模板引擎
- 什么是模板引擎
- 实现 Scanner 类
- 根据模板字符串生成 tokens
- 在 index.js 引入 parseTemplateToTokens
- 实现 tokens 的嵌套
- One More Thing
- tokens 结合数据解析为 dom 字符串
- 定义 lookup 函数
- 定义 renderTemplate 函数

什么是模板引擎
模板引擎是将数据变为视图最优雅的解决方案
以前出现过的其它数据变视图的方法
-
纯 DOM 法
-
数组 join 法
在 js 里单双引号内的内容是不能换行的,为了提高 dom 结构可读性,利用了数组的 join 方法(将数组变为字符串),注意 join 的参数 ‘’ 不可以省略,否则得到的 str 字符串会是以逗号间隔的 -
es6 的模板字符串(``)
刚开始用模板引擎时可以引用 如下:
<script src="https://cdn.bootcdn.net/ajax/libs/mustache.js/4.2.0/mustache.js"></script>
<script src="https://cdn.bootcdn.net/ajax/libs/mustache.js/4.2.0/mustache.js"></script>
底层核心机理
//最简单的模板的实现机理,利用的是正则表达式中的replace()方法
// replace()的第二个参数可以是一个函数,这个函数提供捕获的东西的参数,就是$1
//结合data的对象,即可进行智能的替换
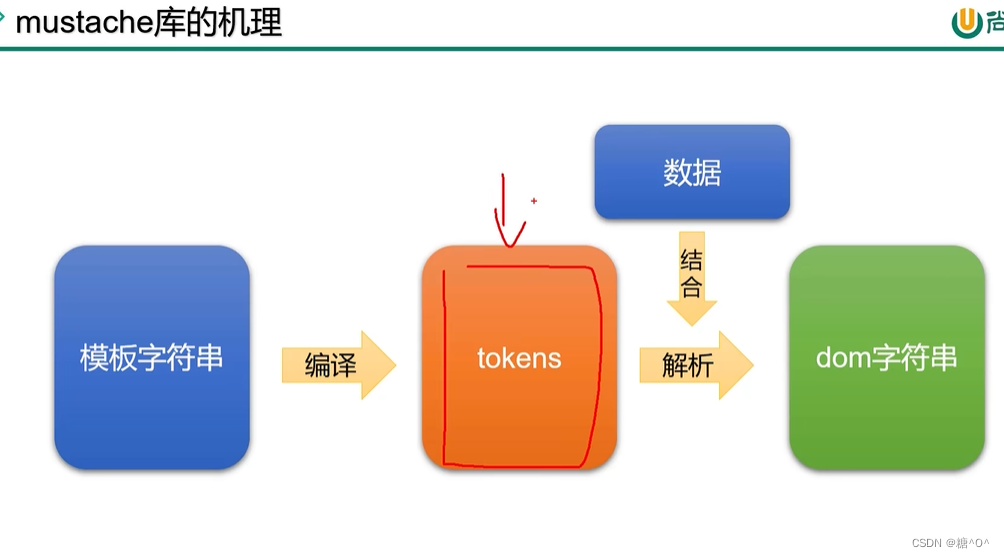
//编译普通对象成token
const templateStr = `<h3>我今天买了一部{{thing}}手机,花了我{{money}}元,心情好{{mood}}啊</h3>`;
[
["text",'<h3>我今天买了一部'],
["name",'thing'],
["text",'手机,花了我'],
["name",'money']
["text",'元,心情好'],
["name","mood"],
["text",'啊']
]
模块化打包工具有webpack(webpack-dev-server) 、rollup、Parcel等
我们经常使用webpack进行模块化打包
实现 Scanner 类
Scanner 类的实例就是一个扫描器,用来扫描构造时作为参数提供的那个模板字符串
- 属性
- pos:指针,用于记录当前扫描到字符串的位置
- tail:尾巴,值为当前指针之后的字符串(包括指针当前指向的那个字符)
- 方法
- scan:无返回值,让指针跳过传入的结束标识 stopTag
- scanUntil:传入一个指定内容 stopTag 作为让指针 pos 结束扫描的标识,并返回扫描内容
// Scanner.js
export default class Scanner {
constructor(templateStr) {
this.templateStr = templateStr
// 指针
this.pos = 0
// 尾巴
this.tail = templateStr
}
scan(stopTag) {
this.pos += stopTag.length // 指针跳过 stopTag,比如 stopTag 是 {{,则 pos 就会加2
this.tail = this.templateStr.substring(this.pos) // substring 不传第二个参数直接截取到末尾
}
scanUntil(stopTag) {
const pos_backup = this.pos // 记录本次扫描开始时的指针位置
// 当指针还没扫到最后面,并且当尾巴开头不是 stopTag 时,继续移动指针进行扫描
while (!this.eos() && this.tail.indexOf(stopTag) !== 0){
this.pos++ // 移动指针
this.tail = this.templateStr.substring(this.pos) // 更新尾巴
}
return this.templateStr.substring(pos_backup, this.pos) // 返回扫描过的字符串,不包括 this.pos 处
}
// 指针是否已经抵达字符串末端,返回布尔值 eos(end of string)
