大数据面试之MapReduce常见题目
MapReduce中Shuffle过程及优化
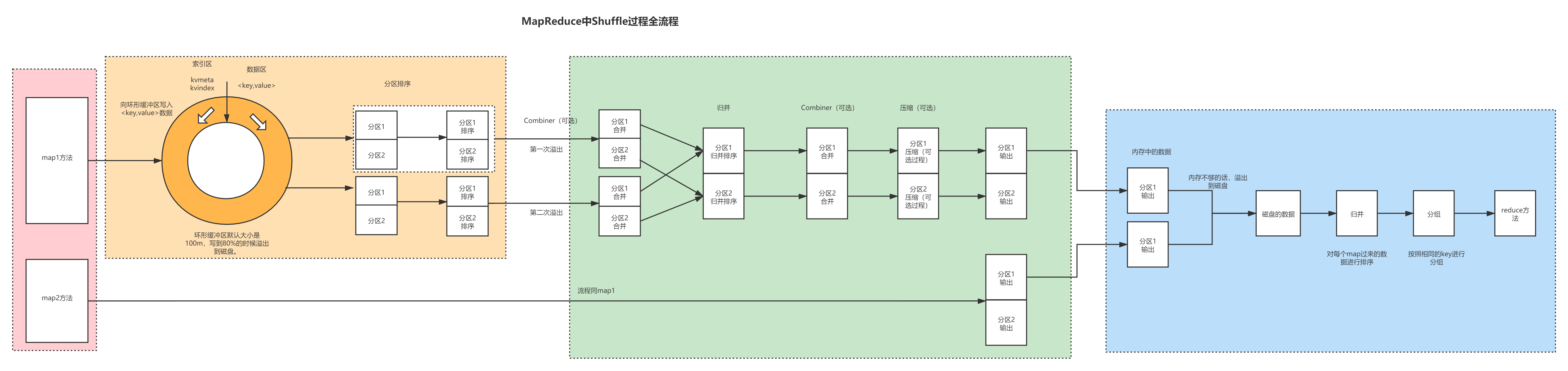
1.1 Shuffle的详细图解
1.2 Shuffle的详细文字过程
Shuffle文字部分描述:
Shuffle横跨Map和Reduce阶段,是指map()方法之后,reduce()方法之前,中间这段汇洗的过程,叫做Shuffle。Shuffle是最消耗性能的。具体过程如下:
1.2.1 分区
1、首先数据经过map()方法之后进入环形缓冲区,进入环形缓冲区的时候有些参数,一个参数是getPartition()方法,这个方法是标记数据是哪一个分区的,之所以要提前进行分区标记,是因为后续所有的操作都是在分区内进行处理的,这样效率会高些。否则就是给所有的数据都放到一起,最后在排序、归并、等完毕了之后,再给分区圈出来,效率比较低。所以提前分区,后续数据都是分区内排序,数据在分区内排序,比整体排序再分开效率高些。
1.2.2 环形缓冲区参数
2、数据分区之后进入环形缓冲区。环形缓冲区的大小默认是100M,到达80%的时候,也就是到80M的时候会发生溢写。这个设计是非常巧妙的,之所以不到达100%的时候再溢写,是因为在100%进行溢写的时候是不能接受外部的发送过来的数据的,外部进来的数据只能等待。现在在80%的时候进行溢写,就可以使用剩余两成的空间来接受数据,这样写入流就可以源源不断地进来,基本上无须等待。这样效率高些。
1.2.3 溢写前快速排序
3、接下来进行溢写操作,在进行溢写的时候会产生大量的溢写文件。在溢写之前会在内存中进行排序,排序的方式是快速排序,具体是对key的索引(理解成具体key的hash值)按照字典顺序进行排序。一般情况下,对无序的数据进行排序基本上都是采用快排。另外,对排序一般都是对索引进行排序,比直接对真实的数据进行排序效率会高些。
1.2.4 溢写后归并排序
4、数据溢写出来之后形成了多个文件,对这多个文件需要进行归并排序。因为溢写出来的文件都是在磁盘当中的,而归并是要在内存当中完成。这个时候需要给数据再次加载到内存中,以不同的分区进行归并。另外多说一下,归并一般是对已经有序的数据进行排序,因为溢写文件在溢写之前都已经进行了快速排序了,所以是溢写的都是有序的文件。这个时候再进行归并操作,速度会高些。
1.2.5 归并之后形成分区文件
5、归并完成之后,会再次给内存当中的数据溢写到磁盘当中。按照对应的分区准备到磁盘上面。比如说,形成了对应的0号分区、1号分区的磁盘文件。
1.2.6 Reduce阶段拉取分区数据并排序
6、这个时候就开始进入Reduce阶段。Reduce阶段拉取自己指定分区的数据,拉取过来之后先放到内存当中,内存不够用的情况下,再溢写到磁盘文件中。拉取过来的数据,不管是内存当中的数据还是磁盘当中的数据,都需要重新进行排序,这是因为在拉取数据的时候有可能拉取的是多个上游溢写、归并之后的文件的0号分区的数据。这些数据在各自的文件内部的0号分区有序。但是拉取过来之后就不一定了。所以要进行排序。这个时候对已经有序的数据进行排序,使用归并排序即可。
1.2.7 Reduce阶段数据写出
7、归并完成之后,再给数据写出到Reduce阶段的reduce()方法当中。这个时候通过reduce()方法给结果数据write到磁盘即可。
以上就是Shuffle的详细过程。
1.3 Shuffle优化
1.3.1 Map阶段
