0.摘要
目前用于语义分割的先进模型是基于最初设计用于图像分类的卷积网络的改进。然而,像语义分割这样的密集预测问题在结构上与图像分类不同。在这项工作中,我们开发了一个专门为密集预测设计的新的卷积网络模块。所提出的模块使用膨胀卷积来系统地聚合多尺度的上下文信息,而不会丢失分辨率。该架构基于膨胀卷积支持对感受野的指数级扩展,同时不会丢失分辨率或覆盖范围。我们证明了所提出的上下文模块可以提高最先进的语义分割系统的准确性。此外,我们还研究了将图像分类网络适应到密集预测的方法,并证明简化适应网络可以提高准确性。
1.引言
计算机视觉中许多自然问题都是密集预测的实例。其目标是为图像中的每个像素计算一个离散或连续的标签。一个著名的例子是语义分割,它需要将每个像素分类到给定的一组类别中(He et al., 2004; Shotton et al., 2009; Kohli et al., 2009; Krahenbühl & Koltun, 2011)。语义分割具有挑战性,因为它要求在像素级准确性和多尺度上下文推理之间进行组合(He et al., 2004; Galleguillos & Belongie, 2010)。最近通过使用卷积网络(LeCun et al., 1989)通过反向传播(Rumelhart et al., 1986)进行训练,在语义分割中取得了显著的准确性提升。具体而言,Long等人(2015)表明,最初为图像分类开发的卷积网络架构可以成功地重新用于密集预测。这些重新用途的网络在具有挑战性的语义分割基准测试中明显优于先前的最先进方法。这引发了一些新的问题,这些问题受到图像分类和密集预测之间结构差异的启发。在重新用途的网络中,哪些方面是真正必要的,哪些在密集操作时会降低准确性?专门为密集预测设计的专用模块能否进一步提高准确性?
现代图像分类网络通过连续的池化和子采样层集成多尺度的上下文信息,以降低分辨率直到获得全局预测(Krizhevsky et al., 2012; Simonyan & Zisserman, 2015)。相比之下,密集预测需要将多尺度的上下文推理与全分辨率输出相结合。最近的研究工作探讨了两种处理多尺度推理和全分辨率密集预测冲突要求的方法。
一种方法涉及重复的上卷积,旨在恢复丢失的分辨率,并将来自下采样层的全局视角保留下来(Noh et al., 2015; Fischer et al., 2015)。这引发了一个问题,即是否真正需要进行严重的中间降采样。
另一种方法涉及将图像的多个尺度版本作为网络的输入,并组合这些多个输入获得的预测(Farabet et al., 2013; Lin et al., 2015; Chen et al., 2015b)。同样,目前尚不清楚是否真正需要对调整尺度的输入图像进行单独分析。
在这项工作中,我们开发了一个卷积网络模块,可以在不失去分辨率或分析调整尺度图像的情况下聚合多尺度的上下文信息。该模块可以插入到任何分辨率的现有架构中。与从图像分类中继承的金字塔形架构不同,所提出的上下文模块专门设计用于密集预测。它是一个由卷积层组成的长方体,没有池化或子采样。该模块基于扩张卷积,可以支持感受野的指数级扩展,而不会丢失分辨率或覆盖范围。作为这项工作的一部分,我们还重新检查了重新用途的图像分类网络在语义分割上的性能。核心预测模块的性能可能会被越来越复杂的系统所混淆,这些系统涉及结构化预测、多列架构、多个训练数据集和其他增强技术。因此,我们在受控环境中研究了深度图像分类网络的主要改进,并移除阻碍密集预测性能的残留组件。结果是一个简化的初始预测模块,比先前的改进方法更简单和更准确。使用简化的预测模块,我们通过对Pascal VOC 2012数据集(Everingham et al.,2010)进行受控实验来评估所提出的上下文网络。实验证明,将上下文模块插入现有的语义分割架构中可可靠地提高其准确性。
