文章目录
- 前言
- 1. 读入文本格式数据文件
- 1.1 pd.read_csv
- 实例
- 1.2 pd.read_table
- 1.3 pd.read_excel
- 实例
- 1.4 pd.read_sql
- 2. 保存数据文件
- 2.1 保存数据文件到外部文件中
- 2.2 保存数据文件到数据库中
- 结束语
前言
在数据分析和数据挖掘中,数据通常以文件的形式存储在磁盘上。文件I/O(输入/输出)操作是指将数据从文件读取到内存或将内存中的数据写入到文件中的过程。
在实际应用中,数据可能存储在不同的文件中,如CSV、Excel、JSON等格式
- CSV(Comma-Separated Values):逗号分隔值文件是最常见的数据文件格式之一。它将数据以纯文本形式存储,每行表示一条记录,各字段之间用逗号或其他分隔符分隔。
- Excel:Excel是一种电子表格软件,广泛用于数据处理和数据分析。它支持多个工作表,每个工作表包含多行和列的数据。
- JSON(JavaScript Object Notation):JSON是一种轻量级的数据交换格式,易于阅读和编写。它以键值对的形式组织数据,支持嵌套结构。
- SQL(Structured Query Language):SQL是一种用于管理和查询关系数据库的语言,可以将数据存储在数据库中,并通过SQL查询从数据库中检索数据。
- HDF5(Hierarchical Data Format 5):HDF5是一种用于存储和组织大规模科学数据的文件格式,适用于存储复杂的数据集和多维数组。
- Parquet:Parquet是一种列式存储格式,通常用于大规模数据分析,特别适合处理嵌套数据结构。
在这篇博客中主要介绍CSV、Excel、SQL文件的I\O操作
1. 读入文本格式数据文件
下面将会介绍三种读取数据文件的操作,主要内容包括函数、函数参数、实例三个部分
1.1 pd.read_csv
CSV(Comma-Separated Values)文件是一种文本文件格式,用于存储简单的表格数据,每行表示一条记录,每个字段之间用逗号或其他字符进行分隔。CSV文件是一种常用的数据交换格式,因为它简单、轻量且易于处理,可以被各种不同的应用程序和编程语言读取和写入。在Pandas中使用pd.read_csv来读取.csv后缀的文件
pd.read_csv(
# 读入的文件路径
filepath_or_buffer: ""
# 列分割符号
sep = ''
# 指定第几行作为变量名
header =
# 定义变量名列表
name =
# 索引的列名
index_col =
# 读入文件的编码
encoding =
# 读哪几列
usecols =
# 读多少行
nrow =
# 跳过读取文件的行数,可以是整数或列表形式
skiprows
############不常用的参数#######
# 指定每列的数据类型,可以是字典形式的列名与数据类型的映射
dtype
# 指定需要解析为日期的列,可以是列名的列表或者列的索引位置的列表
parse_dates
# 用于指定日期解析函数,将字符串转换为日期对象的函数
date_parser
# 指定要视为缺失值的值,可以是单个值、列表、字典或者字符串
na_values
# 布尔值,是否过滤缺失值
na_filter
# 跳过文件末尾的行数
skipfooter
# 添加前缀到列名,如果没有指定列名,则使用prefix和列的索引号
prefix
# 是否跳过空行
skip_blank_lines = True
# 设置注释字符,出现在该字符之后的行将被视为注释而跳过
comment
)
实例
案例数据表covid19.csv
