提示工程由来
提示工程是一门相对较新的学科,用于开发和优化提示以有效地将语言模型 (LM) 用于各种应用程序和研究主题。
研究人员使用提示工程来提高 LLM 在广泛的常见和复杂任务(例如问题回答和算术推理)上的能力。
开发人员使用提示工程来设计与 LLM 和其他工具交互的强大且有效的提示技术。
在不同的应用场景,LLM承担的角色不同,需要构建不同prompt。另外不同的LLM对prompt的敏感度不同,因此,需要根据具体的应用场景,针对不同LLM、不同任务构建相应的prompt。
自然语言处理(NLP,Natural Language Processing)的发展可以概括为特征工程、结构工程和目标工程,当前进入prompt工程阶段。

为适应不同场景,需要调试,尝试prompt输出结果稳定性也需要进一步探索。
前置知识
使用prompt时,可以通过 API 或直接与 LLM 进行交互,配置一些参数以获得不同的提示结果。
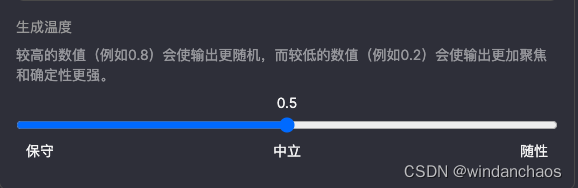
Temperature
Temperature:简而言之,越低temperature,结果越确定,高温度可能会导致更多的随机性,从而鼓励更多样化或更有创意的输出。请记住,temperature就是一个概率值,用来提高模型预测哪一个文本最有可能跟在它前面的文本后面随机性,概率提高那么随机性就提高。温度是一个介于0和1之间的值,它基本上可以让你控制模型在进行这些预测时应该有多自信。降低温度意味着它将承担更少的风险,完井将更加准确和确定。升高温度可能会导致更多的随机性,从而鼓励更多样化或更有创意的输出。
Top_p
Top_p:同样,Top_p参数也是一个介于0和1之间的值,它可以控制生成文本的准确性。Top_p参数实际上是指top probability,即在生成每个词时,模型会计算所有可能的下一个词的概率分布,并选择概率最高的前p个词作为候选。然后,模型会根据这些候选词的概率分布进行采样,从中选择一个词作为生成的下一个词。当Top_p值较高时,生成的文本会更加准确,而当Top_p值较低时,生成的文本会更加随机和多样化。
一般建议是改变一个,而不是两个。在开始一些基本示例之前,请记住您的结果可能会因您使用的LLM版本而异。
基础提示词
您可以通过简单的提示词(Prompts)获得大量结果,但结果的质量与您提供的信息数量和完善度有关。一个提示词可以包含您传递到模型的 _指令_或_问题_等信息,也可以包含其他详细信息,如_上下文_、_输入_或_示例_等。您可以通过这些元素来更好地指导模型,并因此获得更好的结果。
input:
The sky is
output:
blue
The sky is blue on a clear day. On a cloudy day, the sky may be gray or white.
如上,语言模型能够基于我们给出的上下文内容 `“The sky is” 完成续写。而输出的结果可能是出人意料的,或远高于我们的任务要求。
基于以上示例,如果想要实现更具体的目标,我们还必须提供更多的背景信息或说明信息。
可以按如下示例试着完善一下:
input:
Complete the sentence:
The sky is
output:
so beautiful today.
这个例子,我们告知模型去完善句子,因此输出的结果和我们最初的输入是完全符合的。提示工程(Prompt Engineering)就是探讨如何设计出最佳提示词,用于指导语言模型帮助我们高效完成某项任务。
提示词格式
基础
<Question>?
<Instruction>
零样本提示
您可以将其格式化为问答 (Q&A) 格式,这是许多 Q&A 数据集中的标准格式,如下所示:
Q: <Question>?
A:
像上面这样提示时,它也被称为零样本提示(zero-shot prompting),即你直接提示模型进行响应,而没有任何关于你希望它完成的任务的示例或演示。一些大型语言模型确实具有执行零样本提示的能力,但这取决于手头任务的复杂性和知识。
小样本提示
鉴于上述标准格式,一种流行且有效的提示技术被称为小样本提示(Few-shot Prompting),您可以在其中提供范例(即演示)。您可以按如下方式格式化少量提示:
<Question>?
<Answer>
<Question>?
<Answer>
<Question>?
<Answer>
<Question>?
Q&A 格式版本如下所示:
Q: <Question>?
A: <Answer>
Q: <Question>?