2.扩张卷积
设F: Z2 → R是一个离散函数。设Ωr = [−r;r]2 \ Z2,k: Ωr → R是一个大小为(2r + 1)2的离散滤波器。离散卷积运算符∗可以定义为(F ∗k)(p) = Σs+t=p F(s)k(t)。(1) 现在我们推广这个运算符。设l是一个扩张因子,定义∗l为(F ∗l k)(p) = Σs+lt=p F(s)k(t)。(2) 我们将∗l称为扩张卷积或l-扩张卷积。过去,扩张卷积运算符被称为“使用扩张滤波器的卷积”。它在小波分解的algorithme a trous`中扮演着关键的角色(Holschneider et al., 1987; Shensa, 1992)。我们使用术语“扩张卷积”而不是“使用扩张滤波器的卷积”,以澄清没有“构造或表示扩张滤波器”的意思。卷积运算符本身被修改为以不同的方式使用滤波器参数。扩张卷积运算符可以使用不同的扩张因子在不同的范围内应用相同的滤波器。我们的定义反映了扩张卷积运算符的正确实现方式,它不涉及构造扩张滤波器。在最近关于语义分割的卷积网络的研究中,Long等人(2015)分析了滤波器的扩张,但选择不使用它。Chen等人(2015a)使用扩张来简化Long等人(2015)的架构。相比之下,我们开发了一个新的卷积网络架构,系统地使用扩张卷积来进行多尺度上下文聚合。
我们的架构受到一个事实的启发,即扩张卷积支持指数级扩展的感受野,而不会丢失分辨率或覆盖范围。设F0;F1;:::;Fn−1: Z2 → R是离散函数,k0;k1;:::;kn−2: Ω1 → R是离散的3×3滤波器。考虑以指数级增加的扩张率应用这些滤波器:Fi+1 = Fi ∗2i ki,其中i =0;1;:::;n−2。(3)将Fi+1中元素p的感受野定义为改变Fi+1(p)值的F0中的元素集合。定义Fi+1中元素p的感受野大小为这些元素的数量。很容易看出,Fi+1中每个元素的感受野大小为(2i+2 −1)×(2i+2 −1)。感受野是一个指数级增加大小的正方形。如图1所示。

图1:系统化扩张支持感受野的指数级扩展,而不会丢失分辨率或覆盖范围。
(a)通过1倍扩张卷积将F0生成F1;F1中的每个元素具有3×3的感受野。
(b)通过2倍扩张卷积将F1生成F2;F2中的每个元素具有7×7的感受野。
(c)通过4倍扩张卷积将F2生成F3;F3中的每个元素具有15×15的感受野。
每个层的参数数量是相同的。感受野呈指数级增长,而参数数量呈线性增长。
3.多尺度上下文聚合
上下文模块的设计旨在通过聚合多尺度的上下文信息来增加稠密预测架构的性能。该模块以C个特征图作为输入,并产生C个特征图作为输出。输入和输出具有相同的形式,因此该模块可以插入现有的稠密预测架构中。我们首先描述上下文模块的基本形式。在这个基本形式中,每个层具有C个通道。每个层中的表示是相同的,可以直接用于获得密集的每类预测,尽管特征图没有被归一化,并且模块内部没有定义损失。直观地说,该模块可以通过将特征图传递给暴露上下文信息的多个层来提高特征图的准确性。
