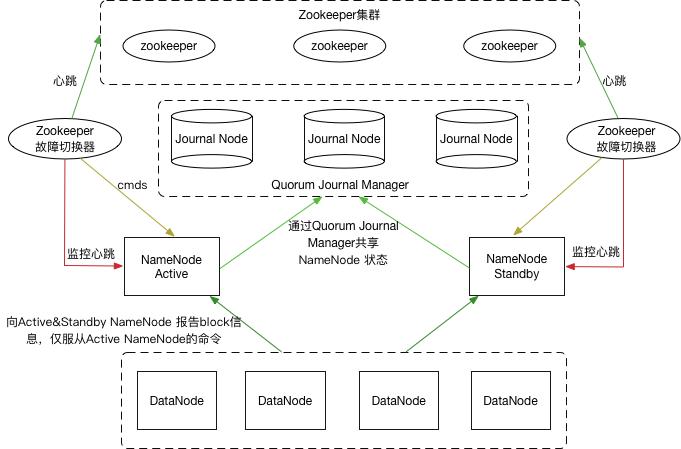
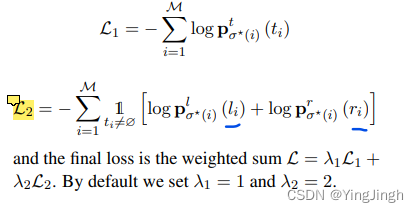文章目录
- 前言
- 数据集准备
- 数据标注
- 数据集格式转换
- AI Studio平台介绍及使用
- 数据集准备
- 创建工程
- 模型配置
- 模型训练
- 模型转化及优化
- 模型减支
- 模型转化
- 验证测试
- 总结分析
- 参考文献
前言
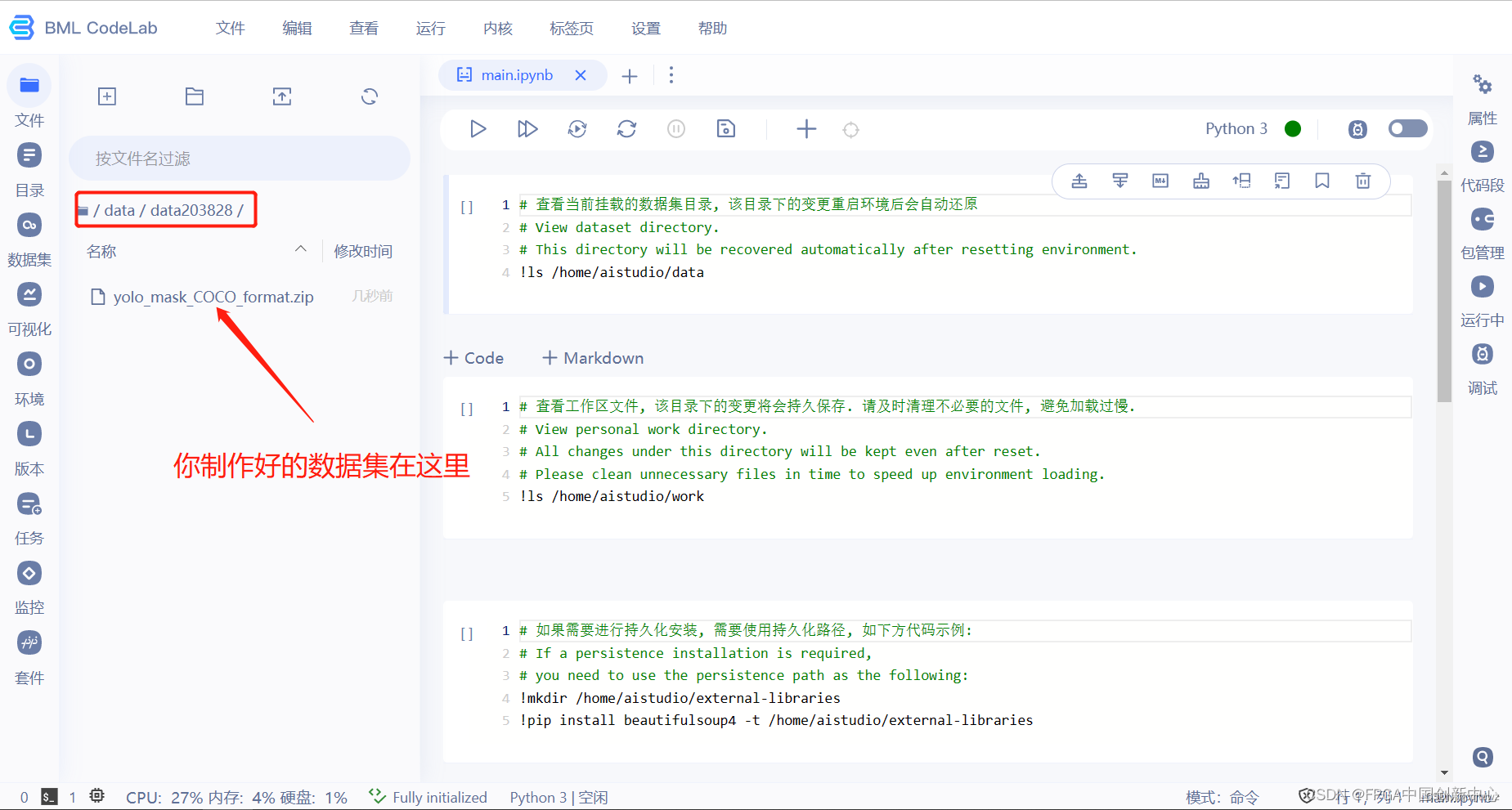
环境:
python 3.7.9
本次项目的内容是基于卷积神经网络的人脸笑容识别和性别识别。
笑容识别:
借助CNN的优势,模型能够自动识别人脸图像中是否含有笑容这一特征。通过对724张带有笑容和非笑容标签的人脸图像样本进行训练,模型能够学习到笑容的关键特征。通过提取这些特征,并结合适当的分类算法,模型能够在新的人脸图像上进行的笑容识别。
性别识别:
通过这个模型,能够自动地根据人脸图像来判断人的性别。
使用了八百多张有标记性别的人脸图像作为训练数据。通过学习这些图像中不同性别之间的特征差异,模型可以识别出人脸图像中的性别信息。通过结合适当的分类算法,模型能够在新的人脸图像上进行性别识别。
本文主要以笑容识别为例,性别检测与笑容检测实现方法相同可以照搬。
数据集准备
