1.HPA
1.1HPA介绍
1.在Kubernetes中,HPA自动更新工作负载资源(例如:Deployment或者StatefulSet),目的是自动扩缩工作负载以满足需求,水平扩缩意味着对增加的负载的响应是部署更多的 Pod,与垂直扩缩不同,对于Kubernetes,垂直扩缩意味着将更多资源(例如:内存或CPU)分配给已经为工作负载运行的Pod;如果负载减少,并且Pod的数量高于配置的最小值,HPA会指示工作负载资源(Deployment、StatefulSet 或其他类似资源)缩减,HPA不适用于无法扩缩的对象(例如:DaemonSet)
2.HPA会通过调整副本数量使得CPU使用率尽量向期望值靠近,而且不是完全相等.另外,官方考虑到自动扩展的决策可能需要一段时间才会生效;例如当pod所需要的CPU负荷过大,从而在创建一个新pod的过程中,系统的CPU使用量可能会同样在有一个攀升的过程;所以,在每一次作出决策后的一段时间内,将不再进行扩展决策;对于扩容而言,这个时间段为3分钟,缩容为5分钟
官网地址:
https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale/1.2工作原理
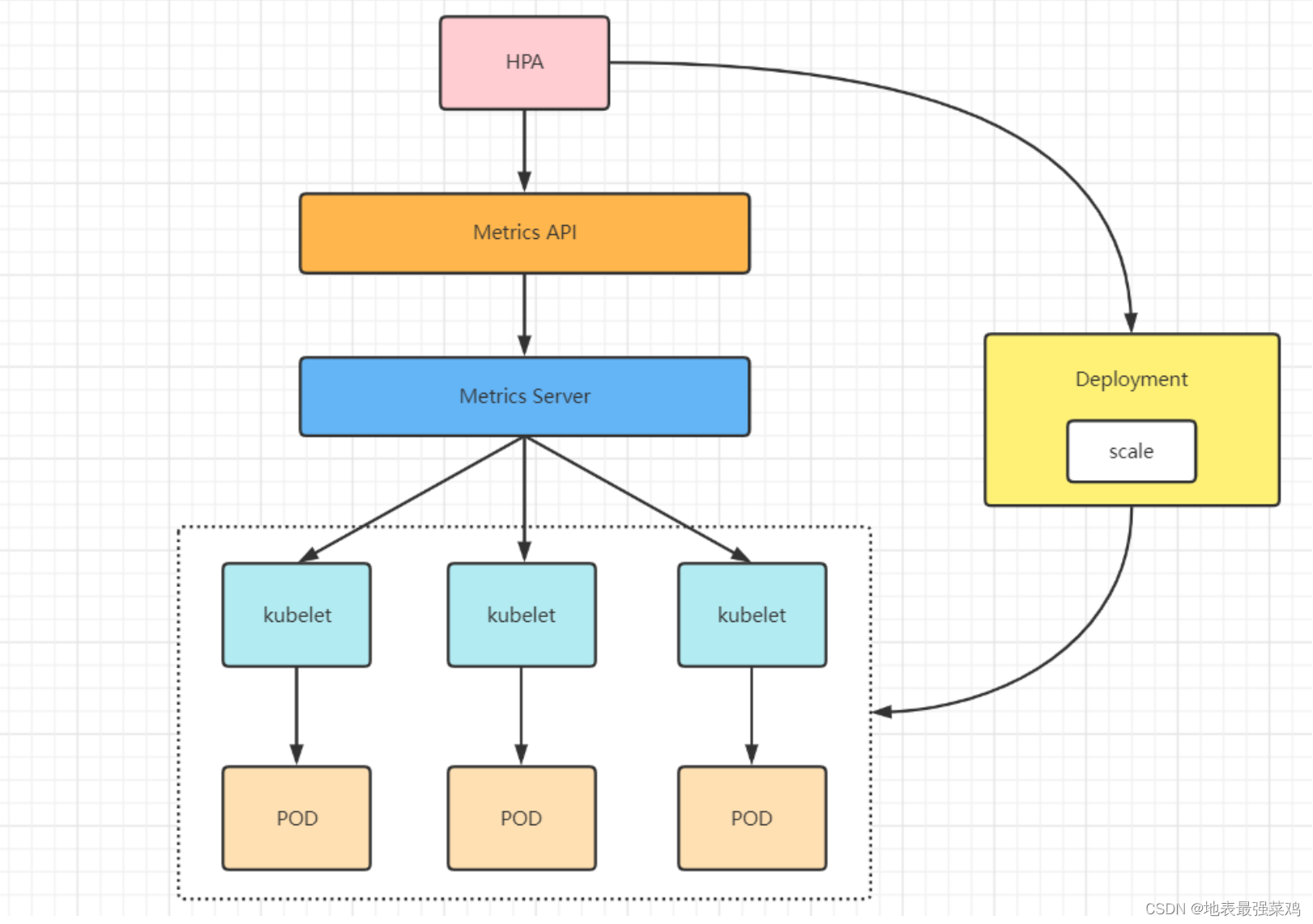
kubernetes中的Metrics Server会持续采集Pod的指标数据,HPA控制器通过Metrics Server的API获取这些数据,基于用户定义的扩缩容规则进行计算,得到目标Pod副本数量;当目标Pod副本数量与当前副本数量不同时,HPA控制器就向Pod的副本控制器(Deployment、StatefulSet或ReplicaSet)发起scale操作,然后副本控制器会调整Pod的副本数量,完成扩缩容操作
2.Metrics Server
2.1Metrics Server介绍
Metrics Server是Kubernetes容器资源指标的可扩展、高效来源、内置自动缩放管道,是由用户开发的一个api server,集群范围的资源使用情况的指标监控器,在HAP早期版本使⽤的是⼀个叫Heapster组件来提供CPU和内存指标的,在后期的版本Kubernetes转向了使⽤Metrcis Server组件来提供Pod的CPU和内存指标,Metrcis Server通过Metrics API将数据暴露出来,然后我们就可以使⽤Kubernetes的API来获取相应的数据;
文档地址:
https://github.com/kubernetes-sigs/metrics-server2.1Metrics Server安装
下载项⽬yaml⽂件
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/high-availability.yaml修改配置文件
spec:
hostNetwork: true #使⽤host⽹络模式
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls #跳过证书检查
image: bitnami/metrics-server:0.6.0 #修改为本地的镜像创建资源
kubectl apply -f high-availability.yaml查看结果


3.创建dp资源压测
3.1autoscaling/v1
CPU指标实践
1)创建deployment资源
$ vim nginx-dp.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-hpa
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: docker.io/nginx
