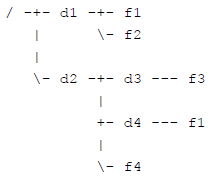ImageNet Classification with Deep Convolution Nerual Networks
论文原文:ImageNet Classification with Deep Convolutional Neural Networks
1 引言
解决的问题:
提高效率(GPU训练),防止过拟合(dropout)
关键点:
· 大量带标签数据——ImageNet
· 高性能计算资源——GPU(GPU搭配了高度优化的2D卷积实现,强大到足够促进有趣大量CNN的训练)
· 合理算法模型——CNN深度卷积网络(与具有层次大小相似的标准前馈神经网络相比,CNNs有更少的连接和参数,因此它们更容易训练,而它们理论上的最佳性能可能仅比标准前馈神经网络稍微差一点)
创新点:
· 采用ReLu加快大型神经网络训练
· 采用LRN
· 采用Overlapping Pooling提升指标
· 采用随机裁剪翻转及色彩扰动增加数据多样性
· 采用Dropout减轻过拟合
2 数据集
ImageNet 包含各种分辨率的图像,而我们的系统要求固定的输入维度。
预处理:将图像进行下采样到固定的256×256分辨率。
1)给定一个矩形图像,首先缩放图像短边长度为256;
2)然后从结果图像中裁剪中心的256×256大小的图像块。
除了在训练集上对像素减去平均活跃度外,我们不对图像做任何其它的预处理。因此我们在原始的RGB像素值(中心化的)上训练我们的网络。
3 The Architecture 网络结构
AlexNet的网络结构如图所示。它总共包含八层可学习的层——五层卷积层和三层全连接层。

3.1 ReLU Nonlinearity ReLU非线性激活函数
对模型神经元输出的标准激活函数: 或者
。
整流线性单元(ReLUs):在训练阶段使用梯度下降算法,在训练期间,这种饱和非线性函数的速度显著慢于非饱和非线性函数 。
ReLU优点:使网络训练更快;防止梯度消失(弥散),使网络具有稀疏性。
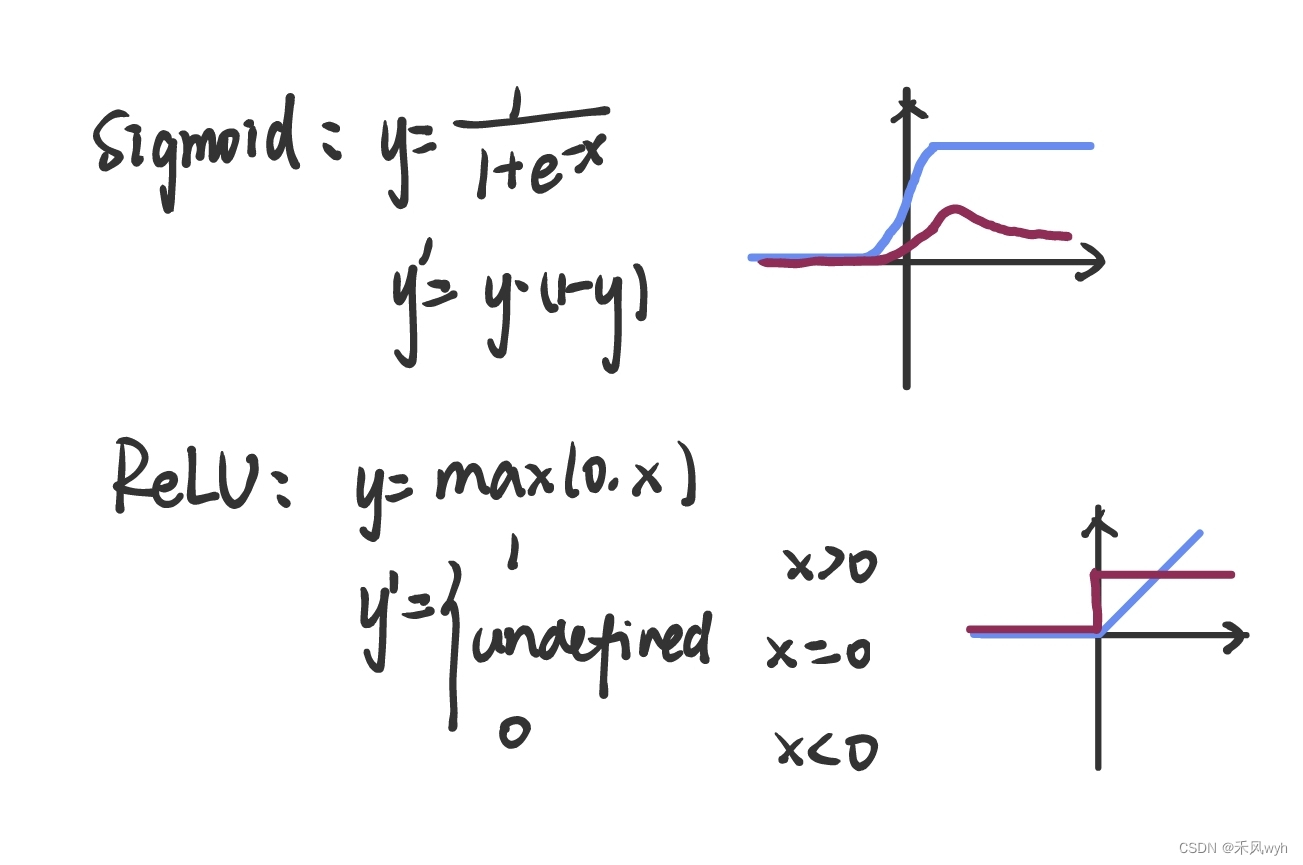
结果:用ReLUs训练的卷积神经网络比用tanh训练的网络快几倍。在与传统饱和神经元模型做对比时,我们不需要用大型神经网络来做该实验。

3.2 Training on Multiple GPUs 多张GPU训练
优点:
1)当前的GPUs能够有效的跨GPU并行——精确的控制交互的数量从而达到可接收的总计算量
2)能够互相直接读取彼此的内存,还不用增加即时内存——将神经元在每张GPU上放一半
并行机制的限制:GPUs的通信只限于特定的层。例如,第三层可以得到第二层的所有神经元输出。可是第四层就只能得到位于同一GPU的第三层的输出。
3.3 Local Response Normalization 局部响应归一化
ReLUs优势:不需要输入的归一化来避免饱和。如果一些训练样本给予ReLU正向刺激输入,在该神经元就能进行有效学习。
