目录
0.前言
1.什么是链表
1.1链表简介
1.2链表的分类
1.3为什么要有链表(vs顺序表)
1.3.1顺序表的缺点
1.3.2 链表的优点
1.3.3 顺序表的优点是链表的缺点
1.4.为什么选择实现结构最简单的单链表
2* 什么是单链表(两种理解逻辑)
2.实现单链表
2.1 如何代表一个单链表
2.2* 单链表的尾插
2.3* 单链表的尾删
2.4 单链表的头插
2.5 单链表的头删
2.6 单链表的销毁
2.7 单链表的插入(Insert--在目标节点之前插入)
2.8* 单链表的删除
2.9 单链表的pos之后插入(更适合单链表)
2.10 单链表的pos之后删除(更适合单链表)
2.11单链表的查找
3. 单链表的测试
0.前言
本文所有代码都汇总至gitee网站当中:
3单链表实现 · onlookerzy123456qwq/data_structure_practice_primer - 码云 - 开源中国 (gitee.com)![]() https://gitee.com/onlookerzy123456qwq/data_structure_practice_primer/tree/master/3%E5%8D%95%E9%93%BE%E8%A1%A8%E5%AE%9E%E7%8E%B0
https://gitee.com/onlookerzy123456qwq/data_structure_practice_primer/tree/master/3%E5%8D%95%E9%93%BE%E8%A1%A8%E5%AE%9E%E7%8E%B0
1.什么是链表
1.1链表简介
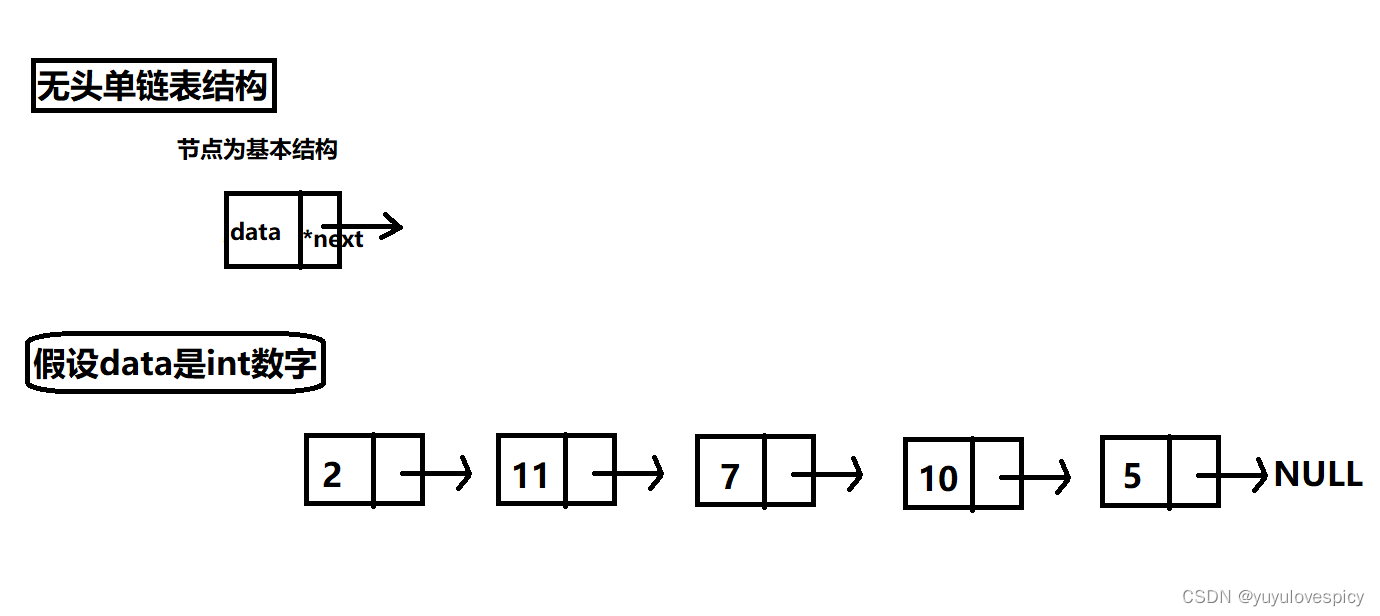
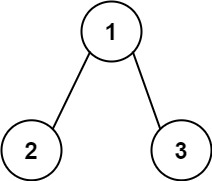
我们首先想象火车,火车是由一节一节车厢链接起来的,每一个车厢作为一个节点,和周围旁边的两个车厢链接起来。其实一个链表就是一辆火车。