如果能够找到相应的数据集建议直接从网上下载,避免自己准备的图片数据集有误,这一步我将会讲解我在数据集准备时候的方法和遇到的问题
首先我们进行了数据集的准备,由于第一次进行模型数据集的收集没有经验,导致后面对数据集进行处理出错埋下了隐患。在进行人脸数据收集时,我们小组通过python写了一个通过输入关键字,自动下载有关图片的程序。这个程序大大节省了收集数据的时间。
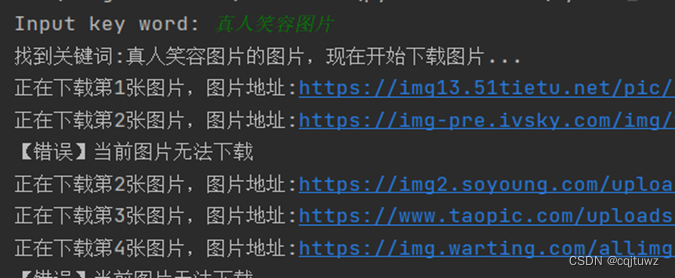
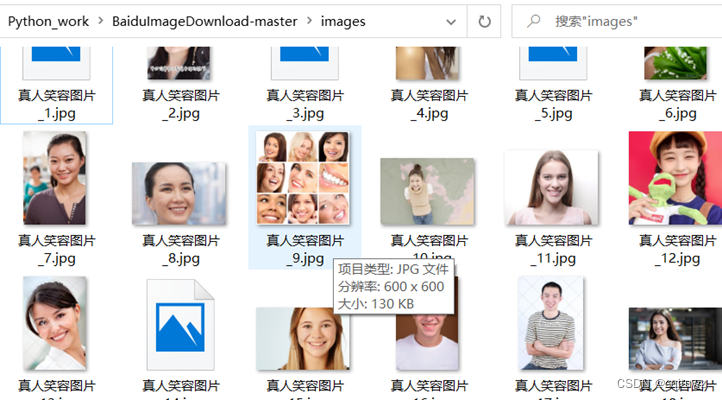
之后,我们通过再次通过python程序将数据集整理成为统一的命名格式,并打乱有笑容与无笑容的图片。
数据标注
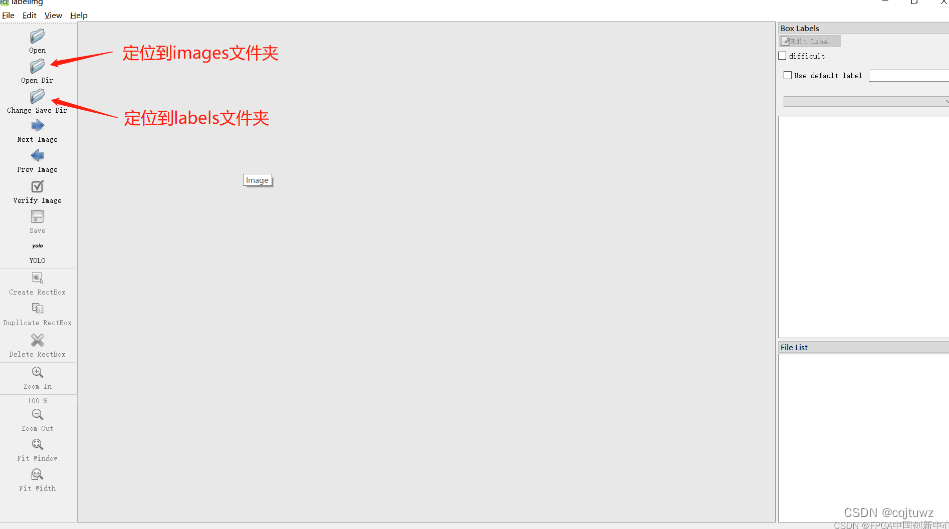
通过在python的环境中安装labelimg,进行数据集的标注。labelimg的使用方法请参考:数据标注
进行数据标注之前要选择YOLO数据集格式
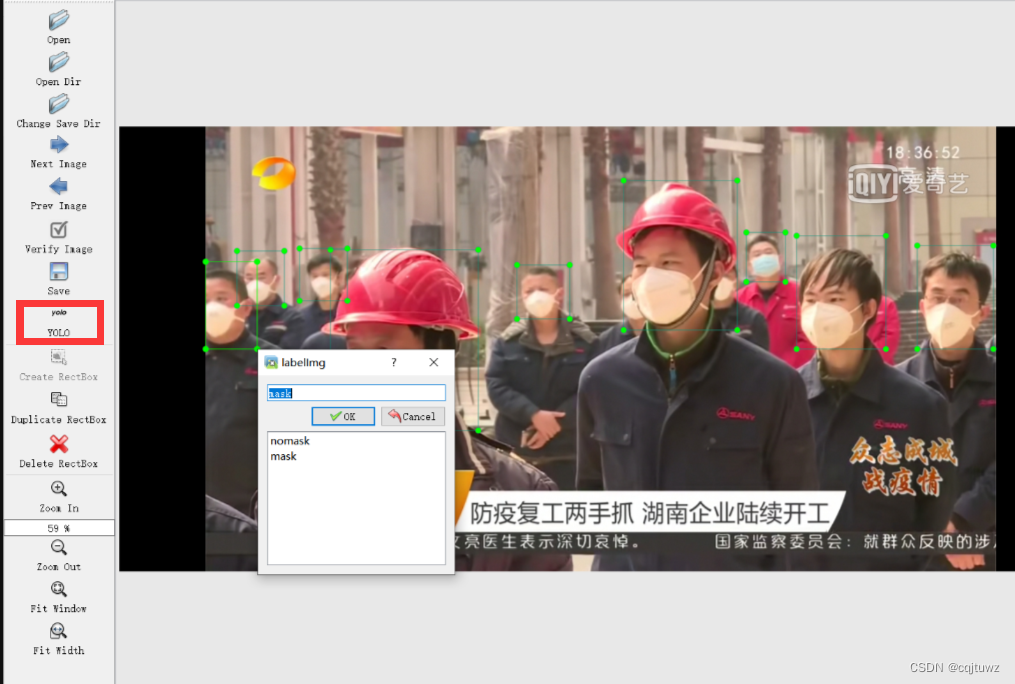
进行数据标志的时候需要注意的是,如果是多人合作进行数据标注的话,由于最开始的对于不同标签的标注顺序不同,会导致生成的标签不一致。因此,在多人标注数据之前要按照相同的顺序对每一种数据类型进行一次标注。避免由于最开始的标注顺序不同人所标注的标签代号顺序不同。

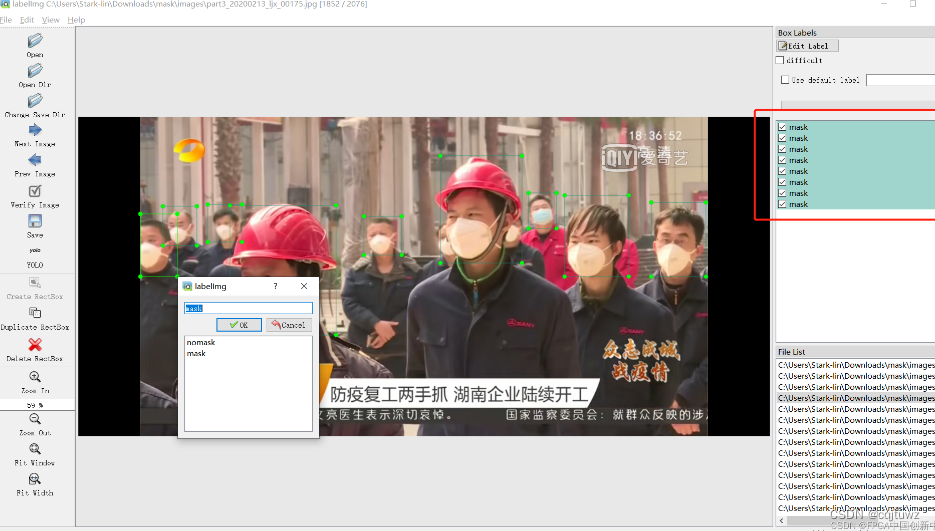
