摘要:本文整理自联通数科实时计算团队负责人、Apache StreamPark Committer 穆纯进在 Flink Forward Asia 2022 平台建设专场的分享,本篇内容主要分为四个部分:
实时计算平台背景介绍
Flink 实时作业运维挑战
基于 StreamPark 一体化管理
未来规划与演进
点击查看原文视频 & 演讲PPT
一、实时计算平台背景介绍

上图是实时计算平台的整体架构,最底层是数据源,由于一些敏感信息,没有将数据源的详细信息列出,它主要包含三部分,分别是业务数据库、用户行为日志、用户位置,联通的数据源非常多,业务数据库这一项就有几万张表;主要通过 Flink SQL 和 DataStream API 来处理数据 ,数据处理流程包括 Flink 对数据源的实时解析、规则的实时计算以及实时产品;用户在可视化订阅平台上进行实时数据订阅,用户可以在地图上画一个电子围栏,并设置一些规则,如来自于哪里,在围栏里驻留多长时间等,还可以筛选一些特征,符合这些规则的用户信息会实时进行推送,然后是实时安全部分,当某个用户连接了高危基站或是有异常操作行为时,我们会认为可能存在诈骗行为,会对手机号码进行关停等等,还有用户的一些实时特征以及实时大屏。
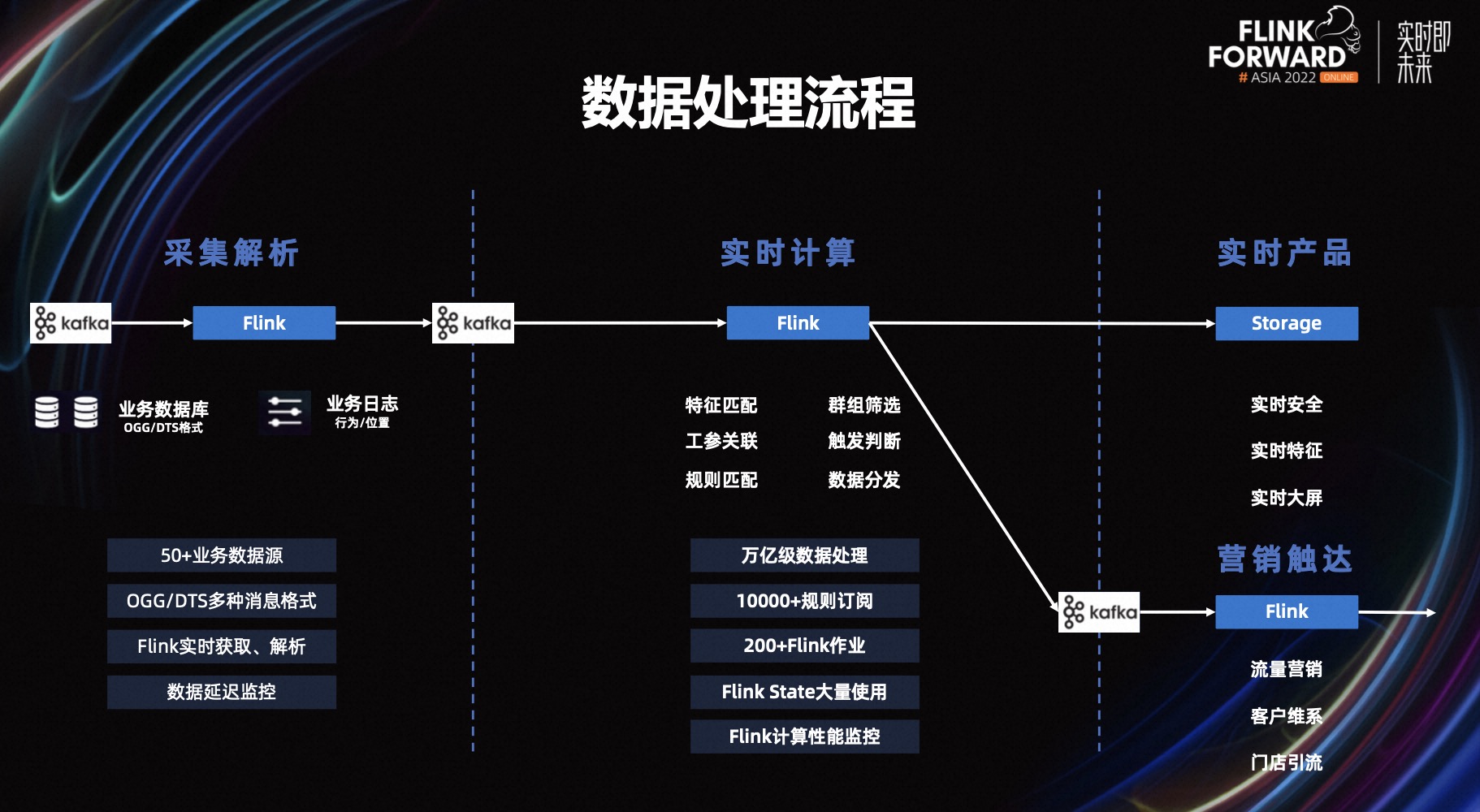
上图是数据处理的详细的流程。
第一部分是采集解析,我们的数据源来自于业务的数据库,包含 OGG 和 DTS 格式的消息、日志消息、用户行为和用户位置数据,总共 50 多种数据源,后续还会逐渐增加,所有数据源均使用 Flink 做实时解析;并增加了 Metrics 来监控数据源的延迟情况。
第二部分是实时计算, 这个环节处理的数据量很大,数据量在万亿级别,支撑了 10000+的数据实时订阅,有 200 多个 Flink 任务,我们将某一种同类型的业务封装成一种场景,同一个 Flink 作业可以支持相同场景的多个订阅,目前 Flink 作业数还在不停的增长,后续可能会增加到 500 多个;其中面临的一个很大挑战是每天万亿级的数据实时关联电子围栏、用户特征等信息,电子围栏有几万个,用户特征涉及数亿用户,最初我们将电子围栏信息和用户特征放到 