Python库的选择
话说,工欲善其事,必先利其器,虽然我们已经选择Python来完成剩余的工作,但是我们需要考虑具体选择使用Pytho的哪些利器来帮助我们更快更好地完成剩余的工作。
我们可以看一下,在这个任务中,主要涉及到四类工作要完成:
-
csv文件的读取;
-
对读取的数据,按照我们要分析的指标进行数据处理和指标计算;
-
根据数据分析的结果,生成可视化的数据图表;
-
通过web页面展示数据分析结果报告;
我们下面就根据这四类工作,来看看我们分别选择Python的哪些库来帮助我们完成工作。
1.数据处理和分析库
对类似csv、excel等格式文件的读取和处理,其实就是对一维和二维数据的处理,对此类数据的处理,Python中常用的库是Pandas,其提供的数据结构中的Series对应一维数据,DataFrame对应二维数据,同时Pandas也提供了大量的高效内置函数和操作来实现对内存中一维和二维数据的处理。
而对于更高维度数据比如矩阵的计算,Python中则需要用Nunpy库来完成。numpy是以矩阵为基础的数学计算模块,提供高性能的矩阵运算,数组结构为ndarray,可以把它看作是多维数组(ndarray)的容器,可以对数组执行元素级计算以及直接对数组执行数学运算的函数。
Pandas是基于Numpy数组构建的,但二者最大的不同是pandas是专门为处理表格和混杂数据设计的,比较契合统计分析中的表结构,而numpy更适合处理统一的数值数组数据。
所以,第1步和第2步的工作,我们基本依靠Pandas库就能完成,不过,这次的数据分析报告中,我也用到了Numpy库的直方图计算的功能,后面会详细讲到。
2.数据可视化库
而第3步的工作,其实是一个数据可视化的任务,在Python中可以用于进行数据可视化的库,常用的主要有三个:
-
Matplotlib
-
Seanborn
-
Pyecharts
Matplotlib
Matplotlib可以说是Python数据可视化库的鼻祖了,他是Python编程语言及其数值计算包NumPy的可视化操作界面,其中pyplot是matplotlib的一个模块,提供了类似MATLAB的接口。其可以和Numpy、Pandas无缝结合,但一些图标的样式不够美观,而且原生不支持生成动态可交互的图表,虽然可以通过改变使用的后端来实现,但相对还是比较麻烦一些,而且如果想要在一个web页面中实现一个动态可交互的图表,目前没有什么特别好的办法,最近matplotlib在更面向web交互方面有了很多进展,比如新的HTML5/Canvas后端,可以从如下地址了解一下:
http://code.google.com/p/mplh5canvas/
但还没有完全完成。
Seanborn
Seaborn跟matplotlib最大的区别就是它的默认绘图风格和色彩搭配都具有现代美感,其实他是在matplotlib的基础上进行了更高级的API封装,让你能用更少的代码去调用matplotlib的方法,从而使得作图更加容易。但matplotlib存在的动态交互性的问题他同样存在。
Pyecharts
说到Pyecharts则不得不提到ECharts,这个可是在前端数据可视化领域非常知名的库了,毕竟他出自我的老东家百度的前端工程师之手,最开始在百度内部孵化,我在百度工作期间,还和后来参与到ECharts开发的核心工程师有过其他项目合作。后来2018年捐赠给Apache基金会,成为ASF孵化级项目,并于2021年正式毕业,成为Apache顶级项目。
而Pyecharts则是基于ECharts实现的python版本,支持大量丰富的可视化图表类型,而且相比前两个库最大的优势在于,能够非常方便地生成支持交互性(如鼠标点选、拖拽、缩放等)的图片,且可动态地展示在web页面上。
基于以上的对比分析,鉴于这次我希望给我朋友生成一个动态可交互的web数据分析报告页面,在这一点上,Pyecharts无疑更有优势,于是这次我们就用Pyecharts库来进行我们的数据可视化展现。
