为了深⼊理解强化学习(Reinforcement Learning,简称RL)这⼀核⼼概念,我们从⼀个⽇常游戏的例⼦出发。在“贪吃蛇”这个经典游戏中,玩家需要掌控⼀条蛇,引导它吞吃屏幕上出现的各种果实。每次成功捕获果实,得分就会相应增加,同时蛇的身体也会逐渐变⻓。玩家必须避免蛇碰撞到屏幕边缘或⾃身,否则游戏就会结束。游戏的主要⽬标是获得尽可能⾼的分数。
现在,假如我们想让⼀台AI模型来接管并进⾏这个游戏,我们应该如何训练它呢?本⽂将通过探索这个问题,揭示 AlphaGo 如何通过强化学习击败⼈类的秘密。

(图片由山石网科新技术研究院姜珂用AI制作)
一、⼀般机器学习VS强化学习
在深⼊探讨如何训练模型玩游戏之前,我们⾸先需要理解机器学习和强化学习之间的核⼼差异。
传统的机器学习,如监督学习和⽆监督学习,主要依赖于预先标记好的数据集进⾏学习。以分类问题为例,我们会向模型提供⼤量带有标签的数据,如图⽚和相应的物体名称,然后模型根据这些数据学习如何对新的图⽚进⾏分类。在这种学习过程中,每次预测的正确性或错误性都会⽴即得到反馈,并⽤于调整模型的参数,以提⾼未来预测的准确性。
然⽽,强化学习与此截然不同。⾸先,强化学习没有预先标记好的数据集。回到我们的《贪吃蛇》示例,模型需要⾃我探索游戏环境,找出哪些⾏为可以提⾼得分,哪些⾏为可能导致游戏结束。其次,强化学习的反馈(也称为奖励)并不总是⽴即得到。例如,蛇在游戏中的某些动作可能会⽴即导致游戏结束,这种负⾯反馈是即时的;⽽其他动作可能会使蛇避开危险,但这种正⾯反馈只有在⼀段时间后蛇还活着并成功吃到果实时才能确认。因此,强化学习需要学习如何根据延迟的奖励来调整⾏动策略。

(图片由山石网科新技术研究院姜珂用AI制作)
二、强化学习的基本原理和过程
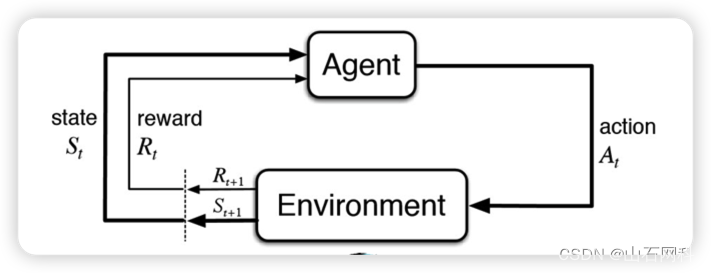
图片来源于论文,标题为"The Ultimate Beginner’s Guide to Reinforcement Learning"
强化学习的基本过程可以归结为四个主要元素:环境(Environment)、智能体(Agent)、⾏为(Action)和奖励(Reward)。这个过程可以看作⼀个循环:智能体在环境中采取⾏为,环境因此发⽣改变,并向智能体提供奖励和新的环境状态,智能体根据这些信息决定下⼀步的⾏为。
具体到《贪吃蛇》游戏,智能体就是我们控制的蛇,环境就是游戏界⾯,⾏为则是蛇的移动⽅向,奖励则是每吃掉⼀个果实得到的分数或者游戏失败的惩罚。在游戏开始时,蛇可能会随机选择⾏为,但随着不断地尝试和学习,蛇会逐渐发现哪些⾏为会带来正⾯奖励,哪些⾏为会导致游戏结束,然后调整⾃⼰的策略以获取更⾼的分数。
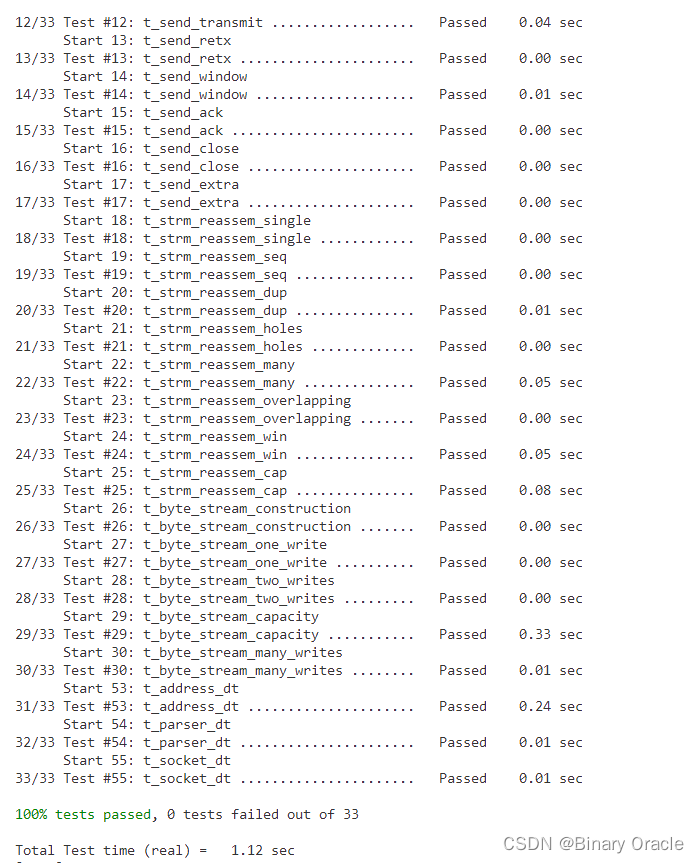
强化学习的基本⽬标就是找到⼀个最优策略,让智能体在与环境的交互中获取最⼤的累计奖励。这⾥涉及到⼀个重要的概念叫做“价值函数”,它预测了在某个状态下执⾏某个⾏为或者遵循某个策略能够获得的预期奖励。通过最⼤化价值函数,智能体就可以找到最优的⾏为策略。
三、价值函数