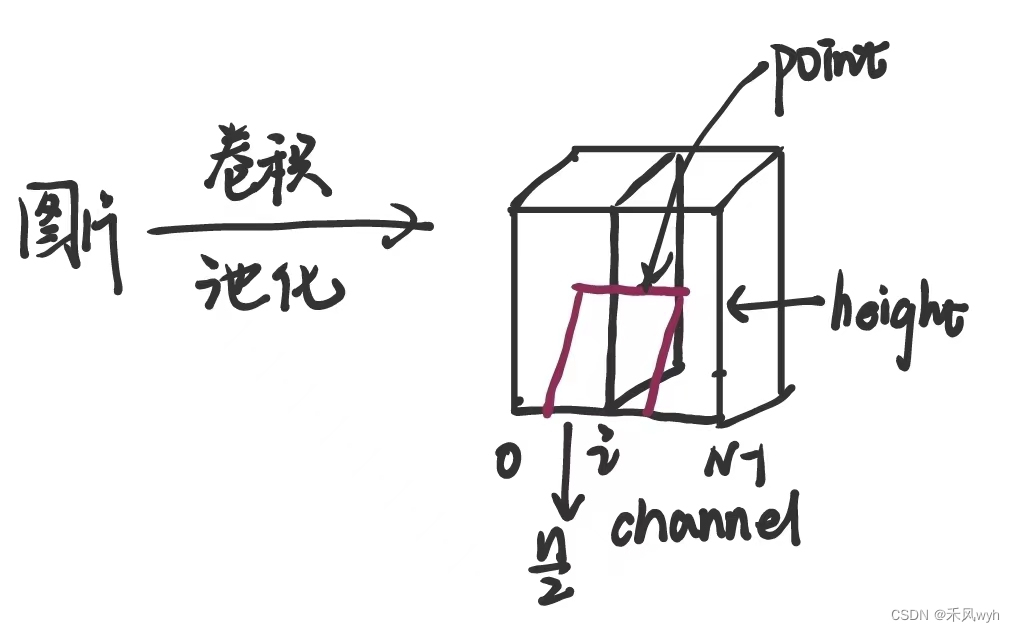
LRN能够避免泛化:定义 为核i 在位置 (x,y) 的神经元,然后使用ReLU非线性激活函数,对应的局部响应归一值
的表达式展示如下:
其中,,
, n,
都为常数,a为特征图中i对应像素具体值,i为通道channel
侧向抑制:lateral inhibition

3.4 Overlapping Pooling 重叠池化
CNN中的池化层只是将同一内核映射层的相邻单元进行了池化。按传统方式,相邻的池化单元是不重叠的。
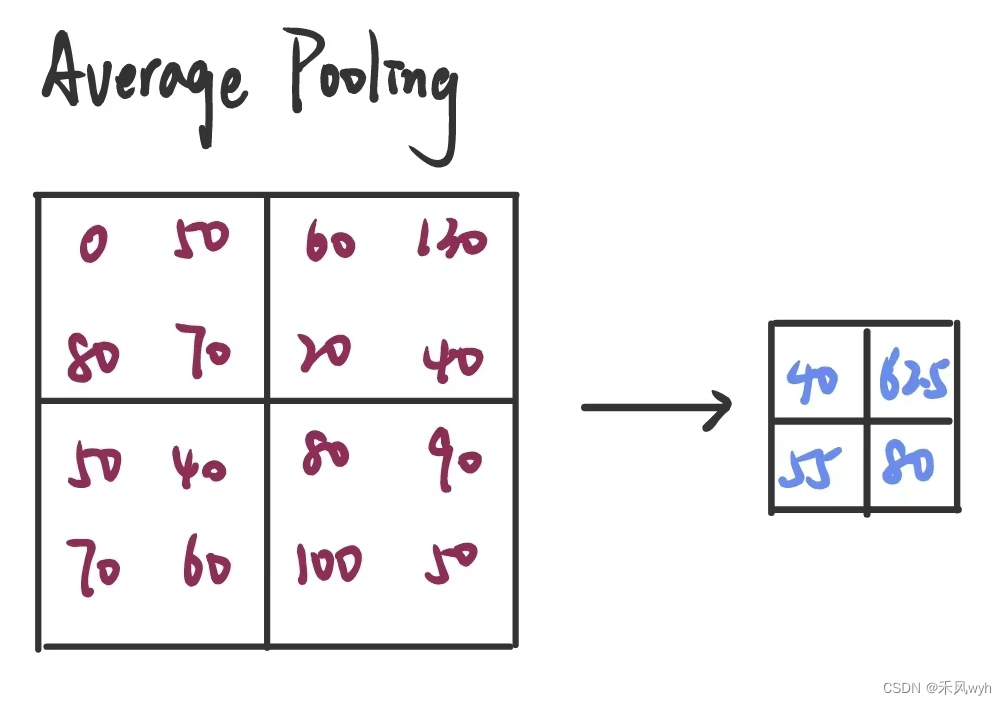
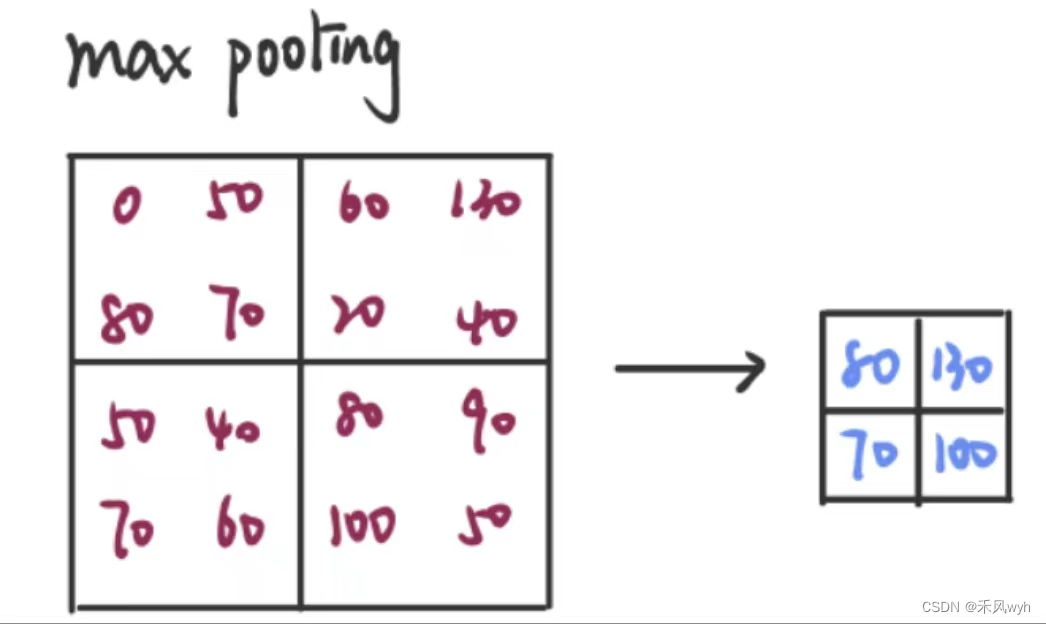
重叠池化机制分别降低了错误率top-1 0.4个点以及错误率top-5 0.3个点。我们同样发现用重叠池化训练的模型能够有效缓解过拟合。
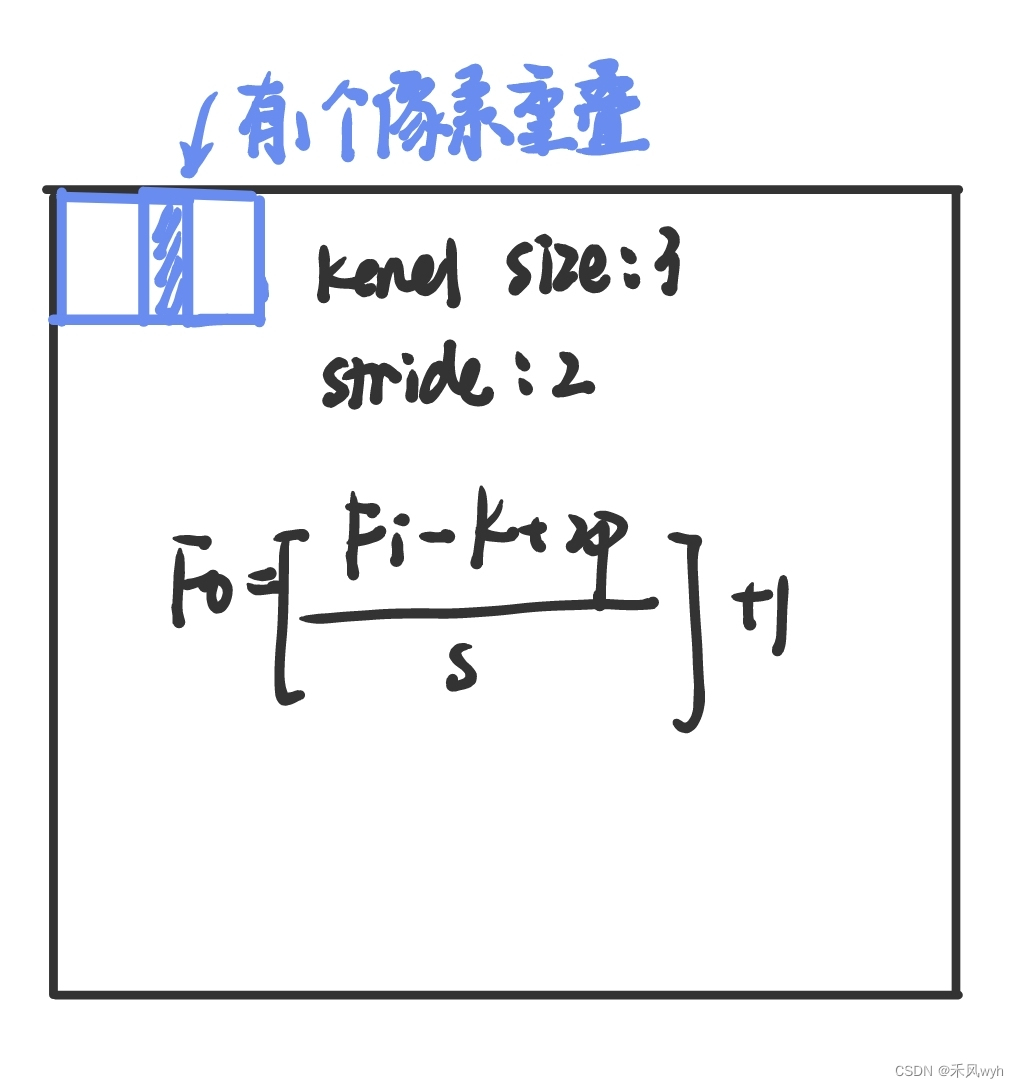
3.5 Overall Architecture 整体架构
网络总共包含8层及其权重,刚开始五层是卷积层,后三层是全连接层。最后一个全连接层的输出为1000大小的softmax,包含1000种类的分布。我们的网络最大化多项逻辑回归目标,这相当于最大化基于训练样例的预测分布下正确标签的对数概率的平均值。
第2,4,5卷积层只与同一GPU的前一层输出相关。第三层卷积层与第二层的所有输出相关。全连接层中的神经元与前一层的所有神经元相连。局部响应归一化层在第一、二层卷积层。第五层卷积层包括3.4节中所讨论的最大池化层以及局部响应归一化层。ReLU非线性激活函数用于每一层卷积层和全连接层。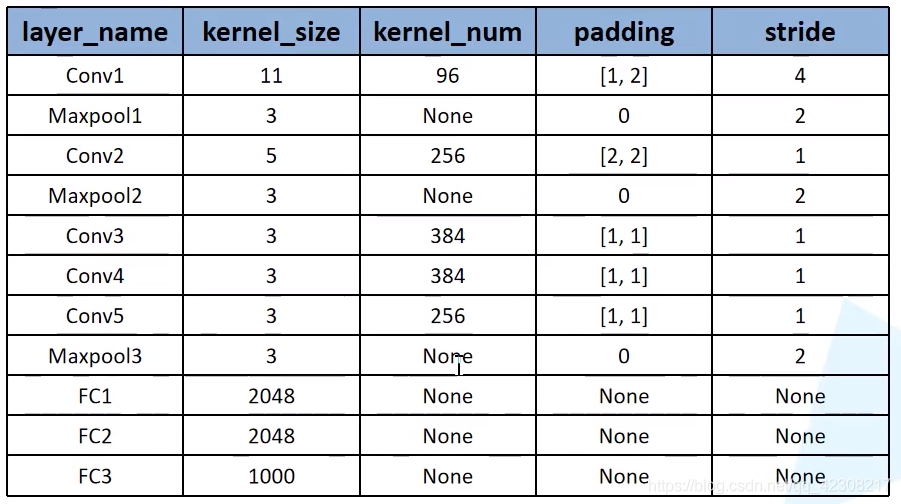
4 Reducing Overfitting 降低过拟合
4.1 Data Augmentation 数据增强
用于图像数据集降低过拟合的最简单以及最常用的方式是用标签保留转换(label-preserving transformations)来增强数据集。
我们使用两种直接的数据增强方式,只需要很少的计算量就可以从原数据集中产生新的转换图像,因此这种增强后的图像不需要保存在磁盘。
第一种方式:针对位置
训练阶段:
1)图片统一缩放至256x256
2)随机位置裁剪出224x224区域 ——(256-224)的平方
3)随机进行水平翻转 ——(256-224)的平方*2
测试阶段:
1)图片统一缩放至256x256
2)裁剪出5个224x224区域(左上角、右上角、左下角、右下角、中心)
3)均进行水平翻转,共得到10张224*224图片
第二种方式:
通过PCA方法修改RGB通道的像素值,实现颜色扰动,效果有限,将top-1错误率降低了1%。
4.2 Dropout
随机失活——weight = 0,无连接无权值,以这种方式"退出"的神经元不参与前向传播,也不参与反向传播。