3.Web应用库
在这个领域Python的选择主要有两个:
-
Django
-
Flask
Django是用 Python 开发的一个免费开源的 Web 框架,提供了许多网站后台开发经常用到的模块,本身自带了相当多的功能,这些功能是由官方和社区共同维护的,因而是个大而全的较重的框架,所以耦合度相比flask会高一些,做二次修改难度更高。
相比之下,Flask是一个免费的开放源代码的轻量型的Web框架,Flask不包含例如上载处理,ORM(对象关系映射器),数据库抽象层,身份验证,表单验证等web应用常用功能模块(这些Django提供了),但是可以使用预先存在的外部库来集成这些功能,因此是一个更灵活、扩展性更好的Web框架。
而我们这次的场景,仅仅只需要提供一个静态的web页面用于展示数据可视化结果,并不涉及其他复杂的web应用功能,因此,Flask是我们的不二之选。
开始我们的数据可视化分析之旅
好了,选择好了我们的工具之后,我们就要正式开始我们的数据可视化分析之旅了。我们先来看一下我们要分析的这一份数据,如图:
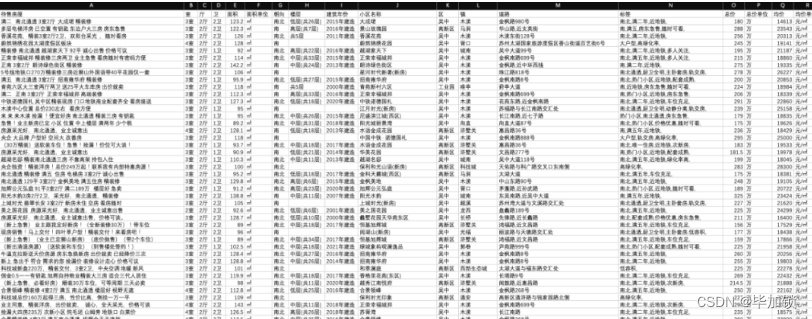
我们爬取到的房产数据,主要是苏州二手房的房源信息,主要包括了待售房源的户型、面积、朝向、楼层、建筑年份、小区名称、小区所在的城区-镇-街道、房子被打的标签、总价、单价等信息。
数据读取到内存的过程使用Pandas来完成很简单,这里就不赘述了。接下来重点讲一下数据分析和可视化图表的生成。根据要分析的数据指标,这次我们主要用到了Pyecharts的5类图表组件,分别是Bar(柱状图)、Pie(饼图)、Histogram(直方图) 、Scatter(散点图)、Map(地图)和WordCloud(词云图),接下来就分别介绍一下。
-
Bar(柱状图)
因为我们这次要分析的是二手房的数据,关于房子,我们最关心的就是不同类型房子的价格,比如不同户型、不同面积、不同小区的房子总价和单价的情况,而柱状图特别适合按不同数据类型进行数值的呈现。
因此这次的数据分析报告中,在分析按房屋面积区间的房屋单价、按房子户型的房屋单价以及小区房价Top10这三个数据图表中,我们使用了柱状图来呈现数据分析结果
接下来我们就以小区房价Top10为例,来看一下如何生成柱状图。
其实主要过程包括两个步骤(PS:后续每个图表都按着两个步骤来介绍):
-
数据计算处理
-
数据可视化处理
我们先来看第一步的数据计算处理。因为要找到这个城市小区房价的Top10,所以我们主要完成如下几个计算步骤:
-
根据原始数据表中的”小区名称“字段进行group by;
-
对每个分组,对”均价“字段求平均值;
-
对上述结果的”均价“字段按降序进行排序;
-
对排序结果取前10项结果;
完成上述四个计算步骤的代码如下所示:
def unit_price_analysis_by_estate(df,isembed):
#获取要分析的数据列
analysis_df = df.loc[:,['小区名称','均价']]
analysis_df.loc[:,'小区名称'] = analysis_df.loc[:,'小区名称'].astype('str')
#对小区名称分组,然后按照分组计算单价均价
group = analysis_df.groupby('小区名称',as_index=False)
group_df = group.mean()
group_df.loc[:,'均价'] = group_df.loc[:,'均价'].astype('int')
#按照均价列降序排序
group_df.sort_values('均价',ascending=False, inplace=True)
#取Top10
top10_df = group_df.head(10)
#为了横向柱状图展示,再从低到高排序一下
top10_df.sort_values('均价',ascending=True,inplace=True)
......
