背景
在深度学习中学习率这个超参数,在选取和调整都是有一定策略的,俗称炼丹。有时我们遇到 loss 变成 NaN 的情况大多数是由于学习率选择不当引起的。
神经网络在刚开始训练的时候模型的权重(weights)是随机初始化的,选择一个较大的学习率,可能带来模型的不稳定(振荡),因此刚训练时的学习率应当设置一个比较小的值,进而确保网络能够具有良好的收敛性。但较小的学习率会使得训练过程变得非常缓慢,于是learning rate warmup这个概念应运而生。
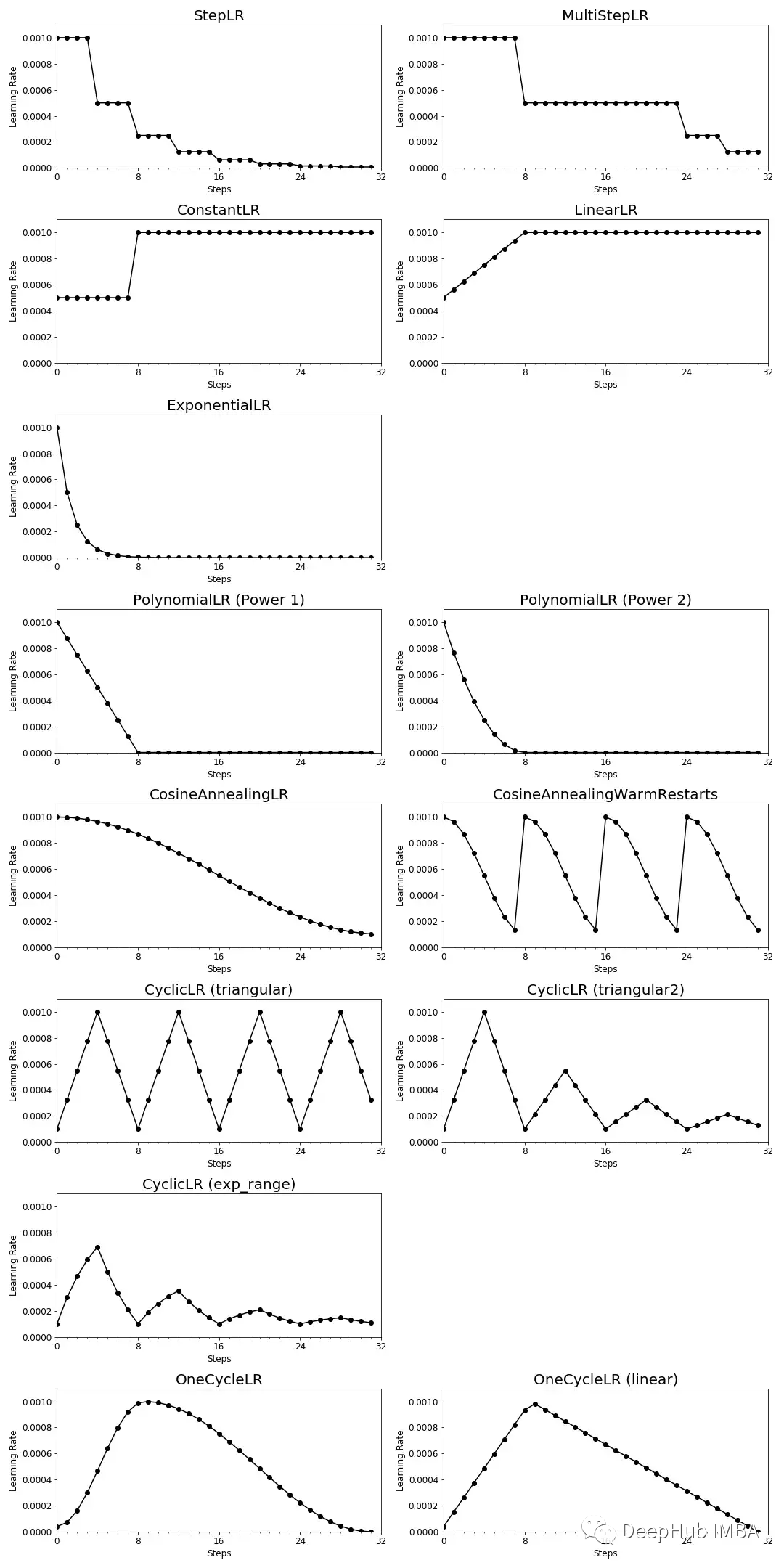
warmup采用以较低学习率逐渐增大至较高学习率的方式实现网络训练的“热身”阶段,随着训练的进行学习率慢慢变大,到一定程度后就可以设置的预设的学习率进行训练了,随着模型的拟合,需要的学习率也会越来越小,这时也会需要将学习率调小。学习率的warmup和学习率衰减可如下图走势:
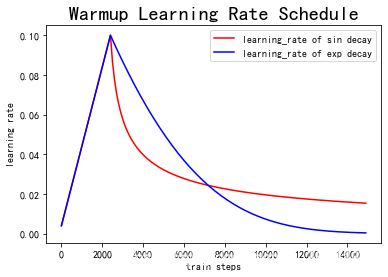
warmup
Resnet论文中使用一个110层的ResNet在cifar10上训练时,先用0.01的学习率训练直到训练误差低于80%(大概训练了400个steps),然后使用0.1的学习率进行训练。其不足之处在于从一个很小的学习率一下变为比较大的学习率可能会导致训练误差突然增大。18年Facebook提出了gradual warmup来解决这个问题,即从最初的小学习率开始,每个step增大一点点,直到达到最初设置的比较大的学习率时,采用最初设置的学习率进行训练。有了这种思想后,也逐渐衍生了多种warmup方式。
在transformers有对应的warmup,如下:
- get_constant_schedule_with_warmup,
- get_cosine_schedule_with_warmup,
- get_cosine_with_hard_restarts_schedule_with_warmup,
- get_linear_schedule_with_warmup,
- get_polynomial_decay_schedule_with_warmup
可通过from transformers import get_constant_schedule_with_warmup 方式导入。其中get_cosine_schedule_with_warmup在transformers官网中的学习率变化曲线如下:
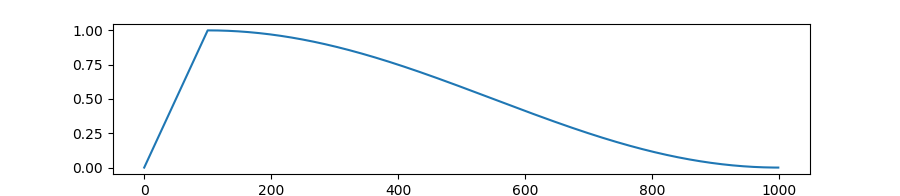
pytorch中adjust learning rate
这部分内容参考了:pytorch之warm-up预热学习策略。pytorch官方文档:https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate也介绍了几种根据训练epoch调整学习率的方法:torch.optim.lr_scheduler,如果想自定义warmup和decay的话,可以使用torch.optim.lr_scheduler.LambdaLR,书写方法可以参考transformers中的写法如下:
def get_cosine_schedule_with_warmup(
optimizer: Optimizer, num_warmup_steps: int, num_training_steps: int, num_cycles: float = 0.5, last_epoch: int = -1
):
"""
Create a schedule with a learning rate that decreases following the values of the cosine function between the
initial lr set in the optimizer to 0, after a warmup period during which it increases linearly between 0 and the
