最近接到一个接口自动化测试的case,并展开了一些调研工作,最后发现,使用pytest测试框架并以数据驱动的方式执行测试用例,可以很好的实现自动化测试。这种方式最大的优点在于后续进行用例维护的时候对已有的测试脚本影响很小。当然,pytest还有以下其他优点:
- 可以让用户写出更为紧凑的测试套件;
- 涉及到的样板代码并不多,因此用户能够容易地编写和理解各种测试;
- 测试夹具(fixture)函数常被用来向测试函数添加某个参数,并返回不同的值。在pytest中,可以通过使用一个fixture来模块化另外一个。同时也可以使用多个fixture,在无需重写测试用例的情况下,将测试覆盖到所有参数的组合;
- 可扩展性强,pytest有许多实用的插件。例如:pytest-xdist可以在不使用其他测试器的情况下,被用于执行并行测试;pytest-rerunfailures可以在测试失败后重新运行,而且运行次数和运行之间的延迟时间都是可以设置的;allure/pytest-html生成测试报告;
相比较其它的测试框架,比如Robot Framework(在创建自定义的HTML报告方面比较繁琐,顶多能用来生成xUnit格式的简短报告)、UniteTest/PyUnit(需要大量的样板代码),pytest更适合作为本次自动化测试的框架。
下面为大家详细的介绍这种自动化测试的实现过程。
1 前期的准备工作
1.1 接口路径表
根据接口文档,将接口的地址和路径以及请求方式记录在excel表中,key:接口名称,type:请求方式,value:接口路径,第一行baseurl为基本路径,type不填。接口名称建议与接口文档中的接口名称一致,这样方便检查。如果同一个接口有多种请求方式,需要重新填写一行,type为相对应的请求方式。这样记录接口路径和请求方式是为了方便后面的数据提取和处理。

1.2 测试用例表
测试用例表中主要记录9列类型的数据,测试模块:将接口按照模块进行划分有利于问题的定位和数据的分类;
- 测试模块:将被测接口按照功能进行模块划分;
- 用例编号:主要用于记录用例的条数,建议按照模块名称进行命名,如:登录模块,用例编号为login_001,login_002;
- 用例标题:记录测试的内容;
- 前置条件:当被测接口需要其他接口的数据支撑时,在前置条件栏中填入需要的接口数据:如:login_001:token(login_001指用例编号,token指该用例执行后返回的响应参数中token字段的值),前提条件是该接口用例在本条用例之前;
- 测试步骤:方便于模块用例的执行;
- 请求接口:按照接口路径表中key的命名填写,需要请求登录接口时,就填写上图中表中key命名的登录接口。请求头部:当请求头部中有特殊的参数时,比如该接口需要身份验证authorization字段,而该字段的数据来源于登录接口返回的token,这种用例的请求头部应该这样填写: Content-Type=application/json,Authorization=<token>;
- 请求数据:填写测试用例的请求数据,按照key=value的格式记录,如果需要其他接口的返回数据,在前置条件中加入之后,再填写请求数据中需要的返回数据即可,如:username =admin,password=zxcvbnm,token=<token>;
- 断言:根据接口返回的数据进行断言,主要是验证返回数据中的某个字段是否正确,也是按照key=value的格式进行填写;

2 目录结构及运行流程
2.1 文件目录结构
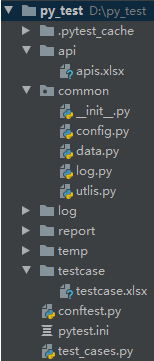
- testcase文件夹:存放测试用例表;
- api文件夹:存放接口路径表;
- common文件夹:common文件中存放通用的数据处理的脚本,如data.py和utlis.py(主要作用是将表中的数据进行处理,后面会进行详细的说明)、config.py(测试套件的基本配置);