HBase, 但这样会导致 HBase 压力很大,经常遇到性能问题造成数据延迟,而且一旦产生数据积压,需要很长的时间去消化,得益于 Flink State 的强大,我们将电子围栏信息和用户特征放到状态里,目前已经很好的支撑了大并发的场景,同时我们也增加了数据处理的性能监控;最后是实时产品和营销触达前端的一些应用。
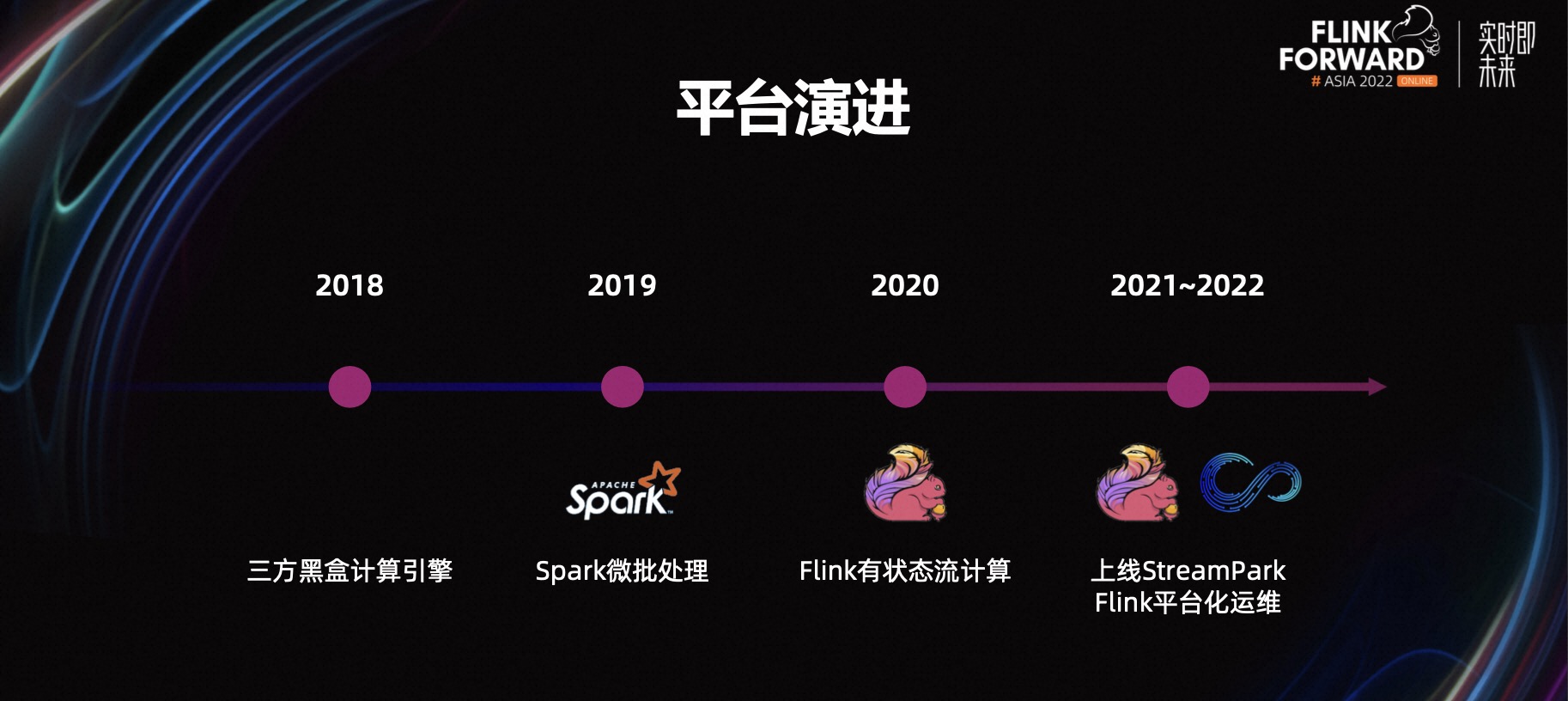
2018 年采用了三方黑盒的计算引擎,不能支持灵活定制个性化功能,且依赖过多外部系统,导致外部系统负载高,运维复杂;2019 年使用了 Spark Streaming 的微批处理,2020 年开始使用 Flink 的流式计算,从 2021 年开始,几乎所有 Spark Streaming 的微批处理都被 Flink 替代了,同时上线了 Apache StreamPark 对我们的 Flink 作业进行管理。

总结一下平台背景,主要包含以下几部分:
-
数据量大:日均 2.3 万亿的数据处理。
-
数据源多:集成了 50 多种实时数据源。
-
订阅多:支撑了 10000+的数据服务订阅。
-
用户多:支撑了 30 多个内部和外部用户使用。

运维背景也可以分为以下几部分:
-
支撑需求多:50 多种数据源,10000+的数据服务订阅。
-
实时作业多:现在有 200+Flink 生产作业,并且持续快速增长中, 未来可达 500+。
-
上线频率高:每天都有新增的或增强的 Flink 作业上线操作。
-
开发人员多:50+研发人员参与开发 Flink 实时计算任务。
-
使用用户多:30+内部和外部组织的用户使用。
-
监控延迟低:一旦发现问题我们要立马进行处理,避免引起用户的投诉。
二、Flink 实时作业运维挑战

基于平台和运维背景,尤其是 Flink 作业越来越多的情况下,遇到了很大的挑战,主要有两方面,分别是作业运维困境和业务支撑困境。
