引的列
- 3.深分页处理方案
- 4.redo log、binlog、innodb log
- 5.慢日志
- 6.sql语句优化
- 7. show profile
- 8.explain
- 9.information_schema
- 10.两阶段提交
- 11.B-True
- 12.B+True
- 五、MyBatils
- 1.`#{}`和`${}`的区别是什么?
- 2.Mybatis的`一级`、`二级`缓存
- 六、Spring
- 1. AOP
- 2.IOC
- 3.双亲委派
- 4.MVC执行流程
- 5. 如何把服务交给Spring管理
- 七、SpringCloud Albaba
- 组件
- 组件
- Nacos 服务发现、配置管理和服务管理平台
- 1.多人本地开发,如何共同使用测试环境的同一个Nacos进行调试?
- 2.Config 配置信息更改,代码中是如何感知到的?
- 3.Config 配置文件存储在哪里?
- 4.服务的注册发现是如何实现的?
- Getway 网关
- 1.如何使用灰度发布
- 2.白名单
- 2.路径跳转
- Sentinel 分布式服务架构的实时流量控制、熔断降级和系统负载
- Seata 分布式事务
- Admin 监控服务
- SkyWalking 链路追踪
- RocketMQ 消息队里
- 微服务架构图
- 八丶微服务面试题
- 1.微服务中A服务调用B服务如何传递Token?
- 2.微服务 如何把A服务提供为工具,然后引入到别的服务中,原理是什么?
- 九丶Elasticsearch
- 1.搜索字段的类型设计 field type【`text`、`keyword`】
- 2. Elasticsearch 的打分机制
- 2.4. 其他打分方法
- 3. elasticsearch 的倒排索引是什么
- 4. elasticsearch 是如何实现 master 选举的
- 5. elasticsearch 分片,备份的设计
- 十丶JVM
- 1 jstack
- 2 Arthas(Java 应用诊断利器)
一、JAVA基础
1.ArrayList
2.HashMap
3.Concurrenthashmap
4.Stream
5.synchronized
6.线程池
7.CompletableFuture
8.Fork/join
9.数组与链表的区别
10.单例模式
1.饿汉模式
顾名思义,很饿,没见过吃的,一开始就要吃。其实就在在启动的时候就创建对象,这种方式比较的消耗内存,不太推荐在内存消耗较大的对象上面使用,好处是一开始就创建对象,没有多线程下的安全问题
public class Hungry {
//私有构造方法,防止自行实例化对象
private Hungry() {
}
//静态属性,在一开始就创建是实例对象
private final static Hungry HUNGRY = new Hungry();
//通过这个方法拿是实例对象
public static Hungry getInstance() {
return HUNGRY;
}
}
2.懒汉模式
顾名思义,很懒,不火烧眉毛不动手。这种模式只会在你使用对象的时候才创建对象,这种方式避免一开始就使用过多的内存,推荐在内存消耗较大的对象上面使用。
public class LazyMan {
//volatile->禁止指令重排,避免创建实例对象时重排指令空指针异常
private volatile static LazyMan lazyMan;
// 双重检测锁模式的 懒汉式单例 DCL懒汉式(double check lock)
public static LazyMan getInstance() {
if (lazyMan == null) {
synchronized (LazyMan.class) {//对LazyMan上锁,同一时间只能有一个线程能够进入创建对象
if (lazyMan == null) {
lazyMan = new LazyMan(); // 不是一个原子性操作
}
}
}
return lazyMan;
}
10.1、 为啥使用synchronized?
答:在多个线程进入getInstance()方法时,如果不加入synchronized锁住LazyMan.class,可能会有对个线程成功实例化对象,这就会违背单例模式的初衷,当加上以后,因为锁住的是class,所以只会有一个线程能够拿到锁来实例化对象,保证单例.
10.2、 又为啥使用volatile?