价值函数就像是⼀个指南,告诉你在当前的位置(状态)下,哪个⽅向(⾏动)可能会让你获得更多的分数。这个"可能"是基于你过去的经验和学习得出的。也就是说,价值函数是对未来奖励的⼀种预测或期望。
回到贪吃蛇的例⼦,假设你是那条蛇,你⾯前有⼀个苹果。你的⽬标是吃掉它。在这个情况下,价值函数可能会告诉你,向苹果的⽅向移动可能会让你获得更多的分数,因为吃到苹果就能得分。
然⽽,这个决策并不是只基于当前的情况。价值函数还要考虑⻓期的奖励。⽐如,如果直接向苹果移动可能会让你撞到墙或者⾃⼰的尾巴,那么这个⾏动的⻓期奖励可能就会变得很低。因此,你可能需要选择⼀个看起来迂回,但更安全的路线来接近苹果。
这就是价值函数的基本思想。它指导AI模型在环境中选择最佳的⾏动,以期最⼤化未来的奖励。同时,这个函数也是动态更新的,随着AI模型与环境的互动和学习,它会不断调整⾃⼰的预测,从⽽帮助模型更好地适应环境和改进策略。
下⾯列出⼏种⽐较简单的价值函数的计算原理:
1. 蒙特卡洛⽅法(Monte Carlo Methods)
想象你正在玩⼀个掷骰⼦的游戏,你并不知道每次掷出的点数对你的最终得分有什么影响,你只知道游戏结束后的总得分。这就是蒙特卡洛⽅法的基本思想。你会反复玩这个游戏,记录每次的⾏动和结果,然后通过⽐较不同游戏的结果,来推断出每次掷骰⼦的价值。
但是,这种⽅法有⼀个明显的局限性,那就是它需要很多次的试验和很⻓的时间才能得到准确的结果。此外,它只能⽤于可以清晰定义结束条件的问题,例如棋盘游戏。对于没有明确结束的问题,⽐如⾃动驾驶,蒙特卡洛⽅法可能就⽆法应⽤。
2. 时序差分学习(Temporal-Difference Learning)
时序差分学习可以理解为⼀种更快的蒙特卡洛⽅法。它不需要等到游戏结束才开始学习,⽽是在每⼀步都尝试去学习。每当你做出⼀个决定,你就会看看这个决定的结果如何,然后调整你对这个决定的期待。这就好像你在⾛迷宫,每⾛⼀步,都会根据当前的情况来判断之前的决定是否正确。
时序差分学习的⼀个局限性是它假设环境是⻢尔科夫决策过程(MDP),也就是说,下⼀步的结果只取决于当前的状态和决定。但在现实⽣活中,很多情况下,下⼀步的结果可能会受到前⼏步的影响,这就使得时序差分学习变得复杂。
3. Q-Learning
Q-Learning就像⼀个更聪明的时序差分学习。它试图学习在每个状态下采取每种⾏动的价值,然后总是选择价值最⾼的⾏动。这就好像你在玩⼀个游戏,每到⼀个新的关卡,你都会尝试所有可能的⾏动,看看哪⼀个能得到最⾼的分数,然后在以后遇到这个关卡时,总是选择这个⾏动。
Q-Learning的局限性在于它可能会过于贪婪,只关注当前的最⾼奖励,⽽忽视了⻓远的规划。⽐如,你在玩⼀个游戏,看到前⽅有⼀个宝箱,你可能会⽴即去拿它,⽽没有注意到这样做可能会让你掉⼊陷阱。此外,Q-Learning在⼤规模问题中也可能⾯临计算资源的问题,因为它需要对每个状态和动作对都存储⼀个价值,⽽在实际问题中,可能存在⼤量的状态和动作对。
在实际的复杂问题中,我们往往不能直接计算出价值函数。反⽽,我们需要通过⼀种称为深度强化学习的技术,训练出⼀个能够预测价值函数的模型。这个模型通常是⼀个深度神经⽹络,它可以处理⼤量的状态和动作对,并能够通过学习不断提⾼预测的准确性。
四、AlphaGo是如何训练⽣成的?