在作业运维困境上,首先作业部署流程长、效率低;在联通安全是第一红线下,在服务器上部署程序的时候,要连接 VPN、登录 4A、打包编译、部署、然后再启动,整个流程比较长,最初在开发 Flink 的时候,都是用脚本启动的,导致代码分支是不可控的,部署完之后也难以追溯,再就是脚本很难与 git 上的代码进行同步,因为对于脚本代码,开发人员更喜欢在服务器上直接改,很容易忘记上传 git。
由于作业运维困境上的种种因素,会产生业务支撑困境,如导致上线故障率高、影响数据质量、上线时间长、数据延迟高、告警漏发处理等,引起的投诉,此外,我们的业务影响不明确,一旦出现问题,处理问题会成为第一优先级。
三、基于 StreamPark 一体化管理
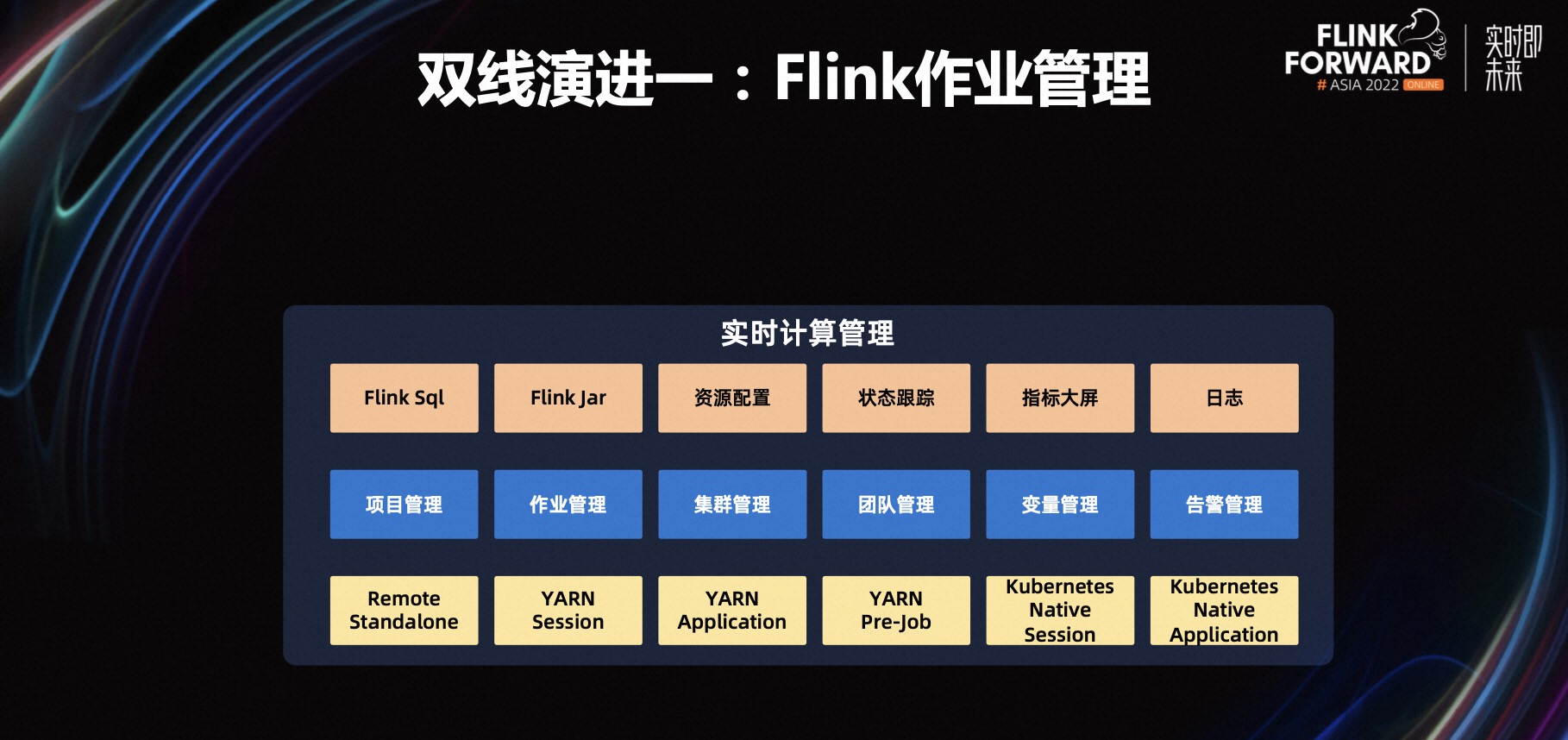
对于以上的两种困境,我们基于 StreamPark 一体化管理解决了很多问题,首先来看一下 StreamPark 的双线演进,分别是 Flink 作业管理和 Flink 作业 DevOps 平台;在作业管理上,StreamPark 支持将 Flink 实时作业部署到不同的集群里去,比如 Flink 原生自带的 Standalone 模式,Flink on Yarn 的 Session、Application、PerJob 模式,在最新的版本中将支持 Kubernetes Native Session 模式;中间层是项目管理、作业管理、集群管理、团队管理、变量管理、告警管理。
-
项目管理:当部署 Flink 程序的时候,可以在项目管理里填写 git 地址,同时选择要部署的分支。
-
作业管理:可以指定 Flink 作业的执行模式,比如你要提交到什么类型的集群里去,同时还可以配置一些资源,比如 TaskManager 的数量、TaskManager/JobManager 的内存大小、并行度等等,还可以设置一些容错,比如 Flink 作业失败后,StreamPark 可以支持它自动拉起,同时支持传入一些动态参数。
-
集群管理:可以在界面上添加和管理大数据集群。
-
团队管理:在企业的实际生产过程中会有多个团队,团队之间是隔离的。
-