在完成数据集的标注之后,最好抽样检查一下,是否图片与生成的label文本文件中的标签一致。我这里0代表happy,1代表sad(没有笑容)。
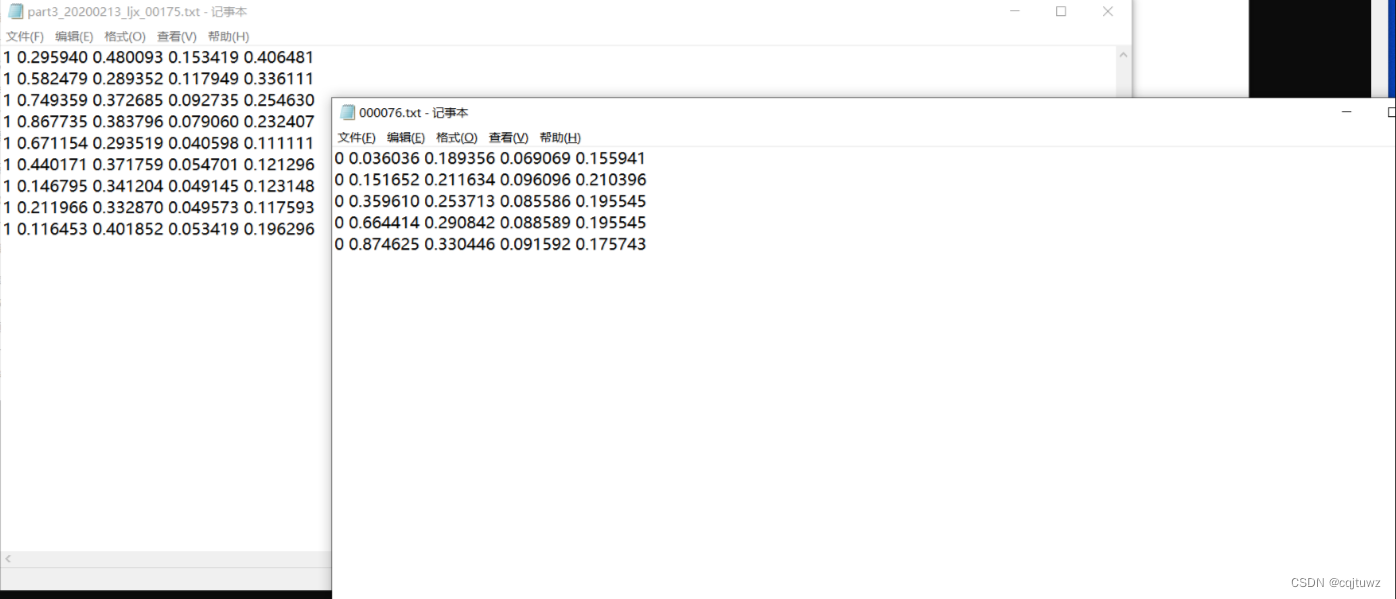
数据集格式转换
完成数据集的标注之后,由于我们使用的训练平台不支持YOLO数据集,因此需要将YOLO格式的数据集转换成为COCO类型的数据集。转换流程参考:数据转换
AI Studio平台介绍及使用
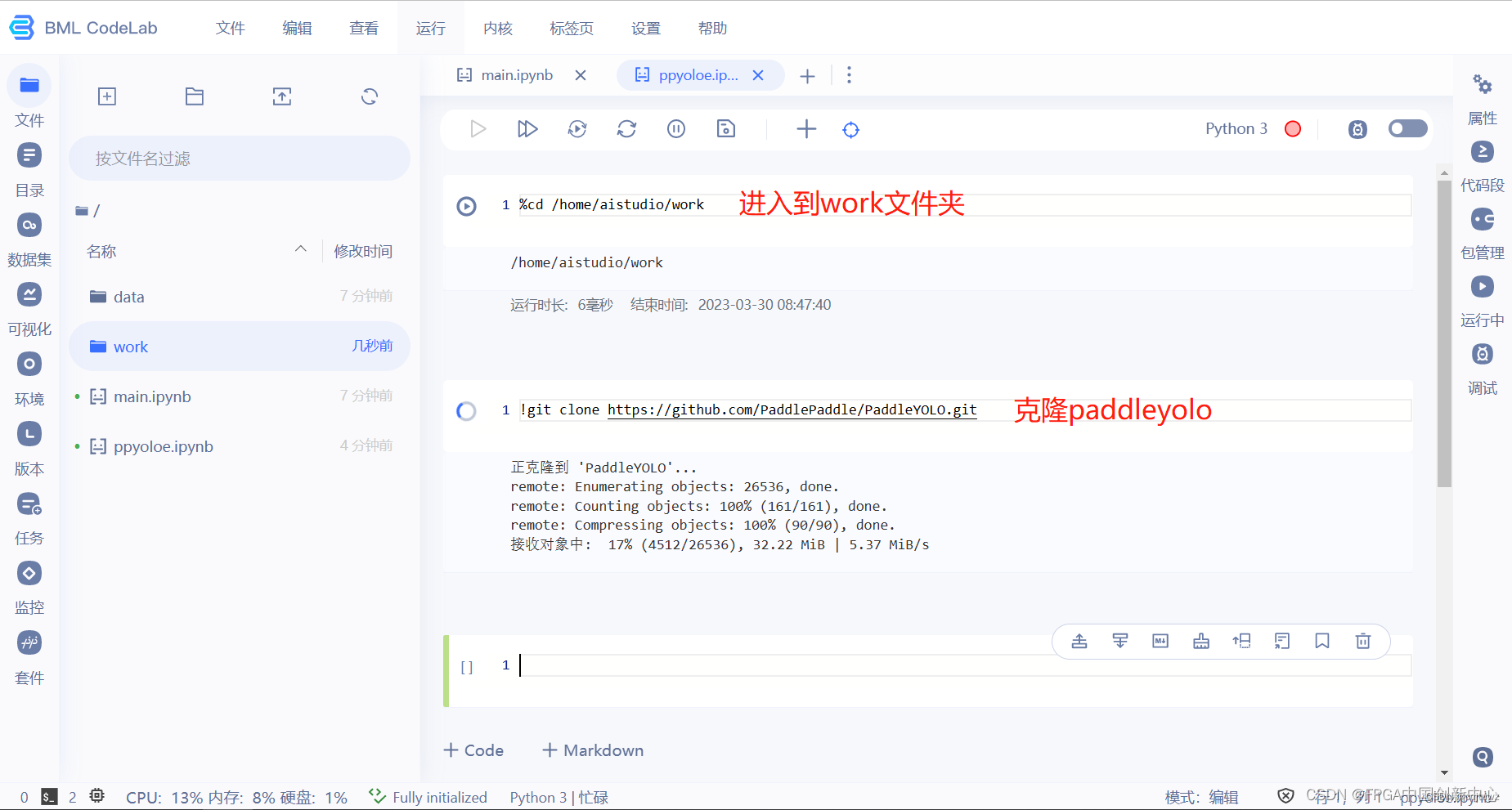
将刚刚生成的COCO类型的数据源集打包上传到平台上进行模型训练的准备。
以下部分是以参考文献中口罩检测为例,我这里直接使用了口罩检测的操作步骤截图,实际上笑容识别和性别识别操作是一样的
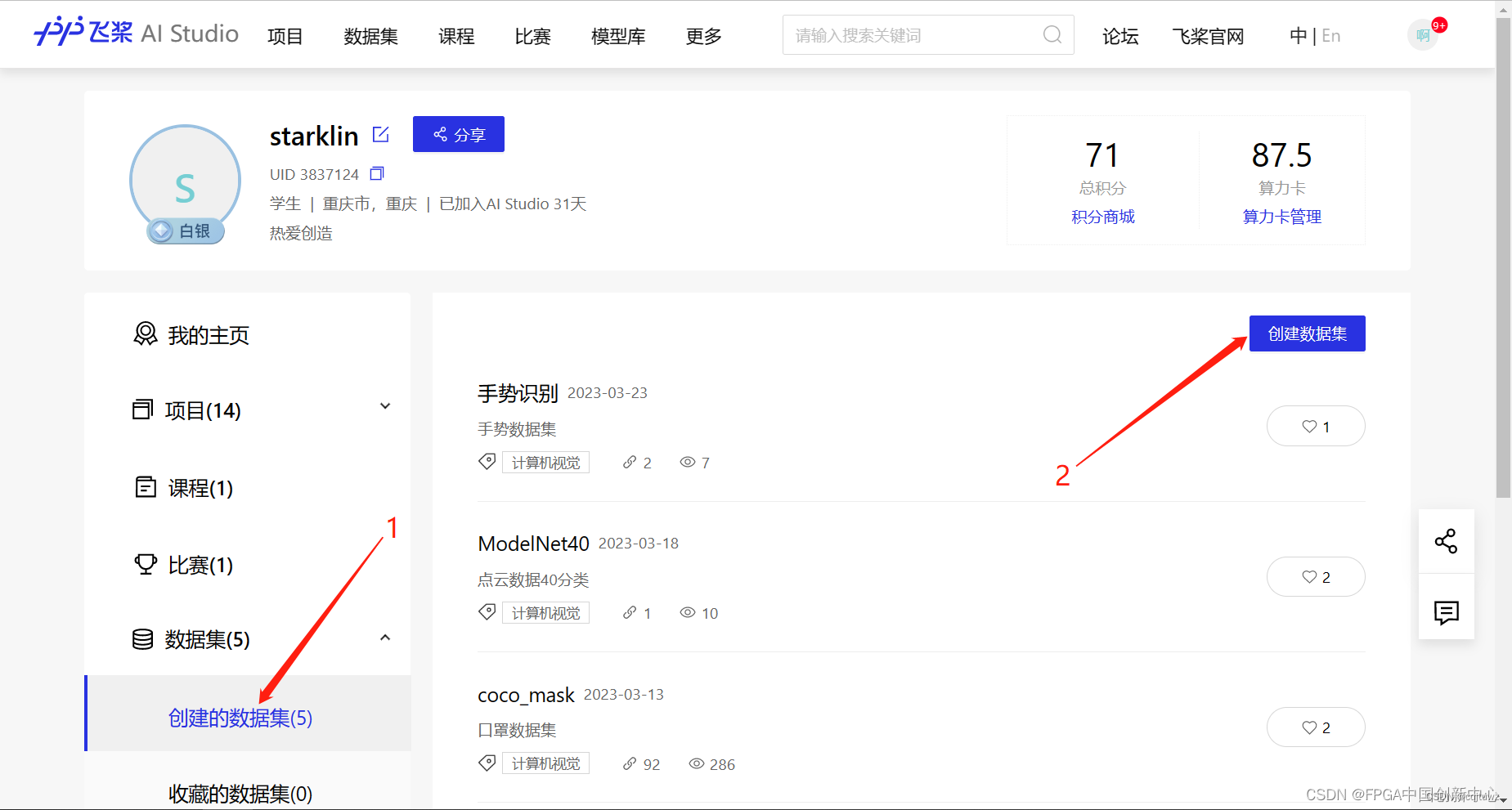
数据集准备
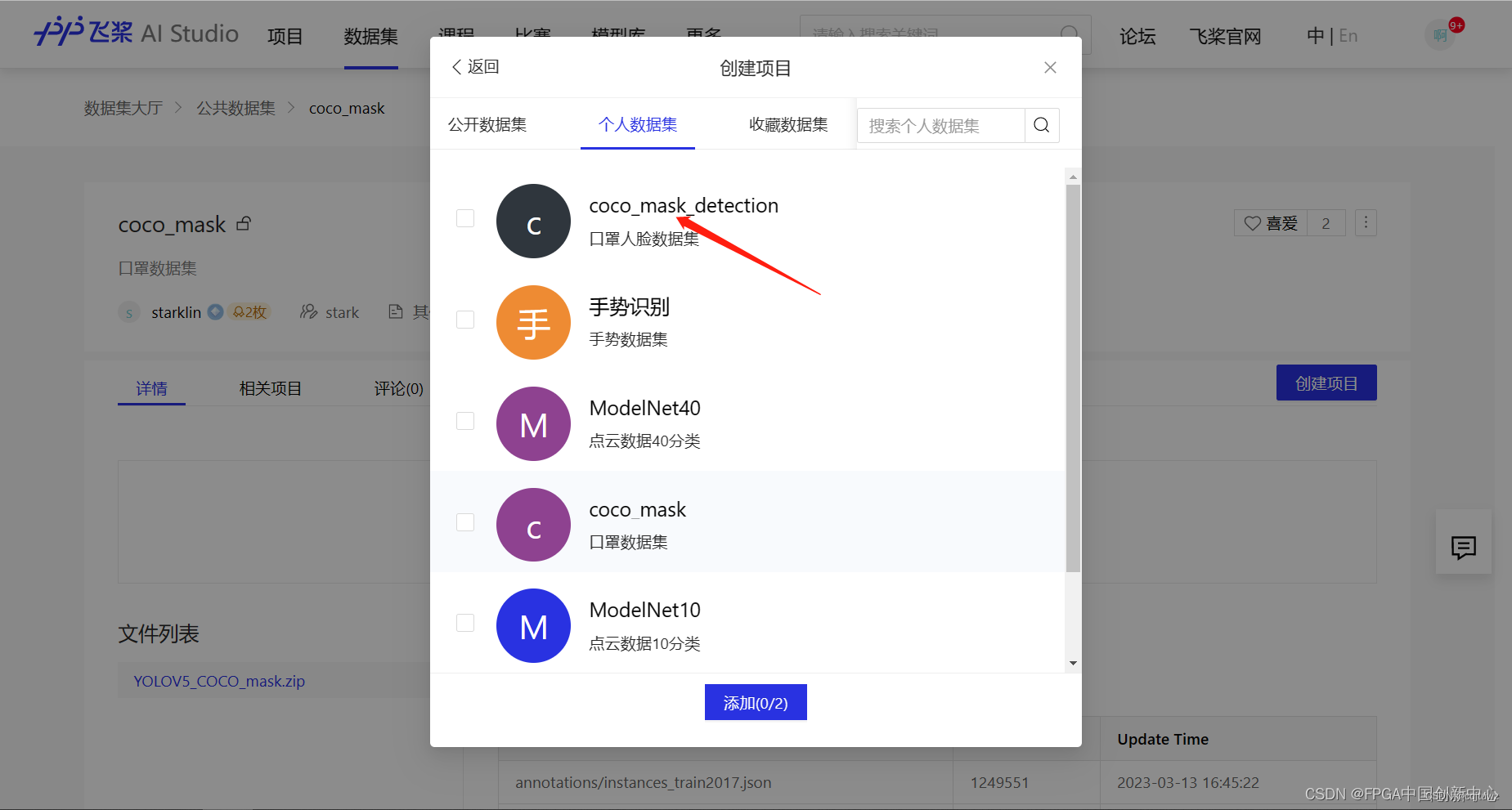
因为数据集过大,启动一个项目,然后直接上传是不行的,所以先创建一个数据集,再在数据集基础上创建项目。
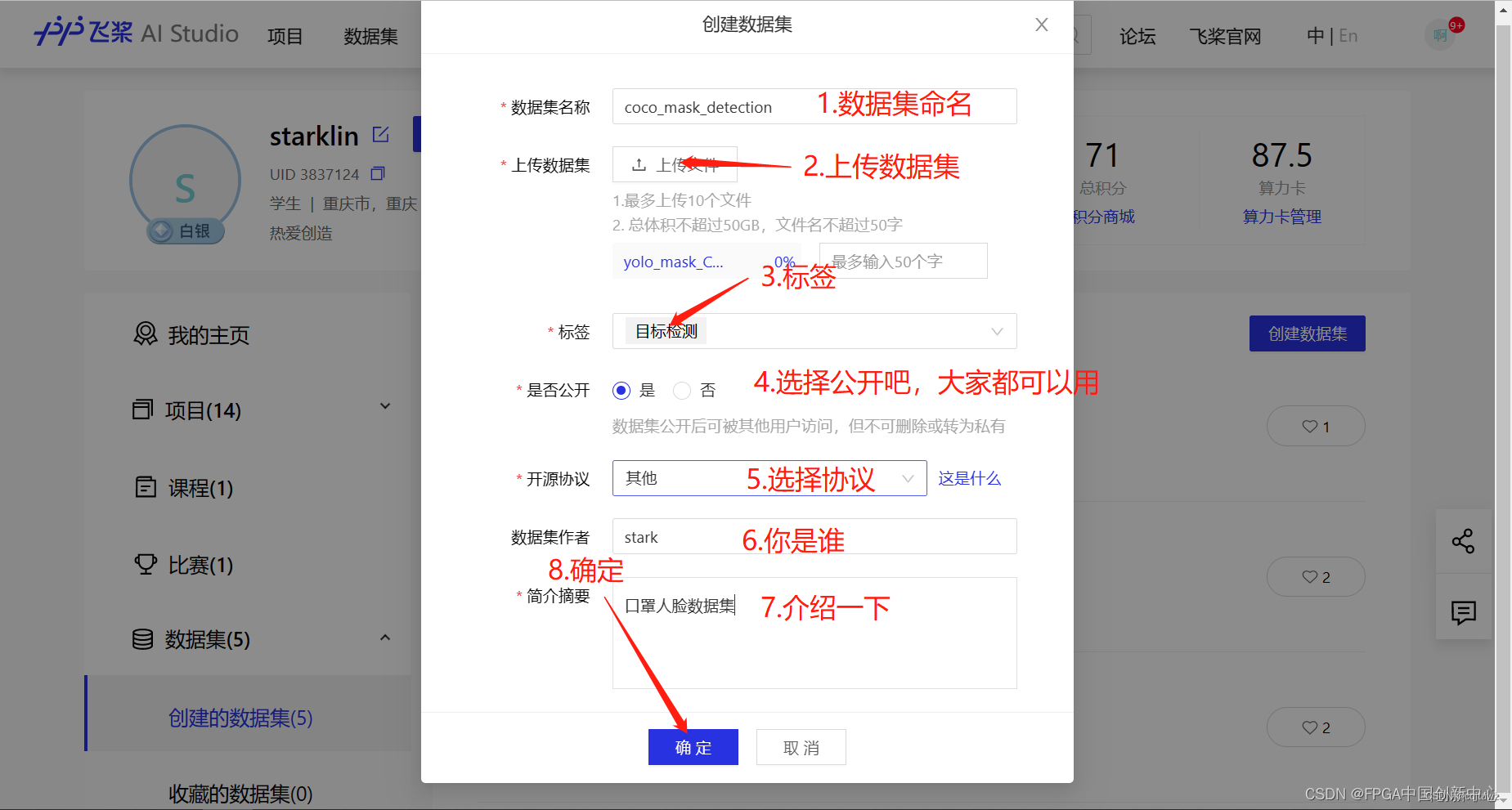
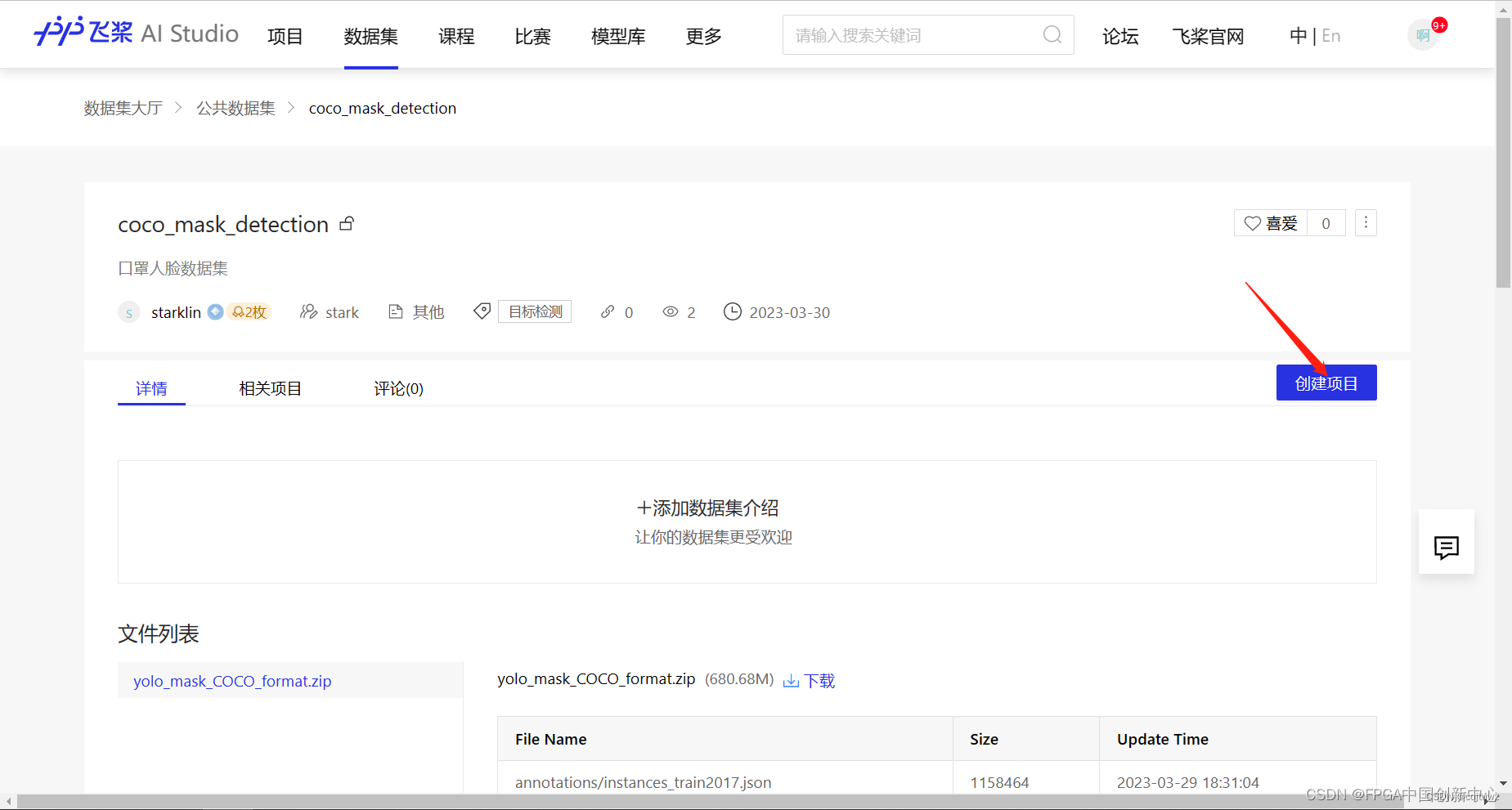
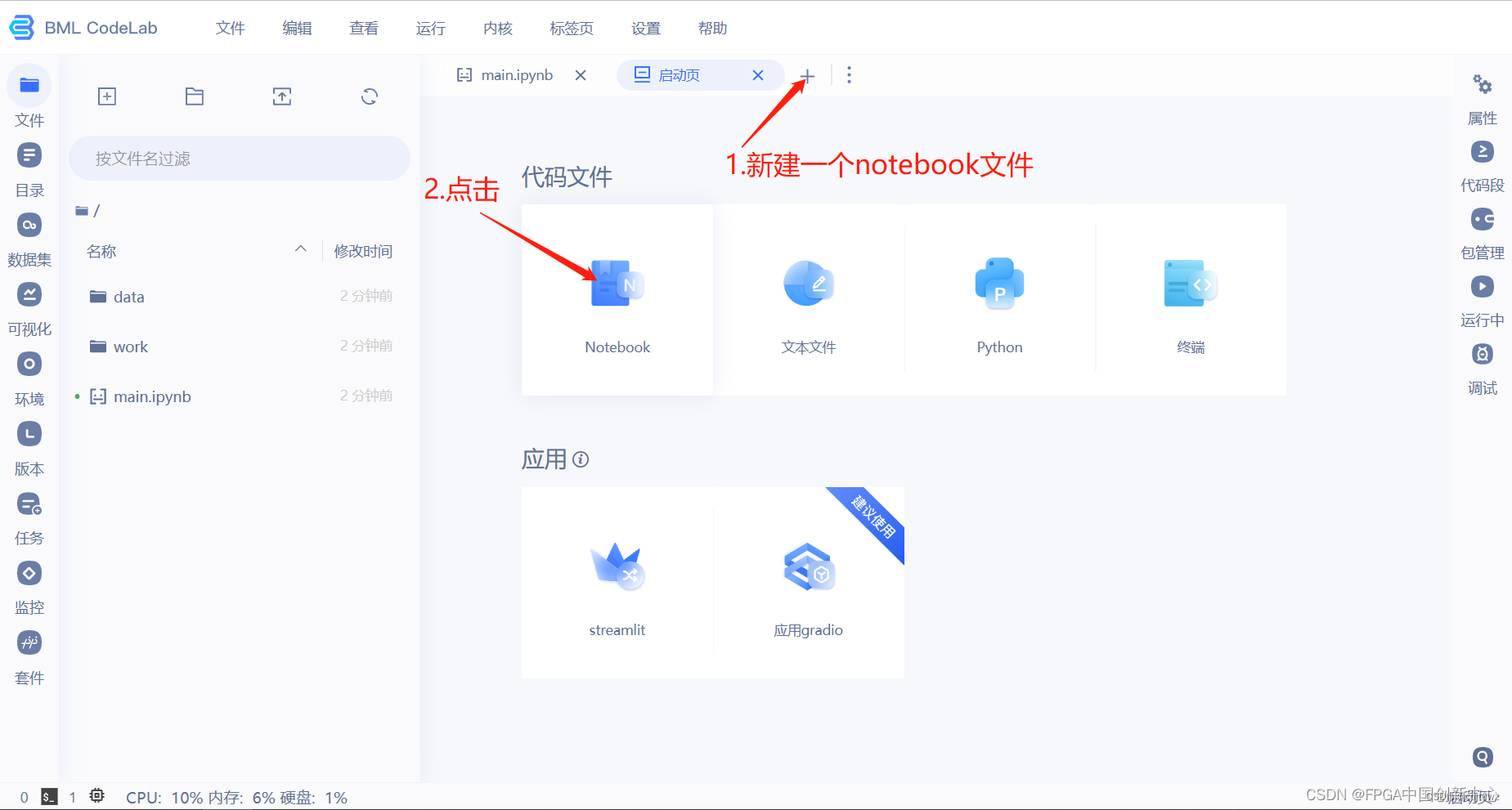
创建工程
