最近刚刚完成了HBase相关的一个项目,作为项目的技术负责人,完成了大部分的项目部署,特性调研工作,以此系列文章作为上一阶段工作的总结.
前言
其实目前就大多数做应用的情况来讲,我们并不需要去自己搭建一套HBase的集群,现有的很多云厂商提供的服务已经极大的方便日常的应用使用,不必像多年前一样刀耕火种似得从头开始部署这些底层的组件,大多数时候只需要开箱即用,遇到对应的问题时再去处理相关的问题即可.如果是本地开发呢,我们可以快速的使用docker去启动一个HBase,也能满足日常开发的需求.
但是对于该项目,需要对HBase的内核及实现原理进行调研梳理,就不得不从0搭建一个可以作为特性调研的集群.
搭建步骤
由于HBase依赖了HDFS,所以我们需要先搭建HDFS集群
搭建HDFS
参考文档:
搭建HDFS集群: Apache Hadoop 3.3.6 – Hadoop Cluster Setup
搭建HDFS HA集群: Apache Hadoop 3.3.6 – HDFS High Availability
节点规划
因为在大数据系统中,每台机器中搭建的组件比较多,搭建集群之前,需要做好节点规划的记录,防止忘记每个节点需要部署什么组件
| 节点 | 部署 |
| 172.36.176.238 | namenode datanode |
| 172.36.176.239 | datanode |
这里使用了两台机器,hdfs使用了两个datanode,因为我们主要想对hbase进行调试,所以能够实现HBase访问多个datanode的特性即可,如果是生产环境搭建的话,还需要搭建secordaryNamenode.
安装java