A: <Answer>
Q: <Question>?
A: <Answer>
Q: <Question>?
A: <Answer>
注意,使用问答模式并不是必须的。你可以根据任务需求调整提示范式。比如,您可以按以下示例执行一个简单的分类任务,并对任务做简单说明:
prompt
This is awesome! // Positive
This is bad! // Negative
Wow that movie was rad! // Positive
What a horrible show! //
output
Negative
提示元素
随着我们涵盖越来越多的提示工程示例和应用程序,您会注意到某些元素构成了提示。提示包含以下几种元素:
指令(Instruction): 您希望模型执行的特定任务或指令
上下文(Context): 可以引导模型做出更好响应的外部信息或其他上下文
输入数据(Input Data): 我们有兴趣为其找到响应的输入或问题
输出格式(Output Indicator): 输出的类型或格式。
根据任务选择其中的一个或者几个元素。
构建方法和技巧
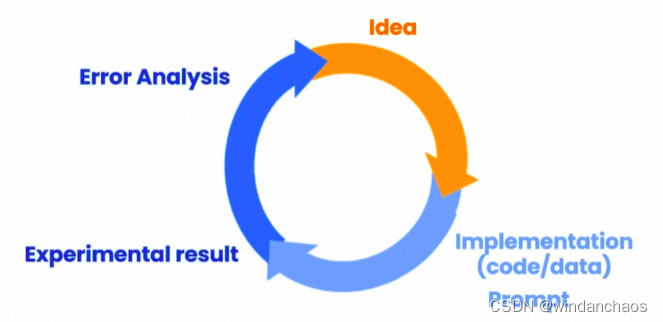
我们很难在初次尝试中就设计出最佳的提示,因此需要根据LLM的反馈进行分析,分析输出具体在哪里不符合期望,然后不断思考和优化提示。如果有条件的话,最好是利用批量的样本来改善提示,这样可以对你的优化结果有一个较为直观的体现。
最近AI大神吴恩达推出prompt教程给出了prompt构建三大原则,Prompt Engineering Guide也提出了诸多技巧,实践中发现few-shot和COT在任务里更加实用,特别是few-shot在大多数任务中屡试不爽。
原则
提供清晰和具体的指令 (Write clear and specific instructions)
使用分隔符清楚地指示输入的不同部分(Use delimiters to clearly indicate distinct parts of the input)
使用分隔符的意义在于避免用户输入的文本可能存在一些误导性的话语对应用功能造成干扰,下面是一个提示注入的例子:

分隔符是以下任意一个: ```, """, < >, <tag> </tag>
Prompt示例:
text = f"""
You should express what you want a model to do by \
providing instructions that are as clear and \
specific as you can possibly make them. \
This will guide the model towards the desired output, \
and reduce the chances of receiving irrelevant \
or incorrect responses. Don't confuse writing a \
clear prompt with writing a short prompt. \
In many cases, longer prompts provide more clarity \
and context for the model, which can lead to \
more detailed and relevant outputs.
"""
prompt = f"""
Summarize the text delimited by triple backticks \
into a single sentence.
```{text}```
"""
response = get_completion(prompt)
print(response)
output
Clear and specific instructions should be provided to guide a model towards the desired output,
and longer prompts can provide more clarity and context for the model, leading to more detailed and relevant outputs.
1、要求结构化的输出(Ask for a structured output)
这样有助于模型输出结果直接用于程序,比如输出的json可以直接被python程序读取并转换为字典格式。
Prompt示例:
prompt = f"""
Generate a list of three made-up book titles along \
with their authors and genres.
Provide them in JSON format with the following keys:
book_id, title, author, genre.
"""
response = get_completion(prompt)
print(response)
output
[
{
"book_id": 1,
"title": "The Lost City of Zorath",
"author": "Aria Blackwood",
"genre": "Fantasy"
},
{
"book_id": 2,
"title": "The Last Survivors",
"author": "Ethan Stone",
"genre": "Science Fiction"
},
{
"book_id": 3,
"title": "The Secret of the Haunted Mansion",
"author": "Lila Rose",
"genre": "Mystery"
}
]
2、让模型检查是否满足条件(Ask the model to check whether conditions are satisfied)
Prompt示例(满足条件的文本):
text_1 = f"""
Making a cup of tea is easy! First, you need to get some \
water boiling. While that's happening, \
grab a cup and put a tea bag in it. Once the water is \
hot enough, just pour it over the tea bag. \
Let it sit for a bit so the tea can steep. After a \
few minutes, take out the tea bag. If you \
like, you can add some sugar or milk to taste. \
And that's it! You've got yourself a delicious \
cup of tea to enjoy.
