大家好啊,我是董董灿。
在学习自然语言处理(NLP,Natural Language Processing)时,最先遇到的一个概念,可能就是词嵌入(word embedding)了。
词嵌入,是让AI真正理解人类自然语言的技术(看完本文再回过头来看这句话,或许会有不一样的认识)。
那什么是词嵌入呢? 在自然语言处理中为什么需要词嵌入技术呢?
1、什么是词嵌入?
词嵌入,英文 Word Embedding,是自然语言处理中的一项关键技术。简单来说,它就是把单词或汉字转换成向量的过程。
我们知道,计算机在处理任何形式的数据时,处理的都是数字,更极端点处理的都是二进制数字。
不论是显示图片、文本,还是播放语音、视频,在计算机看来都是数据流。
因此,计算机在处理文本时,只有将文本转换成数字形式才能进行计算,而词嵌入就是为了解决这个问题。
它将每个单词映射成一个向量,这个向量可以用来表示这个单词的语义和特征。
举个例子,我们可以把“苹果”这个单词映射成一个向量[0.2, 0.9, -0.1, ...],把“香蕉”映射成[0.5, -0.3, 0.8, ...],这样计算机在看到向量[0.2, 0.9, -0.1, ...]时,就能够理解这个单词是“苹果”了。
2、为什么需要词嵌入?
我猜你肯定会问一个问题:为什么不直接用数字来表示单词,而非要搞出一个向量呢?
这是因为单纯用数字表示单词,会丢失掉很多有用的信息。
比如,假设用数字1代表“苹果”,用数字2代表“香蕉”,虽然这样可以区分出“苹果”和“香蕉”,但是无法表示他们之间的关系。
而词嵌入的好处在于,它能够在向量空间中保持单词之间的相似关系,也就是说,语义相近的单词在向量空间中会有相近的表示。
举个例子,我们用一个二维向量表示单词,可以把“苹果”表示为[1, 1],把“香蕉”表示为[2, 2]。
在这个向量空间中,你会发现这两个向量非常接近(可以更科学的计算两者之间的距离),因为它们的含义很相似,这点其实和one-hot编码有点像,可以查看 5分钟理解 one-hot 编码。
这样的表示方式使得计算机能够更好地理解单词之间的关系,比如在文本分类、情感分析等任务中,word embedding 可以使模型更准确地识别单词的含义和上下文。
3、一个例子
接下来看一个例子,来更直观地理解 word embedding 的作用。
假设我们要对一篇文章中的单词进行编码,有四个单词:“猫”、“狗”、“鱼”、“跑”。
首先,用数字表示这些单词:
- 猫:1
- 狗:2
- 鱼:3
- 跑:4
如果我们只是用数字表示,那么计算机只能知道它们是不同的单词,无法确定“猫”和“狗”更接近,还是“鱼”和“跑”更接近,因为他们之间的数值都相差1。
现在我们来用 word embedding 方法来表示这些单词,词向量可能是:
- 猫:[0.2, 0.7]
- 狗:[0.3, 0.9]
- 鱼:[-0.5, 0.2]
- 跑:[0.8, -0.1]
将这四个向量画在坐标轴上,如图所示:
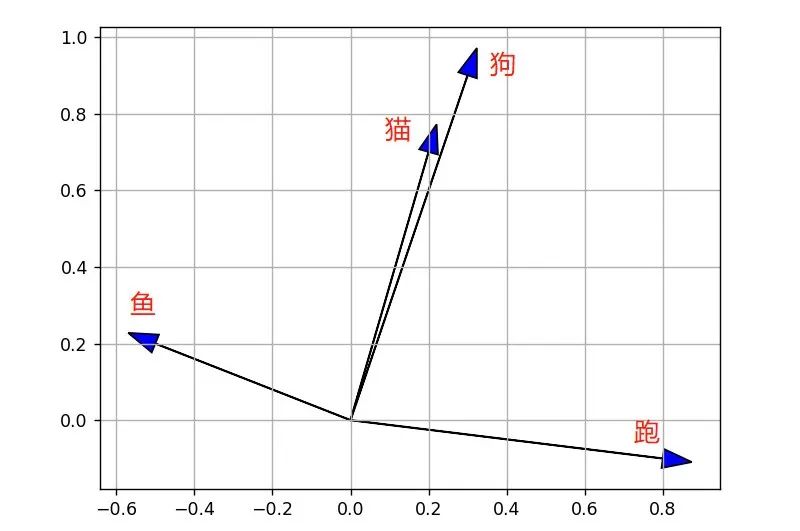
可以看到,“猫”和“狗”这两个向量非常接近,因为它们都属于动物,“鱼”和“跑”这两个向量则相距很远,因为它们不论属性还是含义都相差很远。
这样的表示方式让计算机能够更好地理解单词之间的关系,比如在文本分类任务中,当计算机遇到一个句子“猫和狗在跑”,它会知道“猫”和“狗”是相似的词,而“跑”则和它们有些不同。
通过 word embedding 技术,将单词转换成向量表示,保留了单词之间的语义和特征关系,这样计算机便能够更准确地理解文本中的含义和语义关系,从而提高自然语言处理的性能。
中华上下5000年,那么多单词和文本,计算机是如何把大量的文本转换到向量空间,同时维持不同对应的向量之间的远近关呢?这需要专门的模型来处理,比如 word2vec 模型等等,后面会逐步写一写。
欢迎持续关注“董董灿是个攻城狮”,一起拆解好玩的算法。