摘要
- 本文提出一个新的无监督的AES方法ULRA,它不需要真实的作文分数标签进行训练;
- ULRA的核心思想是使用多个启发式的质量信号作为伪标准答案,然后通过学习这些质量信号的聚合来训练神经自动评分模型。
- 为了将这些不一致的质量信号聚合为一个统一的监督信号,我们将自动评分任务视为一个排序问题,并设计了一种特殊的深度成对排名聚合(DPRA)损失函数进行训练。
- 在DPRA损失中,我们为每个信号设置了一个可学习的置信权重来解决信号间的冲突,并且以成对的方式训练神经AES模型以解开部分排序对之间的级联效应。
方法
- 我们的ULRA框架包括两个阶段:模型训练和模型推理。
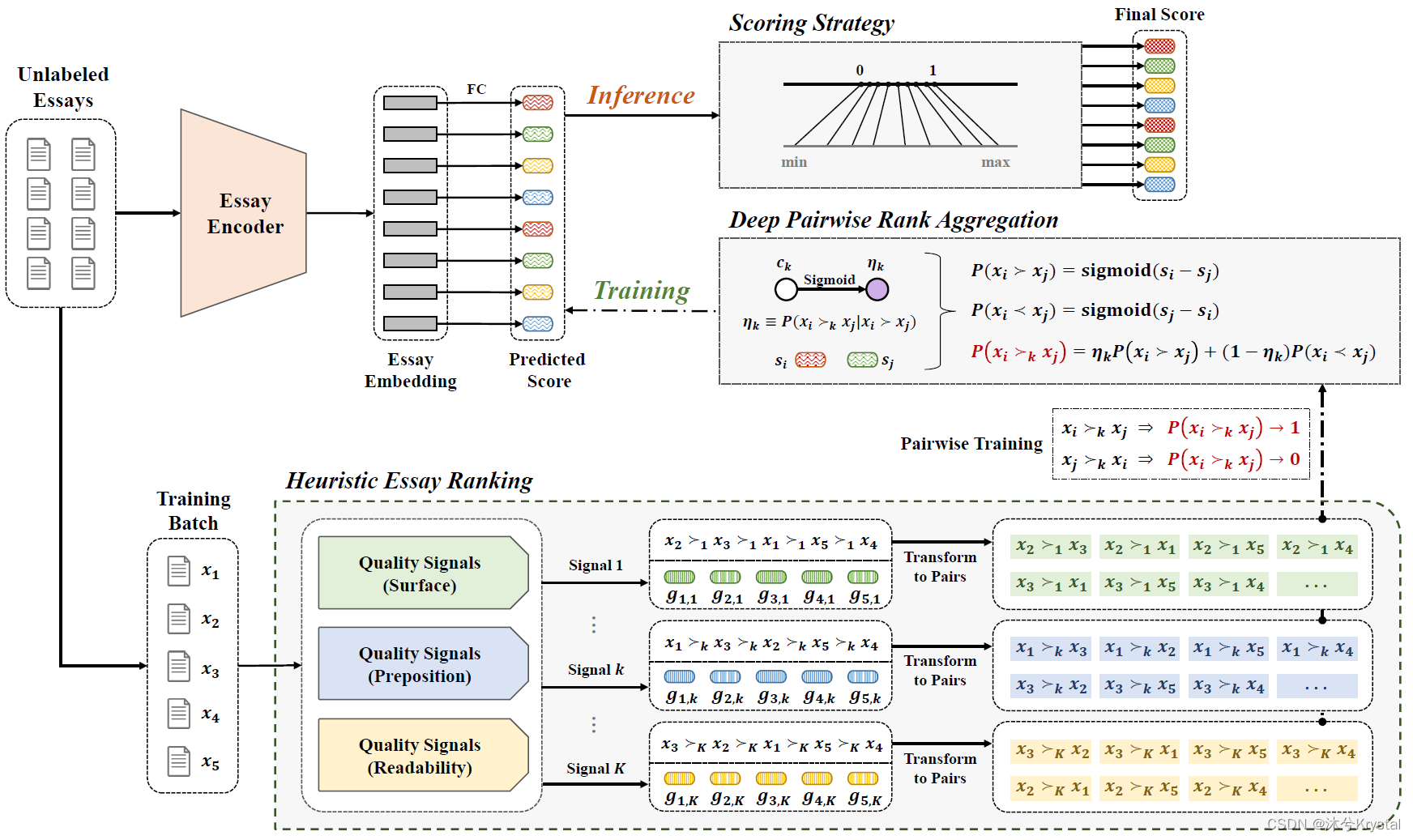
- 在模型训练阶段,ULRA框架包含两个模块: 1)启发式作文排序模块:根据启发式质量信号产生排序对;2)深度成对排序聚合模块:聚合来自多个质量型号的排序对,到一个统一的监督中。
- 在模型推理阶段,考虑到神经AES模型预测的作文分数可能和预定义的分数集合有不同的分数,我们提出了一个评分策略来转换被神经AES模型预测的分数到预训练的分数集合的范围。
启发式作文排序
- 多个经典的质量信号被引入从不同的方面描述作文的质量;每个质量信号的值可以之后被用来排序文章和产生一个排序列表。
