目录
经典开头 — C++的历史
作用域运算符
using的用法
命名空间 - namespace
命名空间的基本使用
特殊的命名空间 - 无名命名空间
全部展开和部分展开
std — C++所有的标准库都在std命名空间内
省缺值 - 默认参数
占位参数
内联函数 - inline
函数重载
函数重载的用法
函数重载的原理剖析
引用
基础用法
常量引用与非常量引用
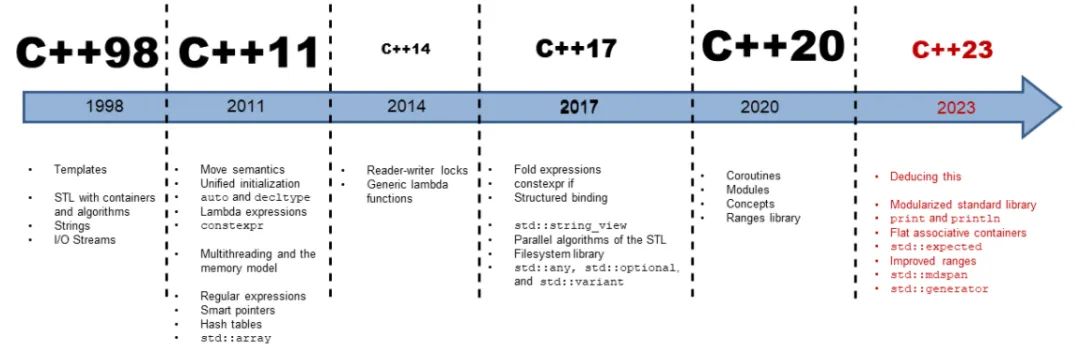
经典开头 — C++的历史
C语言是结构化和模块化的语言,适合处理较小规模的程序。对于复杂的问题,规模较大的
程序,需要高度的抽象和建模时,C语言则不合适。为了解决软件危机, 20世纪80年代, 计算机
界提出了OOP(object oriented programming:面向对象)思想,支持面向对象的程序设计语言
应运而生。
1982年,Bjarne Stroustrup博士在C语言的基础上引入并扩充了面向对象的概念,发明了一
种新的程序语言。为了表达该语言与C语言的渊源关系,命名为C++。因此:C++是基于C语言而
产生的,它既可以进行C语言的过程化程序设计,又可以进行以抽象数据类型为特点的基于对象的
程序设计,还可以进行面向对象的程序设计。

1979年,贝尔实验室的 Bjarne 等人试图分析unix内核的时候,试图将内核模块化,于是在C语言的基础上进行扩展,增加了类的机制,完成了一个可以运行的预处理程序,称之为C with classes。语言的发展就像是练功打怪升级一样,也是逐步递进,由浅入深的过程。一下是C++的一些历史版本。

作用域运算符
双冒号(::)表示作用域解析运算符(Scope Resolution Operator)。它用于指定命名空间(namespace),类(class)或结构体(struct)的作用域,或者在类的成员函数外部引用类的成员。一般来说如果作用域运算符前没有任何类或者命名空间,则表示这是指定的全局作用域。用法示例如下:
/*用于在类外部定义和实现成员函数。*/
class MyClass {
public:
static int x;
void func();
};
int MyClass::x = 5; // 类外定义静态成员变量
void MyClass::func() { // 类外定义成员函数
// 函数实现代码
}/*用于访问命名空间中的成员。*/
namespace MyNamespace {
int x;
void func();
}
void MyNamespace::func() {
// 函数实现代码
}
int main() {
MyNamespace::x = 10; // 访问命名空间中的变量
MyNamespace::func(); // 调用命名空间中的函数
return 0;
}
/*用于访问枚举类型中的值。*/
enum MyEnum {
VALUE1,
VALUE2
};
int main() {
MyEnum value = MyEnum::VALUE1; // 访问枚举类型中的值
return 0;
}using的用法
在C++中,using关键字常用于引入命名空间、别名和模板的成员等。下面是using关键字的几种常见用法:
1. 引入命名空间:
using namespace namespace_name;
示例:
using namespace std;
// 可以直接使用std命名空间中的成员,无需前缀
cout << "Hello, world!" << endl;
2. 引入单个成员:
using namespace_name::member_name;示例:
using std::cout;
// 引入std命名空间中的cout成员
cout << "Hello, world!" << endl;3. 定义类型别名:
using alias_name = type_name;
示例:
using MyInt = int;
// 定义MyInt作为int的别名
MyInt num = 42;5. 引入模板类成员:
template<typename T>
using alias_name = template_name<T>;示例:
template<typename T>
class MyTemplate {
public:
void doSomething();
};
template<typename T>
void MyTemplate<T>::doSomething() {
// 实现...