训练&测试两个阶段的尺度发生变化,测试时,神经元输出值需*p。
效果:每次呈输入时,神经元都会得到不一样的架构,但所有这些架构都是权值共享的。这种技术减少了神经元复杂的协同适应,因为神经元不能依赖于特定其他神经元的存在。因此,这种方式能够使得神经元从不同随机子集合中学到更鲁棒的特征。
前两层全连接层中使用dropout。没有dropout的加持,我们的网络面临着严重的过拟合问题。Droput使得需要两倍的迭代周期实现收敛。
5 启发点
(1)深度与宽度可决定网络能力
(2)更强大的GPU及更多数据可进一步提高模型性能
(3)图片缩放细节,对短边先缩放
(4)ReLU不需要对输入进行标准化来防止饱和现象,即说明Siagmoid/tanh激活函数有必要对输入进行标准化
(5)卷积核学习到频率、方向和颜色特征
(6)相似图像具有“相近”的高级特征
(7)图像检索可基于高级特征,效果应该优于基于原始图像
(8)网络结构具有相关性,不可轻易移除某一层
(9)采用视频数据,可能有突破
代码
1. 网络结构
import torch.nn as nn
import torch
class AlexNet(nn.Module): # 定义类
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__() # 继承
self.features = nn.Sequential(
# 特征提取
# 卷积层:output_width=(input_width-kernel_size+2*padding)/stride+1
# output_height=(input_height-kernel_size+2*padding)/stride+1
# 最大池化层:output_width=(input_width-pool_size)/stride+1
# output_height=(input_height-pool_size)/stride+1
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2),
# 第一层卷积层input[3, 224, 224], output[48, 55, 55], 输入通道数, 输出通道数
nn.ReLU(inplace=True),
# 激活函数
nn.MaxPool2d(kernel_size=3, stride=2),
# 第一层最大池化层output[48, 27, 27],输出通道数不变,只改变尺寸
nn.Conv2d(48, 128, kernel_size=5, padding=2),
# 第二层卷积层output[128, 27, 27]
nn.ReLU(inplace=True),
# 激活函数
nn.MaxPool2d(kernel_size=3, stride=2),
# 第二层最大池化层output[48, 27, 27],输出通道数不变,只改变尺寸
nn.Conv2d(128, 192, kernel_size=3, padding=1),
