本文针对centos7.4即以上版本的hadoop环境搭建,因为这部分搭建是个很复杂且很容易出错的内容,所以在结合了多种搭建方案后给出最适宜当前版本的搭建。
目录
- 一、准备阶段
- 环境要求
- 软件版本要求
- 配置部署环境
- 二、部署阶段
- 部署ZooKeeper
- 安装ZooKeeper并配置环境变量
- 修改ZooKeeper配置文件
- 同步配置到其它节点
- 运行验证
- 问题
- 出现:Error contacting service. It is probably not running.
- hadoop搭建
- 安装Hadoop
- 添加hadoop至环境变量
- 修改hadoop配置文件
- (1)修改hadoop-env.sh文件
- (2)修改yarn-env.sh
- (3)修改core-site.xml
- (4)修改hdfs-site.xml文件
- (5)修改mapred-site.xml
- (6)修改yarn-site.xml
- (7)修改slaves或workers
- 同步配置到其它节点
- 启动Hadoop集群
- (1)启动ZooKeeper集群
- (2)启动JournalNode
- (3)格式化HDFS
- (4)格式化ZKFC
- (5)启动HDFS
- (6)启动Yarn
- (7)查看所有进程是否都启动
- 问题
- hdfs namenode -format出现:ERROR: namenode can only be executed by root.
- start nameNode出现错误的节点,启动的是node180,但是我是node181节点
- start-yarn.sh出现问题
- hdfs getconf -namenodes出现:ERROR conf.Configuration: error parsing conf hdfs-site.xml
- hdfs namenode -format出现问题:java.io.IOException: Cannot create directory /home/xzr/spark_mv/data/data1/hadoop/nn/current
- Starting namenodes on [node181] node181: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,p
- Starting datanodes时出现:sed: can't read : No such file or directory
- 安装参考链接
一、准备阶段
环境要求
本教程适用于CentOS 7.4即以上版本,如果是Ubuntu等其它linux内核版本则不适合。
查看系统版本:
cat /etc/redhat-release

软件版本要求
| 软件 | 版本 | 获取方法 |
|---|---|---|
| OpenJDK | 1.8.0_252 | https://github.com/AdoptOpenJDK/openjdk8-binaries/releases/download/jdk8u252-b09/OpenJDK8U-jdk_x64_linux_hotspot_8u252b09.tar.gz |
| Maven | 3.5.4 | |
| Hadoop | 3.1.1 | https://archive.apache.org/dist/hadoop/core/hadoop-3.1.1/ |
| CMake | 3.12.4 | |
| Protobuf | 2.5.0 | |
| ZooKeeper | 3.4.6 | https://archive.apache.org/dist/zookeeper/zookeeper-3.4.6/ |
| Hive | 3.1.0 | https://archive.apache.org/dist/hive/hive-3.1.0/ |
| Spark | 2.3.2 | https://archive.apache.org/dist/spark/spark-2.3.2/ |
| Scala | 2.11.12 | https://downloads.lightbend.com/scala/2.11.12/scala-2.11.12.tgz |
配置部署环境
我们规划以四台机器分别作为集群的节点1、节点2、节点3、节点4。
四台机器的IP分别为:10.214.151.181、10.214.151.186、10.214.151.187、10.214.151.188,并分别设置静态主机名为:node181、node186、node187、node188
我们把node181作为server,node186、node187、node188作为agent
(1)依次登录四台机器,设置四台机器的静态主机名
hostnamectl set-hostname 主机名 --static
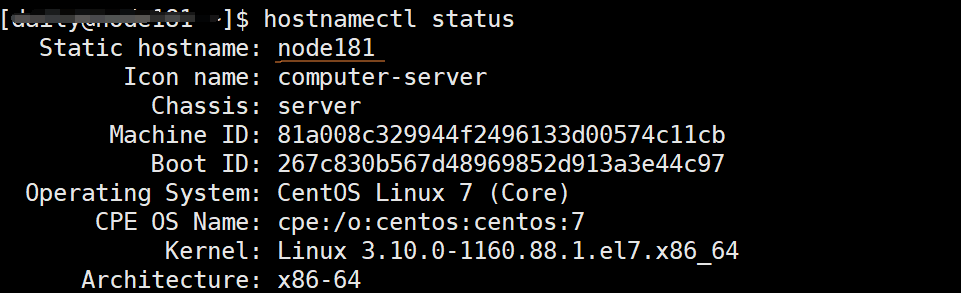
查看静态主机名,以node181为例:
hostnamectl status
(2)登录四台机器,添加集群所有机器的"地址-主机名"映射
- 打开“/etc/hosts”文件
vim /etc/hosts
- 填加如下映射内容
10.214.151.181 node181
10.214.151.186 node186
10.214.151.187 node187
10.214.151.188 node188
(3)登录四台机器,关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
(4)登录四台机器,配置SSH免密登录
- 生成SSH密钥
ssh-keygen -t rsa
