目录
前言
一、 获取实体店铺信息
二、 获取全国各省市县地图json数据
四、 获取网络图片、视频资源
五、 自动化测试
总结
前言
续上篇,我们简单讲述一下puppeteer常见的应用场景,包括静态页面数据获取,网络请求获取截取、图片、视频资源下载、自动化测试等。
一、 获取实体店铺信息
这个案例是我在网上看到的真实案例,需求是需要爬取店铺信息,用于广告投放,需要有店铺面积、联系方式、租金、位置等信息,出价800¥,还是非常诱人的。大家学会了puppeteer后,也可以接这种单子做。

下面我们来实现这个案例:
先爬取基础信息吧,这个代码是 puppeteer最基础的代码了。
// 初始化puppeteer
async function initPuppeteer() {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
page.goto(baseURL);
} 信息都在这个div里面,我们使用 page.$eval()选择这个div,向里取数。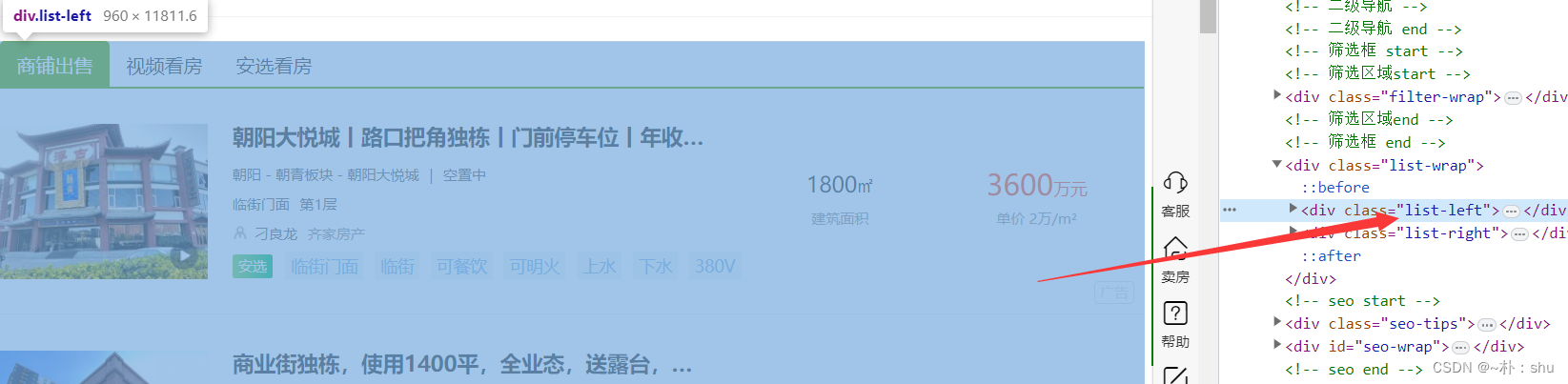

我们想要的信息在这,使用 document.querySelectorAll()选中所有的 class='list-item',每一项单独获取信息即可:
await page.$eval('div[class="list-left"]', (listLeft) => {
// 这里不用document,而是在 已经选中的基础上进行下一步操作
const items = listLeft.querySelectorAll('div[class="list-item"]');
items.forEach(async (item) => {
// 这里获取的是每一项数据,可以直接拿到信息
const item_a_link = item.querySelector("a");
// 获取图片链接
const item_img_src = item_a_link
.querySelector('div[class="item-img"]')
.querySelector("img")
.getAttribute("src");
// 获取标题
const item_title = item_a_link
