目录
0. 相关文章链接
1. ShuffleMapStage与ResultStage
2. HashShuffle解析
2.1. 未优化的HashShuffle
2.2. 优化后的 HashShuffle
3. SortShuffle解析
3.1. 普通SortShuffle
3.2. bypass SortShuffle
0. 相关文章链接
Spark文章汇总
1. ShuffleMapStage与ResultStage
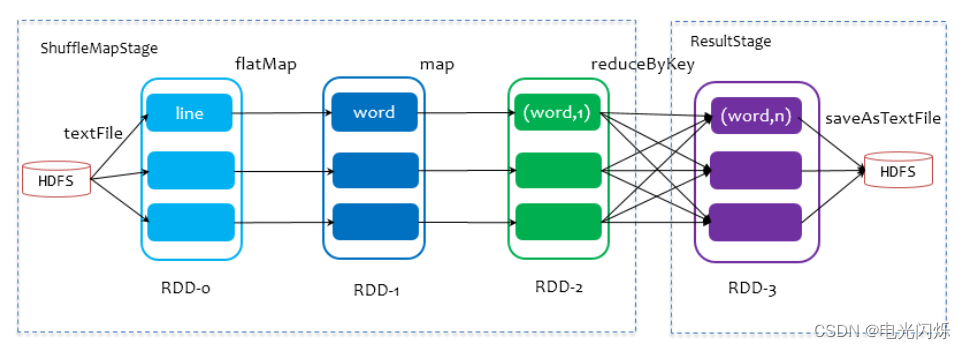
在划分 stage 时,最后一个 stage 称为 finalStage,它本质上是一个 ResultStage 对象,前面的所有 stage 被称为 ShuffleMapStage。
- ShuffleMapStage 的结束伴随着 shuffle 文件的写磁盘
- ResultStage 基本上对应代码中的 action 算子,即将一个函数应用在 RDD 的各个 partition的数据集上,意味着一个 job 的运行结束
2. HashShuffle解析
2.1. 未优化的HashShuffle
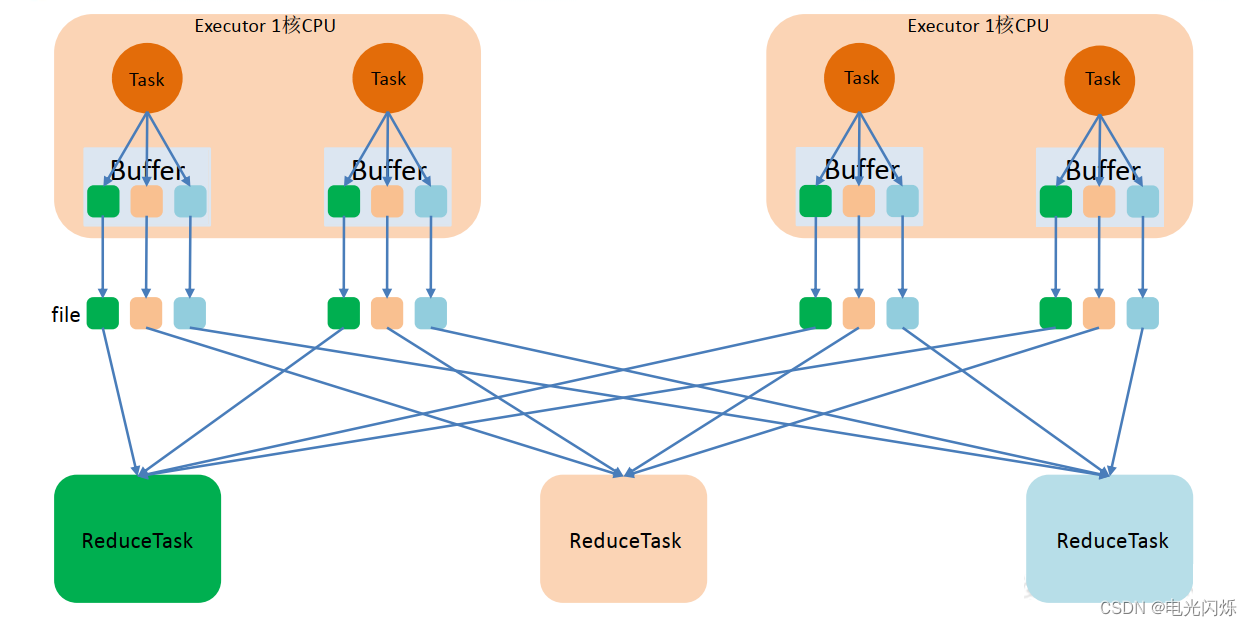
这里我们先明确一个假设前提:每个 Executor 只有 1 个 CPU core,也就是说,无论这个 Executor 上分配多少个 task 线程,同一时间都只能执行一个 task 线程。如下图中有3个Reducer,从 Task 开始那边各自把自己进行 Hash 计算(分区器: hash/numreduce 取模),分类出 3 个不同的类别,每个 Task 都分成 3 种类别的数据,想把不同的数据汇聚然后计算出最终的结果,所以 Reducer 会在每个 Task 中把属于自己类别的数据收集过来,汇聚成一个同类别的大集合,每 1 个 Task 输出 3 份本地文件,这里有 4 个 Mapper Tasks,所以总共输出了 4 个 Tasks x 3 个分类文件 = 12 个本地小文件。