2.配置SSH免密登录,自身节点的免密。注意,下列的xzr切换为自己所用的用户名。
ssh-copy-id -i ~/.ssh/id_rsa.pub xzr@节点IP
(5)登录四台机器,安装OpenJDK
-
下载并安装OpenJDK
下载; wget https://github.com/AdoptOpenJDK/openjdk8-binaries/releases/download/jdk8u252-b09/OpenJDK8U-jdk_x64_linux_hotspot_8u252b09.tar.gz 解压: tar -zxf OpenJDK8U-jdk_x64_linux_hotspot_8u252b09.tar.gz -C /home/xzr/spark_mv其中,参数
-C后是下载的路径,自行修改。 -
配置环境变量,推荐配置在各自用户下的
.bashrc文件里
vim ~/.bashrc
添加内容,路径为刚才加压的OpenJDK:
export JAVA_HOME=/home/xzr/spark_mv/jdk8u252-b09
export PATH=$JAVA_HOME/bin:$PATH
- 生效环境变量
source ~/.bashrc
- 检查OpenJDK是否安装成功。
java -version

二、部署阶段
部署ZooKeeper
安装ZooKeeper并配置环境变量
(1)登录到node186节点,下载zookeeper-3.4.6.tar.gz,并解压。
下载:
wget http://archive.apache.org/dist/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz
解压:
tar -zxvf zookeeper-3.4.6.tar.gz -C /home/xzr/spark_mv
(2)建立软链接,便于后期版本更换。
ln -s /home/xzr/spark_mv/zookeeper-3.4.6 /home/xzr/spark_mv/zookeeper
(3)添加ZooKeeper到环境变量
vim ~/.bashrc
添加如下内容:
export ZOOKEEPER_HOME=/home/xzr/spark_mv/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH
(4)生效环境变量
source ~/.bashrc
(5)在node187/node188节点重复执行,配置ZooKeeper的环境变量。
修改ZooKeeper配置文件
(1)登录node186节点,进入ZooKeeper所在目录。
cd /home/xzr/spark_mv/zookeeper/conf
(2)拷贝配置文件
cp zoo_sample.cfg zoo.cfg
(3)打开配置文件修改参数
vim /home/xzr/spark_mv/zookeeper/conf/zoo.cfg
修改数据目录:
dataDir=/home/xzr/spark_mv/zookeeper/tmp
添加如下,其中node186/node187/node188都是部署ZooKeeper的节点:
server.1=node186:2888:3888
server.2=node187:2888:3888
server.3=node188:2888:3888
(4)添加JMX配置
(1)打开文件
vim /home/xzr/spark_mv/zookeeper/bin/zkServer.sh
(2)配置JMXDISABLE,在下图位置添加
JMXDISABLE=true
(5)添加JVM配置
打开zkEnv.sh文件:
vim /home/xzr/spark_mv/zookeeper/bin/zkEnv.sh
添加如下配置至文件末尾:
# default heap for zookeeper server
ZK_SERVER_HEAP="${ZK_SERVER_HEAP:-10000}"
export SERVER_JVMFLAGS="-Xmx${ZK_SERVER_HEAP}m $SERVER_JVMFLAGS"
# default heap for zookeeper client
ZK_CLIENT_HEAP="${ZK_CLIENT_HEAP:-256}"
export CLIENT_JVMFLAGS="-Xmx${ZK_CLIENT_HEAP}m $CLIENT_JVMFLAGS"
(6)创建“tmp”目录作数据目录
mkdir /home/xzr/spark_mv/zookeeper/tmp
(7)在“tmp”目录中创建一个空文件,并向该文件写入ID
touch /home/xzr/spark_mv/zookeeper/tmp/myid
echo 1 > /home/xzr/spark_mv/zookeeper/tmp/myid
(8)配置文件权限
chmod 750 /home/xzr/spark_mv/zookeeper
find /home/xzr/spark_mv/zookeeper/bin -name "*.sh" | xargs -i chmod 500 {}
find /home/xzr/spark_mv/zookeeper/conf -name "*" -type f | xargs -i chmod 600 {}
同步配置到其它节点
(1)在node186将配置好的ZooKeeper拷贝到其它节点
scp -r /home/xzr/spark_mv/zookeeper-3.4.6 xzr@node187:/home/xzr/spark_mv
分开执行:
scp -r /home/xzr/spark_mv/zookeeper-3.4.6 xzr@node188:/home/xzr/spark_mv
