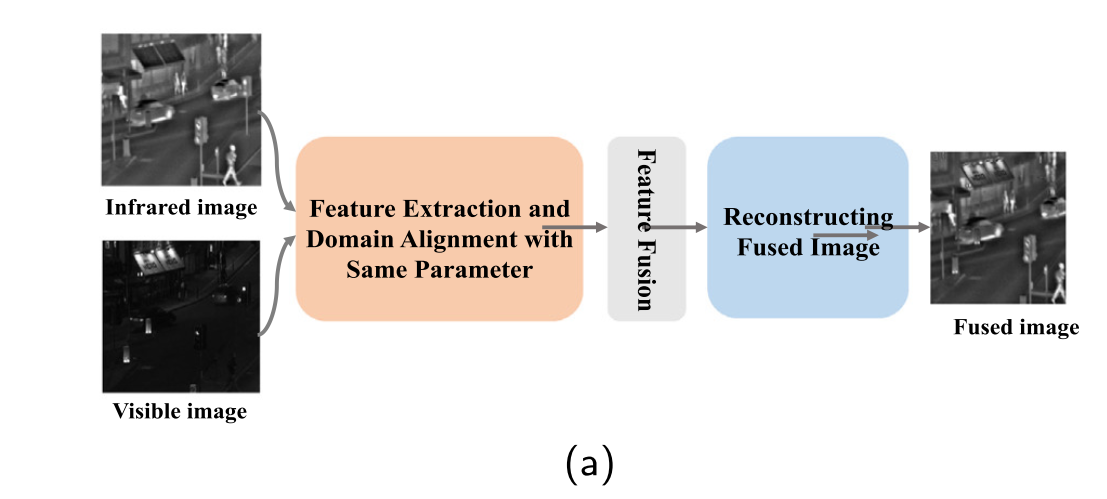
Self-supervised feature adaption for infrared and visible image fusion
(红外和可见光图像融合的自监督特征自适应)
总述:首先,我们采用编码器网络来提取自适应特征。然后,利用两个具有注意机制块的解码器以自我监督的方式重建源图像,从而迫使经过调整的特征包含源图像的重要信息。此外,考虑到源图像包含低质量信息的情况,我们设计了一种新颖的红外和可见光图像融合和增强模型,提高了融合方法的鲁棒性。
介绍
深度学习的方法的融合可以分两类:
1)具有域差异的源图像的特征自适应实现了相同的卷积算子。例如,Liu等人提出了一种用于红外和可见图像的权重图生成的孪生(siamese)卷积网络。Li等将红外图像和可见光图像分解为基础层和细节内容层,然后使用相同的卷积算子提取红外图像和可见光图像的细节内容特征,从而实现特征自适应。Li等提出了DenseFuse架构融合红外和可见光图像,其中编码网络用于特征提取和自适应,然后解码网络用于获得融合结果。总体而言,上述方法对具有相同参数的红外和可见光图像进行了特征提取。但是,由于红外和可见光图像的域差异,相同的卷积算子没有专门的特征提取设计,很容易丢失重要的细节。
2)用生成对抗网络 (GAN) 来处理域差异。GAN 广泛用于多域图像平移。 已经提出了许多基于GAN的红外和可见光图像融合方法,其中可以通过生成器在对抗过程中实现特征自适应。例如马等人开发了一个名为FusionGAN的生成对抗网络,其中采用生成器来生成包含可见纹理细节以及红外热辐射信息,并使用鉴别器来增强融合结果的可见光图像信息。马等人进一步提出了一种双重鉴别器条件生成对抗网络 (DDcGAN),其中双重鉴别器旨在融合红外和可见光的最大数量的信息。此外,提出了许多基于双重鉴别器和注意机制的红外和可见光图像融合方法。例如,Li等人 提出了一种用于红外和可见光图像融合的端到端双重鉴别器Wasserstein生成对抗网络 (D2WGAN),其中第一鉴别器设计用于融合红外图像的像素强度和细节,第二鉴别器用于保留可见图像的纹理信息。为了进一步融合可见图像的前景目标和上下文信息,Li等人将多粒度注意模块集成到由生成器和两个鉴别器构建的融合框架 (MgAN-Fuse) 中。此外,AttentionFGAN 被提出来感知源图像的最有区别的区域,它将多尺度注意力机制集成到生成器和鉴别器中,以帮助捕获注意力区域。这些基于GAN的方法通过生成器生成融合图像,并且通过对抗过程实现特征自适应。但是,基于GAN的模型很难优化,这最终会影响融合性能。融合结果趋于模糊,并且缺少一些重要特征。
我们总结了红外和可见光图像融合中的缺点:
(1) 通过不同的传感器获得红外和可见光图像,从而存在域差异。这种域差异给图像融合带来了巨大的挑战。现有框架通常采用相同的卷积算子进行特征提取,以实现特征自适应,这容易导致重要特征的丢失。