其实如果是生成常规的纵向柱状图的话,上面的代码里最后一步是不需要的。但因为要生成横向柱状图,需要对纵向柱状图进行一个reverse()操作,在reverse()操作后如果要保持从上至下降序的顺序,我们的对Top10的排序结果也需要倒置一下。
接下来就是柱状图的数据可视化图表生成部分了,这部分代码如下:
bar = (
Bar(init_opts=opts.InitOpts(width="1500px"))
.add_xaxis(top10_df['小区名称'].tolist())
.add_yaxis("房价单价",top10_df['均价'].tolist(),itemstyle_opts=opts.ItemStyleOpts(color=JsCode(top10_color_function)))
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
.set_global_opts(title_opts=opts.TitleOpts(title="苏州各小区二手房房价TOP10"),
xaxis_opts=opts.AxisOpts(axislabel_opts={'interval':'0'}),
legend_opts=opts.LegendOpts(is_show=False))
)
关于代码里详细的参数设置我就不一一解释了,大家可以去Pyecharts的官网查看到每个图表非常详细的参数解释和demo代码。
在这里唯一额外提一下的,就是关于如何给柱状图不同的柱子设置不同的颜色,需要我们提供一个自定义的js函数来实现,Pyecharts提供了这样的机制,可以让我们嵌入这样的js函数来完成部分自定义的功能,比如我是这样来实现的:
top10_color_function = """
function (params) {
if (params.value > 58000 && params.value < 59000) {
return 'red';
} else if (params.value > 59000 && params.value < 60000) {
return 'blue';
}else if (params.value > 60000 && params.value < 61000){
return 'green'
}else if (params.value > 61000 && params.value < 61800){
return 'purple'
}else if (params.value > 61800 && params.value < 70000){
return 'brown'
}else if (params.value > 70000 && params.value < 73000){
return 'gray'
}else if (params.value > 73000 && params.value < 79000){
return 'orange'
}else if (params.value > 79000 && params.value < 85000){
return 'pink'
}else if (params.value > 85000 && params.value < 100000){
return 'navy'
}
return 'gold';
}
"""
在这个函数中,我们需要根据每个柱子实际数值的大小,来划分区间,以决定每个柱子的颜色。
完成上述两个步骤后,我们的横向柱状图就生成了如图所示:
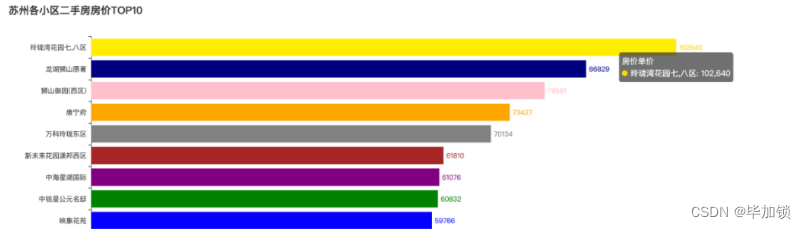
从上图可以看到,当我们把鼠标移到某个柱子上的时候,会出现相应的浮层,展示当前柱子代表的category的数值。也即,就如我们之前提到的,Pyecharts的图表是动态可交互的图表。
另外,从图中我们可以看到,苏州玲珑湾花园小区是苏州二手房房价最贵的小区,尤其是七区和八区,至于为什么,大家可以自行上百度搜索看看。
-
Pie(饼图)
饼图一般用来分析不同类型的数量的占比。在这次的数据报告中,因为是对二手房的分析,所以我们想看一下待售卖的二手房中,不同建筑年份的房子数量占比情况,据此可以看看哪些年份的老房子是卖的比较多的。
数据计算处理步骤:
-
因为原数据表中没有待售房屋数这一列,因此我们先增加一列,用于后续计算;
-
对建筑年份列进行group by;
-
对每个分组进行统计计数,结果写入新增加的待售房屋数列;
代码实现如下:
def add_sale_estate_col(row):
return 0
def sale_estate_analysis_by_year(df,isembed):
#增加一列待售房屋数,初始值均为0
df.loc[:,'待售房屋数'] = df.apply(add_sale_estate_col,axis=1)
#获取要用作数据分析的两列:建筑年份和待售房屋数
analysis_df = df.loc[:,['建筑年份','待售房屋数']]
#因为建筑年份列有空值,先预处理一下
analysis_df.dropna(inplace=True)
#按照建筑年份进行分组
group = analysis_df.groupby('建筑年份',as_index=False)
#对每个分组进行统计计数
group_df = group.count()
group_df.loc[:,'待售房屋数'] = group_df.loc[:,'待售房屋数'].astype('int')
......
