预测道路参与者的future behavior.
摘要
- 将输入由dense image-based encoding改为a sparse encoding of heterogeneous scene elements.
即用polylines(折现)来描述road features和原始的agent state information(例如位置、速度和加速度)。
主要方法是对这些元素进行a context-aware fusion,然后开发一个可重复使用的(reusable) multi-context gating fusion组件. - 重新考虑预定义的、静态的anchors的选择,使得模型可以端到端学习latent anchor embeddings.
- ensemble和output aggregation技术,寻找effective概率的多模型输出表达
Introduction
目前在自动驾驶中,对human agents建模和预测有以下难点:
- Multimodal output space: 未来环境的不可知性,使得模型必须可以表达rich output space.
- Heterogenous, interrelated(相互关联的) input space:动静态混合输入,包括道路信息、交通灯、agents的历史状态. 驾驶是高度交互的,可以有很多agent.
MultiPath的光栅化的方法有如下缺点:
- 空间网格的分辨率、视野和计算要求三者的trade-off.
- 这是个人工特征工程,一些特征内在的不适合,例如径向速度(radial velocity)
- 小的卷积视野很难获取长距离的交互。
- 信息是系数的,dense表达是潜在浪费的.
MultiPath++比MultiPath有如下改进:
- 避开光栅化+CNN的方法,将road元素表示为折现(polylines),agent的历史信息保存为一个RNN编码的序列,agent交互为与本车相邻的状态的RNNs. 避免了荣誉的光栅化
- 获取road和agent之间的关系很重要,将所有road element交互地编码效果会更好,因此提出multi-context gating(MCG).
- 探索轨迹建模。比较基于动力学控制和连续时间地多项式
- 在miss-rate(MR)和mAP上得到提升.
- 在Waymo Open Motion Dataset上第一,在Argoverse Motion Forecating上第4.
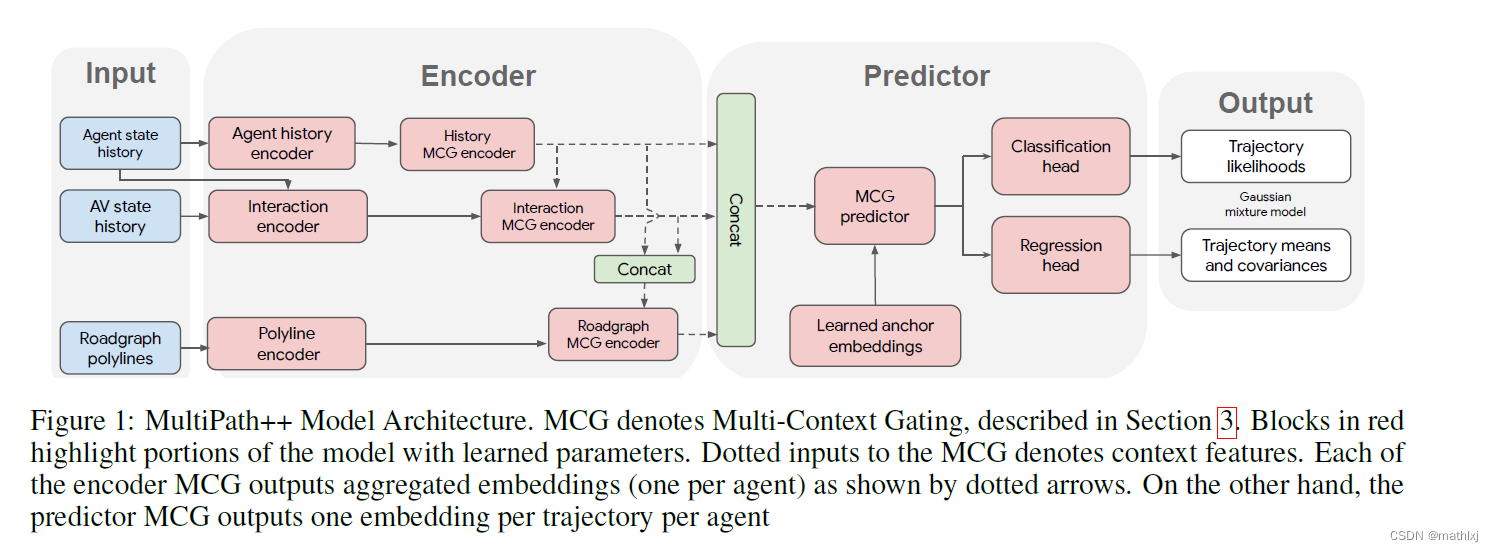
3.1 输入表达
- Agent state history: 一个state sequence, 固定past steps. 坐标系: agent-centric坐标系,最近的agent pose在原点,朝向东.
- 在Waymo数据集中,包括位置、速度、3D框的大小、朝向角和目标类型.
- Argoverse数据集,仅有位置信息.
- Road network:路网例如车道线、人行道、停止线,表达为参数曲线。进一步通过对每个road element 近似点序列作为线性/多项式的a set of piecewise.
