1.什么是函数指针
在C语言中,一个函数在编译时被分配一个入口地址(第一条指令的地址),我们可以将地址赋给一个指针,这样,指针变量持有函数入口地址,它就指向了该函数,所以称这种指针为指向函数的指针,简称函数指针。
我们在编写代码的时候可以用函数名获得函数的地址,这一点如同数组一样,数组就可以通过数组名获得数组的起始地址。
2.怎样定义和使用函数指针
函数指针定义的一般形式:
数据类型 (*指针变量名)(形参类型);
在说明函数指针时,同时也要说明这个指针所指向的函数的参数类型和个数,以及函数的返回值类型。例如:
int (* pfunp)(int ia,int ib);
注意:在这个例子中,包围*号和函数指针名funp的圆括号是必须的,如果定义成
int *pfunp(int ia,int ib);就是错误的,因为按照结合性和优先级来看就是先和()结合,然后变成了一个返回整形指针的函数了,而不是函数指针,这一点尤其需要注意!
该语句声明了一个函数指针变量pfunp。这funp被解释为:pfunp是一个指针,它指向带有两个int类型参数的函数,函数返回值类型为int。
函数指针的性质与数据指针相同,惟一的区别是数据指针指向的是内存的数据存储区,而函数指针指向的是内存的程序代码存储区(因为函数本身就是一段程序代码)。由于这一区别,使得他们的“*”运算的意义是不同的,数据指针访问的是内存中的数据,而函数指针用“*”访问时,其结果是使程序控制转移至该函数指针所指向的函数的入口地址,从而开始执行该函数。因此,当把函数的地址赋给一个指针变量时,对该指针变量的使用就等同于调用该函数。
下面是一个使用函数指针的例子,它简单地演示了通过指针变量调用函数的情况。
#include<stdio.h>
void main()
{
int im;
int in;
int iresult;
int ifunc(int ia,int ib);
int (* pf)(int a,int b); /* 定义一个函数指针变量pf */
pf = ifunc;
/* 将函数func的入口地址赋给了函数指针pf,从而使函数指针指向了该函数 */
printf("please enter two integers :\n");
scanf("%d",&im);
scanf("%d",&in);
iresult=(* pf)(im,in); /* 等价执行result=ifunc(5,10) */
printf( "result is :%d",iresult);
}
int ifunc(int ia,int ib)
{
return (ia + ib);
}
例1
typedef定义可以简化函数指针的定义,在定义一个的时候感觉不出来,但定义多了就知道方便了,上面的代码改写成如下的形式:
#include<stdio.h>
typedef int (*pf)(int ia,int ib);
void main()
{
int im;
int in;
int iresult;
int ifunc(int ia,int ib);
pf pftemp;
pftemp = ifunc;
printf("please enter two integers :\n");
scanf("%d",&im);
scanf("%d",&in);
iresult=(*pftemp)(im,in);
printf("result is :%d",iresult);
}
int ifunc(int ia,int ib)
{
return (ia + ib);
}
例2
下面再看一个例子
int max(int x,int y){ return x>y?x:y; }
int min(int x,int y){ return x<y?x:y; }
int add(int x,int y){ return x+y; }
