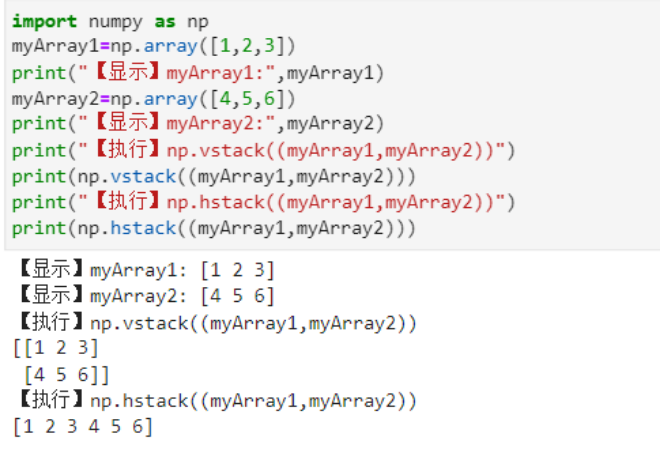
管道模式是责任链模式的常用变种之一,但是管道模式和责任链模式有一个关键的区别,在看一些博客的时候并没有体现出来出来,很多人都把责任链模式当做管道模式来说。
定义
管道模式使用有序的Stage(或者Handler)来顺序的处理一个输入值,每个处理过程被看做一个阶段。 但是每一个阶段都以来上一个阶段的输出。
如果不依赖上一个阶段的输出结果,那么使用责任链模式即可。责任链模式的每个处理器互相独立,不依赖别的处理器结构。
做个比喻:
-
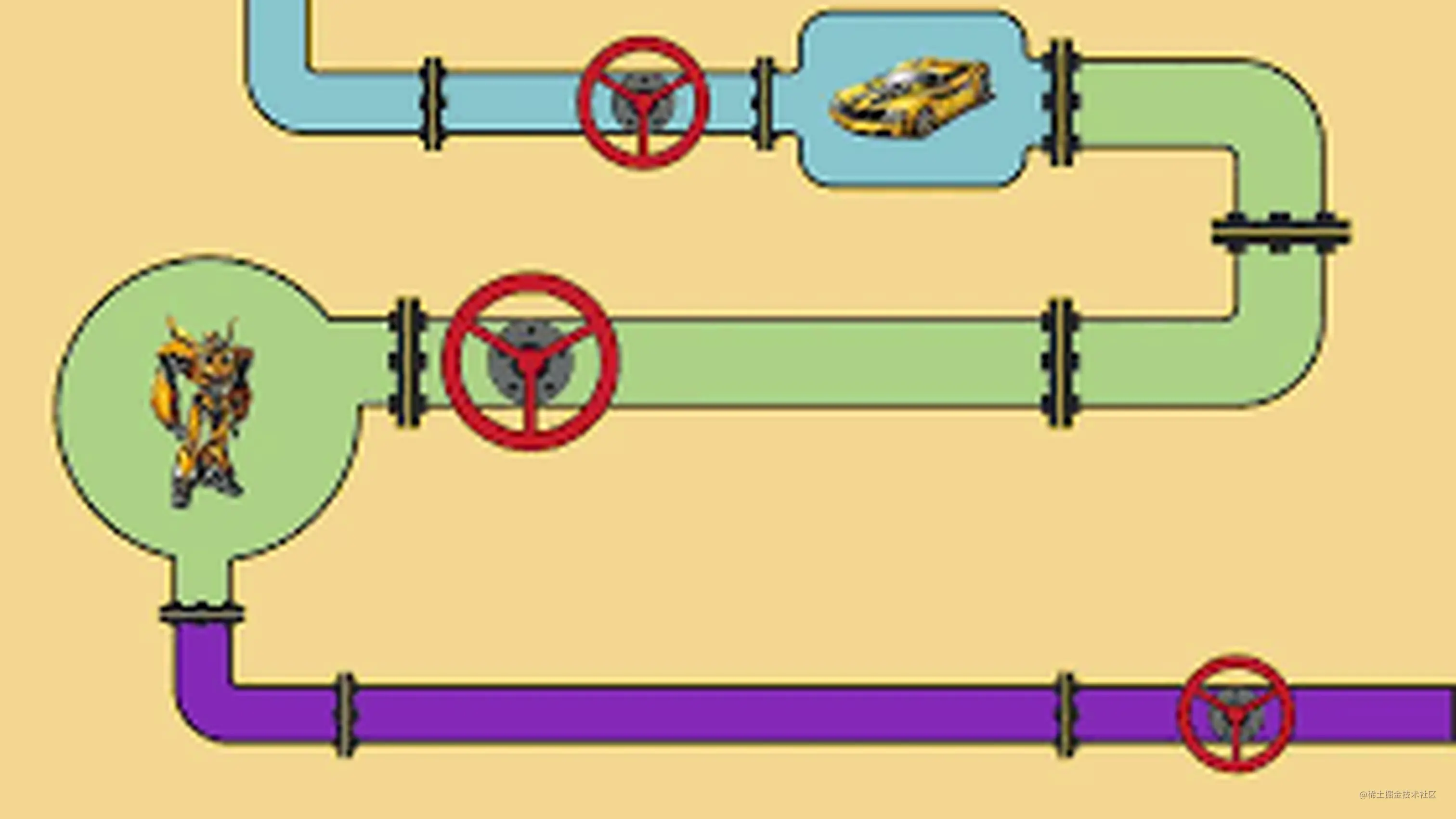
管道模式可用看做是富士康流水线,每个环节都依赖上个环节的输出
-
责任链模式类似于招标,下发任务,谁有能力谁处理,不需要关心其他人;
当然设计模式肯定是可以混用的,都是使用两个模式也是OK的。
需求中的案例
在负责的项目中,一般我们的业务模型会越来越复杂,想要做一件事需要和多个模型交互;
而模型之间又存在依赖关系,一个模型依赖另外一个模型的某个属性;
每个模型都有需要校验的部分,连续多个之后,我们的代码结构就会变得比较长。
比如:
输入某个任务:
1、检查任务是否有其他导出渠道。 查出渠道模型;
2、检查渠道是否审核通过;
3、检查渠道审核通过之后是否有导出记录; 查记录模型;
4、检查导出记录状态是否符合预期;
复制代码3,4是以来1,2的结果的,但是都在一起写,目前还不是很长,但是如果继续增加逻辑就会变得更长。
如果使用的管道模式的话:
Code
定义阶段
管道模式的输入依赖上一个阶段的输出,因此入参和出参都需要考虑进去。
public interface PipeStage<I,O> {
/**
* 通过异常来终止观点的执行过程
*/
class StepException extends RuntimeException {
public StepException(Throwable t) {
super(t);
}
}
O process(I input);
}
复制代码定义管道
管道可以不断的添加新的阶段,并且每个阶段依赖上个阶段的输出
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class Pipeline<I, O> {
private final PipeStage<I, O> currentHandler;
Pipeline(PipeStage<I, O> currentHandler) {
this.currentHandler = currentHandler;
}
<K> Pipeline<I, K> addHandler(PipeStage<O, K> newHandler) {
log.info("addHandler");
PipeStage<I, K> ikHandler = input -> newHandler.process(currentHandler.process(input));
return new Pipeline<>(ikHandler);
}
O execute(I input) {
return currentHandler.process(input);
}
}