(2) 红外和可见光图像融合的地面真实性不足,给特征适应带来了困难。许多基于GAN的方法都采用红外和可见光图像作为参考图像,以迫使融合结果合并源图像的重要信息。但是,基于GAN的模型难以优化,这会对融合结果产生负面影响。
为了缓解上述问题,我们提出了一种自我监督的策略,以实现特征自适应,同时避免重要特征的丢失。具体来说,编码器从红外和可见图像中提取特征。然后,利用两个具有注意机制块的解码器以自我监督的方式重建源图像,从而迫使经过调整的特征包含源图像的重要信息。最后,我们基于我们的自我监督框架获得的自适应特征,介绍了红外和可见光图像融合和增强模型。
主要贡献如下:
1)通过将特征自适应的思想整合到红外和可见光图像融合中,提出了一种新颖的自监督特征自适应框架。开发了自我监督策略以进行特征适应,同时通过重建源图像避免了重要特征的丢失。
2)在提取特征自适应的前提下,针对源图像中包含低质量信息的情况,设计了一种新颖的红外和可见光图像融合和增强方法。
相关工作
Traditional fusion methods
对于红外和可见光图像融合,已经提出了多种特征提取策略和融合规则。通常,多尺度变换 (MST) ,稀疏表示 (SR) ,基于子空间的,神经网络方法 ,基于显着性的方法 和混合模型 作为代表方法,广泛用于图像融合。
基于MST的方法包括多尺度分解、多尺度融合和多尺度重构的步骤。从变换方法选择的角度,Li等人研究了curvelet和contourlet分解方法,并为图像融合提供了相应的最优候选。Li等人开发了基于潜在低秩表示 (DDLatLRR) 框架的深度分解,用于红外和可见光图像融合,其中采用LatLRR来学习用于显着特征提取的项目矩阵。
SR 旨在从一组训练图像中获得的学习过完整字典生成融合图像,该训练图像组合了一系列稀疏系数。例如,Lu等人 通过核奇异值分解 (KSVD) 学习过完备字典,提出了一种基于SR的红外和可见光图像融合方法。Wang等人开发了一种非负SR方法,称为NNSP,用于特征提取,然后融合红外和可见光图像。
作为基于子空间的方法,已经提出了用于图像融合的主成分分析 (PCA) ,独立成分分析 (ICA) 和非负矩阵分解 (NMF)。例如,Mitianoudis等人 在图像融合中验证了基于独立分量分析 (ICA) 和地形独立分量分析基础的变换样式方法。Kong等人采用一种新颖的NMF进行特征提取,同时保留红外和可见光图像的热信息和纹理细节。
混合模型旨在通过将各种方法组合到集成框架中来提高融合性能。例如,Liu等人 通过集成多尺度变换和稀疏表示,提出了一种图像融合框架,以克服单一方法的缺点。对于红外和可见光图像融合,Zhou等人提出了一种混合多尺度分解 (hybrid-MSD),通过在多尺度分解阶段联合使用多尺度高斯和双边滤波器来改善感知信息。Ming等人将shift-invariant dual-tree complex shearlet变换和稀疏表示相结合,以获得更好的可见质量的融合结果。