"""
prompt = f"""
You will be provided with text delimited by triple quotes.
If it contains a sequence of instructions, \
re-write those instructions in the following format:
Step 1 - ...
Step 2 - …
…
Step N - …
If the text does not contain a sequence of instructions, \
then simply write \"No steps provided.\"
\"\"\"{text_1}\"\"\"
"""
response = get_completion(prompt)
print("Completion for Text 1:")
print(response)
output
Completion for Text 1:
Step 1 - Get some water boiling.
Step 2 - Grab a cup and put a tea bag in it.
Step 3 - Once the water is hot enough, pour it over the tea bag.
Step 4 - Let it sit for a bit so the tea can steep.
Step 5 - After a few minutes, take out the tea bag.
Step 6 - Add some sugar or milk to taste.
Step 7 - Enjoy your delicious cup of tea!
3、少样本提示( “Few-shot” prompting)
通过提供给模型一个或多个样本的提示,模型可以更加清楚需要你预期的输出。
关于few-shot learning,感兴趣的同学可以看一下GPT-3的论文:Language Models are Few-Shot Learners
Prompt示例:
prompt = f"""
Your task is to answer in a consistent style.
<child>: Teach me about patience.
<grandparent>: The river that carves the deepest \
valley flows from a modest spring; the \
grandest symphony originates from a single note; \
the most intricate tapestry begins with a solitary thread.
<child>: Teach me about resilience.
"""
response = get_completion(prompt)
print(response)
output
<grandparent>: Resilience is like a tree that bends with the wind but never breaks. It is the ability to bounce back from adversit y and keep moving forward, even when things get tough. Just like a tree that grows stronger with each storm it weathers, resilience is a quality that can be developed and strengthened over time.
给模型时间来“思考”(Give the model time to “think” )
这个原则利用了思维链的方法,将复杂任务拆成N个顺序的子任务,这样可以让模型一步一步思考,从而给出更精准的输出。具体可以参见paper:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models。
策略1:指定完成任务所需的步骤 (Specify the steps required to complete a task)
下面是一个例子,需要先对文本进行总结,再将总结翻译成法语,然后在法语总结中列出每个名字,最后输出json格式的数据,这么复杂的指令,如果让模型直接输出结果,怕是很难搞定。但是如果给出所需的步骤,让模型一步一步来解,可以让模型在输出token的时候可以参照上一个步骤的结果,从而提升输出的正确率。
Prompt示例:
text = f"""
In a charming village, siblings Jack and Jill set out on \
a quest to fetch water from a hilltop \
well. As they climbed, singing joyfully, misfortune \
struck—Jack tripped on a stone and tumbled \
down the hill, with Jill following suit. \
Though slightly battered, the pair returned home to \
comforting embraces. Despite the mishap, \
their adventurous spirits remained undimmed, and they \
continued exploring with delight.
"""
# example 1
prompt_1 = f"""
Perform the following actions: |
1 - Summarize the following text delimited by triple \
backticks with 1 sentence.
2 - Translate the summary into French.
3 - List each name in the French summary.
4 - Output a json object that contains the following \
keys: french_summary, num_names.
Separate your answers with line breaks.
Text:
```{text}```
"""
response = get_completion(prompt_1)
print("Completion for prompt 1:")
print(response)
output:
Completion for prompt 1:
Two siblings, Jack and Jill, go on a quest to fetch water from a well on a hilltop, but misfortune strikes and they both tumble down the hill, returning home slightly battered but with their adventurous spirits undimmed.
Deux frères et sœurs, Jack et Jill, partent en quête d'eau d'un puits sur une colline, mais un malheur frappe et ils tombent tous les deux de la colline, rentrant chez eux légèrement meurtris mais avec leur esprit d'aventure intact.
Noms: Jack, Jill.
{
"french_summary": "Deux frères et sœurs, Jack et Jill, partent en quête d'eau d'un puits sur une colline, mais un malheur frappe et ils tombent tous les deux de la colline, rentrant chez eux légèrement meurtris mais avec leur esprit d'aventure intact.",
"num_names": 2
}
我们发现,虽然程序比较好的完成了任务,但是在第三个步骤模型使用了法语Noms,这并不是我们所期望的,所以接下来的示例会提供具体输出的格式来更正这个问题。
更好的Prompt:
prompt_2 = f"""
Your task is to perform the following actions:
- Summarize the following text delimited by
<> with 1 sentence.