就像火车是以一节节车厢为基本单位一样,链表是以一个一个节点为基本单位的,火车相邻的两个车厢与车厢之间,是链接起来的,链表的两个相邻的节点之间也存在链接关系。如下图我们看最简单的一个单链表结构:
1.2链表的分类
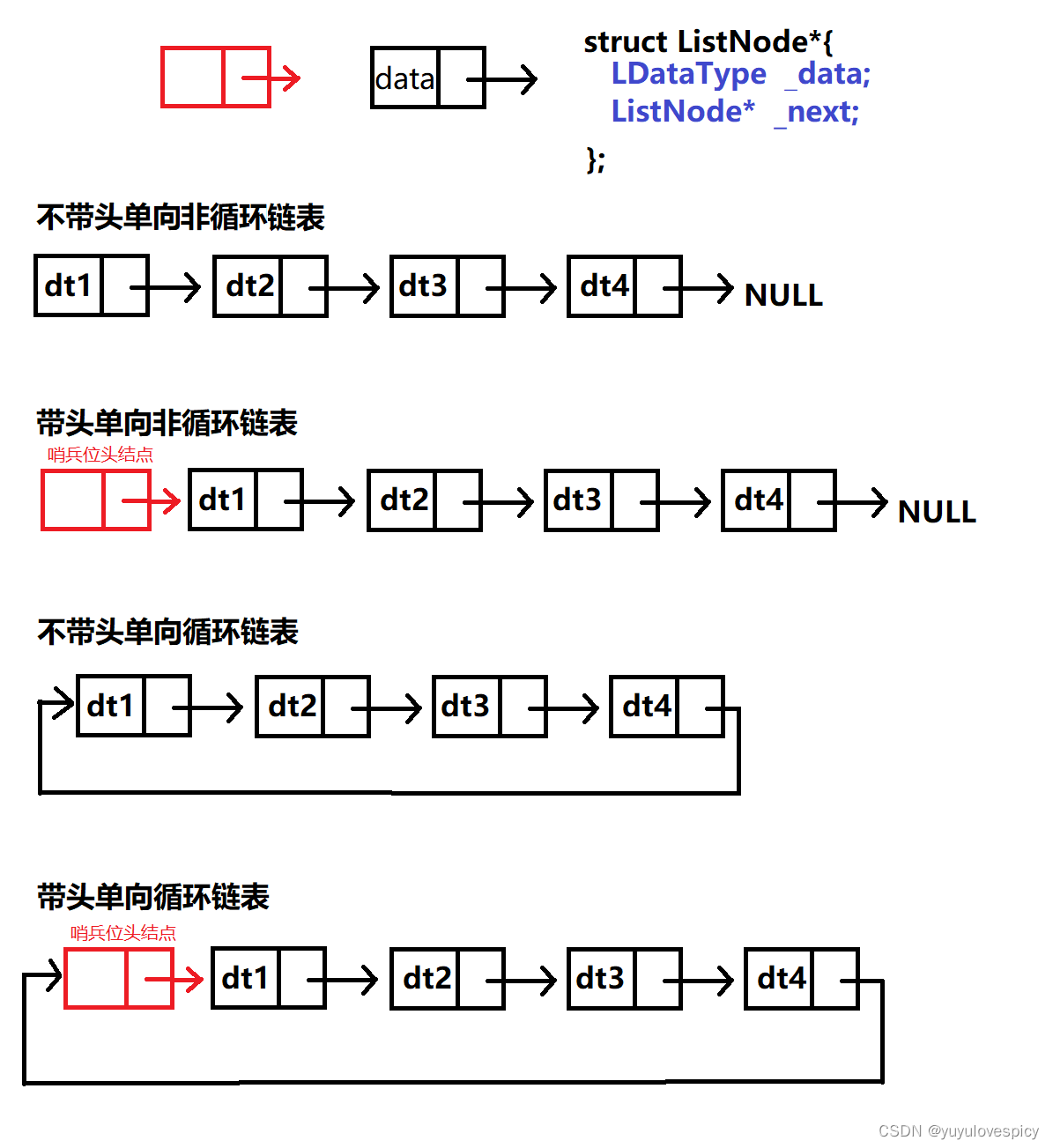
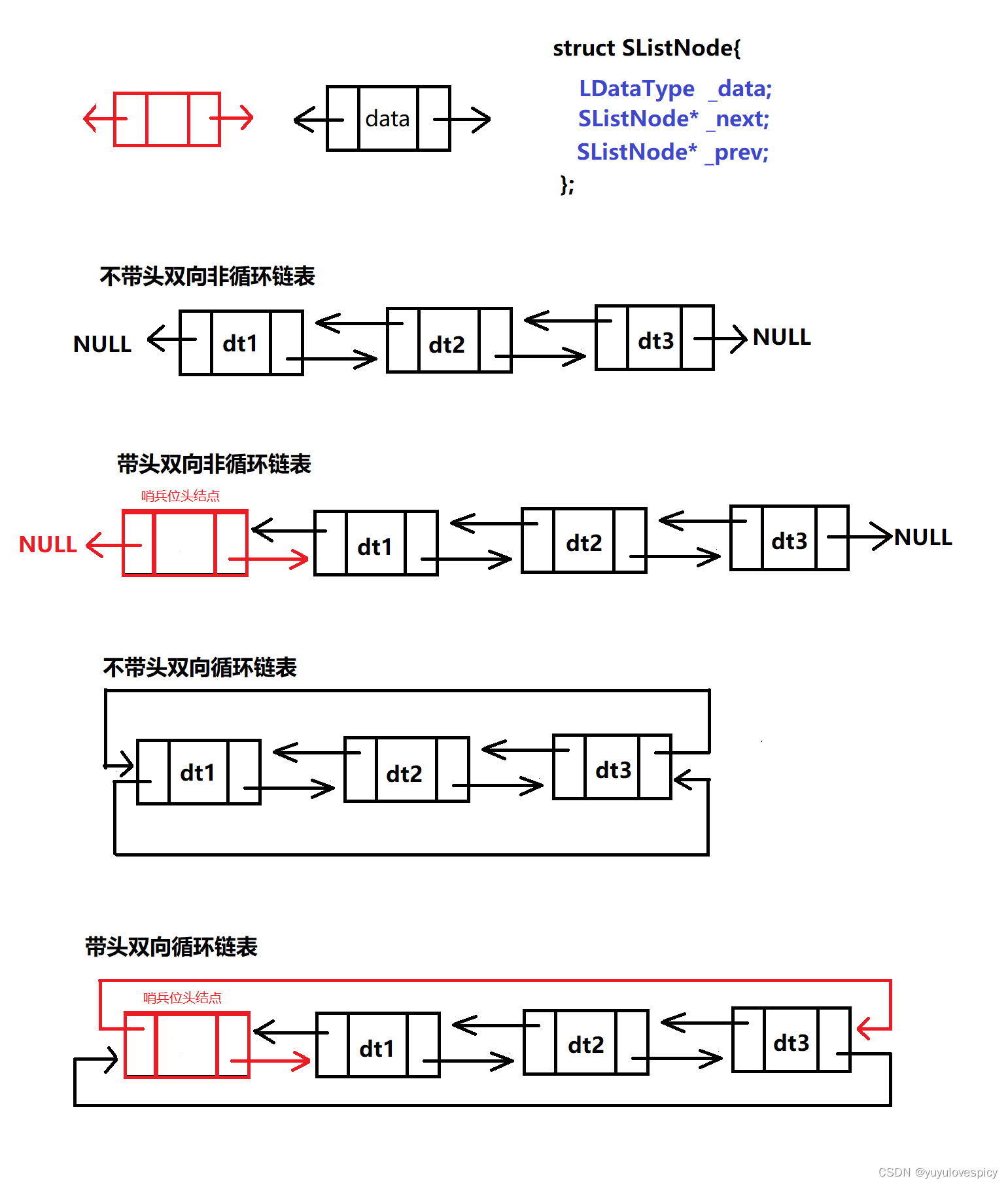
链表是以一个一个节点为基本单位的,相邻节点之间有链接关系,而链接的方式分为两种,一个是单向链接,一个是双向链接,前者是只有前一个节点链接到后一个节点,而没有后一个节点却没有链接到前一个节点,只能往后找,不能往前找;而后者是相邻的两个节点,都是相互链接指向的,可以后节点往前找,也可以前节点往后找。
同时链表一开始可以就固定有一个节点,我们称之为哨兵位的头结点,以后插入的节点都在这个哨兵头结点的后面。而一开始定义一个链表也可以没有这个头节点,即从一开始链表是NULL,没有任何节点,这个我们称之为不带头。哨兵位头结点的有无,可以分为带头/不带头。
而首节点和尾节点之间是否存在链接关系,这也是很重要的一个点。如果首节点和为尾节点之间不存在链接关系,则是非循环链表;如果首节点和尾节点之间存在链接关系,则是循环链表。
根据单向链接vs双向链接 和 有头节点vs无头结点 和 循环vs非循环,这三对矛盾,我们就可以对链表做如下的分类:
1.3为什么要有链表(vs顺序表)
为什么要有链表结构,其实链表是根据顺序表的缺点设计出来的:
1.3.1顺序表的缺点
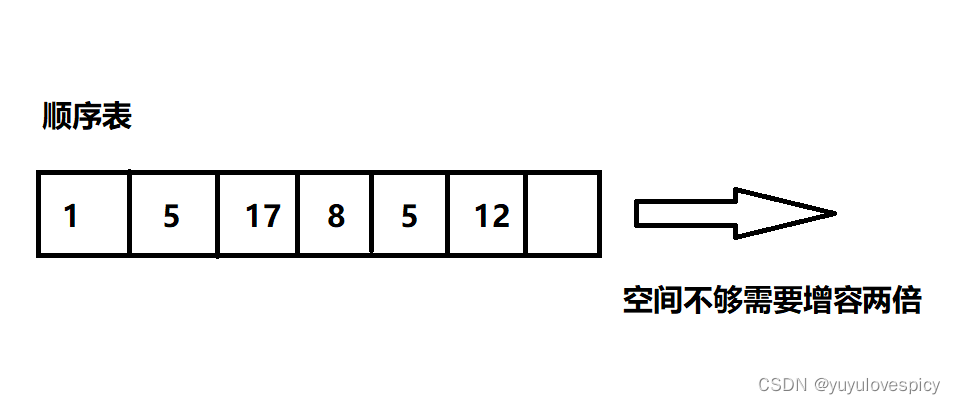
顺序表的缺点是由其基本性质决定的,首先顺序表,即开辟的数组的空间必须是连续的;同时顺序表中的数据必须是在物理地址上是连续存储的,不能有间隔和跳跃。
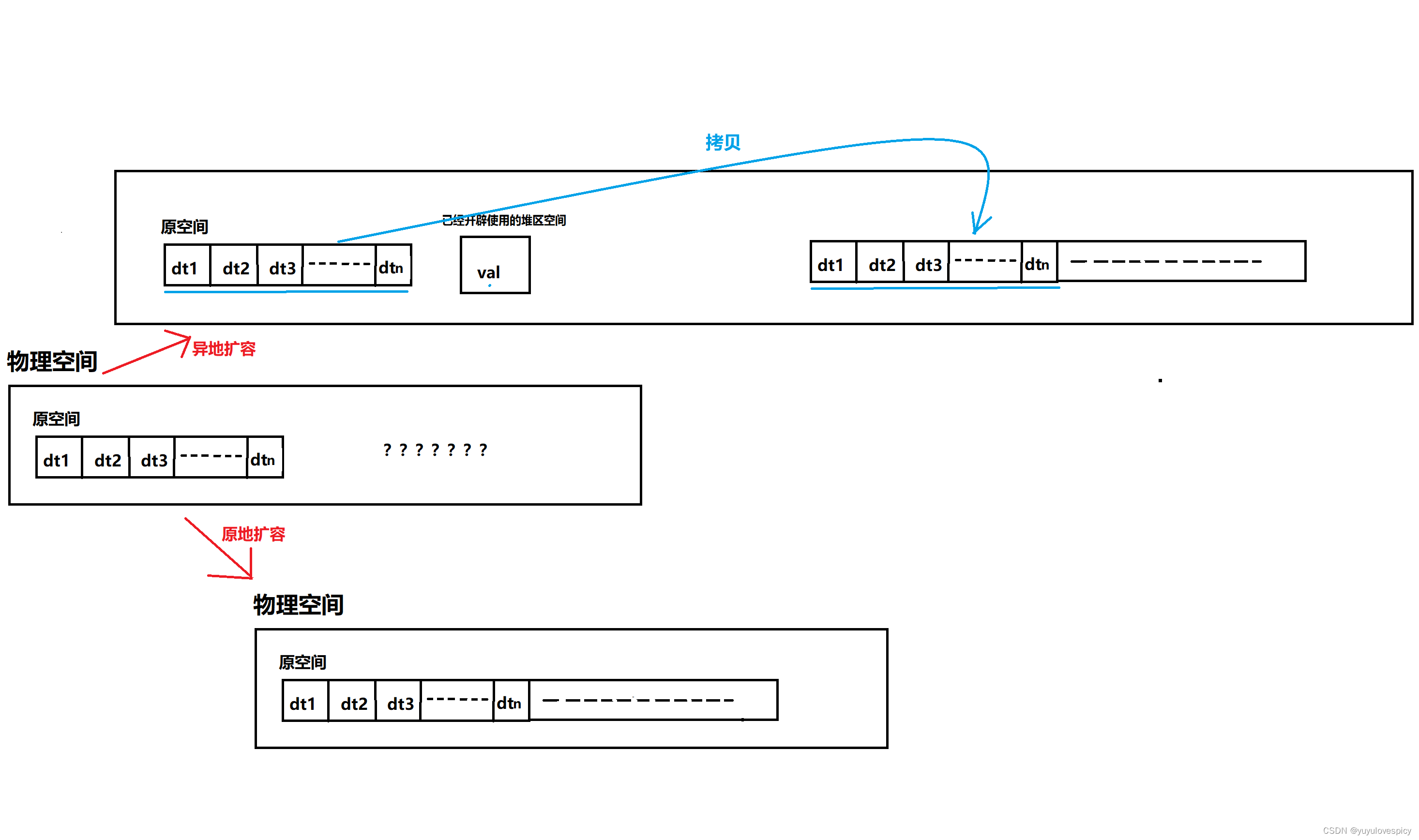