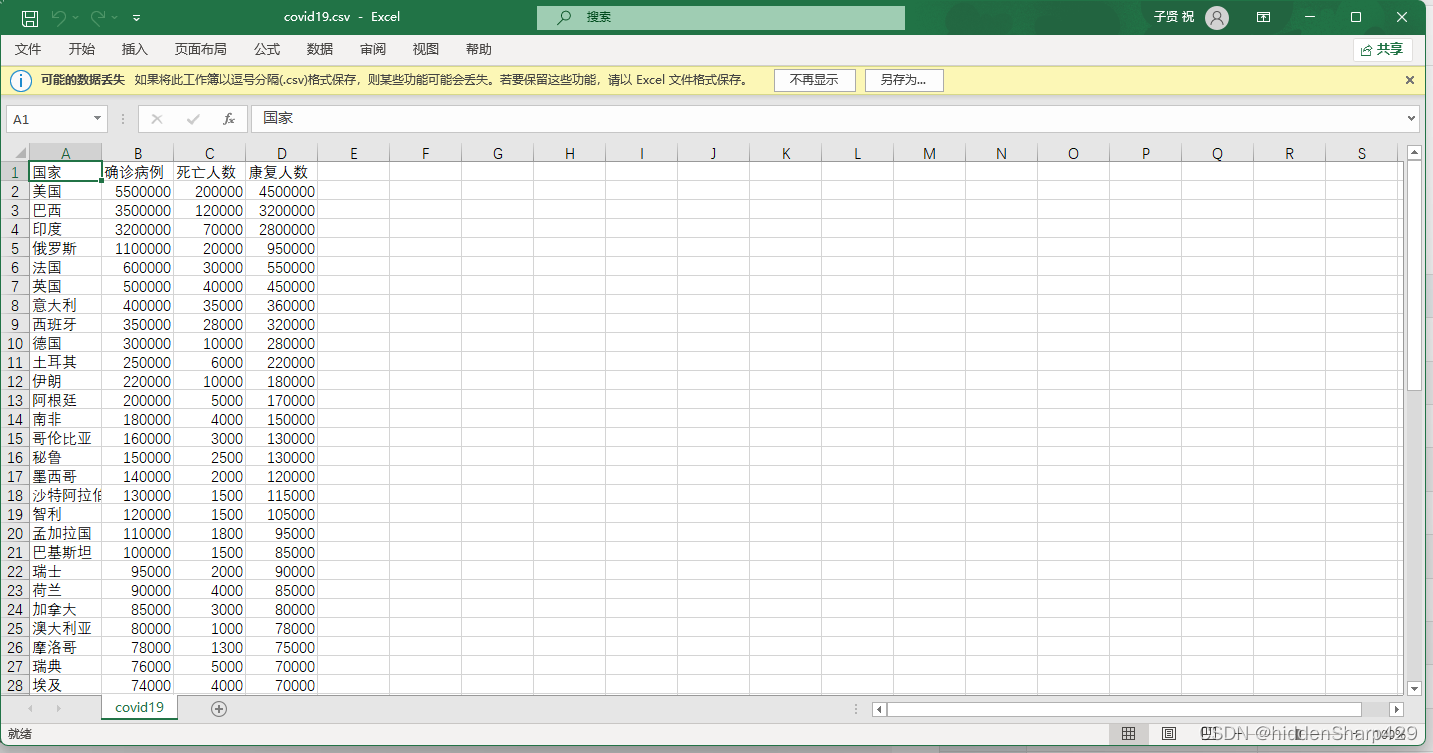
In[0]:
import pandas as pd
csv1 = pd.read_csv("covid19.csv", encoding="UTF-8")
csv1
out[0]:
| 国家 | 确诊病例 | 死亡人数 | 康复人数 | |
|---|---|---|---|---|
| 0 | 美国 | 5500000 | 200000 | 4500000 |
| 1 | 巴西 | 3500000 | 120000 | 3200000 |
| 2 | 印度 | 3200000 | 70000 | 2800000 |
| 3 | 俄罗斯 | 1100000 | 20000 | 950000 |
| 4 | 法国 | 600000 | 30000 | 550000 |
| ... | ... | ... | ... | ... |
| 57 | 尼泊尔 | 12000 | 100 | 11000 |
| 58 | 阿尔巴尼亚 | 10000 | 200 | 9000 |
| 59 | 泽西岛 | 8000 | 100 | 7000 |
| 60 | 莱索托 | 6000 | 100 | 5000 |
| 61 | 安道尔 | 4000 | 50 | 3000 |
62 rows × 4 columns
1.2 pd.read_table
read_table功能与read_csv类似,不过read_table的默认列分割符默认为"\t",sep = "\t"
pd.read_table实际上是pd.read_csv的一个别名,两者功能几乎完全相同,只是pd.read_table默认的分隔符是制表符 \t。因此,通常更推荐使用pd.read_csv,除非你确定要使用制表符作为分隔符。
In[1]:
table1 = pd.read_table("covid19.csv")
table1
out[1]:
| 国家,确诊病例,死亡人数,康复人数 | |
|---|---|
| 0 | 美国,5500000,200000,4500000 |
| 1 | 巴西,3500000,120000,3200000 |
| 2 | 印度,3200000,70000,2800000 |
| 3 | 俄罗斯,1100000,20000,950000 |
| 4 | 法国,600000,30000,550000 |
| ... | ... |
| 57 | 尼泊尔,12000,100,11000 |
| 58 | 阿尔巴尼亚,10000,200,9000 |
| 59 | 泽西岛,8000,100,7000 |
| 60 | 莱索托,6000,100,5000 |
| 61 | 安道尔,4000,50,3000 |
62 rows × 1 columns
我们再来验证一下,修改一下pd.read_table的sep参数,会不会跟pd.read_csv返回结果一样
In[2]:
table2 = pd.read_table("covid19.csv", sep=",")
table2
out[2]:
| 国家 | 确诊病例 | 死亡人数 | 康复人数 | |
|---|---|---|---|---|
| 0 | 美国 | 5500000 | 200000 | 4500000 |
| 1 | 巴西 | 3500000 | 120000 | 3200000 |
| 2 | 印度 | 3200000 | 70000 | 2800000 |
| 3 | 俄罗斯 | 1100000 | 20000 | 950000 |
| 4 | 法国 | 600000 | 30000 | 550000 |