}
// 使用using引入模板类的成员
using MyAlias = MyTemplate<int>;
MyAlias obj;
obj.doSomething(); // 调用模板类的成员函数以上是`using`关键字的一些常见用法和相应的示例。根据需要选择适合的用法,并确保理解命名空间和类型别名的概念以及它们的用法和限制。
命名空间 - namespace
命名空间的基本使用
创建名字是程序设计过程中一项最基本的活动,当一个项目很大时,它会不可避免地包含大量名字。在C++中,名称(name)可以是符号常量、变量、函数、结构、枚举、类、对象等等。工程越大,名称互相冲突性的可能性越大。而且使用多个厂商的类库时,也可能导致名称冲突。为了避免这些标识符的命名发生冲突,C++引入了namespace(命名空间)关键字,可以更好地控制标识符的作用域。用法示例:
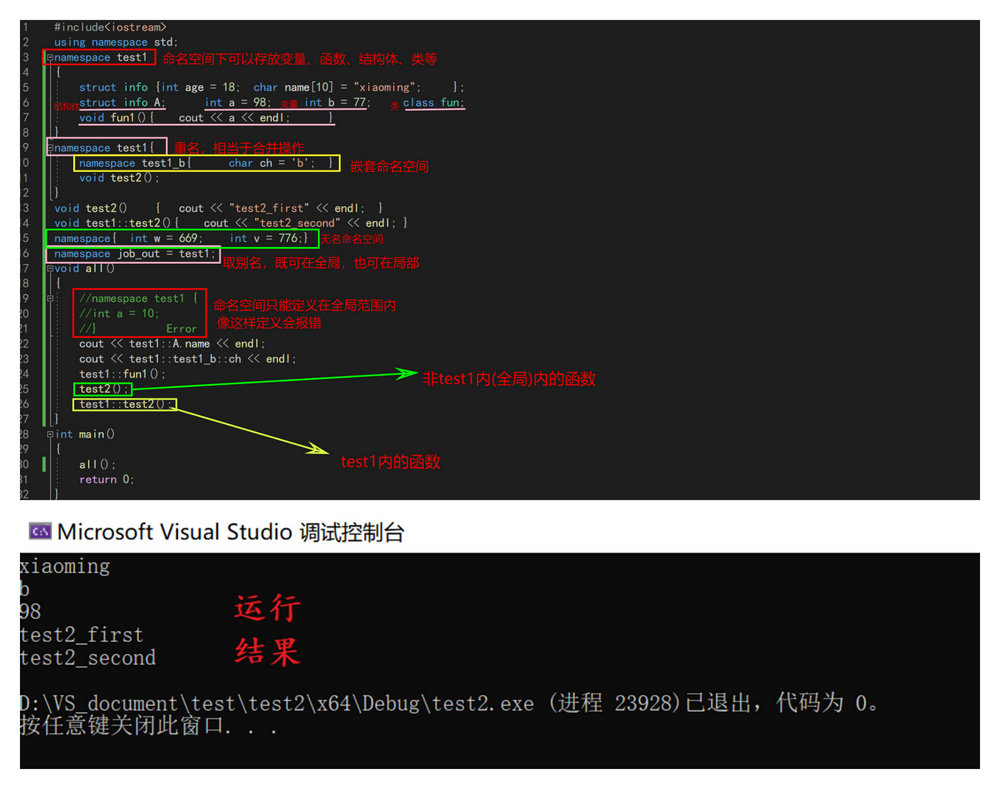
要点概括如下:
- 命名空间内可以存放变量、函数、结构体、类等,而且命名空间中也可以再存放命名空间,可以说C++中几乎所有的东西都可以放在命名空间内。
- 每一个命名空间都相当于是一个私人空间,每个命名空间内的函数名、变量名等都相互独立,并不会触发命名冲突的问题。
- 如果两个命名空间的名字相同,那么它们会自动合并,相当于是一个命名空间。
- 命名空间可以取别名,命名空间可以取别名,格式:namespace NewName = OldName;
- 命名空间中的函数可以在命名空间内声明,在外部定义。但定义时需要加上命名空间作用域。
- 要注意,头文件的包含并不包括命名空间的展开,也就是说我们虽然包含了某一头文件,但这个头文件中的命名空间还是相对于是一个私有的空间,如果需要使用,也是需要展开才能使用的。
特殊的命名空间 - 无名命名空间
其实,命名空间也可以没有名字,而这种没有名字的命名空间就叫无名命名空间。
无名命名空间的注意事项:
- 无名命名空间内的所有成员都相当于加上了static修饰,只能被当前文件调用。属于内部链接属性。
- 如果两个源文件都含有无名命名空间,这两个无名命名空间可以定义相同名字的成员,因为每个命名空间之间是相互独立的。
- 无名命名空间的成员名称不能与全局作用域的成员名称相同,会导致二义性。
全部展开和部分展开
全部展开也叫全部授权,命名空间的全部展开相当于把原来私有的东西给公开了。像我们平常写的
using namespace std;其中的std就是全部展开的,这种全部展开意思是当前文件可以不用限制符说明,直接访问std命名空间里的内容,例如std全展开之后,我们平常写的cout就可以选择加限定符的写法 std::cout ,也可以选择不加限定符的写法直接 cout。
但这种全部展开还有一种潜在的危险,如果全部展开了多个命名空间,而这些命名空间内有同名元素,而且我们在使用时没有加域限定符来限定,那么就会造成命名冲突。或者如果全部展开的命名空间内有与当前文件元素重名的情况,且在使用时没加限定符也会引发命名冲突。
所以一个稳妥的做法就是我们在使用全部展开的命名空间下的成员时,加上域限定符来显示的指定要使用的成员是哪一个命名空间的,这样就不会有上述的危险出现了。如果想要使用全局下的元素,域限定符前面不加东西就可以了。
与全部展开相对应的时部分展开(部分授权),顾名思义,全部展开是展开命名空间下的所有元素,那么部分展开就是只展开命名空间下的一小部分元素,例如:
using std::cout;
using std::endl;这就是只展开了std命名空间下的cout和endl,std下的元素就只有cout和endl可以使用,而且使用时不用加限定符也不用担心会出现全部展开命名冲突的危险。但局限性也是显而易见的。