答:如果看过编译原理,其实里面有一个对编译器的介绍中,编译器会根据需要将代码的执行顺序进行优化,类比这里,我们在实例化一个对象的时候,可能是这样的顺序:为1.lazyMan分配内存空间->2.初始化lazyMan->3.为lazyMan指向第一步中分配的内存空间。但是在编译器的好心下,我们的执行顺序变成了1->3->2,那么这就出现问题了,我们的其他的线程拿对象会到哪里去拿?回到第一步分配的内存空间去拿!假如现在实例对象的线程正好按着1->3->2的顺序刚刚执行完了3,我们另一个线程过来了,因为2还没有执行,内存地址对应的内存空间中还没有东西,那么我们拿的就是个空,但是这个时候这个地址确实是被分配了的。这个时候就会出现空指针异常,也就是因为实例化对象的时候不满足原子性。
10.3、 那又又为啥用两个if (lazyMan == null)
答:好问题!第一个外层的好解释,在我们成功实例化对象之后,我们还需要进入加锁的哪一步吗?其实是不需要的,我们就可以直接返回对象去用就好了。那么第二个内层的又是用来干嘛的?在我们未创建实例对象的时候,我们假设有一千个线程来创建这个实例对象,我们一号线程拿到了锁,二号线程撞到了门上,没拿到锁,于是它在门口等,此时注意二号线程已经经过了第一个if (lazyMan == null),然后线程一执行完了实例,然后返回了这个实例对象LazyMan2@7f1d78ac,这个时候线程二啪的一下拿到了线程一扔下的锁,很快啊!然后又因为没有第二层的if (lazyMan == null),他又实例化了一个对象LazyMan2@688ee48d,然后线程二开心的返回了。此时我们的实例对象已经是线程二的LazyMan2@688ee48d,这个时候第三个线程来了,它在第一层的if (lazyMan == null)被告知对象已经实例化了,拿走去用吧,后来的都是像线程三一样被安排的明明白白。从此以后就只有一个对象LazyMan2@688ee48d,但是这个是正常的吗。我们也违反了单例模式的原则。所以需要加上第二层的if (lazyMan == null)。
11.单例模式中,双重检查锁是干什么用的
二次判空原因
第一次判断是为了验证是否创建对象,判断为了避免不必要的同步
第二次判断是为了避免重复创建单例,因为可能会存在多个线程通过了第一次判断在等待锁,来创建新的实例对象。
判断是为了在null的情况下创建实例代码会检查两次单例类是否有已存在的实例,一次加锁一次不加锁,一次确保不会有多个实例被创建。
单例模式中用volatile和synchronized来满足双重检查锁机制
12.volatile [禁止指令重排]
读volatile:每当子线程某一语句要用到volatile变量时,都会从主线程重新拷贝一份,这样就保证子线程的会跟主线程的一致。
写volatile: 每当子线程某一语句要写volatile变量时,都会在读完后同步到主线程去,这样就保证主线程的变量及时更新。
13.接口和类的区别
14.项目中反射是如何应用的
15.为什么重写hashcode一定要重写equals?
二、Redis
数据类型
| 数据类型 | 数据结构 |
|---|---|
| String | 字符串: key,value |
| List | 快速列表 quicklist【 双向列表+ziplist(压缩列表)】 |
| Hash | ziplist(压缩列表)+ hashtable |
| Set | intse【存储纯数字的情况下才会用到】,hashtable |
| ZSet | 有序集合:底层也是 Set 集合,只不过对于每个 value 前添加了 score,为了便于 Redis 对集合内元素排序, 【ziplist(压缩列表)+ skiplist【跳跃表】】 |
| Geo | 地理空间 |
| HyperLogLog | 基数统计: 是去重复统计功能的基数估计算法 |
| bitmap | 位图:是由 0 和 1 状态表现的二进制位的 bit 数组 |
| bitfield | 位域 |
| Stream | 流 |
1、Redis 的回收策略(淘汰策略)?
- volatile-
lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰 - volatile-
ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰 - volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-enviction(驱逐):禁止驱逐数据
2、Redis 过期键的删除策略?
- 定时删除:在设置键的过期时间的同时,创建一个定时器 timer。让定时器在键的过期时间来临时,立即执行对键的删除操作。
- 惰性删除:放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键。
- 定期删除:每隔一段时间程序就对数据库进行一次检查,删除里面的过期键。至于要删除多少过期键,以及要检查多少个数据库,则由算法决定。
3、Redis 的持久化机制是什么?各自的优缺点?