eos() {
return this.pos >= this.templateStr.length
}
}
根据模板字符串生成 tokens
tokens是一个JS的嵌套数组,说白了,就是模板字符串的JS表示
有了 Scanner 类后,就可以着手去根据传入的模板字符串生成一个 tokens 数组了。最终想要生成的 tokens 里的每一条 token 数组的第一项用 name(数据) 或 text(非数据文本) 或 #(循环开始) 或 /(循环结束) 作为标识符
// parseTemplateToTokens.js
import Scanner from './Scanner.js'
import nestTokens from './nestTokens' // 后面会解释
// 函数 parseTemplateToTokens
export default templateStr => {
const tokens = []
const scanner = new Scanner(templateStr)
let word
while (!scanner.eos()) {
word = scanner.scanUntil('{{')
word && tokens.push(['text', word]) // 保证 word 有值再往 tokens 里添加
scanner.scan('{{')
word = scanner.scanUntil('}}')
/**
* 判断从 {{ 和 }} 之间收集到的 word 的开头是不是特殊字符 # 或 /,
* 如果是则这个 token 的第一个元素相应的为 # 或 /, 否则为 name
*/
word && (word[0] === '#' ? tokens.push(['#', word.substr(1)]) :
word[0] === '/' ? tokens.push(['/', word]) : tokens.push(['name', word]))
scanner.scan('}}')
}
return nestTokens(tokens) // 返回折叠后的 tokens, 详见下文
}
在 index.js 引入 parseTemplateToTokens
// index.js
import parseTemplateToTokens from './parseTemplateToTokens.js'
window.My_TemplateEngine = {
render(templateStr, data) {
const tokens = parseTemplateToTokens(templateStr)
console.log(tokens)
}
}
这样我们就可以把传入的 templateStr 初步转成 tokens 了,比如 templateStr 为
const templateStr = `
<ul>
{{#arr}}
<li>
<div>{{name}}的基本信息</div>
<div>
<p>{{name}}</p>
<p>{{age}}</p>
<div>
<p>爱好:</p>
<ol>
{{#hobbies}}
<li>{{.}}</li>
{{/hobbies}}
</ol>
</div>
</div>
</li>
{{/arr}}
</ul>
`
那么目前经过 parseTemplateToTokens 处理将得到如下的 tokens

实现 tokens 的嵌套
新建 nestTokens.js 文件,定义 nestTokens 函数来做 tokens 的嵌套功能,将传入的 tokens 处理成包含嵌套的 nestTokens 数组返回。
然后在 parseTemplateToTokens.js 引入 nestTokens,在最后 return nestTokens(tokens)。
在 nestTokens 中,我们遍历传入的 tokens 的每一个 token,遇到第一项是 # 和 /的分别做处理,其余的做一个默认处理。
大致思路是当遍历到的 token 的第一项为 # 时,就把直至遇到配套的 / 之前,遍历到的每一个 token 都放入一个容器(collector)中,把这个容器放入当前 token 里作为第 3 项元素
但这里有个问题:在遇到匹配的 / 之前又遇到 # 了怎么办?也就是如何解决循环里面嵌套循环的情况?
