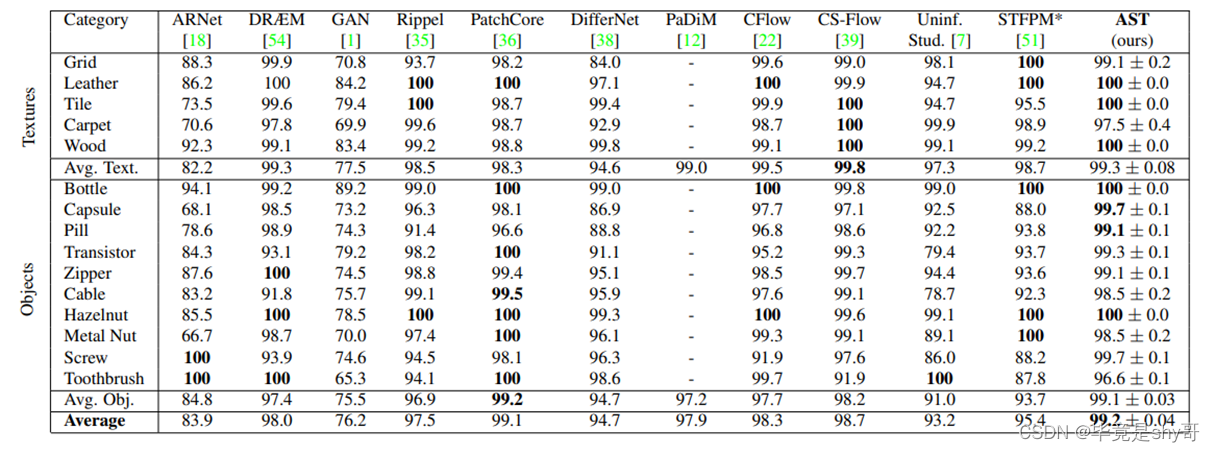
背景
在Android ART虚拟机中,GC的部分流程中会执行stop the world的操作,那么,STW在虚拟机中如何实现呢?本文就深入到ART虚拟机源码中,探寻STW的实现过程。
【本文基于android12源码分析】
CheckPoint机制
ART虚拟机中采用的是主动式挂起暂停某个线程的执行。也就是说,当GC或者其他操作需要挂起线程的时候,不直接对线程进行操作,而仅仅是简单地给线程设置一个标志,线程执行过程中主动去轮询这个标志,发现这个标志是挂起状态时,主动暂停本线程的执行。轮训检查这个标志的位置就叫做检查点(Check Point)。在JVM虚拟机(HotSpot VM)中,叫做安全点(Safe Point)。
虚拟机的Check Point机制主要包括三个部分内容:
- 有一个标志位控制变量,外部可以设置它;
- 无论是解释执行还是机器码执行过程中,需要经常去检查这个标志位是否有变化,检查标志位的地方就是Check Point;
- 如果检查到标志位有变化,则执行其他操作,这个操作包括:暂停线程执行,遍历堆栈,调用垃圾回收等等;
CheckPoint标志位和线程状态
每个Java线程都需要有一个存储线程是否需要挂起的标志位变量,由于Java线程在ART虚拟机中都对应了一个art::Thread指针,因此,这个变量就保存在art::Thread类的state_and_flags成员变量中。
这个成员变量的值由两个枚举类ThreadFlag和ThreadState组成。
ThreadFlag枚举类中定义了CheckPoint相关的线程状态。
先看标志位的枚举类型:
art/runtime/thread.h
enum ThreadFlag {
kSuspendRequest = 1, // If set implies that suspend_count_ > 0 and the Thread should enter the
// safepoint handler.
kCheckpointRequest = 2, // Request that the thread do some checkpoint work and then continue.
kEmptyCheckpointRequest = 4, // Request that the thread do empty checkpoint and then continue.
kActiveSuspendBarrier = 8, // Register that at least 1 suspend barrier needs to be passed.
};
ThreadFlag中的几个枚举值定义了虚拟机使用check point机制的四种场景:
- kSuspendRequest:如果设置该标志,表示着suspend_count大于0,则要求线程进入到挂起状态;
- kCheckpointRequest:如果设置该标志,则请求当前线程执行check point任务,执行完成后继续原任务;
- kEmptyCheckpointRequest:如果设置该标志,则请求当前线程执行空的check point任务,执行完成后继续原任务;
- kActiveSuspendBarrier:如果设置该标志,则要求至少设置一个挂起栅栏给当前线程,这个标志只在设置了kSuspendRequest标志才生效,并且仅用于挂起所有线程(SuspendAll)的流程中。这个机制类似于Java多线程并发编程中的栅栏(CyclicBarrier)。
ThreadState枚举类中定义了虚拟机中线程所有可能的状态:
art/runtime/thread_state.h
enum ThreadState {
// Java
// Thread.State JDWP state
kTerminated = 66, // TERMINATED TS_ZOMBIE Thread.run has returned, but Thread* still around
//线程正常运行状态
kRunnable, // RUNNABLE TS_RUNNING runnable
//调用了Object.wait(),并设置了超时时长的状态
kTimedWaiting, // TIMED_WAITING TS_WAIT in Object.wait() with a timeout
//调用了Thread.sleep()进入sleep状态
kSleeping, // TIMED_WAITING TS_SLEEPING in Thread.sleep()
//被monitor阻塞,一般是尝试持有锁,但锁未被释放
kBlocked, // BLOCKED TS_MONITOR blocked on a monitor
//调用Object.wait()
kWaiting, // WAITING TS_WAIT in Object.wait()
kWaitingForLockInflation, // WAITING TS_WAIT blocked inflating a thin-lock
kWaitingForTaskProcessor, // WAITING TS_WAIT blocked waiting for taskProcessor
//等待GC完成
kWaitingForGcToComplete, // WAITING TS_WAIT blocked waiting for GC
//GC时等待检查点执行完成
kWaitingForCheckPointsToRun, // WAITING TS_WAIT GC waiting for checkpoints to run
//正在执行GC
kWaitingPerformingGc, // WAITING TS_WAIT performing GC
kWaitingForDebuggerSend, // WAITING TS_WAIT blocked waiting for events to be sent
kWaitingForDebuggerToAttach, // WAITING TS_WAIT blocked waiting for debugger to attach
//主线程等待调试器
kWaitingInMainDebuggerLoop, // WAITING TS_WAIT blocking/reading/processing debugger events
kWaitingForDebuggerSuspension, // WAITING TS_WAIT waiting for debugger suspend all
//等待dlopen和JNI_Onload执行完成
kWaitingForJniOnLoad, // WAITING TS_WAIT waiting for execution of dlopen and JNI on load code
kWaitingForSignalCatcherOutput, // WAITING TS_WAIT waiting for signal catcher IO to complete
kWaitingInMainSignalCatcherLoop, // WAITING TS_WAIT blocking/reading/processing signals
//等待HDeoptimization流程中挂起所有线程
kWaitingForDeoptimization, // WAITING TS_WAIT waiting for deoptimization suspend all
kWaitingForMethodTracingStart, // WAITING TS_WAIT waiting for method tracing to start
kWaitingForVisitObjects, // WAITING TS_WAIT waiting for visiting objects
kWaitingForGetObjectsAllocated, // WAITING TS_WAIT waiting for getting the number of allocated objects
kWaitingWeakGcRootRead, // WAITING TS_WAIT waiting on the GC to read a weak root
kWaitingForGcThreadFlip, // WAITING TS_WAIT waiting on the GC thread flip (CC collector) to finish
kNativeForAbort, // WAITING TS_WAIT checking other threads are not run on abort.