ports:
- containerPort: 80
resources:
limits:
cpu: 200m
requests:
cpu: 200m2)创建hpa资源
$ vim nginx-hpa.yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
spec:
maxReplicas: 5
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-hpa
targetCPUUtilizationPercentage: 10清单解释:
apiVersion: autoscaling/v1 #版本为autoscaling/v1
kind: HorizontalPodAutoscaler #类型为HPA
metadata:
name: nginx-hpa #HPA的名称
labels:
app: nginx #选择app=nginx的pod
spec:
maxReplicas: 5 #伸缩最大副本数
minReplicas: 1 #伸缩最小副本数
scaleTargetRef: #要伸缩的目标资源,这里为 deployment
apiVersion: apps/v1 #伸缩类型的版本,这里为 deployment,版本为apps/v1
kind: Deployment #扩缩容的对象是deployment
name: nginx-hpa #deployment的名称
targetCPUUtilizationPercentage: 10 # 定义检测的CPU使用率指标的阈值,这里为10,当小于10%的时候就会缩容,大于的时候就会扩容查看

3)增大负载压测
创建一个 busybox 的Pod,并且循环访问上面创建的Pod
kubectl run -it --image busybox test-hpa --restart=Never --rm /bin/sh
/ # while true; do wget -q -O- http://10.224.102.190; done新开一个窗口查看


如果CPU使⽤率降下来了,默认5分钟后进⾏收缩
#坑:
创建的pod一定要加资源限制,否则hpa会报错unknown
3.2autoscaling/v2beta2
基于resource类型cpu和内存的限制实践
1)创建deployment资源
$ vim nginx-dpv2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-hpa
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: docker.io/nginx
ports:
- containerPort: 80
resources:
requests:
memory: 32Mi
cpu: 50m
limits:
memory: 256Mi
cpu: 100m2)创建hpa资源
$ vim nginx-hpav2.yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpav2
labels:
app: nginx
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-hpa
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
- type: Resource
resource:
name: memory
target:
type: AverageValue
averageValue: 300Mi清单解释:
apiVersion: autoscaling/v2beta2 #版本为autoscaling/v2beta2
kind: HorizontalPodAutoscaler #类型为HPA
metadata:
name: nginx-hpav2 #HPA的名称
labels:
app: nginx #选择app=nginx的pod
spec:
scaleTargetRef: #要伸缩的目标资源,这里为deployment
apiVersion: apps/v1 #伸缩类型的版本,这里为deployment,版本为apps/v1
kind: Deployment #扩缩容的对象是deployment
name: nginx-hpa #deployment的名称
minReplicas: 1 #最小副本数
maxReplicas: 10 #最大副本数
metrics: #动态伸缩的控制指标
- type: Resource
resource: #当前伸缩对象下的pod的指标,只支持Utilization和AverageValue类型的阈值
name: cpu #限制cpu
target:
type: Utilization
averageUtilization: 80 #当整体的资源利用率超过百分之80的时候,会进行扩容
- type: Resource
resource:
name: memory #限制内存
target:
type: AverageValue
averageValue: 300Mi #当指标的平均值或资源的平均利用率超过300的时候,会进行扩容运行
kubectl apply -f nginx-dpv2.yaml
kubectl apply -f nginx-hpav2.yaml3)增大负载压测
#创建一个 busybox 的Pod,并且循环访问上面创建的Pod
kubectl run -it --image busybox test-hpa --restart=Never --rm /bin/sh
/ # while true; do wget -q -O- http://10.224.102.133; done查看pod可以看到扩容了2个pod
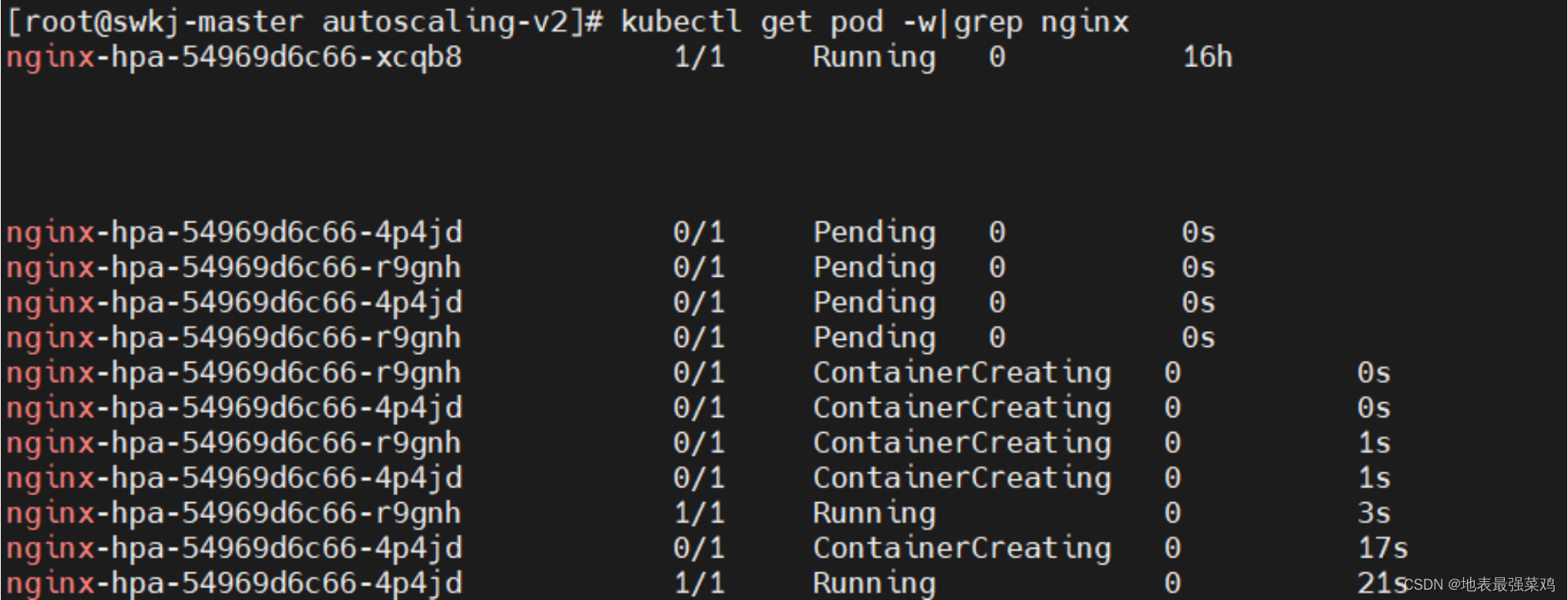
查看hpa

4.hpa资源配置清单不同类型模板
apiVersion: autoscaling/v2beta2 #版本为autoscaling/v2beta2
kind: HorizontalPodAutoscaler #类型为HPA
metadata:
name: xxxx #HPA的名称
namespace: xxxx #命名空间
behavior: #用来精确控制hpa的扩容和缩容的速度
scaleDown: #缩容速度策略
policies:
- type: Pods #允许在一分钟内最多缩容4个副本
value: 4
periodSeconds: 60
- type: Percent #允许在一分钟内最多缩容当前副本个数的百分之十
value: 10
periodSeconds: 60
stabilizationWindowSeconds: 300 #5分钟后进⾏收缩
scaleUp: #扩容速度策略
policies:
- type: Percent #每15秒扩容100%当前运行的副本数
value: 100
periodSeconds: 15
- type: Pods #每15秒添加4个Pod
value: 4
periodSeconds: 15
selectPolicy: Max #取两个策略中的最大改变值
stabilizationWindowSeconds: 0
maxReplicas: xx #最大副本数
