Hugging Face开源库accelerate详解
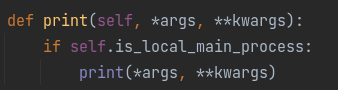
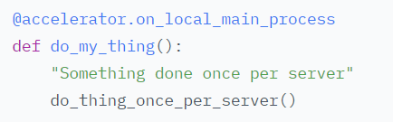
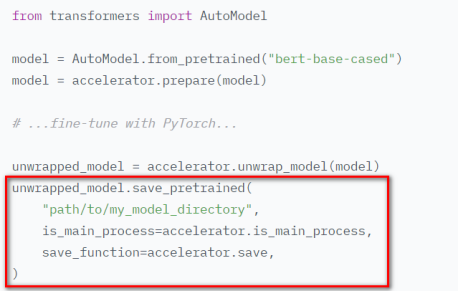
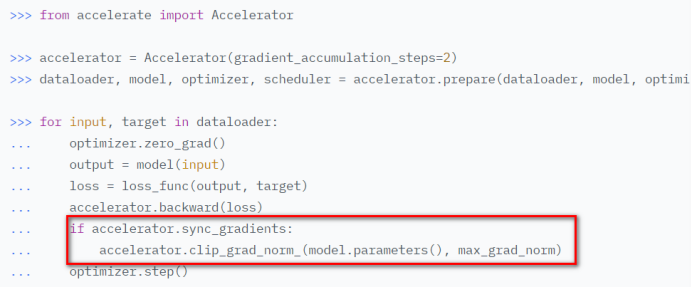
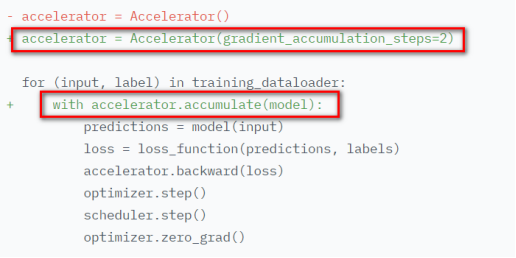
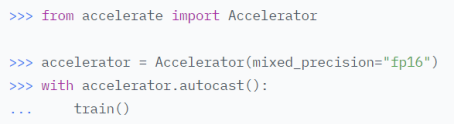
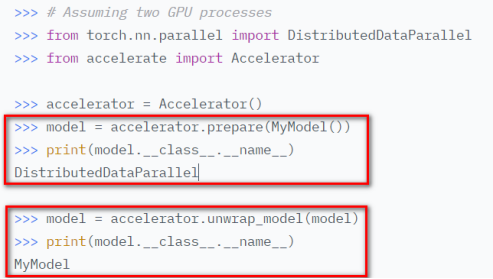
初始化accelerate对象accelerator = Accelerator() 调用prepare方法对model、dataloader、optimizer、lr_schedluer进行预处理 删除掉代码中关于gpu的操作,比如.cuda()、.to(device)等,让accelerate自行判断硬件设备的分配 将loss.backbard()替换为accelerate.backward(loss) 当使用超过1片GPU进行分布式训练时,在主进程中使用gather方法收集其他几个进程的数据,然后在计算准确率等指标 device_placement (bool, optional, defaults to True) — 是否让accelerate来确定tensor应该放在哪个device split_batches (bool, optional, defaults to False) — 分布式训练时是否对dataloader产生的batch进行split,如果True,那么每个进程使用的batch size = batch size / GPU数量,如果是False,那么每个进程使用就是batch size,总的batch size = batch size * GPU数量 mixed_precision (str, optional) — 是否使用混合精度训练 gradient_accumulation_steps (int, optional, default to 1) — 梯度累加的步数,也可以使用GradientAccumulationPlugin插件进行详细配置 cpu (bool, optional) — 是否强制使用CPU执行 deepspeed_plugin (DeepSpeedPlugin, optional) — 使用此参数调整与DeepSpeed相关的参数,也可以使用accelerate config直接配置 fsdp_plugin (FullyShardedDataParallelPlugin, optional) — 使用此参数调整FSDP(Fully Sharded Data Parallel)相关参数,也可以使用accelerate config直接配置 megatron_lm_plugin (MegatronLMPlugin, optional) — 使用此参数调整与MegatronLM相关的参数,可以使用accelerate config直接配置 step_scheduler_with_optimizer (bool, *optional, defaults to True) – lr_scheduler是否和optimizer同步更新 gradient_accumulation_plugin (GradientAccumulationPlugin, optional) — 梯度累积插件 accelerator.print() accelerator.is_local_main_process wait_for_everyone() accelerator.save_model() / load_state_dict / Accelerate与Transformers库搭配使用进行模型保存 使用accelerator做梯度裁剪: 梯度累加gradient accumulation autocast混合精度训练 gather、gather_for_metrics Prepare reduce:跨进程做tensor的reduce操作 save_state / load_state:保存、加载模型的状态数据 unscale_gradients:混合训练过程中不对梯度进行缩放 unwrap_model 执行accelerate config根据提问和实际硬件情况设置配置文件 执行accelerate test --config_file path_to_config.yaml验证环境配置是否正常 执行进行命令进行分布式训练,accelerate launch --config_file path_to_config.yaml path_to_script.py --args_for_the_script 参考:https://huggingface.co/docs/accelerate/usage_guides/big_modeling
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/771961.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!













![[javascript核心-08] V8 内存管理机制及性能优化](https://img-blog.csdnimg.cn/img_convert/81364972f4fea6cdac2ce1d20746b796.png)