复制代码定义管道阶段实现
使用刚才的例子:
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class AbstractHandler {
@Data
static class ChannelConfig {
/**
* 渠道Id
*/
private String id;
/***
* 审判状态
*/
private int applyStatus;
}
@Data
static class ChannelExportRecord{
private String configId;
/**
* 导出状态
*/
private int exportStatus;
}
static class CheckApprovedHandler implements PipeStage<String, ChannelConfig> {
@Override
public ChannelConfig process(String input) {
// ... 此处查询input中的值,判断渠道配置
log.info("apprvoed {}",input);
ChannelConfig channelConfig = new ChannelConfig();
return channelConfig;
}
}
public static class CheckRecordSuccessHandler implements PipeStage<ChannelConfig, ChannelExportRecord> {
@Override
public ChannelExportRecord process(ChannelConfig input) {
log.info("record passed {}",input);
return new ChannelExportRecord();
}
}
}
复制代码使用管道
把我们刚才的代码组合起来:
Slf4j
public class PipeDemo {
public static void main(String[] args) {
Pipeline<String, ChannelExportRecord> handler = new Pipeline<>(
new CheckApprovedHandler())
.addHandler(new CheckRecordSuccessHandler());
//String filters = (String)handler;
log.info("start Handler");
ChannelExportRecord record = handler.execute("导出配置Id");
log.info("result {}", JSON.toJSONString(record));
}
}
复制代码运行结果

总结
1、每个管道阶段在实现的时候是互相独立的;这样也更方便单测 2、管道阶段在使用的时候会组合成一个流水线管道,每个阶段的输入和输出有一定依赖关系,上个阶段要为下个阶段准备好数据。 3、设计模式的通用好处:代码可读性,维护性提升;当然管道模式有点像Java的Stream,只是Stream里面一般不会写笔记复杂的逻辑。