变量管理:可以把一些变量统一维护在一个地方,比如 Kafka 的 Broker 地址定义成一个变量,在配置 Flink 作业或者 SQL 的时候,就可以以变量的方式来替换 Broker 的 IP,且后续这个 Kafka 要下线的时候,也可以通过这个变量去查看到底哪些作业使用了这个集群,方便我们去做一些后续的流程。
-
告警管理:支持多种告警模式,如微信、钉钉、短信和邮件。
StreamPark 支持 Flink SQL、Flink Jar 的提交,支持资源配置,支持状态跟踪,如状态是运行状态,失败状态等,同时支持指标大屏和各种日志查看。

Flink 作业 DevOps 平台,主要包括以下几部分:
- 团队:StreamPark 支持多个团队,每个团队都有团队的管理员,他拥有所有权限,同时还有团队的开发者,他只有少量的一部分权限。
- 编译、打包:在创建 Flink 项目时,可以把 git 地址、分支、打包的命令等配置在项目里,然后一键点击 build 按钮进行编译、打包。
- 发布、部署:发布和部署的时候会创建 Flink 作业,在 Flink 作业里可以选择执行模式、部署集群、资源设置、容错设置、变量填充,最后通过一键启动停止,启动 Flink 作业。
- 状态监测:Flink 作业启动完成之后,就是状态的实时跟踪,包括 Flink 的运行状态、运行时长、Checkpoint 信息等,并支持一键跳转到 Flink 的 Web UI。
- 日志、告警:包含构建的一些日志和启动日志,同时支持钉钉、微信、邮件、短信等告警方式。

企业一般有多个团队同时开发实时作业,在我们公司包含实时采集团队、数据处理团队和实时的营销团队,StreamPark 支持多个团队的资源隔离。
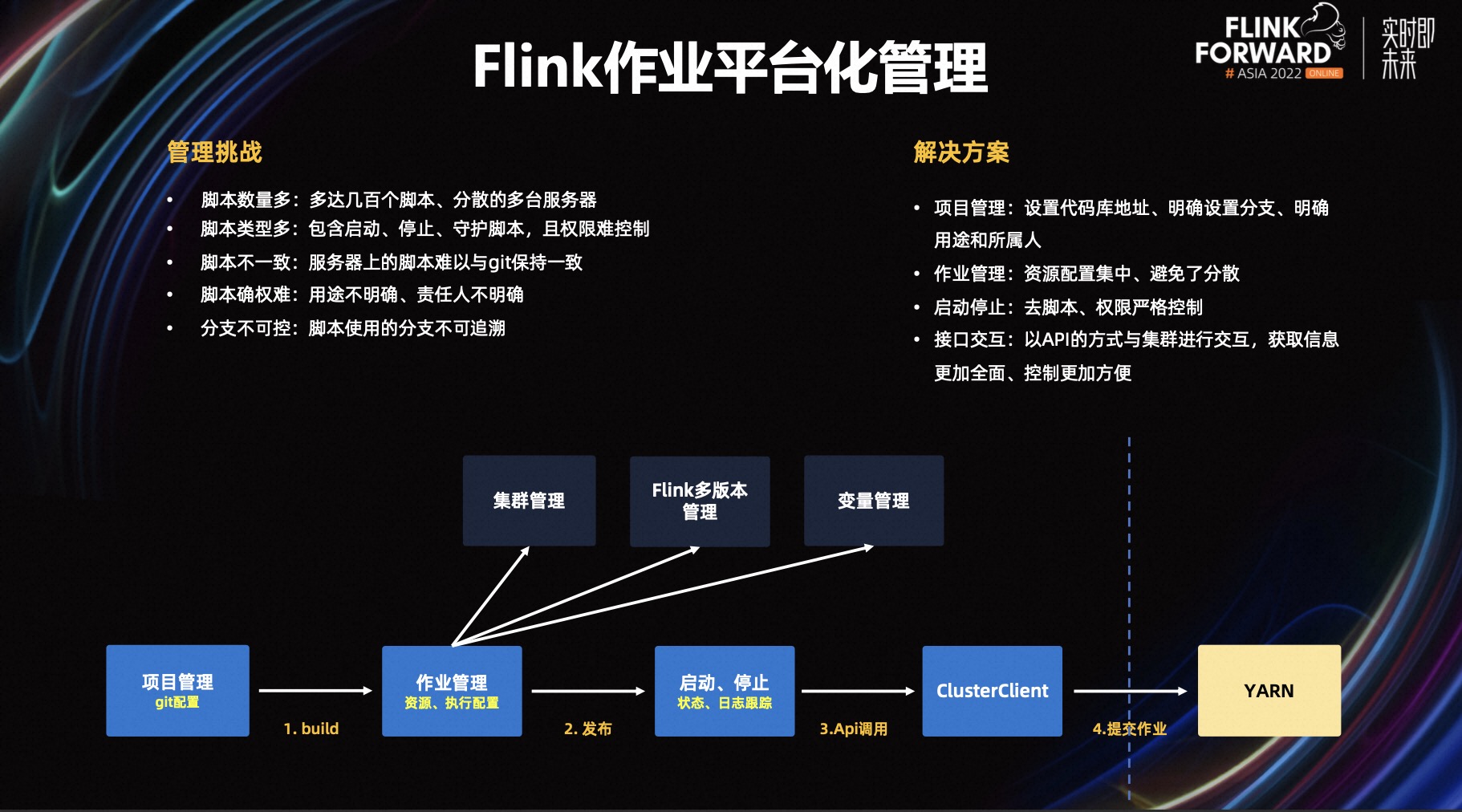
Flink 作业平台化管理面临如下挑战:
-
脚本数量多:平台有几百个脚本,分散在多个服务器上。
-
脚本类型多:在启动 Flink 作业时,会有启动脚本、停止脚本和守护脚本,而且操作权限很难控制。
-
脚本不一致:服务器上的脚本与 git 上的脚本不一致。
-
脚本确权难:Flink 作业的责任人,用途不明确。
-
分支不可控:启动作业的时候,需要在脚本里指定 git 分支,导致分支不可追溯的。