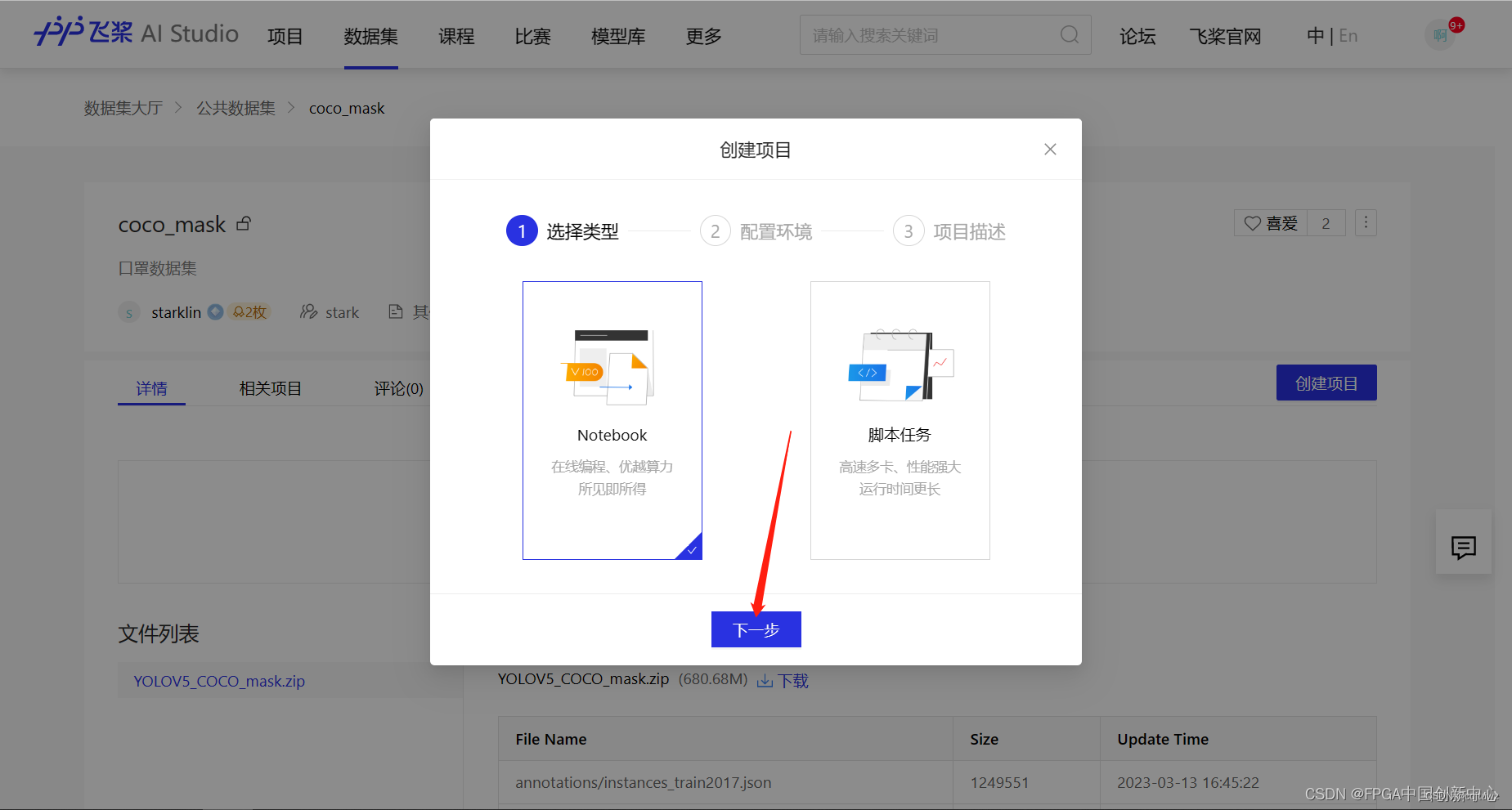
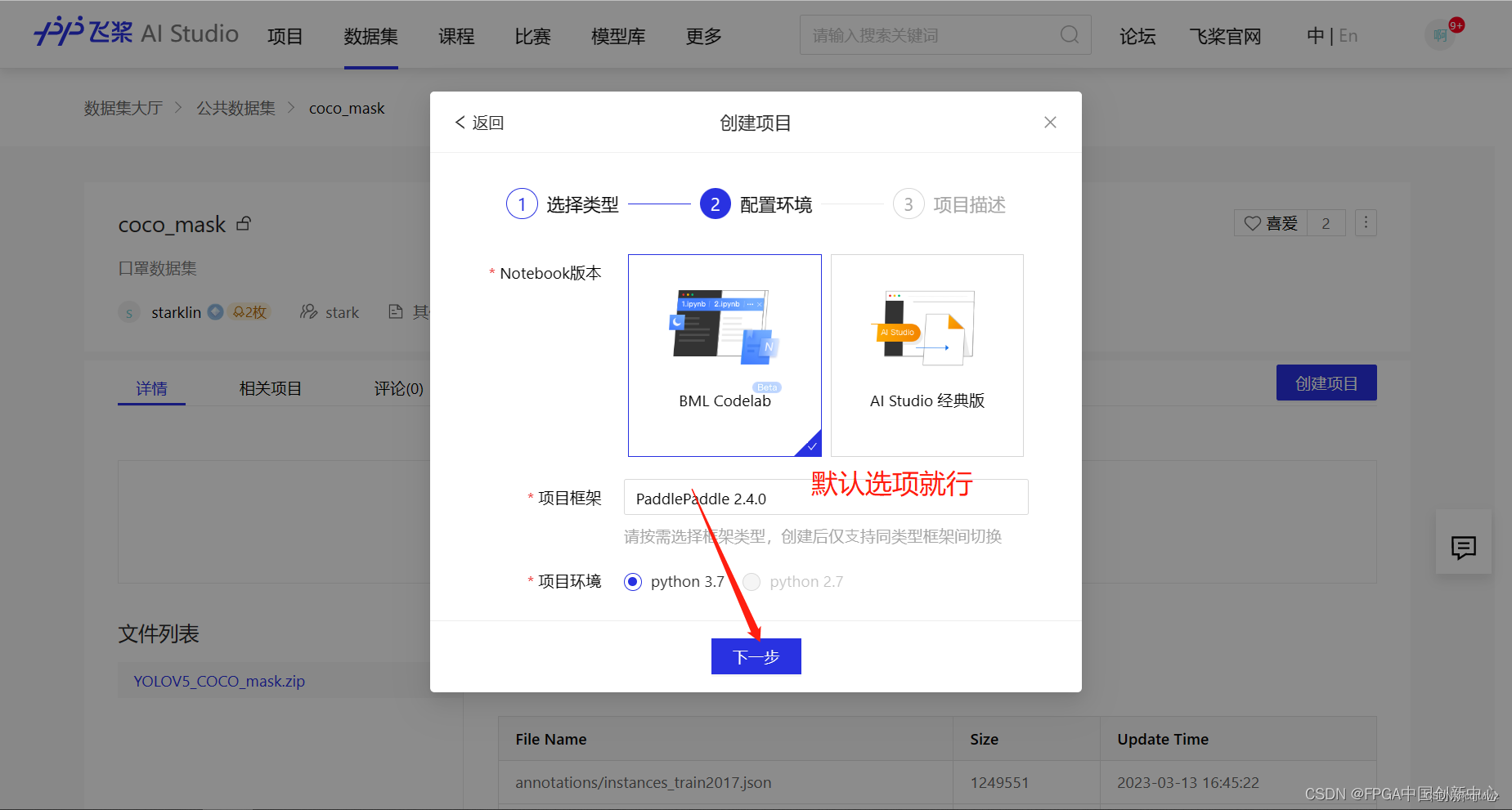
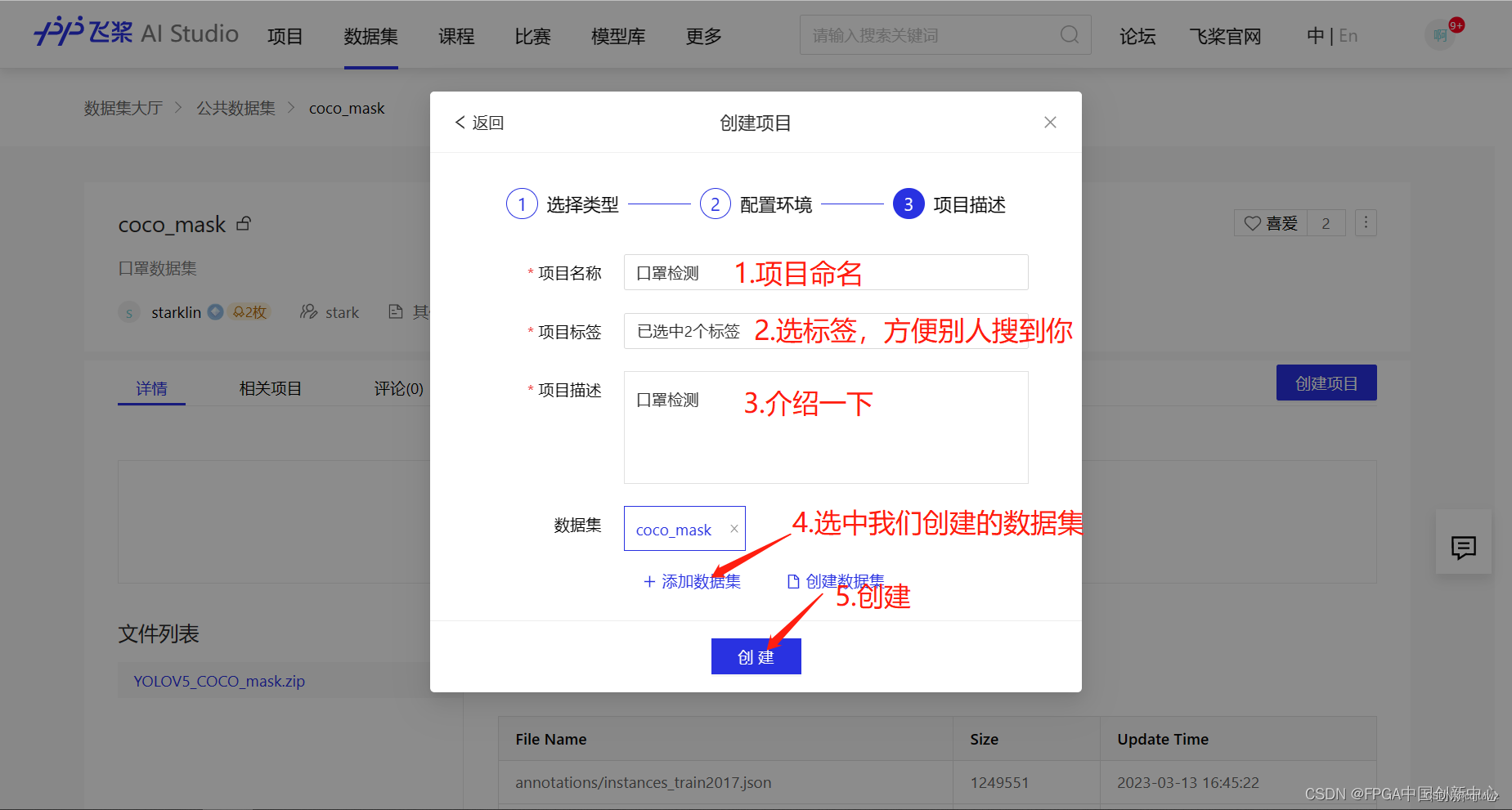
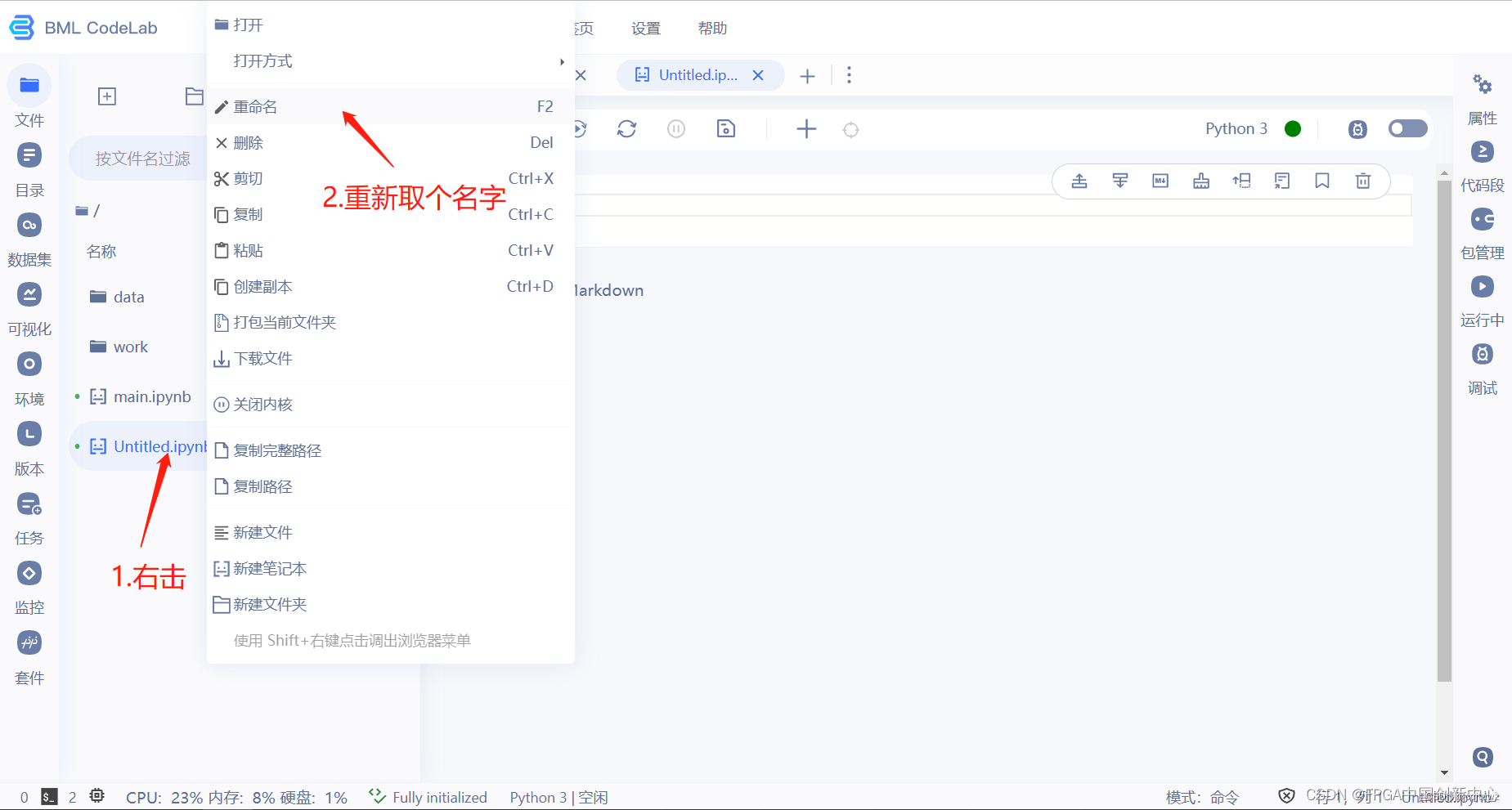
以下页面是点击4.选中我们创建的数据集弹出的框。
模型配置
在configs下面有很多模型,文件夹名就是模型名字,除了可以使用ppyoloe,还有yolov5,yolov8等。
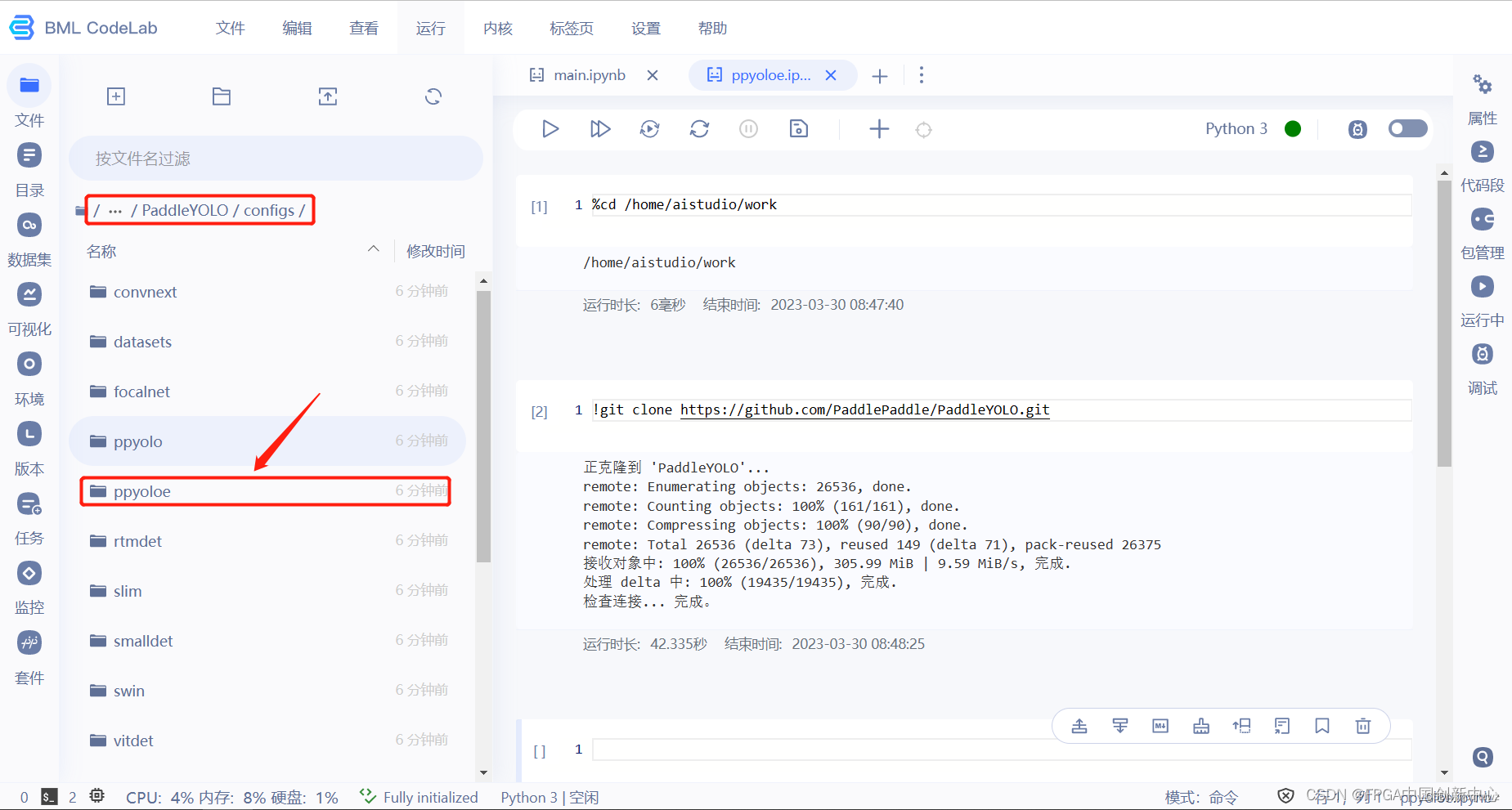
选择一个模型文件夹,修改文件夹里面的配置文件,我们选择的是small版本的ppyoloe,需要训练80 epochs。
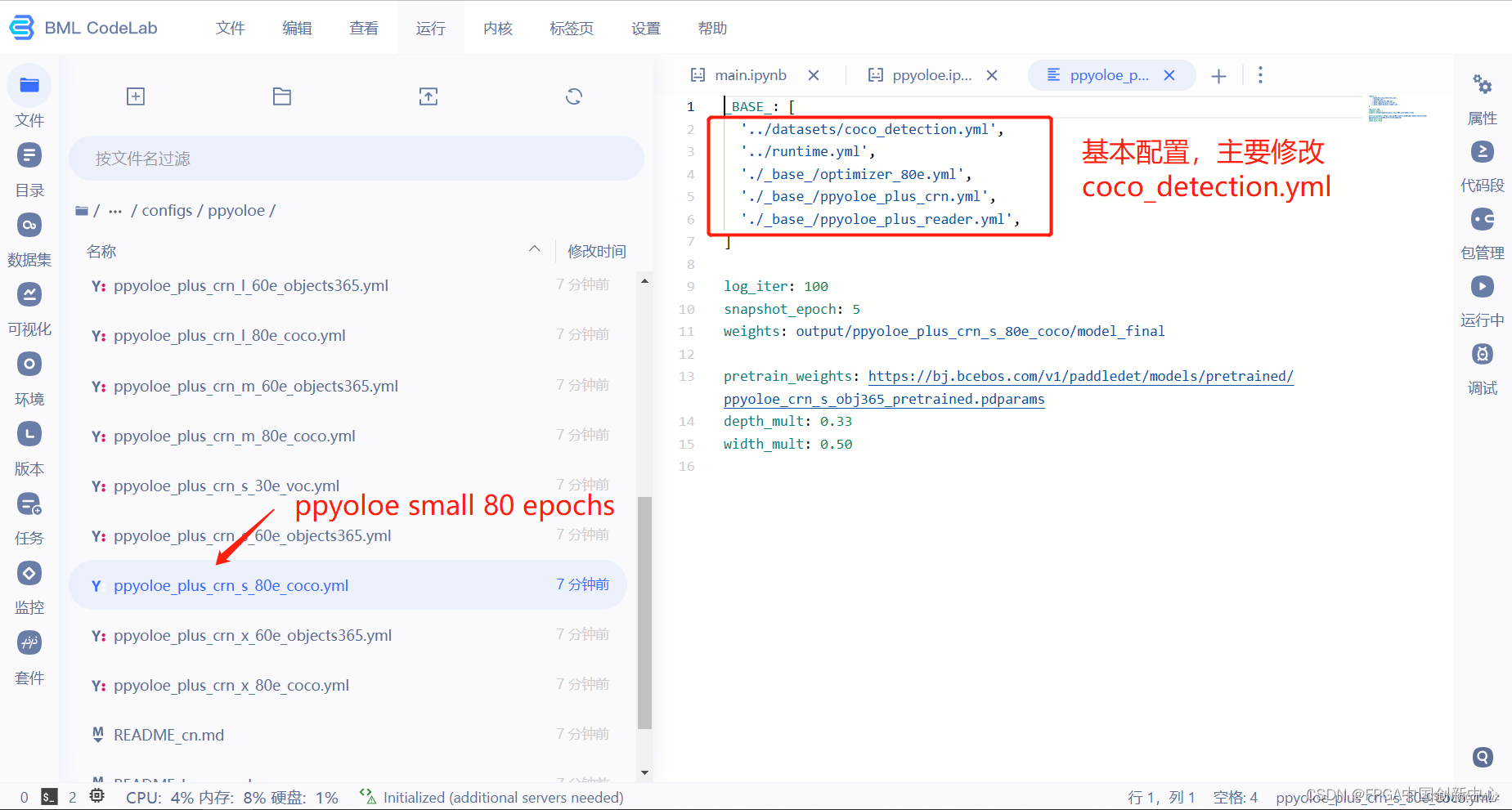
我们需要把num_classes修改成2,因为我们的数据集只有两个标签,分别是nomask,mask。改完记得ctrl+s保存。
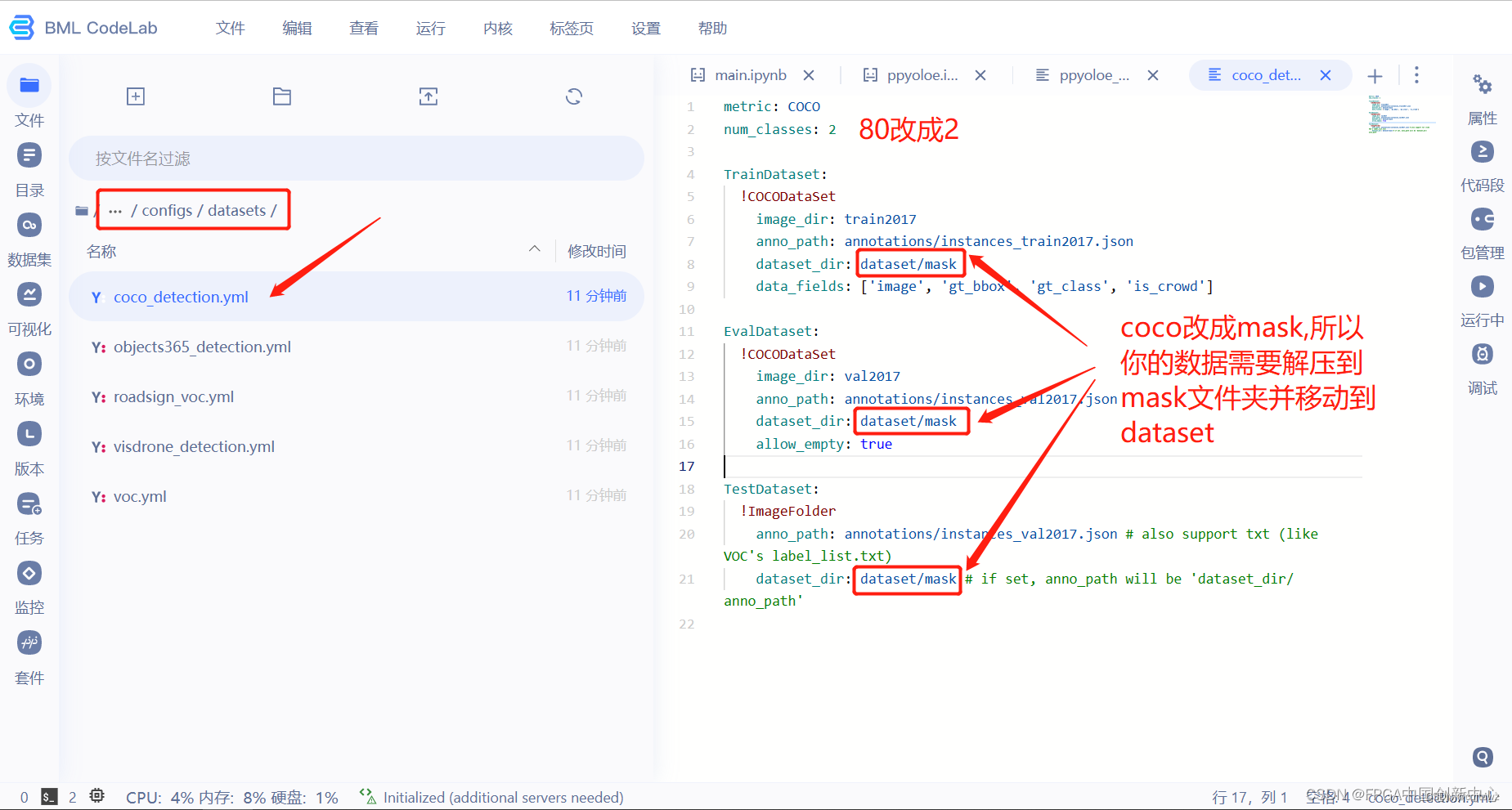
因为配置文件中要求数据放到dataset/mask里面,所以需要把数据集放置到此处。
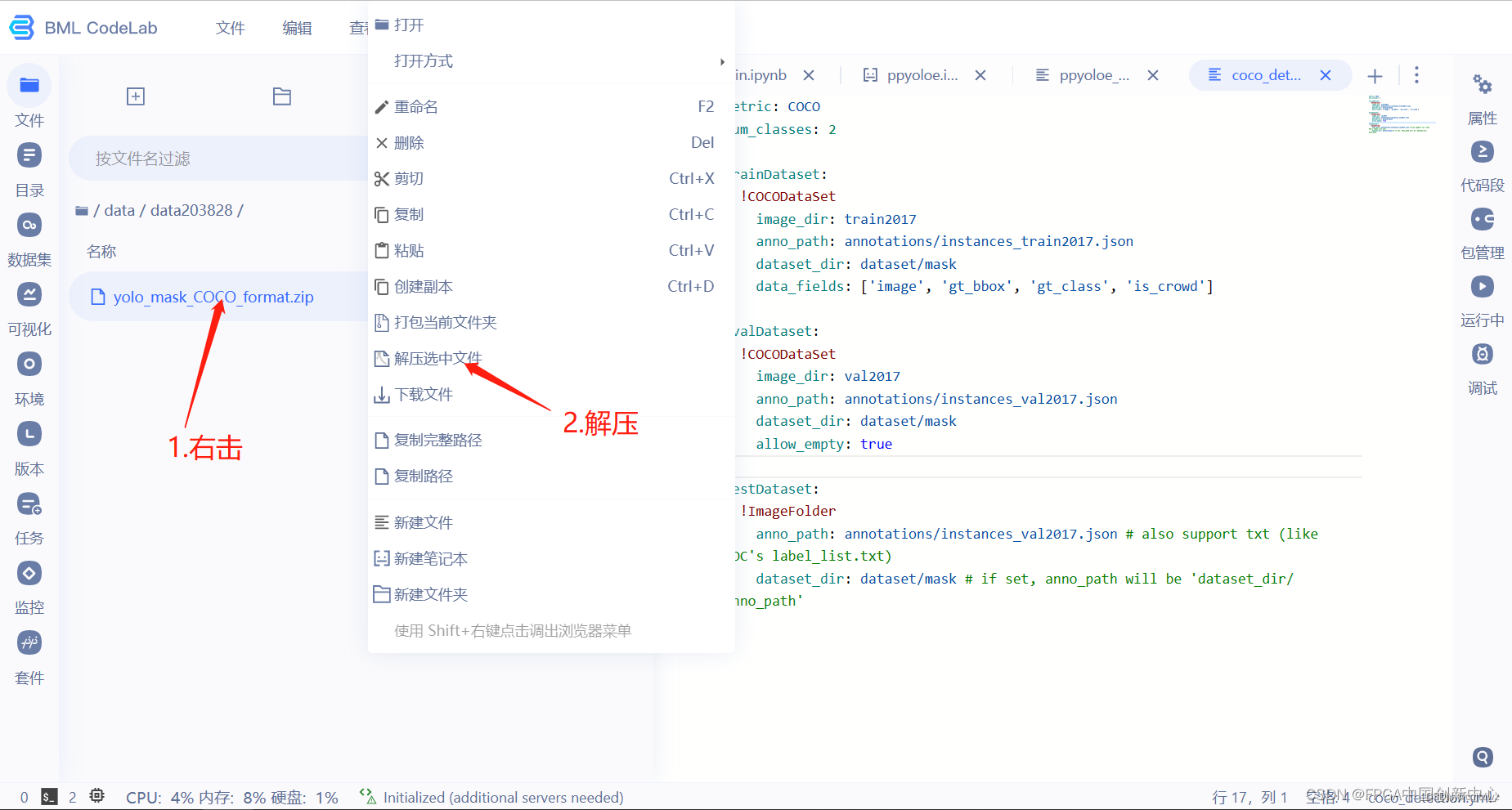
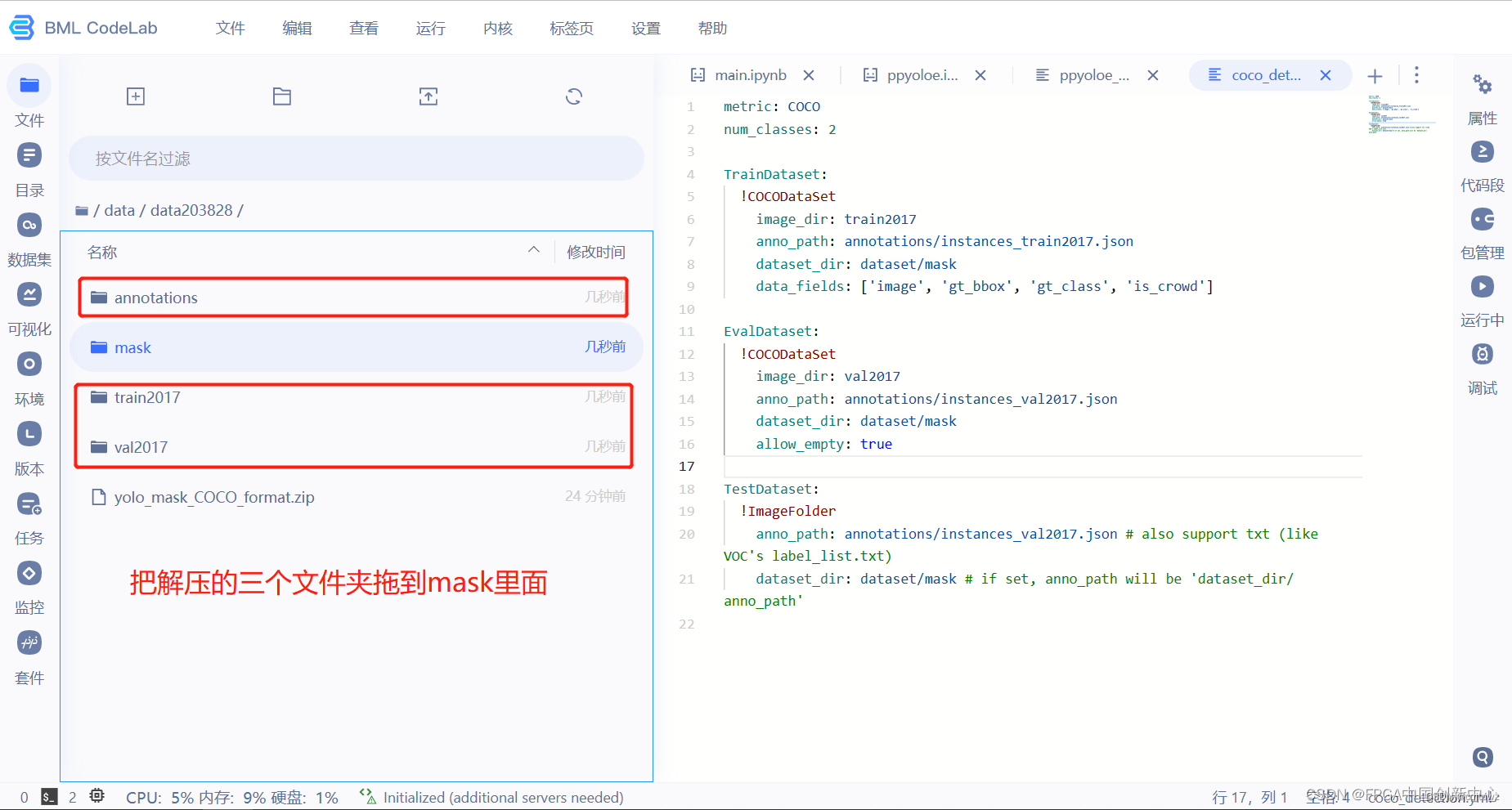