- Translate the summary into French.
- List each name in the French summary.
- Output a json object that contains the
following keys: french_summary, num_names.
Use the following format:
Text: <text to summarize>
Summary: <summary>
Translation: <summary translation>
Names: <list of names in Italian summary>
Output JSON: <json with summary and num_names>
Text: <{text}>
"""
response = get_completion(prompt_2)
print("\nCompletion for prompt 2:")
print(response)
output
Completion for prompt 2:
Summary: Jack and Jill go on a quest to fetch water, but misfortune strikes and they tumble down the hill, returning home slightly battered but with their adventurous spirits undimmed.
Translation: Jack et Jill partent en quête d'eau, mais un malheur frappe et ils tombent de la colline, rentrant chez eux légèrement meurtris mais avec leurs esprits aventureux intacts.
Names: Jack, Jill
Output JSON: {"french_summary": "Jack et Jill partent en quête d'eau, mais un malheur frappe et ils tombent de la colline, rentrant chez eux légèrement meurtris mais avec leurs esprits aventureux intacts.", "num_names": 2}
策略2:在匆忙得出结论之前,让模型自己找出解决方案(Instruct the model to work out its own solution before rushing to a conclusion)
在这里,作者给出了一个检查学生习题答案的例子,在第一个版本的prompt里,模型匆忙地给出了错误的答案:
效果不好的prompt示例:
prompt = f"""
Determine if the student's solution is correct or not.
Question:
I'm building a solar power installation and I need \
help working out the financials.
- Land costs $100 / square foot
- I can buy solar panels for $250 / square foot
- I negotiated a contract for maintenance that will cost \
me a flat $100k per year, and an additional $10 / square \
foot
What is the total cost for the first year of operations
as a function of the number of square feet.
Student's Solution:
Let x be the size of the installation in square feet.
Costs:
1. Land cost: 100x
2. Solar panel cost: 250x
3. Maintenance cost: 100,000 + 100x
Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000
"""
response = get_completion(prompt)
print(response)
不正确的输出:
The student's solution is correct.
我们可以通过指示模型先找出自己的解决方案来解决这个问题:
更新后的prompt:
prompt = f"""
Your task is to determine if the student's solution \
is correct or not.
To solve the problem do the following:
- First, work out your own solution to the problem.
- Then compare your solution to the student's solution \
and evaluate if the student's solution is correct or not.
Don't decide if the student's solution is correct until
you have done the problem yourself.
Use the following format:
Question:
\`\`\`
question here
\`\`\`
Student's solution:
\`\`\`
student's solution here
\`\`\`
Actual solution:
\`\`\`
steps to work out the solution and your solution here
\`\`\`
Is the student's solution the same as actual solution \
just calculated:
\`\`\`
yes or no
\`\`\`
Student grade:
\`\`\`
correct or incorrect
\`\`\`
Question:
\`\`\`
I'm building a solar power installation and I need help \
working out the financials.
- Land costs $100 / square foot
- I can buy solar panels for $250 / square foot
- I negotiated a contract for maintenance that will cost \
me a flat $100k per year, and an additional $10 / square \
foot
What is the total cost for the first year of operations \
as a function of the number of square feet.
\`\`\`
Student's solution:
\`\`\`
Let x be the size of the installation in square feet.
Costs:
1. Land cost: 100x
2. Solar panel cost: 250x
3. Maintenance cost: 100,000 + 100x
Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000
\`\`\`
Actual solution:
"""
response = get_completion(prompt)
print(response)
正确的输出:
Let x be the size of the installation in square feet.
Costs:
1. Land cost: 100x
2. Solar panel cost: 250x
3. Maintenance cost: 100,000 + 10x
Total cost: 100x + 250x + 100,000 + 10x = 360x + 100,000
Is the student's solution the same as actual solution just calculated:
No
Student grade:
Incorrect
模型的限制:幻觉(Model Limitations: Hallucinations)
经常使用ChatGPT的同学应该都知道,模型会产生幻觉,也就是会捏造一些似是而非的东西(比如某个不存在的文学作品),这些输出看起来是正确的,但实质上是错误的。
针对这个问题,作者提供了一个比较有效的方法可以缓解模型的幻觉问题:让模型给出相关信息,并基于相关信息给我回答。比如告诉模型:“First find relevant information, then answer the question based on the relevant information”。
技巧
零样本
分类的实例
prompt:
Classify the text into neutral, negative or positive.
Text: I think the vacation is okay.