kStarting, // NEW TS_WAIT native thread started, not yet ready to run managed code
//正在执行JNI代码
kNative, // RUNNABLE TS_RUNNING running in a JNI native method
//挂起状态
kSuspended, // RUNNABLE TS_RUNNING suspended by GC or debugger
};
checkPoint相关的flag和线程状态相关的state,保存在art::Thread类StateAndFlags联合体中。
StateAndFlags联合体的定义如下:
art/runtime/thread.h
class Thread{
......
union PACKED(4) StateAndFlags {
StateAndFlags() {}
struct PACKED(4) {
volatile uint16_t flags; //跟Check Point机制相关的标志位,取值为ThreadFlag的值
volatile uint16_t state; //跟线程状态相关的状态位,取值为ThreadState的值
} as_struct;
AtomicInteger as_atomic_int;
volatile int32_t as_int;
};
......
};
数据结构StateAndFlags是一个联合体,长度为32位,包含三个身份:
- as_struct:包含两个长度为16位的成员,低16位为flags,这个就是跟Check Point机制相关的状态变量,取值来自于枚举类ThreadFlag,高16位为state,表示线程运行状态,取值来自于枚举类ThreadState;
- as_atomic_int: 用于整体设置as_struct的值,由于是原子操作,确保了线程安全;
- as_int: 用于整体设置as_struct的值,非线程安全;
线程挂起恢复流程
挂起函数
虚拟机中,挂起所有线程和挂起单个线程,分别调用了thread_list.cc文件中的SuspendAll()函数和SuspendThreadByThreadId()函数。这两个函数的核心流程都是调用了thread.cc中的ModifySuspendCountInternal函数,这个函数的实现如下:
bool Thread::ModifySuspendCountInternal(Thread* self,
int delta,
AtomicInteger* suspend_barrier,
SuspendReason reason) {
...
...
uint16_t flags = kSuspendRequest;
if (delta > 0 && suspend_barrier != nullptr) {
uint32_t available_barrier = kMaxSuspendBarriers;
for (uint32_t i = 0; i < kMaxSuspendBarriers; ++i) {
if (tlsPtr_.active_suspend_barriers[i] == nullptr) {
available_barrier = i;
break;
}
}
if (available_barrier == kMaxSuspendBarriers) {
// No barrier spaces available, we can't add another.
return false;
}
// 这个是挂起所有线程时,用于处理栅栏
tlsPtr_.active_suspend_barriers[available_barrier] = suspend_barrier;
flags |= kActiveSuspendBarrier;
}
tls32_.suspend_count += delta;
switch (reason) {
case SuspendReason::kForUserCode:
tls32_.user_code_suspend_count += delta;
break;
case SuspendReason::kInternal:
break;
}
if (tls32_.suspend_count == 0) {
AtomicClearFlag(kSuspendRequest);
} else {
// Two bits might be set simultaneously.
tls32_.state_and_flags.as_atomic_int.fetch_or(flags, std::memory_order_seq_cst);
TriggerSuspend();
}
return true;
}
ModifySuspendCountInternal函数的逻辑很好理解,要点有:
- 如果需要暂停线程,传入的参数delta设置为1,那么将会给线程的成员变量
state_and_flags设置kSuspendRequest这个flag,标识这个线程需要被挂起; - 如果需要恢复线程,传入的参数delta设置为-1,如果
tls32_.suspend_count + delta的值变成了0,则清除线程的kSuspendRequest标志位。
这个函数的另外一个参数suspend_barrier是用于挂起所有线程的,将suspend_barrier地址保存到每个需要挂起的线程中,并给线程设置kActiveSuspendBarrier标志位。每个线程挂起完成后,都会将suspend_barrier减去1,只要等到suspend_barrier的值为0,就可以知道所有线程都完成挂起。后面的SuspendAll流程中再详细分析这个过程。
另外, TriggerSupend() 是 Android 5.1 版本之前旧的实现,通过注释可以看到,这是隐式的触发suspend的实现,主要原理是通过一个空指针异常触发一个SIGSEGV信号,然后在 signal_handler中,切换到suspend check,进行suspend的。不过现在 ART 源码里已经找不到读取tlsPtr_.suspend_trigger的代码,这个逻辑已经被废弃。
从其代码注释中也可以看出来:
// Trigger a suspend check by making the suspend_trigger_ TLS value an invalid pointer.
// The next time a suspend check is done, it will load from the value at this address
// and trigger a SIGSEGV.
// Only needed if Runtime::implicit_suspend_checks_ is true and fully implemented. It currently
// is always false. Client code currently just looks at the thread flags directly to determine
// whether we should suspend, so this call is currently unnecessary.
void TriggerSuspend() {
tlsPtr_.suspend_trigger = nullptr;
}
CheckSuspend函数
在Android源码中搜索kSuspendRequest使用之处,仅发现三处,分别是函数:
CheckSuspend
TransitionFromSuspendedToRunnable
TransitionFromSuspendedToRunnable

这里,CheckSuspend函数是整个CheckPoint机制中最核心的一个函数。上文提到,无论是在解释执行或者机器码执行的流程中,都会注入检查点,这个检查点就是CheckSuspend函数。
CheckSuspend函数的实现如下:
inline void Thread::CheckSuspend() {
DCHECK_EQ(Thread::Current(), this);
for (;;) {
if (ReadFlag(kCheckpointRequest)) {
RunCheckpointFunction();
} else if (ReadFlag(kSuspendRequest)) {
FullSuspendCheck();
} else if (ReadFlag(kEmptyCheckpointRequest)) {
RunEmptyCheckpoint();
} else {
break;
}
}
}
逻辑比较简单,判断当前线程的state_and_flag是否设置kCheckpointRequest,kSuspendRequest,kEmptyCheckpointRequest这三个标志位,如果有设置,则分别做相应的处理。
它们的作用分别为:
kCheckpointRequest:调用函数RunCheckpointFunction(),执行Check Point闭包函数;kSuspendRequest:调用FullSuspendCheck(),将线程挂起;kEmptyCheckpointRequest:调用RunEmptyCheckpoint(),执行空的Check Point闭包函数;
先看看FullSuspendCheck函数中将线程挂起的实现过程。
线程挂起
如果线程设置了 kSuspendRequest标志位,则执行FullSuspendCheck(),这个函数的实现如下:
void Thread::FullSuspendCheck() {
ScopedTrace trace(__FUNCTION__);
VLOG(threads) << this << " self-suspending";
// Make thread appear suspended to other threads, release mutator_lock_.
// Transition to suspended and back to runnable, re-acquire share on mutator_lock_.