RDB(Redis DataBase)持久化方式:是指用数据集快照的方式半持久化模式记录 Redis 数据库的所有键值对,在某个时间点将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件,达到数据恢复。
优点:
只有一个文件 dump.rdb,方便持久化。
容灾性好,一个文件可以保存到安全的磁盘。
性能最大化,fork 子进程来完成写操作,让主进程继续处理命令,所以是 IO 最大化。
使用单独子进程来进行持久化,主进程不会进行任何 IO 操作,保证了 Redis的高性能。相对于数据集大时,比 AOF 的启动效率更高。
缺点:
数据安全性低。
RDB 是间隔一段时间进行持久化,如果持久化之间 Redis 发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候
AOF(Append-only file)持久化方式:是指所有的命令行记录以 Redis 命令请求协议的格式完全持久化存储保存为 aof 文件。
优点:
数据安全,aof 持久化可以配置 appendfsync 属性,有 always,每进行一次命令操作就记录到 aof 文件中一次。
通过 append 模式写文件,即使中途服务器宕机,可以通过 redis-check-aof 工具解决数据一致性问题。
AOF 机制的 rewrite 模式。AOF 文件没被 rewrite 之前(文件过大时会对命令进行合并重写),可以删除其中的某些命令(比如误操作的 flushall)
缺点:
AOF 文件比 RDB 文件大,且恢复速度慢。
数据集大的时候,比 RDB 启动效率低。、
4、说说 Redis 哈希槽的概念?
Redis 集群没有使用一致性 hash,而是引入了哈希槽的概念,Redis 集群有 16384 个哈希槽,每个 key 通过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
5、Redis 集群的主从复制模型是怎样的?
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有 N-1 个复制品。
6、Redis 集群会有写操作丢失吗?为什么?
Redis 并不能保证数据的强一致性,这意味着在实际中集群在特定的条件下可能会丢失写操作。
7、Redis 集群之间是如何复制的?
异步复制。
8、Redis 集群最大节点个数是多少?
16384 个。
9、Redis 集群如何选择数据库?
Redis 集群目前无法做数据库选择,默认在 0 数据库。
10、 Redis击穿、穿透、雪崩
-
缓存穿透
缓存穿透:指在redis缓存中不存在数据,这个时候只能去访问持久层数据库,当用户很多时,缓存都没有命中就会照成很大压力 解决方案 : (1)布隆过滤器(对可能查询的数据先用hash存储) (2)缓存空对象:在没有的数据中存一个空,而这些空的对象会设置一个有效期) -
缓存击穿
缓存击穿:指在同一个时间内访问一个请求的请求数过多,而在这个时候缓存某个key失效了,这个时候就会冲向数据库照成缓存击穿 解决方案: (1)设置缓存永远不过期 (2)加互斥锁,使用分布式锁,保证每个key只有一个线程去查询后端服务,而其他线程为等待状态。这种模式将压力转到了分布式锁上 -
缓存雪崩
缓存雪崩:在某个时间段,缓存集体过期、redis宕机
解决方案:给key的失效时间设置为随机时间,避免集体过期;双缓存;加互斥锁
三,RabbitMQ 【消息队列】
1. 为什么要使用rabbitmq
-
异步处理 - 相比于传统的串行、并行方式,提高了系统吞吐量。
-
应用解耦 - 系统间通过消息通信,不用关心其他系统的处理。
-
流量削锋 - 可以通过消息队列长度控制请求量;可以缓解短时间内的高并发请求。
-
消息通讯 - 消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。
2. 如何确保消息正确地发送至RabbitMQ?如何确保消息接收方消费了消息?
2.1 发送方确认模式
- 将信道设置成confirm模式(发送方确认模式),则所有在信道上发布的消息都会被指派一个唯一的ID。
- 一旦消息被投递到目的队列后,或者消息被写入磁盘后(可持久化的消息),信道会发送一个确认给生产者(包含消息唯一 ID)。
- 如果 RabbitMQ发生内部错误从而导致消息丢失,会发送一条nack(notacknowledged,未确认)消息。发送方确认模式是异步的,生产者应用程序在等待确认的同时,可以继续发送消息。当确认消息到达生产者应用程序,生产者应用程序的回调方法就会被触发来处理确认消息。
2.2,接收方确认机制
-
2.3,接收方消息确认机制
消费者接收每一条消息后都必须进行确认(消息接收和消息确认是两个不同操作)。 只有消费者确认了消息,RabbitMQ才能安全地把消息从队列中删除。 这里并没有用到超时机制,RabbitMQ仅通过Consumer的连接中断来确认是否需要重新发送消息。 也就是说,只要连接不中断,RabbitMQ给了Consumer足够长的时间来处理消息。保证数据的最终一致性;
下面罗列几种特殊情况
如果消费者接收到消息,在确认之前断开了连接或取消订阅,RabbitMQ会认为消息没有被分发,然后重新分发给下一个订阅的消费者。
(可能存在消息重复消费的隐患,需要去重)如果消费者接收到消息却没有确认消息,连接也未断开,则RabbitMQ认为该消费者繁忙,
将不会给该消费者分发更多的消息。
3、如何避免消息重复投递或重复消费?