minReplicas: xx #最小副本数
scaleTargetRef: #要伸缩的目标资源,这里为deployment
apiVersion: apps/v1 #伸缩类型的版本,这里为deployment,版本为apps/v1
kind: Deployment #扩缩容的对象是deployment
name: xxxx #deployment的名称
metrics: #动态伸缩的控制指标
- type: Resource #Resource类型的指标
resource: #当前伸缩对象下的pod的指标
name: cpu #限制cpu
target:
type: Utilization #Resource类型的指标只支持Utilization和AverageValue类型的目标值
averageUtilization: xx #当整体的资源利用率超过百分之xx的时候,会进行扩容
- type: ContainerResource #ContainerResource类型的指标
containerResource: #伸缩对象下的容器的cpu和memory指标
container: xxxx #容器名
name: cpu #限制cpu
target:
type: Utilization
averageUtilization: 60 #对容器执行扩缩操作确保所有Pod中容器的平均CPU用量为60%
- type: Pods #Pods类型的指标
pods: #伸缩对象Pods的指标,数据需要第三方的adapter提供
metric:
name: xxxx #Pod的指标名
selector: #具有此标签的指标名
- matchExpressions:
- key: xxxx
operator: In
values:
- xxxx
- xxxx #可以定义多个标签
target:
type: AverageValue #Pods指标类型下只支持AverageValue类型的目标值
averageValue: 1k #在目标指标平均值为1000时触发扩缩容操作
- type: External #External类型的指标
external: #k8s外部的指标
metric:
name: xxxx #外部指标名
selector:
matchLabels: #外部指标标签
env: "xxxx"
app: "xxxx" #可以定义多个标签
target:
type: AverageValue #External指标类型下只支持Value和AverageValue类型的目标值
averageValue: 30 #在目标指标平均值为30时触发扩缩容操作
- type: Object
object: #用于描述k8s内置对象的指标
describedObject:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress #扩缩容的对象是deploymentIngress
name: main-route
metric:
name: ingress_test #指标名
target:
type: Value #Object类型的指标只支持Value和AverageValue类型的目标值
value: 2k #在Ingress的每秒请求数量达到2000个时触发扩缩容
- type: Object
object:
metric:
name: 'http_requests' #指标名
selector: 'verb=GET' #具有verb=GET标签的资源对象
target:
type: AverageValue
AverageValue: 500 #在指标平均值达到500时触发扩缩容操作到此 Kubernetes HPA 动态弹性扩缩容介绍完成。