std — C++所有的标准库都在std命名空间内
在C++中,标准库的所有内容都位于std命名空间中。std是C++标准库的命名空间,包含了各种类、函数和对象,用于常见的操作和功能,例如输入输出、容器、算法、字符串处理等。
当使用C++标准库的功能时,通常需要在代码中使用using语句或者使用完整的限定符来指定所需的标识符。
以下是一些常见的C++标准库的成员,它们位于std命名空间中:
输入输出相关:cin、cout、cerr、endl等。
容器类:vector、list、map、set等。
算法:sort、find、transform、accumulate等。
字符串处理:string、getline、stoi、to_string等。
数值操作:abs、min、max、sqrt、pow等。
省缺值 - 默认参数
C++在声明函数时可为一个或者多个参数指定默认(缺省)的参数值,当函数调用的时候如果没有指定这个值,编译器会自动用默认值代替。也就是说,设置了默认值后,有实参传入就使用实参,没有实参传入则使用默认参数。
在C++中使用默认参数时,有如下这样几个注意事项:
1、当使用默认参数时,函数的调用可以省略相应的实参。省略的实参会被自动替换为对应参数的默认值。如果需要指定非默认值的参数,可以通过按顺序提供实参,或者通过指定参数名来显式地指定。
2、函数传参需要严格遵守从左往右传参,既是有默认参数也不能例外。
3、默认参数只能在函数的声明中指定,不能同时在声明和定义两个地方都指定。通常的做法是在函数的声明中指定默认参数,而在函数的定义中省略默认参数的指定。
4、默认参数只能从右向左连续地出现。也就是说,如果一个函数有多个参数有默认值,那么这些参数的默认值只能从右向左地连续指定。例如,下面的函数定义是合法的:
void foo(int a, int b = 0, int c = 0);但是下面的函数定义是不合法的:
void bar(int a = 0, int b, int c = 0); // 不合法,b之前的参数没有默认值5、默认参数的值在函数声明的时候确定,并且只会在函数调用时被求值一次。这意味着如果默认参数的值是一个表达式,那么该表达式只会在函数第一次被调用时求值,并在后续调用中保持不变。例如,考虑以下函数声明:
void foo(int a, int b = 0, int c = a + b);下面是一个示例来说明这一点:
void foo(int a, int b = 0, int c = a + b); int main() { foo(1); // 第一次调用,a = 1, b = 0, c = 1 + 0 = 1 foo(2, 3); // 第二次调用,a = 2, b = 3, c = 2 + 3 = 5 (使用提供的实参覆盖默认值) foo(4); // 第三次调用,a = 4, b = 0, c = 4 + 0 = 4 foo(5, 6); // 第四次调用,a = 5, b = 6, c = 5 + 6 = 11 (使用提供的实参覆盖默认值) }6、注意避免二义性。如果一个函数有多个重载,并且某些重载函数在参数列表中具有相同的类型和个数,但其中一些参数有默认值,那么在调用时可能会产生二义性。编译器无法确定调用哪个重载函数,因为可以通过省略参数来匹配多个重载。在这种情况下,可以通过显式地指定参数来解决二义性。
占位参数
在C++中,占位参数是指在函数声明或定义中使用没有具体名称的参数,占位参数通常用于表示某个参数的存在,但在函数实现中并不使用该参数。
例如:
void(int a,int b,int,int)后两个参数就是占位参数。
注意事项:
- 调用函数时,占位参数的部分也要传参
- 函数体内部一般是无法直接使用占位参数的