- report文件夹:用于存放测试完成后生成的测试报告;
- conftest.py:属于pytest的一种全局公用的文件,一些通用的方法可以放在conftest.py中;
- pytest.ini:pytest的配置文件;
2.2 测试的运行流程
触发自动化测试之后,测试数据的提取与处理并不会使用到pytest框架,当把数据处理为测试套件后,按模块分配给pytest进行执行,包括测试模块、http请求、断言。所有模块执行完之后将测试结果体现在生成的测试报告report.html中。测试结束之后可以通过邮件或者钉钉机器人的方式通知测试或开发本次自动化测试的测试结果。

3 测试用例的实现过程
下面简单介绍一下测试用例实现过程中部分脚本的作用。
3.1 读取excel表
使用xlrd库读取excel表中的内容,python中还有很多可以对excel的数据进行操作的库,如:openpyxl、xlsxwriter;循环遍历每一行的数据,保存为列表并赋值给self.list_data。
# -*- coding: utf-8 -*-
import xlrd
class Excel(object):
def __init__(self, file_name):
# 读取excel
self.wb = xlrd.open_workbook(file_name)
self.sh = self.wb.sheet_names()
self.list_data = []
def read(self):
for sheet_name in self.sh:
sheet = self.wb.sheet_by_name(sheet_name)
rows = sheet.nrows
for i in range(0, rows):
rowvalues = sheet.row_values(i)
self.list_data.append(rowvalues)
3.2 将数据格式化成测试套件
第一步将表格数据保存为列表后,还不是我们需要的数据格式,这样的数据列表不能直接使用,这里进行了一次数据的格式化。这里需要用到config.py中的case_header的配置,将中文的标题换成英文,并作为字典的key值。之后从第1个元素开始循环遍历data,将data中每个元素都以 [{'key1': 'value1', 'key2': 'value2'}, {}, {}, ...]的形式保存为list_dict_data并返回。
def data_to_dict(data):
"""
:param data: data_list
:return:
"""
head = []
list_dict_data = []
for d in data[0]:
d = case_header.get(d, d)
head.append(d)
for b in data[1:]:
dict_data = {}
for i in range(len(head)):
if isinstance(b[i], str):
dict_data[head[i]] = b[i].strip()
else:
dict_data[head[i]] = b[i]
list_dict_data.append(dict_data)
return list_dict_data
case_header = {
'测试模块': 'module',
'用例编号': 'id',
'用例标题': 'title',
'前置条件': 'condition',
'测试步骤': 'step',
'请求接口': 'api',
'请求方式': 'method',
'请求头部': 'headers',
'请求数据': 'data',
'断言': 'assert',
'步骤结果': 'score' }
3.3 生成可执行的测试套件