.querySelector('div[class="item-info"]')
.querySelector('div[class="item-title"]')
.querySelector("span").innerText;
// 获取 联系人 名称
const item_user = item_a_link
.querySelector('div[class="item-info"]')
.querySelectorAll("p")[2]
.querySelector("span").innerText;
});
}); 
现在处理联系方式:

页面设计为需要打开新tab页,点击 电话联系TA 按钮,才能显示电话 ,因为需要等待 60 的浏览器响应数据,因此,设计为异步处理。异步处理则是在一个页面中跳转路由,而不是打开多个浏览器,节省内存,不然会导致内存溢出,程序中断。
for (const item of data) {
if (!item.phoneUrl) return;
// 请求phone
await page.goto(item.phoneUrl);
// 处理 元素不存在,需要点击校验的问题(存在机器校验问题,需要等待元素)
if (!(await page.waitForSelector('div[class="tel-wrap"]')))
await page.click('input[class="btn_tj"]');
await page.waitForSelector('div[class="tel-wrap"]');
// 点击 电话联系ta 显示号码
await page.click('div[class="tel-wrap"]');
// 等待元素
await page.waitForSelector('div[class="tel-phone-number"]');
// 获取号码
const phone = await page.evaluate(() => {
return document.querySelector('div[class="tel-phone-number"]').innerText;
});
item.phone = phone;
// 这里不要 page.close() 不然没有操作页面,
// 其二 close 后,一定要 newPage(),两种方案