# 第三层卷积层output[192, 13, 13]
nn.ReLU(inplace=True),
# 激活函数
nn.Conv2d(192, 192, kernel_size=3, padding=1),
# 第四层卷积层output[192, 13, 13]
nn.ReLU(inplace=True),
# 激活函数
nn.Conv2d(192, 128, kernel_size=3, padding=1),
# 第五层卷积层output[128, 13, 13]
nn.ReLU(inplace=True),
# 激活函数
nn.MaxPool2d(kernel_size=3, stride=2),
# 第五层最大池化层output[128, 6, 6],输出通道数不变,只改变尺寸
)
self.classifier = nn.Sequential(
# 分类器
nn.Dropout(p=0.5),
# Dropout概率
nn.Linear(128 * 6 * 6, 2048),
# 第六层全连接层128*6*6进行平展
nn.ReLU(inplace=True),
# 激活函数
nn.Dropout(p=0.5),
# Dropout概率
nn.Linear(2048, 2048),
# 第七层全连接层
nn.ReLU(inplace=True),
# 激活函数
nn.Linear(2048, num_classes),
# 第八层全连接层(num_classes为类的数量)
)
if init_weights:
self._initialize_weights()
#初始化权重
def forward(self, x):
# 实现了网络的前向计算过程:输入图像经过特征提取部分后被平展成一维张量,最后通过分类器部分得到最终的分类结果
x = self.features(x)
# 特征提取
x = torch.flatten(x, start_dim=1)
#平展
x = self.classifier(x)
#分类器
return x
def _initialize_weights(self):
# 用于初始化模型的权重
for m in self.modules():
if isinstance(m, nn.Conv2d):
# 对卷积层使用kaiming_normal_初始化方法
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
# 如果偏置不为None,则使用nn.init.constant_函数将偏置初始化为常数0
if isinstance(m, nn.Linear):
# 对全连接层使用normal_初始化方法
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