在消息生产时,MQ内部针对每条生产者发送的消息生成一个inner-msg-id,作为去重的依据(消息投递失败并重传),避免重复的消息进入队列;
在消息消费时,要求消息体中必须要有一个 bizId(对于同一业务全局唯一,如支付ID、订单ID、帖子ID 等)作为去重的依据,避免同一条消息被重复消费。
4、消息基于什么传输?
由于TCP连接的创建和销毁开销较大,且并发数受系统资源限制,会造成性能瓶颈。RabbitMQ使用信道的方式来传输数据。
信道是建立在真实的TCP连接内的虚拟连接,且每条TCP连接上的信道数量没有限制
5、消息怎么路由?
消息提供方->路由->一至多个队列
消息发布到交换器时,消息将拥有一个路由键(routing key),在消息创建时设定。
通过队列路由键,可以把队列绑定到交换器上。
消息到达交换器后,RabbitMQ 会将消息的路由键与队列的路由键进行匹配(针对不同的交换器有不同的路由规则);
常用的交换器主要分为一下三种
-
fanout:如果交换器收到消息,将会广播到所有绑定的队列上
-
direct:如果路由键完全匹配,消息就被投递到相应的队列
-
topic:可以使来自不同源头的消息能够到达同一个队列。 使用topic交换器时,可以使用通配符
6、如何确保消息不丢失?
消息持久化,当然前提是队列必须持久化
RabbitMQ确保持久性消息能从服务器重启中恢复的方式是,将它们写入磁盘上的一个持久化日志文件,当发布一条持久性消息到持久交换器上时,Rabbit会在消息提交到日志文件后才发送响应。
一旦消费者从持久队列中消费了一条持久化消息,RabbitMQ会在持久化日志中把这条消息标记为等待垃圾收集。如果持久化消息在被消费之前RabbitMQ重启,那么Rabbit会自动重建交换器和队列(以及绑定),并重新发布持久化日志文件中的消息到合适的队列。
7、死信队列
8、消息优先级【VIP插队】
-
rabbitmq 创建消息队列的时候 x-max-priority 属性 可配置
1.优先级属性是 byte类型的,所以它的取值范围:[0,255]; 2.消息优先级为0或不设优先级的效果一样; 3.消息优先级大于设定的优先级最大值时,效果同优先级的最大值(我们可以自行实验);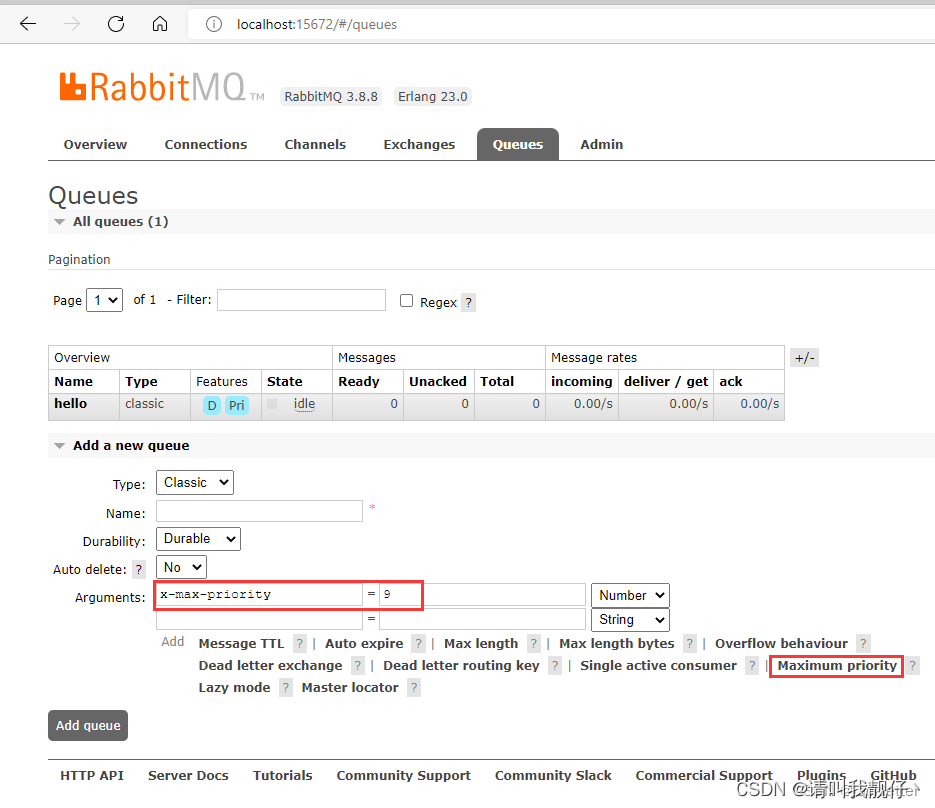
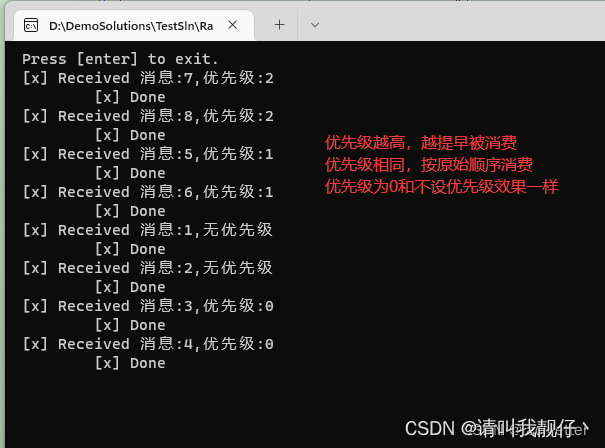
9、顺序消费
保证循序消费的方案【URL跳转】
四、MYSQL
-
1.SQL执行流程
- 客户端
- 连接器
- 查询缓存
- 分析器
- 优化器
- 执行器
- 存储引擎
-
2.索引
索引类型 数据结构 普通索引 普通索引是最基本的索引,它没有任何限制,值可以为空;仅加速查询。 唯一索引 唯一索引与普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。简单来说:唯一索引是加速查询 + 列值唯一(可以有null) 主键索引 主键索引是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。简单来说:主键索引是加速查询 + 列值唯一(不可以有null)+ 表中只有一个。 唯一索引 组合索引指在多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合。 -
索引的优点
