目录
- 前言
- 一、HuggingFace介绍
- 1-1、HuggingFace的介绍
- 1-2、安装
- 二、Tokenizer分词库:分词工具
- 2-0、加载BertTokenizer:需要传入预训练模型的名字
- 2-1、使用Tokenizer对句子编码:
- 2-2、使用增强Tokenizer对句子编码:
- 2-3、批量编码单个句子:
- 2-4、添加新词:
- 2-5、AutoTokenizer与BertTokenizer的区别
- 三、Datasets数据集库: 数据集使用
- 3-1、数据集使用
- 3-2、数据集操作
- 3-3、评价函数
- 四、模型
- 4-1、各类NLP任务的常用模型
- 五、实战案例分析
- 5-1、Kaggle竞赛 Real or Not? NLP with Disaster Tweets 文本分类
- 5-1-1、数据介绍
- 总结
前言
Hugging Face是一个以自然语言处理(NLP)为重点的技术公司,也是一个开源社区和平台,旨在提供丰富的NLP模型、工具和资源。 Hugging Face的目标是成为NLP领域的社区和创新驱动者,他们通过为开发者和研究人员提供开源工具、预训练模型和数据集来实现这一目标。Hugging Face的开源库和工具广泛应用于各种NLP任务,包括文本分类、命名实体识别、情感分析、机器翻译等。一、HuggingFace介绍
1-1、HuggingFace的介绍
Hugging Face是一个致力于自然语言处理(NLP)领域的开源社区和技术公司。他们提供了一个广泛的NLP工具和资源平台,旨在帮助开发者和研究人员快速构建、训练和部署各种NLP模型。
通过Hugging Face,你可以使用他们开发的开源库和工具,如transformers、tokenizers和datasets等,来处理文本数据、构建预训练的Transformer模型,并进行微调和迁移学习。这些工具支持各种常见的NLP任务,如文本分类、命名实体识别、情感分析等。
HuggingFace的主要库为:
- Transformer模型库: 调用各类预训练模型
- Datasets数据集库: 数据集使用
- Tokenizer分词库:分词工具
官方文档:https://huggingface.co/docs
1-2、安装
# 安装transformers和datasets包
pip install transformers -i https://mirror.baidu.com/pypi/simple
pip install datasets -i https://mirror.baidu.com/pypi/simple
二、Tokenizer分词库:分词工具
2-0、加载BertTokenizer:需要传入预训练模型的名字
from transformers import BertTokenizer
#加载预训练字典和分词方法
tokenizer = BertTokenizer.from_pretrained(
pretrained_model_name_or_path='bert-base-chinese', # 可选,huggingface 中的预训练模型名称或路径,默认为 bert-base-chinese
cache_dir=None, # 将数据保存到的本地位置,使用cache_dir 可以指定文件下载位置
force_download=False,
)
2-1、使用Tokenizer对句子编码:
sents = [
'选择珠江花园的原因就是方便。',
'笔记本的键盘确实爽。',
'房间太小。其他的都一般。',
'今天才知道这书还有第6卷,真有点郁闷.',
'机器背面似乎被撕了张什么标签,残胶还在。',
]
#编码两个句子
out = tokenizer.encode(
text=sents[0],
text_pair=sents[1], # 一次编码两个句子,若没有text_pair这个参数,就一次编码一个句子
#当句子长度大于max_length时,截断
truncation=True,
#一律补pad到max_length长度
padding='max_length', # 少于max_length时就padding