| ... | ... | ... | ... | ... |
| 57 | 尼泊尔 | 12000 | 100 | 11000 |
| 58 | 阿尔巴尼亚 | 10000 | 200 | 9000 |
| 59 | 泽西岛 | 8000 | 100 | 7000 |
| 60 | 莱索托 | 6000 | 100 | 5000 |
| 61 | 安道尔 | 4000 | 50 | 3000 |
62 rows × 4 columns
看的出来返回的结果与pd.read_csv一模一样。
1.3 pd.read_excel
Excel文件是Microsoft Excel电子表格软件的文件格式,Excel是二进制文件,它包含多个工作表(也称为工作簿),每个工作表是一个表格,由行和列组成。Excel文件支持复杂的数据结构,可以包含多种数据类型、公式、图表、图像等。Excel文件通常以.xls或.xlsx为后缀名。在Pandas中同样可以使用pd.read_excel来读取.xls或者.xlsx后缀的文件
pd.read_excel(
# 要读取的Excel文件的路径(字符串),或者一个类似于文件描述符的对象(如文件、字节流等)
io = ""
# 要读入的表单名字,可以是字符串(表示工作表的名称)或整数(表示工作表的索引)。如果为None,则默认读取第一个工作表
sheet_name = ""
# 其他的参数都跟read_csv基本类似
...
...
)
其中sheet_name参数可以使用字符串类型,默认创建一个excel文件会有三个sheet_name,它们分别是Sheet1、Sheet2、Sheet3
注意这里的Sheet都是大写的S
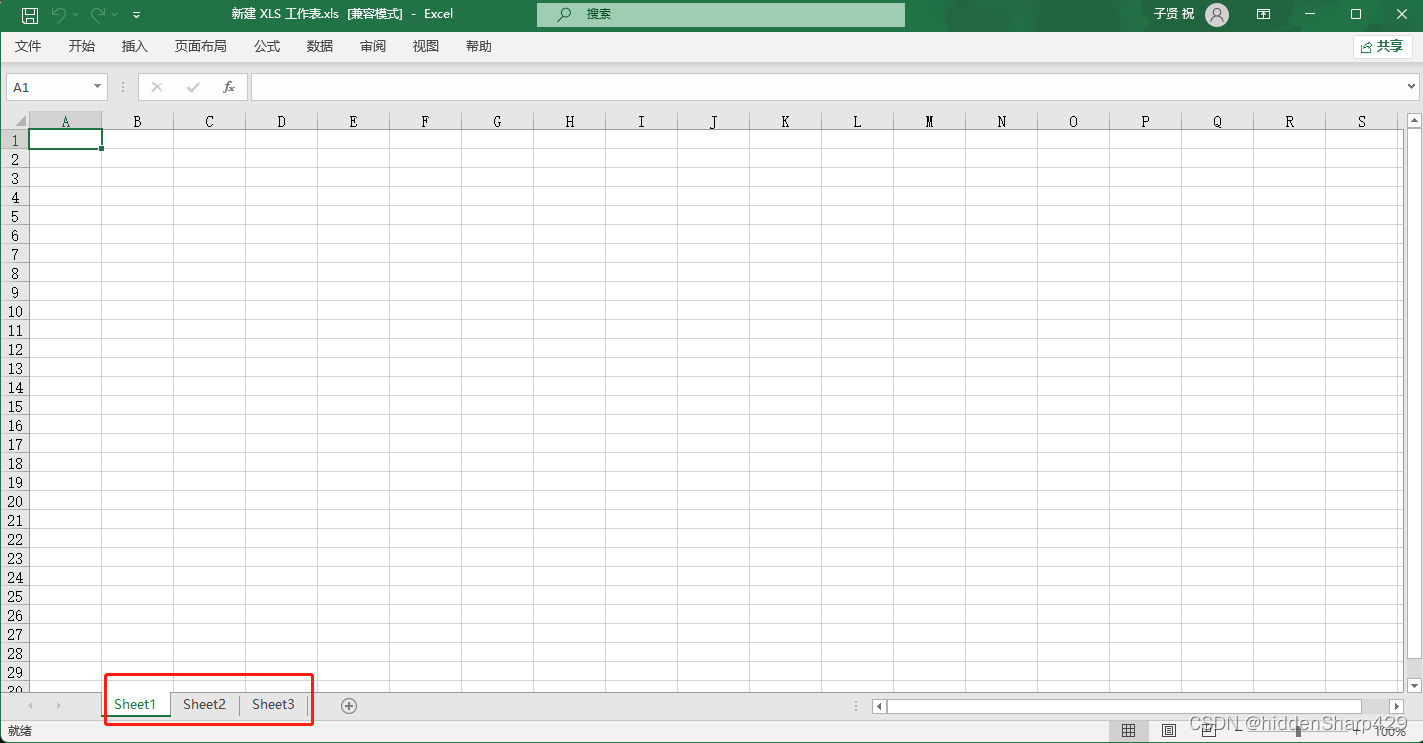
同时可以使用数字之间访问sheet_name,其中0代表第一个子表、1代表第二个子表,2代表第三个子表对应的就算这里的Sheet1\2\3
实例
案例数据表university_rank.xls
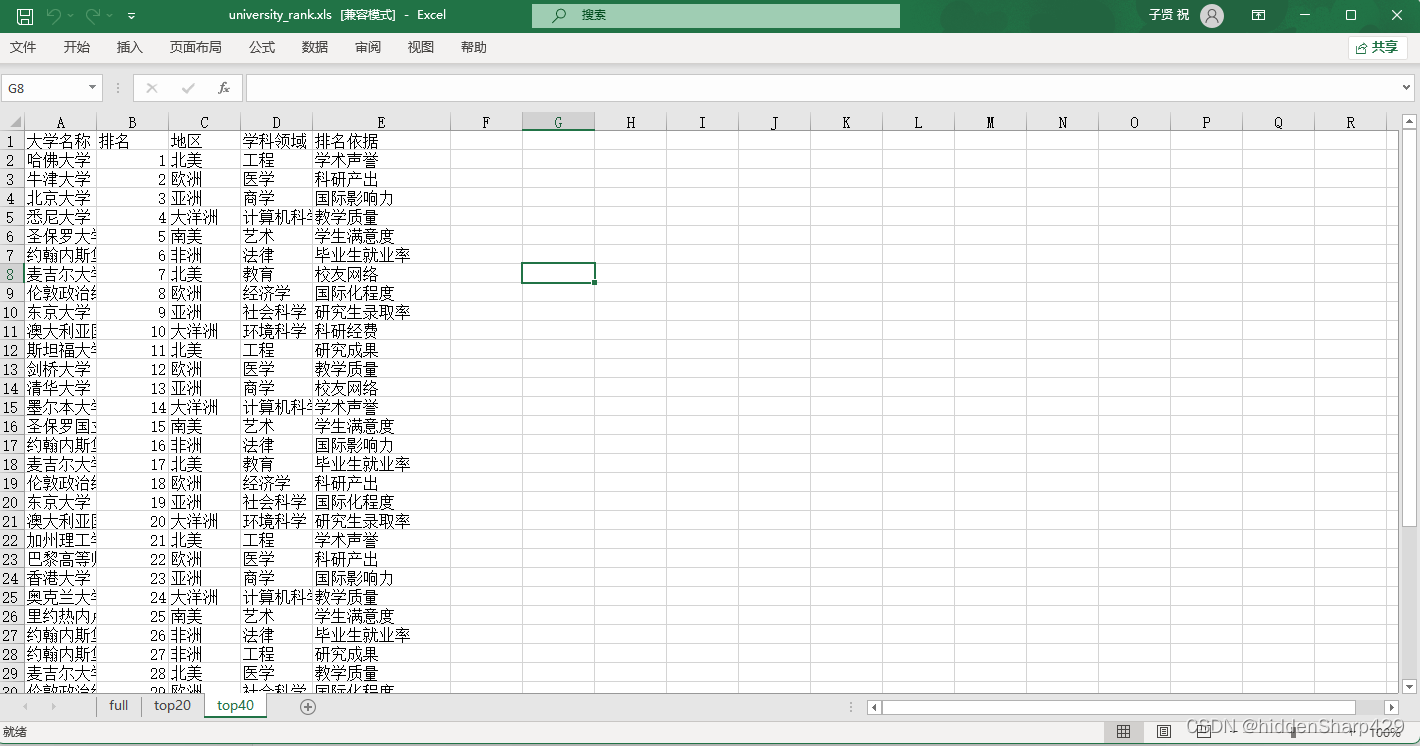
In[3]:
excel_with_string_sheet_name = pd.read_excel(
"university_rank.xls", sheet_name="full")
excel_with_string_sheet_name
out[3]:
| 大学名称 | 排名 | 地区 | 学科领域 | 排名依据 | |
|---|---|---|---|---|---|
| 0 | 哈佛大学 | 1 | 北美 | 工程 | 学术声誉 |
| 1 | 牛津大学 | 2 | 欧洲 | 医学 | 科研产出 |
| 2 | 北京大学 | 3 | 亚洲 | 商学 | 国际影响力 |
| 3 | 悉尼大学 | 4 | 大洋洲 | 计算机科学 | 教学质量 |
| 4 | 圣保罗大学 | 5 | 南美 | 艺术 | 学生满意度 |
| ... | ... | ... | ... | ... | ... |
| 95 | 圣保罗国立大学 | 96 | 南美 | 计算机科学 | 研究生录取率 |
| 96 | 约翰内斯堡大学 | 97 | 非洲 | 环境科学 | 学术声誉 |
| 97 | 麦吉尔大学 | 98 | 北美 | 艺术 | 学生满意度 |
| 98 | 伦敦政治经济学院 | 99 | 欧洲 | 法律 | 国际影响力 |
| 99 | 东京大学 | 100 | 亚洲 | 教育 | 毕业生就业率 |
100 rows × 5 columns
将sheet_name的参数类型从字符串类型换成整数类型呢?