上一步已经将数据处理成了[{'key1': 'value1', 'key2': 'value2'}, {}, {}, ...]这样的格式,但是发现这样的格式没有将模块中的用例整合到一起,列表中每一个元素都是单独的一条用例,这样的话不利于用例的执行,所以,对上一步返回的数据再进行一次处理。因为测试用例和接口路径是保存在两个excel表中的,所以需要将两个表的数据进行合并。首先将接口路径表中的数据读取出来并处理成需要的格式 {'key': {'type': 'value', 'url': 'value'}},之后按照测试步骤中的顺序把测试用例保存在steps字典中。由于代码过长,下面只展示核心部分。
for d in data:
# 将请求数据和断言数据格式化
for key in ('data', 'assert', 'headers'):
if d[key].strip():
test_data = dict()
for i in d[key].split(','):
i = i.split('=')
test_data[i[0]] = i[1]
d[key] = test_data
if d['module'].strip():
if testcase:
testsuite.append(testcase)
testcase = {}
testcase['module'] = d['module']
testcase['steps'] = []
no = str(d['step']).strip()
if no:
step = {'no': str(int(d['step']))}
for key in ('id', 'title', 'condition', 'api', 'headers', 'data', 'assert'):
if key == 'api':
step[key] = {'type': apis[d.get(key, '')]['type'],
'url': apis['baseurl']['url'] + apis[d.get(key, '')]['url']}
else:
step[key] = d.get(key, '')
testcase['steps'].append(step)
if testcase:
testsuite.append(testcase)
3.4 pytest执行测试套件
将http请求封装在了conftest.py中,使用pytest数据驱动的特点,在执行测试文件test_login。py中不需要import就可以直接调用。这里只展示了发起post请求的代码,其它类型的请求类似,pytest.fixture通过固定参数request传递数据。然后使用'标记'中的pytest.mark.parametrize进行参数化和数据驱动更灵活。在fixture中的方法里面准备测试数据和前置依赖方法,在测试方法中参数化,测试方法调用准备数据和前置方法。pytest.mark.parametrize('post_request', data, indirect=True),indirect=True是把post_request当作函数去执行,data则是前面生成的模块的测试用例,其中包括了发起\http请求所需要的所有参数。
@pytest.fixture()
def post_request(request):
data = request.param['data']
header = request.param['headers']
url = request.param['api']['url']
no = request.param['no']
logger.info(f'request: {data}')
response = requests.request('POST', url=url, headers=header, data=json.dumps(data))
logger.info(f'response: {response.json()}')
return response, no
# -*- coding: UTF-8 -*-
import pytest