接下来就是饼图的数据可视化图表生成部分了,这部分代码如下:
pie = Pie(init_opts=opts.InitOpts(width='800px', height='600px', bg_color='white'))
pie.add("pie",[list(z) for z in zip(group_df['建筑年份'].tolist(),group_df['待售房屋数'].tolist())]
,radius=['40%', '60%']
,center=['50%', '50%']
,label_opts=opts.LabelOpts(
position="outside",
formatter="{b}:{c}:{d}%",)
).set_global_opts(
title_opts=opts.TitleOpts(title='苏州二手房不同建筑年份的待售数量', pos_left='300', pos_top='20',
title_textstyle_opts=opts.TextStyleOpts(color='black', font_size=16)),
legend_opts=opts.LegendOpts(is_show=False))
在这部分代码中需要额外提一下的是如下这部分代码:
[list(z) for z in zip(group_df['建筑年份'].tolist()
因为Pie需要的数据格式,是元组数组的形式,因此在上面的代码中,我们使用zip()这个函数,来将两个Series对应的元素拼接成元组。
我们最后生成的饼图如下所示:
从上图我们可以看到,苏州待售的数量较多的二手房,大多是2015-2019年期间建成的,也即距今的房龄不超过10年。2021年及后的房子明显少了很多,应该是跟满二的政策有关系。
-
Histogram(直方图)
直方图又称质量分布图,是一种统计报告图,由一系列高度不等的纵向条纹或线段表示数据分布的情况。一般用横轴表示数据类型,纵轴表示分布情况。为了构建直方图,第一步是将值的范围分段,即将整个值的范围分成一系列间隔,然后计算每个间隔中有多少值。
关于我们要分析的二手房数据,我们最关心的还是房价的分布情况,比如不同单价和总价的房子在不同价格区间的分布数量情况。
因此,我们用直方图来分析苏州二手房不同单价和总价的房子数量的分布。
数据计算处理步骤:
-
将要分析的数据字段进行分段;
-
对每个分段,计算该分段里的分布数量;
上面两个计算步骤,在Python的Numpy库里,提供了一个叫histogram()的函数,能够直接帮我们来实现,见下面代码所示:
import numpy as np
def unit_price_analysis_by_histogram(df,isembed):
hist,bin_edges = np.histogram(df['均价'],bins=100)
bar = (
Bar()
.add_xaxis([str(x) for x in bin_edges[:-1]])
.add_yaxis('价格分布',[float(x) for x in hist],category_gap=0)
.set_global_opts(
title_opts=opts.TitleOpts(title='苏州二手房房价-单价分布-直方图',pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False)
)
)
......