- 质量信号:surface、preposition、readability
- 作文排序:与基于质量信号来对一篇作文评分外,比较他们的质量信号来评价两篇文章的相对质量更容易。所以,对于每个质量信号,我们只通过排序保留作文间的部分有序的关系信息。
- 排序对生成:考虑到在每个排序列表中,只有部分的有序信息是正确的,本文把每个排序列表转换成一个集合的部分有序的排序对,从而使得不正确的部分有序对能够被其他排序列表纠正。
深度成对排序聚合
- 本文设计了一个深度成对的排序聚合损失,它为每个信号设置了一个可学习的置信权重来度量每个信号的重要度。
- 神经AES模型:包括作文编码器和全连接层。
- 置信权重(confidence weight):度量哪个排序对更加可靠。可学习的参数 η k \eta _k ηk可以被定义为在第 k k k个排序列表中的部分有序的信息和真实的分数排序的吻合的概率或程度。
实验
数据集
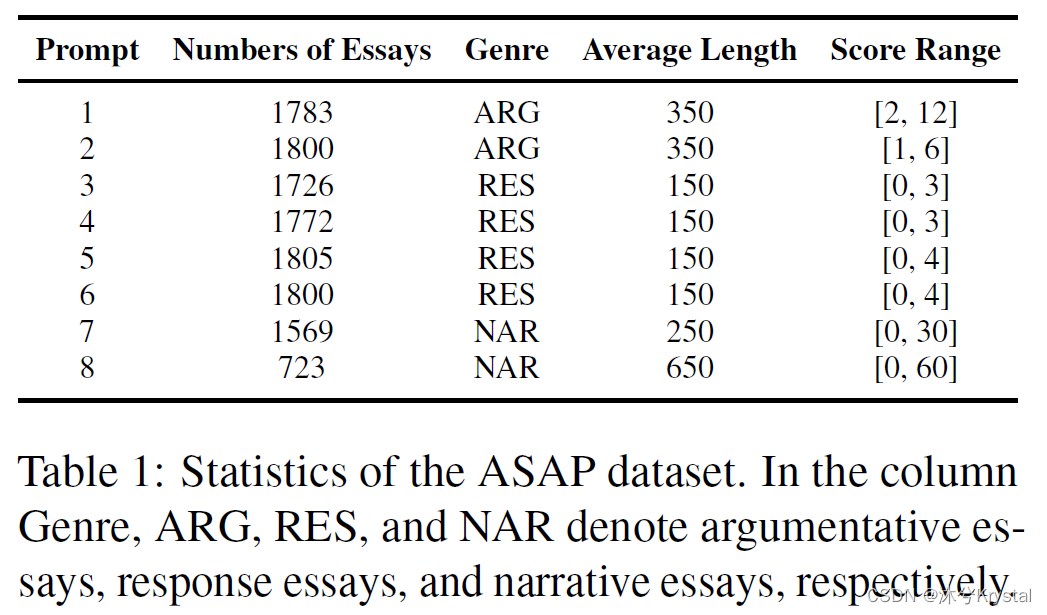
- ASAP数据集,总共12978篇作文,8个主题。
实现细节
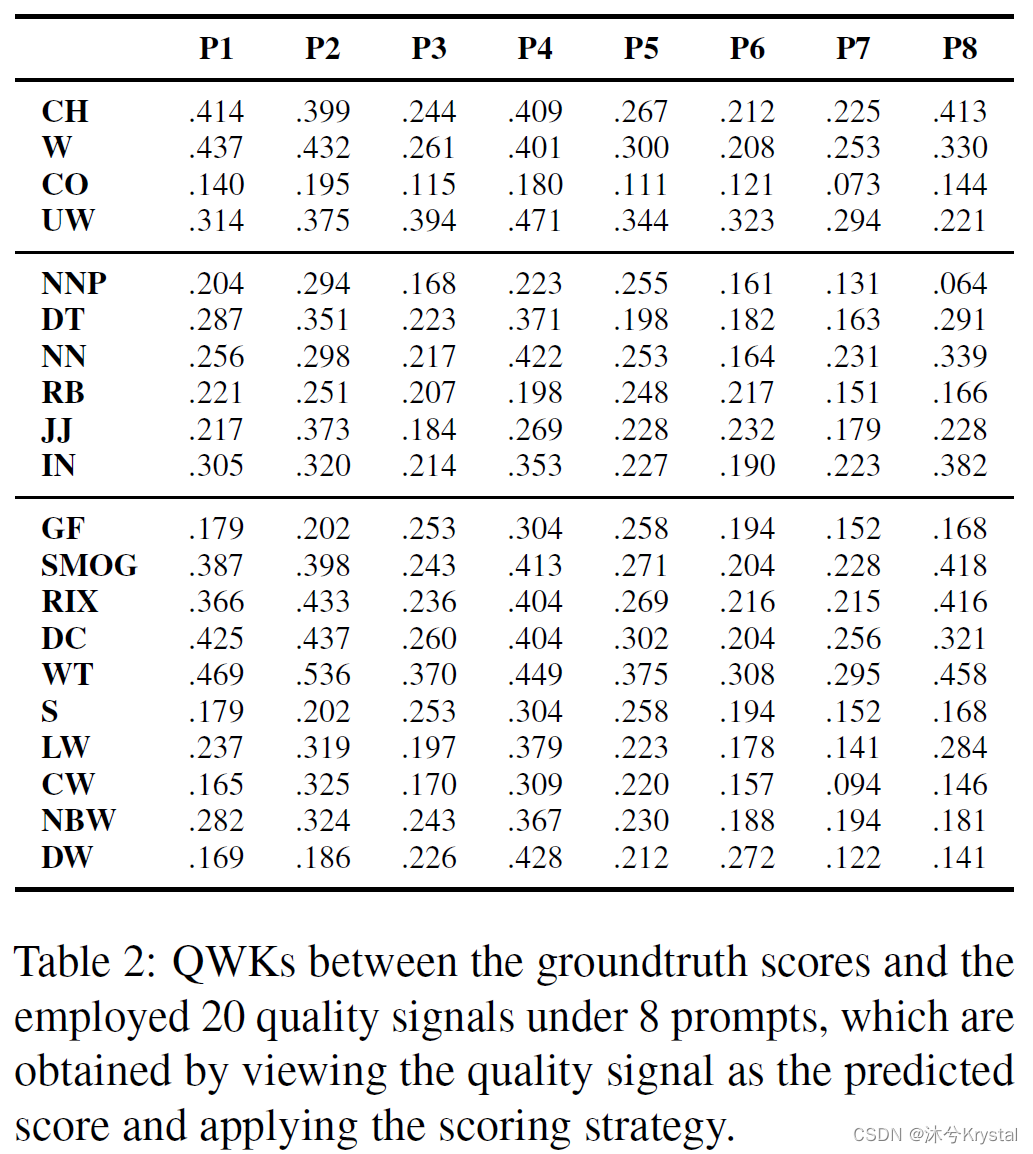
- 质量信号设置:总共用了20个质量信号。分为以下三类:
- 浅层信号(Surface Signals): character number (CH), word number (W), commas number (CO), and number of unique words (UW);
- 介词信号(Preposition Signals):number of noun-plural words (NNP), number of determiner words (DT), number of noun-singular words (NN), number of adverb words (RB), number of adjective words(JJ), and number of preposition/subordinatingconjunction words (IN);
- 可读性信号(Readability Signals):Gunning Fog (GF) index, SMOG index, RIX, Dale-Chall (DC) index, wordtype number (WT), sentence number (S), number of longwords (LW), number of complex words (CW), number of non-basic words (NBW), and number of difficult words (DW).