第一个缺点:因为所开辟的空间必须是连续的空间,所以有时就会非常影响扩容的效率。在扩容realloc的时候,我们必须开辟出一段连续的空间,而随着顺序表数组的增大,要求在内存中开辟的连续的空间就会越来越大,我们知道realloc的原理,存在原地扩容和异地扩容两种情况,如果在原空间的后面还有足够的空间够原空间扩容两倍,那就可以直接原地扩容,这样的成本是很低的;而如果原来的空间后面已经有空间是被征用的了,我们realloc要开辟的连续空间就需要异地扩容,即首先会在堆区当中寻找新的空间,找到足够大的两倍连续空间之后,会花费O(N)的时间先把原来空间的数据拷贝到这块新空间上去,然后使用再free销毁掉原来的空间,这个异地扩容的成本是很高的。
void CheckSLCapacity(SeqList* ps)
{
if (ps->_size == ps->_capacity)
{
int next_cap = (ps->_capacity == 0) ? 4 : ps->_capacity * 2;
SLDataType* ptmp = (SLDataType*)realloc(ps->_a, sizeof(SeqList) * next_cap);
if (ptmp == NULL)
{
//申请空间失败
perror("realloc");
exit(1);
}
ps->_a = ptmp;
ps->_capacity = next_cap;
}
}为了解决频繁扩容而导致的扩容效率问题,我们通常是采用一次扩容两倍的空间。可是这样扩容两倍就会产生一个浪费空间的问题,比如我们想插入101个数据,而现在的数组空间是100的容量,所以只能是扩容到200,这样就会致使99个空间浪费,所以说扩容是存在空间浪费问题的。
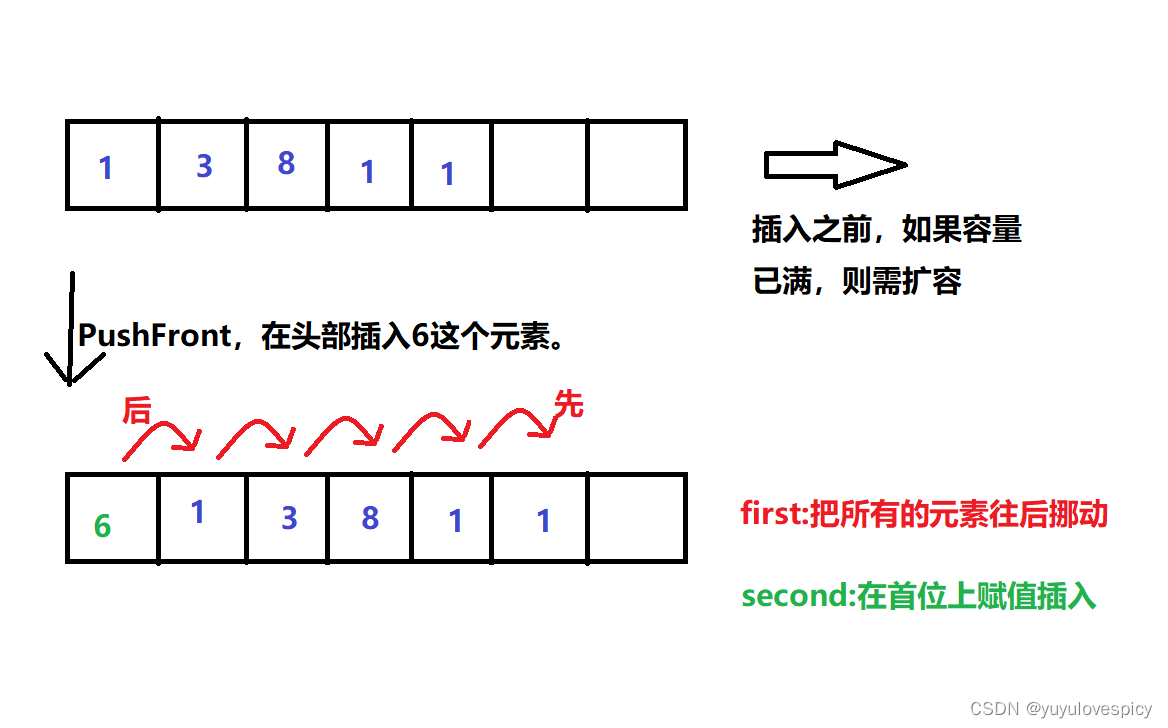
不只是开辟连续的空间,顺序表要求存储的数据也必须是连续的,数据必须没有间隔和跳跃,所以这就导致顺序表在头插和头删的时候效率是极低的,必须涉及所有元素的挪动,这就达到了O(N)的时间复杂度。
总结一下顺序表的缺点:
1.空间不够了需要增容,增容需要付出代价。
2.为避免频繁扩容,一次一搬是按照倍数去扩容(2倍),可能存在一定空间浪费。