ScopedThreadSuspension(this, kSuspended); // NOLINT
VLOG(threads) << this << " self-reviving";
}
这个函数只是构造一个栈上的ScopedThreadSuspensio类的对象,这个对象的作用是:
- 在构造函数中调用了
TransitionFromRunnableToSuspended函数,将线程状态(state_and_flag中的state)从kRunnable切换到kSuspended - 在析构函数中调用了
TransitionFromSuspendedToRunnable函数,,将线程状态从kSuspended切换到kRunnable,这个过程可能会使线程进入等待状态,从而实现线程的挂起。
ScopedThreadSuspension类的构造函数和析构函数实现如下:
inline ScopedThreadSuspension::ScopedThreadSuspension(Thread* self, ThreadState suspended_state)
: self_(self), suspended_state_(suspended_state) {
DCHECK(self_ != nullptr);
self_->TransitionFromRunnableToSuspended(suspended_state);
}
inline ScopedThreadSuspension::~ScopedThreadSuspension() {
DCHECK_EQ(self_->GetState(), suspended_state_);
self_->TransitionFromSuspendedToRunnable();
}
TransitionFromRunnableToSuspended 函数
TransitionFromRunnableToSuspended函数的实现如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3xHmKJbu-1689525091854)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/b8a4d295715a4a77936a96b6d952a2e7~tplv-k3u1fbpfcp-zoom-1.image)]
这个函数主要调用了TransitionToSuspendedAndRunCheckpoints和mutator_lock的TransitionFromRunnableToSuspended()函数,其中前者实现线程状态到kSuspended的切换,后者是释放当前线程对mutator_lock_的 shared hold,Runnable状态的线程都会持有mutator_lock_,切换到Suspended状态时需要释放掉。
TransitionToSuspendedAndRunCheckpoints函数时实现如下:

这个函数最核心的内容就是通过CAS的方式将线程的state_and_flags成员变量设置 kSuspended的state,从而完成线程状态从kRunnable到kSuspended的切换。
在切换线程状态前,先判断是否设置了kCheckpointRequest标志位,如果有设置,则需要先执行Check Point闭包函数。这应该是为了避免线程挂起后,已设置的Check Point函数无法得到及时执行。
TransitionFromSuspendedToRunnable 函数
接下来,在ScopedThreadSuspension类的析构函数中调用了TransitionFromSuspendedToRunnable函数,最终实现线程的挂起。
源码如下:

根据函数名可知,这个函数会将线程状态从kSuspended切换为kRunnable。这个流程里会判断state_and_flags里的flag是否设置了kSuspendRequest标志位,如果设置,则通过调用 Thread::resume_cond_->Wait(thread_to_pass)函数使线程进入等待状态,完成线程的挂起操作。
挂起结束恢复线程时,在while循环退出前调用了 Locks::mutator_lock_->TransitionFromSuspendedToRunnable(this),通过shared方式持有全局锁mutator_lock_,使得Runnable状态的线程持有了这个锁,线程继续执行。
TransitionFromSuspendedToRunnable函数看起来很复杂,其实里面很多内容只不过是因为用了无锁编程而引入的”套路“代码。
线程恢复
线程恢复的流程比较简单。
恢复线程需要调用thread_list.cc中的Resume()函数,代码如下:

Resume函数中,先调用ModifySuspendCount将线程的suspend_count减1,然后再ModifySuspendCountInternal函数中,当线程的suspend_count等于0时,会清除线程state_and_flags的kSuspendRequest的标志位,清除挂起标志位后,调用Thread::resume_cond_->Broadcast()唤醒线程。
线程将从TransitionFromSuspendedToRunnable函数的Thread::resume_cond_->Wait()处被唤醒,开始继续原来的执行流程,并且线程的状态切换为kRunnable。
Wait 和 Broadcast 的实现原理
以上分析了线程挂起和恢复的流程,其中,
线程挂起调用的是Wait函数:
Thread::resume_cond_->Wait(thread_to_pass)
线程恢复调用的是Broadcast函数:
Thread::resume_cond_->Broadcast(self)
resume_cond_是类art::Thread中的静态成员变量,对应的类型是ConditionVariable:
class Thread {
...
// Used to notify threads that they should attempt to resume, they will suspend again if
// their suspend count is > 0.
static ConditionVariable* resume_cond_ GUARDED_BY(Locks::thread_suspend_count_lock_);
...
}
类ConditionVariable中Wait()函数的实现为:
[art/runtime/base/mutex.cc]

根据宏ART_USE_FUTUXES 来判断是使用futex系统调用挂起线程还是使用pthread_cond_wait来挂起。
显然,这里使用了futex,因为宏ART_USE_FUTUXES的定义如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zKZUFlxF-1689525091856)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/d44d5049c300457495937e308122d305~tplv-k3u1fbpfcp-zoom-1.image)]
另外,在Android的bionic库中,pthread_cond_wait最终实现其实也是futex系统调用:
[pthread_cond.cpp]
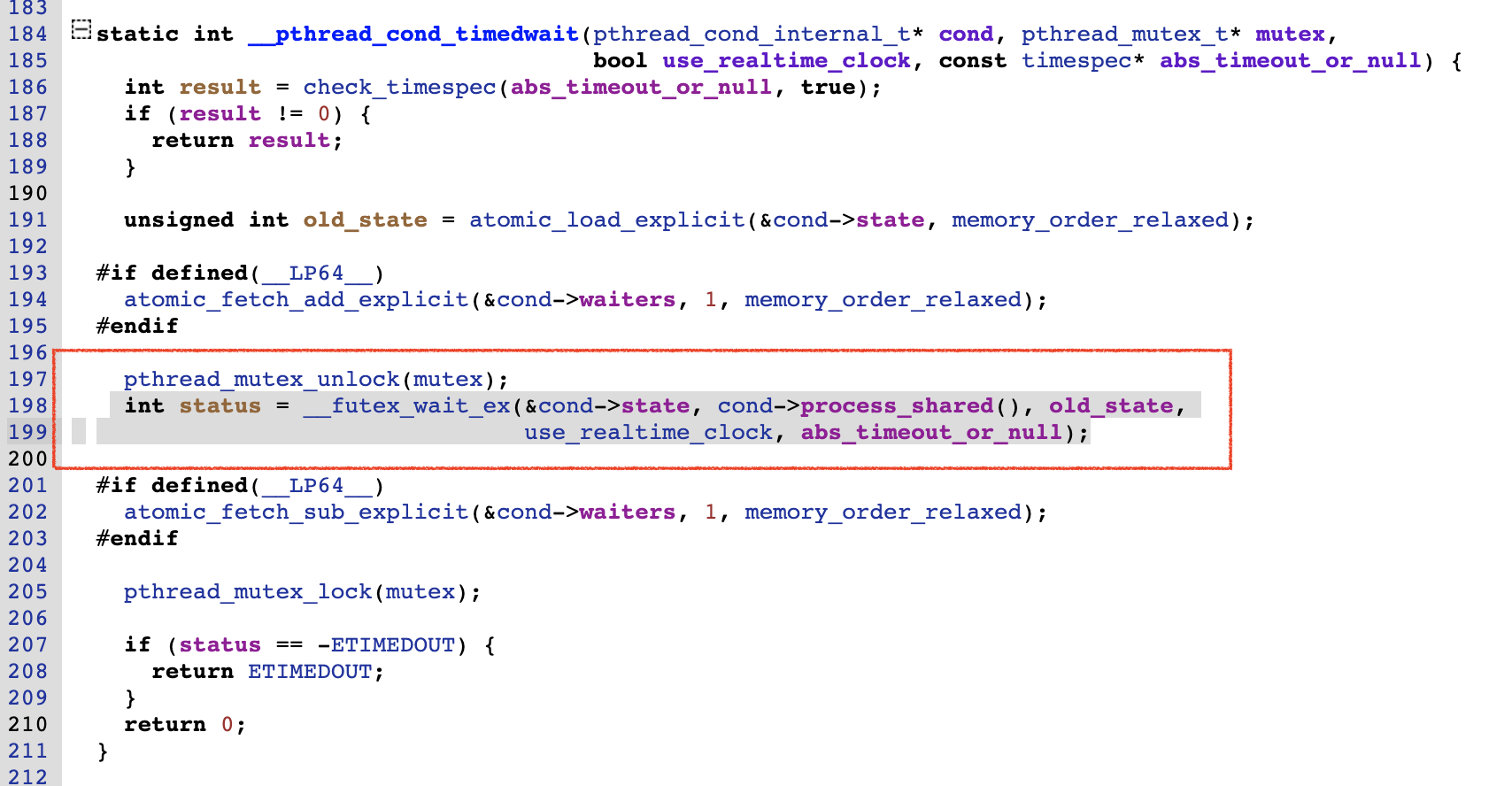