# 用nn.init.constant_函数将偏置初始化为常数02. 训练过程
# 若当前有可使用的GPU设备,就是用第一块GPU来进行训练,若没有则使用CPU训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
# 对数据进行预处理
data_transform = {
# 当Key为train时
"train": transforms.Compose([transforms.RandomResizedCrop(224),
# 将图片随机裁剪成224×224像素大小
transforms.RandomHorizontalFlip(),
# 将图片在水平方向上随机翻转
transforms.ToTensor(),
# 转化成tensor类型
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
# 进行标准化处理
# Key为val时
"val": transforms.Compose([transforms.Resize((224, 224)),
# cannot 224, must (224,224)将图片缩放成224×224的
transforms.ToTensor(),
# 将图片转化成tensor类型
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
# 进行标准化处理
# 读取训练集和测试集并且采用对应的图片处理方式
train_dataset = datasets.ImageFolder(root="flower_data/train",
transform=data_transform["train"])
validate_dataset = datasets.ImageFolder(root="flower_data/val",
transform=data_transform["val"])
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
# 训练相关参数设置
batch_size = 32
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=0)
net = AlexNet(num_classes=5, init_weights=True)
net.to(device)
# 定义一个损失函数
loss_function = nn.CrossEntropyLoss()
# 定义一个优化器_Adam
optimizer = optim.Adam(net.parameters(), lr=0.0002)
def train(dataloader,net,loss_function,optimizer):
# 设定训练次数
epochs = 10
# 设置模型存储路径
save_path = './AlexNet.pth'
# 用来记录最优的正确率
best_acc = 0.0