In[4]:
excel_with_number_sheet_name = pd.read_excel(
"university_rank.xls", sheet_name=0)
excel_with_number_sheet_name
out[4]:
| 大学名称 | 排名 | 地区 | 学科领域 | 排名依据 | |
|---|---|---|---|---|---|
| 0 | 哈佛大学 | 1 | 北美 | 工程 | 学术声誉 |
| 1 | 牛津大学 | 2 | 欧洲 | 医学 | 科研产出 |
| 2 | 北京大学 | 3 | 亚洲 | 商学 | 国际影响力 |
| 3 | 悉尼大学 | 4 | 大洋洲 | 计算机科学 | 教学质量 |
| 4 | 圣保罗大学 | 5 | 南美 | 艺术 | 学生满意度 |
| ... | ... | ... | ... | ... | ... |
| 95 | 圣保罗国立大学 | 96 | 南美 | 计算机科学 | 研究生录取率 |
| 96 | 约翰内斯堡大学 | 97 | 非洲 | 环境科学 | 学术声誉 |
| 97 | 麦吉尔大学 | 98 | 北美 | 艺术 | 学生满意度 |
| 98 | 伦敦政治经济学院 | 99 | 欧洲 | 法律 | 国际影响力 |
| 99 | 东京大学 | 100 | 亚洲 | 教育 | 毕业生就业率 |
100 rows × 5 columns
可以看到并没有什么不同,具体使用的时候可以根据个人的习惯来进行选择。
同时可以通过指定sheet_name = None 来获取这个excel文件的所有子表,并且通过字典的形式展示出来
In[5]:
sheet_name_dict = pd.read_excel("university_rank.xls", sheet_name=None)
sheet_name_dict
out[5]:
{'full': 大学名称 排名 地区 学科领域 排名依据
0 哈佛大学 1 北美 工程 学术声誉
1 牛津大学 2 欧洲 医学 科研产出
2 北京大学 3 亚洲 商学 国际影响力
3 悉尼大学 4 大洋洲 计算机科学 教学质量
4 圣保罗大学 5 南美 艺术 学生满意度
.. ... ... ... ... ...
95 圣保罗国立大学 96 南美 计算机科学 研究生录取率
96 约翰内斯堡大学 97 非洲 环境科学 学术声誉
97 麦吉尔大学 98 北美 艺术 学生满意度
98 伦敦政治经济学院 99 欧洲 法律 国际影响力
99 东京大学 100 亚洲 教育 毕业生就业率
[100 rows x 5 columns],
'top20': 大学名称 排名 地区 学科领域 排名依据
0 哈佛大学 1 北美 工程 学术声誉
1 牛津大学 2 欧洲 医学 科研产出
2 北京大学 3 亚洲 商学 国际影响力
3 悉尼大学 4 大洋洲 计算机科学 教学质量
4 圣保罗大学 5 南美 艺术 学生满意度
5 约翰内斯堡大学 6 非洲 法律 毕业生就业率
6 麦吉尔大学 7 北美 教育 校友网络
7 伦敦政治经济学院 8 欧洲 经济学 国际化程度
8 东京大学 9 亚洲 社会科学 研究生录取率
9 澳大利亚国立大学 10 大洋洲 环境科学 科研经费
10 斯坦福大学 11 北美 工程 研究成果
11 剑桥大学 12 欧洲 医学 教学质量
12 清华大学 13 亚洲 商学 校友网络
13 墨尔本大学 14 大洋洲 计算机科学 学术声誉
14 圣保罗国立大学 15 南美 艺术 学生满意度
15 约翰内斯堡大学 16 非洲 法律 国际影响力
16 麦吉尔大学 17 北美 教育 毕业生就业率
17 伦敦政治经济学院 18 欧洲 经济学 科研产出
18 东京大学 19 亚洲 社会科学 国际化程度
19 澳大利亚国立大学 20 大洋洲 环境科学 研究生录取率,
'top40': 大学名称 排名 地区 学科领域 排名依据
0 哈佛大学 1 北美 工程 学术声誉
1 牛津大学 2 欧洲 医学 科研产出
2 北京大学 3 亚洲 商学 国际影响力
3 悉尼大学 4 大洋洲 计算机科学 教学质量
4 圣保罗大学 5 南美 艺术 学生满意度
5 约翰内斯堡大学 6 非洲 法律 毕业生就业率
6 麦吉尔大学 7 北美 教育 校友网络
7 伦敦政治经济学院 8 欧洲 经济学 国际化程度
8 东京大学 9 亚洲 社会科学 研究生录取率
9 澳大利亚国立大学 10 大洋洲 环境科学 科研经费
10 斯坦福大学 11 北美 工程 研究成果
11 剑桥大学 12 欧洲 医学 教学质量
12 清华大学 13 亚洲 商学 校友网络
13 墨尔本大学 14 大洋洲 计算机科学 学术声誉
14 圣保罗国立大学 15 南美 艺术 学生满意度
15 约翰内斯堡大学 16 非洲 法律 国际影响力
16 麦吉尔大学 17 北美 教育 毕业生就业率
17 伦敦政治经济学院 18 欧洲 经济学 科研产出
18 东京大学 19 亚洲 社会科学 国际化程度
19 澳大利亚国立大学 20 大洋洲 环境科学 研究生录取率
20 加州理工学院 21 北美 工程 学术声誉
21 巴黎高等师范学院 22 欧洲 医学 科研产出
22 香港大学 23 亚洲 商学 国际影响力
23 奥克兰大学 24 大洋洲 计算机科学 教学质量
24 里约热内卢大学 25 南美 艺术 学生满意度
25 约翰内斯堡大学 26 非洲 法律 毕业生就业率
26 约翰内斯堡大学 27 非洲 工程 研究成果
27 麦吉尔大学 28 北美 医学 教学质量
28 伦敦政治经济学院 29 欧洲 社会科学 国际化程度
29 东京大学 30 亚洲 艺术 学生满意度
30 澳大利亚国立大学 31 大洋洲 法律 毕业生就业率
31 斯坦福大学 32 北美 经济学 校友网络
32 剑桥大学 33 欧洲 工程 科研产出
33 清华大学 34 亚洲 医学 学术声誉
34 墨尔本大学 35 大洋洲 商学 教学质量
35 圣保罗国立大学 36 南美 计算机科学 研究生录取率
36 约翰内斯堡大学 37 非洲 环境科学 学术声誉
37 麦吉尔大学 38 北美 艺术 学生满意度
38 伦敦政治经济学院 39 欧洲 法律 国际影响力}
1.4 pd.read_sql
pd.read_sql是Pandas库中用于从SQL数据库中读取数据的函数。它可以将数据库查询的结果读取为Pandas的DataFrame数据结构,在下面的2.2 保存数据文件到数据库中,我们学习了将dataframe格式的数据通过pandas的pd.to_sql指令将数据存入了数据库,那么我们应该怎么读取数据库中的文件呢?