从上面代码里我们可以看到,我们把均价字段分成了100个间隔区间,bin_edges就是划分出来的100个区间,然后我们计算每个区间里的分布数量,hist就是分布数量的计算结果
这样我们画出来的直方图如下所示(以二手房单价直方图为例):
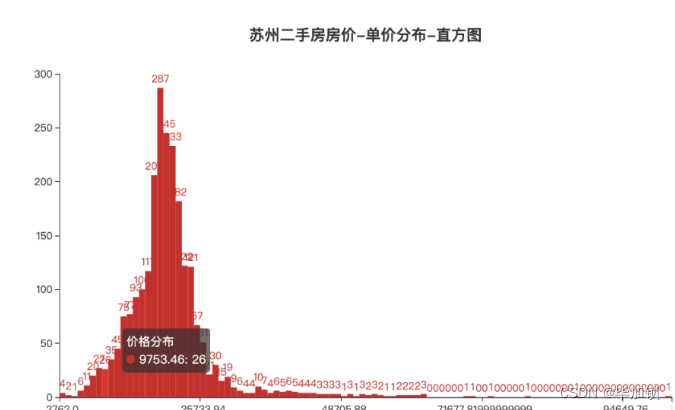
从上图我们可以看到,苏州二手房的单价,大部分集中在17000-21000这个价格区间,单价低于10000或高于30000的房子相对就比较少了。
-
Scatter(散点图)
散点图一般用在回归分析中,是一种数据点在直角坐标系平面上的分布图,用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联的分布模式
对于我们要分析的苏州二手房数据,我们可能会关心,哪些因素是跟二手房的房价有关系的,以及是什么关系,比如如果我们想知道房子面积跟房子单价之间是什么关系?那我们可以画一个面积-单价的散点图来看看。
因为我们的原始数据中已经有面积和均价两个字段,因此不需要我们做更多的数据计算处理,我们直接来看这部分的实现代码:
df.sort_values('面积',ascending=True, inplace=True)
square = df['面积'].to_list()
unit_price = df['均价'].to_list()
scatter = (
Scatter()
.add_xaxis(xaxis_data=square)
.add_yaxis(
series_name='',
y_axis=unit_price,
symbol_size=4,
label_opts=opts.LabelOpts(is_show=False)
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(type_='value'),
yaxis_opts=opts.AxisOpts(type_='value'),
title_opts=opts.TitleOpts(title='苏州二手房面积-单价关系图',pos_left='center')
)
)
我们画出来的散点图如下所示:
从上图我们可以看出,苏州二手房的单价跟房子面积并不是呈线性相关的关系,也即不是面积越大,单价越高,房子单价的高点出现在100-200平方这个区间,然后随着面积逐渐增大单价呈逐渐下降趋势,因此是一个曲线相关的关系,而且这个曲线类似一个正态分布曲线。
-
Map(地图)
在我们爬取到的苏州二手房数据中,有小区所在的区-镇-街道的地理位置信息,因此,我们可以结合地图,直观的来看一下苏州不同区的二手房房价信息。
在做地图展示之前,我们先要做一下如下数据计算处理:
-
获取数据源中的区和均价两个字段;
-
对区字段进行group by;
-
对分组后的数据求平均值;
-
为适配地图组件的行政区划名称,对区字段进行一下转换处理;
-
将数据转换成地图组件需要的二维数组的格式;
def transform_name(row):
district_name = row['区'].strip()
if district_name == '吴中' or district_name == '相城' or district_name == '吴江' or district_name == '虎丘' or district_name == '姑苏' or district_name == '工业园':
district_name = district_name + '区'
if district_name == '常熟' or district_name == '张家港' or district_name == '太仓':
district_name = district_name + '市'
return district_name
data = []
#获取要分析的数据列
analysis_df = df.loc[:,['区','均价']]
#按区列分组
group_df = analysis_df.groupby('区',as_index=False)
#根据分组对均价列求平均值
group_df = group_df.mean('均价')
#print(group_df)
#将区的名字做一下转换,为下面的地图匹配做准备
group_df['区'] = group_df.apply(transform_name,axis=1)
group_df.loc[:,'均价'] = group_df.loc[:,'均价'].astype('int')
#将数据转换成map需要的数据格式
for index,row in group_df.iterrows():
district_array = [row['区'],row['均价']]
data.append(district_array)
数据处理完成后,我们就可以用地图组件进行可视化渲染了:
map = (
Map()
.add('苏州各区域二手房房价',data,'苏州')
.set_global_opts(
title_opts=opts.TitleOpts(title='苏州各区域二手房房价地图',pos_left='center'),
visualmap_opts=opts.VisualMapOpts(max_=26000),
legend_opts=opts.LegendOpts(is_show=False)