(图片由山石网科新技术研究院姜珂用AI制作)
AlphaGo 是由 DeepMind(⼀个属于 Google 的⼦公司)开发的⼈⼯智能围棋程序。在 2016 年,AlphaGo 在⼀场历史性的⽐赛中成功战胜了世界级围棋⼤师李世⽯,成为了第⼀个能够在公开⽐赛中击败⼈类世界冠军的⼈⼯智能
程序, 这个轰动⼀时的AlphaGo也是通过强化学习的⽅式来实现的:
1. 初始训练
AlphaGo⾸先使⽤数百万局的⼈类围棋⽐赛数据进⾏初始训练。这些数据是从互联⽹围棋⽹站上获取的。通过这些数据,AlphaGo训练了⼀个深度神经⽹络,学习预测⼈类选⼿的棋招。这个神经⽹络被称为策略⽹络,它可以给出在当前棋局状态下每个可能的棋步的概率。
2. ⾃我对弈
AlphaGo通过⾃我对弈进⾏强化学习。也就是说,两个相同的AlphaGo副本互相对战。每⼀局结束后,都会根据对局结果更新神经⽹络的参数。在这个过程中,AlphaGo学习了如何落⼦,不仅要考虑当前的棋局状态,还要考虑未来可能的⾛势,从⽽优化⻓期的奖励。这个过程⽣成了⼀个新的神经⽹络,被称为价值⽹络,它可以评估在当前棋局状态下赢棋的概率。
3. 蒙特卡洛树搜索
在实际对弈中,AlphaGo通过策略⽹络和价值⽹络,配合蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)来选择棋步。策略⽹络⽤于缩⼩搜索空间,给出可能的好棋步,⽽价值⽹络⽤于评估在各种棋步后的棋局状态。这样,AlphaGo能够平衡探索和利⽤,选择最有可能赢得棋局的棋步。
通过这些⽅法,AlphaGo能够在围棋这个复杂度极⾼的游戏中,找到优秀的策略,战胜⼈类顶尖选⼿。
五、Chatgpt的训练(RLFH)
再让我们看看强化学习如何在⾃然语⾔处理⽅向中发挥了作⽤。最近⼤⽕的OpenAI的聊天机器⼈ChatGPT就使⽤了⼀种叫做“强化学习从⼈类反馈(Reinforcement Learning from Human Feedback,简称RLHF)”的技术,使ChatGPT达到了前所未有的智能性。
在训练ChatGPT的过程中,第⼀步是通过监督学习对模型进⾏初始训练。在这个阶段,通过⼤量的互联⽹⽂本,让ChatGPT学习⼈类如何使⽤⾃然语⾔来表达思想。这就好像是在给ChatGPT上⼀个语⾔课程,让它理解单词、短语、句⼦等语⾔元素的含义和⽤法,以及他们如何组合在⼀起来表达复杂的思想和信息。
然后,再进⼊了强化学习阶段。在这个阶段,我们采⽤了⼀种名为“强化学习从⼈类反馈(Reinforcement Learning from Human Feedback,简称RLHF)”的技术。这个阶段的⽬标是让ChatGPT理解什么样的回应是好的,什么样的回应是不好的。
⾸先,需要让⼀组⼈类评估员与ChatGPT进⾏交互,并让他们对ChatGPT的回应进⾏评价。评估员会考虑回应的准确性、相关性、清晰性、有⽤性等因素,并对其进⾏评分。这就提供了⼀种直观的“指南”,让ChatGPT知道在不同情境下,什么样的回应是优秀的。
接着,我们创建了⼀个模型,叫做“⽐较模型”,它的任务是学习这个“指南”,并尝试预测在给定情境下,评估员会如何对不同的回应进⾏评分。⼀旦有了这个模型,就可以⽤它作为⼀个奖励函数来指导ChatGPT的训练。
在强化学习阶段,ChatGPT会试图找出最好的回应,即能得到最⾼评分的回应。它会尝试各种不同的回应,看看哪些回应能得到⾼分,哪些得分低。然后,它会根据这些信息更新⾃⼰的“策略”,即在不同情境下应该给出什么样的回应。
这就是强化学习的美妙之处,它可以通过不断试验和学习,找出在各种情况下最佳的⾏动。