- 占位参数也可以设置缺省值
占位参数在日常使用中一般很少用,但并不是说没有应用场景,比如在重载++/--运算符时为了区分前置++和后置++就会使用占位参数来区分。
内联函数 - inline
在C语言中我们有时会把一些简短且频繁使用的计算写成宏,而不是函数,这样做的理由是为了执行效率,宏可以有效的避免函数调用的开销。但是在C++中,使用预处理宏会出现两个问题:
第一个问题在C中也会有:宏看起来像=是一个函数,但还是有很多潜在危险的。
第二个问题是C++特有的:不允许预处理器访问类的成员,也就是说预处理器宏不能用作类类的成员函数。
为了保持预处理宏的效率,并且像一般成员函数那样可以在类里访问自如,还能加安全性。C++引入了内联函数(inline function):在普通函数前面加上inline关键字就变成了内联函数。
内联函数具有普通函数的所有行为,但内联函数是在适当的地方像宏一样展开,省去了函数调用时候的压栈,跳转,返回等开销。内联函数虽然占用空间,但是内联函数相对于普通函数的优势是省去了函数调用时候的压栈,跳转,返回的开销。我们可以理解为内联函数是以空间换时间。
注意事项:
- 内联说明只是向编译器发出的一个请求,编译器可以选择忽略这个请求。内联只是给编译器一个建议,编译器要视情况而定,并不是一定会将这个函数实现为inline的。
- 内联函数要保证函数体简单,不能过于庞大。比如不能出现太多的循环等。(理由在上一条)
- 内联函数的声明可以不加inline,但内联函数的定义必须要加inline。虽然如此,但还是不建议内联函数的声明和定义分开来写,分开来写会导致链接错误。因为如果内联函数被展开了,此时的内联函数是没有地址的,链接时就找不到了。
- 不要对内联函数进行取址操作。因为内联函数是直接将函数体替换掉的,本来就丢了函数入口(即函数地址),再取地址的话就没有意义了。
内联函数和宏的异同
- 宏的替换发生在预处理阶段,内联函数的替换发生在编译阶段
- 宏有隐晦的危险性,内联函数则相对较安全
- 内联函数和宏一样,都省去了调用函数的开销
内联函数普通函数的区别
- 普通函数和内联函数参数传递机制相同
- 普通函数在被调用的时候,会跳转到到函数的入口地址去执行函数体,执行完成之后再跳转回函数调用的地方继续执行,函数始终只有一个。
- 内联函数的调用不需要寻址,当执行到内联函数的时候,会将函数在此处展开。如果程序中调用了N次内联函数,那么则会有N段这样的函数代码
函数重载
函数重载的用法
函数重载是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这
些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,所以常用来处理实现功能类似数据类型不同的问题。
要点概括:
- 发生函数重载的条件是:参数的类型、个数、顺序不同。
- 函数的重载只发生在同一个作用域内(因为每一个作用域都是相互独立的)
- 返回值不同,不能发生重载
- 缺省值作为函数重载的条件需要注意二义性
- 引用作为函数重载的条件需要注意二义性
这里的二义性不是说不能发生重载,而是发生重载之后在实际使用的过程中会造成冲突。
函数重载的原理剖析
理解函数重载的原理之前,我们需要先认识三个东西:符号表、函数签名、函数名修饰。
符号表(Symbol table)是在计算机科学中用于存储程序中定义的标识符(例如变量、函数、类名等)及其相关信息的数据结构。符号表通常是一个类似于字典或映射的数据结构,其中每个标识符都与其关联的信息(如类型、作用域、地址等)相关联。符号表的目的是跟踪程序中的标识符,以便在需要时能够快速索引到它们。
在编译过程中,编译器使用符号表来进行语义分析和类型检查。