上述方法是基于手工制作的特征或手动设计的用于图像融合的规则,这导致复杂场景的性能有限。此外,大多数现有方法对源图像进行相同的图像变换或表示。这不能很好地处理红外和可见光图像,因为红外图像的热辐射信息和可见光图像的纹理特征是两种不同的风格,具有域差异,最终导致融合性能有限。
Deep learning based fusion methods
最近,提出了许多基于深度学习的进展,以有效避免手工特征提取的有限表示能力,例如多焦点图像融合,多光谱图像融合,多模型医学图像融合,红外和可见光图像融合 ,多分支网络融合。
对于红外和可见光图像融合,已经开发了许多CNN来获取源图像的权重图。例如,Liu等人应用连体卷积网络来生成红外和可见光图像的权重图,然后在融合过程中采用多尺度图像金字塔和局部相似性度量来追求更好的可见光感知。Li等人 使用VGG网络进行深度特征提取,这些特征进一步用于通过多层融合策略生成权重图。Li等人采用残差网络从源图像中提取深度特征,并基于零相位分量分析 (ZCA) 对深度特征进行归一化处理,生成权重图。许多其他尝试在特征提取中采用深度学习,然后直接重建融合图像。例如,Li等人提出了基于编码器-解码器网络的DenseFuse网络,用于红外和可见光图像的融合,其中编码网络用于提取特征,融合层通过将源图像的特征图与域差异串联来设计,解码网络用于重建融合图像。Zhang等人提出了IFCNN模型,其中两个由具有相同结构和权重的卷积层组成的分支进行特征提取,然后采用不同的融合规则融合提取的特征,最后使用两个卷积层重建最终的融合图像。Zhang等人 采用梯度路径和强度路径分别提取源图像中的相应信息,并设计了路径传输块来传达两个路径的提取特征。最后,通过连接提取的特征并进行卷积操作来获得融合结果。Xu等人提出了U2Fusion,其中DenseNet 用作骨干网,并设计了信息测量来约束重要信息的保留。
如上所述,红外图像和可见光图像的域差异使两个源的局部结构变化很大。大多数框架通常采用相同的卷积运算符来提取适应的特征。但是,由于域差异,同一运算符限制了特征表示能力,从而导致重要特征的丢失。
GANs based feature adaption
为了缓解域差异问题,已经开发了许多基于GAN的框架 。对于红外和可见光图像融合,一些基于GAN的方法旨在通过发电机网络在具有鉴别器网络的对抗过程中实现特征自适应。例如,FusionGAN使用生成器网络进行特征自适应并获得融合结果,其中可见纹理细节以及热辐射信息通过判别器的对抗过程保留。DDcGAN采用基于编码器-解码器网络的生成器进行特征提取,然后重建融合图像。双重鉴别器旨在融合红外和可见光图像中的最大信息量。在上述方法中,特征适应是在对抗性训练过程中实现的。从生成的角度来看,许多多域生成的GAN被开发用于图像到图像的翻译,例如,可见图像转换为具有重要外观信息的红外图像,其中可以在图像翻译过程中实现特征适应。但是,基于GAN的模型难以优化,最终导致融合图像的透视失真。