int process(int x,int y, int (*f)()) /* 通用两数的处理函数 */
{
return (*f)(x,y);
}
main()
{
int a,b;
printf("Enter two num to a,b:");scanf("%d%d",&a,&b);
printf("max=%d\n",process(a,b,max)); /* 调用通用处理函数 */
printf("min=%d\n",process(a,b,min));
printf("add=%d\n",process(a,b,add));
}
例3
结果:
Enter two num to a,b:3(回车)8
max=8
min=3
add=11
说明:
- 函数process处理两个整数,并返回一个整型值。同时又要求process具有通用处理能力(处理求大数、小数、和),所以可以考虑在调用process时将相应的处理方法(“处理函数”)传递给process。
- process应该有一个函数指针作为形式参数,以接受函数的地址。这样process函数的函数原型应该是:
int process(int x,int y,int (*f)());
- 函数指针变量的定义在通用函数process的形参定义部分实现;函数指针变量的赋值在通用函数的调用时实现;用函数指针调用函数在通用函数内部实现。
- main函数调用通用函数process处理计算两数中大数的过程是这样的:
- 将函数名max(实际是函数max的地址)连同要处理的两个整数a,b一起作为process函数的实参,调用process函数。
- process函数接受来自主调函数main传递过来的参数,包括两个整数和函数max的地址,函数指针变量f获得了函数max的地址。
- 在process函数的适当位置调用函数指针变量f指向的函数,即调用max函数。本例直接调用max并将值返回。这样调用点就获得了两个数当中求大数的结果,由main函数的printf函数输出结果。
同样,main函数调用通用函数process处理计算两个数当中的小数以及两数求和的过程基本一样。
process函数是一个“通用”整数处理函数,它使用函数指针作为其中的一个参数,以实现同一个函数中调用不同的处理函数。
3.回调函数
上面已经介绍了函数指针的一些问题,其实函数指针在我们平时的编程过程中有很多种应用方法,下面介绍一种最常用的方法,回调函数。
3.1 什么是回调函数
用一句话来形容:回调函数还真有点像您随身带的BP机,告诉别人号码,在它有事情时Call您。换句话说,模块A将一个函数以函数指针的形式注册到模块B,模块B满足一定条件时来调用模块A注册过来的函数,来完成一定的功能,这个过程就是函数的回调。
在我们导航系统当中回调函数使用是很广泛的,比如Map需要知道自车当前的一些情报,这样Map会提供函数(这个函数的功能是将当前的自车位置等信息写入到Map的静态变量中),以函数指针的方式注册保存到VP中,当VP监测到自车位置等信息变化的时候,会调用Map的这个函数,将自车的一些信息保存到Map中,由此可见回调函数使用起来还是很方便的。
说到这可能我们要提出问题了,我们一定要使用CallBack函数的方法吗,或者说什么时候该使用回调函数呢,下面一节会给出说明。
3.2 什么时候要使用回调函数
上面我们已经说过了什么是回调函数,为了加深一下大家的理解,在这里用图示的方法再做进一步的说明:
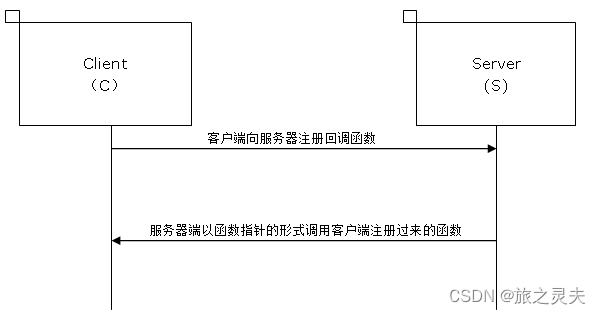
上图很明显的说明了回调函数的原理,下面我们来讨论一个更加实用的话题,什么时候要使用回调函数呢?
假设现在系统中有两个模块,他们是客户端C(以后都简称C)和服务器端S(以后都简称S),在整个系统中C能完成一个功能,并且完成这个功能要用到S中的数据,但是C不知道该什么时候完成这个功能,而S能知道该什么时候完成这个功能,这样该怎么办呢?