再看看线程恢复函数Broadcast的实现:
[art/runtime/base/mutex.cc]

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0YccCvng-1689525091858)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/4503d5d10fa84221a765979ed0047aaf~tplv-k3u1fbpfcp-zoom-1.image)]
最终也是调用的futex函数实现的,跟挂起时相比,只是传入的flag不相同而已。
线程挂起时,调用futex传入flag:
FUTEX_WAIT_PRIVATE,实现线程等待;线程恢复时,调用futex传入flag:
FUTEX_REQUEUE_PRIVATE,实现线程唤醒;
这两个宏定义在futex.h头文件中:
#define FUTEX_WAIT 0 // 等待
#define FUTEX_WAKE 1 // 唤醒
#define FUTEX_REQUEUE 3 // 类似基本的唤醒动作
#define FUTEX_PRIVATE_FLAG 128
#define FUTEX_WAIT_PRIVATE (FUTEX_WAIT | FUTEX_PRIVATE_FLAG)
#define FUTEX_WAKE_PRIVATE (FUTEX_WAKE | FUTEX_PRIVATE_FLAG)
#define FUTEX_REQUEUE_PRIVATE (FUTEX_REQUEUE | FUTEX_PRIVATE_FLAG)
Futex是linux上一种用户态和内核态混合的同步机制,支持进程内的线程之间和进程间的同步锁操作。
futex原理可参考文档:linux–futex原理分析
至此,完成的线程挂起和恢复的流程分析。
SuspendAll和ResumeAll
SuspendAll用于暂停所有Java线程的执行,而ResumeAll用于恢复所有Java线程的执行。
下面分别介绍这两个函数的实现过程。
SuspendAll流程
SuspendAll函数最终调用到了SuspendAllInternal函数,这个函数的具体实现如下:
art/runtime/thread_list.cc
void ThreadList::SuspendAllInternal(Thread* self,
Thread* ignore1,
Thread* ignore2,
SuspendReason reason) {
// The atomic counter for number of threads that need to pass the barrier.
AtomicInteger pending_threads;
uint32_t num_ignored = 0;
if (ignore1 != nullptr) {
++num_ignored;
}
if (ignore2 != nullptr && ignore1 != ignore2) {
++num_ignored;
}
{
MutexLock mu(self, *Locks::thread_list_lock_);
MutexLock mu2(self, *Locks::thread_suspend_count_lock_);
// Update global suspend all state for attaching threads.
++suspend_all_count_;
// 步骤一:设置pending_threads值为线程数量,主要要剔除忽略的线程
pending_threads.store(list_.size() - num_ignored, std::memory_order_relaxed);
// Increment everybody's suspend count (except those that should be ignored).
for (const auto& thread : list_) {
if (thread == ignore1 || thread == ignore2) {
continue;
}
VLOG(threads) << "requesting thread suspend: " << *thread;
// 步骤二: 通知每个线程准备挂起,注意这里传入了pending_threads的地址,这将触发设置kActiveSuspendBarrier标志,用于等待栅栏
bool updated = thread->ModifySuspendCount(self, +1, &pending_threads, reason);
DCHECK(updated);
// Must install the pending_threads counter first, then check thread->IsSuspend() and clear
// the counter. Otherwise there's a race with Thread::TransitionFromRunnableToSuspended()
// that can lead a thread to miss a call to PassActiveSuspendBarriers().
if (thread->IsSuspended()) {
// Only clear the counter for the current thread.
thread->ClearSuspendBarrier(&pending_threads);
pending_threads.fetch_sub(1, std::memory_order_seq_cst);
}
}
}
// Wait for the barrier to be passed by all runnable threads. This wait
// is done with a timeout so that we can detect problems.
#if ART_USE_FUTEXES
timespec wait_timeout;
InitTimeSpec(false, CLOCK_MONOTONIC, NsToMs(thread_suspend_timeout_ns_), 0, &wait_timeout);
#endif
const uint64_t start_time = NanoTime();
while (true) {
// 获取pending_threads中的值是否为0,为0则所有线程挂起完成,不为0,则调用futex继续等待,等待线程挂起完成后调用futxt FUTEX_WAKE_PRIVATE幻唤醒这里的等待
int32_t cur_val = pending_threads.load(std::memory_order_relaxed);
if (LIKELY(cur_val > 0)) {
if (futex(pending_threads.Address(), FUTEX_WAIT_PRIVATE, cur_val, &wait_timeout, nullptr, 0)
!= 0) {
......
} else {
PLOG(FATAL) << "futex wait failed for SuspendAllInternal()";
}
} // else re-check pending_threads in the next iteration (this may be a spurious wake-up).