方法
Motivation
为了缓解域差异问题,已经提出了许多基于深度学习的红外和可见光图像融合方法。这些融合方法主要可分为以下两类 : (1) 使用相同卷积算子的特征自适应;(2) 使用生成对抗网络 (GAN) 的特征自适应。在这里,我们采用了两种具有代表性的红外和可见光图像融合方法,它们分别基于相同的卷积算子策略和GAN框架,来分析它们的局限性,然后提出我们的方法。
(1) DenseFuse。DenseFuse是一种有效的红外和可见光图像融合方法,它采用一系列卷积层提取特征,同时实现特征自适应。然后使用L1-Norm和soft-max操作来融合深度特征,并实现重建网络以获得融合图像,如下图所示:
(2)DDcGAN.Xu等人提出了用于红外和可见光图像融合的DDcGAN,其中在生成融合图像的同时利用发生器进行特征自适应,并设计了双重鉴别器,以通过对抗过程来增强红外图像的热信息和可见光图像的纹理细节。DDcGAN的结构如下图所示:
视觉比较如图1所示。DenseFuse可以保留红外图像的主要热辐射信息和可见图像的结构特征。然而,DenseFuse采用相同的卷积算子来实现特征自适应,这容易导致细节信息丢失,最终导致融合性能有限。如图1(c)所示,细节信息丢失 (例如,红色矩形中的路标和栏杆的结构细节)。
如图1(d) 所示,由DDcGAN生成的融合图像存在透视失真。我们解释说,基于GAN的方法很难优化,最终会影响外观不自然的融合图像。通过考虑上述局限性,提出了一种新颖的自监督特征自适应框架,以改善红外和可见光图像的融合。

Our solution
通过巩固用于提高红外和可见光图像融合性能的特征自适应思想,我们提出了一种新颖的用于红外和可见光图像融合的自监督特征自适应框架。框架如下图所示:
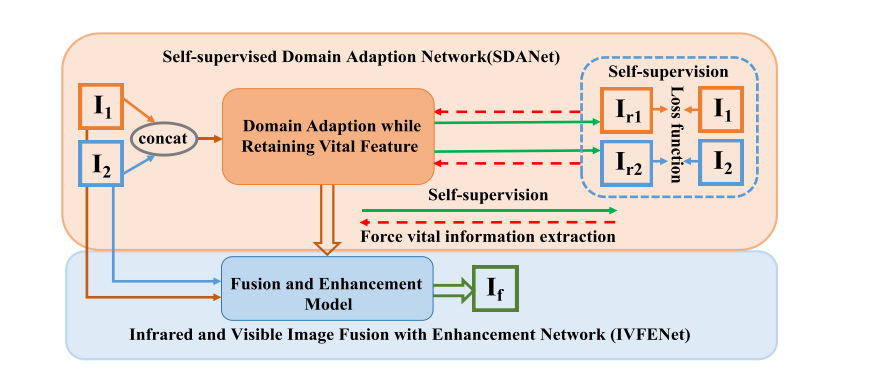
(包括两部分:自监督特征自适应网络 (SFANet),红外和可见光图像融合与增强网络 (IVFENet)。)
在自监督特征自适应框架中,提出了自监督特征提取和自适应策略,避免了重要特征的丢失。具体来说,我们旨在采用特征适应策略来减轻红外图像和可见光图像之间特征空间差异的挑战。基于自监督框架,我们提出了一种改进的编码器-解码器网络,其中特征空间一致性由用于特征提取的编码器和具有注意机制块的两个解码器以自监督的方式重建源图像来实现,避免了传统编码器进行特征提取的重要信息丢失。最后,将那些具有自适应功能的重要功能输入到融合和增强网络中。
Self-supervised feature adaption network
我们旨在设计一种新颖的自监督特征自适应网络,以有效表达具有域差异的红外和可见图像的特征,并将其用于实现IVFENet。
