计数服务如何实现
回顾需求

对于可扩展:对写入的数据进行分区。
对于高性能:借助缓存技术的处理,为了提高吞吐量,需要做批量batch批处理
对于高可靠:不丢数据,需要对数据进行持久化,还要借助复制技术 replication
数据聚合(aggregation)基础
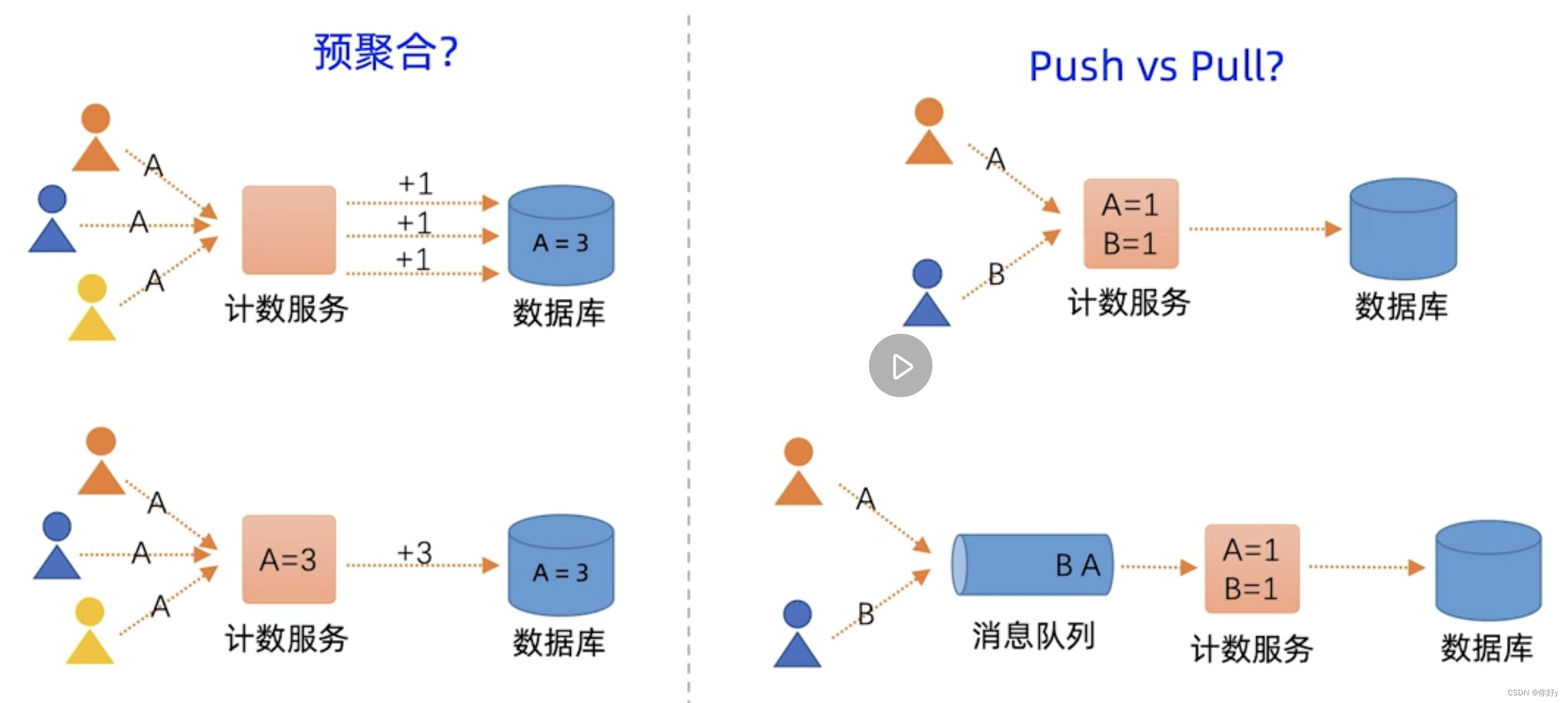
对于技术问题,有两种解决思路:
- 每次把用户观看一个视频,在数据里面视频计数+1。
- 先在计数服务的内存里头进行批量聚合运算,在定期将这个结果异步写入到DB
在大规模数据处理的时候,提高吞吐量,采用预聚合+批处理的方式
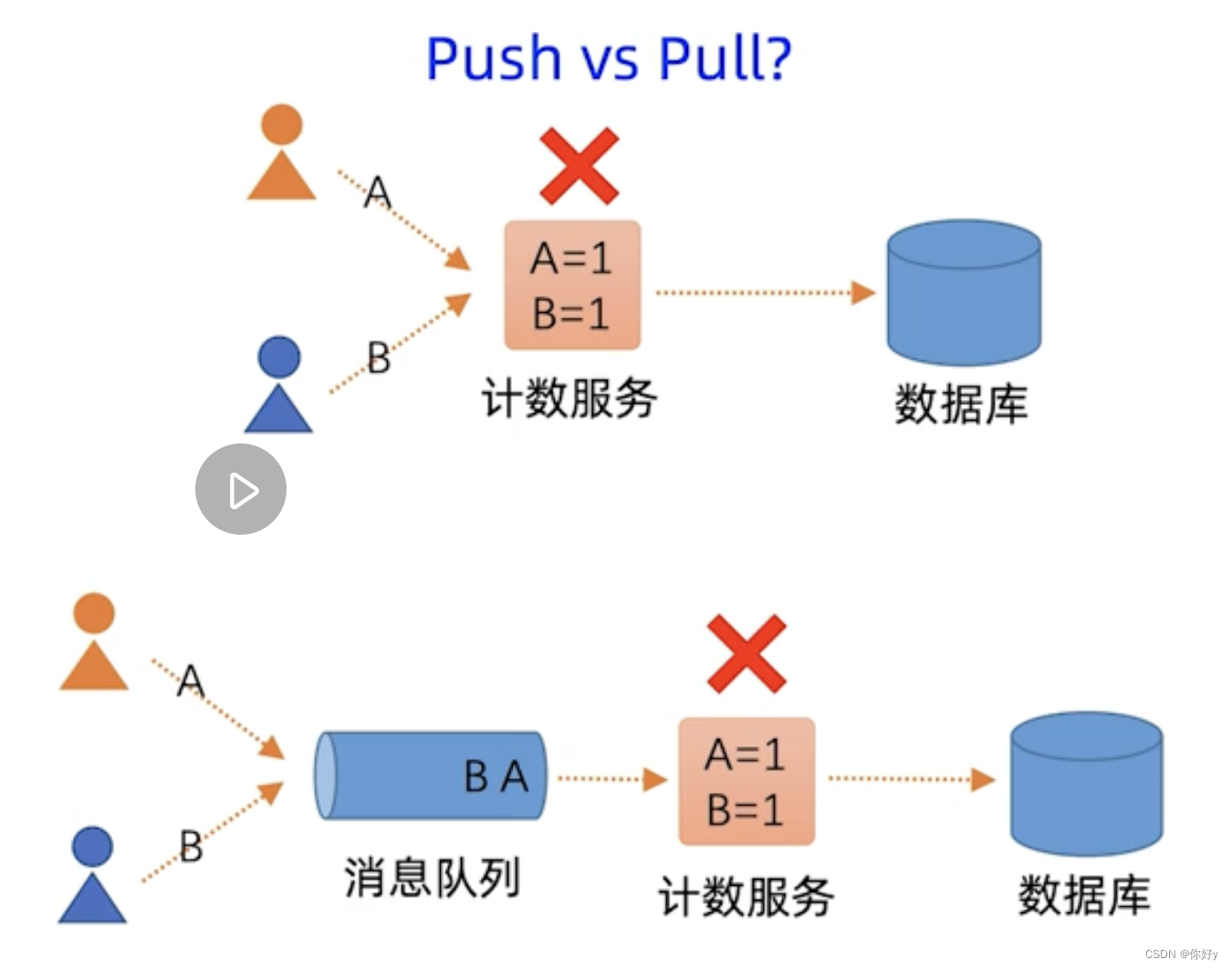