如果我们现在还不知道怎么使用回调函数,那么我们很可能想到的办法是用S来发消息通知C来执行这个功能,这样的话在C中就要有等待S通知的代码,并且还要判断来的通知是不是S要求C来执行这个功能,在判断完成后还要调用S中的接口来取得相应的信息。可以看出这确实是一种实现的办法,但是这种方法除了要有消息判断,还要有取数据的过程;并且要知道像这种跨模块通信的消息多了,对一个系统来说是很麻烦的,会使系统维护变得困难。
回调函数就解决了这个问题,我们可以把C中完成这个功能的主函数以指针的形式注册到S中,并且保存在S中,当然这个函数的参数可以是C完成这个功能所需要的数据,这样就可以在S中直接调用C注册过来的函数指针,来完成这个功能,这是不是更加合情合理呢。
当我们说到这,可能有人马上就会问这样一个问题,那在C中直接设计一个接口直接调用不就可以了吗,这个想法是不应该的,因为服务器端调用客户端的接口,本身就不是一个好的设计,很不符合情理。
为了能够更加生动的说明这个问题,我们还是回到我们导航系统当中,我们知道Map可以提供一个功能能利用自车位置等信息进行Map地图的更新,Map能够完成这个功能,但是不知道什么时机来完成这个功能;而在整个导航的Appli层中VP是一个服务器,为其他模块提供自车相关的数据,而VP能够监测当前的自车的自车位置等信息,能知道什么时候自车位置发生变化了,这样就刚刚好符合我们上面提到的逻辑,所以现在导航中就是用回调函数来触发地图随着自车位置变化而更新的功能的。
其实回调函数能完成的功能,我们用其他的方法都可以完成,但是使用回调函数可以使整个系统结构清晰,分工明确。也使程序的扩展性大大增强了。
在这里还需要补充说明一下,回调函数都是在服务器端定义,在客户端实现的,让客户端来包含服务器端的头文件。
3.3回调函数的使用方法的举例说明
回调函数在我们编程过程中使用的地方很多,下面举一个简单的例子来说明线程间通过回调函数来进行通信的方法。
下面的这个程序中会有一个主线程,然后创建一个辅助线程AssistThread,在创建AssistThread的时候会把主线程要执行的一个函数CBFunc以函数指针的形式传递到AssistThread中,在AssistThread结束的时候会用创建AssistThread时传递过来的函数指针,以回调函数的形式调用CBFunc:
#include <windows.h>
#include <stdio.h>
typedef int (WINAPI *PFCALLBACK)(int Param1,int Param2) ;
/* 定义了一个函数指针类型 */
int WINAPI CBFunc(int Param1,int Param2);
ULONG WINAPI AssistThread(LPVOID Param)
{
PFCALLBACK gCallBack;
/* 定义回调函数指针的变量 */
TCHAR Buffer[256];
MSG Msg;
DWORD StartTick;
int Step=1;
HDC hDC = GetDC(HWND_DESKTOP);
gCallBack = (PFCALLBACK)Param;
/* 给回掉函数变量赋值 */
for(;Step<200;Step++)
{
StartTick = GetTickCount();
/* 这一段为线程交出部分运行时间以让系统处理其他事务 */
for(;GetTickCount()-StartTick<10;)
{
if(PeekMessage(&Msg,NULL,0,0,PM_NOREMOVE) )
{
TranslateMessage(&Msg);
DispatchMessage(&Msg);
}
}
/* 把运行情况打印到桌面 */
sprintf(Buffer,"Running %04d",Step);
if(NULL!=hDC)
TextOut(hDC,30,50,Buffer,strlen(Buffer));
}
(*gCallBack)(Step,1);
/* 延时一段时间后调用回调函数 */
ReleaseDC (HWND_DESKTOP,hDC);
/* 结束 */
return 0;
}
void WINAPI TestCallBack(PFCALLBACK Func)
{
HANDLE hThread;
DWORD ThreadID=0;
if(NULL==Func)return;
hThread = CreateThread(
NULL,
NULL,
AssistThread,
(LPVOID)Func,