pd.read_sql(
# SQL查询语句。可以是完整的SQL查询语句,也可以是查询语句的名称
sql
# 连接方式,可以是SQLAlchemy的Engine对象,也可以是数据库连接字符串。支持多种数据库的连接,如SQLite、MySQL、PostgreSQL
con
# 将会被用作索引的列名
index_col
# 需要读入列的名称 为list类型
columns
# 可选参数,默认为None。表示要传递给SQL查询的参数,通常用于防止SQL注入攻击
params
# 可选参数,默认为True。表示是否将数值类型的列强制转换为浮点数类型
coerce_float
# 可选参数,默认为None。用于指定要解析为日期时间类型的列
parse_dates
)
案例数据库表python_learning
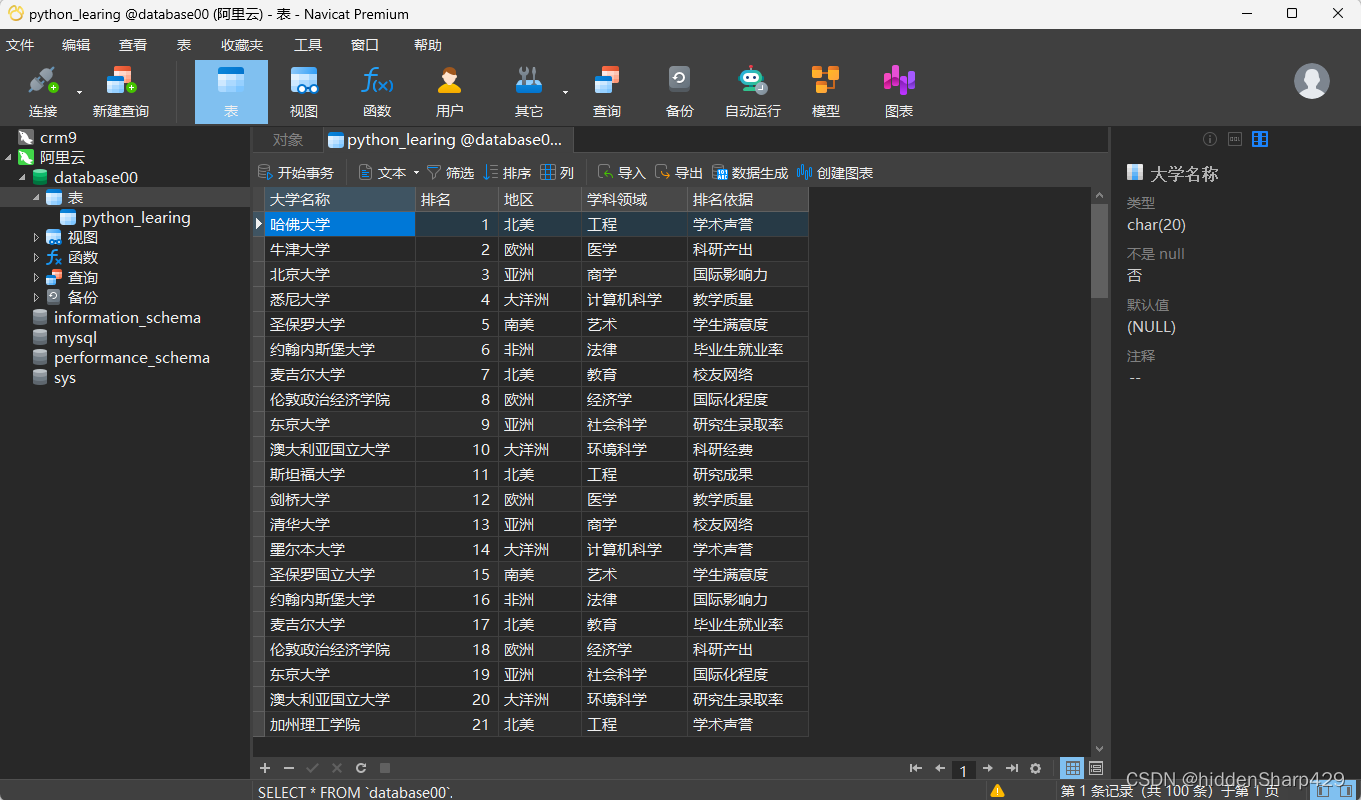
具体操作
- 首先,确保已经建立了与目标数据库的连接,并且获取到了数据库连接对象(con)。
- 构造SQL查询语句,可以是完整的查询语句,也可以是查询语句的名称。
- 使用
pd.read_sql函数执行查询,并将查询结果读取为DataFrame。
con=eng的具体来源在2.2中,在这就不过多赘述了,因此我们先默认完成了第一步。
In[6]:
sql = "select * from python_learing" # 第二步构造SQL查询语句
db = pd.read_sql(
sql=sql,
con=eng,
index_col="排名",
)# 使用`pd.read_sql`函数执行查询
db
out[6]:
| 大学名称 | 地区 | 学科领域 | 排名依据 | |
|---|---|---|---|---|
| 排名 | ||||
| 1 | 哈佛大学 | 北美 | 工程 | 学术声誉 |
| 2 | 牛津大学 | 欧洲 | 医学 | 科研产出 |
| 3 | 北京大学 | 亚洲 | 商学 | 国际影响力 |
| 4 | 悉尼大学 | 大洋洲 | 计算机科学 | 教学质量 |
| 5 | 圣保罗大学 | 南美 | 艺术 | 学生满意度 |
| ... | ... | ... | ... | ... |
| 96 | 圣保罗国立大学 | 南美 | 计算机科学 | 研究生录取率 |
| 97 | 约翰内斯堡大学 | 非洲 | 环境科学 | 学术声誉 |
| 98 | 麦吉尔大学 | 北美 | 艺术 | 学生满意度 |
| 99 | 伦敦政治经济学院 | 欧洲 | 法律 | 国际影响力 |
| 100 | 东京大学 | 亚洲 | 教育 | 毕业生就业率 |
100 rows × 4 columns
这样我们就完成了读取MySQL数据库中相关的表这样的操作了~
2. 保存数据文件
一般保存文件有两种保存的路径它们分为为:保存数据文件到外部文件、保存数据文件到数据库中
对于保存数据文件到外部文件:将数据保存到外部文件对于较小的数据集或与可能无权访问数据库的其他人共享数据非常有用。将数据导出到不同的工具和环境也更容易。
对于保存数据文件到数据库中:对于较大的数据集、需要频繁更新或修改的数据以及需要执行复杂数据查询或分析的情况,首选将数据保存到数据库。
2.1 保存数据文件到外部文件中
首先要读取数据并且保存会dataframe格式到内存中
一会我们要读入的文件路径为"Beijing_HourlyPM2.5/2009.csv", 在这里可能会有疑问?为什么这里文件的路径是长这样的呢?看完文件目录你应该就会明白了
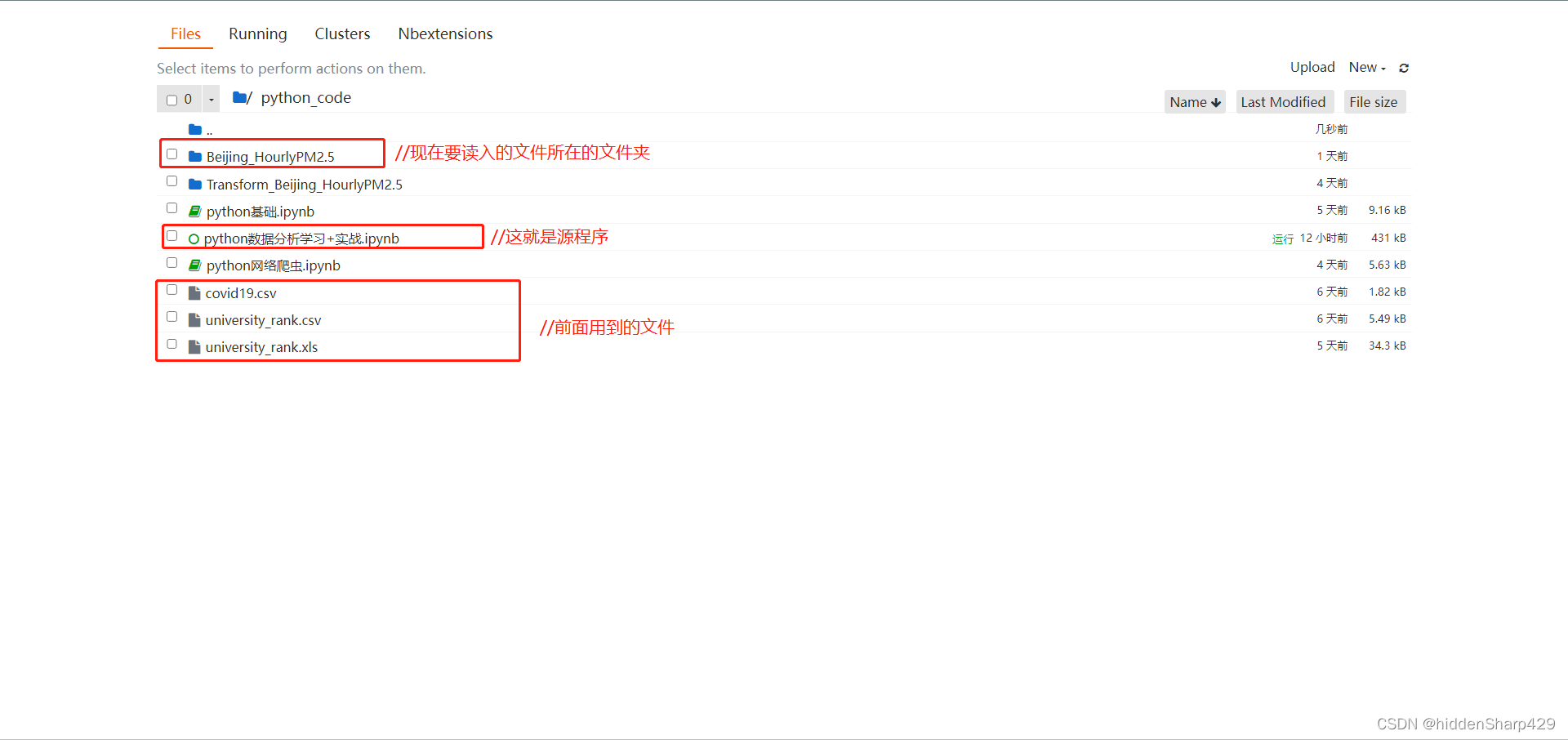
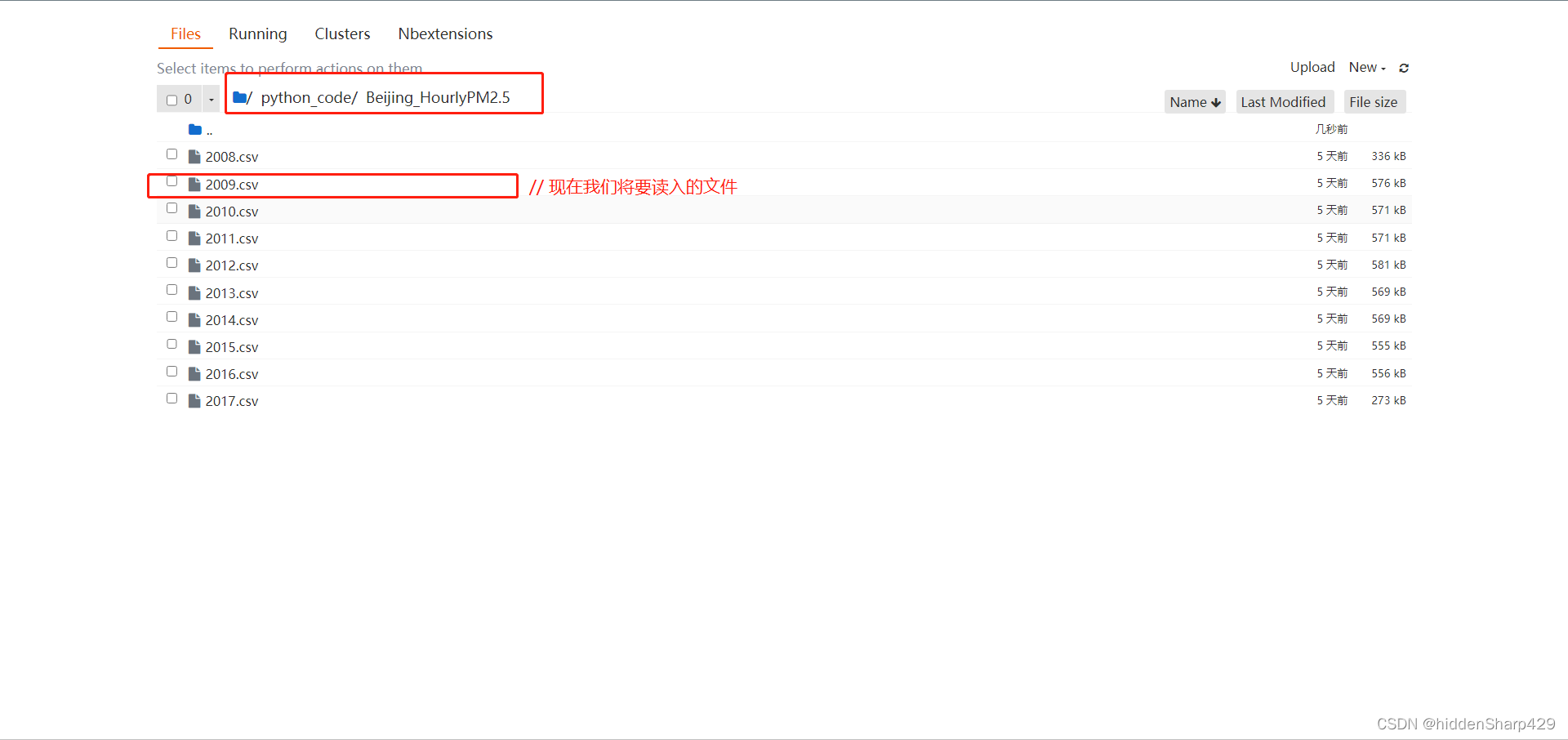
案例数据表2009.csv
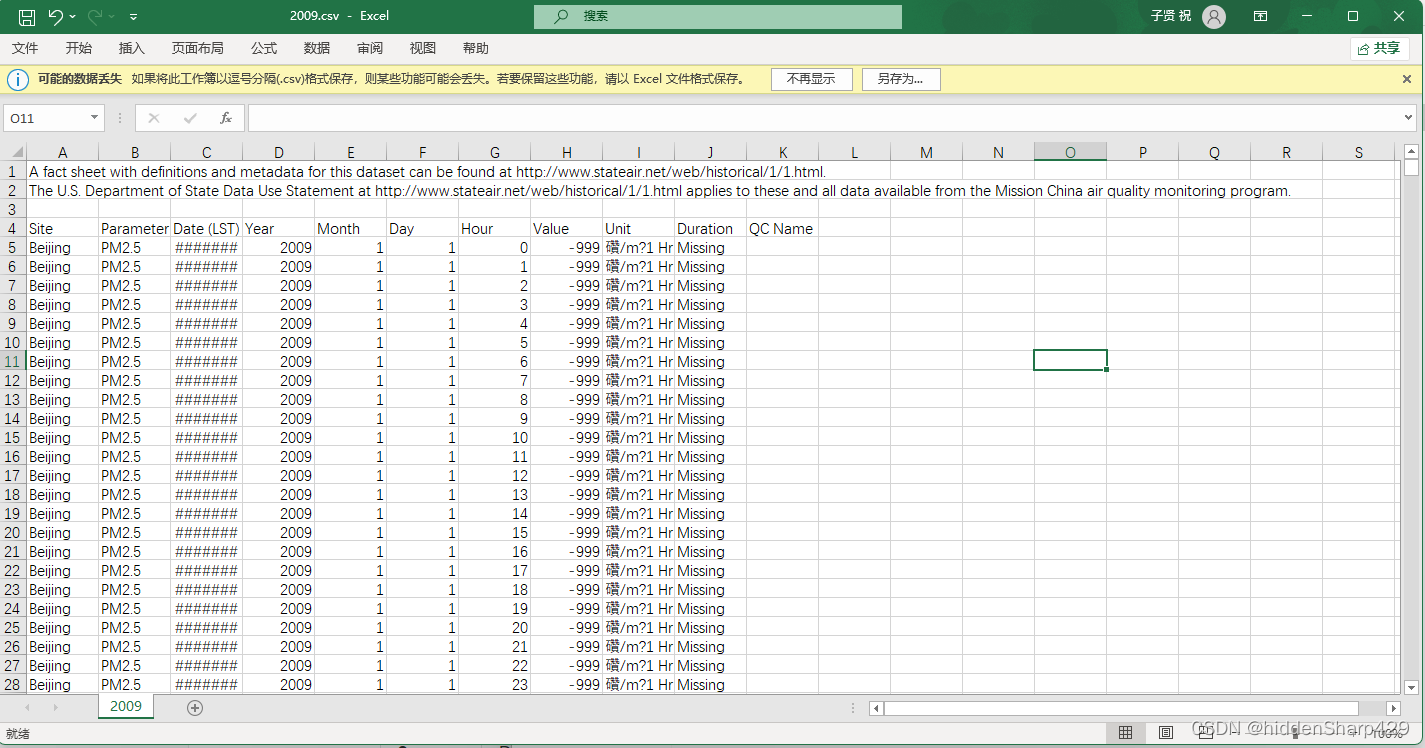
值得注意的是这个表的格式有些特殊,并且有些脏数据需要清理,现在我们就简单操作一下
In[7]:
df = pd.read_csv(
"Beijing_HourlyPM2.5/2009.csv",
skiprows=3, #从第四行开始读取
usecols=[0, 1, 2, 3, 4, 5, 6, 7]) #不读Unit行避开报错行
df
out[7]:
| Site | Parameter | Date (LST) | Year | Month | Day | Hour | Value | |