自监督特征自适应网络的方案如下图所示,包括三个块: 编码器块、注意机制块和解码器块。在此模型中,红外和可见光图像以相同的卷积操作输入到编码器网络,以进行特征自适应。与大多数方法不同,我们通过使用两个解码器网络进一步重建源图像,以确保特征适应,同时避免自我监督的特征恶化。
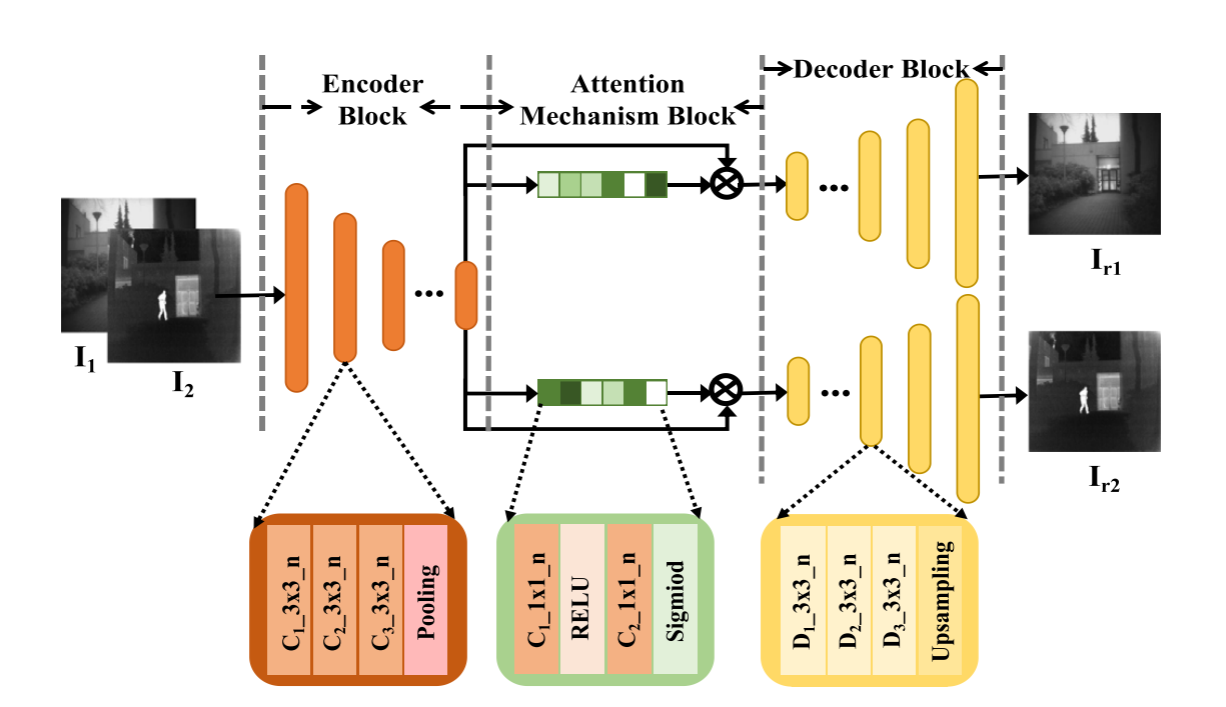
如上图所示,网络由三个块构成: 编码器块、注意机制块和解码器块。具体来说,编码器由五个块组成,其中每个块由三个卷积层组成,然后是一个池化层。更具体地,用于从第一块到第五块的卷积层的滤波器的数量分别被设置为64、128、256、512和512。卷积层的所有内核大小都设置为3 × 3。注意机制块由具有相同结构的挤压和激励 (SE) 模型的两个分支组成。SE模型包括具有32个滤波器的完全卷积层、ReLU层、具有512个滤波器的完全卷积以及然后是sigmoid层。解码器块由具有相同结构的两个解码器网络分支组成。每个解码器网络包含五个块,其中每个块由三个反卷积层组成,然后是一个上采样层。用于从第一块到第五块的去卷积层的滤波器的数目分别被设置为512、256、128和64。卷积层的所有内核大小都设置为3 × 3。
注意力机制块由挤压和激励 (SE) 模型的两个分支组成,旨在从混合特征中选择红外和可见图像的特定于域的特征表示。然后将特定领域的特征表示用于通过解码器网络重建源图像。从理论上讲,SE机制允许网络模型对特征进行校准,从而使网络可以选择性地扩大有价值的特征通道,并从全局信息中抑制无用的特征通道。在我们的自监督特征自适应网络中,使用两个SE块分别从编码器块中选择红外和可见图像的特征表示,然后将其用于重建红外和可见图像。因此,注意力机制块可以增强特征表达能力。本质上,SE模型为红外和可见图像域生成一组域激活向量 𝑉𝐼/𝑉。域特定特征可以通过激活具有相应域激活向量 𝑉∕/𝑉 的混合特征来生成:
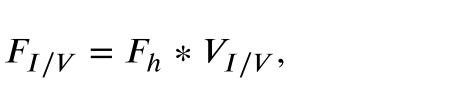
其中 𝑉∕/𝑉分别表示红外域和可见域的域激活向量。𝐹 ℎ表示编码器网络生成的混合特征。𝐹𝐼 /𝑉 代表红外 (𝐹𝐼) 或可见图像 (𝐹𝑉) 的域特有的特征。
解码器块专注于通过以自我监督的方式将源图像视为地面真实来从域激活表示中重建源图像,从而可以强制编码器块在特征自适应过程中保留重要特征,特别是在源图像重建过程中,网络的输入是带有串联操作的组合红外和可见光图像,并将源图像视为地面真实。该网络基于编码器-解码器框架。一种通用的编码器块被设计用于提取丰富的特征,其本质上通过编码操作实现了重要的信息学习,同时消除了其他不需要的特征,例如噪声。然后设计注意机制块,用于从编码器网络生成的混合特征中选择红外和可见图像的特定于域的特征表示。最后,采用了两个分别用于重建红外和可见光图像的解码器块,以自我监督的方式对域激活表示进行解码,从而可以增强编码器块以保留重要特征。仅当编码器网络提供红外和可见图像的主要重要特征时,解码器块才能重建源图像。