基于以上的挑战,StreamPark 通过项目管理来解决了责任人不明确,分支不可追溯的问题,因为在创建项目的时候需要手动指定一些分支,一旦打包成功,这些分支是有记录的;通过作业管理对配置进行了集中化,避免了脚本太过于分散,而且作业启动、停止的权限有严格的控制,避免了脚本化权限不可控的状态,StreamPark 以接口的方式与集群进行交互来获取作业信息,这样做会让作业控制更加精细。
可以看一下上图中下面的图,通过项目管理进行打包,通过作业管理进行配置,然后发布,可以进行一键启停,通过 API 提交作业。

早期我们需要通过 7 步进行部署,包括连接 VPN、登录 4A、执行编译脚本、执行启动脚本、打开 Yarn、搜索作业名、进入 Flink UI 等 7 个步骤,StreamPark 可以支持 4 个一键进行部署,包括一键打包、一键发布、一键启动、一键到 Flink UI。
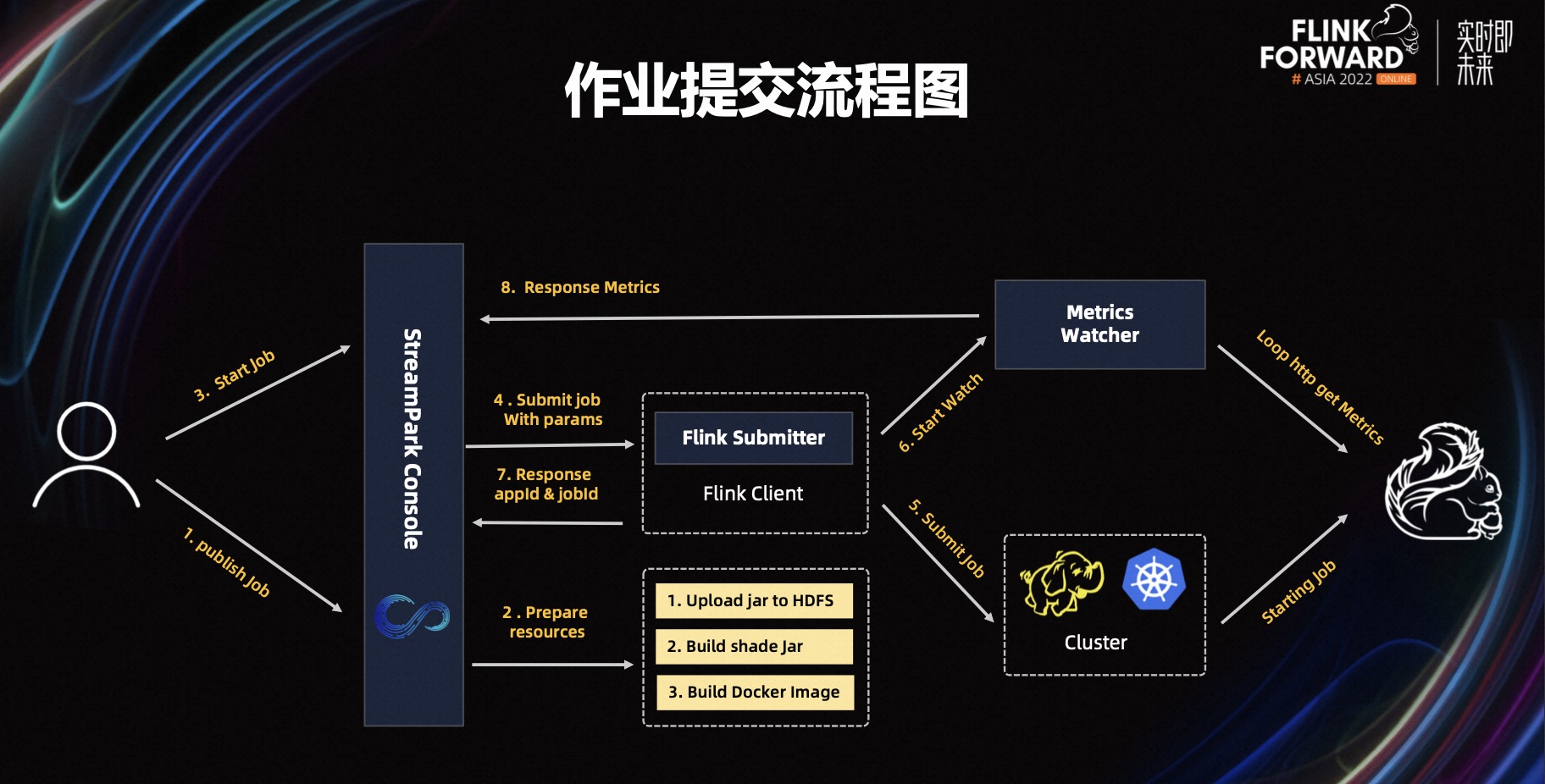
上图是我们 StreamPark 的作业提交流程,首先 StreamPark 会将作业进行发布,发布的时候会上传一些资源,然后会进行作业的提交,提交的时候会带上配置的一些参数,以 Flink Submit 的方式调用接口发布到集群上;这里会有多个 Flink Submit 对应着不同的执行模式,比如 Yarn Session、Yarn Application、Kubernetes Session、Kubernetes Application 等都是在这里控制的,提交作业之后,如果是 Flink on Yarn 作业,会得到这个 Flink 作业的 Application ID 或者 Job ID,这个 ID 会保存在我们的数据库中,如果是基于 Kubernetes 执行的话,也会得到 Job ID,后面我们在跟踪作业状态的时候,主要就是通过保存的这些 ID 去跟踪作业的状态。
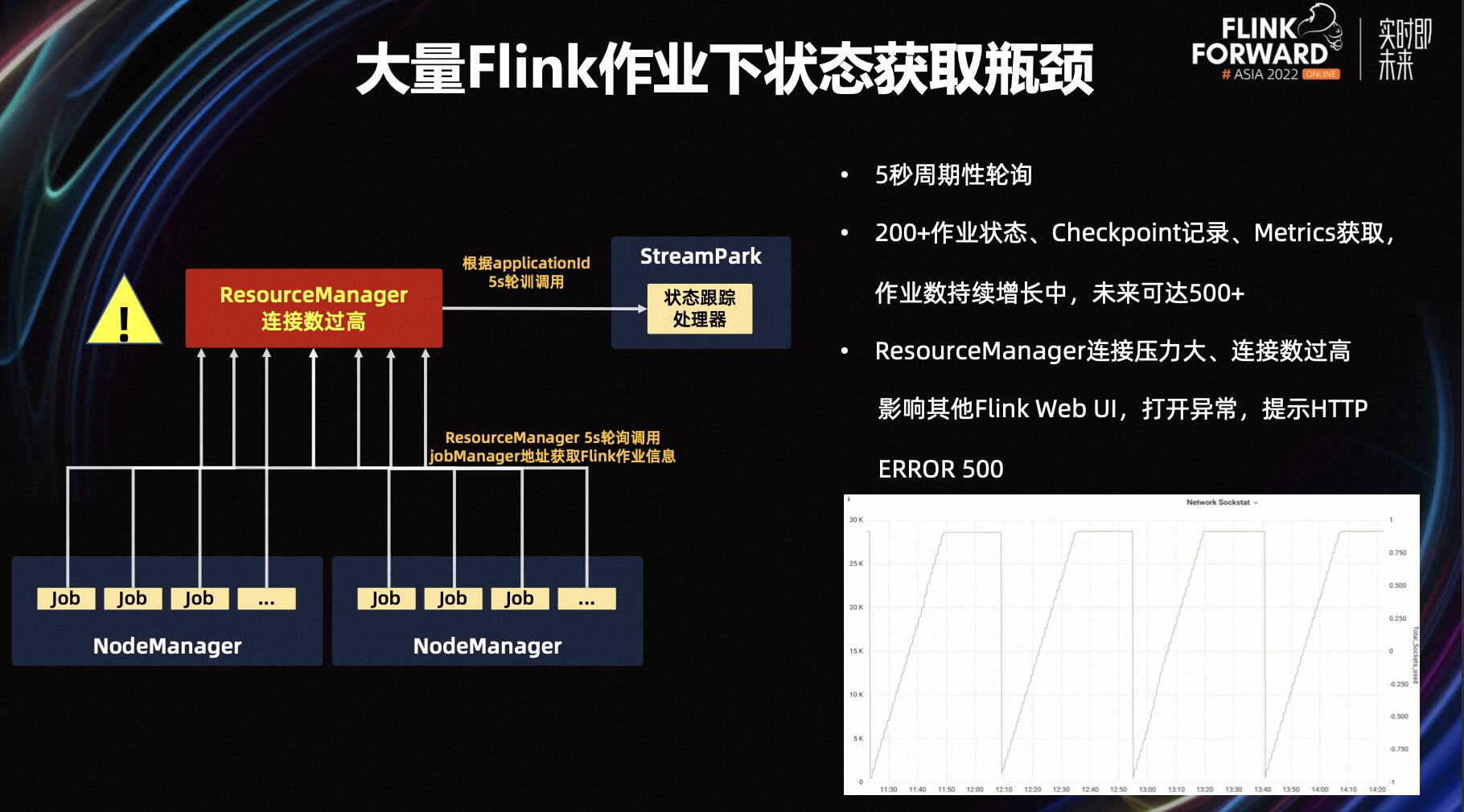