}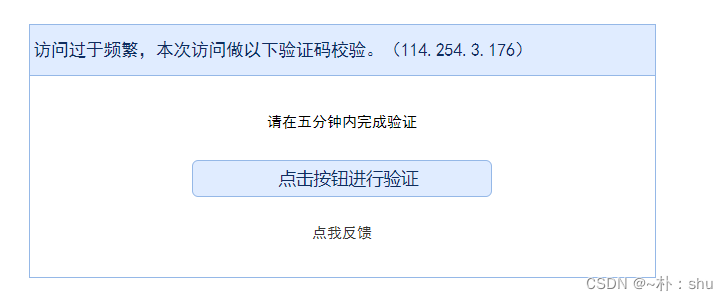
请求次数过多,会有这个提示,这个时候,需要判断元素是否存在,不存在,需要进行点击处理:
// 首页也会有机器校验问题
if (!document.querySelector('div[class="list-left"]'))
await page.click('input[class="btn_tj"]');效果如下:
当然,有些用户的号码是虚拟的,10分有限,那每隔10分钟爬取一次,更新变量就行了,将数据转存为json文件:

测试没问题了,就可以关闭 headless 模式了。还可以通过参数控制数据获取范围,参数型数据获取,我们到下面再说哈。
二、 获取全国各省市县地图json数据
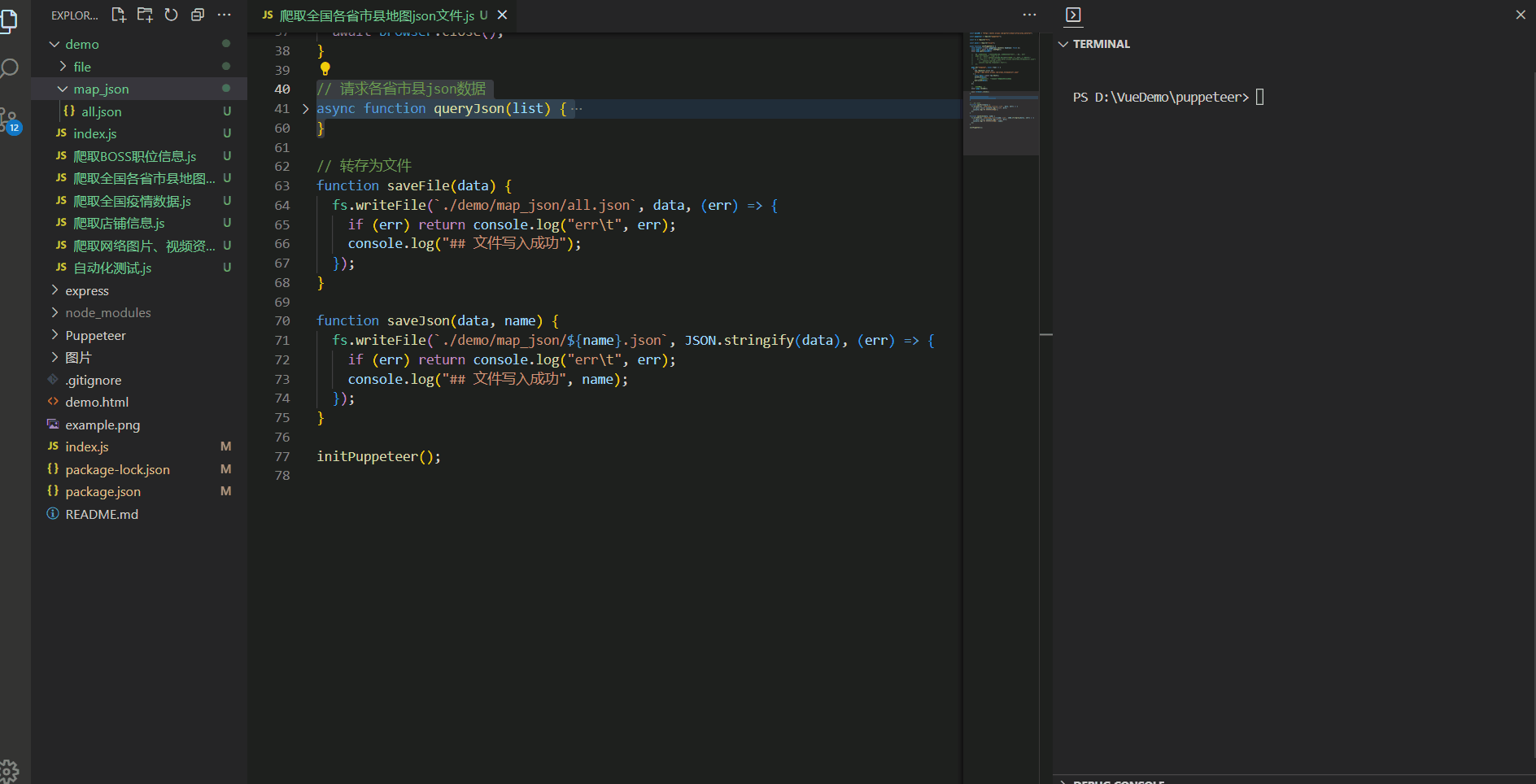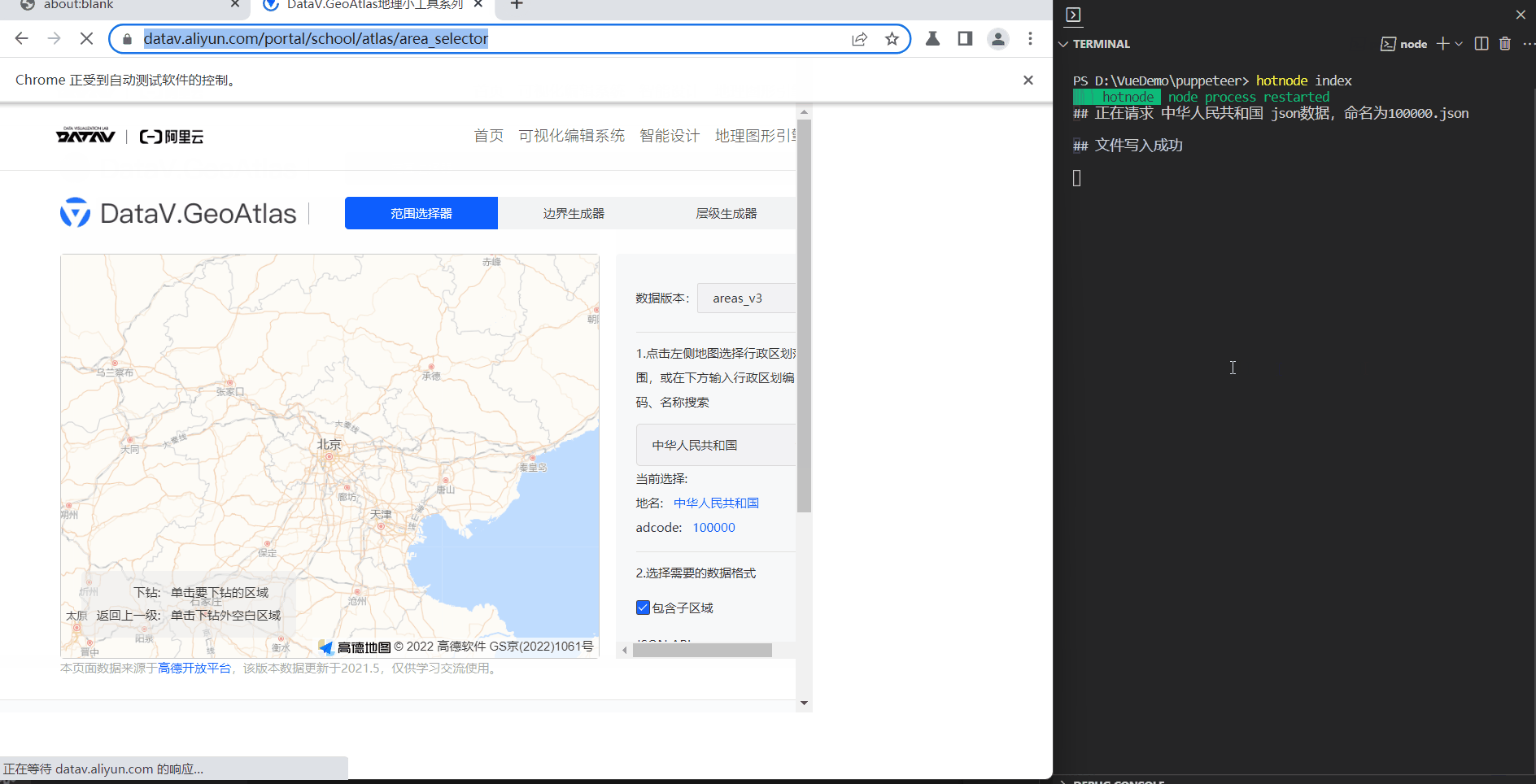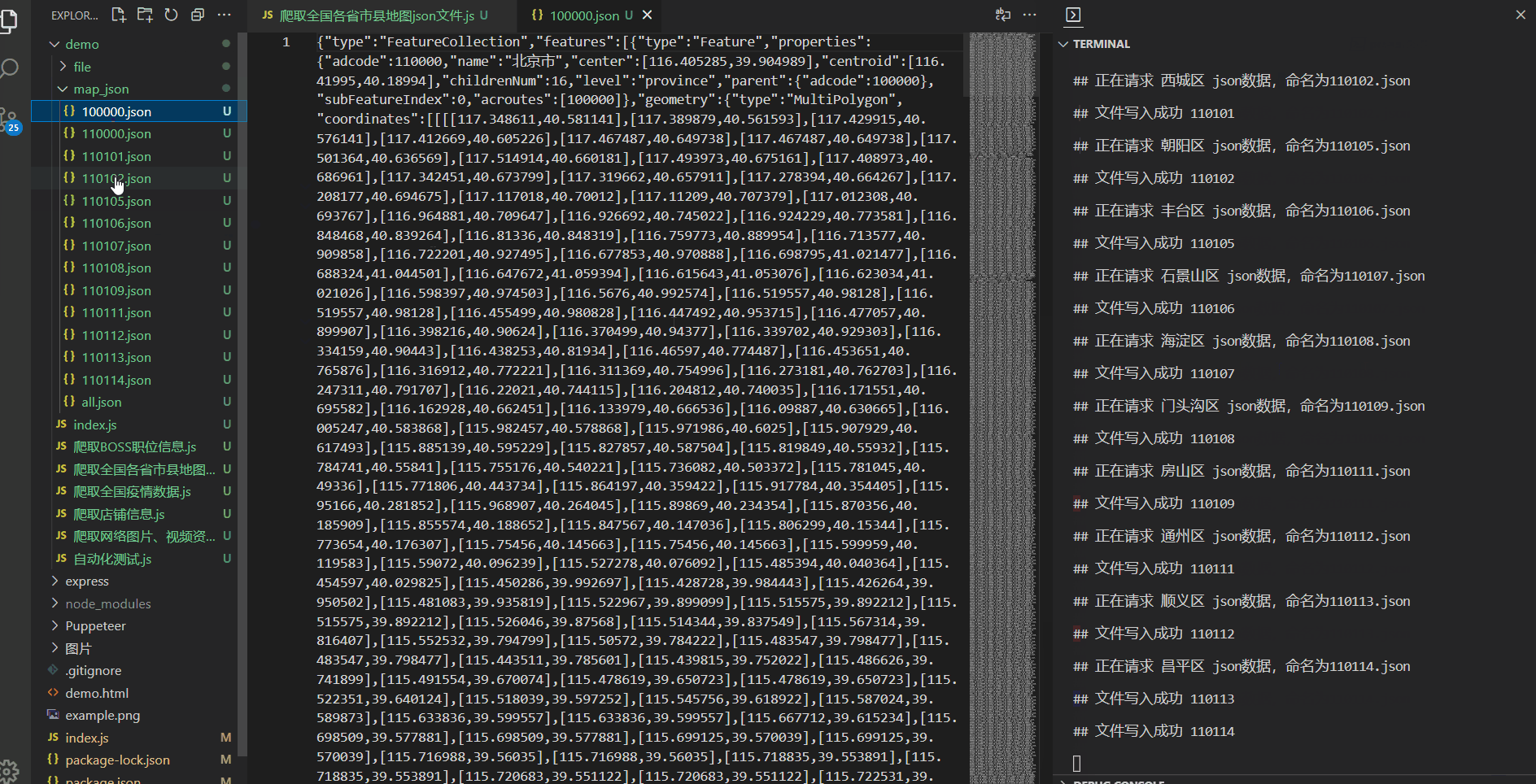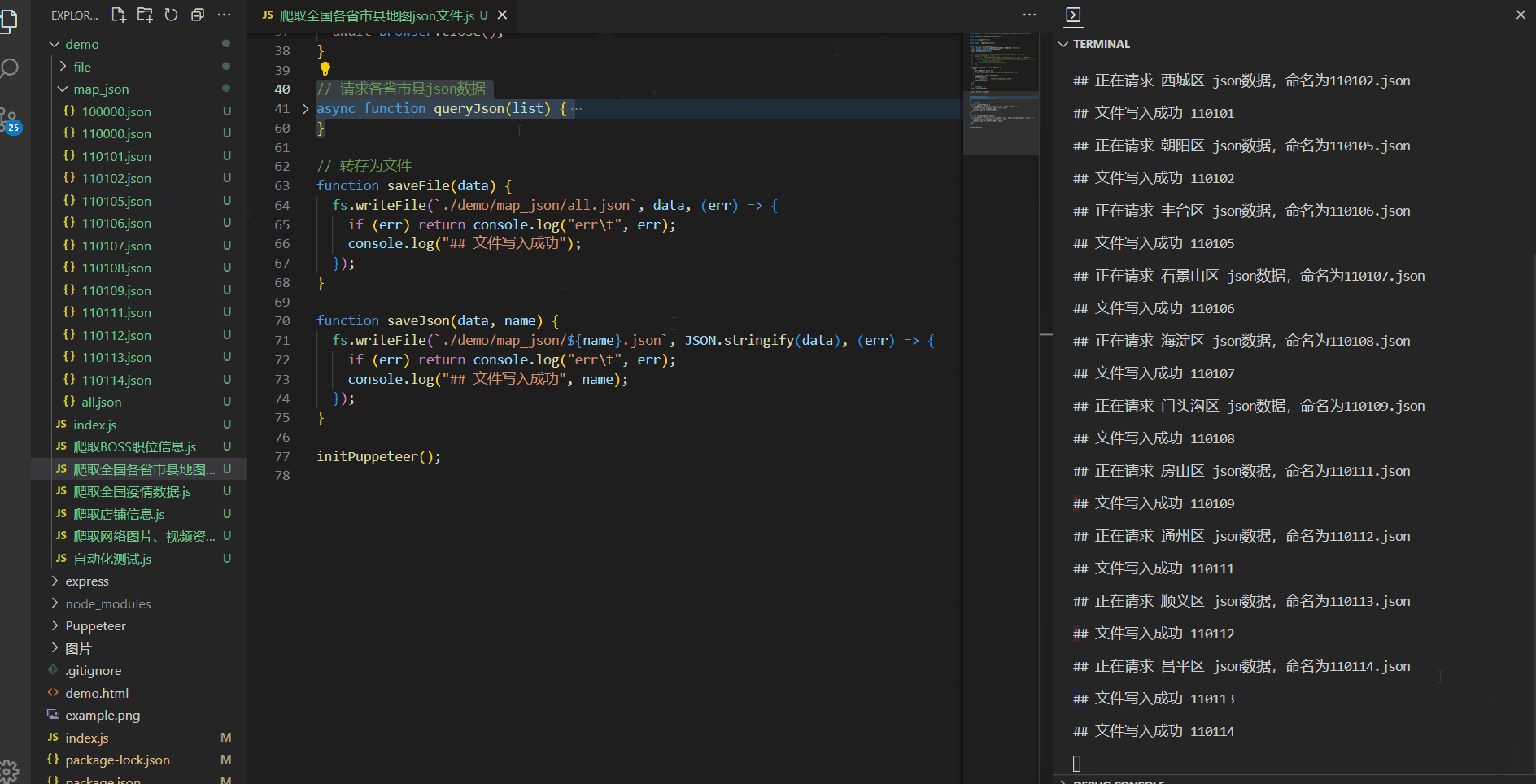
DataV.GeoAtlas地理小工具系列
这个就是我地图篇的数据爬取了,下面说说思路:
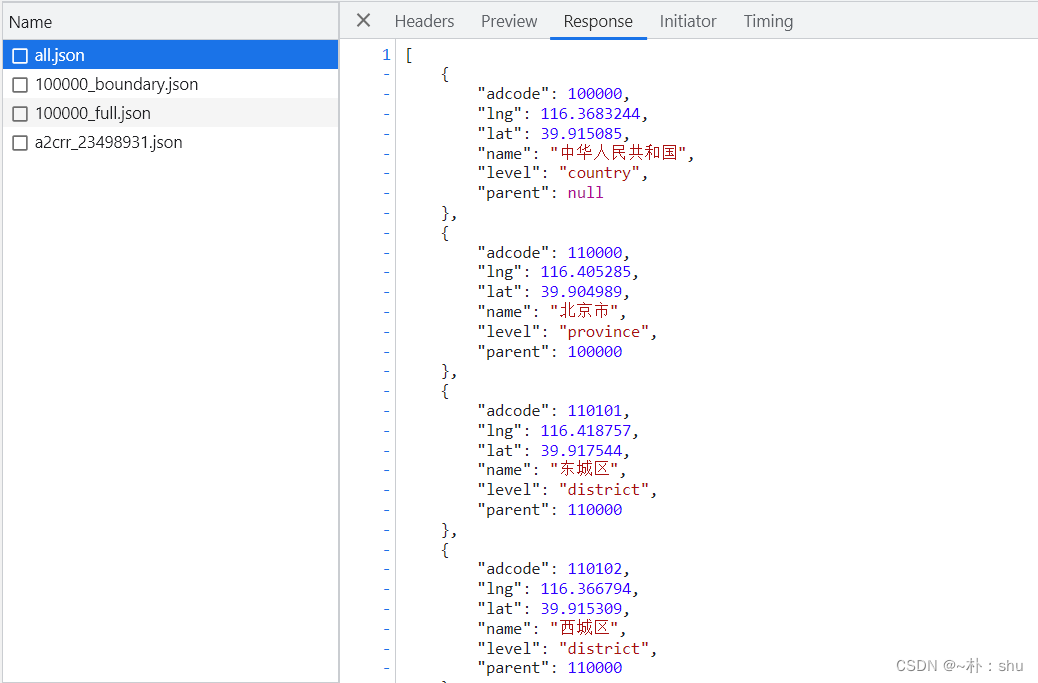
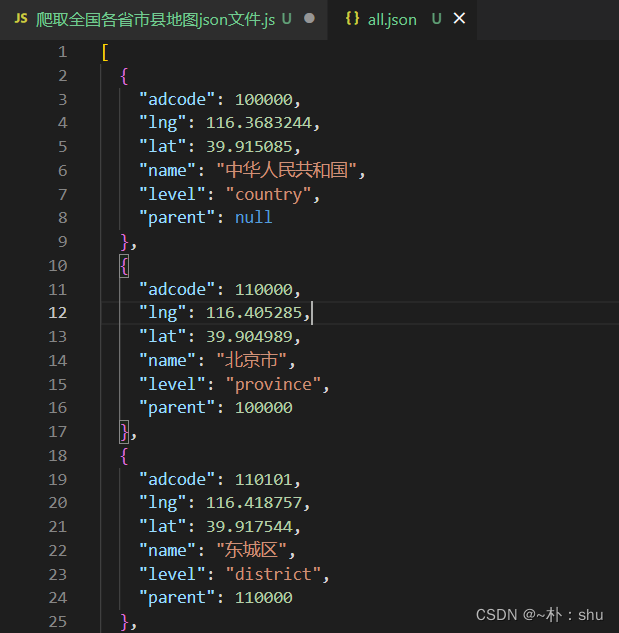
页面网络请求中,有一个 all.json 的请求,是全国各省市县的adcode、name属性,我们先拿到这个数据,然后根据adcode进行分别请求即可。
全国JSON数据:https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json
广西JSON数据:https://geo.datav.aliyun.com/areas_v3/bound/450000_full.json
柳州市JSON数据:https://geo.datav.aliyun.com/areas_v3/bound/450200_full.json
柳城县JSON数据:https://geo.datav.aliyun.com/areas_v3/bound/450222.json