import allure
from common.data import module_data
class TestCase(object):
@allure.feature('登录')
@pytest.mark.parametrize('post_request', module_data(module='登录'), indirect=True)
def test_login(self, post_request):
response = post_request[0].json()
no = int(post_request[1])
assert response['msg'] == module_data(module='登录')[no - 1]['assert']['msg']
def module_data(module):
excel = Excel(file_path.parent / 'testcase/testcase.xlsx')
excel.read()
cases = excel.list_data
test_suit = suite_cases(data_to_dict(cases))
for _ in test_suit:
if _['module'] == module:
data = _['steps']
return data
3.5 运行测试用例
可以在pytest.ini中配置执行测试时的一些文件、类、方法的匹配规则和常用的命令参数,执行时只需要命令行输入D:\py_test>pytest就可以开始执行自动化测试。也可以不用pytest.ini配置,命令行执行D:\py_test>pytest -s test_login.py --html=report/report.html,-s参数:输出所有测试用例的print信息,安装了pytest-html插件后,在执行命令中加入--html=测试报告保存路径。
pytest.ini文件配置如下:
[pytest]
# 打印print,生成保存报告
addopts = -s --html=report/report.html
# 匹配执行文件
python_files = test_*.py
# 匹配执行类
python_classes = Test*
# 匹配执行方法
python_functions = test_*
3.6 结果展示
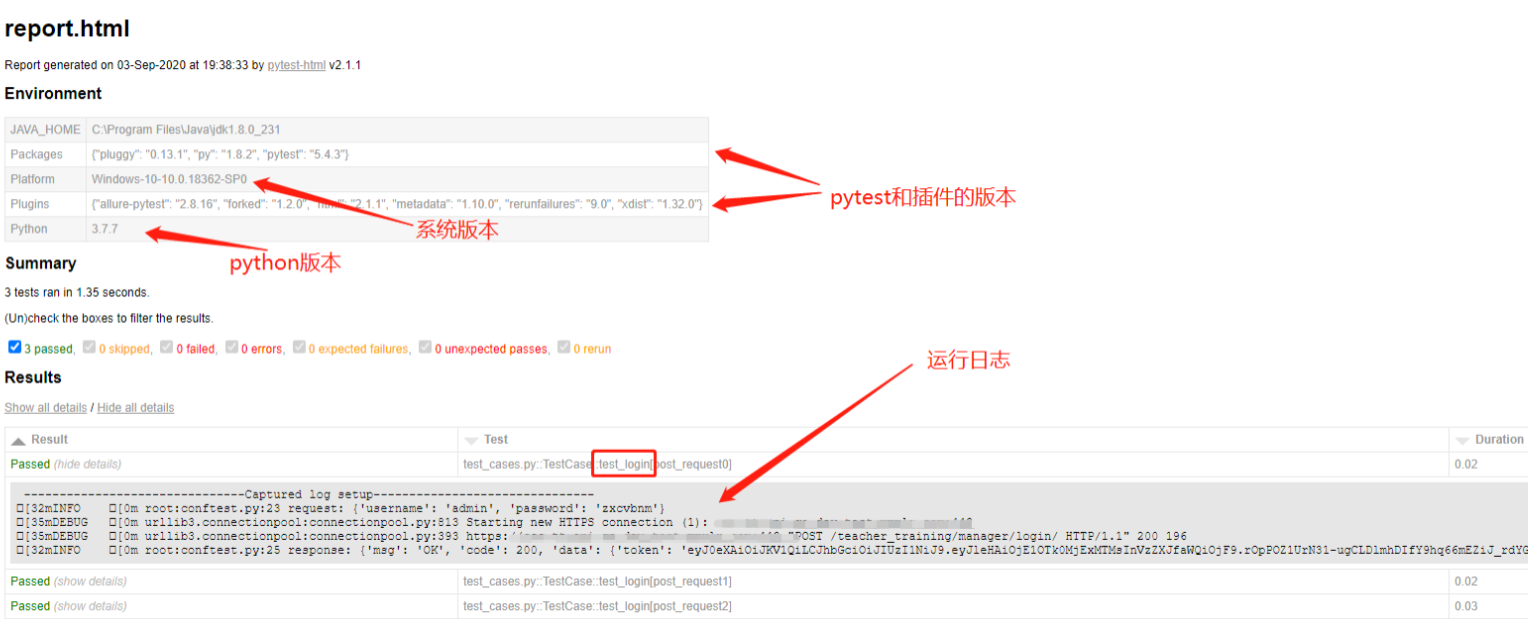
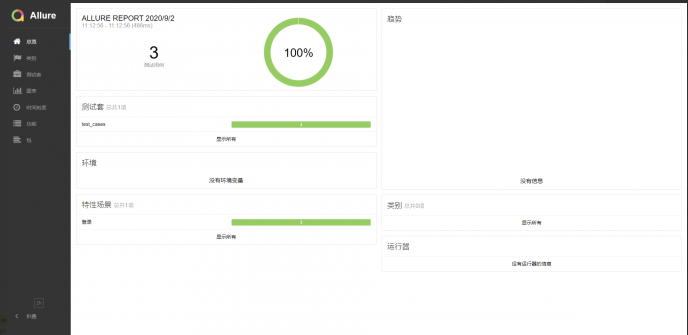
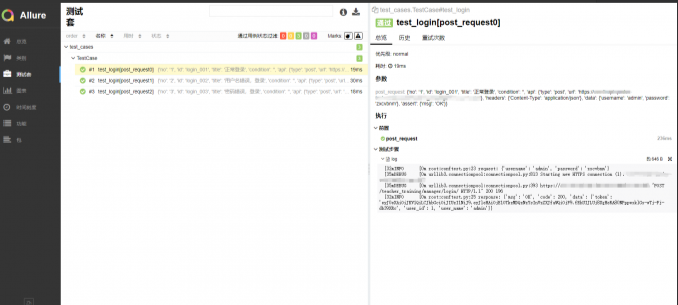
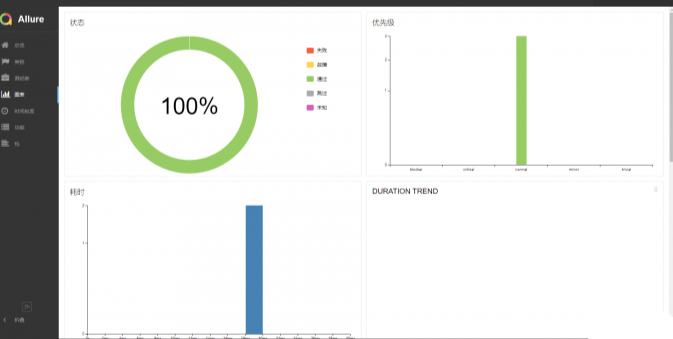
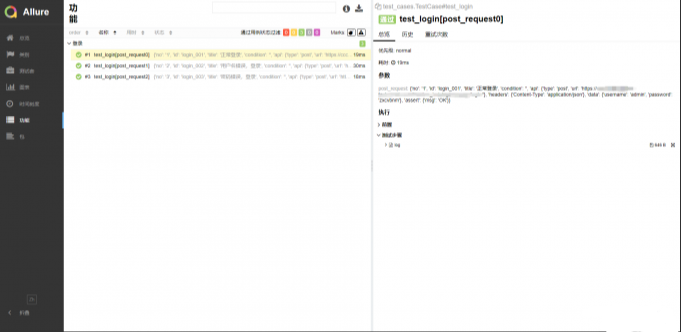
可以在ide中执行测试用例,也可以使用命令行执行,执行完测试用例后,会生成一个html格式的测试报告,在浏览器中打开就可以查看本次自动化测试的测试结果。pytest不仅支持pytest-html插件,还可以使用allure生成更加美观的测试报告。下面分别展示使用pytest-html和allure生成的html测试报告,pytest-html报告中记录的内容比较详尽,包括了用例运行日志、通过\失败\跳过用例条数、用例运行时间等等。allure生成的报告可读性比较强,可以很直观的看到测试结果。
pytest-html生成的测试报告:
allure生成的测试报告:
4 总结
整个项目完成之后,对pytest测试框架有了更深的理解。同时,pytest也可以使用Jenkins将自动化测试加入到持续集成中,设置定时任务构建或者条件触发构建等,这样可以有效的提高测试效率,也节省了人力成本。当然,不仅仅只有这一种实现方式,目前的实现方式还是有很多不足的地方,后面会继续进行完善和改进。
正在学习测试的小伙伴可以通过点击下面的小卡片