图片来源于论文,标题为"DeepSpeed Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales"
六、强化学习在⽹络安全⽅⾯的应⽤

(图片由山石网科新技术研究院姜珂用AI制作)
就像ChatGPT⼀样,强化学习也可以被⽤于改进⽹络安全的各个⽅⾯。让我们来看看⼀些具体的例⼦:
1. ⼊侵检测系统
想象⼀下,你的计算机是⼀个守卫,它需要决定是否让⼀位访客进⼊。在这个情况下,强化学习可以帮助计算机"学习"如何做出最好的决定。强化学习模型通过学习过去的⽹络流量数据和⼊侵尝试,了解到了什么样的⽹络⾏为看起来像是恶意的,什么样的⾏为看起来像是正常的。然后,当新的⽹络流量进⼊时,模型可以判断出这是否可能是⼀次⼊侵尝试,并据此采取⾏动。
2. ⾃适应防御系统
⽹络攻击者不断变化他们的战术来试图突破我们的防御。幸运的是,强化学习可以使我们的防御系统适应这些变化。具体来说,系统可以学习如何根据观察到的⽹络⾏为更改其防御策略,例如调整防⽕墙规则或更新安全软件。
3. 安全策略优化
想象⼀下,你是⼀个⽹络管理员,需要决定如何配置⽹络以最⼤程度地提⾼安全性。强化学习可以帮助你找到最佳策略。它可以模拟不同的策略,看看哪些策略在⾯对攻击时表现最好。这种优化可以应⽤于许多领域,例如⽹络流量管理、访问控制和加密策略。
4. ⾃动化渗透测试
渗透测试是⼀种模拟⿊客攻击的⽅式,以发现并修复安全漏洞。但是,执⾏这些测试通常需要⼤量的时间和专业知识。这是强化学习可以帮助的地⽅。强化学习模型可以⾃动进⾏这些测试,寻找可能的攻击路径,识别潜在的漏洞,甚⾄建议修复措施。
5. ⽹络威胁猎捕
⽹络威胁猎捕是指寻找和研究新的⽹络攻击⽅式。强化学习可以⾃动化这个过程,帮助安全专家更快地收集和分析信息。例如,⼀个强化学习模型可能会⾃动分析⽹络流量,寻找未知的攻击模式,然后向⼈类专家报告这些新发现。
七、结尾
强化学习(RL)的优点主要表现在其⾃主学习和决策优化能⼒上。其独特之处在于,RL可以在没有预先标记的环境中独⽴学习,通过与环境的互动,持续更新其知识库。它特别适合处理涉及连续决策的问题,因为在执⾏任务的同时,它能够进⾏在线学习,不断优化⾃身的策略。
强化学习的另⼀特⾊在于,它不仅着眼于眼前的短期收益,更重视未来的⻓期奖励。在制定策略时,强化学习会结合⻓期视⻆进⾏考量,实现效益的最⼤化。这种在瞬息万变的环境中稳定并持续的优化过程,使得强化学习在⾯对复杂、动态任务,或者在需要考虑⻓期效果的任务时,显得特别有⼒。
总的来说,强化学习的⾃主学习能⼒、连续决策优化、⻓期奖励考量,为解决⼀系列复杂问题提供了新的视⻆和可能。⽽这些优势,正是⼀般的深度神经⽹络在⾯对类似任务时可能⾯临的挑战。因此,强化学习⽆疑是深度学习领域的⼀个重要⽀柱,其潜⼒和应⽤前景令⼈期待。
山石网科新技术研究院简介:
成立于2021年初,横跨中美两地,现有成员30余人。
研究院成员以信息安全技术专业的博士和硕士为主,具有丰富的网络安全产品与行业经验;关注人工智能机器学习在网安产品中的应用、山石网科八大类网安产品及服务所涉及的新技术预研、攻防对抗技术实验和网安硬件架构创新等四大方面。创新结果已申请了二十余项国家专利,现已完成包括基于图引擎的威胁关联分析算法、DLP内容分类识别算法、安全服务边缘(SSE)和基于ASIC的信创安全平台在内的十多类研究成果并成功运用到山石网科产品与服务中,获得了广泛的市场影响力。
面向未来数字世界将长期伴生、变化的网络安全问题,研究院将继续洞察各类前瞻技术,围绕山石网科“可持续安全运营”的技术理念,以远见超越未见,为您的安全竭尽全力!