1)创建索引可以大幅提高系统性能,帮助用户提高查询的速度; 2)通过索引的唯一性,可以保证数据库表中的每一行数据的唯一性; 3)可以加速表与表之间的链接; 4)降低查询中分组和排序的时间。 当然了,没有任何事情是完美的,索引也是如此,尽管索引好处非常多,但是其也有局限性合理性以及片面性。 -
索引的缺点
1)索引的存储需要占用磁盘空间; 2)当数据的量非常巨大时,索引的创建和维护所耗费的时间也是相当大的; 3)当每次执行CRU操作时,索引也需要动态维护,降低了数据的维护速度。 表在正常使用的时候,增删索引,会导致锁表 在当数据太少的时候,全盘搜索可能都比索引查找还快,就没有必要创建索引了,反而还会降低磁盘空间和性能。 -
应该创建索引的列
- 在
经常需要搜索的列上,可以加快搜索的速度 - 在作为
主键的列上,强制该列的唯一性和组织表中数据的排列结构 - 在
经常用在连接(JOIN)的列上,这些列主要是一外键,可以加快连接的速度 - 在
经常需要根据范围(<,<=,=,>,>=,BETWEEN,IN)进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的 - 在
经常需要排序(order by)的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间; - 在
经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
- 在
-
不该创建索引的列
- 对于那些在查询中很少使用或者参考的列不应该创建索引。
若列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。 - 对于那些只有很少数据值或者重复值多的列也不应该增加索引。
这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。 - 对于那些定义为text, image和bit数据类型的列不应该增加索引。
这些列的数据量要么相当大,要么取值很少。 - 当该列修改性能要求远远高于检索性能时,不应该创建索引。(修改性能和检索性能是互相矛盾的)
- 对于那些在查询中很少使用或者参考的列不应该创建索引。
-
3.深分页处理方案
-
4.redo log、binlog、innodb log
-
5.慢日志
-
6.sql语句优化
-
7. show profile
show profile命令可以显示多种性能分析数据,包括查询的执行时间、锁定等待时间、磁盘I/O等待时间、网络I/O等待时间等。 这些数据可以帮助开发人员确定查询的瓶颈所在,以便进行优化。 -
8.explain
mysql> explain select * from student; +----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------+ | 1 | SIMPLE | student | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 100.00 | NULL | +----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------+- id:选择标识符
- select_type:表示查询的类型。
- table:输出结果集的表
- partitions:匹配的分区
type:表示表的连接类型- possible_keys:表示查询时,可能使用的索引
- key:表示实际使用的索引