3.头部或者中间位置的插入/删除,需要挪动数据,挪动数据也是有消耗的。
1.3.2 链表的优点
针对顺序表的三个缺点,我们设计出链表。首先链表是以节点为基本单位的,各节点之间在堆区的任意位置存储,并不需要开辟连续的空间,所以扩容(异地扩容概率极小)消耗小。而且链表是以按需申请空间,不用了就可以释放空间,更加合理的使用了空间。同时按需申请和释放的特点可以使得链表存在空间浪费的情况,给多少数据就存多少数据。在头部或中间插入/删除的时候,不需要挪动数据,就可以提高效率。
总结一下链表的优点:
1.按需申请空间,不用了就释放空间(更合理的使用了空间)。
2.不存在空间浪费。
3.头部/中间,插入/删除数据,不需要挪动数据。
1.3.3 顺序表的优点是链表的缺点
顺序表是数组,数组的每一个元素都是 有下标的,可以直接*(a+i),通过下标进行访问,直接找到数据实体,所以说顺序表是支持随机访问的,而链表只能通过链接关系一个一个的往前/往后找,没有下标,并不支持随机访问。而有些算法,需要存储结构支持随机访问,比如:二分查找,比如:优化的快排等。
1.4.为什么选择实现结构最简单的单链表
我们选择实现的是结构最简单的,不带头节点的,单向的单链表。单链表的缺陷还是很多的,单纯单链表的增删查改的意义并不大。那为什么我们还要学习并实现这种结构呢?
1. 很多OJ题考查并使用的都是单链表
2. 单链表更多的是去作为更复杂数据结构的子结构,例如哈希表中的哈希桶,图中的邻接表等。
因为以上两个点我们需要学习结构最简单的单链表结构。
补充一点,实际上,双向带头链表,才是更有意义的数据结构,我们在实战当中想使用链表这种数据结构的话,使用最多的其实是双向带头链表list。
2* 什么是单链表(两种理解逻辑)
我们首先形象的理解这个链表其实就是一个一个的节点,通过一个个箭头链接起来,每一个前面的节点都通过箭头可以链接找到后面的一个节点。下面这个我们理解的图叫做逻辑结构图。
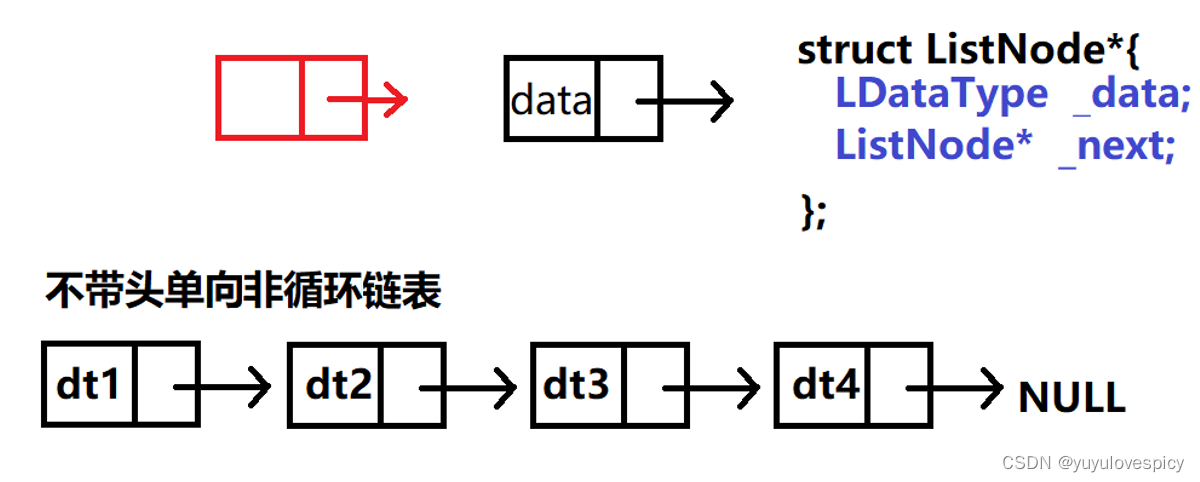
那具体是如何让前面一个节点链接找到后面一个节点呢?