如上所述,如果是 Flink on Yarn 作业,在提交作业的时候会获取两个 ID,Application ID 或者 Job ID,基于这两个 ID 可以获取我们的状态,但当 Flink 作业非常多的时候会遇到一些问题,StreamPark 它是有一个状态获取器,它会通过我们保存的数据库里的 Application ID 或者 Job ID,去向 ResourceManager 做一个请求,会做每五秒钟周期性的轮询,如果作业特别多,每次轮询 ResourceManager 会负责再去调用 Job Manager 的地址访问它的状态,这就会导致 ResourceManager 的连接数压力较大和连接数过高。
上图中 ResourceManager 的连接数阶段性、周期性的持续走高,可以看到 ResourceManager 处于比较红的状态,从主机上去监控的时候,它的连接数确实比较高。
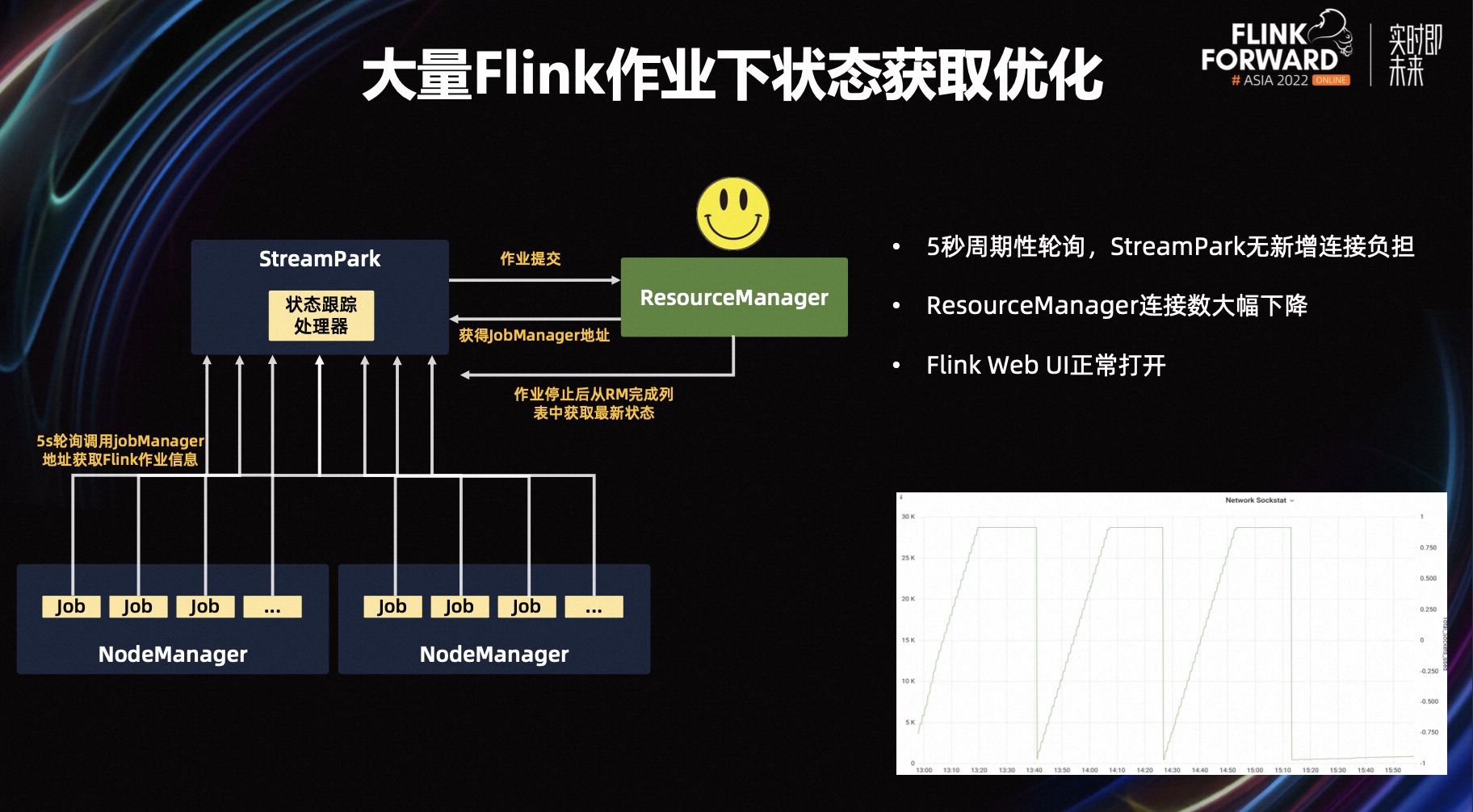
针对上面的问题,我们做了一些优化,首先 StreamPark 保存了提交作业之后的 Application ID 或者 Job ID,同时也会获取 Job Manager 直接访问的地址,并保存在数据库中,每次轮询时不再通过 ResourceManager 获取作业的状态,它可以直接调用各个 Job Manager 的地址实时获取状态,极大的降低了 ResourceManager 的连接数;从上图最后的部分可以看到,基本不会产生太大的连接数,大大减轻了 ResourceManager 的压力,且后续当 Flink 作业越来越多时获取状态也不会遇到瓶颈的问题。
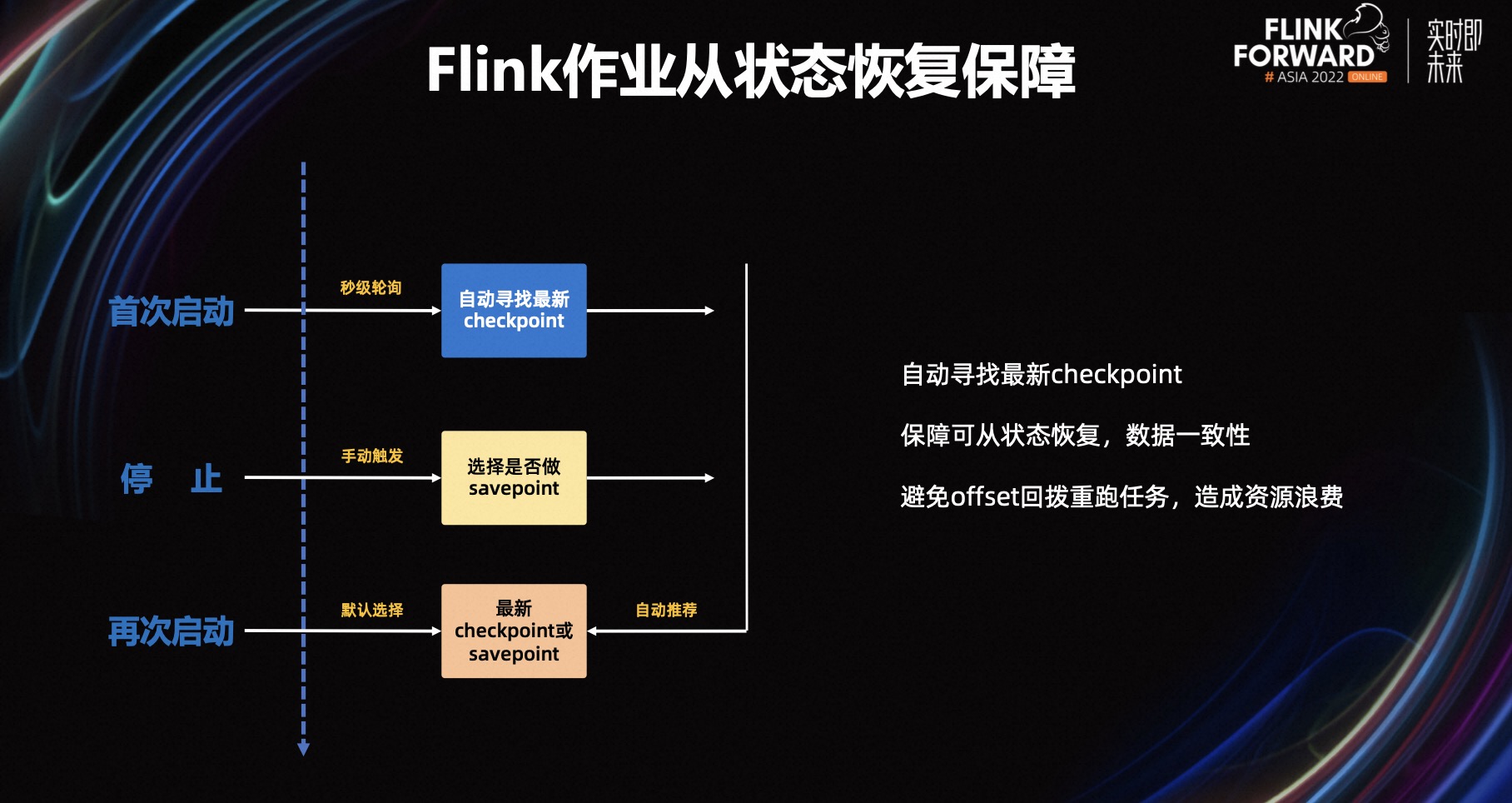
StreamPark 解决的另一个问题是 Flink 从状态恢复的保障,以前我们用脚本做运维的时候,在启动 Flink 的时候,尤其是在业务升级的时候,要从上一个最新的 Checkpoint 来恢复,但经常有开发人员忘记从上一个检查点进行恢复,导致数据质量产生很大的问题,遭到投诉,StreamPark 的流程是在首次启动的时候,每五秒钟轮询一次获取 Checkpoint 的记录,同时保存在数据库之中,在 StreamPark 上手动停止 Flink 