key_len:索引字段的长度ref:列与索引的比较- rows:扫描出的行数(估算的行数)
- filtered:按表条件过滤的行百分比
- Extra:执行情况的描述和说明
-
9.information_schema
-
10.两阶段提交
10.1 update 语句执行的内部流程
update user set name = "张三" where id = 2执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。 执行器拿到引擎给的行数据,把这个值修改成张三 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。 两阶段提交就是先提交 redolog,然后写入 binlog,binlog 写入成功后再提交 redolog -
11.B-True
关键字集合分布在整颗树中; 任何一个关键字出现且只出现在一个结点中; 搜索有可能在非叶子结点结束; 其搜索性能等价于在关键字全集内做一次二分查找; 自动层次控制;
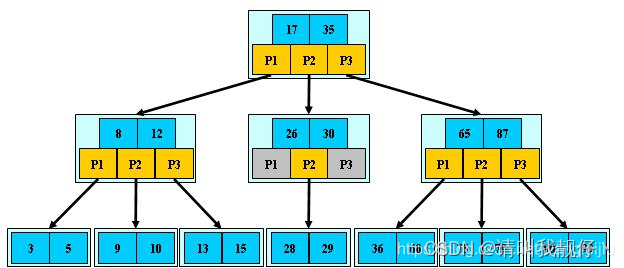
-
12.B+True
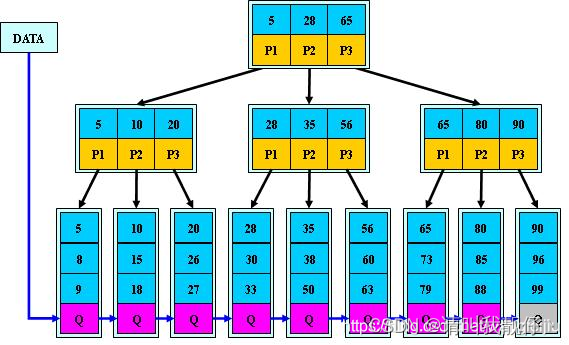
所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的; 不可能在非叶子结点命中; 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层; 每一个叶子节点都包含指向下一个叶子节点的指针,从而方便叶子节点的范围遍历。 更适合文件索引系统;
五、MyBatils
1.#{}和${}的区别是什么?
${}是字符串替换,#{}是预处理;
Mybatis在处理${}时,就是把${}直接替换成变量的值。
而Mybatis在处理#{}时,会对sql语句进行预处理,将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值;
使用#{}可以有效的防止SQL注入,提高系统安全性。
2.Mybatis的一级、二级缓存
(1)一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当 Session flush 或 close 之后,该 Session 中的所有 Cache 就将清空,默认打开一级缓存。
(2)二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同在于其存储作用域为 Mapper(Namespace),并且可自定义存储源,如 Ehcache。默认不打开二级缓存,要开启二级缓存,使用二级缓存属性类需要实现Serializable序列化接口(可用来保存对象的状态),可在它的映射文件中配置 ;
(3)对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了C/U/D 操作后,默认该作用域下所有 select 中的缓存将被 clear 掉并重新更新,如果开启了二级缓存,则只根据配置判断是否刷新。
六、Spring
可以参考
1. AOP
2.IOC
3.双亲委派
4.MVC执行流程
5. 如何把服务交给Spring管理
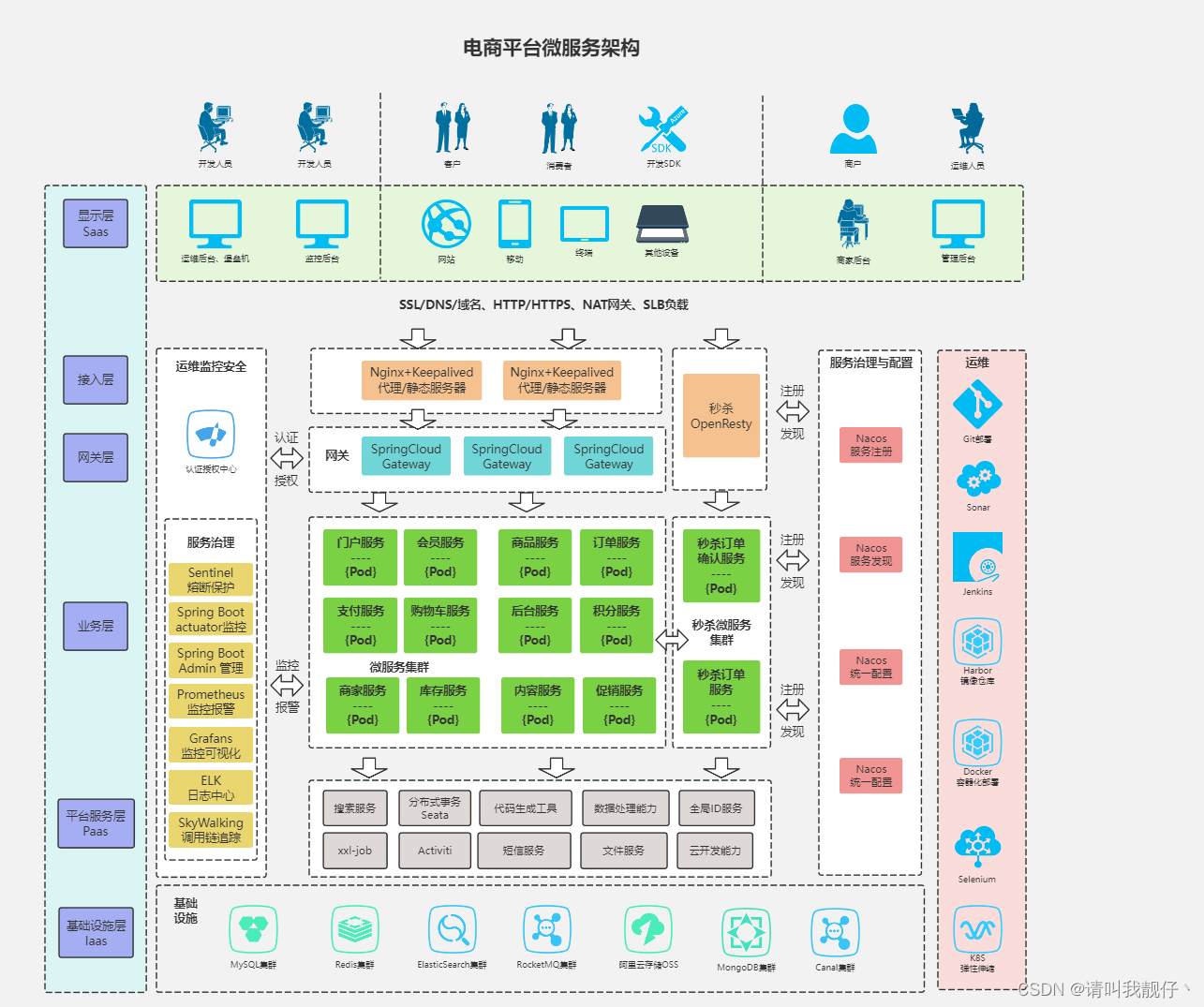
七、SpringCloud Albaba
简介