(2)创建软链接并修改myid内容。
-
node187
cd /home/xzr/spark_mv ln -s zookeeper-3.4.6 zookeeper echo 2 > //home/xzr/spark_mv/zookeeper/tmp/myid -
node188
cd /home/xzr/spark_mv
ln -s zookeeper-3.4.6 zookeeper
echo 3 > /home/xzr/spark_mv/zookeeper/tmp/myid
运行验证
(1)分别在node186、node187、node188上启动ZooKeeper。
cd /home/xzr/spark_mv/zookeeper/bin
./zkServer.sh start
(2)查看ZooKeeper状态
./zkServer.sh status
使用 zkServer.sh status 命令检查 ZooKeeper 服务的状态。如果输出类似于 Mode: follower或Mode: leader 的信息,表示 ZooKeeper 服务已经在运行了。如果输出类似于 Error contacting service. It is probably not running. 的信息,则需要检查 ZooKeeper 服务是否已经启动成功。
问题
出现:Error contacting service. It is probably not running.
使用./zkServer.sh status命令时出现问题:
JMX disabled by user request
Using config: /home/xzr/spark_mv/zookeeper/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
具体看表面也看不出结果,所以我们取ZooKeeper里bin目录下的zookeeper.out查看原因:
2023-05-30 17:21:01,314 [myid:1] - WARN [WorkerSender[myid=1]:QuorumCnxManager@382] - Cannot open channel to 2 at election address node187/10.214.151.187:3888
java.net.ConnectException: Connection refused (Connection refused)
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:607)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:368)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.toSend(QuorumCnxManager.java:341)
at org.apache.zookeeper.server.quorum.FastLeaderElection$Messenger$WorkerSender.process(FastLeaderElection.java:449)
at org.apache.zookeeper.server.quorum.FastLeaderElection$Messenger$WorkerSender.run(FastLeaderElection.java:430)
at java.lang.Thread.run(Thread.java:748)
2023-05-30 17:21:01,317 [myid:1] - WARN [WorkerSender[myid=1]:QuorumCnxManager@382] - Cannot open channel to 3 at election address node188/10.214.151.188:3888
java.net.ConnectException: Connection refused (Connection refused)
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:607)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:368)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.toSend(QuorumCnxManager.java:341)
at org.apache.zookeeper.server.quorum.FastLeaderElection$Messenger$WorkerSender.process(FastLeaderElection.java:449)
at org.apache.zookeeper.server.quorum.FastLeaderElection$Messenger$WorkerSender.run(FastLeaderElection.java:430)
at java.lang.Thread.run(Thread.java:748)
从以上信息中可以看出,ZooKeeper 启动了选举算法,在尝试与其他 ZooKeeper 实例进行通信时遇到了问题,具体而言是无法连接节点 node187 和节点 node188。
解决方法:
原来我们只启动了一个节点,还需要启动其它两个节点,我们去其它两个节点启动ZooKeeper:
./zkServer.sh start
最后查看status:
./zkServer.sh status

发现启动成功!