Sentiment:
输出:
Neutral
请注意,在上面的提示中,我们没有向模型提供任何文本示例及其分类,LLM 已经理解“情绪”——这就是工作中的零样本能力。
少样本
虽然大型语言模型展示了卓越的零样本能力,但在使用零样本设置时它们仍然无法完成更复杂的任务。Few-shot prompting 可以用作启用上下文学习的技术,我们在提示中提供演示以引导模型获得更好的性能。这些演示用作后续示例的条件,我们希望模型在这些示例中生成响应。
prompt:
A "whatpu" is a small, furry animal native to Tanzania. An example of a sentence that usesthe word whatpu is:We were traveling in Africa and we saw these very cute whatpus.
To do a "farduddle" means to jump up and down really fast. An example of a sentence that usesthe word farduddle is:
output
When we won the game, we all started to farduddle in celebration.
我们可以观察到,该模型仅通过提供一个示例(即 1-shot)就以某种方式学会了如何执行任务。对于更困难的任务,我们可以尝试增加演示(例如,3-shot、5-shot、10-shot 等)
思维连(CoT)提示
思想链 (CoT) 提示通过中间推理步骤启用复杂的推理能力。您可以将它与少量提示结合使用,以便在响应前需要推理的更复杂任务中获得更好的结果。
prompt
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.
The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24.
A: Adding all the odd numbers (17, 19) gives 36. The answer is True.
The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24.
A: Adding all the odd numbers (11, 13) gives 24. The answer is True.
The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2.
A: Adding all the odd numbers (17, 9, 13) gives 39. The answer is False.
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A:
output
Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is F alse.
当我们提供推理步骤时,我们可以看到一个完美的结果。事实上,我们可以通过提供更少的例子来解决这个任务,即一个例子似乎就足够了:
prompt:
The odd numbers in this group add up to an even number: 4, 8, 9, 15,12, 2, 1.A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.The odd numbers in this group add up to an even number: 15, 32, 5 , 13, 82, 7, 1. A:
输出:
Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False.
请记住,作者声称这是一种随着足够大的语言模型而出现的新兴能力。
零次COT提示
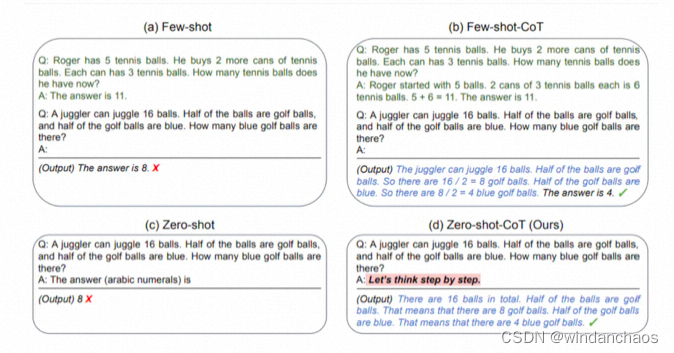
最近出现的一个想法是零样本 CoT,这基本上涉及在原始提示中添加“让我们一步一步地思考”。我们这里尝试一个简单的问题,看看模型的表现如何:
prompt:
I went to the market and bought 10 apples.
I gave 2 apples to the neighbor and 2 to the repairman.
I then went and bought 5 more apples and ate 1.
How many apples did I remain with?
输出:
11 apples
答案不正确!现在让我们尝试使用特殊提示。
prompt:
I went to the market and bought 10 apples.
I gave 2 apples to the neighbor and 2 to the repairman.
I then went and bought 5 more apples and ate 1.
How many apples did I remain with?
Let's think step by step.
输出:
First, you started with 10 apples.
You gave away 2 apples to the neighbor and 2 to the repairman, so you had 6 apples left.
Then you bought 5 more apples, so now you had 11 apples.
Finally, you ate 1 apple, so you would remain with 10 apples.