新建一个mask文件夹,把解压过后的数据文件夹拖到mask里面。
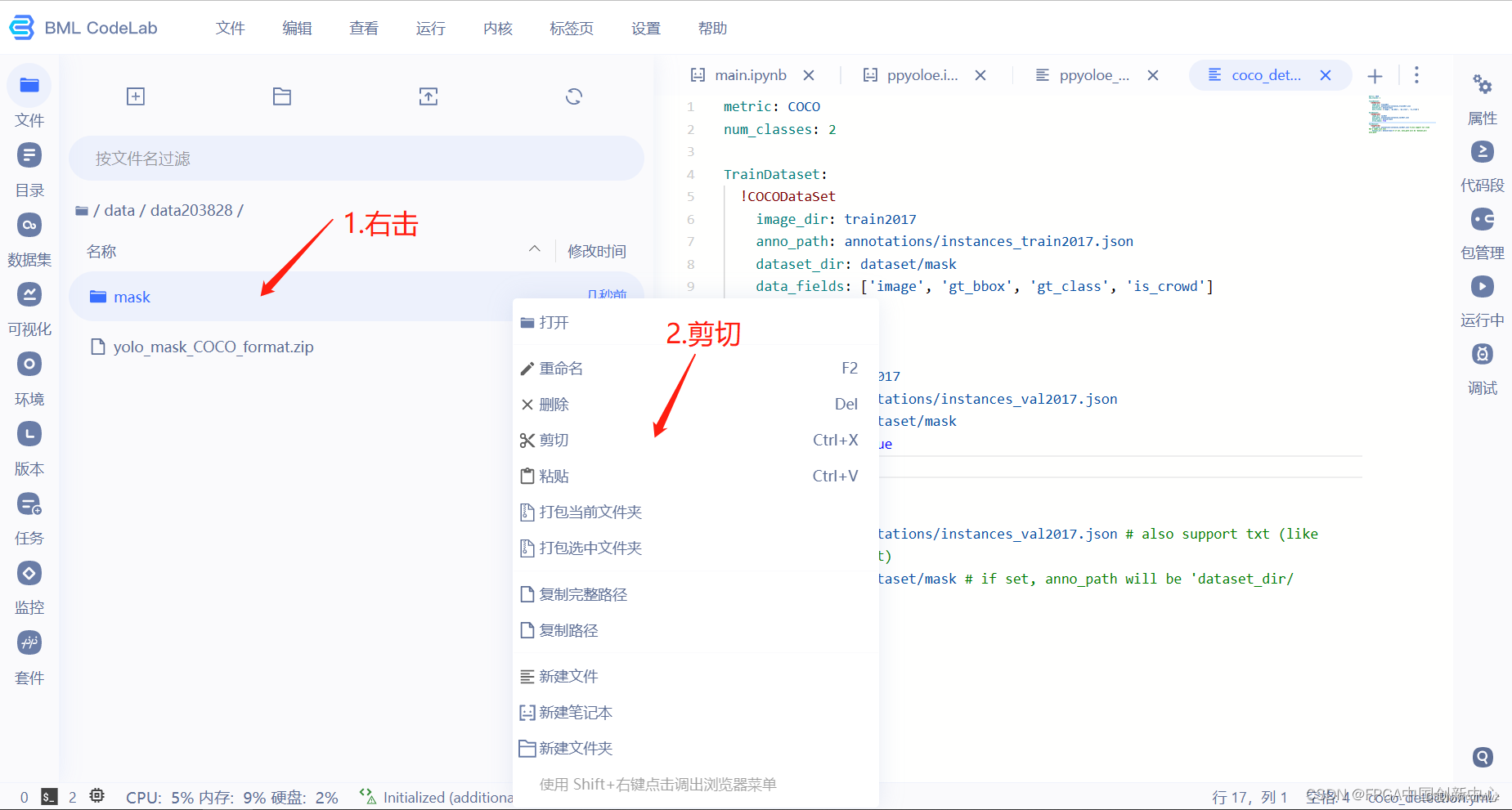
为了方便,直接剪切。
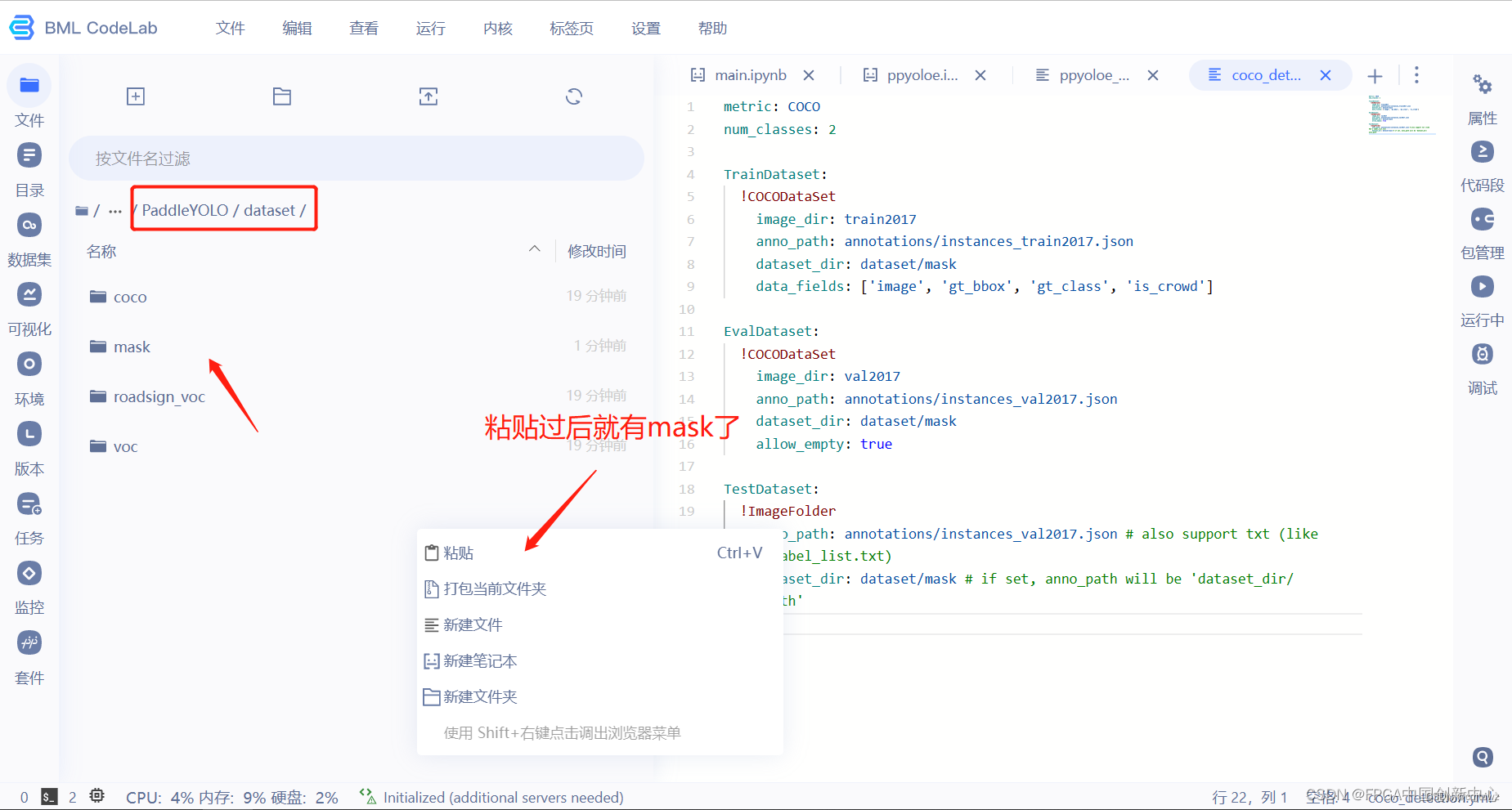
粘贴到dataset文件夹下,注意红色框的路径。
模型训练
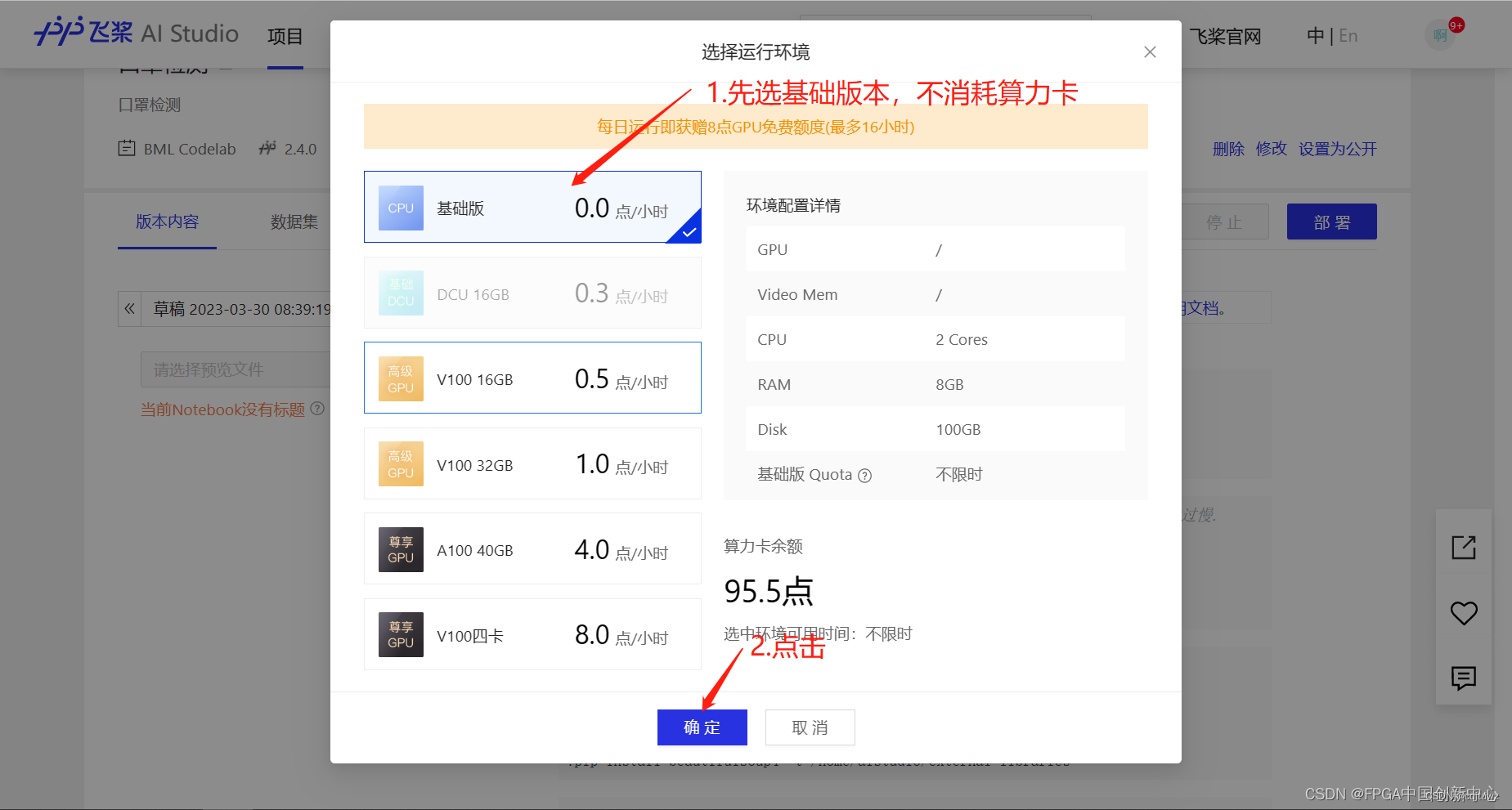
因为我们是基础版本环境,没有GPU,所以需要切换环境。如果你像下面这样切换环境,大概率你是切换不了的,因为文件过多过大。
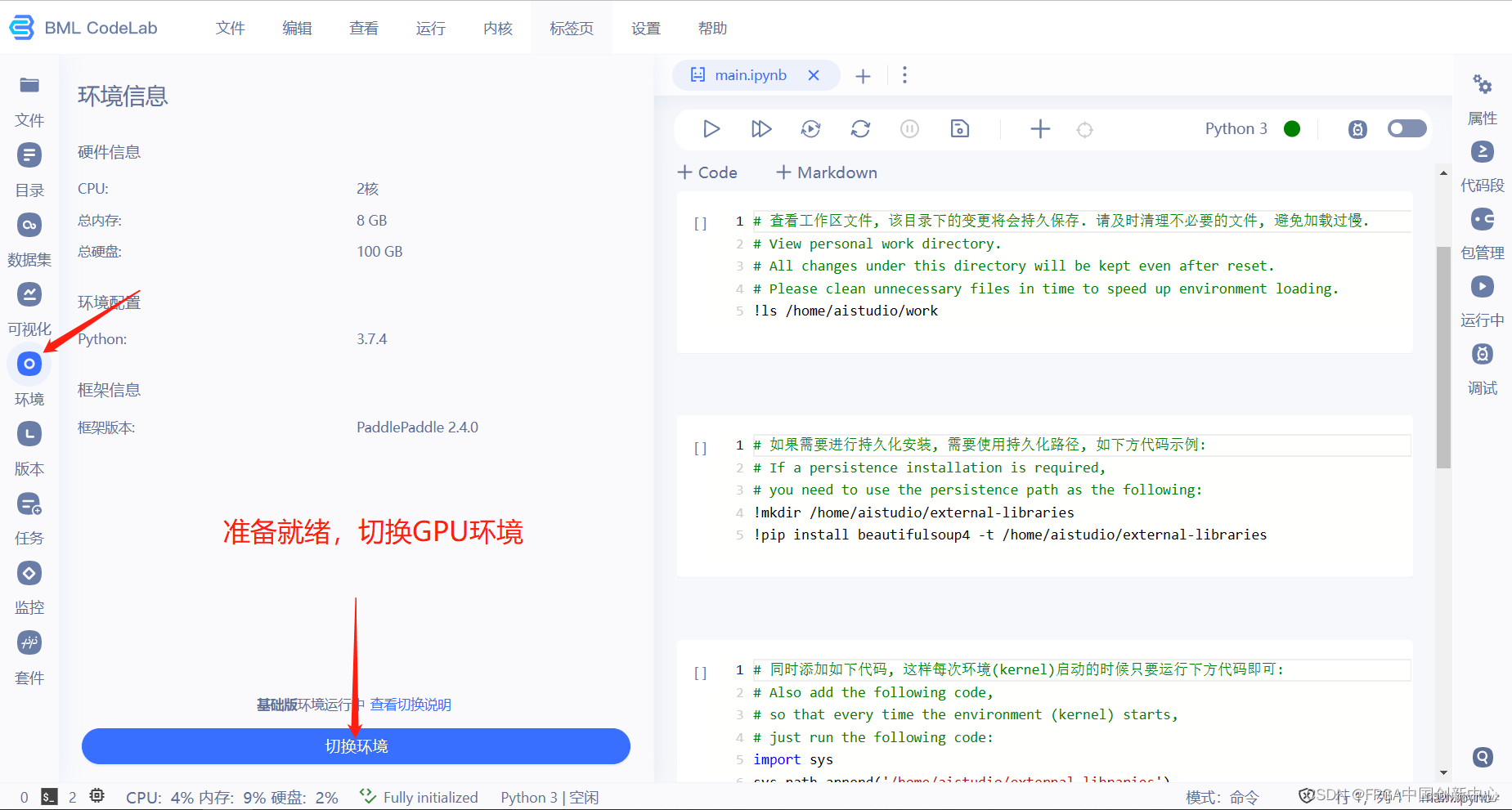
切到这个页面停止
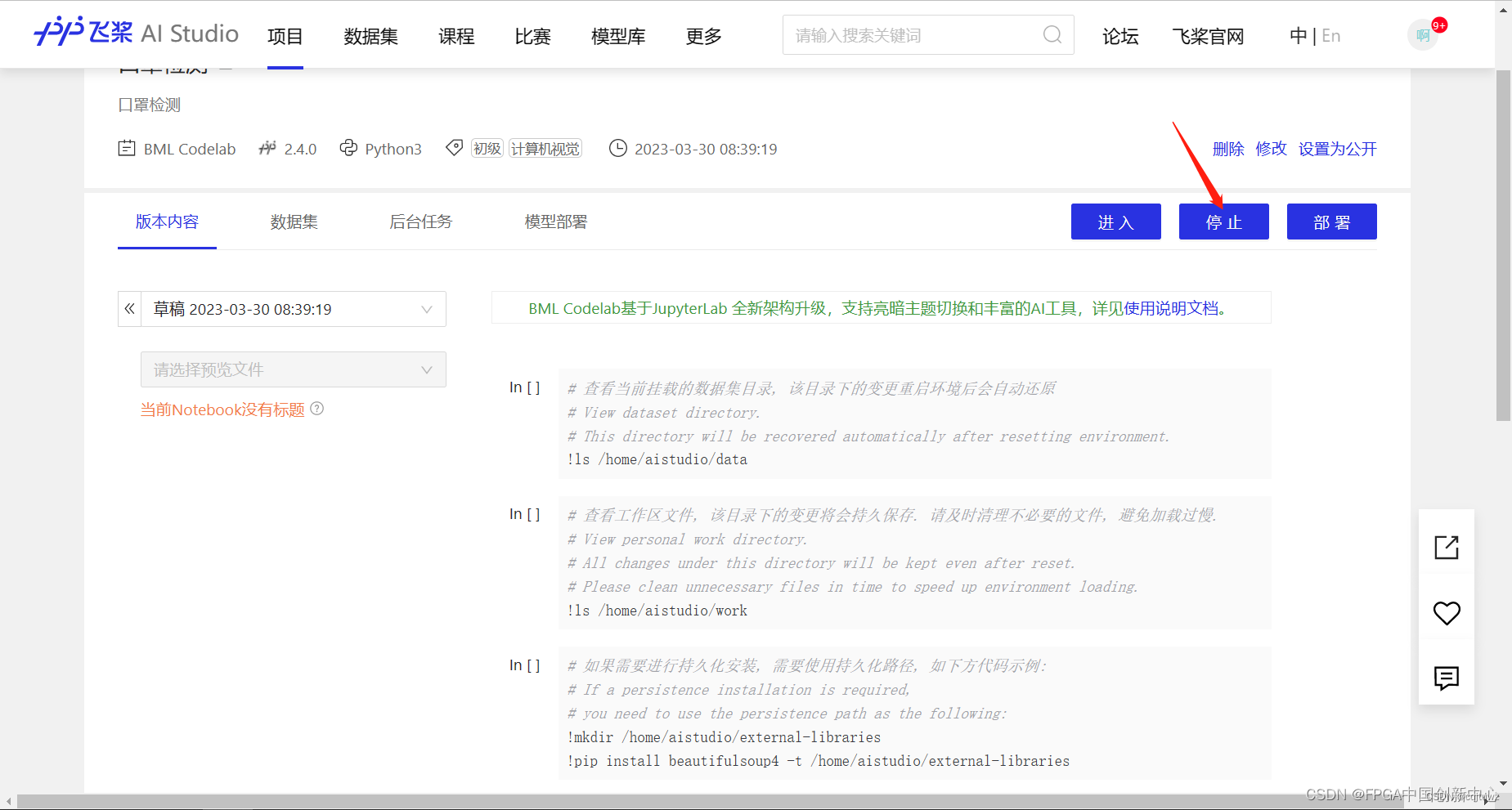
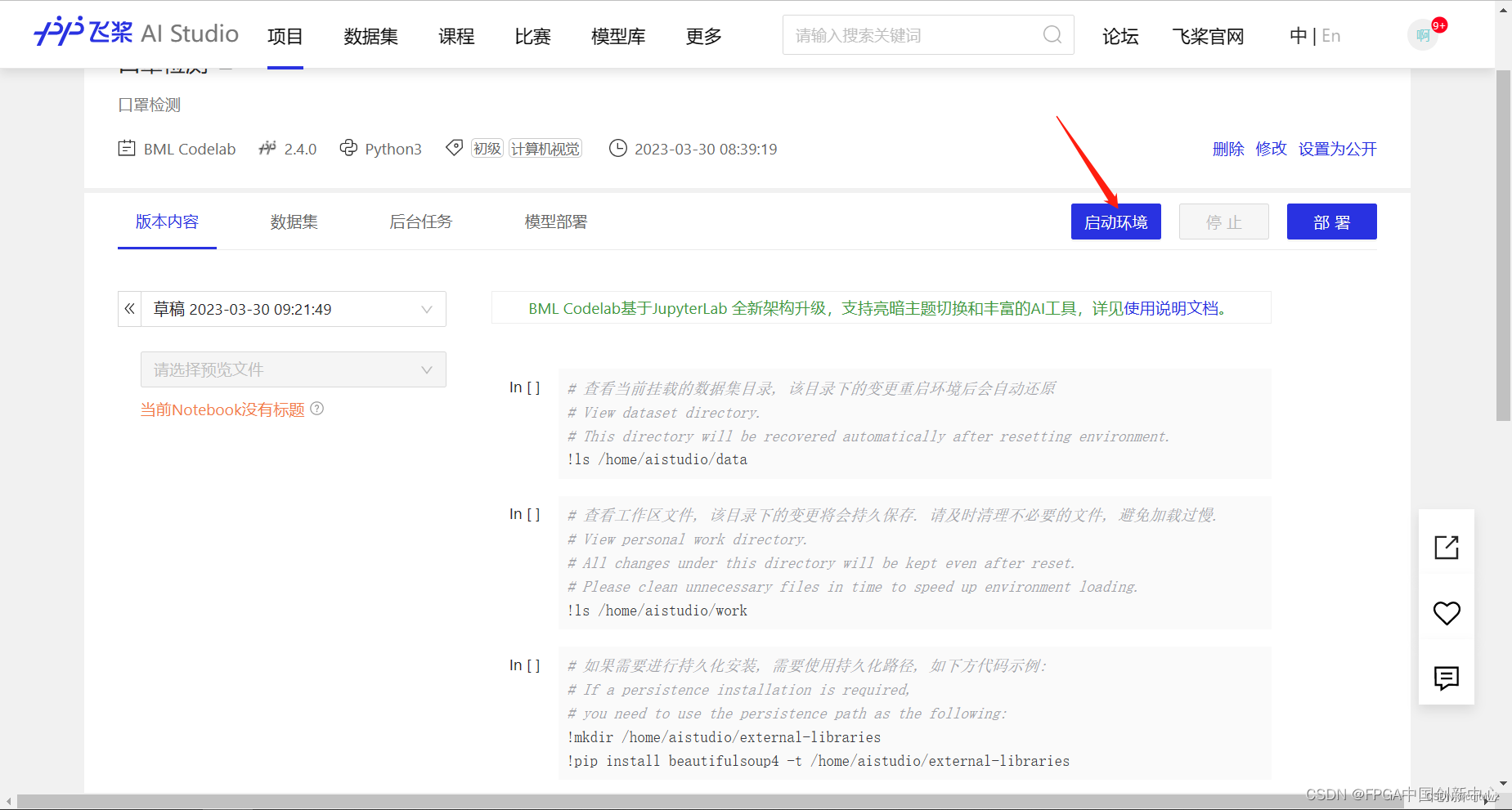
重启环境,但是这次你要选择GPU环境,根据自己的算力卡富余量决定选哪个选项,土豪的话,四个GPU起飞。
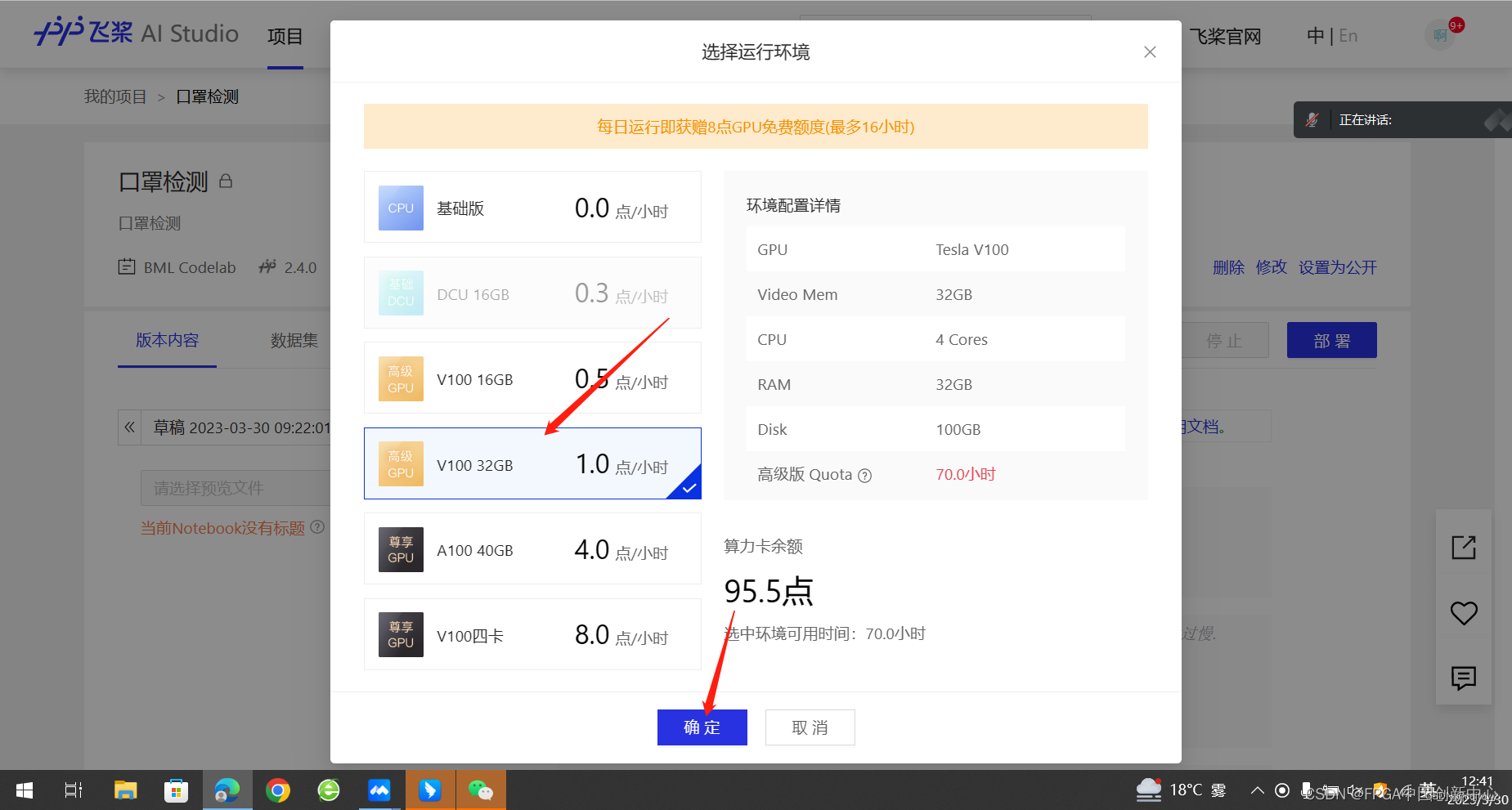
这个模型选这个就可以,新人有免费时长,千万不要浪费,如果模型不复杂数据集不大可以选择算力配置低一点的,如果选择高算力的配置也需要考虑自己的模型能不能在免费时长内完成训练,如果选择不当也可能会导致白白训练几个小时。
在ppyoloe模型文件夹里面有个readme_cn.md,里面有训练模型的命令。将改命令复制到ppyoloe.ipynb文件里面执行。