)
)
最终我们可以看到苏州二手房根据地图展示的各区房价
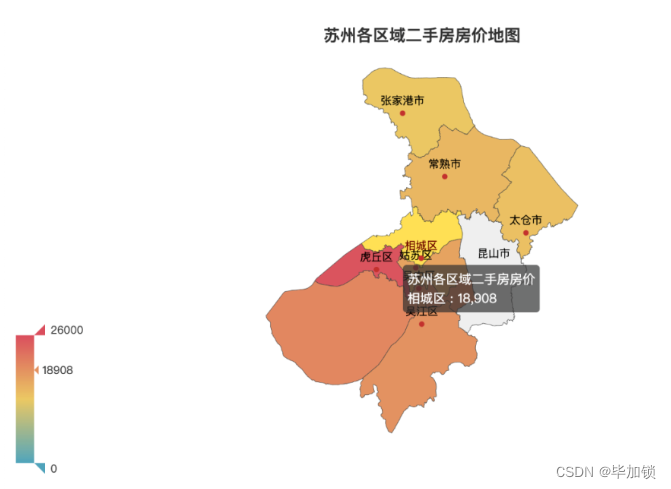
从地图上可以很直观的看到,虎丘区的平均房价是最高的。这里需要说明一下的是,因为Pyecharts的map组件的地理位置数据相对比较老了,所以没有体现出苏州最新的行政区域划分,比如我们原始数据中的工业园区、高新区等数据没法体现出来,时间原因,我没有尝试其他的map组件,大家有兴趣可以自行试试。
-
WordCloud(词云图)
在我们爬取到的苏州二手房数据中,有两列纯文本类型的字段,一个是待售房屋,一个是标签,这两列的文本描述了待售房源的一些特征信息,我们可以提前其中一些高频特征,来看看购房者最关注的房屋关键词有哪些
在这个分析场景中,我们会用到一个新的第三方库jieba,这个库可以对我们要分析的文本进行分词,然后自动分析每个分词出现的频率并给出相应的权重,权重越高代表词频越高。
我们首先要进行一步数据处理,即把待售房屋字段和标签字段的文本合并到一起,然后把合并之后的文本交给jieba进行处理,最后把jieba分词计算处理的结果交给WordCloud图表组件进行渲染,整个代码实现如下所示:
txt = ''
for index,row in df.iterrows():
txt = txt+ str(row['待售房屋']) + ';'+ str(row['标签']) + '\n'
word_weights = jieba.analyse.extract_tags(txt,topK=100,withWeight=True)
word_cloud=(
WordCloud()
.add(series_name='高频词语',data_pair=word_weights,word_size_range=[10,100])
.set_global_opts(
title_opts=opts.TitleOpts(
title='苏州二手房销售热度词',
title_textstyle_opts=opts.TextStyleOpts(font_size=23),
pos_left='center'
)
)
)
其中extract_tags()函数的topk参数表示要提取权重排序前多少名的结果
最终我们对苏州二手房数据生成的词云图如下所示:
从上图我们可以看到,交通、朝向是购房者第一位关注的房子信息,其次是是否有车位、是否满五(二)唯一、是否精装修等。
生成动态可交互的Web数据分析报告
好了,通过上面的步骤,我们已经把要分析的数据可视化图表都生成了,但我朋友总不能把这些图表一个个的发给她老板看,除非她真的想看看新的机会了。我们需要把这些图表放到一个web页面上,生成一份完整的数据分析报告后,再递呈老板审阅。所以,最后一步,我们来完成一个web页面来完整地呈现这份数据分析报告。
这个步骤的实现主要包括如下三个部分组成:
-
用flask库实现的app.py脚本,这个脚本主要干如下几件事:
-
启动一个web服务;
-
读取我们要分析的原始数据;
-
实现一个函数负责将读取的数据传给不同的数据图表生成函数,拿到生成的数据图表对象,然后调用模版进行渲染;
-
绑定一个url路由关系,映射到步骤三的函数;
-
-
用来渲染生成最终数据分析报告的HTML文件,这个文件主要干如下几件事:
-
对每个数据图表定义一个div;
-
使用ECharts组件对div进行初始化;
-
通过变量拿到flask返回的数据图表数据,对ECharts组件进行设置;
-
-
HTML渲染和计算所依赖的静态资源文件,主要有如下三个:
-
echarts-wordcloud.min.js,主要用于词云图生成;
-
jiang1_su1_su1_zhou1.js,主要用于苏州地图生成;
-
echarts.min.js,是所有数据图表依赖的基础js
-

flask的app.py脚本的核心代码如下:
from flask import Flask,render_template
import drawChart as dbc
import pandas as pd
app = Flask(__name__)
#读取要分析的数据
fpath = 'path/filename.xlsx'
df = pd.read_excel(fpath,sheet_name="Sheet1",header=[0],engine='openpyxl')
#绑定url映射关系
@app.route("/show_all_analysis_chart")
def show_all_analysis_chart():
#获取按面积区间的单价分析数据
unit_price_analysis_by_square = dbc.unit_price_analysis_by_square(df,False)
#获取按室区分的单价分析数据
unit_price_analysis_by_layout = dbc.unit_price_analysis_by_layout(df,False)
#获取苏州各小区二手房房价TOP10
unit_price_analysis_by_estate = dbc.unit_price_analysis_by_estate(df,False)
#获取不同建筑年份的待售房屋数
sale_estate_analysis_by_year = dbc.sale_estate_analysis_by_year(df,False)