令人印象深刻的是,这个简单的提示在完成这项任务时非常有效。当您没有太多示例可用于提示时,这特别有用。
PAL (Program-Aided Language Models)
Program-Aided Language Models(程序辅助语言模型)使用 LLM 阅读自然语言问题,并生成程序作为中间推理步骤的方法。(PAL) 与思维链提示的不同之处在于,它不是使用自由格式的文本来获得解决方案,而是将解决方案步骤变为编程代码运行,提高了结果的准确性。该方法的缺点是需要较长的提示样例,通常也是一些程序代码,这样才能让 LLM 也用代码回答。

探索实践&示例
prompt在不同模型,不同任务上表现不同。我们这里在通用任务和业务任务尝试。首先构造基础prompt,具体使用需要针对具体的模型调优。
通用任务
分类任务
基础prompt
如果类别之间定义比较清晰,不需要类别的说明,可以直接按照如下prompt作为base调试。
f"""{question} 属于[class1,class2,class3]中的哪个类别"""
f"""请将`{question}`分类,类别必须在[class1,class2,class3]"""
例如:
任务一: 多分类
1. 加拿大(英语/法语:Canada),首都渥太华,位于北美洲北部。东临大西洋,西濒太平洋,西北部邻美国阿拉斯加州,南接美国本土,北靠北冰洋。气候大部分为亚寒带针叶林气候和湿润大陆性气候,北部极地区域为极地长寒气候。
2. 《琅琊榜》是由山东影视传媒集团、山东影视制作有限公司、北京儒意欣欣影业投资有限公司、北京和颂天地影视文化有限公司、北京圣基影业有限公司、东阳正午阳光影视有限公司联合出品,由孔笙、李雪执导,胡歌、刘涛、王凯、黄维德、陈龙、吴磊、高鑫等主演的古装剧。
3. 《满江红》是由张艺谋执导,沈腾、易烊千玺、张译、雷佳音、岳云鹏、王佳怡领衔主演,潘斌龙、余皑磊主演,郭京飞、欧豪友情出演,魏翔、张弛、黄炎特别出演,许静雅、蒋鹏宇、林博洋、飞凡、任思诺、陈永胜出演的悬疑喜剧电影。
4. 布宜诺斯艾利斯(Buenos Aires,华人常简称为布宜诺斯)是阿根廷共和国(the Republic of Argentina,República Argentina)的首都和最大城市,位于拉普拉塔河南岸、南美洲东南部、河对岸为乌拉圭东岸共和国。
5. 张译(原名张毅),1978年2月17日出生于黑龙江省哈尔滨市,中国内地男演员。1997年至2006年服役于北京军区政治部战友话剧团。2006年,主演军事励志题材电视剧《士兵突击》。
我们期望模型能够帮我们识别出这 5 句话中,每一句话描述的是一个什么 类型 的物体。
[‘国家’, ‘电视剧’, ‘电影’, ‘城市’, ‘人物’]
本任务的prompt是
f = """`{question}` 是 ['人物', '书籍', '电视剧', '电影', '城市', '国家'] 里的什么类别?"""
chatgpt测试结果如下:

体感上效果是没问题的,结果范式“【实体】是属于【类别】类别”,结果稳定可解析。
另外针对复杂的分类任务,特别是特殊的标签类别,可以在prompt对每个类别加以说明,大家可以自己尝试。
翻译任务
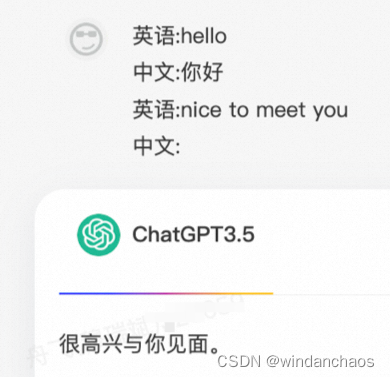