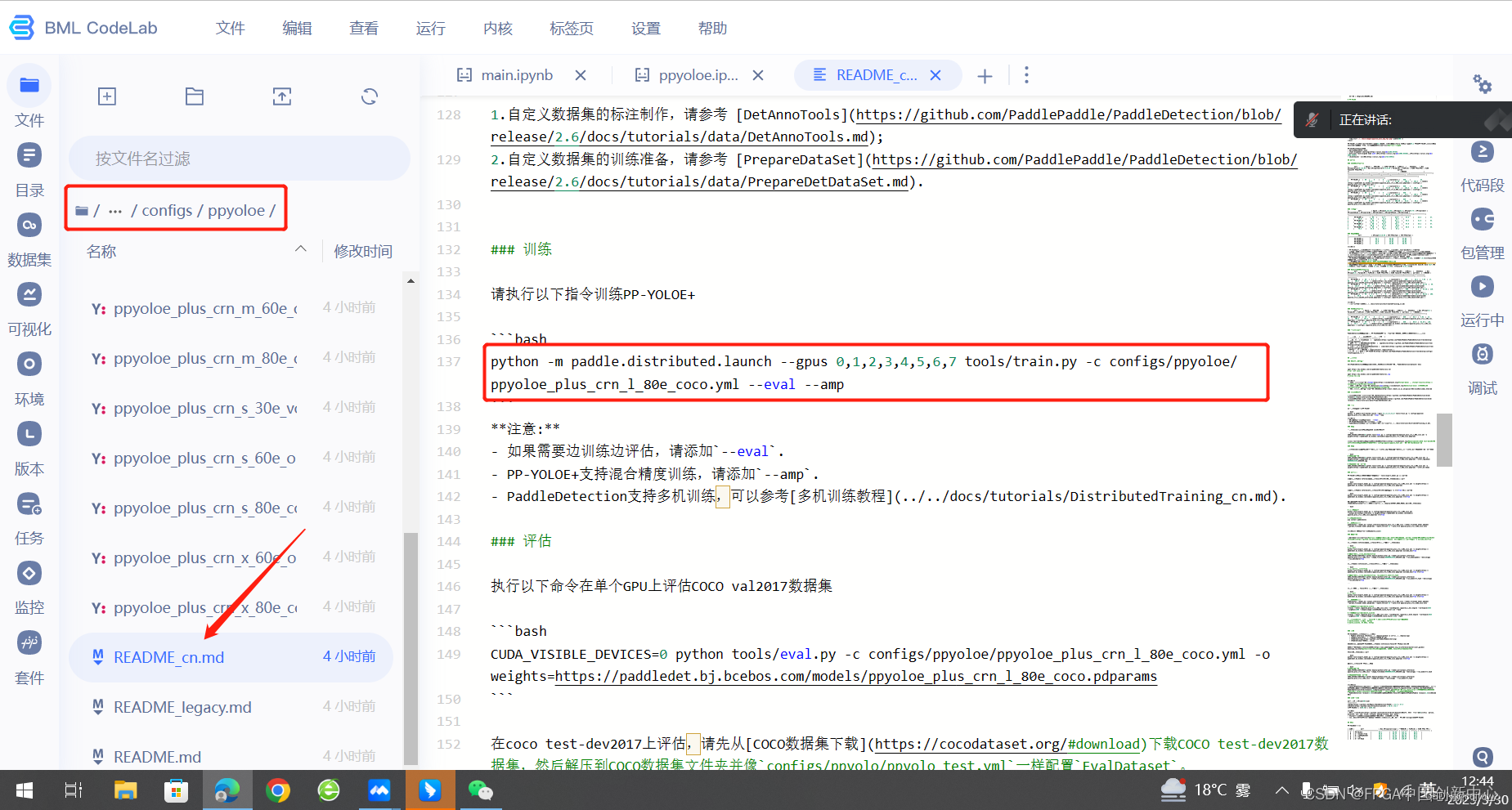
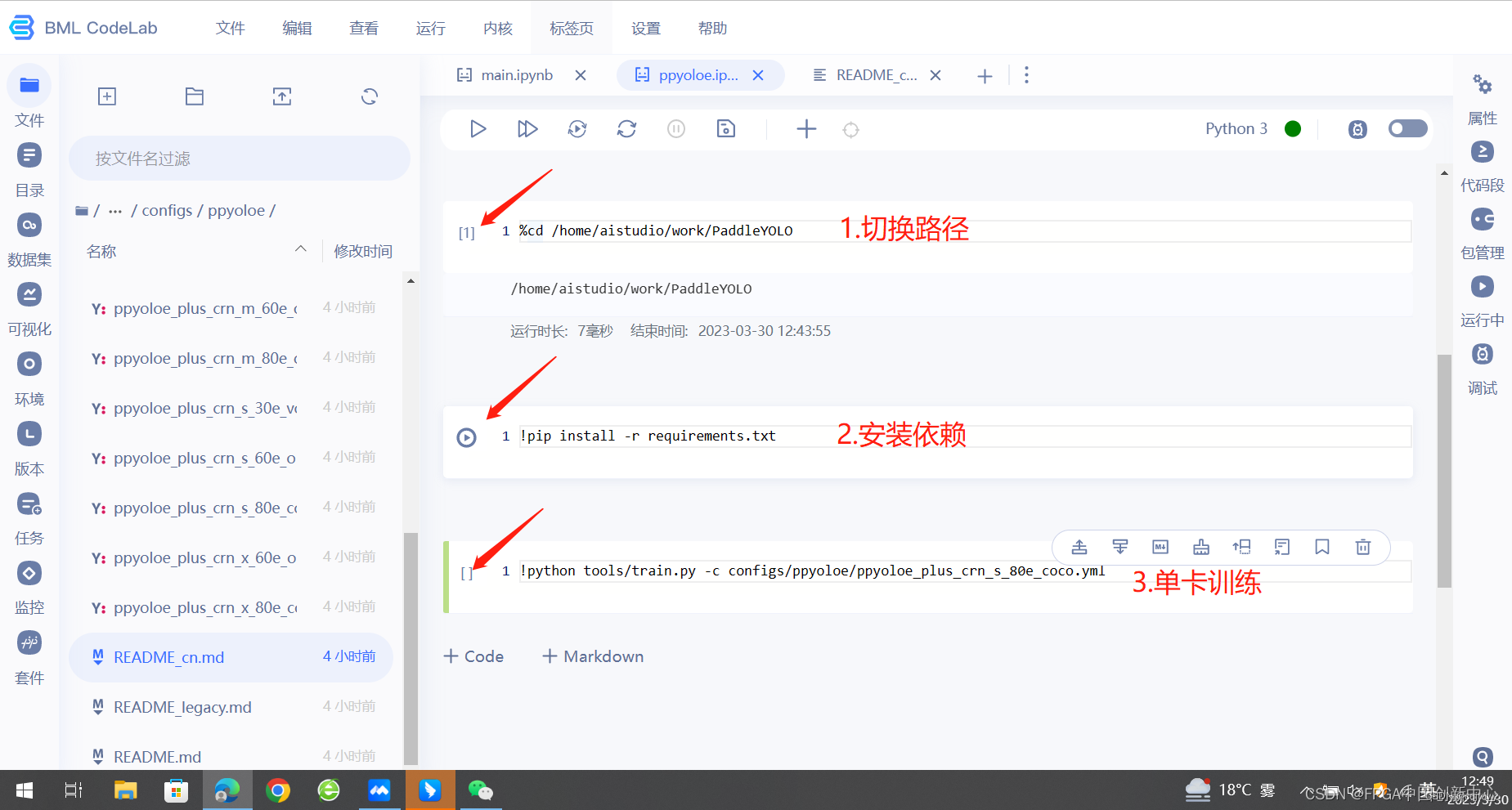
命令是多卡训练,我们需要稍作修改,换成单卡训练,因为你启动工程的时候就选了一个卡。
!python tools/train.py -c configs/ppyoloe/ppyoloe_plus_crn_s_80e_coco.yml
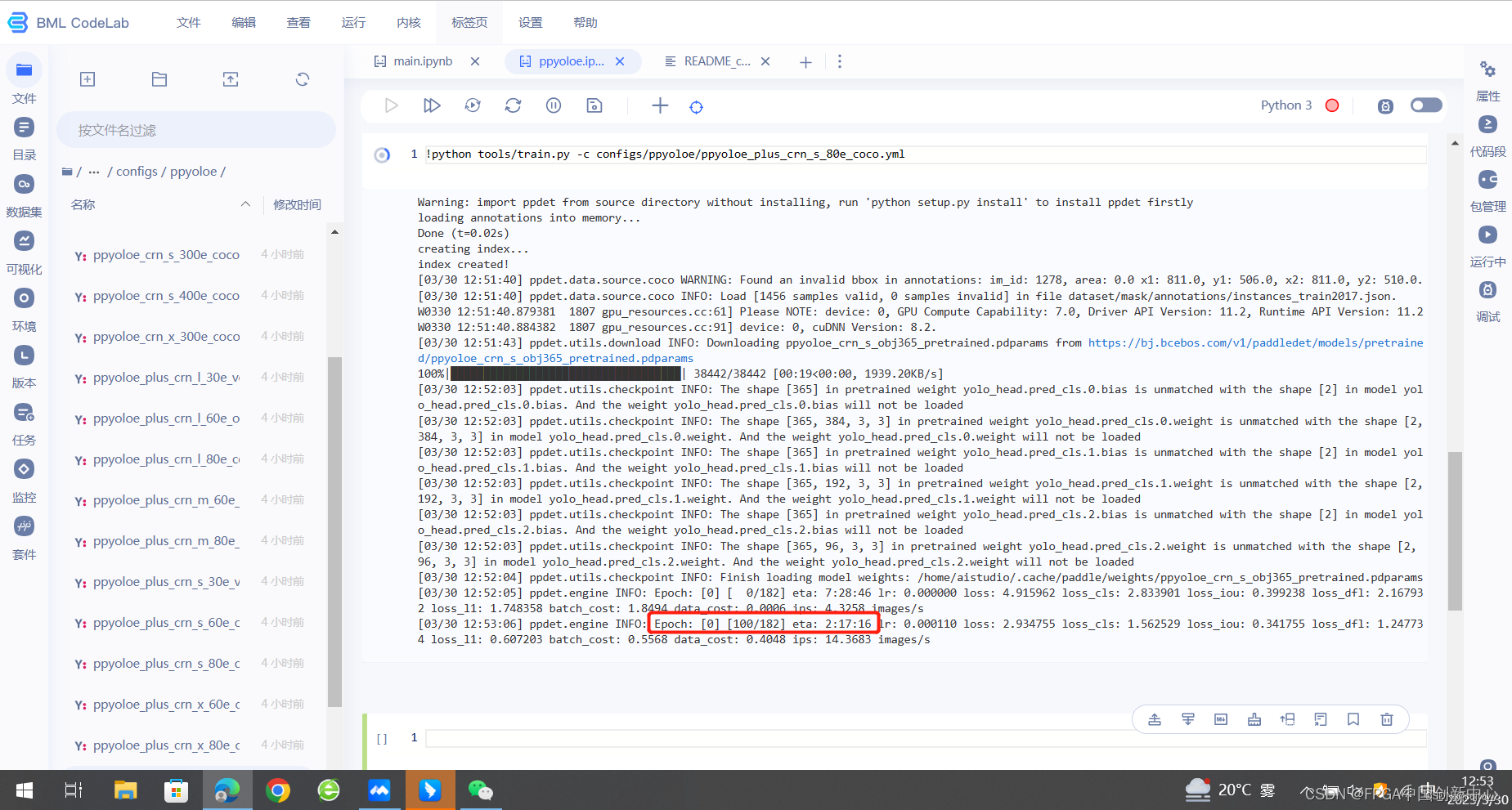
模型训练标志,此时是0 epoch,eta时间时间由模型复杂度和数据集的体量决定。时间会变,我做的笑容识别和性别识别,在训练四十次的情况下不到半小时就训练完成了,所以可以开个黑回来刚好合适。
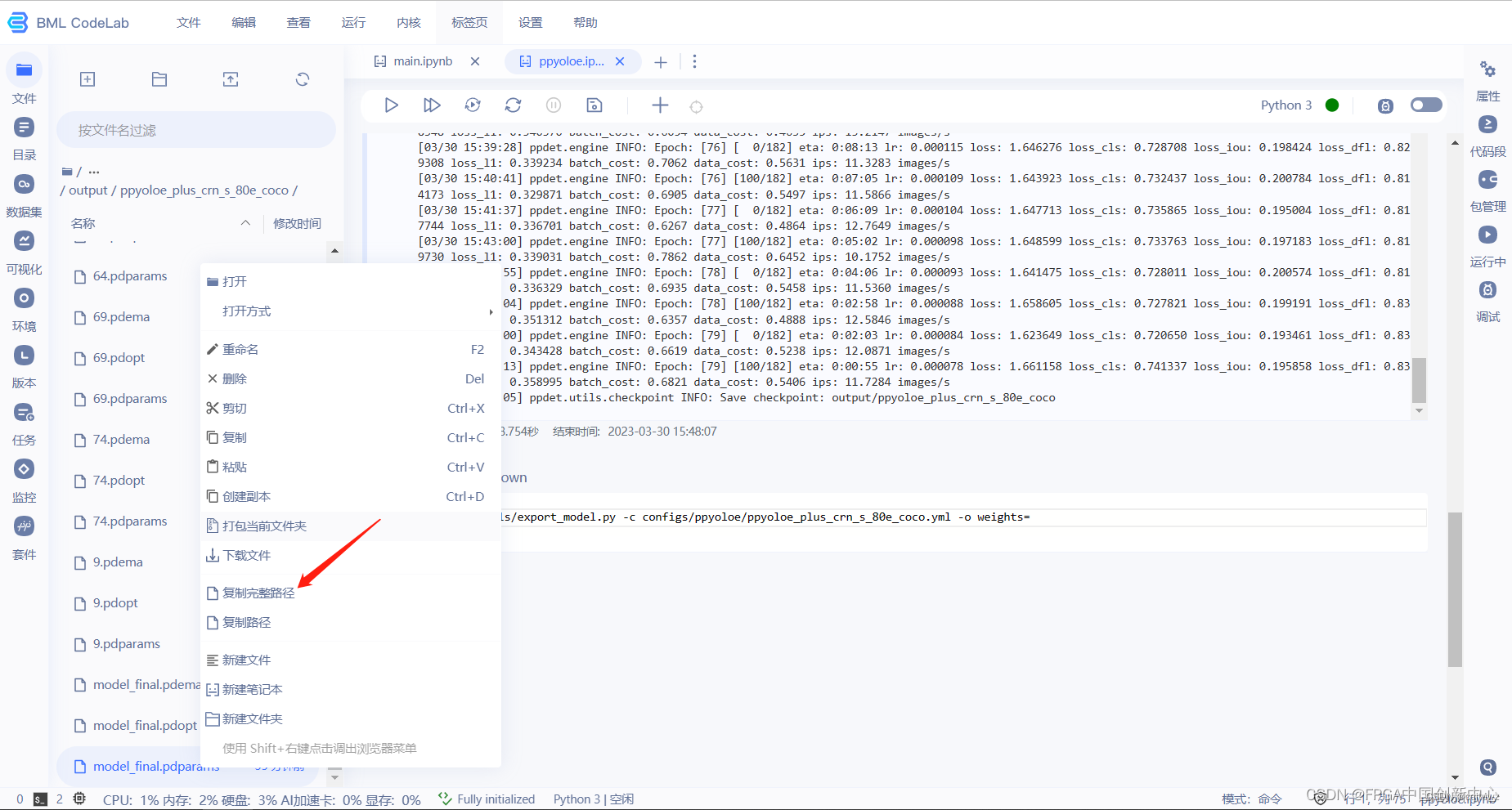
找到自己的模型放置位置,在生成的output文件夹下。如下图操作可以获取模型model_final.pdparams的绝对路径,然后粘贴至weights=后面,导出模型。
!python tools/export_model.py -c configs/ppyoloe/ppyoloe_plus_crn_s_80e_coco.yml -o weights=模型参数绝对路径
导出模型会放置output_inference文件夹下。