add_special_tokens=True,
max_length=30, # 指定最大长度为30。
return_tensors=None, # None表示不指定数据类型,默认返回list
)
print(out)
print(tokenizer.decode(out))
输出:开头是特殊符号 [CLS],两个句子中间用 [SEP] 分隔,句子末尾也是 [SEP],最后用 [PAD] 将句子填充到 max_length 长度
[101, 6848, 2885, 4403, 3736, 5709, 1736, 4638, 1333, 1728, 2218, 3221, 3175, 912, 511, 102, 5011, 6381, 3315, 4638, 7241, 4669, 4802, 2141, 4272, 511, 102, 0, 0, 0]
[CLS] 选 择 珠 江 花 园 的 原 因 就 是 方 便 。 [SEP] 笔 记 本 的 键 盘 确 实 爽 。 [SEP] [PAD] [PAD] [PAD]
2-2、使用增强Tokenizer对句子编码:
sents = [
'选择珠江花园的原因就是方便。',
'笔记本的键盘确实爽。',
'房间太小。其他的都一般。',
'今天才知道这书还有第6卷,真有点郁闷.',
'机器背面似乎被撕了张什么标签,残胶还在。',
]
#增强的编码函数
out = tokenizer.encode_plus(
text=sents[0],
text_pair=sents[1],
#当句子长度大于max_length时,截断
truncation=True,
#一律补零到max_length长度
padding='max_length',
max_length=30,
add_special_tokens=True,
#可取值tensorflow,pytorch,numpy,默认值None为返回list
return_tensors=None,
#返回token_type_ids
return_token_type_ids=True,
#返回attention_mask
return_attention_mask=True,
#返回special_tokens_mask 特殊符号标识
return_special_tokens_mask=True,
#返回offset_mapping 标识每个词的起止位置,这个参数只能BertTokenizerFast使用
#return_offsets_mapping=True,
#返回length 标识长度
return_length=True,
)
print(out) # 字典
print(tokenizer.decode(out['input_ids']))
输出:
{‘input_ids’: [101, 6848, 2885, 4403, 3736, 5709, 1736, 4638, 1333, 1728, 2218, 3221, 3175, 912, 511, 102, 5011, 6381, 3315, 4638, 7241, 4669, 4802, 2141, 4272, 511, 102, 0, 0, 0], ‘token_type_ids’: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0], ‘special_tokens_mask’: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1], ‘attention_mask’: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0], ‘length’: 30}
[CLS] 选 择 珠 江 花 园 的 原 因 就 是 方 便 。 [SEP] 笔 记 本 的 键 盘 确 实 爽 。 [SEP] [PAD] [PAD] [PAD]
指标详细解释:
- input_ids 就是编码后的词,即将句子里的一个一个词变为一个一个数字
- token_type_ids 第一个句子和特殊符号的位置是0,第二个句子的位置是1(含第二个句子末尾的 [SEP])