可以看出,前缀是一样的,无非就是更换了请求的adcode,县级地图没有 _full ,因此,我们最重要的三个数据项:adcode、name、level,【但是我们仔细看all.json,他只有四个层级,country、province、city、district。】就可以爬取全国各省市县的JSON数据,下面我们开始吧。
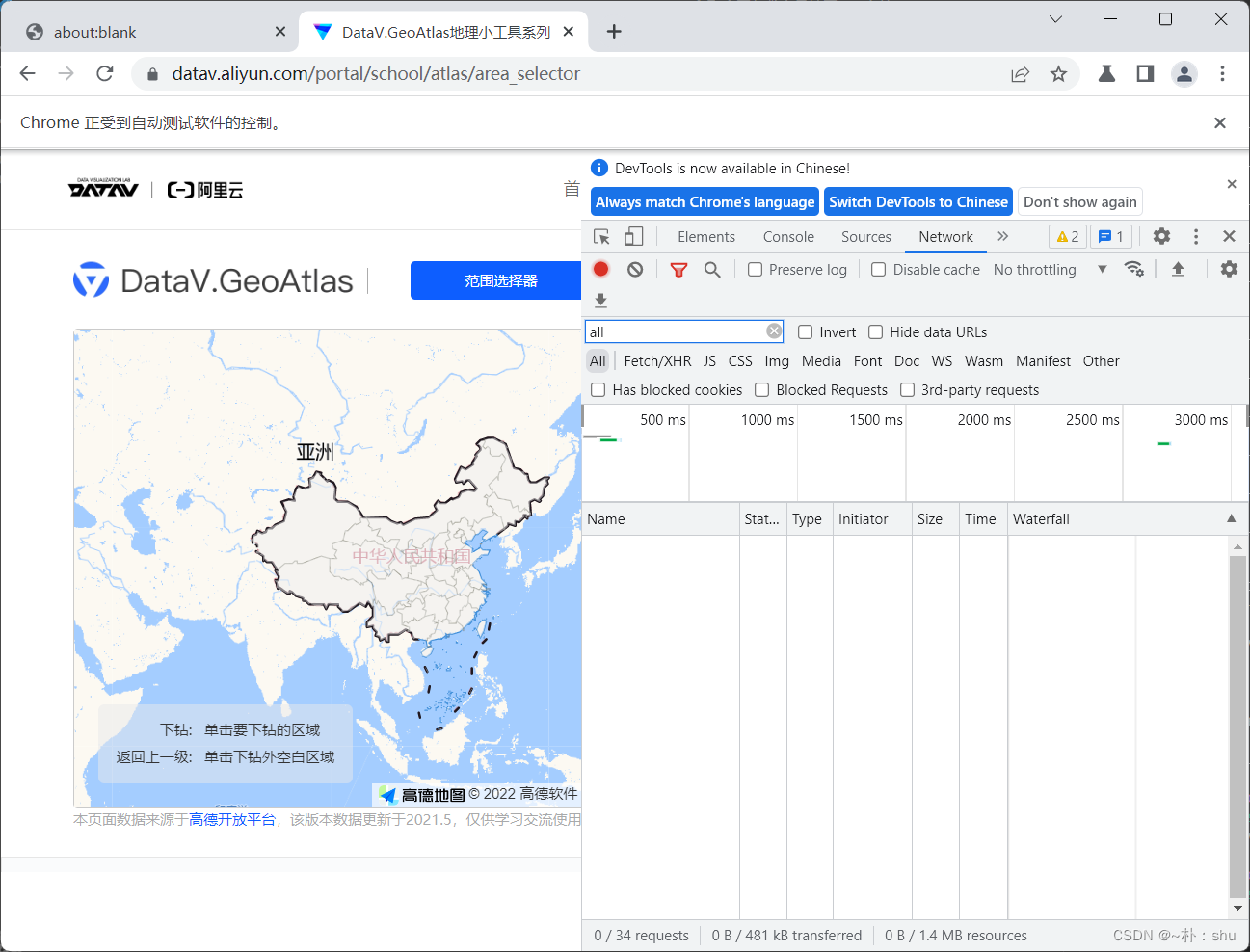
puppeteer 页面刚加载时,并没有请求 all.json,因此需要实现刷新页面 page.reload(),监听请求没有响应体,转为监听响应了,两者都是相似的
page.on("response", async (res) => {
if (
res.request().url() ===
"https://geo.datav.aliyun.com/areas_v3/bound/all.json"
)
const data = await res.text();
saveFile(data);
}); 
拿到这个数据后,直接发送get请求,就可以得到响应体实现文件转存了:

// 请求各省市县json数据
async function queryJson(list) {
if (!list.length) return;
for (const item of JSON.parse(list)) {
// 一共3000多个,我就模拟前几个就行了 到 adcode = 110115 退出
if (item.adcode === 110115) break;
// 发送请求
console.log(`## 正在请求 ${item.name} json数据,命名为${item.adcode}.json`);
const url =
item.level === "district"
? `https://geo.datav.aliyun.com/areas_v3/bound/${item.adcode}.json`
: `https://geo.datav.aliyun.com/areas_v3/bound/${item.adcode}_full.json`;
try {
const { data } = await axios.get(url);
saveJson(data, item.adcode);