- Agent interactions:对于每个agent,考虑其所有邻居agent. 对于每个邻居,考虑agent坐标系下的坐标系. 例如相对朝向、相对距离、历史和速度
- AV-relative features: 提取自动驾驶车辆相对于其它agent的features,
3.2 Multi Context Gating for fusing modalities
MCG满足:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QRfQg1R0-1670638818528)(:/065b5969e0f84f7f88db1037806f9228)]](https://img-blog.csdnimg.cn/5818ec9331fb4875bb4926bc1246801e.png)
s
1
:
N
s_{1:N}
s1:N作为elements的集合
置换之后,input context vector
c
c
c不变, 输出为输入的置换.
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Hm9DYGTA-1670638818529)(:/4c46ada762134c239382a9136b29c3cd)]](https://img-blog.csdnimg.cn/7cafe96c61c84563a3b3ea9da6d20ddc.png)
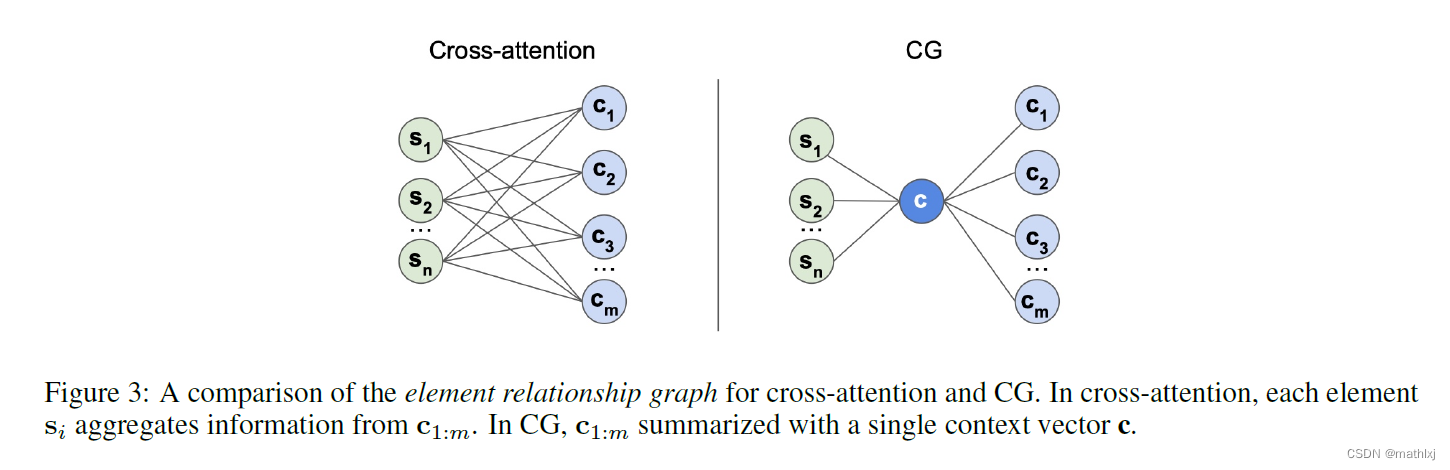
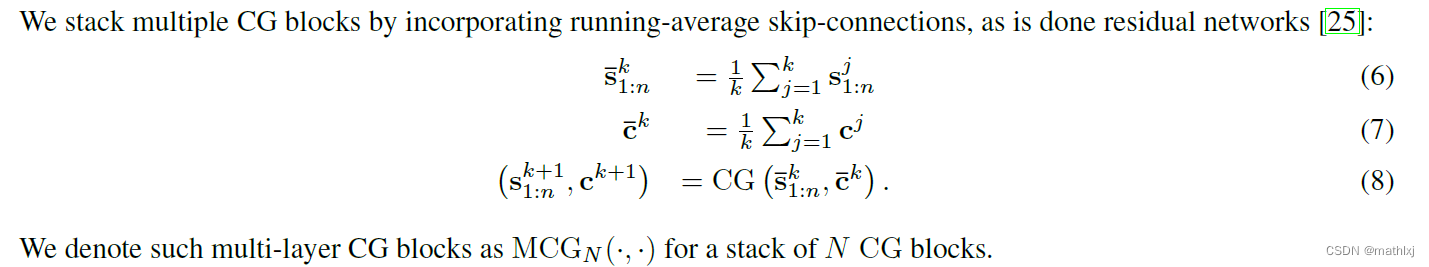
3.3 Encoders
-
Agent history encoding. encode由以下三个向量concat
- 对历史features作用于LSTM,从历史时间T到当前
- LSTM到相邻feature之差
- frame_id: one-hot; MCG blocks运用到这些历史的elements,每个element的包含历史位置和time offset(以秒为单位)相对于当前时间
-
Agent interaction encoding:
考虑每个相邻agent v v v的历史观测
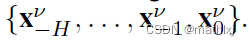
将第 v v v个状态转到当前建模agent的坐标系,使用LSTM来获取一个embedding.