} else {
CHECK_EQ(cur_val, 0);
break;
}
}
}
这个函数的核心逻辑包含三部分,分别是:
- 将需要挂起的线程数量设置到
pending_threads变量中,此变量起到栅栏作用,用于等待所有线程的挂起完成; - 遍历所有线程,调用针对每个线程调用
ModifySuspendCount函数,传入pending_threads的地址,将线程的suspend_cout加1,设置kSuspendRequest标志,并且设置kActiveSuspendBarrier标志(表示此次挂起需要等待栅栏); - 等待所有线程挂起完成,方法是在循环语句中检测
pending_threads值是否为0,不为0则通过futex系统调用继续等待,直到等于0,则所有线程挂起成功,完成SuspendAll的流程;
SuspendAllInternal函数跟Suspend单个线程的核心不同点是SuspendBarrier的栅栏处理流程。
挂起多个线程,需要使用栅栏等待所有线程完成挂起,挂起完成后通知到调用侧。
每个线程执行到Check Point后完成本线程的挂起,同时也要处理栅栏。此时,会调用art::Thread的PassActiveSuspendBarriers函数。
PassActiveSuspendBarriers源码如下:
art/runtime/Thread.cc
bool Thread::PassActiveSuspendBarriers(Thread* self) {
......
uint32_t barrier_count = 0;
for (uint32_t i = 0; i < kMaxSuspendBarriers; i++) {
AtomicInteger* pending_threads = pass_barriers[i];
if (pending_threads != nullptr) {
bool done = false;
do {
int32_t cur_val = pending_threads->load(std::memory_order_relaxed);
CHECK_GT(cur_val, 0) << "Unexpected value for PassActiveSuspendBarriers(): " << cur_val;
// Reduce value by 1.
done = pending_threads->CompareAndSetWeakRelaxed(cur_val, cur_val - 1);
if (done && (cur_val - 1) == 0) { // Weak CAS may fail spuriously.
futex(pending_threads->Address(), FUTEX_WAKE_PRIVATE, INT_MAX, nullptr, nullptr, 0);
}
} while (!done);
++barrier_count;
}
}
CHECK_GT(barrier_count, 0U);
return true;
}
这个函数其实很简单,主要包含两个逻辑:
- 将调用SuspendAllInternal时传入本线程的计数器
pending_threads指针变量的值减1; - 当
pending_threads减小到0时,调用futex FUTEX_WAKE_PRIVATE,唤醒调用SuspendAllInternal的线程,通知它所有线程已完成挂起;
ResumeAll流程
ResumeAll用于恢复所有暂停线程,使其继续执行。
由于这里并不用等待暂停线程的状态变更,所以实现非常简单,跟恢复单个线程执行的流程基本一致。
核心逻辑就两条:
- thread->ModifySuspendCount:将所有线程的
suspend_count减1,如果suspend_count等于0,则清除线程state_and_flags的kSuspendRequest的标志; - Thread::resume_cond_->Broadcast:通知所有线程,如果线程的
state_and_flags的kSuspendRequest的标志被清除就立即恢复执行;
源码如下:
art/runtime/thread_list.cc
void ThreadList::ResumeAll() {
Thread* self = Thread::Current();
......
long_suspend_ = false;
Locks::mutator_lock_->ExclusiveUnlock(self);
{
MutexLock mu(self, *Locks::thread_list_lock_);
MutexLock mu2(self, *Locks::thread_suspend_count_lock_);
// Update global suspend all state for attaching threads.
--suspend_all_count_;
// Decrement the suspend counts for all threads.
for (const auto& thread : list_) {
if (thread == self) {
continue;
}
bool updated = thread->ModifySuspendCount(self, -1, nullptr, SuspendReason::kInternal);
DCHECK(updated);
}
......
Thread::resume_cond_->Broadcast(self);
}
}
执行CheckPoint闭包任务
在上面CheckSuspend()函数的分析中,如果线程的state_and_flag变量设置了kCheckpointRequest标志位,则会调用RunCheckpointFunction()函数,执行检查点任务。
下面详细分析此流程。
执行Closure任务流程
RunCheckpointFunction函数的代码如下:art/runtime/thread.cc
Closure* checkpoint_function GUARDED_BY(Locks::thread_suspend_count_lock_);
// Pending extra checkpoints if checkpoint_function_ is already used.
std::list<Closure*> checkpoint_overflow_ GUARDED_BY(Locks::thread_suspend_count_lock_);
void Thread::RunCheckpointFunction() {
Closure* checkpoint;
{
MutexLock mu(this, *Locks::thread_suspend_count_lock_);
checkpoint = tlsPtr_.checkpoint_function;
if (!checkpoint_overflow_.empty()) {
// Overflow list not empty, copy the first one out and continue.
tlsPtr_.checkpoint_function = checkpoint_overflow_.front();
checkpoint_overflow_.pop_front();
} else {
// No overflow checkpoints. Clear the kCheckpointRequest flag
tlsPtr_.checkpoint_function = nullptr;
AtomicClearFlag(kCheckpointRequest);
}
}
checkpoint->Run(this); // 执行Check Point任务
}
这个函数的实现并不复杂,主要包含两点:
- 保存线程成员变量
checkpoint_function到checkpoint指针中,并执行这个Closure任务; - 将线程成员变量
checkpoint_overflow_这个list中的头部元素取出保存到checkpoint_function中,下次继续执行这个Closure任务,如果list中任务已经消费完,则清除线程的kCheckpointRequest标志;
其中,
线程的checkpoint_function变量:保存了当前需要执行的Closure任务
线程的list变量checkpoint_overflow_:保存了下次需要执行的所有Closure任务。
这里,Closure是一个非常简单的纯虚类,内部仅包含一个析构函数和一个虚函数Run(),有点类似于Java的Runnable接口:
class Closure {
public:
virtual ~Closure() { }
virtual void Run(Thread* self) = 0;
};
设置Closure任务
下面看看如何设置Closure任务。
thread.cc中有两个可设置Closure任务的函数:RequestSynchronousCheckpoint和RequestCheckpoint。
前者是同步的,也就是设置后,当前线程会等待目标线程Closure任务执行完成。
后者是异步的,只给线程设置Closure任务,不关心执行完成的时间。
这里介绍下RequestCheckpoint的实现。
其源码如下:art/runtime/thread.cc
bool Thread::RequestCheckpoint(Closure* function) {
union StateAndFlags old_state_and_flags;
old_state_and_flags.as_int = tls32_.state_and_flags.as_int;
if (old_state_and_flags.as_struct.state != kRunnable) {
return false; // Fail, thread is suspended and so can't run a checkpoint.
}
// We must be runnable to request a checkpoint.
DCHECK_EQ(old_state_and_flags.as_struct.state, kRunnable);
union StateAndFlags new_state_and_flags;
new_state_and_flags.as_int = old_state_and_flags.as_int;
new_state_and_flags.as_struct.flags |= kCheckpointRequest;
bool success = tls32_.state_and_flags.as_atomic_int.CompareAndSetStrongSequentiallyConsistent(
old_state_and_flags.as_int, new_state_and_flags.as_int);
if (success) {
// Succeeded setting checkpoint flag, now insert the actual checkpoint.