hadoop搭建
安装Hadoop
(1)下载hadoop,https://archive.apache.org/dist/hadoop/core/hadoop-3.1.1/
(2)解压hadoop
tar -zxvf hadoop-3.1.1.tar.gz -C /home/xzr/spark_mv
(3)建立软链接,便于后期版本更换。
ln -s /home/xzr/spark_mv/hadoop-3.1.1 /home/xzr/spark_mv/hadoop
添加hadoop至环境变量
(1)打开.bashrc文件
vim ~/.bashrc
(2)添加环境变量
export HADOOP_HOME=/home/xzr/spark_mv/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
(3)使环境变量生效
source ~/.bashrc
修改hadoop配置文件
以下操作需要切换到hadoop路径下的/etc/hadoop中:
cd /home/xzr/spark_mv/hadoop/etc/hadoop
vim /home/xzr/spark_mv/hadoop/etc/hadoop/hadoop-env.sh
(1)修改hadoop-env.sh文件
注意下面的xzr替换为自己的用户名:
echo "export JAVA_HOME=/home/xzr/spark_mv/jdk8u252-b09" >> hadoop-env.sh
echo "export HDFS_NAMENODE_USER=xzr" >> hadoop-env.sh
echo "export HDFS_SECONDARYNAMENODE_USER=xzr" >> hadoop-env.sh
echo "export HDFS_DATANODE_USER=xzr" >> hadoop-env.sh
(2)修改yarn-env.sh
修改用户为当前用户xzr:
echo "export YARN_REGISTRYDNS_SECURE_USER=xzr" >> yarn-env.sh
echo "export YARN_RESOURCEMANAGER_USER=xzr" >> yarn-env.sh
echo "export YARN_NODEMANAGER_USER=xzr" >> yarn-env.sh
(3)修改core-site.xml
打开文件:
vim core-site.xml
添加或修改configuration标签范围内的参数:
<property>
<name>fs.defaultFS</name>
<value>hdfs://node181:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/xzr/spark_mv/hadoop_tmp_dir</value>
</property>
<property>
<name>ipc.client.connect.max.retries</name>
<value>100</value>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
在node181创建目录:
mkdir /home/xzr/spark_mv/hadoop_tmp_dir
(4)修改hdfs-site.xml文件
打开文件:
vim hdfs-site.xml
添加或修改configuration标签范围内的参数:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/xzr/spark_mv/data/data1/hadoop/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/xzr/spark_mv/data/data1/hadoop/dn,/home/xzr/spark_mv/data/data2/hadoop/dn,/home/xzr/spark_mv/data/data3/hadoop/dn,/home/xzr/spark_mv/data/data4/hadoop/dn,/home/xzr/spark_mv/data/data5/hadoop/dn,/home/xzr/spark_mv/data/data6/hadoop/dn,/home/xzr/spark_mv/data/data7/hadoop/dn,/home/xzr/spark_mv/data/data8/hadoop/dn,/home/xzr/spark_mv/data/data9/hadoop/dn,/home/xzr/spark_mv/data/data10/hadoop/dn,/home/xzr/spark_mv/data/data11/hadoop/dn,/home/xzr/spark_mv/data/data12/hadoop/dn</value>
</property>
<property>
<name>dfs.http.address</name>
<value>node181:50070</value>
</property>
<property>
<name>dfs.namenode.http-bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node181:9870</alue></property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node186:9870</value></property>
<property>
<name>dfs.datanode.handler.count</name>
<value>600</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>600</value>
</property>
<property>
<name>dfs.namenode.service.handler.count</name>
<value>600</value>
</property>
<property>
<name>ipc.server.handler.queue.size</name>
<value>300</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
在node186/node187/node188分别创建dfs.datanode.data.dir对应目录:
mkdir -p /home/xzr/spark_mv/data/data{1,2,3,4,5,6,7,8,9,10,11,12}/hadoop
(5)修改mapred-site.xml
打开文件:
vim mapred-site.xml
添加或修改configuration标签范围内的参数:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
<description>The runtime framework for executing MapReduce jobs</description>
</property>
<property>
<name>mapreduce.job.reduce.slowstart.completedmaps</name>
<value>0.88</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/home/xzr/spark_mv/hadoop/etc/hadoop,
/home/xzr/spark_mv/hadoop/share/hadoop/common/*,
/home/xzr/spark_mv/hadoop/share/hadoop/common/lib/*,
/home/xzr/spark_mv/hadoop/share/hadoop/hdfs/*,
/home/xzr/spark_mv/hadoop/share/hadoop/hdfs/lib/*,
/home/xzr/spark_mv/hadoop/share/hadoop/mapreduce/*,
/home/xzr/spark_mv/hadoop/share/hadoop/mapreduce/lib/*,
/home/xzr/spark_mv/hadoop/share/hadoop/yarn/*,
/home/xzr/spark_mv/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>6144</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>6144</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx5530m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2765m</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx2048m -Xms2048m</value>
</property>
<property>
<name>mapred.reduce.parallel.copies</name>
<value>20</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/xzr/spark_mv/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/xzr/spark_mv/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/xzr/spark_mv/hadoop</value>
</property>
<property>
<name>mapreduce.job.counters.max</name>
<value>1000</value>
</property>
(6)修改yarn-site.xml
打开文件:
vim yarn-site.xml
添加或修改configuration标签范围内的参数:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<final>true</final>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node181</value>
</property>
<property>
<name>yarn.resourcemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>371200</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>371200</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>64</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>64</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.client.nodemanager-connect.max-wait-ms</name>
<value>300000</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
/home/xzr/spark_mv/hadoop/etc/hadoop,
/home/xzr/spark_mv/hadoop/share/hadoop/common/*,
/home/xzr/spark_mv/hadoop/share/hadoop/common/lib/*,
/home/xzr/spark_mv/hadoop/share/hadoop/hdfs/*,
/home/xzr/spark_mv/hadoop/share/hadoop/hdfs/lib/*,
/home/xzr/spark_mv/hadoop/share/hadoop/mapreduce/*,
/home/xzr/spark_mv/hadoop/share/hadoop/mapreduce/lib/*,
/home/xzr/spark_mv/hadoop/share/hadoop/yarn/*,
/home/xzr/spark_mv/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/xzr/spark_mv/data/data1/hadoop/yarn/local,/home/xzr/spark_mv/data/data2/hadoop/yarn/local,/home/xzr/spark_mv/data/data3/hadoop/yarn/local,/home/xzr/spark_mv/data/data4/hadoop/yarn/local,/home/xzr/spark_mv/data/data5/hadoop/yarn/local,/home/xzr/spark_mv/data/data6/hadoop/yarn/local,/home/xzr/spark_mv/data/data7/hadoop/yarn/local,/home/xzr/spark_mv/data/data8/hadoop/yarn/local,/home/xzr/spark_mv/data