作业的时候,可以选择做不做 Savepoint,如果选择了做 Savepoint,会将 Savepoint 的路径保存在数据库中,同时每次的 Checkpoint 记录也保存在数据库中,当下次启动 Flink 作业的时候,默认会选择最新的 Checkpoint 或者 Savepoint 记录,有效避免了无法从上一个检查点去恢复的问题,也避免了导致问题后要进行 offset 回拨重跑作业造成的资源浪费,同时也保证了数据处理的一致性。

StreamPark 还解决了在多环境下多个组件的引用挑战,比如在企业中通常会有多套环境,如开发环境、测试环境、生产环境等,一般来说每套环境下都会有多个组件,比如 Kafka,HBase、Redis 等,而且在同一套环境里还可能会存在多个相同的组件,比如在联通的实时计算平台,从上游的 Kafka 消费数据的时候,将符合要求的数据再写到下游的 Kafka,这个时候同一套环境会涉及到两套 Kafka,单纯从 IP 很难判断是哪个环境哪个组件,所以我们将所有组件的 IP 地址都定义成一个变量,比如 Kafka 集群,开发环境、测试环境、生产环境都有 Kafka.cluster 这个变量,但它们指向的 Broker 的地址是不一样的,这样不管是在哪个环境下配置 Flink 作业,只要引用这个变量就可以了,大大降低了生产上的故障率。

StreamPark 支持 Flink 多执行的模式,包括基于 on Yarn 的 Application/ Perjob / Session 三种部署模式,还支持 Kubernetes 的 Application 和 Session 两种部署模式,还有一些 Remote 的模式。

StreamPark 也支持 Flink 的多版本,比如联通现在用的是 1.14.x,现在 1.16.x 出来后我们也想体验一下,但不可能把所有的作业都升级到 1.16.x,我们可以把新上线的升级到 1.16.x,这样可以很好的满足使用新版本的要求,同时也兼容老版本。
四、未来规划与演进

未来我们将加大力度参与 StreamPark 建设,以下我们计划要增强的方向。
-