/* 将回调函数指针Func传递到线程AssistThread的主函数中 */
0,
&ThreadID
);
WaitForSingleObject( hThread, INFINITE );
return;
}
int WINAPI CBFunc(int Param1,int Param2)
{
int res= Param1+Param2;
TCHAR Buffer[256]="";
sprintf(Buffer,"callback result = %d",res);
MessageBox(NULL,Buffer,"Testing",MB_OK); /* 演示回调函数被调用 */
return res;
}
void main()
{
TestCallBack(CBFunc); /* 函数的参数CBFunc为回调函数的地址 */
return;
}
例4
这个例子很典型地说明了回调函数的一般的用法。
3.4 使用回调函数的注意事项
我们在使用回调函数的时候,要特别注意两个问题,一个是避免死锁,一个是要充分考虑服务器端的性能。

如图2所表示的那样,对于客户端和服务器端的功能来说这样的形式感觉是合情合理的,服务器端触发了客户端的动作,客户端要到服务器端取得数据。
但是我们从图2这个很简单的时序图关系来说,这样是很危险的,在服务器的线程中调用了客户端的回调函数,然后还接着占用服务器端的线程来有调用服务器的接口取得数据,这样就很可能造成系统的死锁。
所以正确的方法是如果客户端完成这个功能需要从服务器端取得数据的话,最好有个线程切换的过程,这样便能避免出现死锁了,如图3所示。
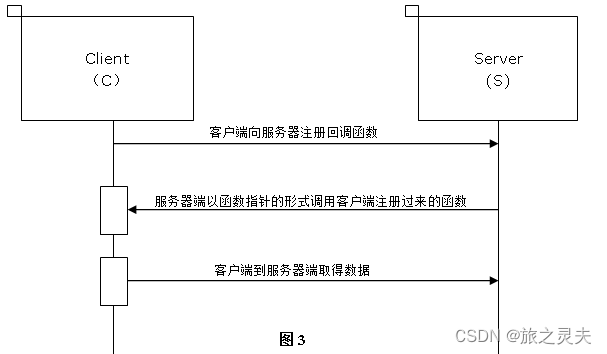
还有一种情况的回调会产生死锁,具体情况下图表示得很清楚。

如上图所示,这种情况下很容易出现死锁,在S端首先Lock住自己的信号量C,然后将要调用C端的回调函数(在回调函数中C端首先要Lock自己的信号量A),这时C端的另外一个线程正好要调用S端的接口取得数据,C首先Lock住自己的信号量A,然后将要调用S端的接口(S的接口中要Lock信号量C)。
很明显这样就出现了相互等待的情况而出现死锁。
上面出现的死锁,问题实际上是出在客户端,如果客户端在回调函数中,和在调用服务器端接口的时候使用不同的信号量就可以避免死锁了。
使用回调函数还要注意性能问题,在回调函数中不能有很浪费时间的处理,道理和上面一样,要知道回调函数本身被调用是占用服务器端的线程的,服务器端还要处理自己要做的事情,并且不是只为一个客户端来服务,如果这个服务器的资源长时间被这个回调函数占用的话,对整个系统来说都是不好的。
和上面问题一样,在客户端来个线程切换就可以解决这个问题。
3.5 小结
其实在我们日常的工作中遇到的回调函数比比皆是,使用技巧很多,例如windows的消息机制、和我们导航中的快速排序算法,都用到了回调函数的原理。大家可以多思考这些问题,对大家理解回调函数有很大的帮助。
4.函数指针的使用技巧-函数指针在表驱动方法中的应用
函数指针的使用其实是很灵活的,它有很多技巧性很高的应用,在表驱动方法中的应用很典型,这里着重介绍一下。
4.1 什么是表驱动方法
表是几乎所有数据结构课本都要讨论的非常有用的数据结构。表驱动方法出于特定的目的来使用表,下面将对此进行讨论。
程序员们经常谈到“表驱动”方法,但是课本中却从未提到过什么是“表驱动”方法。表驱动方法是一种使你可以在表中查找信息,而不必用很多的逻辑语句(if或Case)来把它们找出来的方法。事实上,任何信息都可以通过表来挑选。在简单的情况下,逻辑语句往往更简单而且更直接。但随着逻辑链的复杂,表就变得越来越富有吸引力了,通过下面的这个例子大家就能知道什么是所谓的表驱动方法了。
假设你需要一个可以返回每个月中天数的函数(为简单起见不考虑闰年),一个比较笨的方法是一个大的if语句:
int iGetMonthDays(int iMonth)
{
int iDays;
if(1 == iMonth) {iDays = 31;}
else if(2 == iMonth) {iDays = 28;}
else if(3 == iMonth) {iDays = 31;}
else if(4 == iMonth) {iDays = 30;}
else if(5 == iMonth) {iDays = 31;}
else if(6 == iMonth) {iDays = 30;}
else if(7 == iMonth) {iDays = 31;}