- special_tokens_mask 特殊符号的位置是1,其他位置是0
- attention_mask pad的位置是0,其他位置是1
- length 返回句子长度
2-3、批量编码单个句子:
sents = [
'选择珠江花园的原因就是方便。',
'笔记本的键盘确实爽。',
'房间太小。其他的都一般。',
'今天才知道这书还有第6卷,真有点郁闷.',
'机器背面似乎被撕了张什么标签,残胶还在。',
]
# 批量编码一个一个的句子
out = tokenizer.batch_encode_plus(
batch_text_or_text_pairs=[sents[0], sents[1]], # 批量编码,一次编码了两个句子(与增强的编码函数相比,就此处不同)
# 当句子长度大于max_length时,截断
truncation=True,
# 一律补零到max_length长度
padding='max_length',
max_length=15,
add_special_tokens=True,
# 可取值tf,pt,np,默认为返回list
return_tensors=None,
# 返回token_type_ids
return_token_type_ids=True,
# 返回attention_mask
return_attention_mask=True,
# 返回special_tokens_mask 特殊符号标识
return_special_tokens_mask=True,
# 返回offset_mapping 标识每个词的起止位置,这个参数只能BertTokenizerFast使用
# return_offsets_mapping=True,
# 返回length 标识长度
return_length=True,
)
print(out) # 字典
print(tokenizer.decode(out['input_ids'][0]))
输出:
{‘input_ids’: [[101, 6848, 2885, 4403, 3736, 5709, 1736, 4638, 1333, 1728, 2218, 3221, 3175, 912, 102], [101, 5011, 6381, 3315, 4638, 7241, 4669, 4802, 2141, 4272, 511, 102, 0, 0, 0]], ‘token_type_ids’: [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], ‘special_tokens_mask’: [[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1], [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1]], ‘length’: [15, 12], ‘attention_mask’: [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0]]}
[CLS] 选 择 珠 江 花 园 的 原 因 就 是 方 便 [SEP]
2-4、添加新词:
#获取字典
zidian = tokenizer.get_vocab()
#添加新词
tokenizer.add_tokens(new_tokens=['月光', '希望'])
#添加新符号
tokenizer.add_special_tokens({'eos_token': '[EOS]'}) # End Of Sentence
# 获取更新后的字典
zidian = tokenizer.get_vocab()
# 解码新词
#编码新添加的词
out = tokenizer.encode(
text='月光的新希望[EOS]',
text_pair=None,
#当句子长度大于max_length时,截断
truncation=True,
#一律补pad到max_length长度
padding='max_length',
add_special_tokens=True,