基本的上下文模块具有7个层,其中使用不同的扩张因子进行3×3的卷积操作。这些扩张因子分别为1,1,2,4,8,16和1。每个卷积操作作用于所有的层:严格来说,这些是在前两个维度上有扩张的3×3×C卷积操作。每个卷积操作之后都跟随一个点对点的截断max(·;0)。最后一层执行1×1×C的卷积操作,并产生模块的输出。该结构在表1中进行了总结。需要注意的是,在我们的实验中,提供输入给上下文网络的前端模块在64×64的分辨率下产生特征图。因此,在第6层之后,我们停止了感受野的指数扩张。最初的尝试训练上下文模块未能提高预测准确性。实验证明,标准的初始化过程不容易支持模块的训练。卷积网络通常是使用从随机分布中采样的样本进行初始化的(Glorot & Bengio,2010; Krizhevsky et al.,2012; Simonyan & Zisserman,2015)。然而,我们发现随机初始化方案对于上下文模块并不有效。我们发现使用具有明确语义的替代初始化方法更加有效:

其中,a是输入特征图的索引,b是输出特征图的索引。这是一种身份初始化的形式,最近在循环网络中得到了提倡(Le et al.,2015)。这种初始化将所有的滤波器设置为每个层将输入直接传递给下一层的方式。一个自然的担忧是这种初始化可能使网络处于一个状态,使得反向传播不能显着改善简单地通过传递信息的默认行为。然而,实验证明这并不是事实。反向传播可靠地利用网络提供的上下文信息,提高处理后的特征图的准确性。
这完成了对基本上下文网络的介绍。我们的实验表明,即使是这个基本模块也可以在定量和定性上提高密集预测的准确性。考虑到网络中的参数数量很少(总共≈64C2个参数),这一点尤为显著。我们还训练了一个更大的上下文网络,在更深层中使用了更多的特征图。大网络中的特征图数量在表1中进行了总结。我们将初始化方案推广到适应不同层中特征图数量的差异。设ci和ci+1是两个连续层中的特征图数量。假设C同时整除ci和ci+1。初始化方法如下所示:

这里的“∼N(0;σ2)”表示从均值为0、方差为σ2的正态分布中采样,其中σ=C=ci+1。随机噪声的使用打破了具有共同前任的特征图之间的平局。
表1:上下文网络架构。该网络通过在逐渐增加的尺度上聚合上下文信息来处理C个特征图,同时不丢失分辨率。

4.前端模块
我们实现并训练了一个前端预测模块,它以彩色图像作为输入,并生成C = 21个特征图作为输出。前端模块遵循了Long等人(2015)和Chen等人(2015a)的工作,但是我们单独实现了它。我们对VGG-16网络(Simonyan和Zisserman,2015)进行了改进,用于密集预测,并删除了最后两个池化和步幅层。具体而言,我们删除了每个池化和步幅层,并将所有后续层中的卷积操作扩张了2倍,以适应被删除的池化层。因此,跟随被删除的池化层的最后几层中的卷积操作扩张了4倍。这样可以使用原始分类网络的参数进行初始化,但产生更高分辨率的输出。前端模块以填充的图像作为输入,并在分辨率为64×64的位置生成特征图。我们使用反射填充:缓冲区域通过将图像关于每条边进行镜像填充来进行填充。
我们通过去除对密集预测无益的分类网络的残余部分来获得我们的前端模块。最重要的是,我们完全删除了最后两个池化和步幅层,而Long等人保留了它们,Chen等人将步幅替换为扩张,但保留了池化层。我们发现通过删除池化层简化网络可以提高准确性。我们还去除了中间特征图的填充。原始的分类网络中使用了中间填充,但在密集预测中既不必要也不合理。这个简化的预测模块是在Pascal VOC 2012训练集上训练的,该数据集由Hariharan等人(2011)创建的注释进行了增强。我们没有使用VOC-2012验证集的图像进行训练,因此只使用了Hariharan等人(2011)的注释的一个子集。训练是通过随机梯度下降(SGD)进行的,使用小批量大小为14,学习率为10^-3,动量为0.9。网络进行了60K次迭代的训练。