如果技术服务挂了,数据丢失,不能满足高可用。
将用户的请求先放在消息队列缓冲里面,然后计数服务再从这个MQ当中拉取请求计算,是一种pull 拉模式。
起到了流量削峰的作用。同时引入MQ将生产和消费两方面进行解耦 。即便计数服务需要下线进行维护升级, MQ仍然可以缓冲消息,不会丢数据, 实现了高可用。
消息队列基础
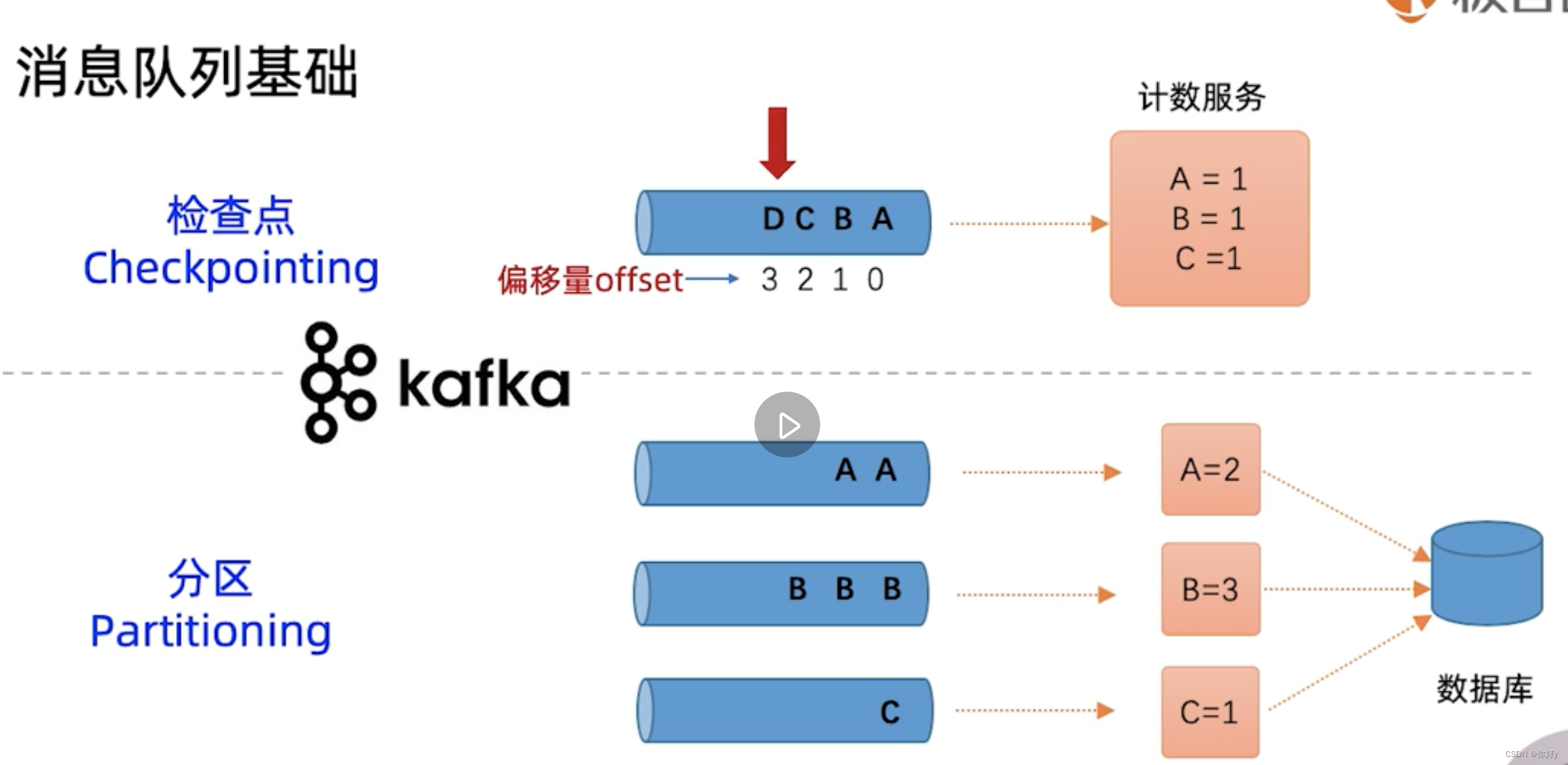
每次消费一个元素,消费指针都会递增1。Kafka 的消费指针对应了数据处理当中的概念:检查点 Checkpoint。检查点的值必须被保存起来,必须记住已经消费到哪个下标了,下次如果消费者重启,他就可以从 Checkpoint 开始消费,不会丢失消息。