#苏州二手房房价-单价分布-直方图
unit_price_analysis_by_histogram = dbc.unit_price_analysis_by_histogram(df,False)
#苏州二手房房价-总价分布-直方图
total_price_analysis_by_histogram = dbc.total_price_analysis_by_histogram(df,False)
#苏州二手房面积-单价关系图
unit_price_analysis_by_scatter = dbc.unit_price_analysis_by_scatter(df,False)
#苏州二手房销售热度词
hot_word_analysis_by_wordcloud = dbc.hot_word_analysis_by_wordcloud(df,False)
#苏州各区域二手房房价
unit_price_analysis_by_map = dbc.unit_price_analysis_by_map(df,False)
return render_template("show_analysis_chart.html",
unit_price_analysis_by_square_option = unit_price_analysis_by_square.dump_options(),
unit_price_analysis_by_layout_option = unit_price_analysis_by_layout.dump_options(),
unit_price_analysis_by_estate_option = unit_price_analysis_by_estate.dump_options(),
sale_estate_analysis_by_year_option = sale_estate_analysis_by_year.dump_options(),
unit_price_analysis_by_histogram_option = unit_price_analysis_by_histogram.dump_options(),
total_price_analysis_by_histogram_option = total_price_analysis_by_histogram.dump_options(),
unit_price_analysis_by_scatter_option = unit_price_analysis_by_scatter.dump_options(),
hot_word_analysis_by_wordcloud_option = hot_word_analysis_by_wordcloud.dump_options(),
unit_price_analysis_by_map_option = unit_price_analysis_by_map.dump_options()
)
#启动web应用
if __name__ == "__main__":
app.run()
Html的核心代码如下:
<head>
<meta charset="UTF-8">
<title>苏州二手房数据分析报告</title>
<script type="text/javascript" src="/static/echarts.min.js"></script>
<script type="text/javascript" src="/static/echarts-wordcloud.min.js"></script>
<script type="text/javascript" src="/static/jiang1_su1_su1_zhou1.js"></script>
</head>
<body>
<h1 align="center">苏州二手房数据分析报告</h1>
<h2>1.苏州二手房按面积区间的房屋单价</h2>
<div id="unit_price_analysis_by_square" style="width:900px; height:500px;"> </div>
<script type="text/javascript">
var unit_price_analysis_by_square_chart = echarts.init(document.getElementById('unit_price_analysis_by_square'));
var option = {{ unit_price_analysis_by_square_option | safe }};
unit_price_analysis_by_square_chart.setOption(option);
</script>
......
制作不易,点个关注再走吧~
我是毕加索 期待你的关注








![[论文阅读] 颜色迁移-梯度保护颜色迁移](https://img-blog.csdnimg.cn/1a70eda52f5a40c4bfc952c3d8f7e9fe.png)

![[附源码]Python计算机毕业设计SSM基于农产品交易系统(程序+LW)](https://img-blog.csdnimg.cn/37e991aeccf147c5afe41e97f6690000.png)