2.2. 优化后的 HashShuffle
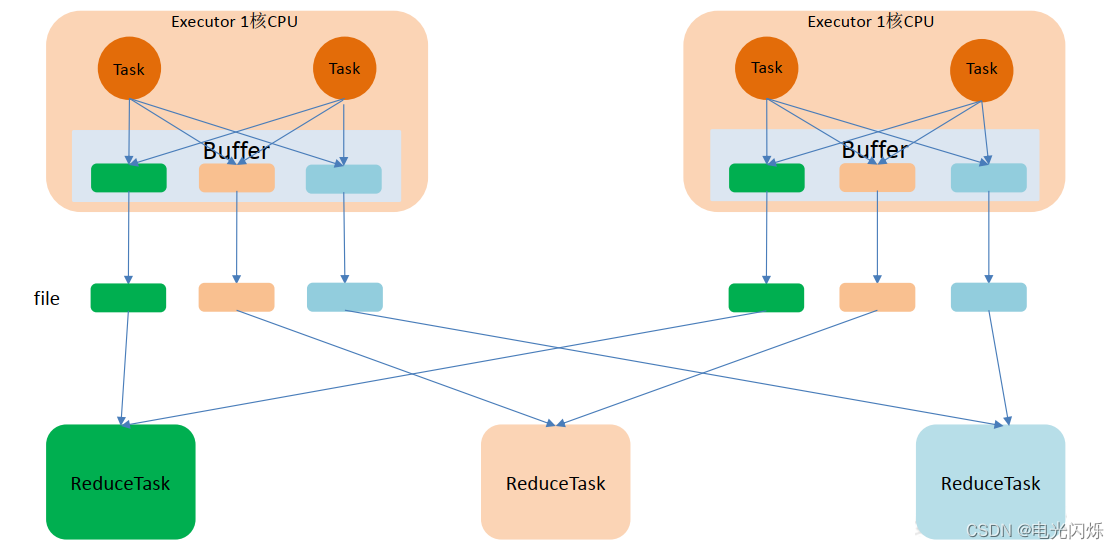
优化的 HashShuffle 过程就是启用合并机制,合并机制就是复用 buffer,开启合并机制的配置是 spark.shuffle.consolidateFiles。该参数默认值为 false,将其设置为 true 即可开启优化机制。通常来说,如果我们使用 HashShuffleManager,那么都建议开启这个选项。
这里还是有 4 个 Tasks,数据类别还是分成 3 种类型,因为 Hash 算法会根据你的 Key进行分类,在同一个进程中,无论是有多少过 Task,都会把同样的 Key 放在同一个 Buffer 里,然后把 Buffer 中的数据写入以 Core 数量为单位的本地文件中,(一个 Core 只有一种类型的 Key 的数据),每 1 个 Task 所在的进程中,分别写入共同进程中的 3 份本地文件,这里有 4 个 Mapper Tasks,所以总共输出是 2 个 Cores x 3 个分类文件 = 6 个本地小文件。
3. SortShuffle解析
3.1. 普通SortShuffle
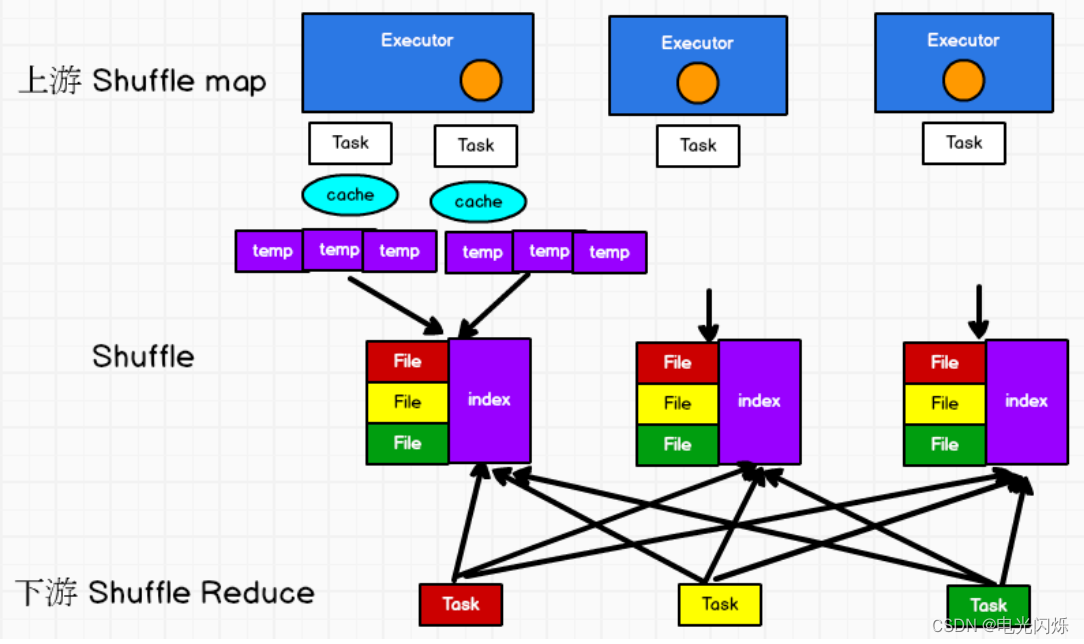
在该模式下,数据会先写入一个数据结构,reduceByKey 写入 Map,一边通过 Map 局部聚合,一遍写入内存。Join 算子写入 ArrayList 直接写入内存中。然后需要判断是否达到阈值,如果达到就会将内存数据结构的数据写入到磁盘,清空内存数据结构。