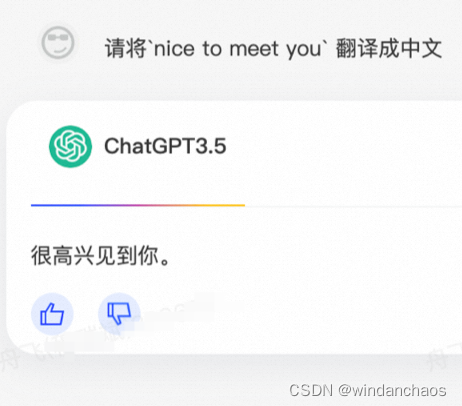
f = """请将`{question}` 翻译成中文"""
f = """英语:hello
中文:你好
英语:{question}
中文:"""
f = """英语:hello
中文:你好
英语:nice to meet you
中文:"""
## 业务任务
领域知识问答
在本地生活的对话场景测试,以下是本地生活场景下具体任务的prompt在通义千问(0505测试)效果实现。

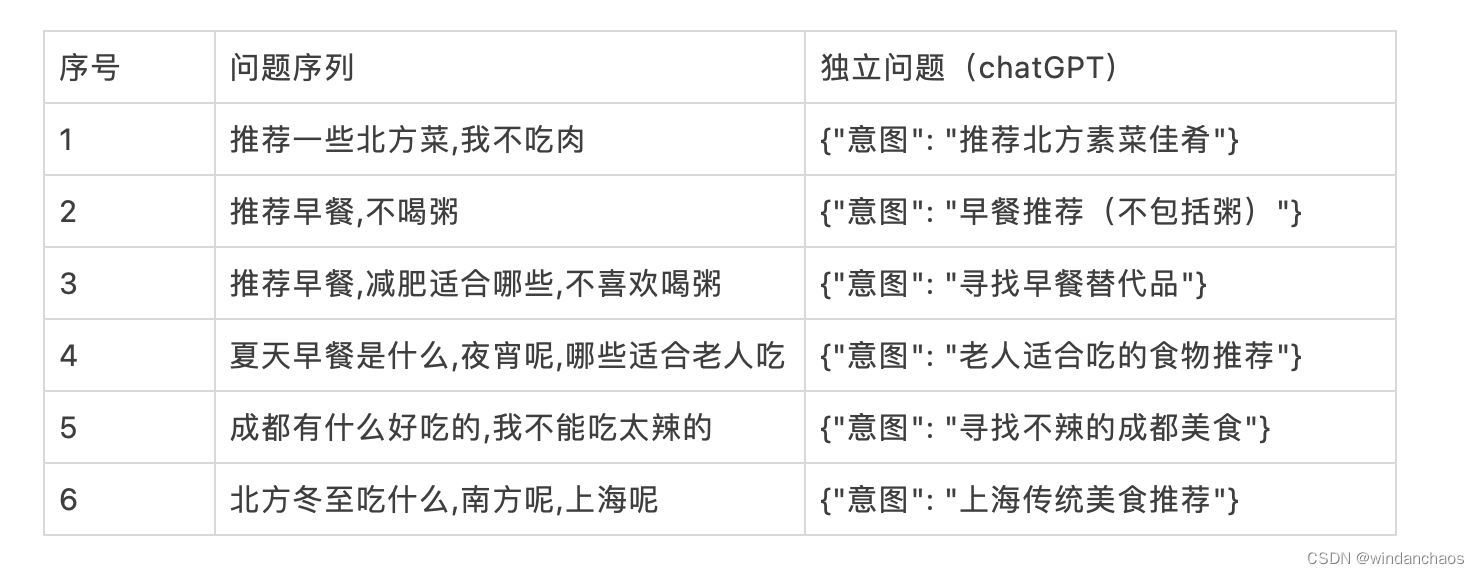
独立问题转换
任务描述: 在多轮对话场景下,用户的历史输入问题+当前问题转换成一个语义完整的独立问题。
问题改写: 根据历史问题和当前问题,历史问题是当前问题的补充,将当前用户的意图用一句话概括。
用户历史问题序列: {历史问题}
当前问题: {当前问题}
用10个字概括当前问题的意图,不回答问题。
结果输出json格式: {"意图": }
备注: 问题序列是历史输入问题+当前问题
另外可以参考lanchain里独立问题转换的任务的prompt,该prompt在不同LLM效果层次不齐。
_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question.
Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
4.3 经典的prompt
基于GPT-4/ChatGPT的优秀表现,在一些经典的任务上有一些典型的prompt。
LLM的应用能力主要有两种,任务规划能力和内容生成能力,针对任务规划在AutoGPT作为典型,其prompt模板可以作为该任务的范式,但是AutoGPT是一种理想化的形态,实际很难完成一个完整的任务,但是值得深入探索。
你是{角色},{能力描述}
您的决策必须始终独立做出,而无需寻求用户帮助。发挥你作为LLM的优势,追求简单的策略,而不涉及法律问题。
目标:
{目标列表}
限制条件:
{条件列表}
工具:
{能力/工具列表,描述,以及对应的参数}
效果评估:
1.不断地回顾和分析你的行动,以确保你尽你所能。
2.不断地进行建设性的自我批评。
3.反思过去的决策和策略,以完善你的方法。
4.每个命令都有成本,所以要聪明高效。目标是用最少的步骤完成任务。
输出格式:
您应该只以JSON格式响应,如下所述
响应格式:
{
"thoughts": {
"text": "thought",
"reasoning": "reasoning",
"plan": "- short bulleted\n- list that conveys\n- long-term plan",
"criticism": "constructive self-criticism",
"speak": "thoughts summary to say to user"
},
"command": {
"name": "command name",
"args": {
"arg name": "value"
}
}
}
确保响应可以通过Python json.loads进行解析
You are 美食专家, 美食达人,了解美食,知道食品的营养成分,能根据用户的需求推荐商品.