if (tlsPtr_.checkpoint_function == nullptr) {
tlsPtr_.checkpoint_function = function;
} else {
checkpoint_overflow_.push_back(function);
}
CHECK_EQ(ReadFlag(kCheckpointRequest), true);
// 隐式suspendCheck方法,过时代码
TriggerSuspend();
}
return success;
}
这个函数的要点有:
- 线程的状态如果非
kRunnable,则无法设置Closure任务,返回false; - 给线程设置
kCheckpointRequest的标志位; - 如果线程的
checkpoint_function为空,则将任务保存到里面,如果非空,则保存到这个list中checkpoint_overflow_;
所有线程执行Closure任务
在thread_list.cc中,还有一个函数可以设置所有线程执行某个Closure任务:RunCheckpoint。
RunCheckpoint函数的要点有:
- 遍历所有Java线程,针对每个线程调用
RequestCheckpoint函数,设置线程的Closure任务; - 如果线程是非
kRunnable状态,RequestCheckpoint会设置任务失败,此时会调用ModifySuspendCount函数尝试挂起线程,并轮训等待线程挂起完成,挂起成功后将线程指针保存到suspended_count_modified_threads这个vector中; - 遍历保存了挂起线程的vector:
suspended_count_modified_threads,在本线程执行Closure任务,然后恢复线程的执行。
代码如下:
art/runtime/thread_list.cc
size_t ThreadList::RunCheckpoint(Closure* checkpoint_function, Closure* callback) {
Thread* self = Thread::Current();
......
std::vector<Thread*> suspended_count_modified_threads;
size_t count = 0;
{
......
count = list_.size();
for (const auto& thread : list_) {
if (thread != self) {
bool requested_suspend = false;
while (true) {
if (thread->RequestCheckpoint(checkpoint_function)) {
// This thread will run its checkpoint some time in the near future.
if (requested_suspend) {
// The suspend request is now unnecessary.
bool updated =
thread->ModifySuspendCount(self, -1, nullptr, SuspendReason::kInternal);
DCHECK(updated);
requested_suspend = false;
}
break;
} else {
// The thread is probably suspended, try to make sure that it stays suspended.
if (thread->GetState() == kRunnable) {
// Spurious fail, try again.
continue;
}
if (!requested_suspend) {
// 尝试挂起线程
bool updated =
thread->ModifySuspendCount(self, +1, nullptr, SuspendReason::kInternal);
DCHECK(updated);
requested_suspend = true;
if (thread->IsSuspended()) {
break;
}
} else {
DCHECK(thread->IsSuspended());
break;
}
}
}
if (requested_suspend) {
suspended_count_modified_threads.push_back(thread);
}
}
}
// Run the callback to be called inside this critical section.
if (callback != nullptr) {
callback->Run(self);
}
}
// Run the checkpoint on ourself while we wait for threads to suspend.
checkpoint_function->Run(self);
// Run the checkpoint on the suspended threads.
for (const auto& thread : suspended_count_modified_threads) {
// We know for sure that the thread is suspended at this point.
DCHECK(thread->IsSuspended()); // 所有线程都要进入suspend状态
checkpoint_function->Run(thread);
{
MutexLock mu2(self, *Locks::thread_suspend_count_lock_);
// 恢复线程执行
bool updated = thread->ModifySuspendCount(self, -1, nullptr, SuspendReason::kInternal);
}
}
{
MutexLock mu2(self, *Locks::thread_suspend_count_lock_);
Thread::resume_cond_->Broadcast(self);
}
return count;
}
通过RunCheckpoint可知,它会要求所有线程都执行指定的Closure任务,假如某些线程非Runnable状态(比如kSuspend状态),无法执行Closure任务,则由调用者来代替这些线程执行Closure任务,即是在调用者线程里直接调用Run函数,并传入真正的目标线程对象。
哪些情况下会用到这种强操作呢?
比如,应用程序的某些重要线程阻塞了,但我们又需要打印所有线程的调用栈信息以协助排查问题。显然,让阻塞的线程从阻塞处退出并进入CheckPoint点以执行打印调用栈是不现实的。此时,RunCheckpoint的这种处理方式就派上用场了。
源码中Check Point闭包使用案例
打印线程调用堆栈:DumpCheckPoint
当App发生ANR时,会发送一个SIGQUIT信号,在信号处理器SignalCatcher中,监听到SIGQUIT后,调用了signal_catcher的HandleSigQuit()函数,代码如下:
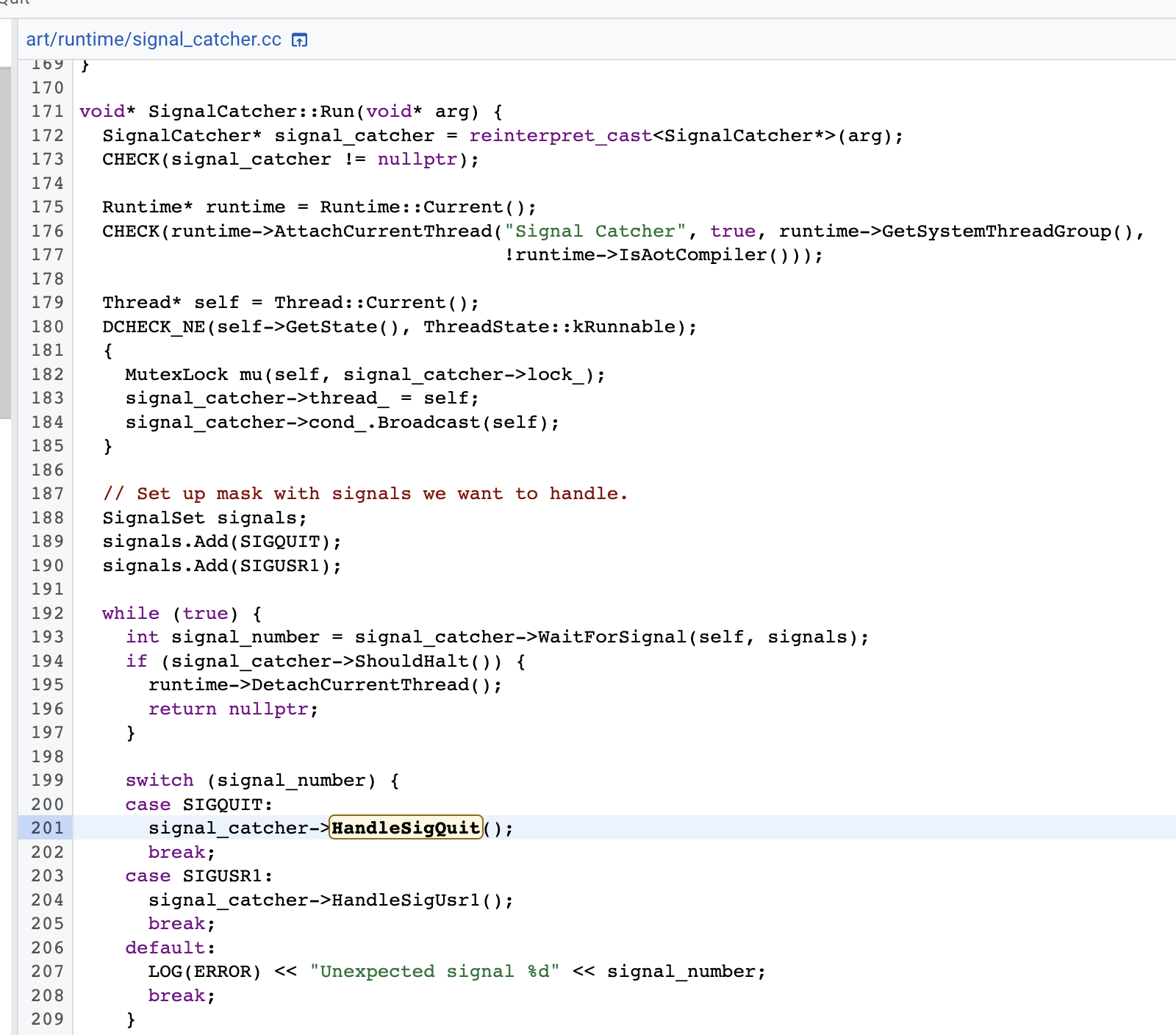
在HandleSigQuit函数中,调用了runtime的DumpForSigQuit函数

在Runtime的DumpForSigQuit函数中,调用了thread_list.cc中的DumpForSigQuit函数,打印所有线程的调用堆栈,包括Java线程和native线程:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BKI7tB6X-1689525091860)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/eb815404d8bc49779a321fbeb524d95f~tplv-k3u1fbpfcp-zoom-1.image)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J4rm06VS-1689525091860)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/973acae84bc24d13a604864cf79a35f9~tplv-k3u1fbpfcp-zoom-1.image)]
