实在是太忙了,终于闲下来更新一下CSDN来介绍自己的工作
《Surprisingly Popular-Based Adaptive Memetic Algorithm for Energy-Efficient Distributed Flexible Job Shop Scheduling》发表在IEEE Transactions on Cybernetics上。
原文链接-可下载
Matlab代码
IEEE原文引用链接
背景
16年发表在Nature上的一篇letter,作者讲述了,如何通过数据采集,bayes概率公式,对人群中的决策进行修正,发现调查问卷中真正正确的答案,并给出了修正算法名为Surprisingly Popular Algorithm.
大致过程如下图所示,美国的宾夕法尼亚是费城最大的城市,所以多数人以为宾州是费城的省会,但其实费城的省会是哈里斯伯格。这是因为群体的人都是凭借主观意识和经验在做决策,而非客观的专家知识。正如你小时候没学过地理知识,以为深圳是广东最发达的城市就误以为深圳是广东的省会,但其实广州才是广东省会。这样的案例使得作者Prelec做出了市场调研,并发现了这一个规律。

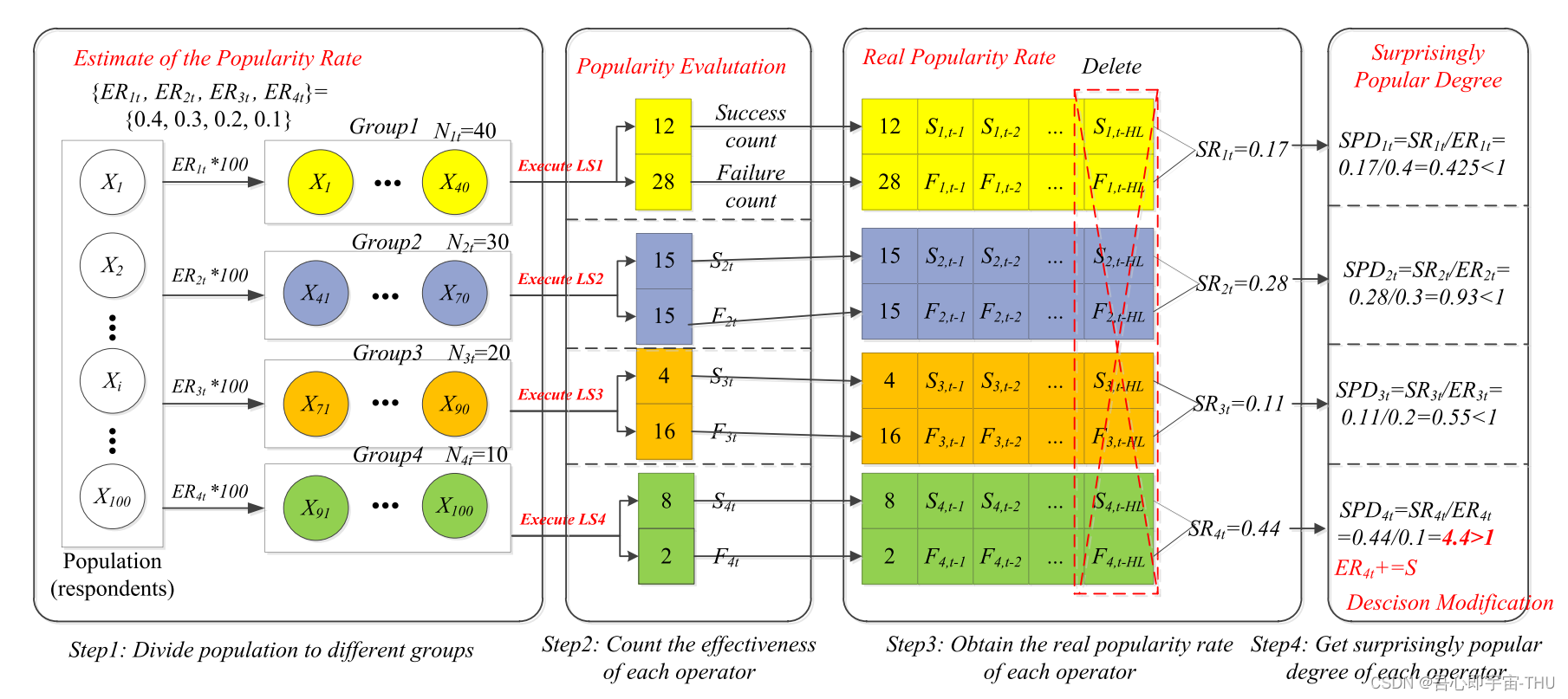
种群规律:如果将种群中每部分个体,让他们对一个决策给出自己的答案,对,错,弃权,并统计他们的比例R,让他们对自己的答案给出一个预估流行度E。则通过贝叶斯概率公式矫正,以每个答案的比例,乘以其在种群中的真实比例算出每个答案真正的流行度。例如yes的真正流行度如下,被修正为88.2而No的概率被修正为11.8,说明知道正确答案的人也认为,这是个冷知识,没学过的人肯定不知道。那么将预估流行度E和真正流行度P做一个比值,得到意外流行度SPD=E/D。结果发现意外流行度大于1的答案就是正确答案。
为了验证这个观点,作者又做了另一个城市的调研,发现规律一致。则说明,种群中无知的人会盲目乐观,认为别人肯定也是这么认为的,而有专家知识的人,确实是少数,即真理掌握在少数人手里。
有一些人用SPA去预测NBA,NFL季后赛冠军,结果都说对了,说明这是个很强的算法,这些论文被发表在IJCAI,Machine Learning等顶会顶刊上。