/data9/hadoop/yarn/local,/home/xzr/spark_mv/data/data10/hadoop/yarn/local,/home/xzr/spark_mv/data/data11/hadoop/yarn/local,/home/xzr/spark_mv/data/data12/hadoop/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name><value>/home/xzr/spark_mv/data/data1/hadoop/yarn/log,/home/xzr/spark_mv/data/data2/hadoop/yarn/log,/home/xzr/spark_mv/data/data3/hadoop/yarn/log,/home/xzr/spark_mv/data/data4/hadoop/yarn/log,/home/xzr/spark_mv/data/data5/hadoop/yarn/log,/home/xzr/spark_mv/data/data6/hadoop/yarn/log,/home/xzr/spark_mv/data/data7/hadoop/yarn/log,/home/xzr/spark_mv/data/data8/hadoop/yarn/log,/home/xzr/spark_mv/data/data9/hadoop/yarn/log,/home/xzr/spark_mv/data/data10/hadoop/yarn/log,/home/xzr/spark_mv/data/data11/hadoop/yarn/log,/home/xzr/spark_mv/data/data12/hadoop/yarn/log</value>
</property>
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.hostname</name>
<value>node181</value>
</property>
<property>
<name>yarn.timeline-service.http-cross-origin.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.system-metrics-publisher.enabled</name>
<value>true</value>
</property>
节点node186、node187、node188分别创建yarn.nodemanager.local-dirs对应目录:
mkdir -p /home/xzr/spark_mv/data/data{1,2,3,4,5,6,7,8,9,10,11,12}/hadoop/yarn
(7)修改slaves或workers
打开文件:
vim workers
修改workers文件,只保存所有agent节点的IP地址(可用主机名代替),其余内容均删除:
node186
node187
node188
同步配置到其它节点
(1)node181节点创建“journaldata”目录。
mkdir -p /home/xzr/spark_mv/hadoop-3.1.1/journaldata
(2)拷贝hadoop-3.1.1到node186、node187、node188节点:
scp -r /home/xzr/spark_mv/hadoop-3.1.1 xzr@node186:/home/xzr/spark_mv
scp -r /home/xzr/spark_mv/hadoop-3.1.1 xzr@node187:/home/xzr/spark_mv
scp -r /home/xzr/spark_mv/hadoop-3.1.1 xzr@node188:/home/xzr/spark_mv
(3)分别登录到node186、node187、node188节点,为hadoop-3.1.1建立软链接:
ln -s /home/xzr/spark_mv/hadoop-3.1.1 /home/xzr/spark_mv/hadoop
启动Hadoop集群
注意:
只在第一次进行格式化操作时,需要执行2-4,完成格式化后,下次启动集群,只需要执行1、5、6。
(1)启动ZooKeeper集群
分别在node186、node187、node188上启动Zookeeper:
cd /home/xzr/spark_mv/zookeeper/bin
./zkServer.sh start
查看是否启动成功:
jps | grep Quor

上图说明启动成功!
(2)启动JournalNode
分别在node186、node187、node188节点上启动JournalNode。
cd /home/xzr/spark_mv/hadoop/sbin
./hadoop-daemon.sh start journalnode

看到JournalNode说明开启成功!
(3)格式化HDFS
在node181节点上格式化HDFS
hdfs namenode -format
格式化后集群会根据core-site.xml配置的hadoop.tmp.dir参数生成目录
(4)格式化ZKFC
在node181节点上格式化ZKFC。
hdfs zkfc -formatZK
(5)启动HDFS
在node181节点上启动HDFS。
cd /home/xzr/spark_mv/hadoop/sbin
./start-dfs.sh
(6)启动Yarn
在server1节点上启动Yarn
cd /home/xzr/spark_mv/hadoop/sbin
./start-yarn.sh
(7)查看所有进程是否都启动
jps
问题
hdfs namenode -format出现:ERROR: namenode can only be executed by root.
从字面意思是需要切换到root用户去启动,但是如果没有root用户权限呢?
(1)检查hadoop-env.sh文件,发现以下参数:
export JAVA_HOME=/home/xzr/spark_mv/jdk8u252-b09
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_DATANODE_USER=root
实际上,将他们修改为当前用户即可:
export JAVA_HOME=/home/xzr/spark_mv/jdk8u252-b09
export HDFS_NAMENODE_USER=xzr
export HDFS_SECONDARYNAMENODE_USER=xzr
export HDFS_DATANODE_USER=xzr
或者直接切换root用户然后再启动其它操作。
但是发现还是无法启动?