} catch (error) {
console.log("请求出错", error);
}
}
}
通过这两个案例,你也能清晰看出,每个页面的数据获取并不全是一样的。一定要先关注你想爬取的数据,是怎么来的,页面静态数据、接口数据还是啥,下面的案例,我们说一下怎么通过监听接口响应来获取数据。
三、 cookies
上面两个案例,接触了静态页面数据获取、接口数据获取,既然puppeteer也能进行输入操作,为什么不直接输入账号密码登录,而是要进行cookies设置?有些是需要手机验证码的,在puppeteer上等待验证码不太好,因此,登录一次后,进行cookies设置是最合适的。目前没找到合适的案例进行说明,以后遇到了再补充。
四、 获取网络图片、视频资源
https://www.upupoo.com/bd01?n=20210426043&bd_vid=11724880147497932614
难点在于请求的资源进行保存,使用 fs 模块完成即可。
// 在这里处理一下 参数 的真正实现的思路吧(先获取映射)
const paramsIndex = await page.evaluate(() => {
let map = [];
const lis = document
.querySelector('ul[class="wallpaper-tag-list"]')
.querySelectorAll("li");
lis.forEach((i) => map.push(i.innerText));
return map;
});
// 判断参数
if (type) {
const btns = await page.$$('ul[class="wallpaper-tag-list"] li');
btns[paramsIndex.findIndex((i) => i === type)].click();
}先使用page的方法,点击了页面后,才可以进行页面数据获取,这才是参数型获取数据正确的做法。
await page.exposeFunction("downloadImg", downloadImg);
// 处理数据(又要等待,不然没结果)
await page.waitForSelector('li[class="wallpaper-item"] div img');