DumpForSigQuit函数最终调用了thread_list.cc中的Dump函数打印线程堆栈,Dump函数中,构造了一个DumpCheckPoint类型的闭包任务,然后调用RunCheckPoint函数,通知所有Java线程执行这个闭包任务(挂起的线程在当前线程中执行闭包),代码如下:

上面已经介绍RunCheckPoint函数的执行流程,这里重点介绍下thread_list.cc中的DumpCheckPoint这个类的具体实现。
DumpCheckpoint继承了纯虚类Closure,实现了虚函数Run函数,在Run函数中调用Thread的Dump函数输出当前线程的调用堆栈。
DumpCheckpoint类中,比较难理解的点是成员变量barrier_以及函数WaitForThreadsToRunThroughCheckpoint。这里重点介绍下。
Barrier这个词的本意是栅栏,在ART虚拟机中,它是当做多线程同步计数器来使用。比如,有6个线程,其中一个线程需要等待其他5个线程执行完某个任务才能返回,这种情形下,就可以使用Barrier来实现。
具体用法如下:
- 创建一个
Barrier对象,设置初始值为5,并将这个对象传递给另外5个线程; - 这5个线程执行完任务后,调用
Barrier的Pass函数,该函数会将Barrier的计数器减1; - 第6个线程将等待着这个
Barrier对象,直到其计数器变成0;
在thread_list.cc的Dump函数中,调用了RunCheckPoint,根据上面的分析,这个函数会返回需要执行check point任务的线程数量,然后将这个数量传给WaitForThreadsToRunThroughCheckpoint函数,将barrier_的计数器加上线程的数量,并等待barrier_计数器减少到0。
而在DumpCheckpoint的Run函数中,执行完后会将barrier_的计数器减去1,变成0后,说明所有线程的DumpCheckpoint都执行完,WaitForThreadsToRunThroughCheckpoint函数从barrier_.Increment处开始恢复执行,代码如下:
// A closure used by Thread::Dump.
class DumpCheckpoint final : public Closure {
public:
DumpCheckpoint(std::ostream* os, bool dump_native_stack)
: os_(os),
barrier_(0, /*verify_count_on_shutdown=*/false),
backtrace_map_(dump_native_stack ? BacktraceMap::Create(getpid()) : nullptr),
dump_native_stack_(dump_native_stack) {
if (backtrace_map_ != nullptr) {
backtrace_map_->SetSuffixesToIgnore(std::vector<std::string> { "oat", "odex" });
}
}
void Run(Thread* thread) override {
// Note thread and self may not be equal if thread was already suspended at the point of the
// request.
Thread* self = Thread::Current();
CHECK(self != nullptr);
std::ostringstream local_os;
{
ScopedObjectAccess soa(self);
// 调用Thread的Dump函数,打印调用堆栈信息
thread->Dump(local_os, dump_native_stack_, backtrace_map_.get());
}
{
// Use the logging lock to ensure serialization when writing to the common ostream.
MutexLock mu(self, *Locks::logging_lock_);
*os_ << local_os.str() << std::endl;
}
// 完成check point任务后,调用Pass,barrier_计数器减1,这个计数器初始为0,因此,可能是一个负数,也可能是正数
barrier_.Pass(self);
}
void WaitForThreadsToRunThroughCheckpoint(size_t threads_running_checkpoint) {
Thread* self = Thread::Current();
ScopedThreadStateChange tsc(self, kWaitingForCheckPointsToRun);
// barrier_在这里等待计数器变成0,或者等待超时,这里传入的threads_running_checkpoint等于所有需要执行check point任务的线程数
bool timed_out = barrier_.Increment(self, threads_running_checkpoint, kDumpWaitTimeout);
if (timed_out) {
LOG((kIsDebugBuild && (gAborting == 0)) ? ::android::base::FATAL : ::android::base::ERROR)
<< "Unexpected time out during dump checkpoint.";
}
}
private:
std::ostream* const os_;
// The barrier to be passed through and for the requestor to wait upon.
Barrier barrier_;
// A backtrace map, so that all threads use a shared info and don't reacquire/parse separately.
std::unique_ptr<BacktraceMap> backtrace_map_;
const bool dump_native_stack_;
};
这里使用Barrier的原因是,在RunCheckPoint函数中,如果线程是kRunnable状态,则会将check point任务丢到该线程的check point点处,在本线程中执行。因此,需要Dump线程等待其他线程执行完check point任务。
Jit垃圾回收:MarkCodeClosure
在JIT流程中,有一个类JitCodeCache,它提供了一个存储空间,用于存放JIT编译的结果。当编译结果超过一定的阈值时(大约是64M),该部分空间会被释放,也就是JIT的GC过程。
对于JIT的GC而言,使用的算是Mark-Sweep,即标记清除法。
标记时,需要判断所有线程的正在执行的方法栈是否有使用到JIT编译的机器码,如果有,则标记这些方法对应的code cache,清除时忽略这些方法对应的机器码。
JIT GC的标记对应的函数是jit_code_cache.cc中的 MarkCompiledCodeOnThreadStacks,这个函数具体实现如下:
void JitCodeCache::MarkCompiledCodeOnThreadStacks(Thread* self) {
Barrier barrier(0);
size_t threads_running_checkpoint = 0;
// 构造一个MarkCodeClosure
MarkCodeClosure closure(this, GetLiveBitmap(), &barrier);
// 让所有Java线程执行这个Closure
threads_running_checkpoint = Runtime::Current()->GetThreadList()->RunCheckpoint(&closure);
// Now that we have run our checkpoint, move to a suspended state and wait
// for other threads to run the checkpoint.