函数签名(Function signature)是指函数的类型及其参数的类型和顺序。它描述了函数的输入参数和返回值的特征,以及函数名。函数签名用于区分不同的函数并确保在调用函数时正确匹配参数。
函数签名通常由函数名和参数列表组成,参数列表包括参数的类型、顺序和个数。函数签名不包括函数的实现细节,只关注函数的接口,它是函数的抽象表示。
函数签名的重要性在于它允许编译器、解释器和其他代码使用者在编译或运行时检查函数调用的正确性。通过匹配函数签名,可以确保传递给函数的参数类型与函数定义中的参数类型相匹配,并且可以检查函数的返回值类型是否与期望的类型相符。
函数签名还用于函数重载。在一些编程语言中,允许定义具有相同名称但参数类型或数量不同的多个函数。编译器或解释器通过函数签名来区分这些函数,以便在调用时选择正确的函数。
函数名修饰规则(Function name mangling rules)是一种命名约定或规则,用于在编译器中对函数名进行转换,以便区分具有相同名称但不同参数列表或不同作用域的函数。
函数名修饰规则通常在编译过程中使用,特别是在支持函数重载和命名空间的编程语言中。
函数名修饰通常涉及以下几个方面:
1. 参数列表:函数名修饰规则会根据参数的类型、顺序和个数来创建唯一的函数名。这样可以确保具有不同参数的函数在编译后具有不同的名称。
2. 命名空间:函数名修饰规则还会考虑函数所属的命名空间,以避免命名冲突。
3. 作用域:如果同一作用域内存在具有相同名称但参数列表不同的函数,此时函数名修饰规则可以使用作用域的信息来区分它们。
函数名修饰规则的具体实现因编程语言而异。不同的编译器和语言可能采用不同的函数名修饰方案。例如,C++编译器使用一种称为"Name Mangling"的技术来修饰函数名,将其转换为唯一的符号名称,以便在链接时进行正确的函数匹配。
(PS:可以说,函数名修饰规则就是根据函数签名来的)
- 函数重载的底层原理就与符号表、函数签名以及函数名修饰等息息相关。
函数签名是区分不同函数的关键因素之一。函数签名包括函数的名称、参数的类型和顺序,但不包括返回值类型(这就是为什么返回值不同不能发生重载)。在支持函数重载的编程语言中,可以定义具有相同名称但参数列表不同的多个函数。编译器根据函数签名来识别和区分这些函数,以确保在函数调用时能够选择正确的函数。
函数名修饰规则在编译器中用于生成唯一的函数标识符,以便区分具有相同名称但不同参数列表的函数。函数名修饰规则根据参数的类型、顺序和个数来创建唯一的函数名。这样可以确保具有不同参数的函数在编译后具有不同的名称,以避免函数名冲突。函数名修饰规则在函数重载的实现中起到关键作用,它确保了函数重载的正确性和可用性。
而符号表中会记录具有相同名称但不同参数列表的多个函数的信息。符号表中的条目包含函数的名称、修饰后的函数名、参数类型信息等。在编译或运行时,符号表用于匹配函数调用的函数签名和函数定义,以选择正确的函数进行调用。
引用
基础用法
引用,又叫取别名,是C++中一种用于别名分配的特殊语法。它允许将一个已存在的变量作为一个别名来使用,而不是创建一个新的变量。引用可以看作是一个变量的别名,它和原变量共享同一块内存。引用在C++中的使用可以提高代码的可读性和效率。
要点概括:
- 引用的使用格式:变量类型& 别名=原名。例:int& b=a。
- 同一个变量可以有多个引用。
- 引用其实就是给变量取一个别名,引用的地址就等于原变量的地址。所以如果修改了引用或者原变量其中的一个,另一个也会相应变化。(可以当成不同的名字,同一个变量来理解)
- 引用必须进行初始化,且一旦初始化之后就不可更改了。
- 函数可以返回引用,就像函数可以返回指针一样。但注意不要返回临时的引用或指针。
- 引用的本质,引用在C++的底层实现其实就是一个指针常量,这也就很合理的解释了第4条。(常量必须初始化,不能对常量进行修改)