await page.evaluate(() => {
const images = document.querySelectorAll(
'li[class="wallpaper-item"] div img'
);
images.forEach((img) => {
// 获取li的img属性
downloadImg(img.getAttribute("src"));
});
});async function downloadImg(url) {
// 解析类型
const [name, type] = url.split("theme")[1].split(".");
const { data } = await axios.get(url, {
responseType: "arraybuffer", // 务必设置响应类型
});
const filename = name.split("/");
fs.writeFile(
`./demo/img/${filename[1]}_${filename[2]}.${type}`,
data,
"binary",
function (err) {
if (err) return console.log("文件保存失败", err);
console.log("保存图片成功");
}
);
}
视频的获取也是类似的,都是拿到url,进行请求,然后进行文件保存:
async function initVideo() {
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
page.goto("https://www.douyin.com/");
const closebtn = await page.waitForSelector('div[class="dy-account-close"]');
// 如果有提示登录,则关闭按钮
if (closebtn) await page.click('div[class="dy-account-close"]');
await page.exposeFunction("downloadVideo", downloadVideo);
for (const i of new Array(5).fill(0)) {
await page.evaluate(async () => {
await downloadVideo(
document.querySelector("video source").getAttribute("src")
);
});
// 点击下一个视频
await page.click('div[class="xgplayer-playswitch-next"]');
}
} 
爬取音频:
任何网络资源请求,在操作前,都一定要观察一下它的资源是怎么出现的。无非常见的两种形式:页面url、网络请求。我已经很多次都强调了这个点,每个页面都是不一样的,先观察,再考虑采取什么方式爬取,不然你无从下手。
Vite + Vue + TS 这个音乐播放器就不是常见的页面url,找了元素好久页没有发现音频的路径,而是每点击一次页面请求拿到音频直接播放。因此我们获取响应的请求,判断类型,拿到音频
res.request().resourceType():请求资源类型 资源类型为以下值中的一个:document,stylesheet,image,media,font,script,texttrack,xhr,fetch,eventsource,websocket,manifest,other。
根据请求拿url:

哇,这个页面爬取的跟pc的还不完全一样!只能按照按钮先展示播放进度了,然后再依次点击 下一首,进行请求拦截。先看一下它请求的时候传了什么参数:

请求的id与返回歌曲列表的hash值一致,这样就可以对应唯一的请求,实现歌曲名称歌手对应了。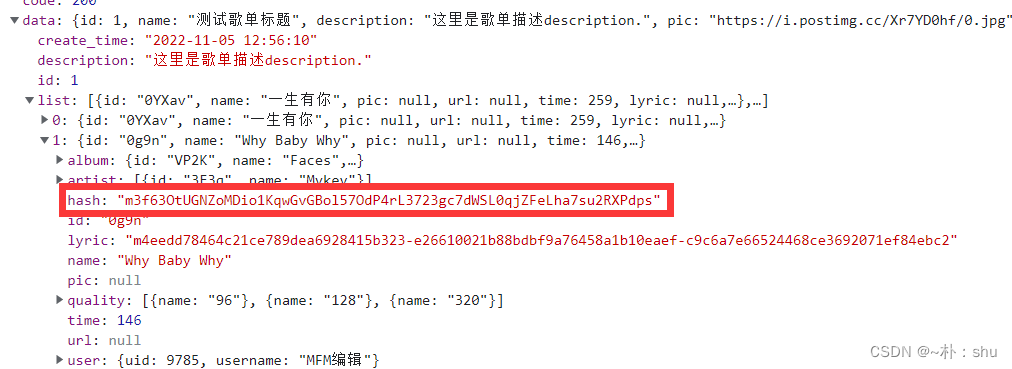
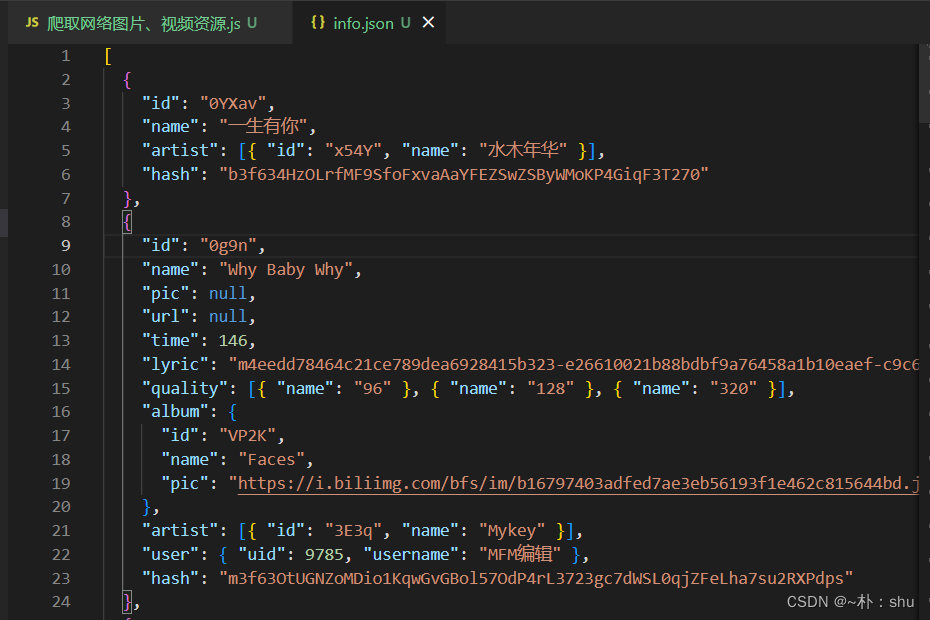
先将歌曲的列表信息存起来,请求的时候,分解hash,找到对应的歌曲信息
// 绑定外部方法,专门处理 url hash
function getUrlHash(url) {
if (!url) return;
let hash = url.split("?")[1]?.split("=")[1].replace("&quality", ""); // url 的请求 hash
if (!hash) return; // hash 值不存在,则表示不是歌曲列表中的请求
// 找歌曲信息
// {
// "id": "0YXav",