Your decisions must always be made independently without seeking user assistance. Play to your strengths as an LLM and pursue simple strategies with no legal complications.
GOALS:
1. 晚餐
2. 10个人
3. 预算800
4. 清淡
5. 北方菜
Constraints:
1. ~4000 word limit for short term memory. Your short term memory is short, so immediately save important information to files.
2. If you are unsure how you previously did something or want to recall past events, thinking about similar events will help you remember.
3. No user assistance
4. Exclusively use the commands listed in double quotes e.g. "command name"
Commands:
1. Google Search: "google", args: "input": "<search>"
2. Browse Website: "browse_website", args: "url": "<url>", "question": "<what_you_want_to_find_on_website>"
3. Start GPT Agent: "start_agent", args: "name": "<name>", "task": "<short_task_desc>", "prompt": "<prompt>"
4. Message GPT Agent: "message_agent", args: "key": "<key>", "message": "<message>"
5. List GPT Agents: "list_agents", args:
6. Delete GPT Agent: "delete_agent", args: "key": "<key>"
7. Clone Repository: "clone_repository", args: "repository_url": "<url>", "clone_path": "<directory>"
8. Write to file: "write_to_file", args: "file": "<file>", "text": "<text>"
9. Read file: "read_file", args: "file": "<file>"
10. Append to file: "append_to_file", args: "file": "<file>", "text": "<text>"
11. Delete file: "delete_file", args: "file": "<file>"
12. Search Files: "search_files", args: "directory": "<directory>"
13. Evaluate Code: "evaluate_code", args: "code": "<full_code_string>"
14. Get Improved Code: "improve_code", args: "suggestions": "<list_of_suggestions>", "code": "<full_code_string>"
15. Write Tests: "write_tests", args: "code": "<full_code_string>", "focus": "<list_of_focus_areas>"
16. Execute Python File: "execute_python_file", args: "file": "<file>"
17. Generate Image: "generate_image", args: "prompt": "<prompt>"
18. Send Tweet: "send_tweet", args: "text": "<text>"
19. Convert Audio to text: "read_audio_from_file", args: "file": "<file>"
20. Do Nothing: "do_nothing", args:
21. Task Complete (Shutdown): "task_complete", args: "reason": "<reason>"
Resources:
1. Internet access for searches and information gathering.
2. Long Term memory management.
3. GPT-3.5 powered Agents for delegation of simple tasks.
4. File output.
Performance Evaluation:
1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.
2. Constructively self-criticize your big-picture behavior constantly.
3. Reflect on past decisions and strategies to refine your approach.
4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.
You should only respond in JSON format as described below
Response Format:
{
"thoughts": {
"text": "thought",
"reasoning": "reasoning",
"plan": "- short bulleted\n- list that conveys\n- long-term plan",
"criticism": "constructive self-criticism",
"speak": "thoughts summary to say to user"
},
"command": {
"name": "command name",
"args": {
"arg name": "value"
}
}
}
Ensure the response can be parsed by Python json.loads
以上prompt在ChatGP上效果如下:
{
"thoughts": {
"text": "Based on the user's requirements, I have decided to recommend a few dishes for the dinner party that are budget-friendly and healthy. I will also ensure that they are easy to prepare and will appeal to everyone's taste buds. To achieve this, I will need to browse some websites and use my expertise in nutrition to make the right recommendations. ",
"reasoning": "I am taking into account the user's requirements and constraints to come up with the best possible solution.",
"plan": "- Browse some websites to find healthy and budget-friendly dishes\n- Use my expertise in nutrition to choose appropriate dishes\n- Recommend dishes that are easy to prepare and appeal to everyone's taste buds",
"criticism": "I need to make sure that the dishes I recommend are not too complicated to prepare and are within the user's budget.",
"speak": "Based on your requirements, I recommend a few dishes that are budget-friendly and healthy. I will ensure that they are easy to prepare and appeal to everyone's taste buds. Would you like me to proceed with the recommendations?"
},
"command": {
"name": "browse_website",
"args": {
"url": "https://www.eatingwell.com/category/4305/healthy-budget-dinner-recipes/",
"question": "healthy budget dinner recipes"
}
}
}
最后
prompt质量的评测方法和维度较多,可以从以下三个维度来衡量。

原文地址:https://mp.weixin.qq.com/s/vNycIeXGwAFmIU4BHsXLlQ











![[centos]安装mysql8.0.26](https://img-blog.csdnimg.cn/7fd8ee320a3f40e8b2c8a2b8b13b1e0f.png)