让每一个节点存储下一个节点的地址,即每个节点都存储着指向下一个节点的指针,就可以通过这个指针指向找到下一个节点实体,即可达到这种链接的效果。下面这个理解的图叫做物理逻辑图。
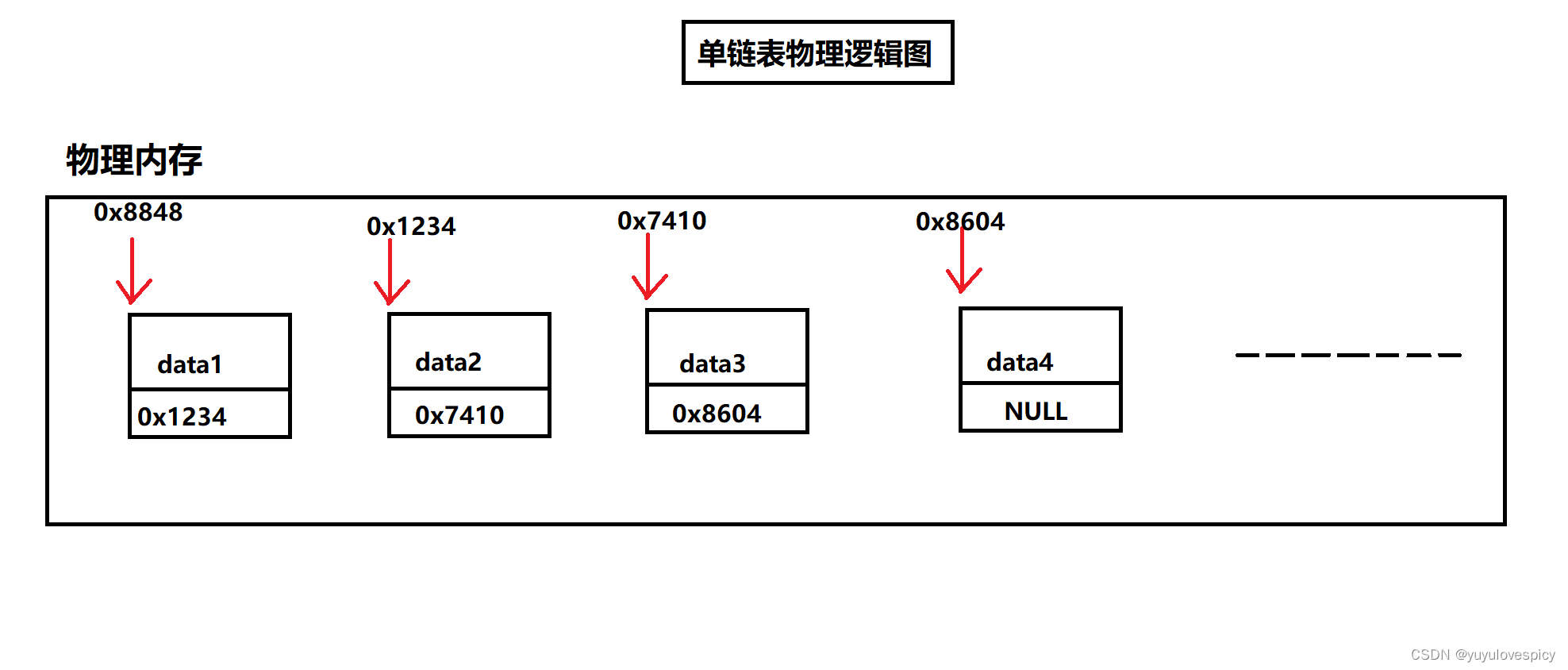
所以我们大致就可以定义出单链表的节点的基本结构,struct SListNode,一个节点里面存储着这个节点存储的数据data,然后还存储下一个节点的地址,即指向下一个节点的指针。
所以我们理解一下下面这段代码:
typedef struct SListNode
{
SLDataType _data;
struct SListNode* _next;
}SListNode;
void SListPrint(SListNode* phead)
{
SListNode* cur = phead;
//如果phead==NULL,空链表不打印
while (cur)
{
printf("%d->", cur->_data);
cur = cur->_next;
}
printf("\n");
}传入了一个phead,也就是一个单链表的头节点的指针,我们要打印这个单链表中的所有数据,所以就需要我们遍历每一个节点,找到每一个节点的存储的数据data进行打印。
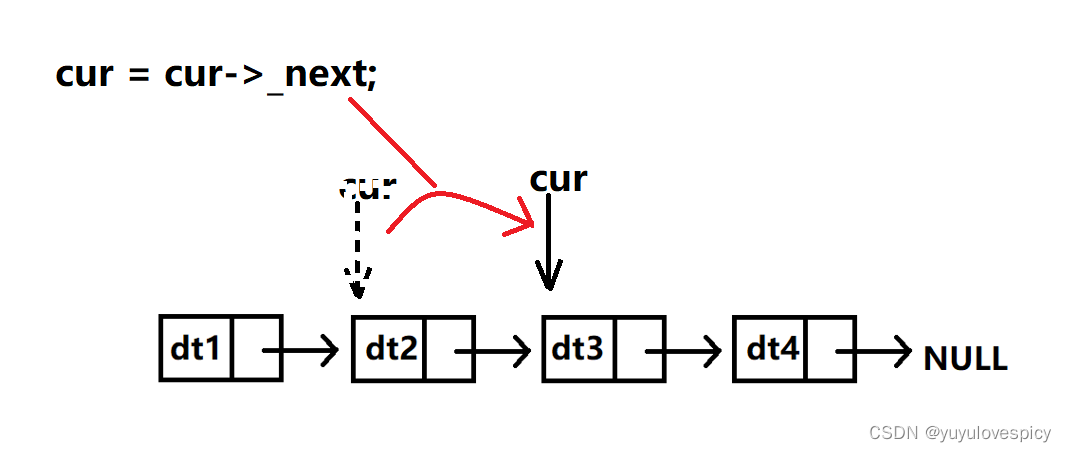
我们定义一个指针cur指向第一个节点head,然后让cur一直往后走,遍历每一个节点。第一句printf("%d->", cur->_data);好理解,我们知道cur是指向一个节点的指针,然后cur->_data就是解引用找到这个指向节点里存储的数据_data。
cur=cur->_next;这一句代码,我们知道cur指向的就是一个节点,cur指针可以访问现在指向的节点的数据成员。而我们知道节点里面存储着下一个节点的地址/指向下一个节点的指针。所以cur->_next获取到的就是下一个节点的指针。cur = cur->_next;就是让cur这个指针更新成指向下一个节点的指针。
所以cur=cur->_next我们从逻辑结构图上理解就是,通过节点之间的链接,cur指向到了下一个节点。从物理结构图上理解,就是cur的地址值不断更新,更新成这节点存储着的下一个节点的地址。
2.实现单链表
2.1 如何代表一个单链表
我们之前封装一个结构体struct SeqList来表示一个顺序表,我们用一个struct SingleList来表示一个单链表也是没有问题的,可是没有必要!