- 数据集设置:
- 对于直推式设置(transductive):模型在整个无标签数据集上训练,并在整个数据集上进行测试,也就是说测试作文在训练时都被看到。
- 对于归纳式设置(inductive):整个无标签的数据集被分为训练集、验证集和测试集(6:2:2),也就是说测试作文在训练时并没有被看到。由于是无监督的设置,验证集并没有作用,所以被舍弃。
比较的方法
- 主要和之前的无监督AES方法进行比较:Signal Clustering (Chen et al., 2010) and Signal Regression (Zhang and Litman, 2021).
- 4个变种(variants):(1) averaged signal as supervision, (2) averaged output as prediction, (3) aggregated signal as supervision, and (4) aggregated output as prediction.
- 也列举了两个额外的基线:分别取20个质量信号的最小和最大值作为预测分数。
性能比较
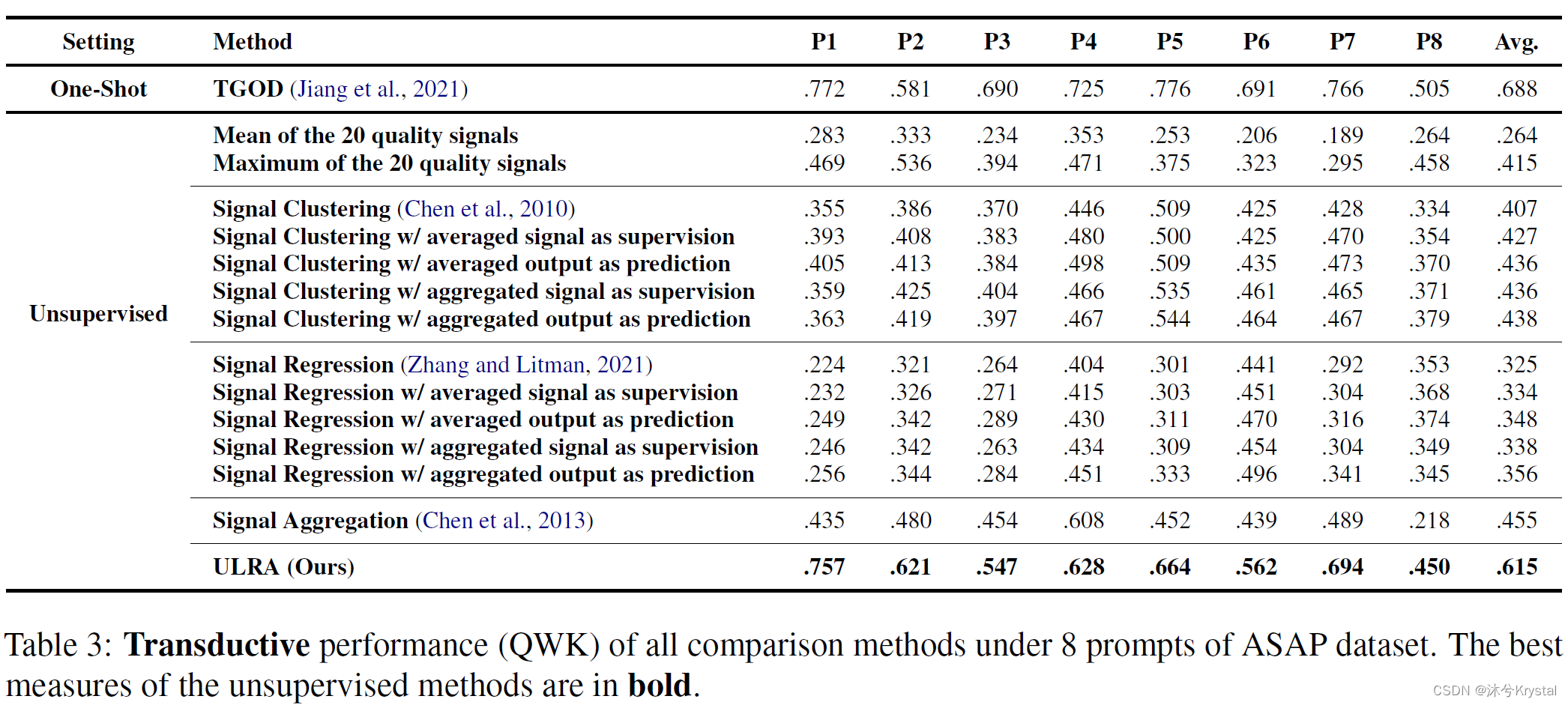
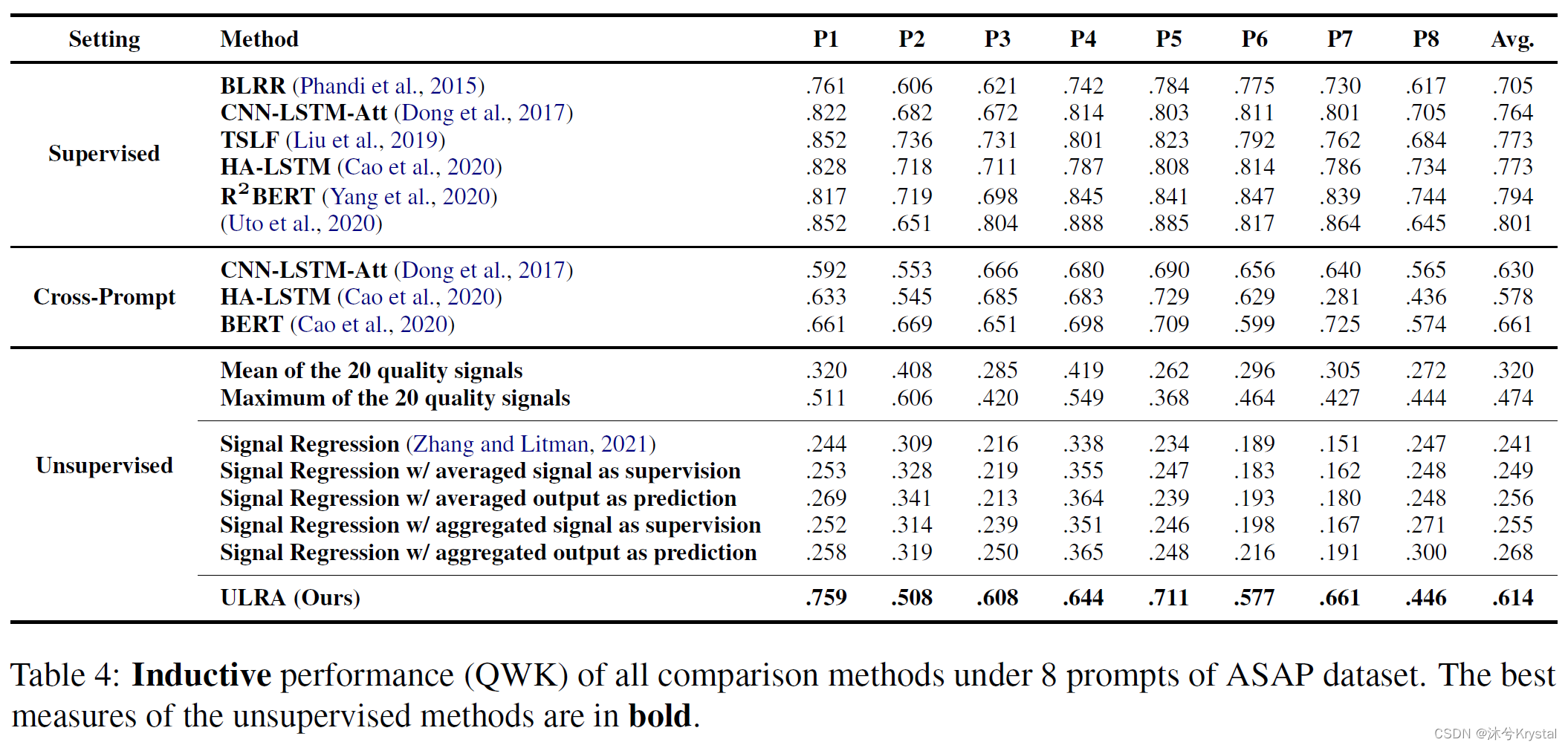
- 我们可以发现ULRA超过了所有的无监督方法,并且提升很大,在直推式的设置下取得了0.615的QWK,在归纳式的设置下取得了0.614的QWK。这显示出ULRA能够在可见和不可见的作文集上都表现良好。