在kafka 中为了提高消费性能,消费指针并不是实时同步提交的,而是定期异步提交的,所以消费者重启可能会出现重复消费的情况。
分区 Partitioning :和数据分区是一样的,如果数据量大,消息队列也要对消息进行分区存储。
计数消费者设计
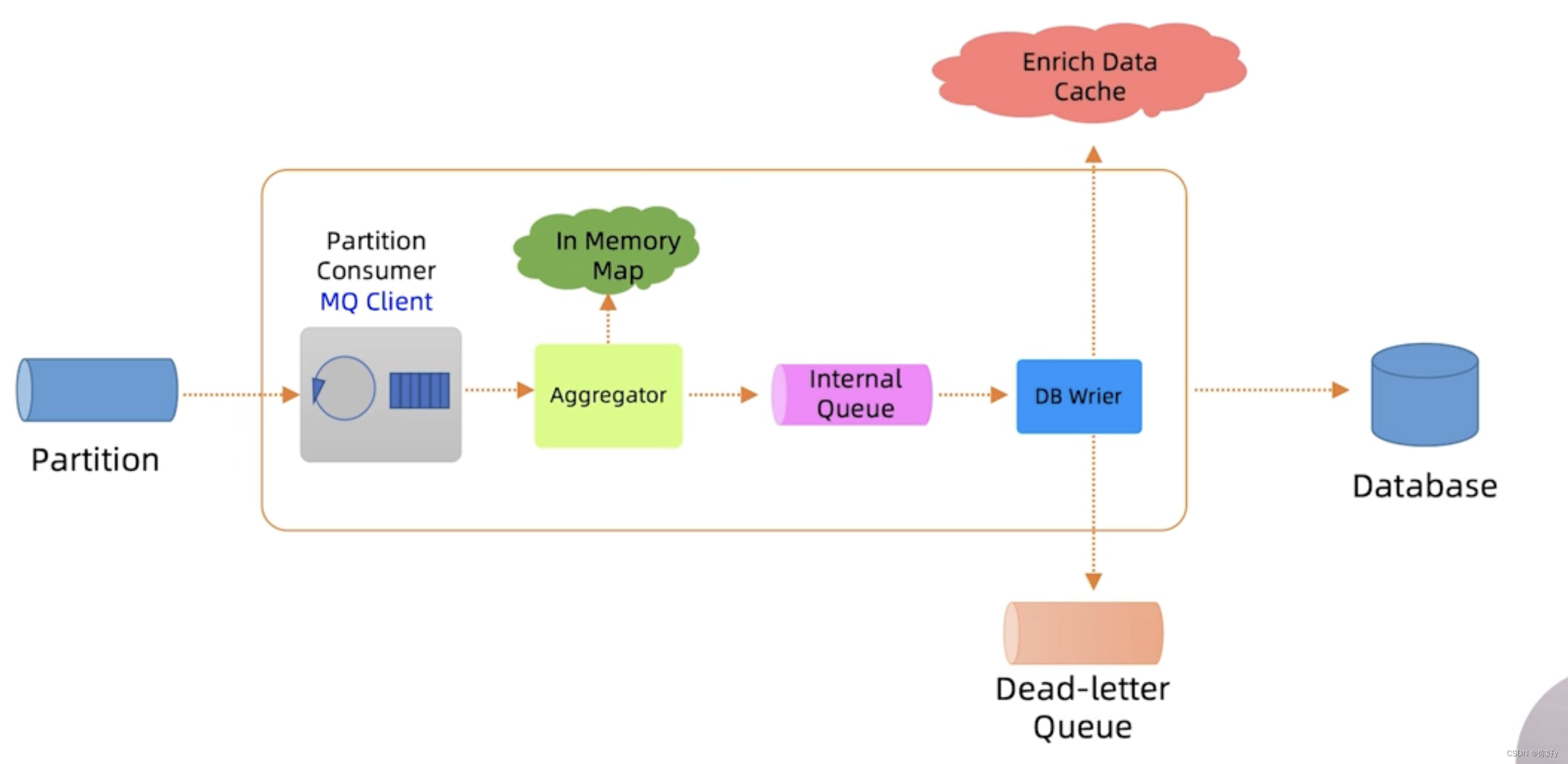
消费者的内部也需要一个小型的数据处理的流水线。
- 流水线中的第一个角色叫分区消费者,他负责拉取对应的分区当中的消息,并且缓冲在内存的队列当中。
分区消费者角色一般由MQ的客户端来承担。比如 kafka client