表示一个顺序表,我们需要描述这个顺序表的数组实体,大小以及容量,这是需要用一个struct结构体封装在一起的,才能够代表描述一个顺序表。可是一个普通的单链表,只需知道首元素即第一个节点的指针,就可以代表描述一个单链表。因为我们只要知道这个首节点的指针,就可以往后通过链接关系,找到后面的所有的节点。
//单链表的定义
/*typedef struct SingleList
{
SListNode* plist;
}SingleList;*/
/*我们并不需要单独创建一个结构体来描述单链表, 因为
单链表只需要一个成员变量,也就是首元素地址,即第一个节点的指针,即可代表表示一个单链表*/
/*SListNode* plist1 = NULL; SListNode* plist2 = NULL;*///定义一个单链表
SListNode* plist = NULL;2.2* 单链表的尾插
我们要知道一件事,我们在main函数中,是使用一个首节点的指针,来代表整个单链表,如果我们调用一个函数接口,对这个单链表实体进行操作,是有可能改变这个单链表首节点的地址的。例如我们的尾插,很多时候都是修改plist后面的节点,并不需要改变首节点的指针值,可是如果一开始单链表是一个空链表,即plist==NULL的时候,在尾插之后,那plist值一定必须要修改成新插入节点的地址。比如下面这个操作,我们如果是这样传参实现单链表的尾插的话:
void SListPushBack(SListNode* phead, SLDataType x)
{
SListNode* newnode=(SListNode*)malloc(sizeof(SListNode));
newnode->_data = x;
newnode->_next = NULL;
if(phead == NULL)
{
phead=newnode;
}
else{
SListNode* cur = phead;
while(cur->_next)
{
//找尾
SListNode* tail = *pphead;
while (tail->_next)
{
tail = tail->_next;
}
//尾插链接
tail->_next = newnode;
newnode->_next = NULL;
}
}
}
int main()
{
//定义一个单链表(单链表首节点的地址)
SListNode* plist = NULL;
//给单链表plist插入数据为6的节点
SListPushBack(plist,6);
}那就会造成一个严重的后果:
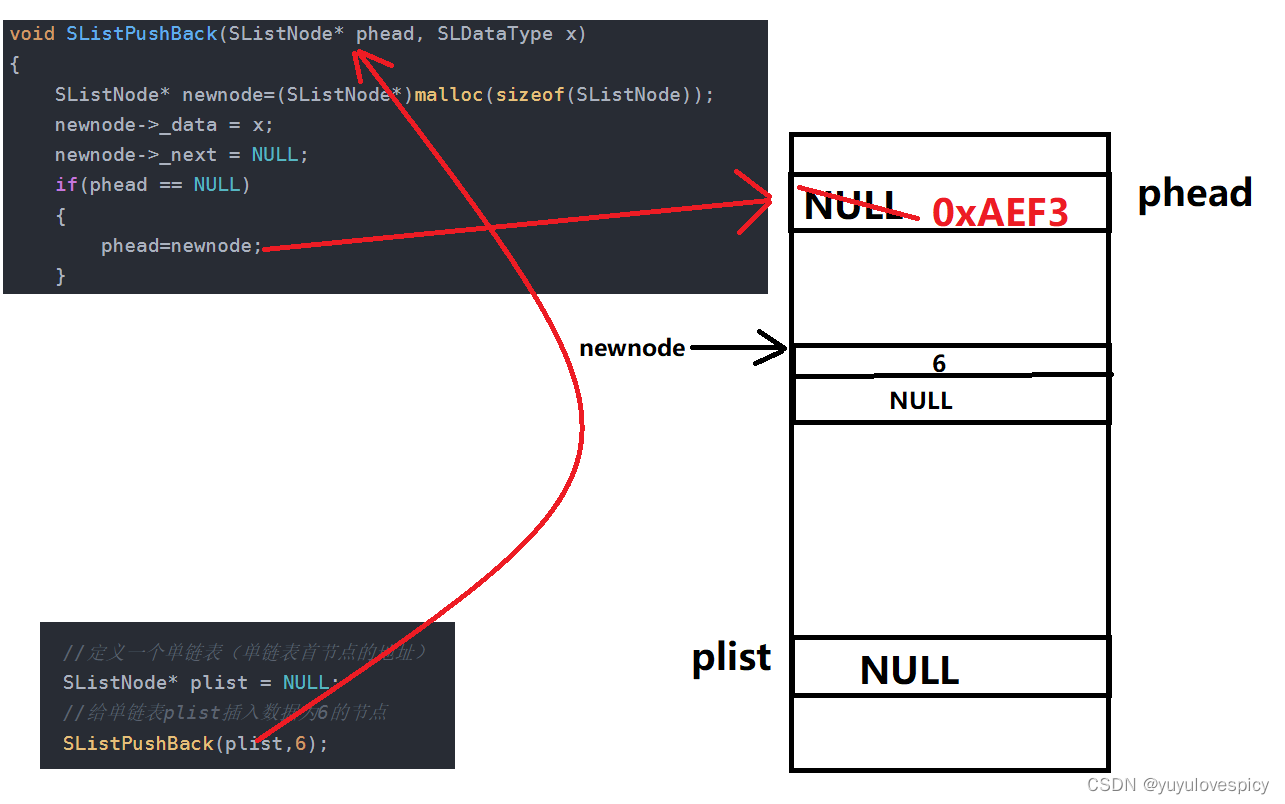
传入的phead是plist的拷贝,所以我们要改变phead的时候,并不能改变到plist实体的值!
所以我们必须让该链表(首节点指针plist)在调用接口的时候,必须要修改的是这个单链表的代表----首节点的指针plist实体。做到这一点我们就要传入plist指针的地址,即指向这个指针变量plist的指针,才能找到plist实体!即我们要传入二级指针!