- 和跨主题以及单样本的方法比较,我们可以发现ULRA实现了可与之比肩的性能,只比跨主题低了0.047,比单样本低了0.073。通过观察通用的有监督方法,我们可以发现,由于缺乏强有力的监督,ULRA的性能仍然比它们低很多。
消融实验
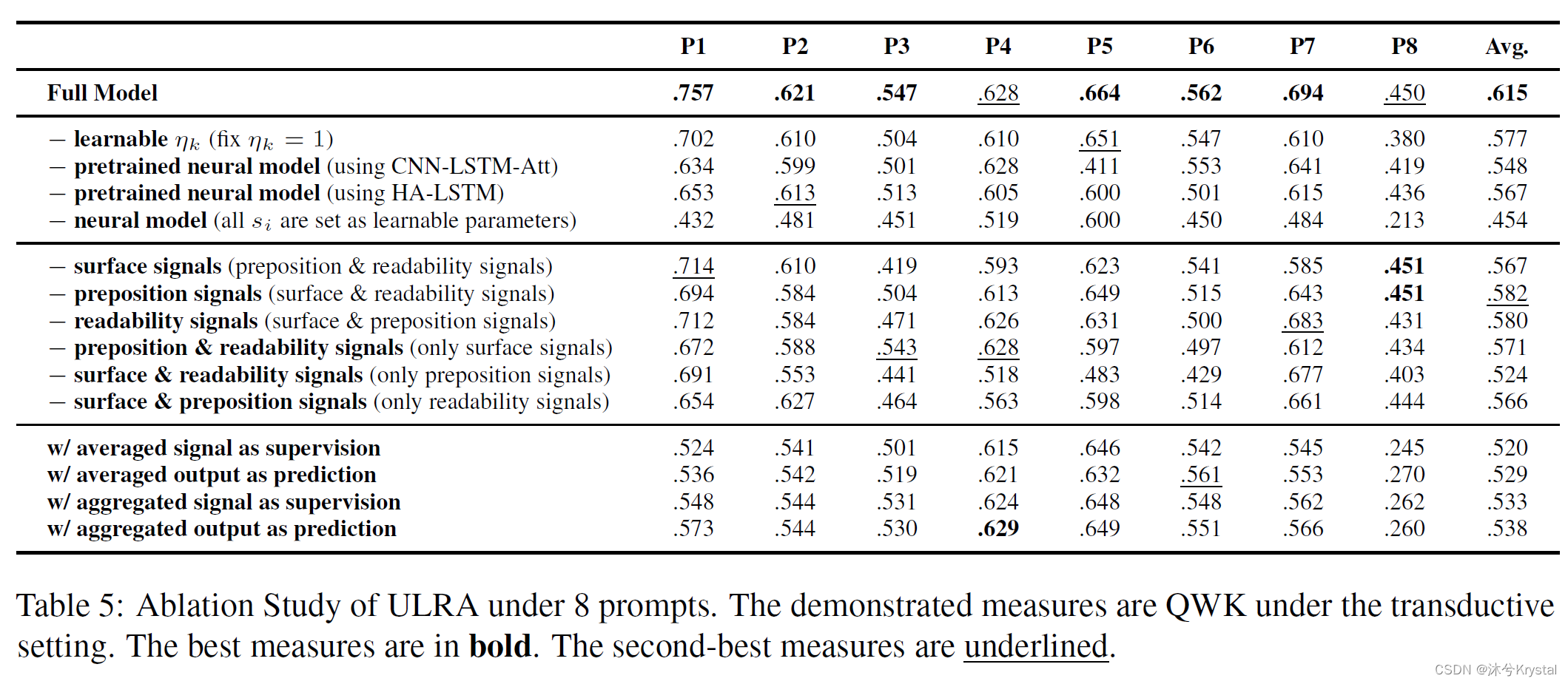
- 我们首先学习了置信权重
η
k
\eta_k
ηk 和神经网络对性能的影响。
- 把可学习的参数 η k \eta_k ηk 固定为1,性能下降很多。显示出可学习的参数 η k \eta_k ηk 可以处理不一致的信号之间的冲突。