大数据组件集成的时候,由于组件众多,需要提起了解不同组件之间的兼容性问题,兼容性会出现在当前组件的文档,或源代码中,例如hadoop有针对jdk的兼容性文档,hbase会有针对hadoop和jdk的兼容性文档,后边文章中集成phoenix会有phoenix对于HBase的兼容性文档.
由于hadoop3.2版本只能支持1.8版本的java,所以我们需要先安装jdk.
根据机器CPU架构不同,可能需要使用不同的架构的安装包,如示例中使用的是arm架构的CPU,所以需要使用对应的版本.
在安装的过程中,因为步骤繁多,我们需要保证每一步都可验证,避免其他人按照步骤完成之后发现系统不能正常使用,增大排错难度.
# 不同的linux发行版对应的命令不同
yum install -y java-1.8.0-openjdk-devel.aarch64
which java
java -version

获取HDFS安装包
在Hadoop官网下载3.2.0版本的hadoop安装包
将hadoop安装包复制到/opt目录下
scp ./hadoop-3.2.0.tar.gz root@172.36.176.238:/opt解压Hadoop安装包到当前目录
tar -xvf hadoop-3.2.0.tar.gz修改集群host
在两个节点分别执行写入hosts的操作,
在自己的电脑上配置VPN使用的IP,在主机上配置内网ip,配置错误hdfs将无法启动
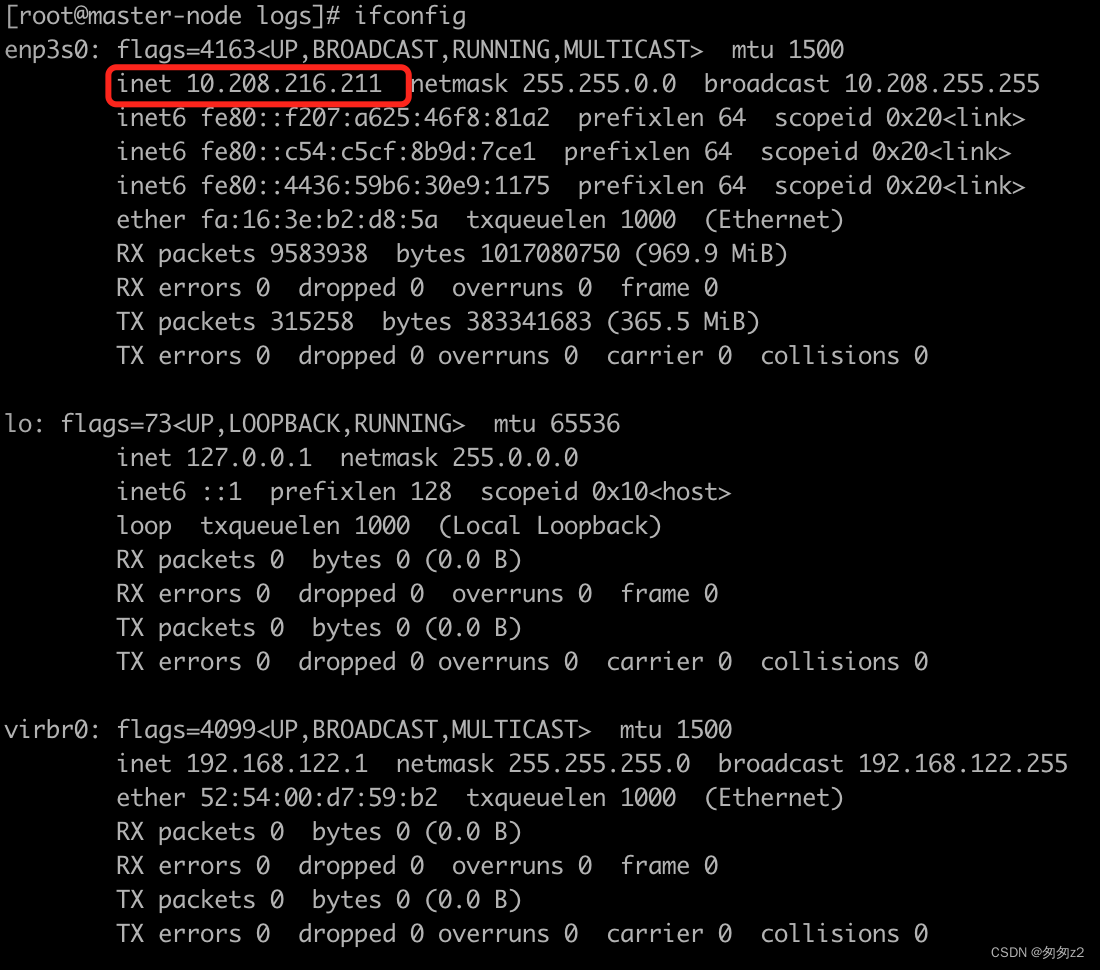
内网ip查看方式
使用ifconfig命令
echo "10.208.216.211 master-node
10.208.5.224 salve-node1 " >> /etc/hosts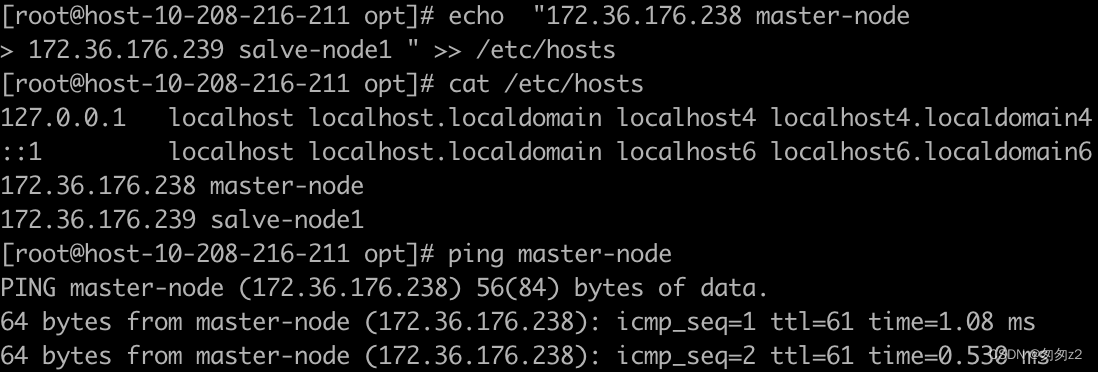
修改hostname
在172.36.176.238节点执行
hostnamectl set-hostname master-node
