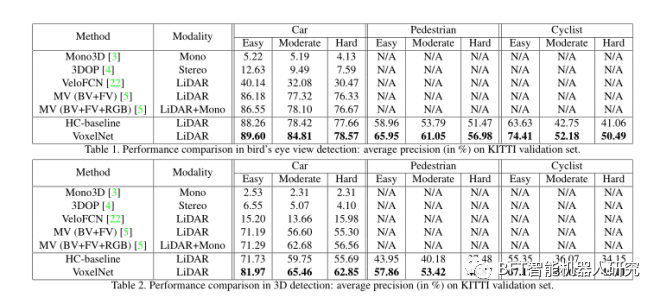
CUDA并行归约算法(二)

文章目录
- CUDA并行归约算法(二)
- 前情回顾
- 线程束分化
- 内存组织
- Reference
- >>>>> 欢迎关注公众号【三戒纪元】 <<<<<
前情回顾
首先看下上节设计的核函数,如何进行并行归约算法的:
__global__ void ReduceNeighbour(int* g_idata, int* g_odata, unsigned int n)
{
//set thread ID
unsigned int t_id = threadIdx.x;
// boundary check
if (t_id >= n)
{
return;
}
int *idata = g_idata + blockIdx.x * blockDim.x;
// in-place reduction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2) {
if((t_id % (2 * stride)) == 0) {
idata[t_id] += idata[t_id + stride];
}
// synchronize within block
__syncthreads();
}
// write result for this block to global memory
if (t_id == 0)
{
g_odata[blockIdx.x] = idata[0]; // 记录每个block的值
}
}
主要是通过设计stride,使其每次加2
idata[t_id] += idata[t_id + stride];
控制每次迭代的与当前线程相加的数,t_id 代表当前线程ID,t_id + stride 代表被加线程ID
这就造成了每轮迭代只有部分线程是活跃的,越到后面,不活跃的线程越多。
由于GPU的硬件设计,每次调度都会以1个线程束为单位进行,所以,1个线程束里只要有1个线程需要活跃,当前线程束内的线程全部都会活跃起来,即便很多线程不参与计算,这就非常影响程序的执行效率。
可以看出有2个比较明显的优化点:
- 线程束分化
- 内存访问
线程束分化
可以通过重新组织线程索引来解决线程束分化问题:
__global__ void ReduceNeighboredLess(int *g_idata, int *g_odata, unsigned int n) {
unsigned idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx > n) {
return;
}
unsigned int tid = threadIdx.x;
// convert global data pointer to the local point of this block
int* idata = g_idata + blockIdx.x * blockDim.x;
// in-place reuction in global memory
for (int stride = 1; stride < blockDim.x; stride *= 2) {
// convert tid into local array index
int index = 2 * stride * tid;
if (index < blockDim.x) {
idata[index] += idata[index + stride];
}
__syncthreads();
}
// write result for this block to global memory
if (tid == 0) {
g_odata[blockIdx.x] = idata[0];
}
}
先跑下结果:
Using device 0: NVIDIA GeForce RTX 3070 Laptop GPU
array size: 16777216
grid size: 16384, block size: 1024
CPU sum: 2139035173
CPU reduction elapsed 48.8141 ms, CPU sum: 2139035173
gpu sum:2139035173
gpu ReduceNeighboredLess elapsed 1.270056 ms <<<grid 16384 block 1024>>>
Test success!
优化前GPU时间为 2.512932 ms,优化后的时间为 1.270056 ms,节约了近一半的时间。
因此,避免线程束的分化十分重要。
到底怎么做到的呢?