kafka client 还具有自动提交偏移的功能,也就是 CheckPoint 的功能
- 流水线的第二个角色就是聚合运算程序 Aggregator
开发者自己开发,它消费内存队列当中的消息实现聚合运算逻辑。
对于计数服务的 Aggregator ,它就负责对视频的每分钟的观看量进行累加计算。消费运算可以用多线程并发来做。具体可以采用 ConcurrentHashmap来实现。
Aggregator 会定期每分钟将计算结果写入到内部的另一个队列。
为什么还要在引入一个队列,不直接写入DB呢?
原因还是考虑高可用,DB可能会慢或者暂时不可用,如果没有内部的队列做缓冲,那么计算结果可能会丢失。
内部队列可以采用磁盘持久化的队列或者嵌入式的DB
- 流水线的最后一个角色是DB Writer,它负责将内部队列当中的计算结果最终写入到DB当中。
为了高可用性,引入了死信队列。如果DB writer 暂时无法写入DB,它可以将结果写入到死信队列。然后引入后台线程 ,单独处理死信队列,重试再写入DB,这样可以不丢失数据。
DB Writer 在写入DB之前。还需要做一些数据填充的工作 Data Enrichment。如果DB Writer 每次都到其他的DB去查询数据性能会比较慢,可以引入缓存 Enchrich Data Cache ,这个缓存可以是Redis 缓存,也可以是消费者本地嵌入式的缓存