在172.36.176.239节点执行
hostnamectl set-hostname salve-node1

重新ssh登录之后hostname已经修改
配置免密登录
生成rsa公钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
添加环境变量
echo "export HADOOP_HOME=/opt/hadoop-3.2.0" >> ~/.bash_profile
echo "export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.272.b10-7.oe1.aarch64" >> ~/.bash_profile
source ~/.bash_profile扩展PATH目录
echo "export PATH=${HADOOP_HOME}/bin:\$PATH" >> ~/.bash_profile
echo "export PATH=${HADOOP_HOME}/sbin:\$PATH" >> ~/.bash_profile
source ~/.bash_profile
创建HDFS数据目录
mkdir -p /data/hadoop
配置core-site.xml
修改${HADOOP_HOME}/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://$${HOSTNAME}:9000value>
property> <property> <name>hadoop.tmp.dirname> <value>/data/hadoopvalue> property> configuration> 初始化namenode
hdfs namenode -format启动namenode
hdfs --daemon start namenode
使用jps命令验证是否启动成功

如果出现错误,根据$HADOOP_HOME/logs 目录下的日志进行排查

使用netstat命令能够发现监听的端口
netstat -ltnp |grep java启动master节点上的datanode
hdfs --daemon start datanode

至此, master node启动成功
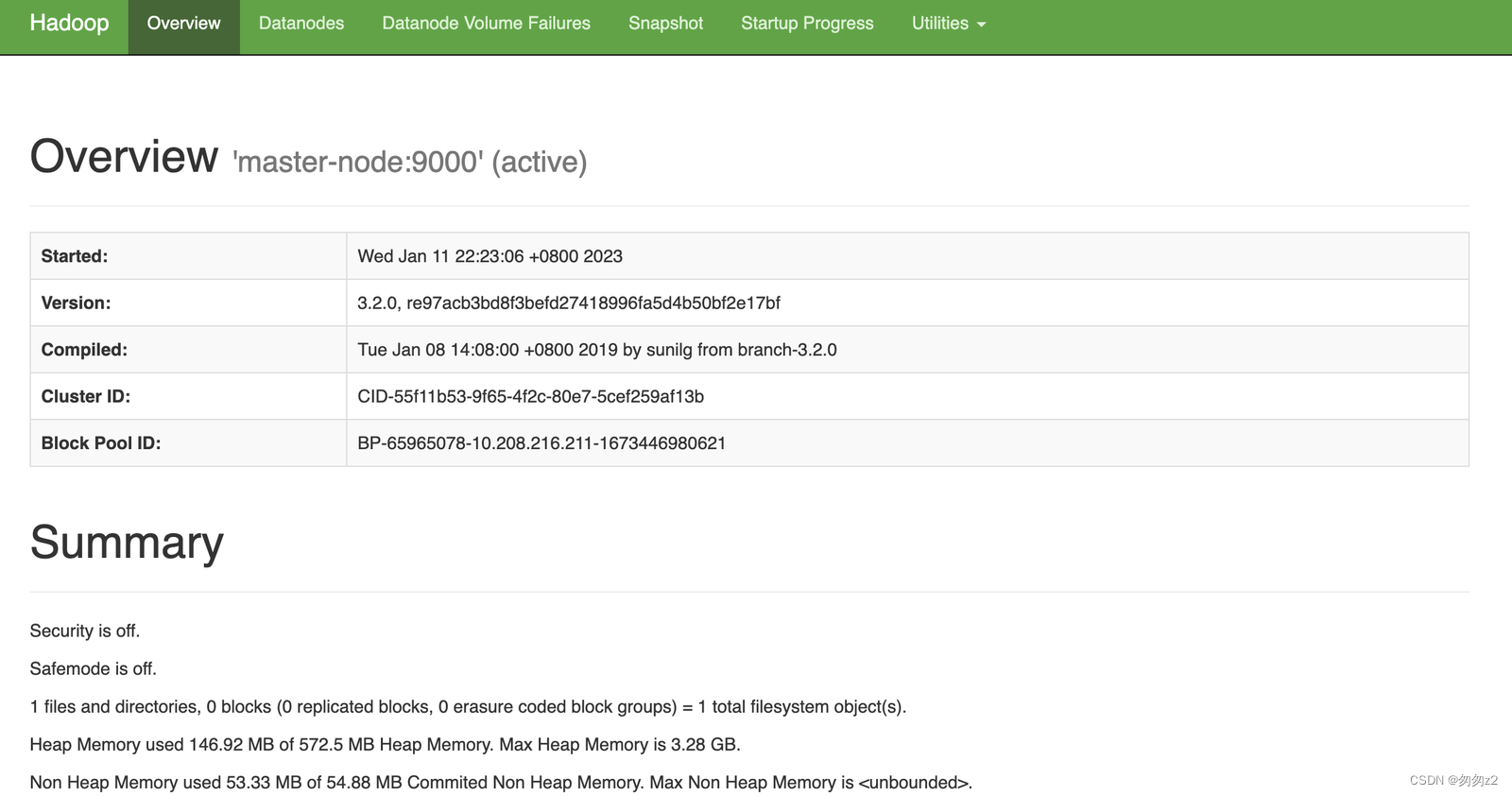
访问HDFS页面
需要关闭防火墙(不同的linux发行版对应的命令可能不同)
# 检查防火墙状态
systemctl status firewalld
# 停止防火墙
systemctl stop firewalld
# 永久关闭防火墙
systemctl disable firewalld.service修改selinux 文件
vim /etc/selinux/config
修改为: SELINUX=disabled
本机访问: http://master-node:9870/
搭建其他datanode
重复 <安装java> 到 <配置core-site.xml> 之间的所有步骤在datanode上
跳过启动namenode的步骤
启动完成datanode之后
使用jps查看进程
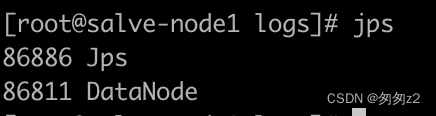
验证多节点datanode搭建成功
http://master-node:9870/dfshealth.html#tab-datanode
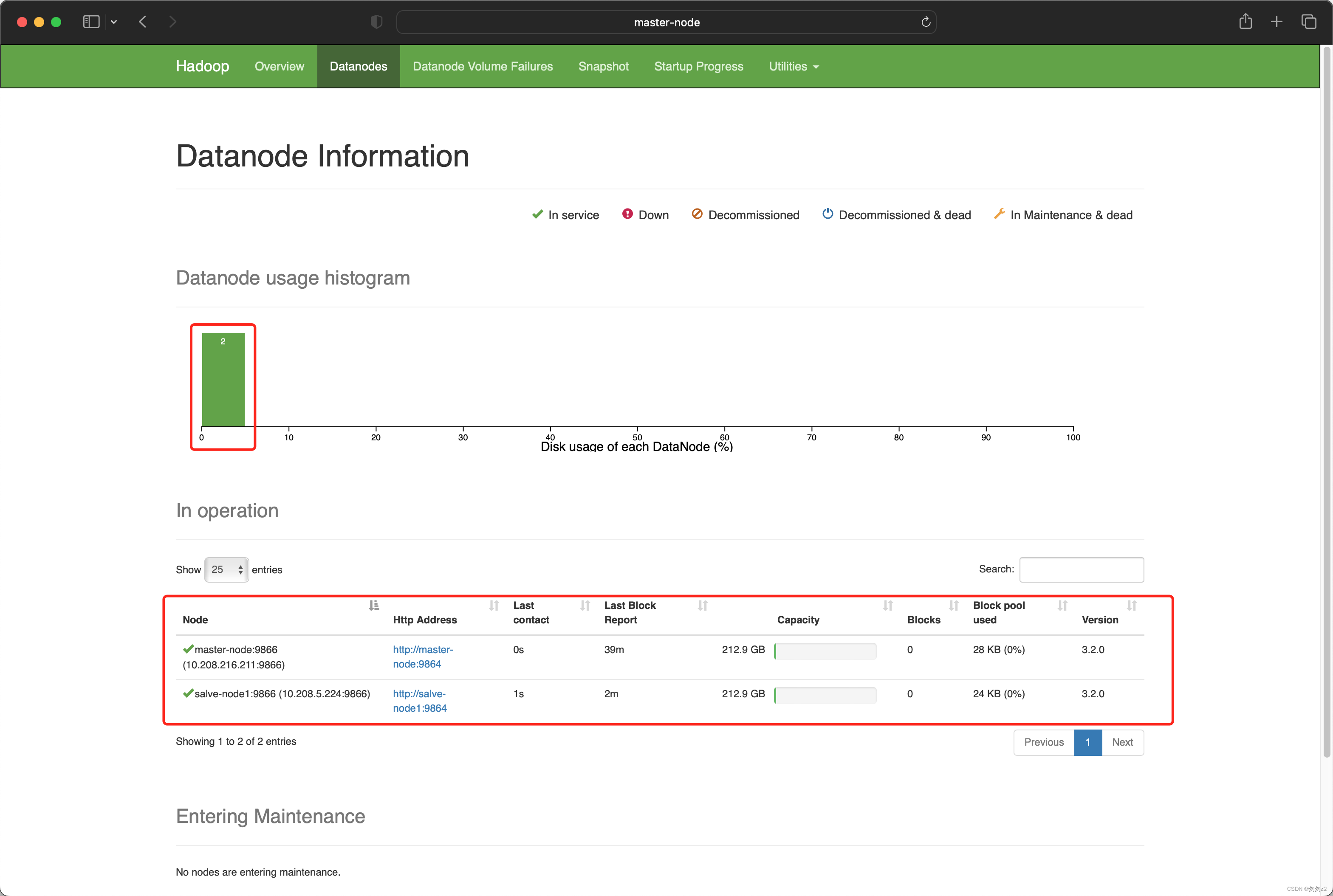
至此,可以看到一个namenode,两个datanode的HDFS集群已经搭建起来了.