我们现在将我们的前端模块的准确性与Long等人(2015)的FCN-8s设计和Chen等人(2015a)的DeepLab网络进行比较。对于FCN-8s和DeepLab,我们评估了原始作者在VOC-2012上训练的公共模型。图2显示了不同模型在VOC-2012数据集上生成的图像分割结果。表2报告了模型在VOC-2012测试集上的准确性。我们的前端预测模块既更简单又更准确。具体而言,我们简化的模型在测试集上的性能超过了FCN-8s和DeepLab网络超过5个百分点。有趣的是,我们简化的前端模块在没有使用CRF的情况下,在测试集上的性能超过了DeepLab+CRF的领先准确率超过一个百分点(67.6%对66.4%)。

图2:不同VGG-16分类网络的适应版本生成的语义分割结果。从左到右依次为:
(a)输入图像,
(b)FCN-8s的预测结果(Long等人,2015),
(c)DeepLab的预测结果(Chen等人,2015a),
(d)我们简化的前端模块的预测结果,
(e)真实标签。
表2:我们的前端预测模块比之前的模型更简单且更准确。该表报告了在VOC-2012测试集上的准确性。
5.实验
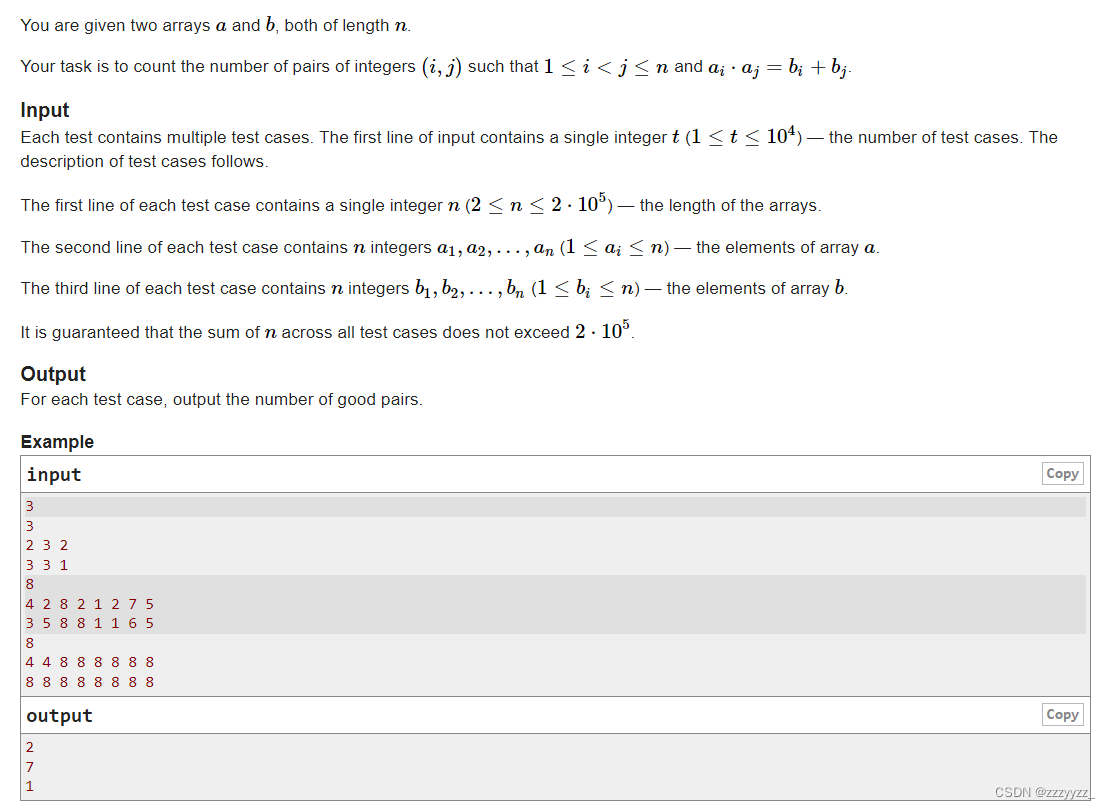
我们的实现基于Caffe库(Jia等人,2014)。我们的扩张卷积实现现在已经成为标准的Caffe发行版的一部分。为了与最近的高性能系统进行公平比较,我们训练了一个与第4节中描述的结构相同的前端模块,但是使用了来自Microsoft COCO数据集(Lin等人,2014)的额外图像进行训练。我们使用了Microsoft COCO中包含至少一个来自VOC-2012类别的对象的所有图像。其他类别的标注对象被视为背景。训练分为两个阶段。在第一阶段,我们将VOC-2012图像和Microsoft COCO图像一起训练。训练是通过SGD进行的,使用小批量大小为14和动量为0.9。进行了100K次迭代,学习率为10^-3,之后进行了40K次迭代,学习率为10^-4。在第二阶段,我们仅在VOC-2012图像上对网络进行微调。微调进行了50K次迭代,学习率为10^-5。VOC-2012验证集的图像没有用于训练。通过这个过程训练的前端模块在VOC-2012验证集上达到了69.8%的平均IoU,在测试集上达到了71.3%的平均IoU。请注意,这个准确性水平仅由前端模块实现,没有使用上下文模块或结构化预测。我们再次将这种高准确性的部分归因于去除了最初为图像分类而开发的残余组件。
对上下文聚合的可控评估。我们现在进行了一系列对上下文网络在第3节中提出的效用进行评估的控制实验。我们首先将两个上下文模块(基本和大)插入到前端。由于上下文网络的感受野为67×67,我们通过在输入特征图周围填充一个宽度为33的缓冲区来填充输入。在我们的实验中,零填充和反射填充产生了类似的结果。上下文模块接受来自前端的特征图作为输入,并在训练过程中接收此输入。在我们的实验中,上下文模块和前端模块的联合训练并没有显著改善。学习率设置为10^-3。训练初始化如第3节所述。表3显示了将上下文模块添加到三种不同的语义分割架构中的效果。
第一种架构(顶部)是第4节中描述的前端模块。它执行类似于Long等人(2015)原始工作的无结构预测的语义分割。
第二种架构(表3,中间)使用稠密CRF进行结构化预测,类似于Chen等人(2015a)的系统。我们使用Krahenb¨uhl和Koltun(2011)的实现,并通过在验证集上进行网格搜索来训练CRF参数。
第三种架构(表3,底部)使用CRF-RNN进行结构化预测(Zheng等人,2015)。我们使用Zheng等人(2015)的实现,并在每个条件下训练CRF-RNN。