举一反三: 实现每小时或者每天的聚合:我们可以把每分钟的聚合再发送回 Kafka 队列,再按每小时进行聚合。
数据接收路径
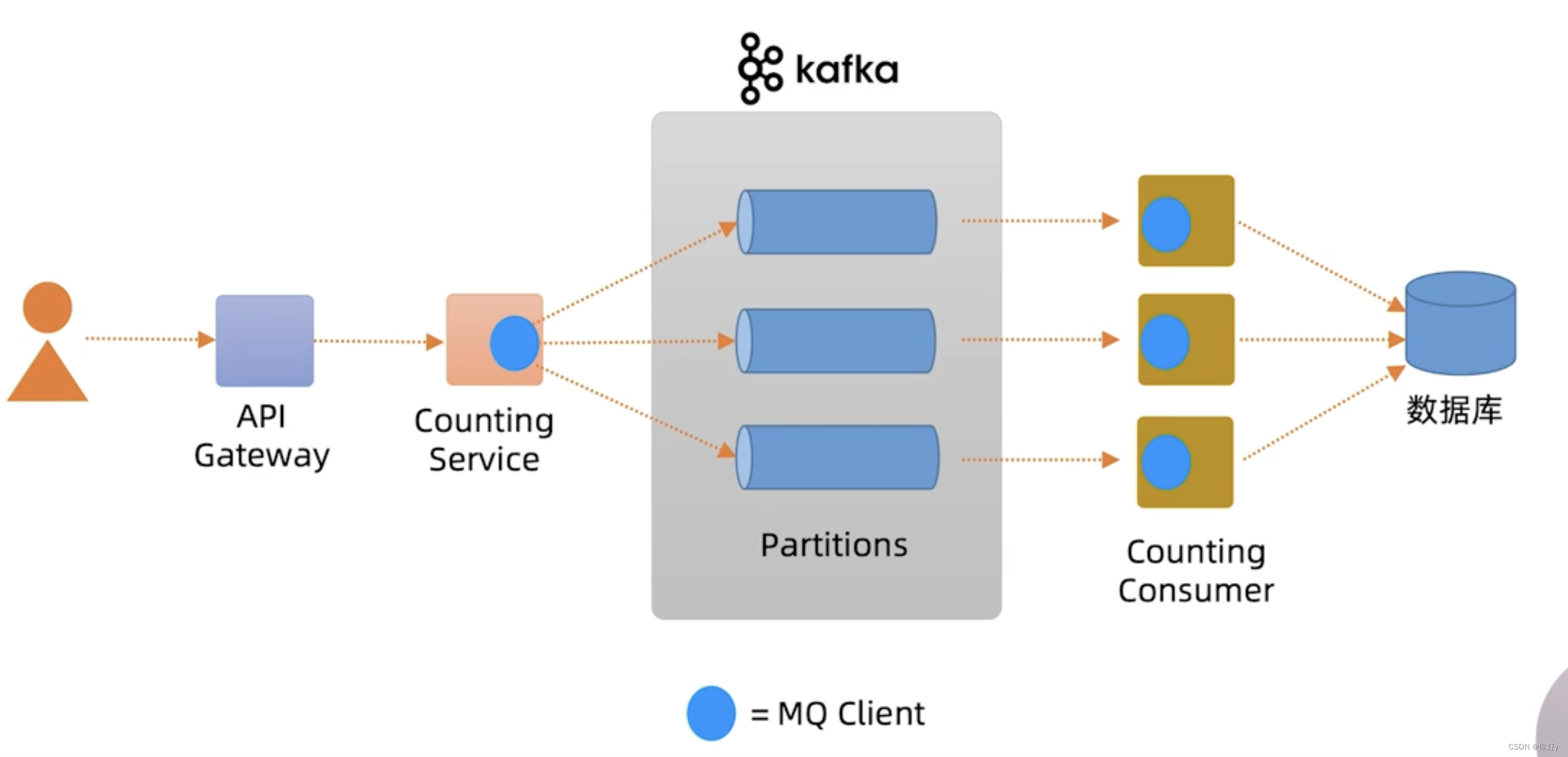
用户点击观看视频,请求先辈转发到 API 网关,API 网关将请求转发到 Counting Service, Counting Service 是通过MQ Client将请求转发到MQ 的某个分区队列,在后台 Counting Consumer 消费对应的 MQ 分区的消息进行聚合运算,最终将结果写入DB 。
数据接收路径上的面试题
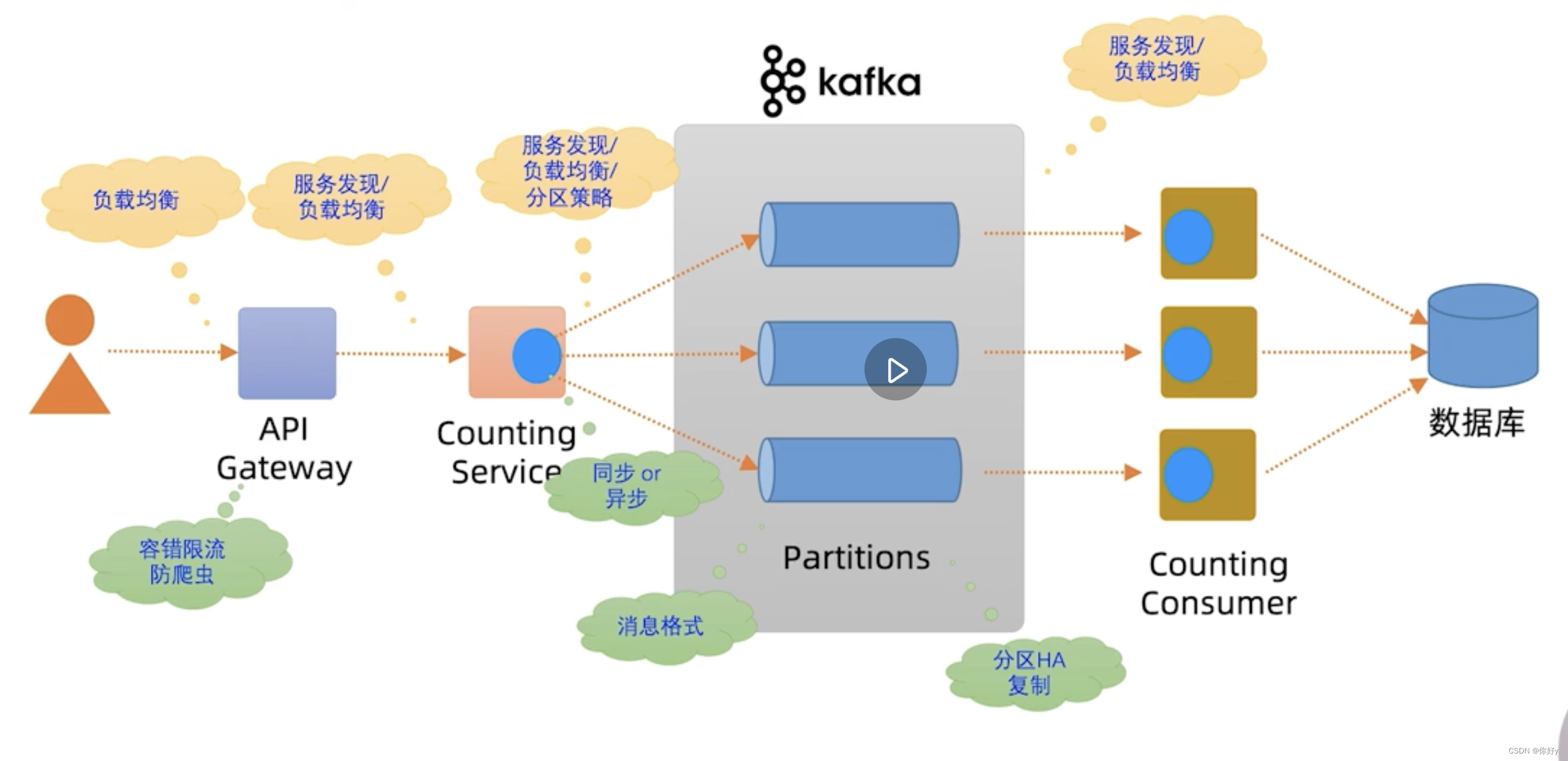
问题:
1、如何实现对 API Gateway 的负载均衡访问
实际上API Gateway 也是要以集群方式部署的,才能实现高可用访问。所以它的前置也还需要负载均衡器,比如软件Nginx 或者硬件 F5
2、API Gateway 怎么发现 Counting Service 的实例
传统集中式的做法: 采用Nginx + DNS 。或者微服务注册中心的做法,比如说采用 Eureka 注册中心 + Ribbon 客户端
3、API 网关如何实现容错限流
引入 Hystrix 容错限流组件
4、消息存在MQ 上这个消息格式的存储问题
可以采用二进制,比如 protobuf 格式,也可以采用文本格式,比方说 json 格式