获取一系列交互embeddings后,使用MCG进行融合:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ymMBjwsg-1670638818535)(:/99cf1521f7d24b60acf0bb7ec8b82f18)]](https://img-blog.csdnimg.cn/ec50043f0f6e4dc7a5be6372db4e0844.png)
- 路网encoding: 折现road element表达, 每个线由start point, end point和road element semantic type
γ
\gamma
γ表示(例如十字路口、黄实双线),对于每个agent,选取最近的P=128个折线,转换到agent的坐标系,即转换之后的segment
p
=
(
a
,
b
)
p=(a,b)
p=(a,b). 对于每个segment, 寻找距离每个segment上最近的点,还有计算a点处的垂线. 表示agent空间关系由如下相邻:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5MHuEacC-1670638818537)(:/0193bd9d3c804347836bbde152acce17)]](https://img-blog.csdnimg.cn/b6648a4bca464a88bf899d1cda8dd639.png)
MCG融合road element embeddings和agent history embedding:
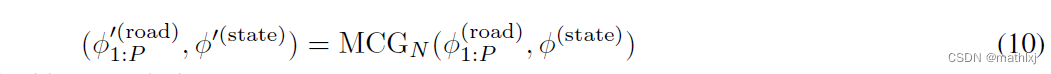
3.4 输出表达
每条轨迹的高斯分布
(
x
,
y
)
(x,y)
(x,y),
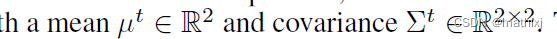
M
M
M个混合,
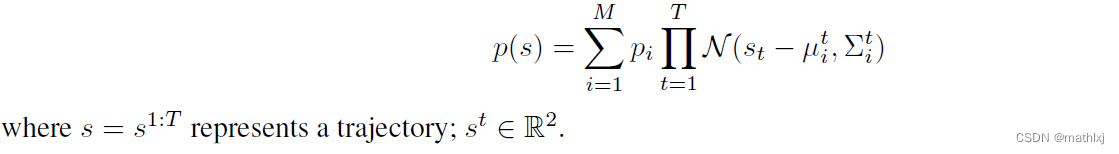
3.5 Prediction architecture with learned anchor embeddings
预测模块预测GMM的参数,namely M M M个轨迹,每个点附近有似然和不确定性.
将学习anchor embeddings作为全局模型训练的一部分,将这些embeddings作为在隐藏空间的anchors. 建立这些embedding到GMM输出轨迹的一对一对应.
将MCG输出的embeddings整合,获得固定长度的特征向量,
就是MLP
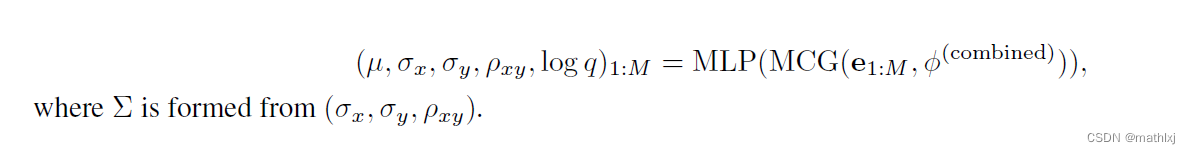
3.6 Internal Trajectory Representation
轨迹由 位置、朝向,验证agent的纵向和横向的高斯不确定性.
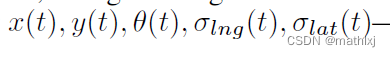
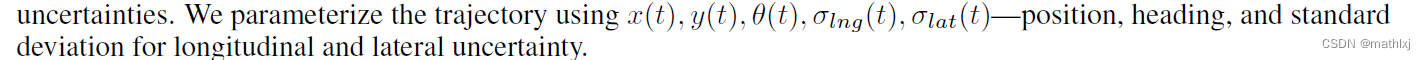
-
- 可以用多项式表示,即添加一个bias,保证光滑,插值表示.
-
- 预测更详细的运动学控制信号:
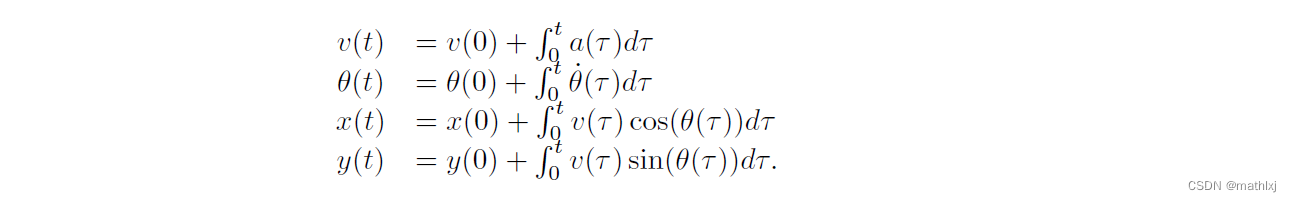
- 预测更详细的运动学控制信号:
算法1 表示了从控制信号到输出位置的转换:

4 Ensembling predictor heads via bootstrap aggregation
集成.
使用bootstrap aggregation (bagging).
类似于dropout 50%.

GMM的集成.
5 Experiments
The Waymo Open Motion Dataset (WOMD),
400x400 cells, 每个cell 0.2 m × 0.2 m 0.2m\times 0.2m 0.2m×0.2m.