在溢写磁盘前,先根据 key 进行排序,排序过后的数据,会分批写入到磁盘文件中。默认批次为 10000 条,数据会以每批一万条写入到磁盘文件。写入磁盘文件通过缓冲区溢写的方式,每次溢写都会产生一个磁盘文件,也就是说一个 Task 过程会产生多个临时文件。
最后在每个 Task 中,将所有的临时文件合并,这就是 merge 过程,此过程将所有临时文件读取出来,一次写入到最终文件。意味着一个 Task 的所有数据都在这一个文件中。同时单独写一份索引文件,标识下游各个Task的数据在文件中的索引,start offset和end offset。
3.2. bypass SortShuffle
bypass 运行机制的触发条件如下:
- shuffle reduce task 数量小于等于 spark.shuffle.sort.bypassMergeThreshold 参数的值,默认为 200。
- 不是聚合类的 shuffle 算子(比如 reduceByKey)。
此时 task 会为每个 reduce 端的 task 都创建一个临时磁盘文件,并将数据按 key 进行 hash 然后根据 key 的 hash 值,将 key 写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的 HashShuffleManager 是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的 HashShuffleManager 来说,shuffle read 的性能会更好。
而该机制与普通 SortShuffleManager 运行机制的不同在于:不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write 过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
注:其他Spark相关系列文章链接由此进 -> Spark文章汇总