来看下线程结构
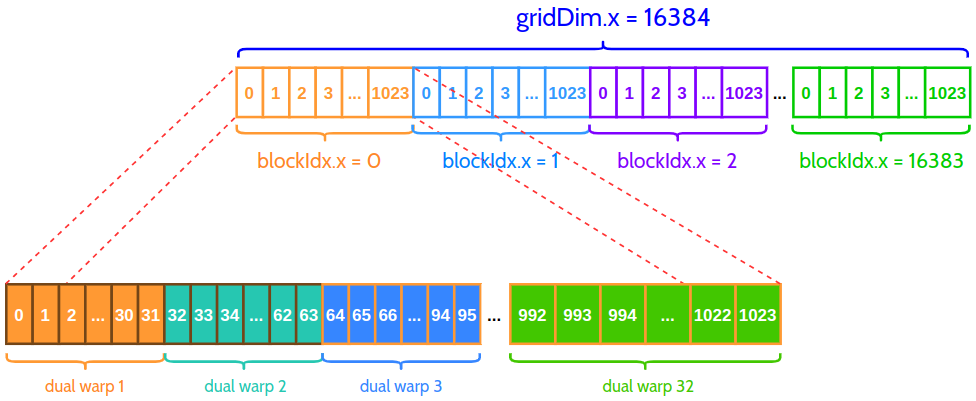
总共有16384个grid,在每个线程块(block)有1024个线程( 16777216 = 16384 × 1024 16777216 = 16384 \times 1024 16777216=16384×1024),每个block中又包含32个双线程束,也就是1024( 1024 = 32 × 32 1024 = 32 \times 32 1024=32×32)个线程被32个线程束管理着,每个线程束管理32个线程。
每次参与计算的线程号其实就是 int index = 2 * stride * tid; 与 index + stride,而线程号需要满足index < blockDim.x (1024)的条件,
因此,第一轮stride = 1,实际参与计算的线程号为:0,1,2,3, …, 511,512。而
512
=
32
×
16
512 = 32 \times 16
512=32×16,也就是实际参与计算的也就前16个线程束,后16个线程束在if (index < blockDim.x)就结束了。
第二轮,stride = 2,实际参与计算的线程id 为 0,2,4,6,12, 14, 256。也就是前8个线程束参与了计算,后24个线程束不计算。
而在原来的代码中,第一轮是线程id为偶数的线程参与计算,第二轮是线程id是4的倍数的线程参与计算,但是其他线程仍然是活跃的。
内存组织
之前的方法,第一轮过后,会造成第二轮因为使用了stride作为跨度量而导致的内存访问不连续。
因此需要重新组织一下配对方法,让对内存的访问更加集中。
可以使用交错配对方法:
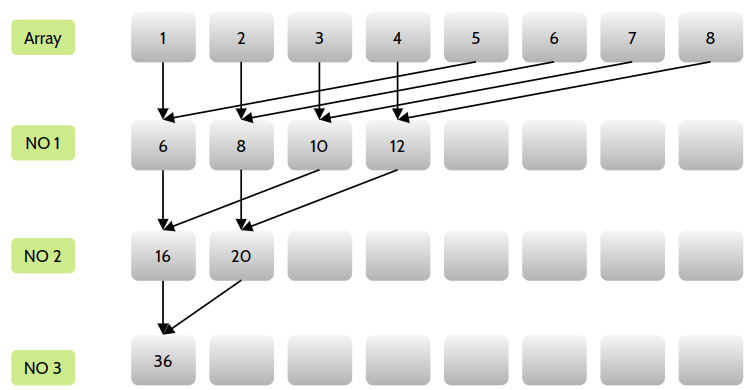
核函数如下:
__global__ void ReduceInterleaved(int * g_idata, int *g_odata, unsigned int n)
{
unsigned idx = blockIdx.x*blockDim.x + threadIdx.x;
if (idx >= n)
return;
// convert global data pointer to the local point of this block
int *idata = g_idata + blockIdx.x*blockDim.x;
unsigned int tid = threadIdx.x;
//in-place reduction in global memory
for (int stride = blockDim.x / 2; stride > 0; stride >>= 1)
{
if (tid <stride)
{
idata[tid] += idata[tid + stride];
}
__syncthreads();
}
//write result for this block to global men
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
结果为:
Using device 0: NVIDIA GeForce RTX 3070 Laptop GPU
with array size 16777216 grid 16384 block 1024
cpu sum:2139617404
cpu reduction elapsed 56.808949 ms cpu_sum: 2139617404
gpu sum:2139617404
gpu reduceInterleaved elapsed 1.042843 ms <<<grid 16384 block 1024>>>
Test success!
优化线程束分化后,又改进了内存放访问方式,时间消耗(1.042843 ms)比仅改进线程束时间消耗更短。
因此,对全局内存的访问要尽量进行合并访问与存储
Reference
- CUDA编程入门(五)更高效的并行归约算法