max_length=8,
return_tensors=None,
)
print(out)
print(tokenizer.decode(out))
输出:

2-5、AutoTokenizer与BertTokenizer的区别
AutoTokenizer是通用封装,根据载入预训练模型来自适应。
主要区别是:
-
自动选择模型类型: AutoTokenizer是一个自动选择适合任务的分词器的工具。它可以根据输入的预训练模型名称或模型类型自动选择对应的分词器。这使得在使用不同的模型时更加方便,而不需要手动指定分词器。例如,你可以使用AutoTokenizer.from_pretrained(“bert-base-uncased”),它将自动选择适合BERT模型的BertTokenizer。
-
具体模型的分词器: BertTokenizer是用于BERT模型的分词器,它是基于WordPiece分词算法的。它将输入的文本分割成小的单词单元(token),并为每个token分配一个唯一的ID。BertTokenizer还提供了其他有用的方法,如获取特殊token的ID(如[CLS]和[SEP]),将文本转换为模型所需的输入格式等。
-
支持更多模型类型: AutoTokenizer可以自动选择适合多种预训练模型的分词器,不仅限于BERT。它支持包括GPT、RoBERTa、XLNet等在内的各种模型。这使得你能够使用同一种工具在不同的模型之间进行切换和比较。
总的来说,AutoTokenizer是一个用于自动选择适合任务的分词器的工具,而BertTokenizer是专门用于BERT模型的分词器。AutoTokenizer提供了更大的灵活性和通用性,可以适用于多种不同的预训练模型。
三、Datasets数据集库: 数据集使用
3-1、数据集使用
Datasets数据集库: 数据集使用
- 数据下载到本地
- 直接从本地读取
- 数据集对应Hugging Face网站: https://huggingface.co/datasets.
# 1
from datasets import load_dataset
#加载数据
dataset = load_dataset(path='lansinuote/ChnSentiCorp')
#保存数据集到磁盘
dataset.save_to_disk(dataset_dict_path='./data/ChnSentiCorp')
# 2
#从磁盘加载数据
from datasets import load_from_disk
dataset = load_from_disk('./data/ChnSentiCorp')
问题:容易报错无法找到数据*ConnectionError: Couldn’t reach ‘seamew/ChnSentiCorp’ on the Hub (ConnectionError)*l
解决方法:打开网站https://huggingface.co/datasets/seamew/ChnSentiCorp获取数据。
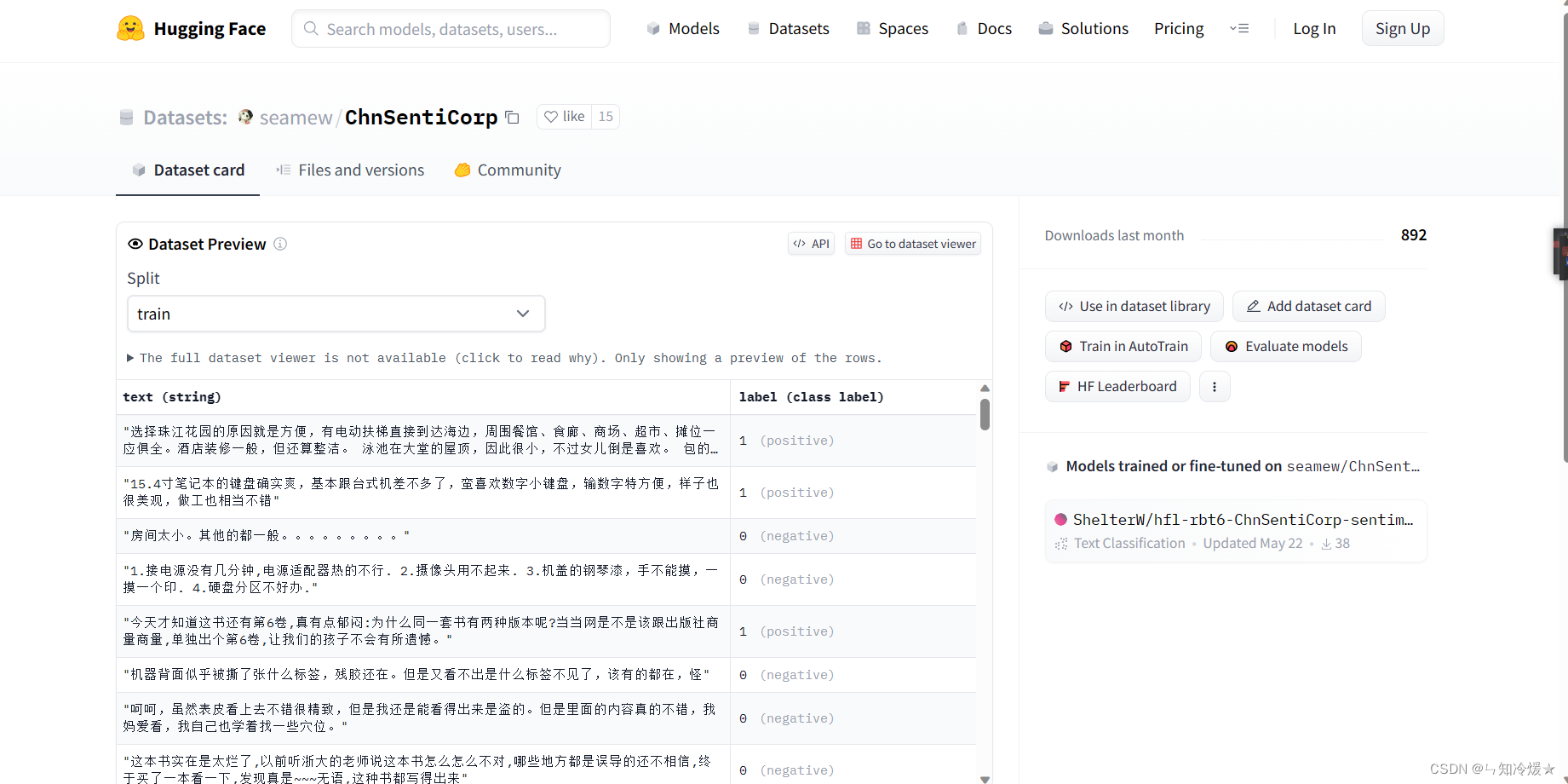
3-2、数据集操作
3-3、评价函数
查看所有的评价指标
from datasets import list_metrics
#列出评价指标
metrics_list = list_metrics()
print(metrics_list)
输出:
[‘accuracy’, ‘bertscore’, ‘bleu’, ‘bleurt’, ‘brier_score’, ‘cer’, ‘character’, ‘charcut_mt’, ‘chrf’, ‘code_eval’, ‘comet’, ‘competition_math’, ‘coval’, ‘cuad’, ‘exact_match’, ‘f1’, ‘frugalscore’, ‘glue’, ‘google_bleu’, ‘indic_glue’, ‘mae’, ‘mahalanobis’, ‘mape’, ‘mase’, ‘matthews_correlation’, ‘mauve’, ‘mean_iou’, ‘meteor’, ‘mse’, ‘nist