(2)那么依然时配置文件的问题,仔细检查后发现,core-site.xml文件需要修改:
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
如果配置了上述选项,修改proxyuser为当前用户即可:
<property>
<name>hadoop.proxyuser.xzr.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.xzr.groups</name>
<value>*</value>
</property>
(3)如果上述仍然无法修改,那么很有可能是你配置的hadoop并不是你当前使用的hadoop,也就是说有另一个hadoop影响了你目前的使用。
具体方案可以参考下列文章:
检查HADOOP_HOME的配置,因为全局配置是高于用户配置的,所以你可能在操作别人的hadoop,而别人的hadoop是放在root权限下的文件夹里的,那么肯定就无法用当前用户操作。
start nameNode出现错误的节点,启动的是node180,但是我是node181节点
启动hdfs时,发现启动的是node180,但是配置的是node181:
root@node181 sbin]# ./start-dfs.sh
Starting namenodes on [node180]
Last login: Wed May 31 15:00:25 CST 2023 on pts/2
node180: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
Starting datanodes
Last login: Wed May 31 15:10:19 CST 2023 on pts/2
node180: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
node182: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
Starting secondary namenodes [node181]
Last login: Wed May 31 15:10:20 CST 2023 on pts/2
查看namenodes启动时的节点:
hdfs getconf -namenodes
发现时node180:

(1)检查HADOOP_HOME:
echo $HADOOP_HOME

发现不是我配置的路径。
这时候我发现我在root用户下,但是我是在xzr下配置路径的。
修改对应的配置,但是发现仍然不对。
(2)检查全局设置
即使这时候修改回来,但是如果在全局文件里设置了参数,以全局为主。
- 检查
/etc/profile文件:
看看是否配置了$HADOOP_HOME
发现并无配置
- 检查
/etc/profile.d/目录下的所有文件:
cd /etc/profile.d
使用正则匹配:
grep -r "HADOOP"

发现确实在custom_env.sh文件里配置了,将其删除即可。

start-yarn.sh出现问题
[root@node181 sbin]# ./start-yarn.sh
Starting resourcemanager
Last login: Wed May 31 15:10:24 CST 2023 on pts/2
Starting nodemanagers
Last login: Wed May 31 15:52:09 CST 2023 on pts/2
node180: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
node182: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
hdfs getconf -namenodes出现:ERROR conf.Configuration: error parsing conf hdfs-site.xml
ERROR conf.Configuration: error parsing conf hdfs-site.xml
com.ctc.wstx.exc.WstxParsingException: Unexpected close tag </alue>; expected </value>.
at [row,col,system-id]: [42,29,"file:/home/xzr/spark_mv/hadoop-3.1.1/etc/hadoop/hdfs-site.xml"]
去检查hdfs-site.xml文件42行:
<property>
<name>dfs.namenode.http-address</name>
<value>node181:9870</alue></property>
<property>
将其删除即可,这部分配置是有问题的。
当然,按照实际情况配置即可。
hdfs namenode -format出现问题:java.io.IOException: Cannot create directory /home/xzr/spark_mv/data/data1/hadoop/nn/current
java.io.IOException: Cannot create directory /home/xzr/spark_mv/data/data1/hadoop/nn/current
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.clearDirectory(Storage.java:436)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:579)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:601)
at org.apache.hadoop.hdfs.server.namenode.FSImage.format(FSImage.java:173)
at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:1159)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1600)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1710)
2023-06-01 16:11:12,472 ERROR namenode.NameNode: Failed to start namenode.
java.io.IOException: Cannot create directory /home/xzr/spark_mv/data/data1/hadoop/nn/current
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.clearDirectory(Storage.java:436)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:579)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:601)
at org.apache.hadoop.hdfs.server.namenode.FSImage.format(FSImage.java:173)
at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:1159)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1600)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1710)
无法创建文件,可能是原来文件已经存在,将原来文件删除即可。
Starting namenodes on [node181] node181: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,p
这个问题的出现主要是因为没有给authorized_keys授权,解决方法如下:
把产生的公钥文件放置到authorized_keys文件中,命令如下:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
Starting datanodes时出现:sed: can’t read : No such file or directory
解决方案1:https://www.javazxz.com/thread-6588-1-1.html
hadoop namenode -format时,会出现个询问,如下图,此处如果选择Y,则/tmp/dfs下name夹子会更新,进而version文件中的clusterID会发生变化,导致data文件的clusterID与name的clusterID不同,此时则无法正常启动datanode,所以提醒大家记得选N,避免不必要的麻烦。
结果:无效
安装参考链接
- 华为鲲鹏搭建spark文档