什么是正则表达式
Regex 代表Regular Expression,是一种用于在文本中搜索模式的表达式。简而言之,它将匹配与模式对应的每个单词或单词组。在 Python 中,您可以使用正则表达式来搜索单词、替换单词、匹配一个单词或一组单词。基本上所有事情都可以使用正则表达式,唯一能阻止你的是你的想象力。
文章目录
- 什么是正则表达式
- 第一个例子
- 一、基本标记和模式
- 二、使用步骤
- 1.引入库
- 2.量词
- 如何在 Pandas 中使用正则表达式
第一个例子
提示:这里可以添加本文要记录的大概内容:
让我们举个例子,找到电子邮件提供商是使用Randommer.io生成的虚假电子邮件列表;
email_list = [ "rosanna_mayer78@yahoo.com" ,
"edmund_haley@hotmail.com" ,
"peyton31@gmail.com" ,
"garnet.ratke77@hotmail.com" ,
"shaun_heathcote@hotmail.com" ,
"andreane68@hotmail. com”、
“rudolph9@gmail.com”、
“oran43@gmail.com”、
“leonel_ferry@gmail.com”、
“virgie20@yahoo.com” ]
首先导入库:第一步是从标准库中导入re包
import re
然后我们写一些代码来遍历列表并在每个字符串中找到一个电子邮件提供商
# For each email in our email list
for email in email_list:
# Searching for an email provider
email_match = re.search('@(\S+)',email)
# If there is a match, print it
if email_match:
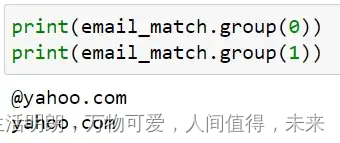
print(email_match.group(1))
让我们解释一下这部分;
re.search('@(\S+)',email)'@(\S+)',email)
re 包中的搜索函数通过此处的输入字符串(电子邮件)扫描匹配我们作为第一个参数(‘@(\S+)’)提供的模式的子字符串。我们在此处提供的模式查找 arobase 符号(@)并捕获组中后面的所有内容,直到遇到空格。圆括号意味着匹配左圆括号和右圆括号之间的子模式的所有内容都是该组的一部分。这里我们的子模式是\S+,其中\S表示非空白字符和+匹配此标记一次或多次。
最后我们的输出是:
yahoo.com
hotmail.com
gmail.com
hotmail.com
hotmail.com
hotmail.com
gmail.com
gmail.com
gmail.com
yahoo.com
提示:以下是本篇文章正文内容,下面案例可供参考
一、基本标记和模式
在 Regex 的世界中存在许多不同的标记和模式,但让我们保持简单。
所有基本字母数字字符都在匹配自身:‘a’、‘2’、“Z”
特殊元字符及其反义词
二、使用步骤
1.引入库
代码如下(示例):
\s -> 空白字符
\S -> 非空白字符
\d -> 数字字符 (0,1,2,3,4,5,6,7,8,9)
\D -> 非数字字符
\w - > 任何单词
\W -> 非单词
。-> 任意字符
\n -> 新行
\r -> 回车
2.量词
? -> zero or one of the token in front (eg: \d?)-> zero or one of the token in front (eg: \d?)
* -> zero or more of the token in front (eg: z*)
+ -> one or more of the token in front (eg: \S+)
{x} -> match x number of times the token in front (eg: a{5} -> match aaaaa)
其它
^ -> Start of a string
$ -> End of a string
| -> Boolean or condition (eg: a|b)
[] -> defining a list of token that could be match
(eg: [A-Za-z] for all letters in both lower and uppercase)
要像我们在示例中所做的那样创建一个组,您需要使用括号并在它们之间写下您的子模式。
您可能已经注意到,在最后一行,我们在 id 1 处打印了组。这是因为重新返回与字符串的总匹配,而不仅仅是我们的组:
如何在 Pandas 中使用正则表达式
现在让我们举个例子,通过在句子列表中查找价格,在 Pandas 中使用正则表达式。
import pandas as pd
sentence_dict ={ "Sentence" : [ "I bought it for $100.50" ,
"$50 is not worth it" ,
"Price: $12" ,
"Pricing on demand" ]}
df = pd.DataFrame(sentence_dict)
现在让我们考虑如何匹配价格?很简单:我们需要一个伟大的团队来捕捉美元符号后的所有数字!但是我们怎么做呢?就在一行中。
df[ '价格' ]=df[ '句子' ]。str .extract( r'\$([0-9.]+)' )
这里我们匹配一个美元符号,注意前面有一个反斜杠,这意味着我们想要一个美元符号而不是字符串的开头。然后我们有带括号的组。在里面我们说匹配任何数字(0 到 9)或点,一次或多次。
我们也可以这样写正则表达式,其中\d是任意数字:
df[ '价格' ]=df[ '句子' ]。str .extract( r'\$([\d.]+)' )
最后我们的输出是:
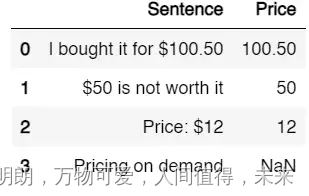
我们有 NaN 的地方,因为在句子中找不到价格。
参考文献:
https://medium.com/mlearning-ai/introduction-to-regex-for-data-scientists-6b4447687655