_mt’, ‘pearsonr’, ‘perplexity’, ‘poseval’, ‘precision’, ‘r_squared’, ‘recall’, ‘rl_reliability’, ‘roc_auc’, ‘rouge’, ‘sacrebleu’, ‘sari’, ‘seqeval’, ‘smape’, ‘spearmanr’, ‘squad’, ‘squad_v2’, ‘super_glue’, ‘ter’, ‘trec_eval’, ‘wer’, ‘wiki_split’, ‘xnli’, ‘xtreme_s’, ‘AlhitawiMohammed22/CER_Hu-Evaluation-Metrics’, ‘BucketHeadP65/confusion_matrix’, ‘BucketHeadP65/roc_curve’, ‘Drunper/metrica_tesi’, ‘Felipehonorato/eer’, ‘He-Xingwei/sari_metric’, ‘JP-SystemsX/nDCG’, ‘Josh98/nl2bash_m’, ‘Kyle1668/squad’, ‘Muennighoff/code_eval’, ‘NCSOFT/harim_plus’, ‘Natooz/ece’, ‘NikitaMartynov/spell-check-metric’, ‘Pipatpong/perplexity’, ‘Splend1dchan/cosine_similarity’, ‘Viona/fuzzy_reordering’, ‘Viona/kendall_tau’, ‘Vipitis/shadermatch’, ‘Yeshwant123/mcc’, ‘abdusah/aradiawer’, ‘abidlabs/mean_iou’, ‘abidlabs/mean_iou2’, ‘andstor/code_perplexity’, ‘angelina-wang/directional_bias_amplification’, ‘aryopg/roc_auc_skip_uniform_labels’, ‘brian920128/doc_retrieve_metrics’, ‘bstrai/classification_report’, ‘chanelcolgate/average_precision’, ‘ckb/unigram’, ‘codeparrot/apps_metric’, ‘cpllab/syntaxgym’, ‘dvitel/codebleu’, ‘ecody726/bertscore’, ‘fschlatt/ner_eval’, ‘giulio98/codebleu’, ‘guydav/restrictedpython_code_eval’, ‘harshhpareek/bertscore’, ‘hpi-dhc/FairEval’, ‘hynky/sklearn_proxy’, ‘hyperml/balanced_accuracy’, ‘ingyu/klue_mrc’, ‘jpxkqx/peak_signal_to_noise_ratio’, ‘jpxkqx/signal_to_reconstruction_error’, ‘k4black/codebleu’, ‘kaggle/ai4code’, ‘langdonholmes/cohen_weighted_kappa’, ‘lhy/hamming_loss’, ‘lhy/ranking_loss’, ‘lvwerra/accuracy_score’, ‘manueldeprada/beer’, ‘mfumanelli/geometric_mean’, ‘omidf/squad_precision_recall’, ‘posicube/mean_reciprocal_rank’, ‘sakusakumura/bertscore’, ‘sma2023/wil’, ‘spidyidcccc/bertscore’, ‘tialaeMceryu/unigram’, ‘transZ/sbert_cosine’, ‘transZ/test_parascore’, ‘transformersegmentation/segmentation_scores’, ‘unitxt/metric’, ‘unnati/kendall_tau_distance’, ‘weiqis/pajm’, ‘ybelkada/cocoevaluate’, ‘yonting/average_precision_score’, ‘yuyijiong/quad_match_score’]