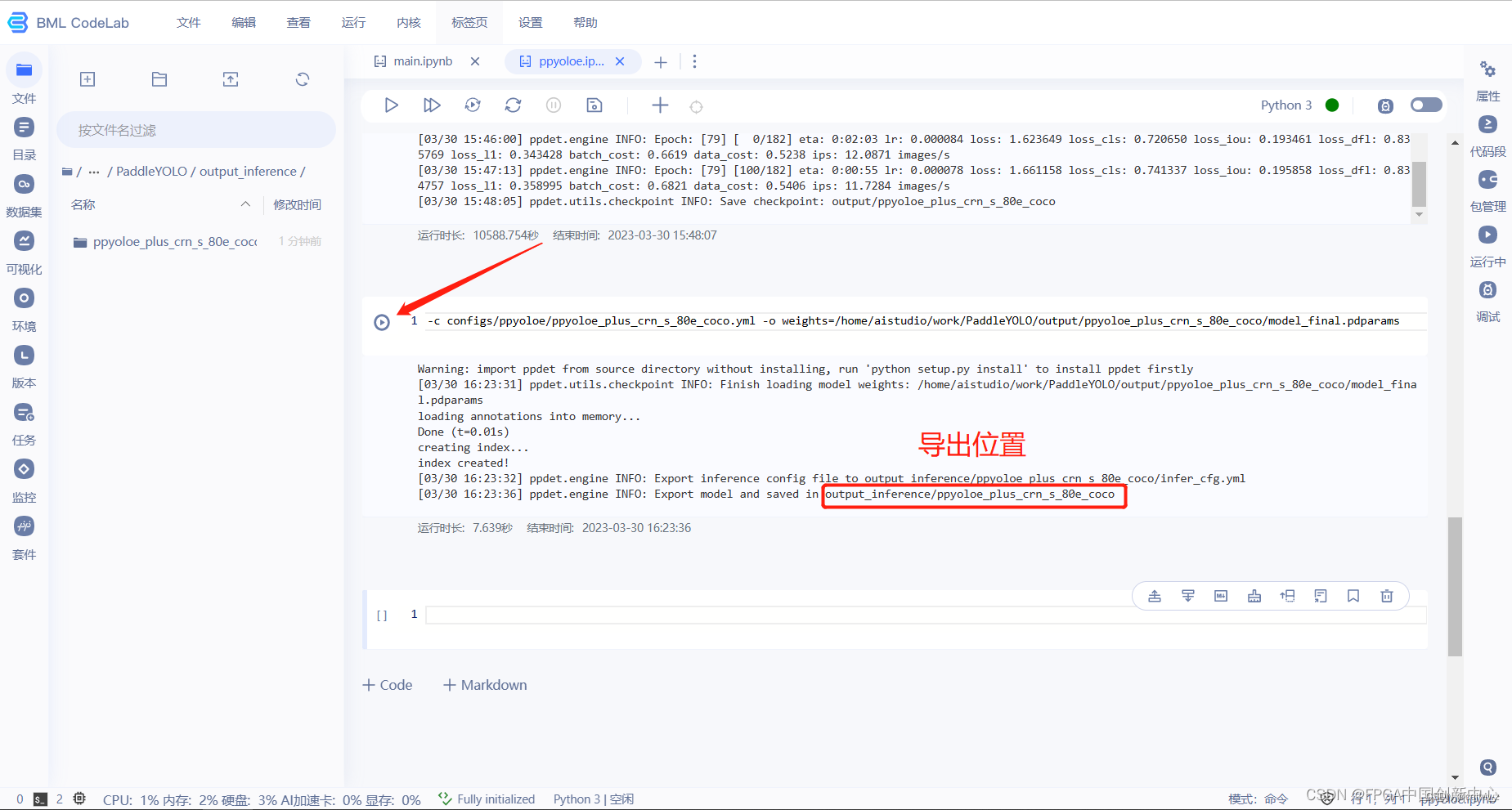
下载导出的模型,用于下模型转换当中。
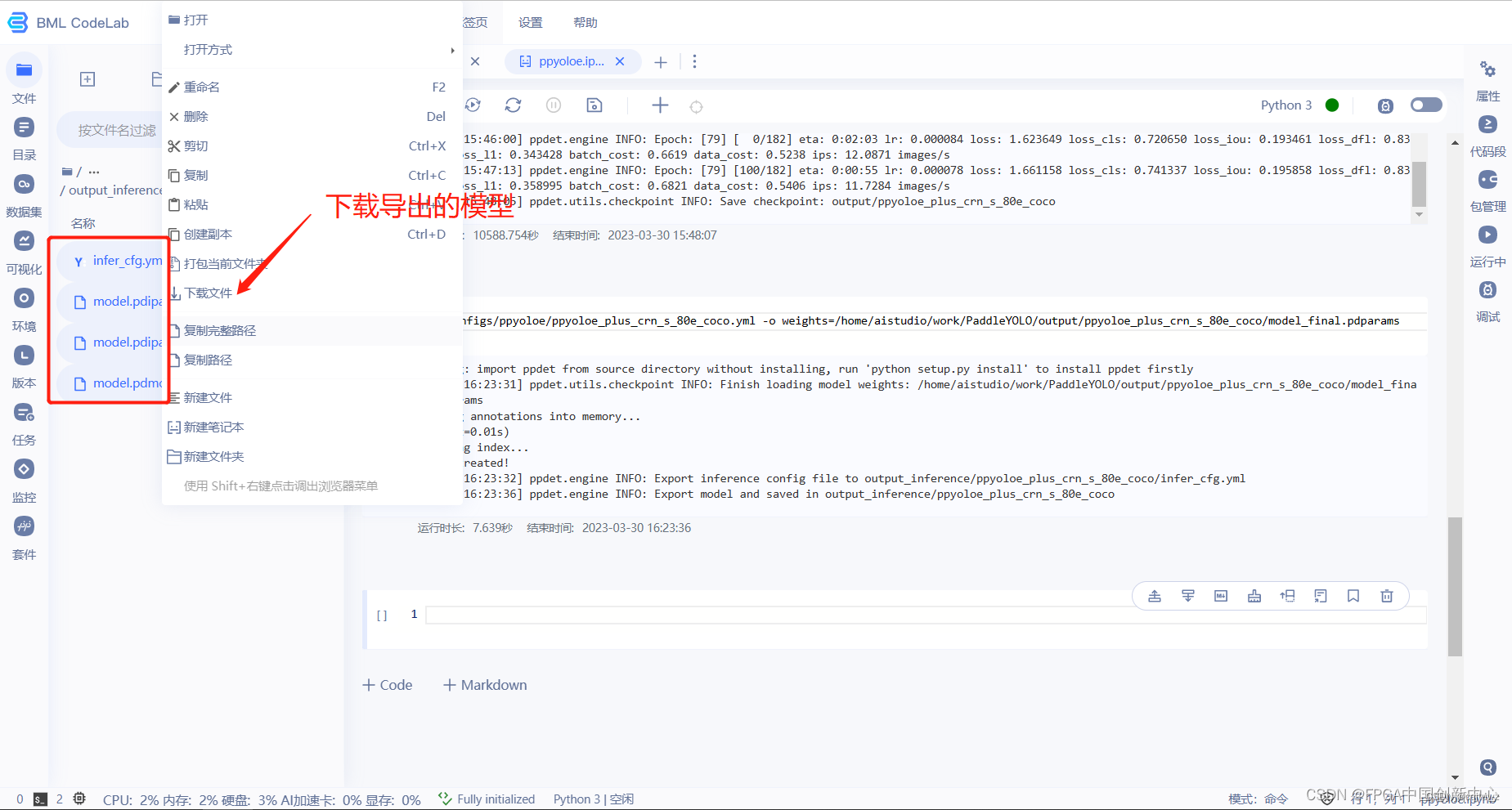
模型转化及优化
模型减支
模型减支的目的就是从输入到两个输出concat_14.tmp_0,tmp_16为止,后面的节点都删掉。
运行以下命令:
python prune_paddle_model.py --model_dir ppyoloe_crn_s_80 --model_filename model.pdmodel --params_filename model.pdiparams --output_names tmp_16 concat_14.tmp_0 --save_dir export_model
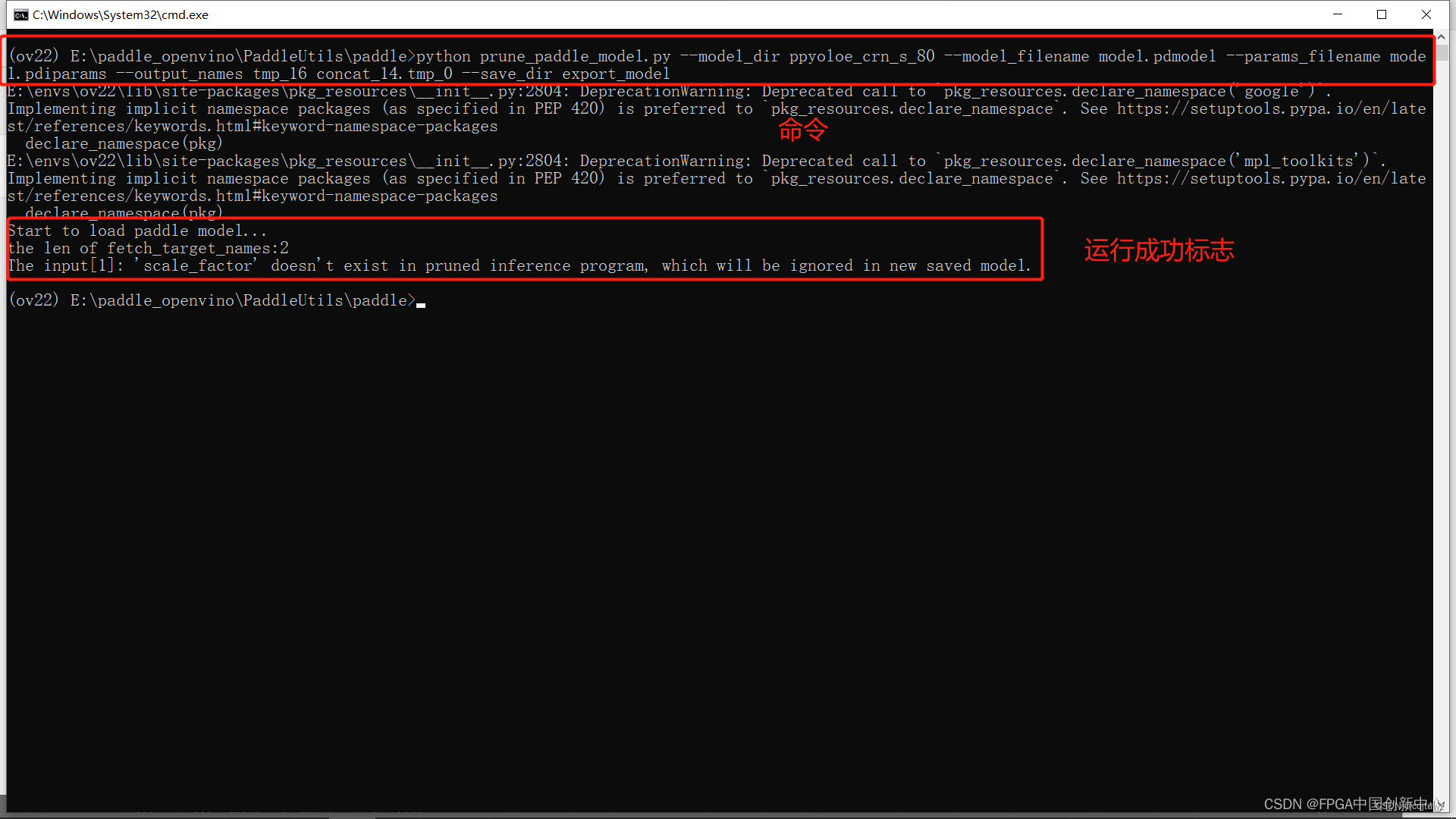
运行过后新增一个减支完成的模型文件夹。
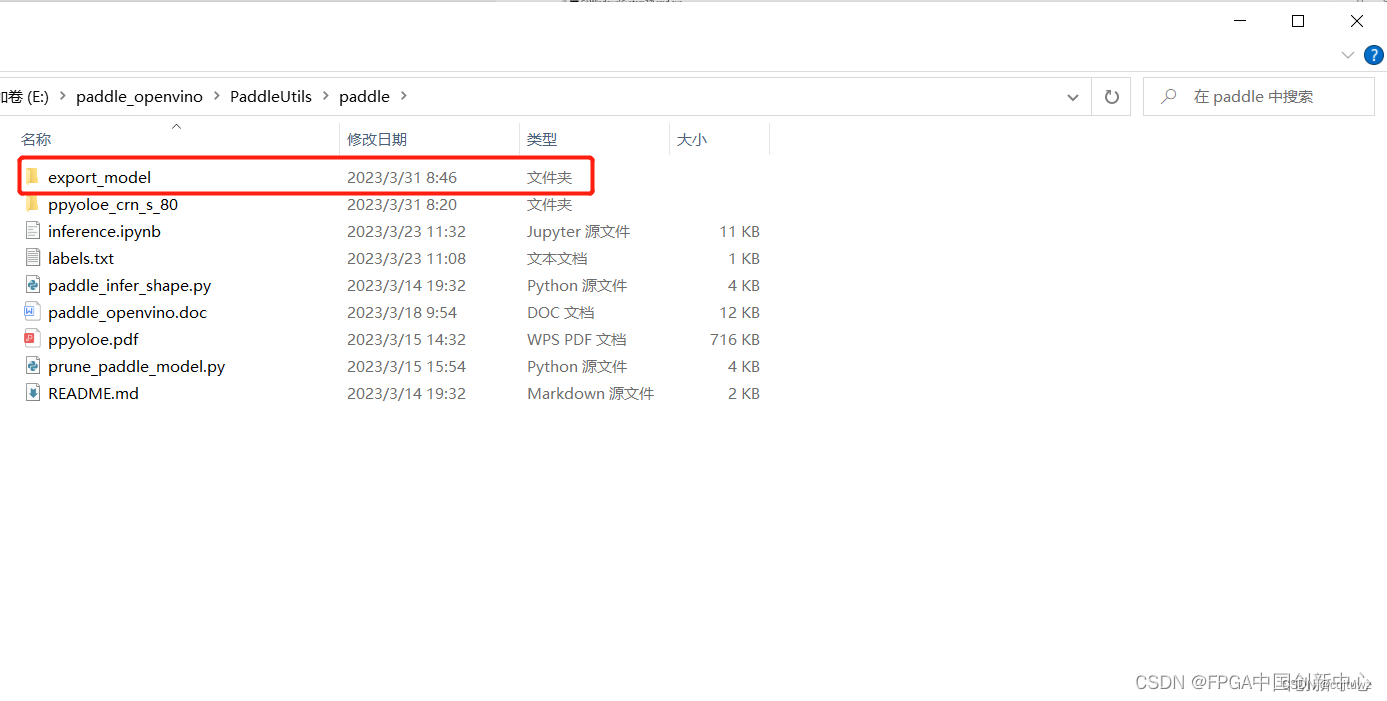
模型转化
先把paddle模型转换为onnx,需要在环境里面提前安装paddle2onnx。执行以下命令。
paddle2onnx --model_dir export_model --model_filename model.pdmodel --params_filename model.pdiparams --input_shape_dict "{'image':[1,3,640,640]}" --opset_version 11 --save_file ppyoloe_crn_s_80.onnx