- 当使用非预训练的编码器,或者直接设置作文的分数为可学习的参数时,性能也下降很多。显示了一个好的作文编码器能够充分利用作文的文本信息来提升评分性能。
模型分析
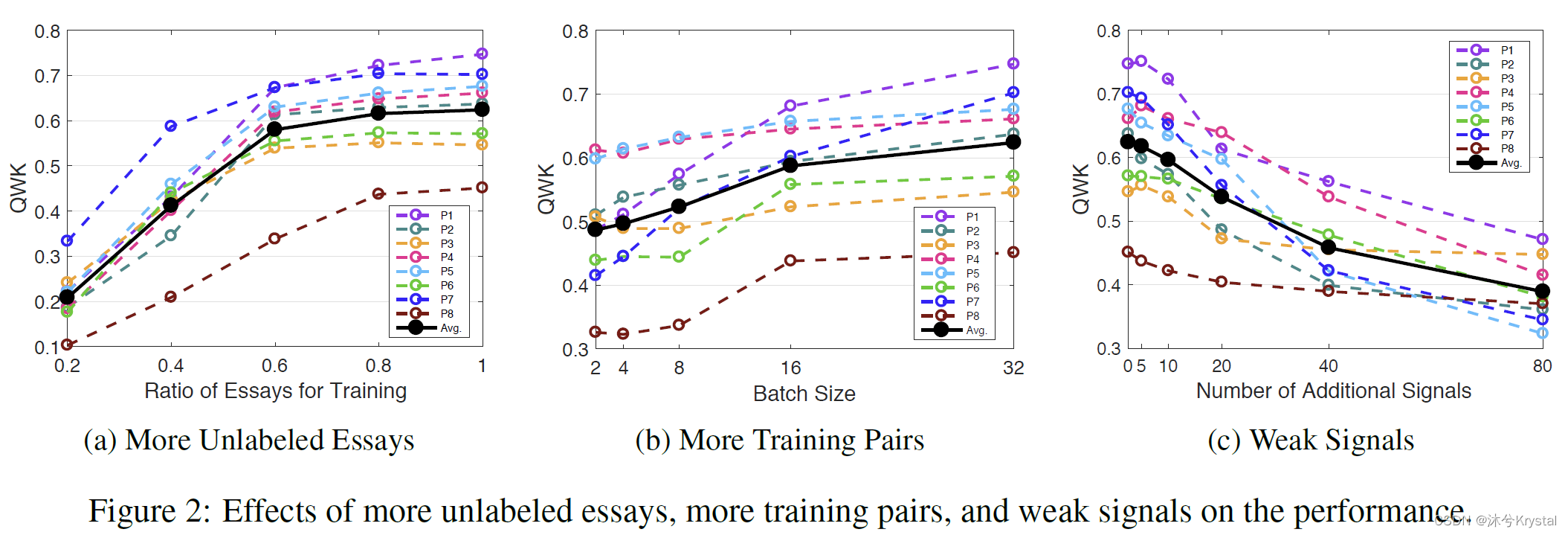
- 更多无标签作文的影响:调整训练的作文的比例从0.2到1.0,曲线先增加,之后在比例为0.6后保持平稳。它显示了大约60%的无标签作文就足够训练一个好的ULRA模型。
- 更多训练对的影响:调整batch size的大小从2到32,以使得一个batch中的训练对的数量能相应得从1增加到496。可以发现所有的线都展示出向上的趋势。它展示出更多数量的训练对能够带来更好的性能。