initial lr set in the optimizer.
Args:
optimizer ([`~torch.optim.Optimizer`]):
The optimizer for which to schedule the learning rate.
num_warmup_steps (`int`):
The number of steps for the warmup phase.
num_training_steps (`int`):
The total number of training steps.
num_cycles (`float`, *optional*, defaults to 0.5):
The number of waves in the cosine schedule (the defaults is to just decrease from the max value to 0
following a half-cosine).
last_epoch (`int`, *optional*, defaults to -1):
The index of the last epoch when resuming training.
Return:
`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
"""
def lr_lambda(current_step):
if current_step < num_warmup_steps:
return float(current_step) / float(max(1, num_warmup_steps))
progress = float(current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))
return max(0.0, 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress)))
return LambdaLR(optimizer, lr_lambda, last_epoch)
源码链接:https://github.com/huggingface/transformers/blob/v4.25.1/src/transformers/optimization.py#L50
常用的有基于余弦退火的lr_scheduler:lr_scheduler.CosineAnnealingLR,
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)
以初始学习率为最大学习率,以 2 ∗ T _ m a x 2 ∗ T\_ {m a x} 2∗T_max 为周期,在一个周期内先下降,后上升。其中:
- T_max(int):学习率下降到最小值时的epoch数,即当epoch=T_max时,学习率下降到余弦函数最小值,当epoch>T_max时,学习率将增大
- eta_min(float):学习率的最小值,即在一个周期中,学习率最小会下降到 eta_min,默认值为 0
- 上一个epoch数,这个变量用来指示学习率是否需要调整。当last_epoch符合设定的间隔时,就会对学习率进行调整;当为-1时,学习率设置为初始值。
更多的lr_schedule 可参考pytorch官方文档。
总结
当然,这种使用warmup和decay的learning rate schedule大多是在bert这种预训练的大模型的微调应用中遇见的。如果是做自然语言处理相关任务的,transformers已经封装了好几个带有warmup 和 decay的lr schedule。如果不是做研究的话,这些已经封装的lr schedule直接拿来用即可。当然也可以使用pytorch中的相关模块自定义。

![[ChatGPT为你支招]如何提高博客的质量,找到写作方向,保持动力,增加粉丝数?](https://img-blog.csdnimg.cn/6659aa1007b845d8a61bfbe62a2417b2.png#pic_center)