- 解决方法就是新建一个
栈数据类型的数组(stack),遇到一个 #,就把当前 token 放入这个栈中,让 collector 指向这个 token 的第三个元素。
遇到下一个 # 就把新的 token 放入栈中,collector 指向新的 token 的第三个元素。
遇到 / 就把栈顶的 token 移出栈,collector 指向移出完后的栈顶 token。
这就利用了栈的先进后出的特点,保证了遍历的每个 token 都能放在正确的地方,也就是 collector 都能指向正确的地址。
// nestTokens.js
export default (tokens) => {
const nestTokens = []
const stack = []
let collector = nestTokens // 一开始让收集器 collector 指向最终返回的数组 nestTokens
tokens.forEach(token => {
switch (token[0]) {
case '#':
stack.push(token)
collector.push(token)
collector = token[2] = [] // 连等赋值
break
case '/':
stack.pop(token)
collector = stack.length > 0 ? stack[stack.length-1][2] : nestTokens
break;
default:
collector.push(token)
break
}
})
return nestTokens
}
One More Thing
上面的代码中有用到 collector = token[2] = [],是为连等赋值,相当于
token[2] = []
collector = token[2]
看着简单,其实暗含着小坑,除非你真的了解它,否则尽量不要使用。比如我在别处看到这么一个例子,
let a = {n:1};
a.x = a = {n:2};
console.log(a.x); // 输出?
答案是 undefined,你做对了吗?
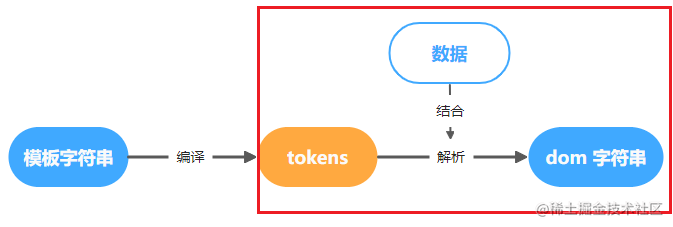
tokens 结合数据解析为 dom 字符串
大致思路是遍历 tokens 数组,根据每条 token 的第一项的值来做不同的处理,为 text 就直接把 token[1]
加入到最终输出的 dom 字符串,为 name 则根据 token[1] 去 data 里获取数据,结合进来。
当 data 里存在多层嵌套的数据结构,比如 data = { test: { a: { b: 10 } } },这时如果某个 token 为 [“name”, “test.a.b”],即代表数据的 token 的第 2 项元素是 test.a.b 这样的有多个点符号的值,那么我么直接通过 data[test.a.b] 是无法拿到正确的值的,因为 js 不认识这种写法。
我们需要提前准备一个 lookup 函数,用以正确获取数据。
定义 lookup 函数
// lookup.js
// 思路就是先获取 test.a 的值, 比如说是 temp, 再获取 temp.b 的值, 一步步获取
export default (data, key) => {
// 如果传入的 key 里有点符号而且不是仅仅只是点符号
if (key.indexOf('.') !== -1 && key !== '.' ) {
const keys = key.split('.') // 将 key 用 . 分割成一个数组
return keys.reduce((acc, cur) => {
return acc[cur] // 一步步获取
}, data)
}
// 如果传入的 key 没有点符号,直接返回
return data[key]
}
定义 renderTemplate 函数
接下来写个 renderTemplate 函数将 tokens 和 data 作为参数传入,解析为 dom 字符串了。
// renderTemplate.js
import lookup from './lookup.js'
import parseArray from './parseArray.js'
export default (tokens, data) => {
let domString = ''
tokens.forEach(token => {
switch (token[0]) {
case 'text':
domString += token[1]
break
case 'name':
domString += lookup(data, token[1])
break
case '#':
domString += parseArray(token[2], data[token[1]])
break
default:
break
}
})
return domString
}
复制代码
需要注意的是遇到循环的情况,也就是当某个 token 的第一项为 “#” 时,要再次递归调用 renderTemplate 函数。这里我们新定义了一个 parseArray 函数来处理。
// parseArray.js
import renderTemplate from './renderTemplate.js'
export default (tokens, data) => {
let domString = ''
data.forEach(itemData => {
domString += renderTemplate(tokens, {
...itemData,
'.': itemData // 针对简单数组的情况,即模板字符串里的 {{.}}
})
})
return domString
}
复制代码
到此,就算是完结了。能力一般,水平有限,难免会有纰漏不足的地方,还请各位看官斧正。





![[ChatGPT为你支招]如何提高博客的质量,找到写作方向,保持动力,增加粉丝数?](https://img-blog.csdnimg.cn/6659aa1007b845d8a61bfbe62a2417b2.png#pic_center)