|---|---|---|---|---|---|---|---|---|
| 0 | Beijing | PM2.5 | 2009-01-01 00:00 | 2009 | 1 | 1 | 0 | -999 |
| 1 | Beijing | PM2.5 | 2009-01-01 01:00 | 2009 | 1 | 1 | 1 | -999 |
| 2 | Beijing | PM2.5 | 2009-01-01 02:00 | 2009 | 1 | 1 | 2 | -999 |
| 3 | Beijing | PM2.5 | 2009-01-01 03:00 | 2009 | 1 | 1 | 3 | -999 |
| 4 | Beijing | PM2.5 | 2009-01-01 04:00 | 2009 | 1 | 1 | 4 | -999 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 8755 | Beijing | PM2.5 | 2009-12-31 19:00 | 2009 | 12 | 31 | 19 | 77 |
| 8756 | Beijing | PM2.5 | 2009-12-31 20:00 | 2009 | 12 | 31 | 20 | 120 |
| 8757 | Beijing | PM2.5 | 2009-12-31 21:00 | 2009 | 12 | 31 | 21 | 163 |
| 8758 | Beijing | PM2.5 | 2009-12-31 22:00 | 2009 | 12 | 31 | 22 | 167 |
| 8759 | Beijing | PM2.5 | 2009-12-31 23:00 | 2009 | 12 | 31 | 23 | -999 |
8760 rows × 8 columns
现在我们就成功的把表读取并存入到df里面了,然后我们需要使用df.to_csv函数来将这个dataframe类型数据保存为外部文件
df.to_csv(
# 文件路径(字符串)或文件对象(类似文件句柄)。指定保存CSV文件的位置和文件名
path_or_buf
# 列分隔符,用于分隔不同的字段。默认是逗号
sep = ','
# 写入的变量列表
columns
# 是否写入列名。默认为True
header = True
# 是否写入行索引。默认为True
index = True
# 写入模式,默认是'w'(覆盖写入)。可以设置为'a'表示追加写入
mode = 'w'
# 指定保存CSV文件时使用的编码格式
encoding = 'utf-8'
# 如果DataFrame中有日期时间类型的列,并且要写入CSV文件,可以指定日期时间的格式
date_format
)
In[8]:
df.to_csv(
'Transform_Beijing_HourlyPM2.5/2009.csv',
header=["地点", "参数", "时间", "年份", "月份", "日期", "小时", "值"],
index=False
) #保存数据文件到外部文件中
df = pd.read_csv("Transform_Beijing_HourlyPM2.5/2009.csv") #读取一下刚才保存的外部文件
df
out[8]:
| 地点 | 参数 | 时间 | 年份 | 月份 | 日期 | 小时 | 值 | |
|---|---|---|---|---|---|---|---|---|
| 0 | Beijing | PM2.5 | 2009-01-01 00:00 | 2009 | 1 | 1 | 0 | -999 |
| 1 | Beijing | PM2.5 | 2009-01-01 01:00 | 2009 | 1 | 1 | 1 | -999 |
| 2 | Beijing | PM2.5 | 2009-01-01 02:00 | 2009 | 1 | 1 | 2 | -999 |
| 3 | Beijing | PM2.5 | 2009-01-01 03:00 | 2009 | 1 | 1 | 3 | -999 |