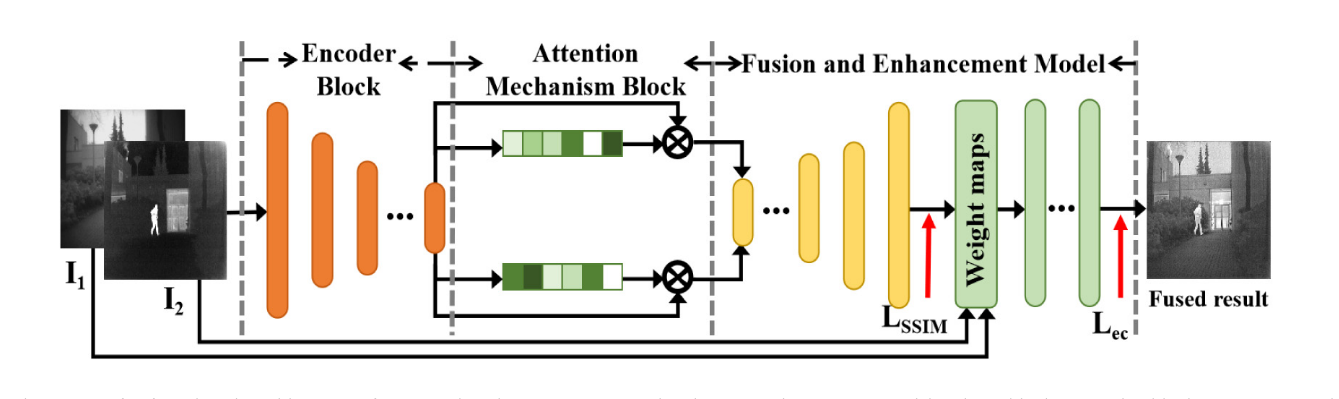
Infrared and visible image fusion with enhancement network
在本节中,我们旨在利用从SFANet获得的具有自适应功能的重要特征来生成融合结果。我们提出了一种与边缘细节和基于对比度的损失函数相协调的增强网络。 IVFENet模型如下图所示,该模型由编码器模型、注意力机制模型和融合增强模型组成。利用编码器模型和注意机制模型提取包含源图像的自适应特征,然后融合和增强模型以生成最终的融合结果。具体地,通过框架图*(上方倒数第二张)* 中的自监督特征适应网络对编码器和注意机制模型进行预训练,以获得具有适应的重要特征。然后,我们设计融合和增强模型以生成最终结果。融合模型包括一系列具有3*3内核和512、256、128、64和64通道的反卷积层,每个都有一个上采样层。最后,进一步采用一组卷积层来增强融合结果,以与边缘细节和基于对比度的损耗相协调。
Model training
我们的网络训练包括两个阶段: 训练自我监督的特征适应网络和训练红外和可见光图像融合与增强网络。具体来说,我们首先训练自监督特征自适应网络。对于具有增强网络的红外和可见光图像融合,我们只训练融合和增强模型,同时固定编码器和注意机制块的参数,这确保了由自监督特征自适应网络产生的具有自适应的重要特征可以直接用于IVFENet中的融合。将介绍所用到的损失函数。
Training self-supervised feature adaption network
为了训练自我监督的特征适应网络,我们打算通过将源图像视为地面真实来重建源图像。因此,我们使用标准均方误差 (MSE) 作为损失函数:
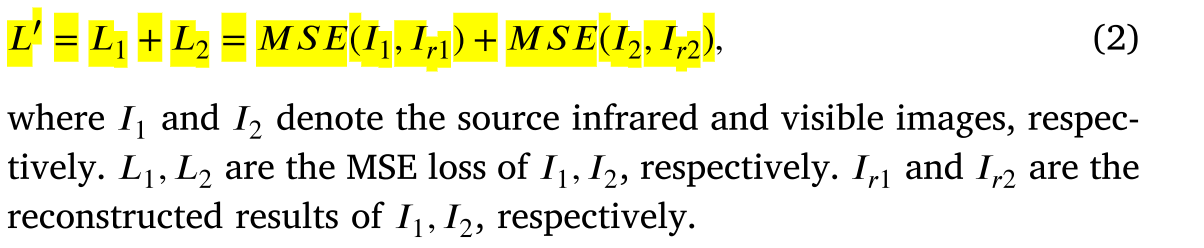
Training infrared and visible image fusion and enhancement network
对于红外和可见光图像融合模型,缺乏地面真相注释给训练过程带来了挑战。在这里,我们旨在设计一种无参考质量测量指标,以实现无监督的融合框架。具体地,我们设计了一个基于结构相似性指标 (SSIM) 的损失函数,命名为 𝐿𝑆𝑆𝐼𝑀,然后基于边缘细节和对比度,命名为 𝐿𝑒𝑐 的可见感知损失,以迫使融合结果进一步融合源图像的生命信息。输入图像 𝐼𝑛 = 𝐼𝑛 | 𝑛 = 1,2在SSIM框架中用对比度 𝐶 、结构 𝑆 和亮度 𝑙 的分量表示:








![我的博客系统[Servlet]](https://img-blog.csdnimg.cn/0edbacb9ebd14d35a2b2257ae9159a3d.png)