else if(8 == iMonth) {iDays = 31;}
else if(9 == iMonth) {iDays = 30;}
else if(10 == iMonth) {iDays = 31;}
else if(11 == iMonth) {iDays = 30;}
else if(12 == iMonth) {iDays = 31;}
return iDays;
}
例5
可以看出本来应该很简单的一件事情,代码却是这么冗余,解决这个的办法就可以用表驱动方法。
static int aiMonthDays[12] = {31,28,31,30,31,30,31,31,30,31,30,31};
/* 我们可以先定义一个静态数组,这个数组用来保存一年十二个月的天数 */
int iGetMonthDays(int iMonth)
{
return aiMonthDays[(iMonth - 1)];
}
例6
接下来不用多说了,大家都能看出用这种表驱动的方法代替这种情逻辑行不强,但分支很多的代码是多么令人“赏心悦目”的了。
可能大家早都会用这样的代码来节省程序的代码量,在这里只是简单介绍一下,这个方法就是所谓的表驱动方法了。
4.2 函数指针在表驱动方法中的应用
在使用表驱动方法时需要说明的一个问题是,你将在表中存储些什么。在某些情况下,表查寻的结果是数据。如果是这种情况,你可以把数据存储在表中。在其它情况下,表查寻的结果是动作。在这种情况下,你可以把描述这一动作的代码存储在表中。在某些语言中,也可以把实现这一动作的子程序的调用存储在表中,也就是将函数的指针保存在表中,当查找到这项时,让程序用这个函数指针来调用相应的程序代码,这个就是函数指针在表驱动方法中的应用。
其实说到这已经说了很多表驱动方法的相关问题了,现在要把函数指针也应用进去,很多人应该已经想到会是个什么样子了,其实也很简单,通过下面这两段伪代码的例子就可以充分体现函数指针在表驱动方法中应用会使代码更加精致。
我们在写一段程序的过程中会经常遇到这样的问题,我们在写一个Task的主函数中有时会要等待不同的Event通知,并且处理不同的分支,首先有如下的Event Bit的宏定义和相应的处理函数的声明。
#define TASK_EVENT_BIT00 (1 << 0)
#define TASK_EVENT_BIT01 (1 << 1)
#define TASK_EVENT_BIT02 (1 << 2)
#define TASK_EVENT_BIT03 (1 << 3)
#define TASK_EVENT_BIT04 (1 << 4)
#define TASK_EVENT_BIT05 (1 << 5)
#define TASK_EVENT_BIT06 (1 << 6)
#define TASK_EVENT_BIT07 (1 << 7)
#define TASK_EVENT_BIT08 (1 << 8)
#define TASK_EVENT_BIT09 (1 << 9)
void vDoWithEvent00();
void vDoWithEvent01();
void vDoWithEvent02();
void vDoWithEvent03();
void vDoWithEvent04();
void vDoWithEvent05();
void vDoWithEvent06();
void vDoWithEvent07();
void vDoWithEvent08();
void vDoWithEvent09();
我们一般首先想到的写法是
unsigned long ulEventBit;
for(;;)
{
xos_waitFlag(&ulEventBit);
if(ulEventBit & TASK_EVENT_BIT00)
{
vDoWithEvent00();
}
if(ulEventBit & TASK_EVENT_BIT01)
{
vDoWithEvent01();
}
if(ulEventBit & TASK_EVENT_BIT02)
{
vDoWithEvent02();
}
if(ulEventBit & TASK_EVENT_BIT03)
{
vDoWithEvent03();
}
if(ulEventBit & TASK_EVENT_BIT04)
{
vDoWithEvent04();
}
if(ulEventBit & TASK_EVENT_BIT05)
{
vDoWithEvent05();
}
if(ulEventBit & TASK_EVENT_BIT06)