搭建高可用HBase
集群规划
| 节点 | 原有部署 | 新增部署 |
| 172.36.176.238 | namenode datanode | RegionServer |
| 172.36.176.239 | datanode | HMaster RegionServer zookeeper |
参考文档
官方文档: Apache HBase ™ Reference Guide
下载HBase源码
下载地址:Index of /dist/hbase/2.2.3
这里需要额外注意,直接下载的源码包编译出来的代码会出现HRegionServer启动报错问题, 需要使用github的hbase代码仓库进行编译
git clone git@github.com:apache/hbase.git
git checkout 2.2.3
# 使用2.2.3分支编译的代码是可以正常部署的本地编译HBase源码为Hadoop指定版本
● 不使用本地编译的版本会导致HBase在服务端启动时报错.
● 由于HBase需要使用指定的hadoop版本,所以需要使用指定的hadoop版本编译
● 本地编译需要使用java 8,不能使用8以上的jdk,会报 package javax.annotation does not exist 错误
mvn -DskipTests clean install && mvn -Dhadoop.profile=3.0 -Dhadoop-three.version=3.2.0 -DskipTests package assembly:single由于本地编译需要下载大量依赖及配置,这里直接放一个编译好的网盘文件
直接下载地址:
链接: https://pan.baidu.com/s/1QKpw11HV7oA_0KJ7335gfA 提取码: 3qfi
获取HBase安装包
将HBase安装包copy到/opt目录下
scp ./hbase-2.2.3-bin.tar.gz root@172.36.176.238:/opt
*从本地上传到服务端之后,服务端之间使用scp使用的内网带宽会更快解压HBase安装包
cd /opt && tar -xvf hbase-2.2.3-bin.tar.gz添加环境变量及修改PATH
echo "export HBASE_HOME=/opt/hbase-2.2.3" >> ~/.bash_profile
source ~/.bash_profile
echo "export PATH=${HBASE_HOME}/bin:\$PATH" >> ~/.bash_profile
source ~/.bash_profile修改hbase-env.sh
此处不能省略,ssh远程执行命令会导致之前写入~/.bash_profile失效
echo "export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.272.b10-7.oe1.aarch64" >> ${HBASE_HOME}/conf/hbase-env.sh
创建zookeeper存储目录
mkdir -p /data/zookeeper添加HBASE配置
在${HBASE_HOME}/conf/hbase-site.xml <configuration>中添加以下内容
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master-node:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>salve-node1:2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/data/zookeeper</value>
</property>
修改regionservers
vim ${HBASE_HOME}/conf/regionservers
# 修改regionservers
master-node
salve-node1
部署其他节点
执行<解压HBase安装包> 到 <创建zookeeper存储目录>的所有步骤
MASTER节点启动
由于之前已经配置了远程登录,并且配置了regionservers所在的服务器,只需要在master节点执行start,即可启动其他机器上对应的节点
start-hbase.sh使用hbase quick start中的hbase shell验证部署成功
Apache HBase ™ Reference Guide
执行quick中的命令,都可以正常执行,即为安装成功.