| 4 | Beijing | PM2.5 | 2009-01-01 04:00 | 2009 | 1 | 1 | 4 | -999 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 8755 | Beijing | PM2.5 | 2009-12-31 19:00 | 2009 | 12 | 31 | 19 | 77 |
| 8756 | Beijing | PM2.5 | 2009-12-31 20:00 | 2009 | 12 | 31 | 20 | 120 |
| 8757 | Beijing | PM2.5 | 2009-12-31 21:00 | 2009 | 12 | 31 | 21 | 163 |
| 8758 | Beijing | PM2.5 | 2009-12-31 22:00 | 2009 | 12 | 31 | 22 | 167 |
| 8759 | Beijing | PM2.5 | 2009-12-31 23:00 | 2009 | 12 | 31 | 23 | -999 |
8760 rows × 8 columns
同样也可以保存为excel文件,使用的函数是df.to_excel该函数的参数与df.to_csv基本类似,在此就不过多赘述
In[9]:
df.to_excel(
"Transform_Beijing_HourlyPM2.5/2009.xls",
header=["地点", "参数", "时间", "年份", "月份", "日期", "小时", "值"],
index=False
)
df = pd.read_excel("Transform_Beijing_HourlyPM2.5/2009.xls")
df
out[9]:
| 地点 | 参数 | 时间 | 年份 | 月份 | 日期 | 小时 | 值 | |
|---|---|---|---|---|---|---|---|---|
| 0 | Beijing | PM2.5 | 2009-01-01 00:00 | 2009 | 1 | 1 | 0 | -999 |
| 1 | Beijing | PM2.5 | 2009-01-01 01:00 | 2009 | 1 | 1 | 1 | -999 |
| 2 | Beijing | PM2.5 | 2009-01-01 02:00 | 2009 | 1 | 1 | 2 | -999 |
| 3 | Beijing | PM2.5 | 2009-01-01 03:00 | 2009 | 1 | 1 | 3 | -999 |
| 4 | Beijing | PM2.5 | 2009-01-01 04:00 | 2009 | 1 | 1 | 4 | -999 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 8755 | Beijing | PM2.5 | 2009-12-31 19:00 | 2009 | 12 | 31 | 19 | 77 |
| 8756 | Beijing | PM2.5 | 2009-12-31 20:00 | 2009 | 12 | 31 | 20 | 120 |
| 8757 | Beijing | PM2.5 | 2009-12-31 21:00 | 2009 | 12 | 31 | 21 | 163 |
| 8758 | Beijing | PM2.5 | 2009-12-31 22:00 | 2009 | 12 | 31 | 22 | 167 |
| 8759 | Beijing | PM2.5 | 2009-12-31 23:00 | 2009 | 12 | 31 | 23 | -999 |
8760 rows × 8 columns
2.2 保存数据文件到数据库中
如果你想将数据保存到数据库中,可以使用Pandas的df.to_sql方法来实现。to_sql方法允许你将DataFrame数据写入数据库表中。
df.to_sql(
# 要保存数据的表名
name
# 数据库连接引擎,可以是SQLAlchemy engine对象或SQLite3数据库文件的路径(字符串)
con
# 表已经存在的处理方式
if_exists = "fail\repleace\append"
#'fail'(默认):如果表已存在,则抛出ValueError。
#'replace':如果表已存在,则删除原有表并创建新表。