- C++编译器在编译过程中用指针常量作为引用的内部实现,所以一个引用所占的内存空间就等于指针在此环境下所占的内存空间。
- 其实从使用者的角度来讲,引用只是一个别名,C++为了实用性而隐藏了引用的底层细节。所以我们并不需要过多的深究引用的底层实现,把引用当作系统为我们封装好的语法糖使用就可以了。
常量引用与非常量引用
在此之前我们需要了解一下引用绑定的概念。
引用绑定: 引用是一个别名,它是一个已存在对象的别名。当我们声明一个引用时,它必须初始化为绑定到一个对象。引用在绑定时就确定了其所指向的对象。
常量引用:
const引用不允许通过引用对所绑定的对象进行修改。它只能读取对象的值,不允许修改。试图通过const引用修改对象的值将导致编译错误。当一个引用被声明为
const时,它表示引用的值是只读的,不能通过该引用修改所引用的对象。这意味着编译器会在编译期间强制执行这个规则,确保我们不会通过该引用修改对象的值。因此,const修饰的引用可以绑定到不同类型的数据,因为我们不能通过该引用来修改这些数据的值,只能读取。
const引用可以绑定到相同类型的对象,也可以绑定到兼容类型的对象。它允许类型之间的隐式转换,包括常规类型转换和用户定义的类型转换。这是因为const引用只用于读取对象的值,不会修改对象,所以允许在一定程度上放宽类型匹配的要求。举个例子,假设有一个
const引用类型为const int&,但我们试图将其绑定到一个double类型的变量。由于存在从double到int的隐式转换,编译器会允许这种隐式转换并将double类型的值转换为int类型,然后将其绑定到const int&引用。
需要注意的是,虽然const修饰的引用允许隐式转换,但这并不意味着它可以绑定到任何类型。仍然需要满足基本的类型兼容性规则。所谓的兼容性规则指的是 a = b 这个操作行得通,例如系统基础的数据类型 int、double、char 等之间都可以,但如果是两个类或者结构体的话需要有对应的operator=或者专门的函数才可以。
非常量引用:
先简单认识一下左值和右值:
左值(L-value):左值是指具有标识符的表达式,或者是可以取地址的表达式。左值可以出现在赋值操作的左侧和右侧,表示一个具体的存储位置或对象。
右值(R-value):右值是指不能取地址的表达式,或者是临时的、即将销毁的值。右值只能出现在赋值操作的右侧。
非
const修饰的引用可以用于修改所引用对象的值。因此,非const引用的类型必须与所引用对象的类型完全匹配。否则,会导致编译错误。非const引用允许通过引用对所绑定的对象进行修改。通过非const引用,可以修改对象的值,包括赋予新值、修改成员等。非const引用的初始值必须为左值。非常量引用的初始值必须是左值,是为了确保引用的有效性,并避免悬空引用、防止意外的修改。
避免悬空引用: 当一个引用被绑定到一个左值时,它将引用该左值所代表的具体对象或存储位置。这意味着引用可以安全地访问和修改所绑定的对象。但是,如果引用被绑定到一个右值(例如临时值、临时对象、表达式的结果、函数的临时返回值等),当该右值超出范围并被销毁后,引用将变成悬空引用。悬空引用指向一个不再存在的对象,使用它可能导致一种很危险的未定义行为。为了避免这种情况,C++要求非常量引用的初始值必须是左值,以确保引用绑定到持久性的对象上。
防止意外的修改: 因为非常量引用允许修改所绑定对象的值。所以如果允许非常量引用绑定到右值(临时对象),那么修改临时对象的值可能会导致不可预料的行为。由于右值可能在其他地方被共享或使那么允许修改它们可能会对程序的正确性和安全性产生负面影响。因此,C++限制了非常量引用的初始值必须是左值,以确保我们只能修改持久性的对象。