PS:plist作为指针指向的一个个的节点实体,我们通过一级指针可以找到每一个节点实体,从而修改每一个节点的值。我们可以通过二级指针pphead,指向的是一级指针实体plist,从而通过二级指针修改plist实体的值。
由此我们也得出一个结论:只要对单链表进行操作的接口有可能修改传入的plist,即这个单链表的代表,也即这个首节点的指针实体,就需要传入二级指针。
SListNode* BuySListNode(SLDataType x)
{
SListNode* ptmp = (SListNode*)malloc(sizeof(SListNode));
//检查申请
if (ptmp == NULL)
{
perror("SListNode malloc");
exit(1);
}
//初始化节点
ptmp->_next = NULL;
ptmp->_data = x;
return ptmp;
}
void SListPushBack(SListNode** pphead, SLDataType x)
{
//创建新节点
SListNode* newnode = BuySListNode(x);
//如果链表为空,需要修改单链表的代表实体,首节点的指针*pphead
if (*pphead == NULL)
{
//现在首节点成为了这个第一个创建的节点
*pphead = newnode;
}
else //链表不为空
{
//找尾
SListNode* tail = *pphead;
while (tail->_next)
{
tail = tail->_next;
}
//尾插链接
tail->_next = newnode;
newnode->_next = NULL;
}
}
任何插入,只要是有效的插入,都要创建节点,所以我们对创建节点的接口做了封装。
然后尾插大多数情况都是要找到最后一个节点,然后在最后一个节点后链接上新创建的节点;但是有一种情况是链表压根就没有节点,即空链表的情况,这时候就需要我们直接对首节点指针实体进行修改,赋值为新创建节点的指针值。
2.3* 单链表的尾删
尾部删除也有可能改变plist实体,即在只有一个节点的单链表的情况下,我们尾删,就会使得链表变成空链表,所以我们必须改变外部的plist实体为NULL,所以一定要传入链表首节点指针plist的二级指针!
然后我们需要考虑各种情况,这是我们写代码之前所要考虑的,要做尾删,那我们能删除空链表吗?显然不能,这是一个应该额外考虑的情况。如果链表当中只有一个节点,那删除之后,链表为空,这个情况我们需要直接修改plist实体为NULL。如果链表中有多个节点,我们需要在删除一个节点之后,对删除的尾部节点的前一个节点,需要把前一个节点的_next置空,这又是另一种情况。
void SListPopBack(SListNode** pphead)
{
//须有元素才可以进行删除
assert(*pphead);
//找尾
SListNode* prv = NULL;
SListNode* tail = *pphead;
while (tail->_next)
{
prv = tail;
tail = tail->_next;
}
//删除尾节点
//需要尾节点前面的节点_next置空
if (prv == NULL)
{
//没有尾前节点,即该单链表只有一个节点 *pphead==tail
free(tail);
*pphead = NULL;
}
else //tail前面有节点
{
free(tail);
prv->_next = NULL;
}
}2.4 单链表的头插
头插一定会改变首节点的地址,因为现在头结点的地址会变成新节点的地址,所以在实现单链表的头插接口时,我们一定要传入首节点的指针plist的地址,即plist的指针,以此来修改plist实体值。
同时我们继续考虑情况,头插需要把plist变成新节点的指针,然后把新节点的指针连接到原来的首节点上。这样无论是对于空链表和有节点的链表实现方法都是一样的,所以不用区分别的情况。
void SListPushFront(SListNode** pphead, SLDataType x)
{
//创建新节点
SListNode* newnode = BuySListNode(x);
//头插一定会改变首节点为新节点
//新节点链接到原来的首节点
newnode->_next = *pphead;
*pphead = newnode;
}2.5 单链表的头删
头删也一定会改变单链表首节点的指针,会变成当前节点的下一个节点的指针,所以我们必须要传入首节点指针plist的地址,即二级指针。
可是我们要考虑另一种情况,那就是当链表为空的时候,空链表是不能进行删除的,所以我们要禁止这种情况。
void SListPopFront(SListNode** pphead)
{
//必须保证链表不为空才可以删除
assert(*pphead);
//头删一定会改变plist首节点指针实体,为第二个节点/空
SListNode* head_next = (*pphead)->_next;
free(*pphead);
*pphead = head_next;
}2.6 单链表的销毁
我们知道所有的空间都是在堆区上开辟的,所以在链表结束使用或程序退出的时候,我们需要销毁free掉每一个节点的空间。这时候我们要注意,我们还是要传入链表首元素地址plist的指针的,因为我们需要对plist实体进行置空,以防止野指针的出现。
然后单链表的销毁我们应该一个一个节点的删除,直至删除到空NULL销毁结束。
void SListDestroy(SListNode** pphead)
{
//在一个一个释放所有节点之后,需要对plist链表指针实体置空
//传入二级指针
SListNode* cur = *pphead;
//对于空链表,就没有free操作
while (cur)
{
SListNode* cur_next = cur->_next;
free(cur);
cur = cur_next;
}
*pphead = NULL;
}2.7 单链表的插入(Insert--在目标节点之前插入)
我们在给定的pos位置,之前插入新节点,我们还是需要改变首节点的指针plist实体,所以还是要传二级指针:这是因为如果pos就是首节点的话,我们此时就要做头插,而头插就必须改变plist,所以我们遇到头插的情况就要改变plist实体。而如果非头结点之前插入,那我们就让前一个节点的_next指向这个新节点,让新节点指向这个插入的pos位置的节点即可。
同时我们知道,如果传入pos是NULL的时候,我们是不允许这种情况出现的,因为我们不能在NULL之前插入!然后Insert在pos节点之前插入,这个Insert接口的特性(在Pos位置之前插入)实际上就限制了Insert接口不能进行尾插,最后一个节点之后没有节点了。同时Insert不能对空链表进行插入,因为对空链表的插入需要一个pos作为参数,而空链表一个节点都没有。
void SListInsert(SListNode** pphead, SListNode* pos, SLDataType x)
{
//在pos位置之前插入新节点,pos为空,找不到该位置之前进行插入
assert(pos);
//创建新节点,把pos位置前一个节点链接到新节点,新节点链接到pos
SListNode* newnode = BuySListNode(x);
//可pos位置之前不一定有节点,即pos可能是首节点
//同时Insert接口不存在对空链表插入的情况,因为我们不能对空位置之前的节点插入
SListNode* prv = NULL;
SListNode* cur = *pphead;
//找pos以及pos前节点
while (cur!=pos)
{
prv = cur;
cur = cur->_next;
}
//不合法的pos位置
if (cur == NULL)
{
printf("Illegal pos Insert\n");
exit(2);
}
//prv->newnode->pos/cur
if (prv == NULL)
{
//在首节点之前插入
//新创建节点变成新头节点
newnode->_next = *pphead;
*pphead = newnode;
}
else //前面有一个节点
{
prv->_next = newnode;
newnode->_next = cur;
}
}2.8* 单链表的删除
删除pos位置的这个节点。这个情况就复杂的多。
情况一:如果这个链表是空链表,那就不允许删除,我们需要禁止这种情况。
情况二:传入的pos位置不属于这个单链表或者就是NULL空位置,属于非法删除。
情况三:把pos这个节点删除,就需要把pos之前的节点链接到pos之后的那个节点链接起来。可是pos之前一定有节点吗?如果pos这个节点是首节点的话就没有pos_prv这个节点,即pos是首节点的话,那就不能有这个链接环节了,这个其实就是情况四。本情况三,pos之前之后都有一个节点。