- 弱信号的影响:弱信号是那些和真实分数具有较弱相关性的信号。从图中可以看到几乎所有的线都呈现出整体的下降趋势。它表明弱监督会弱化监督以及减损模型性能。
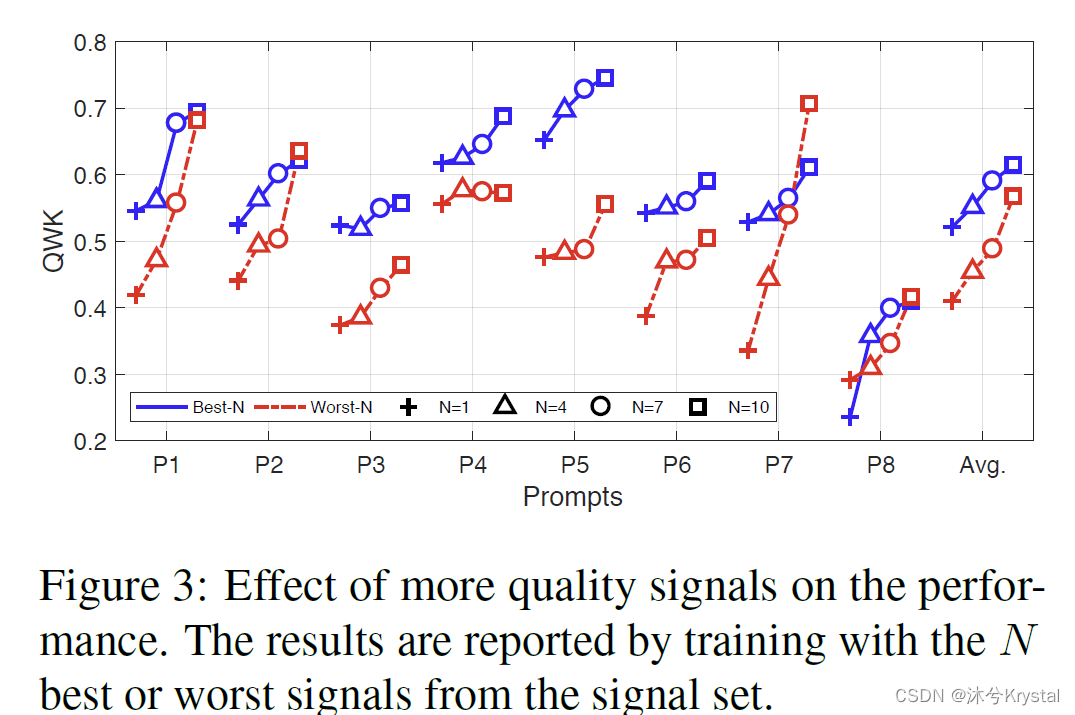
- 更多信号的影响:基于最好的N个质量信号和最差的N个质量信号。通过调整N从1到10,可以发现所有的best-N和所有的worst-N展示了向上的趋势。它显示出更多的信号能够带来更好的性能。
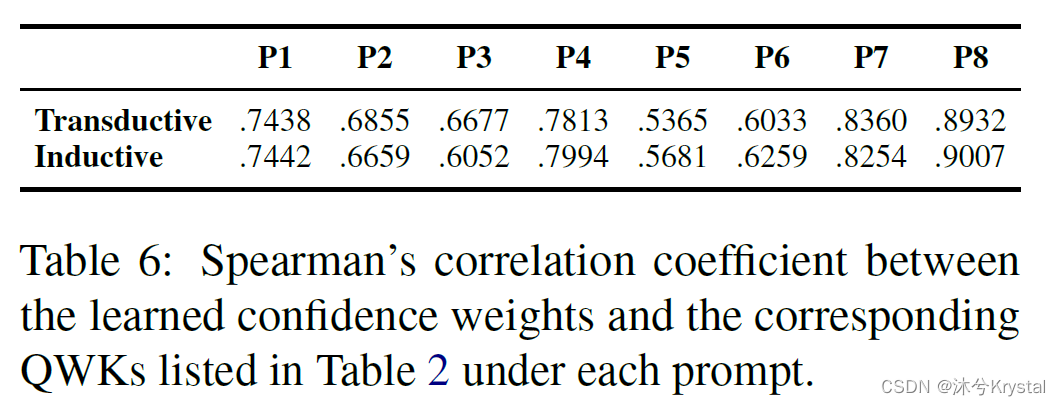
- 置信权重的影响:计算学习到的置信权重和对应的QWK的斯皮尔曼相关系数。可以发现两者是高度相关的。显示出学习到的置信权重确实能够反映质量信号的confidence。