Spring Cloud Alibaba 致力于提供微服务开发的一站式解决方案。此项目包含开发分布式应用微服务的必需组件,方便开发者通过 Spring Cloud 编程模型轻松使用这些组件来开发分布式应用服务。
依托 Spring Cloud Alibaba,您只需要添加一些注解和少量配置,就可以将 Spring Cloud 应用接入阿里微服务解决方案,通过阿里中间件来迅速搭建分布式应用系统。
主要功能
- 服务限流降级 :默认支持 WebServlet、WebFlux, OpenFeign、RestTemplate、Spring Cloud Gateway, Zuul, Dubbo 和 RocketMQ 限流降级功能的接入,可以在运行时通过控制台实时修改限流降级规则,还支持查看限流降级 Metrics 监控。
- 服务注册与发现 :适配 Spring Cloud 服务注册与发现标准,默认集成了 Ribbon 的支持。
- 分布式配置管理 :支持分布式系统中的外部化配置,配置更改时自动刷新。
- 消息驱动能力 :基于 Spring Cloud Stream 为微服务应用构建消息驱动能力。
- 分布式事务 :使用 @GlobalTransactional 注解, 高效并且对业务零侵入地解决分布式事务问题。
- 阿里云对象存储 :阿里云提供的海量、安全、低成本、高可靠的云存储服务。支持在任何应用、任何时间、任何地点存储和访问任意类型的数据。
- 分布式任务调度 :提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。同时提供分布式的任务执行模型,如网格任务。网格任务支持海量子任务均匀分配到所有 Worker(schedulerx-client)上执行。
- 阿里云短信服务 :覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
组件
-
[Sentinel] :阿里巴巴源产品,把流量作为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
-
[Nacos] :一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
-
[RocketMQ] :一款开源的分布式消息系统,基于高可用分布式集群技术,提供低延时的、高可靠的消息发布与订阅服务。
-
[Dubbo] :Apache Dubbo™ 是一款高性能 Java RPC 框架。
-
[Seata] :阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案。
-
[Alibaba Cloud OSS] : 阿里云对象存储服务(Object Storage Service,简称 OSS),是阿里云提供的海量、安全、低成本、高可靠的云存储服务。您可以在任何应用、任何时间、任何地点存储和访问任意类型的数据。
-
[Alibaba Cloud SchedulerX]: 阿里中间件团队开发的一款分布式任务调度产品,提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。
-
[Alibaba Cloud SMS] : 覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
组件
Nacos 服务发现、配置管理和服务管理平台
1.多人本地开发,如何共同使用测试环境的同一个Nacos进行调试?