{
vDoWithEvent06();
}
if(ulEventBit & TASK_EVENT_BIT07)
{
vDoWithEvent07();
}
if(ulEventBit & TASK_EVENT_BIT08)
{
vDoWithEvent08();
}
if(ulEventBit & TASK_EVENT_BIT09)
{
vDoWithEvent09();
}
}
例7
可以看出这样写是不是显得程序太长了呢。
下面我们再看看同样的一段代码用函数指针和表驱动方法结合的方法写出会是什么样子。
typedef struct {
unsigned long ulEventBit;
void (*Func)(void);
} EventDoWithTable_t;
/* 定义EventBit 与相应处理函数关系的结构体 */
static const EventDoWithTable_t astDoWithTable[] = {
{ TASK_EVENT_BIT00 , vDoWithEvent00},
{ TASK_EVENT_BIT01 , vDoWithEvent01},
{ TASK_EVENT_BIT02 , vDoWithEvent02},
{ TASK_EVENT_BIT03 , vDoWithEvent03},
{ TASK_EVENT_BIT04 , vDoWithEvent04},
{ TASK_EVENT_BIT05 , vDoWithEvent05},
{ TASK_EVENT_BIT06 , vDoWithEvent06},
{ TASK_EVENT_BIT07 , vDoWithEvent07},
{ TASK_EVENT_BIT08 , vDoWithEvent08},
{ TASK_EVENT_BIT09 , vDoWithEvent09}
};
/* 建立EventBit与相应处理函数的关系表 */
ulong ulEventBit;
int i;
for(;;)
{
xos_waitFlag(&ulEventBit);
for(i = 0 ; i < sizeof(astDoWithTable)/sizeof(astDoWithTable[0]); i ++)
{
if ( ( ulEventBit & astDoWithTable[i].ulEventBit ) &&
( astDoWithTable[i].Func != NULL ) )
{
(*astDoWithTable[i].Func)();
/* 通过函数指针来调用相应的处理函数 */
}
}
}
例8
可以看出这种代码的风格使代码变得精致得多了,并且使程序的灵活性大大加强了,如果我们还要再加入EventBit,只修改表中的内容就可以了。
5.总结
通过上面介绍的,相信大家已经对函数指针的使用方法有所了解了,但是需要提醒大家,凡事都要具体情况具体分析,使用函数指针的时候一定要多加小心,因为函数指针有它的一个致命的缺点。
函数指针的致命缺点是:无法对参数 (parameter) 和返回值 (return value) 的类型进行检查,因为函数已经退化成指针,指针是不带有这些类型信息的。少了类型检查,当参数或者反回值不一致时,会造成严重的错误。有些编译器并不会帮我们找出函数指针这样的致命错误。所以,许多新的编程语言都不支持函数指针了,而改用其他方式。
从上面的例3中我们可以看到
int max(int x,int y){ return x>y?x:y; }
int min(int x,int y){ return x<y?x:y; }
int add(int x,int y){ return x+y; }
这三个函数都有两个参数,而在后面却把处理函数定义成
int process(int x,int y, int (*f)())
{
return (*f)(x,y);
}
其中第三个参数是一个函数的指针,从表面上看它是个没有参数,并且返回int型的函数的指针,但是在后面却用process(a,b,max)的方式进行调用,max带有两个参数,这段程序在C语言中就可以顺利的编译通过(但是在C++中却编译不通过),可以看出如果编译器没有检查出错误,而我们又不小心写错的话,后果是很严重的,比如return (*f)(x,y);不小心写成return (*f)(x);在C语言中可以正常的被编译通过,但是运行结果一定不是我们想要的。
因此在C语言中使用函数指针的时候,一定要小心“类型陷阱”,小心地使用函数指针,只有这样我们才可以从函数指针中获益。