// "name": "一生有你", // 歌名
// "artist": [{ "id": "x54Y", "name": "水木年华" }], 歌手
// "hash": "b3f634HzOLrfMF9SfoFxvaAaYFEZSwZSByWMoKP4GiqF3T270" 请求
// },
const songsList = require("./mp3/info.json");
const item = songsList.find((i) => i.hash === hash);
if (item) {
musicList.push({
musicUrl: url,
name: item.name,
user: item.artist,
});
console.log("歌曲转存", musicList);
}
}需要等待时长,剩下的就是点击下一首进行其他歌曲的捕获:

这个爬取音频是几个案例中最难的,哇,搞了我一天。没想到这个网页做的这么好,夸一下!
五、 自动化测试
这个就不多说了,无非是 进行按钮的操作、输入框输入,可以配合一些mock库,实现数据模拟,找到好的案例再给大家补充。
总结
这几个案例大家都自己手敲的话,相信大家对puppeteer的掌握程度一定有质的提升。还是对几个案例做一下总结吧:
- puppeteer内部使用 page.$eval、page.evaluate会更多,在node环境中,使用page.$、page.$$更多。
- 内部环境就像是 console 控制台,可以随意使用 document.querySelector,但是在node中,你也想获取元素,就要使用 page.$ 获取元素了,进行 page.$().click()的操作。
- 在想爬取一个网页数据之前,一定先弄清楚数据来源,是静态页面还是 接口数据,还是需要我们自己发请求。
- 一定合理利用 page 的wait方法,可以避免一些错误,特别是 元素选择问题。
- 合理使用 async await,不然你都不知道错误怎么来的hhh
- 当然,我们设计页面时,也可以考虑一下反爬虫,如果大家感兴趣,可以单独出一篇文章。
- 合理利用puppeteer提供的便利,勿做其他非法之事!
- 合理利用puppeteer提供的便利,勿做其他非法之事!
- 合理利用puppeteer提供的便利,勿做其他非法之事!