情况四:要删除的这个节点是首节点,所以需要改变首节点的指针实体plist,使之变成首节点的next下一个节点的地址,所以这种情况就决定了我们必须传入二级指针,即首节点指针plist的指针。
void SListErase(SListNode** pphead, SListNode* pos)
{
//必须有元素才可以进行删除
assert(*pphead);
//删除的pos位置一定不为空且合法
assert(pos);
SListNode* prv = NULL;
SListNode* cur = *pphead;
//寻找pos位置
while (cur != pos)
{
prv = cur;
cur = cur->_next;
}
//不存在合法的pos位置
if (cur == NULL)
{
printf("Illegal pos Erase\n");
exit(3);
}
else
{
//删除的pos是头结点
if (prv == NULL)
{
*pphead = cur->_next;
free(cur);
}
else //pos不是头结点
{
SListNode* cur_next = cur->_next;
free(cur);
prv->_next = cur_next;
}
}
}2.9 单链表的pos之后插入(更适合单链表)
适合单链表的插入,并不是在pos位置之前插入Insert,而是在pos位置之后插入InsertAfter。
因为我们Insert,需要付出O(N)的时间复杂度,因为在pos之前插入,需要遍历单链表找到pos的前一个节点pos_prv,使得pos_prv节点指向新创建的节点。而InsertAfter就可以直接在给定的pos位置的后面插入一个位置,同时pos_next节点也可以直接由pos往后找到,所以就只需要O(1)的时间复杂度就可以实现了。
不仅如此,我们InsertAfter接口还不需要传入二级指针:因为在pos位置之后插入,压根不存在修改头结点的机会,因为我们是在pos之后插入,不存在头插的情况,同时,也不存在对空链表的插入,因为空链表没有pos位置节点进行传入。所以也就没有对plist首节点指针修改的情况出现。
//在pos之后插入不可能改变首节点,所以不需要传入pphead,只需要传入插入位置pos
void SListInsertAfter(SListNode* pos, SLDataType x)
{
//要插入的位置pos(后)必须是有效的,不可为空
assert(pos);
//创建新节点
SListNode* newnode = BuySListNode(x);
SListNode* pos_next = pos->_next;
pos->_next = newnode;
newnode->_next = pos_next;
}2.10 单链表的pos之后删除(更适合单链表)
在pos位置之后删除位置,比删除pos位置的节点,更加适合单链表!
因为删除pos位置的单链表,需要遍历单链表,处理pos位置之前和pos位置之后的节点的链接关系,这就需要付出O(N)的时间复杂度。而且删除pos位置有可能改变首节点的指针实体plist,所以就需要传入二级指针。
而EraseAfter就相对简单了,因为我们不需要遍历单链表了,就可以直接在pos位置之后进行插入,因为此时我们通过pos直接找到下一个要删除的节点,以及找到pos的下下个节点,不用遍历链表就你可以处理链接关系了,时间复杂度只需要O(1)。同时EraseAfter也杜绝了头删的可能,所以从这个情况下说,EraseAfter不可能改变头节点的指针,所以也就没有必要传入二级指针了。
//删除pos后面的的节点,也不会改变单链表的首节点指针实体
void SListEraseAfter(SListNode* pos)
{
//非法情况删除(NULL位置之后不存在位置NULL->_next)
assert(pos);
//非法情况删除(pos之后为空NULL,不可删除)
assert(pos->_next);
SListNode* pos_erase = pos->_next;
SListNode* erase_next = pos_erase->_next;
free(pos_erase);
pos->_next = erase_next;
}2.11单链表的查找
对于单链表的查找,我们只是需要遍历寻找一个对应的节点地址,所以并不需要修改头节点的指针plist实体,所以就没有必要传入二级指针。只需要传入一级指针,即外部首节点指针的拷贝即可。
SListNode* SListFind(SListNode* phead, SLDataType x)
{
SListNode* cur = phead;
while (cur)
{
if (cur->_data == x)
{
return cur;
}
cur = cur->_next;
}
return NULL;
}3. 单链表的测试
我们对每一个接口进行单元测试,就可以对点找错,找到问题所在。同时也要写一个接口就测试一个接口,所以我们分模块,Test1,Test2.....分函数对不同的函数接口进行分块测试。
#include"singlelist.h"
void TestSList1()
{
//定义一个单链表
SListNode* plist = NULL;
//测试尾插,尾删
SListPushBack(&plist, 1);
SListPushBack(&plist, 0);
SListPushBack(&plist, 0);
SListPushBack(&plist, 8);
SListPushBack(&plist, 6);
SListPopBack(&plist);
SListPopBack(&plist);
SListPopBack(&plist);
SListPopBack(&plist);
SListPopBack(&plist);
SListPrint(plist);
SListDestroy(&plist);
}
void TestSList2()
{
SListNode* plist = NULL;
//测试头插,头删
SListPushFront(&plist, 6);
SListPushFront(&plist, 8);
SListPushFront(&plist, 0);
SListPushFront(&plist, 0);
SListPushFront(&plist, 1);
SListPopFront(&plist);
SListPrint(plist);
SListDestroy(&plist);
}
void TestSList3()
{
//测试在pos位置之前插入Insert测试
SListNode* plist = NULL;
SListPushFront(&plist, 8);
SListPushFront(&plist, 0);
SListInsert(&plist, plist , 1);
SListInsert(&plist, plist->_next, 7);
SListPrint(plist);
SListDestroy(&plist);
}
void TestSList4()
{
//测试在pos位置进行删除Erase测试
SListNode* plist = NULL;
SListPushBack(&plist, 1);
SListPushBack(&plist, 0);
SListPushBack(&plist, 0);
SListPushBack(&plist, 8);
SListPushBack(&plist, 6);
SListErase(&plist,plist->_next);
SListErase(&plist, plist);
SListPrint(plist);
SListDestroy(&plist);
}
void TestSList5()
{
//测试在pos之后插入以及在pos之后删除
SListNode* plist = NULL;
SListPushBack(&plist, 1);
SListPushBack(&plist, 0);
SListPushBack(&plist, 0);
SListPushBack(&plist, 8);
SListPushBack(&plist, 6);
SListInsertAfter(plist, 999);
SListInsertAfter(plist->_next->_next->_next, 66);
//SListEraseAfter(plist->_next->_next->_next);
SListPrint(plist);
SListDestroy(&plist);
}
int main()
{
//TestSList1();
//TestSList2();
//TestSList3();
//TestSList4();
TestSList5();
return 0;
}







![[生成 pdf 详解]](https://img-blog.csdnimg.cn/a7dc25f905c84474a4dabe87ae2ba4f3.png)