(0)getPartition()的时候可以自定义分区(默认分区是key的hash)。可以避免数据可能出现的数据倾斜。比如相同的key有十亿个,这个时候可以给这个key的后面加上一些随机数打散,从而可以进入不同的Reduce进行处理,处理完成之后再给随机数去掉,再合并。从而可以避免数据倾斜。
(1)适当调整环形缓冲区大小。由100m扩大到200m
(2)适当调整环形缓冲区溢写的比例。由80%扩大到90%
上面两步骤操作之所以能优化,本质上上是减少了溢写文件的个数。
(3)对溢写之后的文件默认的归并一次是归并10个文件,可以适当调整对溢写文件的merge次数。比如内存充足的情况下,一次可以20个merge。反之如果内存不充足的话,可以减少合并的文件个数。要根据集群的具体的资源情况进行上下的调整。
(4)在不影响实际业务的前提下,采用Combiner提前合并,减少IO。例如求和就可以采用Combine,求平均值就不可以使用Combine。
(5)压缩。在往磁盘写之前可以进行压缩,压缩减少了磁盘的IO。压缩之后数据变小,往下游传输比较方便。这里可以使用snappy压缩,解压缩速度都比较快,用的相对比较多。
1.3.2 Reduce阶段
(0)增加每个Reduce去Map中拿数据的并行数。
在企业当中一般可能是100多个MapTask,Reduce在拉取分区数据的时候会一次性拉取100多个MapTask的结果的0号分区的数据吗?不一定。因为内存可能放不下。默认一次性是拉取5个。如果内存比较充足的情况下,可以增大拉取的个数,比如增加到10个。
(1)集群性能不错的前提下,增大Reduce端存储数据内存的大小。
(2)合理设置Map和Reduce数:两者个数设置要适当。太少,会导致Task等待,延长处理时间;太多,会导致 Map、Reduce任务间竞争资源,造成处理超时等错误。
(3)设置Map、Reduce共存:调整slowstart.completedmaps参数,使Map阶段运行到一定程度后,Reduce也开始运行,减少Reduce的等待时间。
1.3.3 IO传输
采用数据压缩的方式,减少网络IO的时间。这个时候要具体情况具体对待。
压缩:
(1)Map输入端主要考虑数据量大小和切片问题,支持切片的有Bzip2、LZO等。注意:LZO要想支持切片必须创建索引。
(2)Map输出端主要考虑速度,速度快的Snappy、LZO。
(3)Reduce输出端主要看具体需求,假如作为下一个MR输入需要考虑切片问题,永久保存的话,考虑压缩率比较大的GZIP。
1.3.4 整体
(0)MapTask内存默认大小为1G,如果数据量是128M,正常不需要调整内存;如果数据量大于128M,可以适当增加MapTask内存,比如可以增加到4-6g。可以通过参数mapreduce.map.memory.mb 控制分配给MapTask内存上限。按照1g内存处理128M的数据进行比例调整即可。
(1)ReduceTask内存默认大小为1G,如果数据量是128M,正常不需要调整内存;如果数据量大于128M,可以适当调整ReduceTask内存大小,比如调整为4-6g。按照1g内存处理128M的数据进行比例调整即可。
(2)这个时候要考虑CPU配置多少,遵循一个 1CU的原则。也就是一般情况下,一个CPU配置 4g 的内存。企业内部一般是这样处理。
声明
声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
B站: https://space.bilibili.com/1523287361 点击打开链接
微博: http://weibo.com/luoyepiaoxue2014 点击打开链接