2.Config 配置信息更改,代码中是如何感知到的?
3.Config 配置文件存储在哪里?
4.服务的注册发现是如何实现的?
Getway 网关
1.如何使用灰度发布
2.白名单
2.路径跳转
Sentinel 分布式服务架构的实时流量控制、熔断降级和系统负载
Seata 分布式事务
Admin 监控服务
SkyWalking 链路追踪
RocketMQ 消息队里
八丶微服务面试题
-
1.微服务中A服务调用B服务如何传递Token?
-
2.微服务 如何把A服务提供为工具,然后引入到别的服务中,原理是什么?
九丶Elasticsearch
【参考】
1.搜索字段的类型设计 field type【text、keyword】
text用于全文搜索,支持分词,
keyword则用于精确搜索,不分词。
2. Elasticsearch 的打分机制
2.1、TF-IDF 逆文档频率,TF term frequency 词频, IDF inverse document frequency 逆文档频率

第一个句子提到 Elasticsearch 一次 ,而第二个句子提到 Elasticsearch 两次,所以包含第二句话的文档应该比包含第一句话的文档拥有更高的得分。按照数量来讨论,第一句话的
**词频( TF )是 1,而第二句话的词频将是 2。**
2.2、如果一个分词在索引的不同文档中出现越多的次数,那么它就越不重要。逆文档频率是一个重要的因素,用于平衡词条的词频。

词条 Elasticsearch的文档频率是 2 (3篇中2篇出现),文档频率的逆源自得分乘以 1/DF,这里 DF是该词条的文档频率。
词条拥有更高的文档频率, 它的权重就会降低。
词条 the 的文档频率是 3 (3篇中都出现),尽管the在最后一篇文档中出现了两次,它的文档频率还是3。
因为逆文档频率只检查一个词条是否出现在某文档中,而不检查它出现多少次。
2.3、 Lucene评分公式
词条的词频越高,得分越高
索引中词条越罕见,逆文档频率越高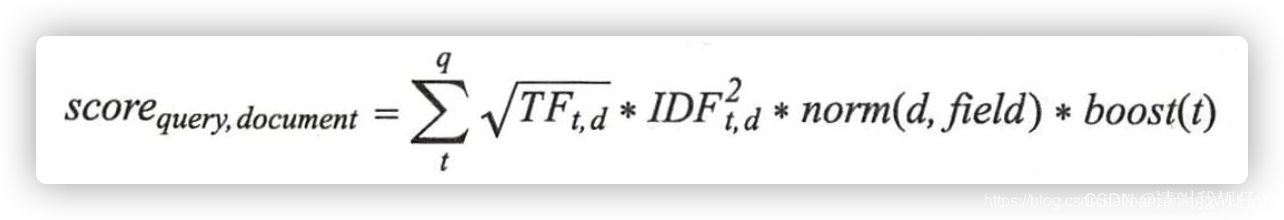
2.4. 其他打分方法
1.Okapi BM25
2.随机性分歧 (Divergence from randomness),即 DFR 相似度
3.基于信息的 (Information based), 即lB相似度
4.LM Dirichlet相似度
5.LM Jelinek Mercer相似度
3. elasticsearch 的倒排索引是什么
4. elasticsearch 是如何实现 master 选举的
5. elasticsearch 分片,备份的设计
3.我是文本 粉红


![LeetCode[剑指Offer51]数组中的逆序对](https://img-blog.csdnimg.cn/252cf06f588e4ff38bfd14b626be18f4.png)