概述
这篇论文的研究背景是关于利用大型语言模型(LLM)生成高效训练数据的方法。
以往的方法通常是通过LLM生成新的数据,但缺乏对生成数据的控制,这导致了生成数据的信息不足以反映任务要求。本文提出了一种基于LLM的属性操作生成方法,通过精心构造的数据生成与任务属性相关的数据,与以往的方法相比可以更好地控制生成数据的质量。
本文提出的方法是通过使用链式思维将LLM操作分解和重构,从而控制生成数据的属性操作。这种方法可以在仅有少量样本的情况下,通过对LLM的操作生成高质量的训练数据,并用于提升少样本学习的性能。
本文在文本分类和其他任务上进行了广泛的实验,并与其他基于LLM的文本生成方法进行了比较。实验结果表明,与使用相同数量训练样本的其他方法相比,基于LLM的属性操作生成方法在性能上具有优势。分析结果还验证了该方法的属性操作有效性,并展示了在更少监督下使用LLM引导学习的潜力。
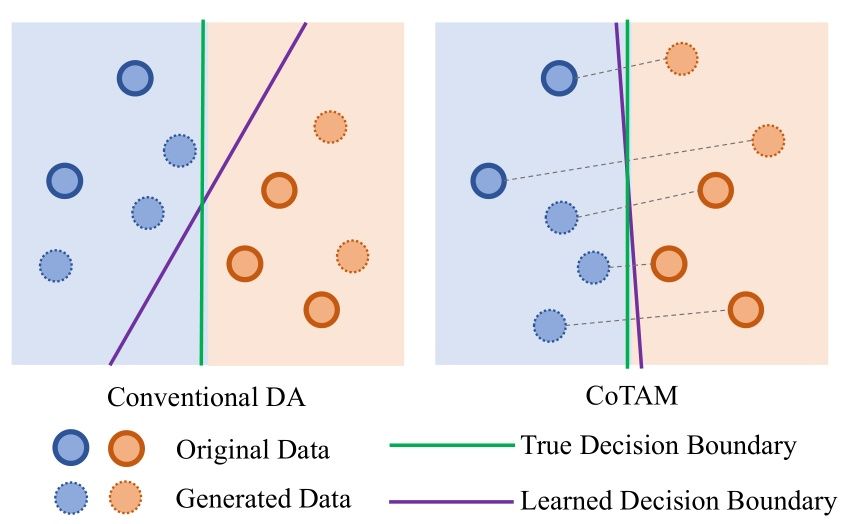

重要问题探讨
1. 为什么作者选择使用LLM来处理文本属性操纵而不是其他方法? 答:在相关工作部分,文章指出属性操作的一种方法是使用data flipping, 即替换文本中的关键词以改变其标签。然而,这种方法无法操作一些文本属性,比如话题。因此,作者选择采用了LLM来处理这些文本属性,通过将输入文本在LLM中分解为多个标签,然后再将其重构以改变属性。
2. 文章提到的CoTAM与现有的可控文本生成方法有何不同之处? 答:常规的可控文本生成方法通常通过控制某些维度来离散地从一个连续的潜在空间生成文本。然而,在当前的可控生成方法中,对于保持其他维度不变的显式控制是存在限制的。而CoTAM方法通过完全将输入文本分解为多个标签,并使用LLM来重构以改变标签属性,从而解决了这个问题。
3. 为什么文章将属性操纵与自然语言处理中的数据反转联系在一起? 答:属性操纵与数据反转联系在一起是因为它们都旨在对数据的特定属性进行控制。数据反转是一种改变文本中关键位置从而切换其标签的方法,而属性操纵则更广泛地用于控制数据的其他属性。由于一些文本属性无法通过数据反转进行操作,所以文章选择了适应LLM来操纵一个由LLM提出的一系列属性近似的潜在空间。
4. LLM的训练目标是什么?为什么目标是最大化下一个标记的概率预测而不是其他的? 答:LLM的训练目标是最大化在人类文本上预测下一个标记的概率预测,即最大化∑p(wn|, w1:n−1)。这是因为通过在大规模语料库上训练LLM,当前的LLM能够按照人类指令达到出色的零样本性能或处理自然语言。因此,训练目标的选择是为了使LLM能够更好地理解和生成人类语言。
5. CoTAM方法的创新之处在于什么地方? 答:CoTAM方法的创新之处在于首先将输入文本完全分解为多个标签,并使用LLM重构文本以改变属性。这种方法实现了对文本属性的精细操纵,并解决了常规可控文本生成方法中对其他维度控制不够明确的问题。通过这种创新方法,CoTAM方法能够更有效地生成满足特定要求的文本。
论文:2307.07099