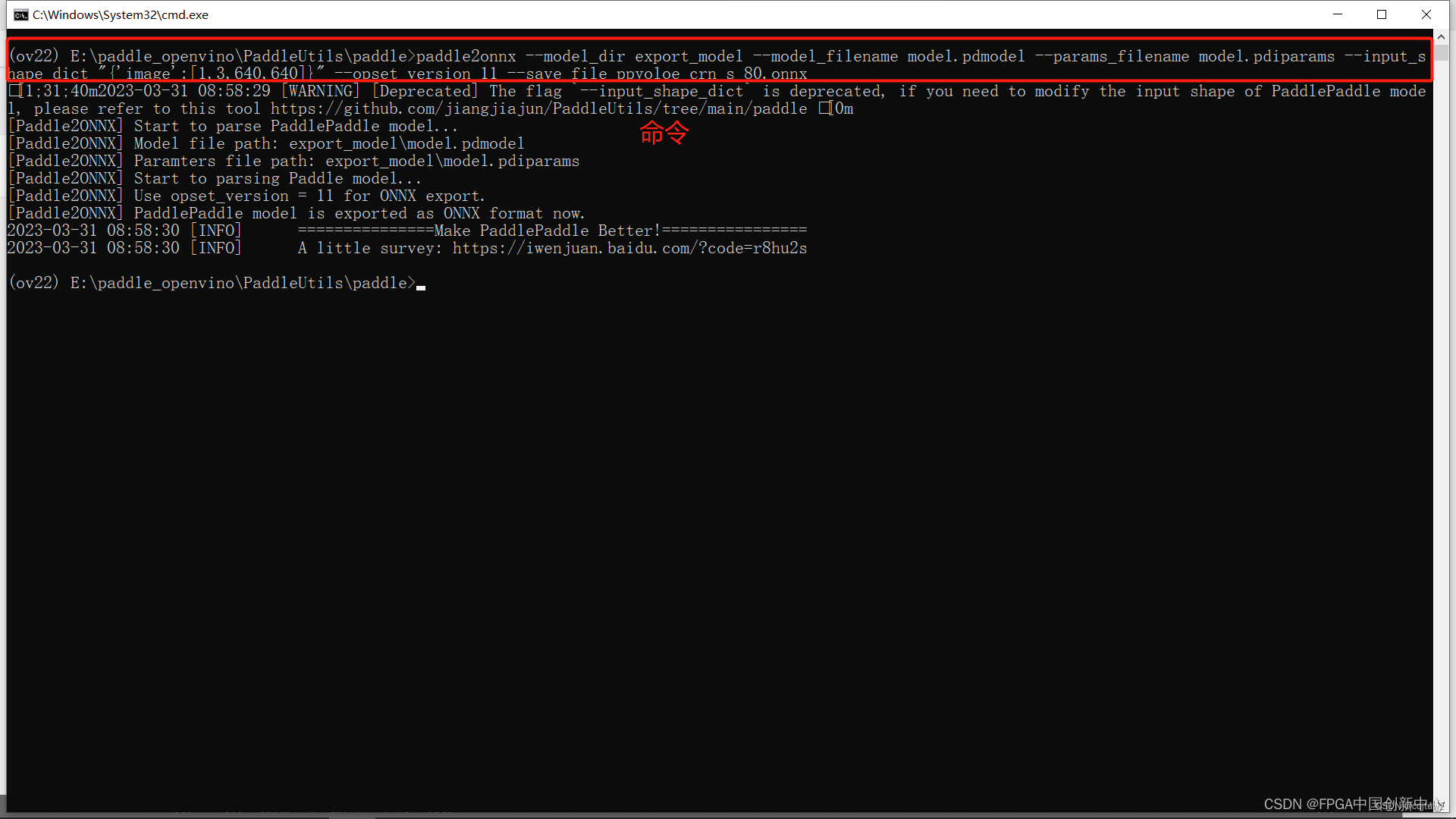
执行生成的ppyoloe_crn_s_80.onnx。
onnx转xml,bin(OpenVINO)。
mo --input_model ppyoloe_crn_s_80.onnx
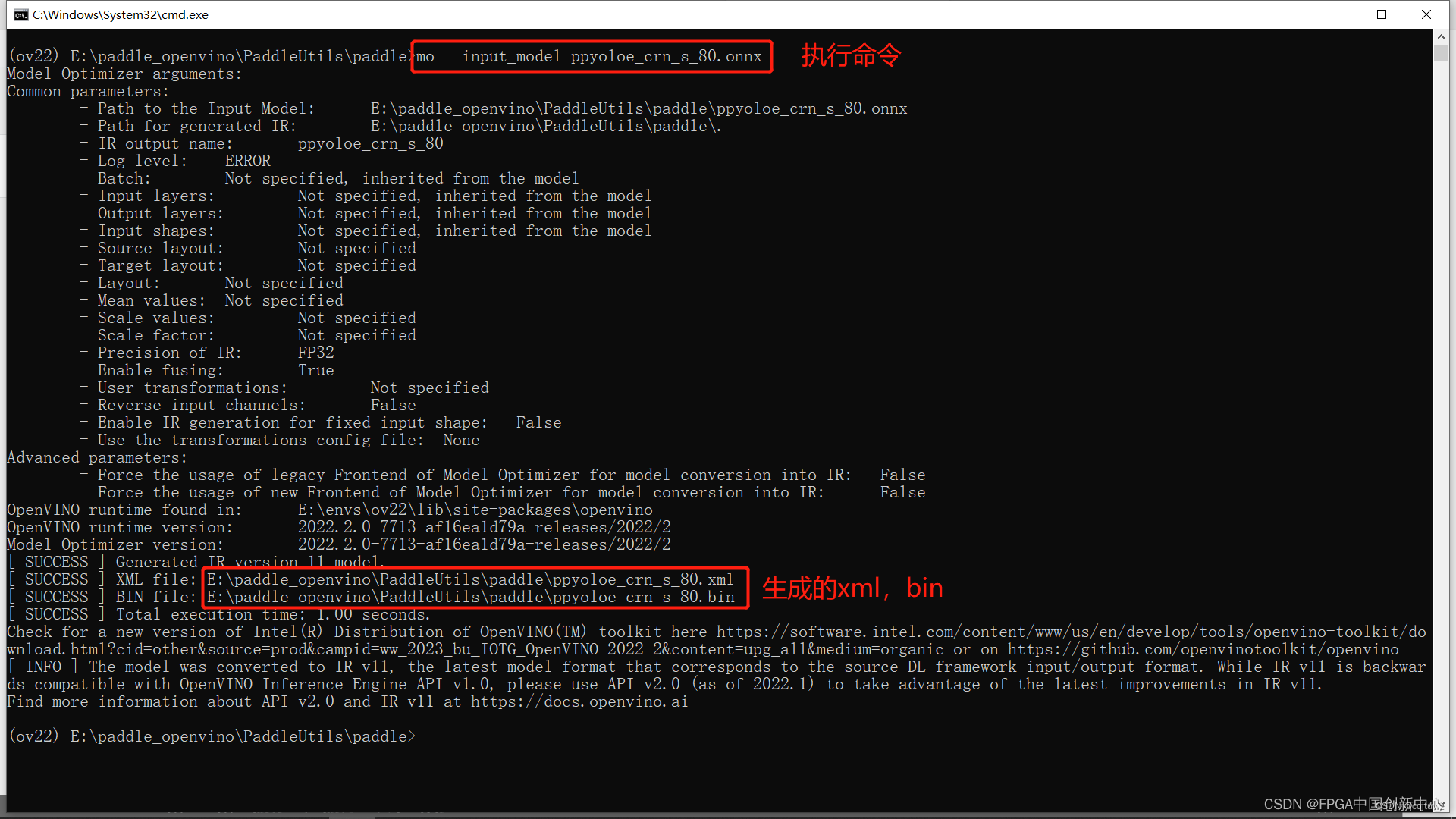
执行结果。
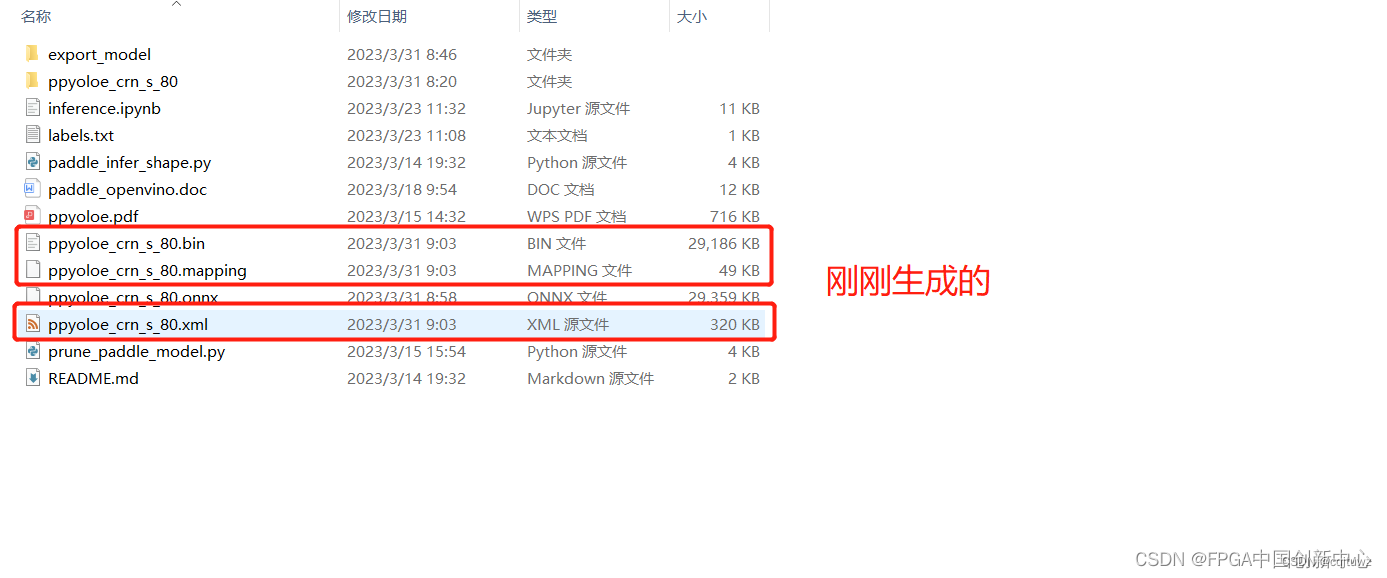
验证测试
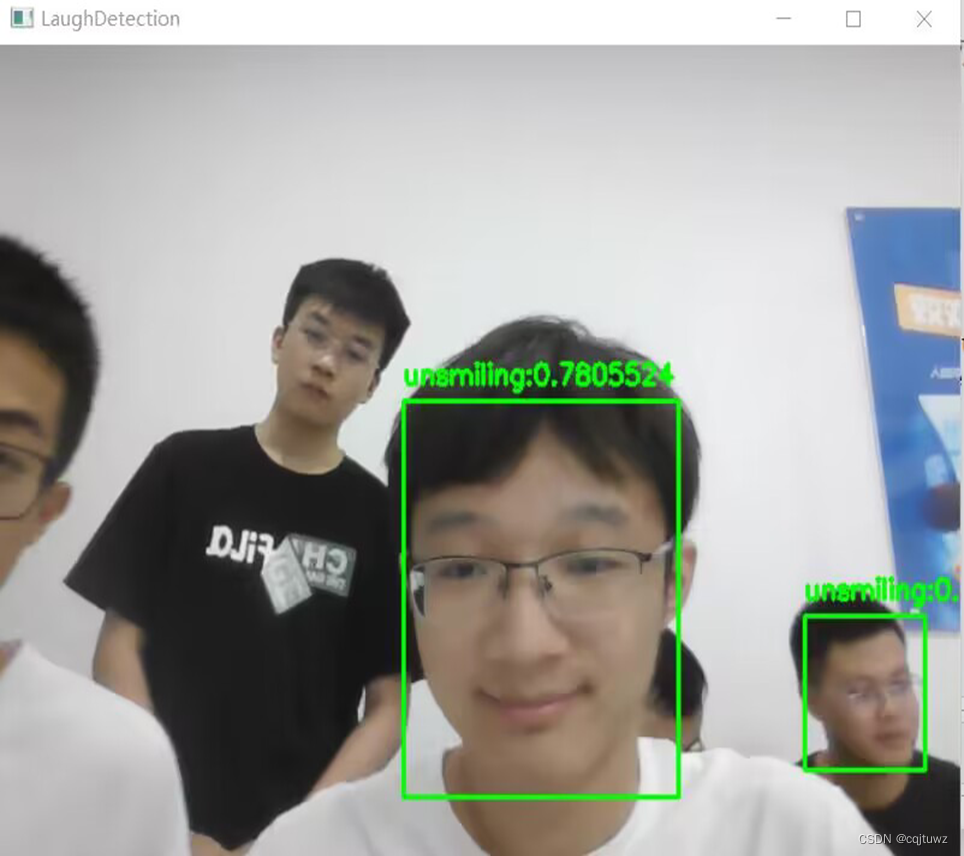
笑容检测:

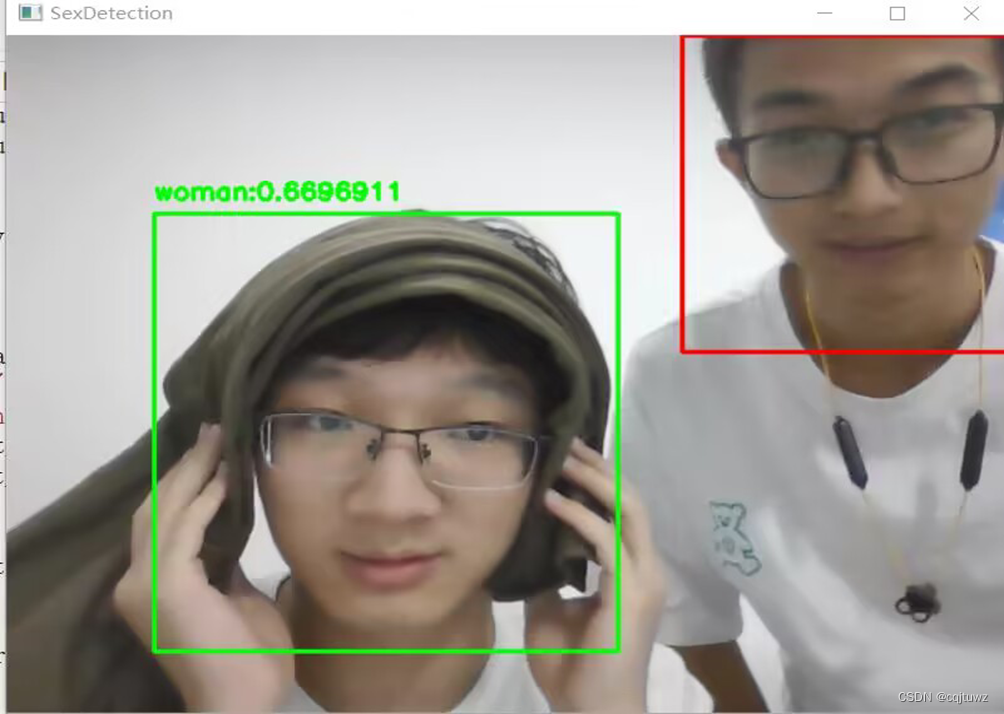
性别检测:

总结分析
缺陷:对于微笑识别不敏感,只有比较明显的露齿笑能够精确判断
原因:数据集选取过于极端,原因在于爬取图片数据时候,关键词限制了获取到的数据集内容,大多都是比较夸张笑容的图片数据,这使得数据集不平衡。
缺陷:过于将头发特征做为判断性别的条件。
原因:选择的数据集中长发是女性区别于男性的主要特征。
参考文献
口罩检测——环境准备(1)
口罩检测——数据准备(2)
口罩检测——模型训练(3)
口罩检测——模型转换(4)
添加链接描述