高可用:StreamPark 目前不支持高可用,这方面还需要做一些加强。
-
状态的管理:在企业实践中 Flink 作业在上线时,每个算子会有 UID。如果 Flink UID 不做设置,做 Flink 作业的升级的时候,就有可能出现状态无法恢复的情况,目前通过平台还无法解决这个问题,所以我们想在平台上增加这个功能,在 Flink Jar 提交时,增加检测算子是否设置 UID 的功能,如果没有,会发出提醒,这样可以避免每次上线 Flink 作业时,作业无法恢复的问题;之前遇到这种情况的时候,我们需要使用状态处理的 API,从原来的状态里进行反序列化,然后再用状态处理 API 去制作新的状态,供升级后的 Flink 加载状态。
- 更细致的监控:目前支持 Flink 作业失败之后,StreamPark 发出告警。我们希望 Task 失败之后也可以发出告警,我们需要知道失败的原因;还有作业反压监控告警、Checkpoint 超时、失败告警性能指标采集,也有待加强。
- 流批一体:结合 Flink 流批一体引擎和数据湖流批一体存储探索流批一体平台。

上图是 StreamPark 的 Roadmap。
- 数据源:StreamPark 会支持更多数据源的快速接入,达到数据一键入户。
- 运维中心:获取更多 Flink Metrics 进一步加强监控运维的能力。
- K8S-operator:现有的 Flink on K8S 还是有点重,经历了打 Jar 包、打镜像、推镜像的过程,后续需要改进优化,积极拥抱上游对接的 K8S-operator。
- 流式数仓:增强对 Flink SQL 作业能力的支持,简化 Flink SQL 作业的提交,计划对接 Flink SQL Gateway;SQL 数仓方面的能力加强,包括元数据存储、统一建表语法校验、运行测试、交互式查询,积极拥抱 Flink 上游,探索实时数仓和流式数仓。
点击查看原文视频 & 演讲PPT



![[STM32教程]01如何开始准备hal库的开发环境](https://img-blog.csdnimg.cn/17de37dbbf9d4d5590924e4e00f27ea0.png)