#'append':如果表已存在,则将数据追加到现有表。
# 是否写入行索引,默认为True
index = True
# 数据库模式(可选),默认为None
schema = None
# 行索引对应的列名,默认为None。
index_label = None
# 指定每次写入的数据块大小。如果数据量较大,可以分块写入数据库,避免一次写入过多数据。
chunksize
# 写入数据的方法,默认为None。可选的值有'multi'、'insert'或None
method = None
)
在此需要注意的是如果想要保存该dataframe到数据库上,需要有对应的表以及列
我的数据库是在云服务器上的,在此简单介绍一下该如何操作~
首先:登录阿里云服务器,启动mysql(若服务器上MySQL未服务)
[root@iZ2zedoqi2b86yyomdcp5qZ ~]# mysql -u root -p其次:输入密码后登录,选择或者创建一个数据库
use database00;然后:创建一个相关的表
mysql> create table python_learing( -> 大学名称 CHAR(20), -> 排名 SMALLINT, -> 地区 CHAR(20), -> 学科领域 CHAR(20), -> 排名依据 CHAR(20) -> );
这样就完成了相关表的初始了,现在我们开始来连接数据库
首先:安装相关的依赖
由于服务器是centos7.x系统并且jupyter并不是按照anaconda自带的,所以需要安装的依赖可能要多一个
pip install sqlalchemy
pip insatll PyMySQL
In[10]:
from sqlalchemy import create_engine #导入create_engine
connect_str = "mysql+pymysql://<数据库用户名>:<数据库密码>@<主机ip地址>/<连接的数据库\模式名>?charset=utf8" #创建相关的连接字符串 例如 root:1670493002b01c@127.0.0.1:3306/database00
eng = create_engine(connect_str)
type(eng) # 验证一下连接引擎
out[10]:
sqlalchemy.engine.base.Engine
看上去没有问题,我们继续
In[11]:
df = pd.read_csv("university_rank.csv") # 读取需要保存到数据库的数据文件
df
out[11]:
| 大学名称 | 排名 | 地区 | 学科领域 | 排名依据 | |
|---|---|---|---|---|---|
| 0 | 哈佛大学 | 1 | 北美 | 工程 | 学术声誉 |
| 1 | 牛津大学 | 2 | 欧洲 | 医学 | 科研产出 |
| 2 | 北京大学 | 3 | 亚洲 | 商学 | 国际影响力 |
| 3 | 悉尼大学 | 4 | 大洋洲 | 计算机科学 | 教学质量 |
| 4 | 圣保罗大学 | 5 | 南美 | 艺术 | 学生满意度 |
| ... | ... | ... | ... | ... | ... |
| 95 | 圣保罗国立大学 | 96 | 南美 | 计算机科学 | 研究生录取率 |
| 96 | 约翰内斯堡大学 | 97 | 非洲 | 环境科学 | 学术声誉 |
| 97 | 麦吉尔大学 | 98 | 北美 | 艺术 | 学生满意度 |
| 98 | 伦敦政治经济学院 | 99 | 欧洲 | 法律 | 国际影响力 |
| 99 | 东京大学 | 100 | 亚洲 | 教育 | 毕业生就业率 |
100 rows × 5 columns
In[12]:
df.to_sql(
name="python_learing",
con=eng,
if_exists='append',
index=False
) # 将数据文件保存到数据库中
搞定!
结束语
如果有疑问欢迎大家留言讨论,你如果觉得这篇文章对你有帮助可以给我一个免费的赞吗?我们之间的交流是我最大的动力!











![解决Vue2中控制台报错 [WDS] Disconnected! 问题](https://img-blog.csdnimg.cn/1b8b9f309d7540639aa1dc1641e0ff09.png)