实验结果表明,上下文模块在每个配置中都提高了准确性。基本上下文模块在每个配置中都提高了准确性,而大型上下文模块则提高了更大的准确性。实验表明,上下文模块和结构化预测是协同的:上下文模块提高了准确性,无论是否接下来进行结构化预测。图3展示了定性结果。
在测试集上的评估。我们现在通过将我们的结果提交到Pascal VOC 2012评估服务器上,在测试集上进行评估。结果如表4所示。我们在这些实验中使用了大型上下文模块。正如结果所示,上下文模块显著提高了准确性。仅有上下文模块,而没有后续的结构化预测,就超过了DeepLab-CRF-COCO-LargeFOV(Chen等人,2015a)。使用Krahenb¨uhl和Koltun(2011)的原始实现的上下文模块与最近的CRF-RNN(Zheng等人,2015)具有相当的性能。结合CRF-RNN的上下文模块进一步提高了准确性,超过了CRF-RNN的性能。

图3:不同模型生成的语义分割结果。从左到右依次为:
(a) 输入图像,
(b) 前端模块的预测结果,
(c) 插入到前端的大型上下文网络的预测结果,
(d) 前端 + 上下文模块 + CRF-RNN 的预测结果,
(e) 真实标签
表3:对上下文模块对三种不同语义分割架构准确性的效果进行的可控评估。实验在VOC-2012验证集上进行。验证图像未用于训练。
顶部:将上下文模块添加到没有结构化预测的语义分割前端(Long等人,2015)。基本上下文模块提高了准确性,大型模块的提高幅度更大。
中部:当上下文模块插入到前端+稠密CRF配置(Chen等人,2015a)时,准确性提高。
底部:当上下文模块插入到前端+CRF-RNN配置(Zheng等人,2015)时,准确性提高。

表4:在VOC-2012测试集上的评估结果。
“DeepLab++”代表DeepLab-CRF-COCO LargeFOV,
“DeepLab-MSc++”代表DeepLab-MSc-CRF-LargeFOV-COCO-CrossJoint(Chen等人,2015a)。
“CRF-RNN”是Zheng等人(2015)的系统。
“Context”指的是插入到我们前端的大型上下文模块。
上下文网络具有非常高的准确性,超过了没有进行结构化预测的DeepLab++架构。
将上下文网络与CRF-RNN结构化预测模块相结合,提高了CRF-RNN系统的准确性。
6.总结
我们已经研究了用于密集预测的卷积网络结构。由于模型必须产生高分辨率的输出,我们认为网络中的高分辨率操作既可行又可取。我们的工作表明,扩张卷积运算符特别适用于密集预测,因为它能够扩展感受野而不丢失分辨率或覆盖范围。我们利用扩张卷积设计了一种新的网络结构,插入到现有的语义分割系统中可可靠地提高准确性。作为这项工作的一部分,我们还展示了通过去除为图像分类开发的遗留组件,可以提高现有卷积网络在语义分割中的准确性。
我们认为,所提出的工作是朝着不受图像分类先驱限制的密集预测专用架构迈出的一步。随着新数据源的出现,未来的架构可以进行端到端的密集训练,不再需要在图像分类数据集上进行预训练。这可以实现架构的简化和统一。具体而言,端到端的密集训练可以使类似于所提出的上下文网络的完全密集架构在整个过程中以完整的分辨率操作,接受原始图像作为输入,并以完整的分辨率产生密集的标签分配作为输出。目前最先进的语义分割系统在未来仍有很大的进步空间。我们将发布我们的代码和训练模型,以支持该领域的进展。

图4:来自VOC-2012验证集的失败案例。我们训练的最准确的架构(上下文+CRF-RNN)在这些图像上表现不佳。