使用某个评价指标:
from datasets import load_metric
#加载一个评价指标
metric = load_metric('glue', 'mrpc')
#计算一个评价指标
predictions = [0, 1, 0]
references = [0, 1, 1]
final_score = metric.compute(predictions=predictions, references=references)
print(final_score)
四、模型
模型对应Hugging Face网站: https://huggingface.co/models.
4-1、各类NLP任务的常用模型
以下列举一些任务的常用模型:
文本分类:finbert、roberta-base-go_emotions、twitter-roberta-base-sentiment-latest
问答:roberta-base-squad2、xlm-roberta-large-squad2、distilbert-base-cased-distilled-squad
零样本分类:bart-large-mnli、mDeBERTa-v3-base-mnli-xnli
翻译:t5-base、 opus-mt-zh-en、translation_en-zh
总结:bart-large-cnn、led-base-book-summary
文本生成:Baichuan-13B-Chat、falcon-40b、starcoder
文本相似度:all-MiniLML6-v2、text2vec-large-chinese、all-mpnet-base-v2
五、实战案例分析
5-1、Kaggle竞赛 Real or Not? NLP with Disaster Tweets 文本分类
5-1-1、数据介绍
数据来源于:kaggle竞赛- Natural Language Processing with Disaster Tweets
任务:我们需要根据文章的location、keyword以及文本text来判断这篇推文是否和灾难有关,相关部门可以据此来第一时间发现可能存在的灾难并且迅速做出反应,将损失降低到最低。
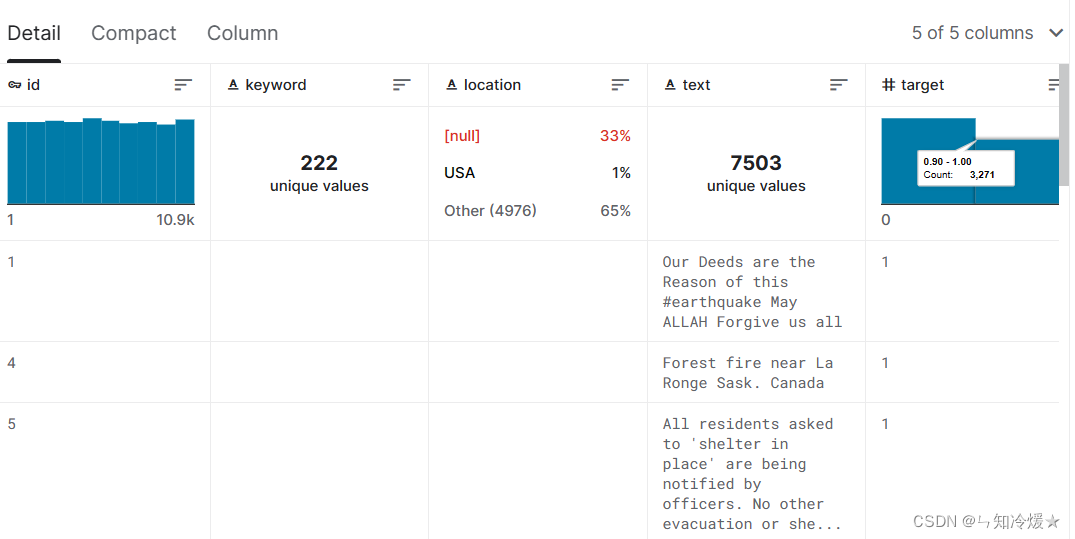
数据规模:Training Set Shape: (7613, 5); Test Set Shape: (3263, 4)
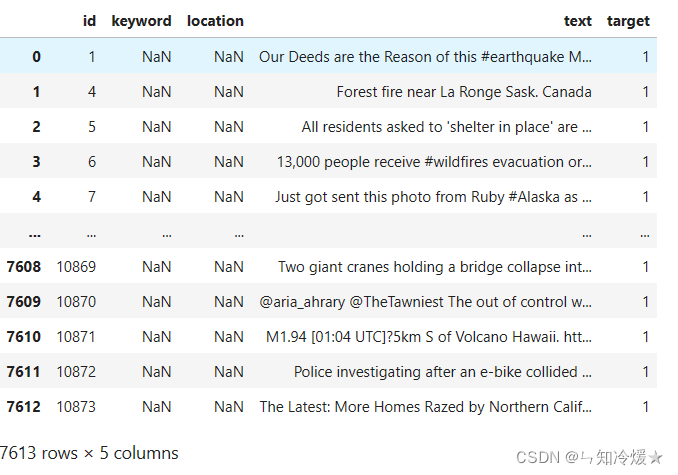
训练集:
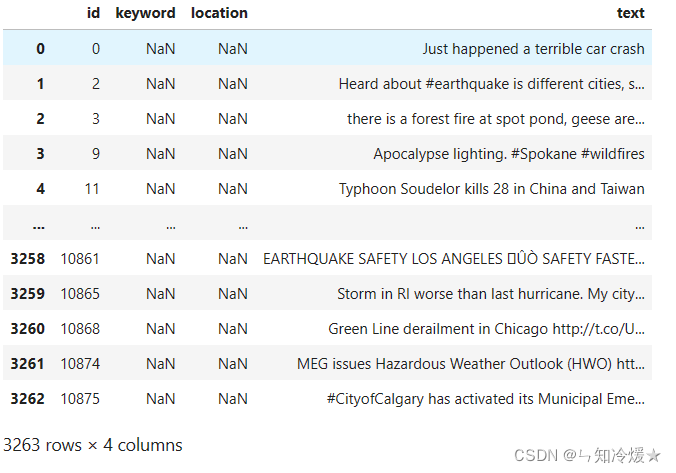
验证集:
其他事项:根据数据分析得知
- location这一列缺失值较多,直接摒弃
- keyword这一列缺失值很少,根据数据分析得知,keyword与标签之间有可见的强相关性。
- 标签分布均匀,我们可以直接拿来训练模型
参考文章:
HuggingFaceg官方GitHub.
HuggingFace快速上手(以bert-base-chinese为例).
NLP各类任务.
EDA探索式数据分析.
pytorch+huggingface实现基于bert模型的文本分类(附代码).
HuggingFace简明教程.
huggingface transformers预训练模型如何下载至本地,并使用?.
hugging face 模型库的使用及加载 Bert 预训练模型.
总结
只想要快乐。


![[javascript核心-08] V8 内存管理机制及性能优化](https://img-blog.csdnimg.cn/img_convert/81364972f4fea6cdac2ce1d20746b796.png)