# 一共有多少个batch(训练集数目 / batch_size),用于后面求平均损失
train_steps = len(train_loader)
# 开始迭代
for epoch in range(epochs):
# train
# 启用Dropout方法
net.train()
# 记录每一次的损失,所以每次迭代都清0
running_loss = 0.0
# 生成一个迭代器
train_bar = tqdm(train_loader, file=sys.stdout)
# 通过enumerate获得迭代器的索引和值
for step, data in enumerate(train_bar):
# 将值赋给图像和标签
images, labels = data
# 每次迭代都清空梯度
optimizer.zero_grad()
# 将图像送入到网络训练(注意添加到设备)
outputs = net(images.to(device))
# 将输出值和实际值做对比,计算损失(注意labels也要添加到设备)
loss = loss_function(outputs, labels.to(device))
# 将损失反向传播
loss.backward()
# 通过优化器更新节点参数
optimizer.step()
# print statistics
# 将每一次的损失累加,用于求平均损失
running_loss += loss.item()
# 输出进度
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
# 禁用Dropout方法
net.eval()
# 用来记录正确预测的个数
acc = 0.0
# 不需要计算梯度也不进行反向传播
with torch.no_grad():
# 生成一个迭代器
val_bar = tqdm(validate_loader, file=sys.stdout)
# 开始验证过程
for val_data in val_bar:
# 将值赋给图像和标签
val_images, val_labels = val_data
# 将图像送入到网络训练(注意添加到设备)
outputs = net(val_images.to(device))
# 在outputs的第1维找最大值;返回的第0维是最大值,第1维是最大值对应的标签;[1]将标签赋给predict_y
predict_y = torch.max(outputs, dim=1)[1]
# 将预测值与实际值对比,相同返回1,否则返回0,求和可得正确的个数,通过item()获得其值
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
# 求预测正确率
val_accurate = acc / val_num
# 打印迭代次数,平均损失,预测正确率
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