吉林大学的wuxuan 应用SPA对PSO的交叉算子选择进行了改进,PSO的选择交叉算子往往选择距离相近的来进化,但受制于种群空间拓扑关系,欧氏距离最近的不一定是最近最好的。所以采用SPA对统计概率进行修正,最终找到了真正最近而不密集的交叉个体,取得了最好的结果,胜过了所有CEC的冠军PSO算法。


wuxuan通过这篇工作也是获得 了吉林大学优秀硕士毕业论文
动机
受wuxuan的启发,我在想,如何将这类技术应用到离散优化例如分布式柔性作业车间调度问题中?使得算法也具备决策修正的能力。是不是在做决策的时候也会出现经验主义而使得决策错误延缓进化呢?
想到的最直接的方法:在车间调度问题,会设计多个算子进行搜索,但不同的算子不同时期表现的优劣不同,那么就会有很多自适应的方法,其中有基于历史经验的方法,例如JADE。那么由于历史经验受前50多代的影响,对于近代一些真正有效的算子不能及时的分配计算资源。所以SPA就可以通过调查统计近代所有算子的成功率和预估成功率,来及时对算子的资源分配进行修正
算法
大致过程如图所示,首先算子依据历史经验来分配资源,其次,统计每个子种群算子的成功率,并累计进去和历史成功率做一个总和(相当于贝叶斯概率修正),而本轮的分配概率即上一轮的历史成功率,那么即为预估的成功率,那么将预估成功率和当前成功率做比值,得到意外流行度,发现,意外流行度大于1的算子近期很有效,应该分配更多的资源。

实验结果
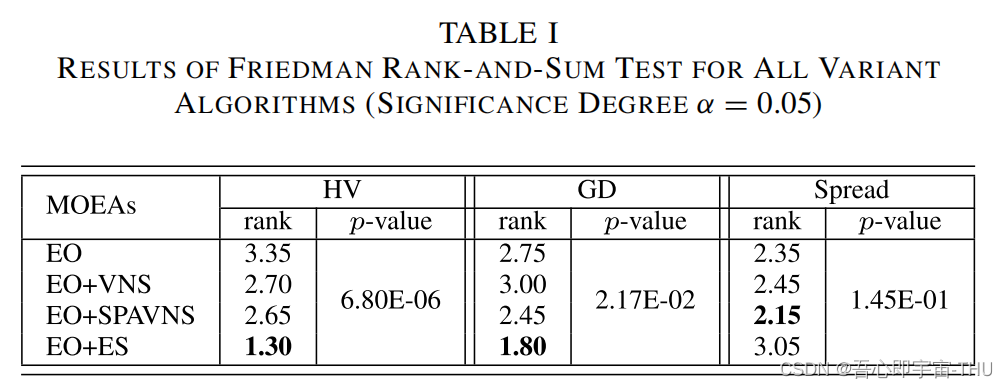
根据Mk测试集,设置了20个不同的分布式FJSP的问题,消融结果统计后,对HV,GD,Spread指标统计均值,并进行了Friedman秩和检验
通过对比SPAVNS和VNS可以发现,各项指标的排名有所提升。说明SPA的修正起到了一定的作用。
不足:设计的SPA算法还是没有设计到精髓,还有更多可以和进化计算结合的场景,等待后人开发。