# 找到正确率最高的模型参数,存到目录
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)3. 预测过程
# 用GPU训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 图片预处理:缩放,转换成tensor,归一化
data_transform = transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 获取图片路径
img_path = "sunflower1.png"
img = Image.open(img_path)
# 显示图片
plt.imshow(img)
# 对图片进行预处理,载入的图片是[H, W, C],经过预处理后会自动把深度提前[C, H, W]
img = data_transform(img)
# 要求的输入有四个维度,所以给图片加一个维度变为[N, C, H, W]
img = torch.unsqueeze(img, dim=0)
# 获取记录类别名称的json文件
json_path = 'class_indices.json'
# 解码成我们需要的字典
with open(json_path, "r") as f:
class_indict = json.load(f)
# 初始化网络
model = AlexNet(num_classes=5).to(device)
# 载入权重
weights_path = "AlexNet.pth"
# 利用torch.load加载权重并利用model.load_state_dict()函数把加载的权重复制到模型的权重中去
model.load_state_dict(torch.load(weights_path))
# 禁用Dropout方法
model.eval()
# 不需要计算梯度也不进行反向传播
with torch.no_grad():
# predict class
# 将图片送入网络,利用squeeze注意要将tensor转换到CPU,因为后面的numpy是CPU-only
output = torch.squeeze(model(img.to(device))).cpu()
# 利用softmax函数使输出满足概率分布
predict = torch.softmax(output, dim=0)
# 获取概率最大处所对应的索引值
predict_cla = torch.argmax(predict).numpy()
# 在记录类别名称的json文件中利用索引获取类别,并且利用索引获得类别对应的概率
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
# 打印出该图片归于每一类的概率
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
# 画图(包括图片展示和归于的最大可能类及其概率)
plt.show()