ScopedThreadSuspension sts(self, kSuspended);
if (threads_running_checkpoint != 0) {
// 等待所有线程的Closure任务都执行完成
barrier.Increment(self, threads_running_checkpoint);
}
}
这里的代码逻辑跟ThreadList::Dump()中使用DumpCheckPoint的流程基本一致,先是构造一个Check point的Closure类,然后调用ThreadList的RunCheckpoint函数让所有线程执行这个Closure,最后,通过barrier等待每个线程的Closure执行完成。
在MarkCodeClosure的Run函数中,通过StackVisitor遍历线程的当前调用栈,如果有quick_code,则判断quick_code是否在jit_code_cache中,如果在,则在CodeCacheBitmap中标记当前quick_code的地址。在JIT的GC的清除阶段,就不清除对应的机器码。
代码如下:
class MarkCodeClosure final : public Closure {
public:
MarkCodeClosure(JitCodeCache* code_cache, CodeCacheBitmap* bitmap, Barrier* barrier)
: code_cache_(code_cache), bitmap_(bitmap), barrier_(barrier) {}
void Run(Thread* thread) override REQUIRES_SHARED(Locks::mutator_lock_) {
ScopedTrace trace(__PRETTY_FUNCTION__);
DCHECK(thread == Thread::Current() || thread->IsSuspended());
StackVisitor::WalkStack(
[&](const art::StackVisitor* stack_visitor) {
const OatQuickMethodHeader* method_header =
stack_visitor->GetCurrentOatQuickMethodHeader();
if (method_header == nullptr) {
return true;
}
const void* code = method_header->GetCode();
// 判断当前线程栈中的机器码是否在jit code cache中
if (code_cache_->ContainsPc(code) && !code_cache_->IsInZygoteExecSpace(code)) {
// Use the atomic set version, as multiple threads are executing this code.
bitmap_->AtomicTestAndSet(FromCodeToAllocation(code));
}
return true;
},
thread,
/* context= */ nullptr,
art::StackVisitor::StackWalkKind::kSkipInlinedFrames);
if (kIsDebugBuild) {
// The stack walking code queries the side instrumentation stack if it
// sees an instrumentation exit pc, so the JIT code of methods in that stack
// must have been seen. We check this below.
for (const auto& it : *thread->GetInstrumentationStack()) {
// The 'method_' in InstrumentationStackFrame is the one that has return_pc_ in
// its stack frame, it is not the method owning return_pc_. We just pass null to
// LookupMethodHeader: the method is only checked against in debug builds.
OatQuickMethodHeader* method_header =
code_cache_->LookupMethodHeader(it.second.return_pc_, /* method= */ nullptr);
if (method_header != nullptr) {
const void* code = method_header->GetCode();
CHECK(bitmap_->Test(FromCodeToAllocation(code)));
}
}
}
// barrier_的计数器减1
barrier_->Pass(Thread::Current());
}
private:
JitCodeCache* const code_cache_;
CodeCacheBitmap* const bitmap_;
Barrier* const barrier_;
};
检查点(CheckPPoint)的插入流程
上面分析了挂起函数的实现,当主动触发线程挂起时,并没有直接让线程暂停执行,而仅仅是将线程的state_and_flags设置了kSuspendRequest标志位,最终是在Thread::CheckSuspend()函数中执行的线程挂起操作。
那么Thread::CheckSuspend()函数又是在何时何处被调用的呢?
答案是,在Check Point(检查点)中被执行的。在Java代码正常执行的过程中,会插入一些检查点,当代码执行到检查点时,会挂起当前线程,而执行其他任务,这些其他任务包括:垃圾回收、Debug、获取调用栈等等。
在ART虚拟机中,检查点存在下面几个位置(解释执行和机器码执行略有区别):
- 方法结束时
- 条件语句分支
- for\while 循环一次结束的出口
- 抛出异常的地方
下面分别分析解释执行和机器码执行流程中,检查点是如何被插入的。
解释执行
先看看解释执行中的检查点。
[art/runtime/interpreter/interpreter_switch_impl-inl.h]
- 异常处理流程中的检查点:

- 方法返回流程中的检查点:

- Goto, switch等跳转中的检查点:

其中 Self()->AllowThreadSuspension() 就是挂起线程的检查点,它最终会执行到 Thread::CheckSuspend() 中,这里的 Self() 就是当前的Thread指针,代码如下:
[art/runtime/thread-inl.h]
inline void Thread::AllowThreadSuspension() {
DCHECK_EQ(Thread::Current(), this);
if (UNLIKELY(TestAllFlags())) {
CheckSuspend();
}
// Invalidate the current thread's object pointers (ObjPtr) to catch possible moving GC bugs due
// to missing handles.
PoisonObjectPointers();
}
可以看到,最终调到了CheckSuspend函数。
机器码执行
字节指令的机器码是在dex2oat或者jit流程中编译生成的,在编译器生成quick code时,会在生成代码的各个流程中插入调用CheckSuspend函数的指令。
生成机器码流程
这里以arm64位指令生成过程为例,介绍机器码生成过程中,是如何插入CheckSuspend函数的相关指令。
机器码中的检查点跟解释执行模式稍有不同,主要安装在以下位置:
- 函数入口设置一个检查点;
- 循环头(Loop Handler)设置一个检查点;
- HGoTo IR处理中,如果存在往回跳转的情况,也会设置一个检查点;
具体来说,构造IR时,在HInstructionBuilder的Build函数中,在以下两处添加SuspendCheck的IR:
- Entry Block中设置一个检查点,其中
HSuspendCheck是用于生成检查点机器码对应的IR; - Loop Header Block中设置一个
HSuspendCheck;
代码如下:
art/compiler/optimizing/instruction_builder.cc
bool HInstructionBuilder::Build() {
......
for (HBasicBlock* block : graph_->GetReversePostOrder()) {
current_block_ = block;
uint32_t block_dex_pc = current_block_->GetDexPc();
InitializeBlockLocals();
if (current_block_->IsEntryBlock()) {
InitializeParameters();
AppendInstruction(new (allocator_) HSuspendCheck(0u));
AppendInstruction(new (allocator_) HGoto(0u));
continue;
} else if (current_block_->IsExitBlock()) {
AppendInstruction(new (allocator_) HExit());
continue;
} else if (current_block_->IsLoopHeader()) {
HSuspendCheck* suspend_check = new (allocator_) HSuspendCheck(current_block_->GetDexPc());
current_block_->GetLoopInformation()->SetSuspendCheck(suspend_check);
// This is slightly odd because the loop header might not be empty (TryBoundary).
// But we're still creating the environment with locals from the top of the block.
InsertInstructionAtTop(suspend_check);
}
if (block_dex_pc == kNoDexPc || current_block_ != block_builder_->GetBlockAt(block_dex_pc)) {
// Synthetic block that does not need to be populated.
DCHECK(IsBlockPopulated(current_block_));
continue;
}
......
}
.....
return true;
}
最终生成机器码时,在CodeGenerator中,会针对HSuspendCheck和HGoTo IR生成与检查点相关的机器码,代码如下:
art/compiler/optimizing/code_generator_arm64.cc
void InstructionCodeGeneratorARM64::VisitSuspendCheck(HSuspendCheck* instruction) {
HBasicBlock* block = instruction->GetBlock();
// 如果是因为循环而设置的HSuspendCheck,则统一放到HGoTo IR的处理流程中操作
if (block->GetLoopInformation() != nullptr) {
DCHECK(block->GetLoopInformation()->GetSuspendCheck() == instruction);
// The back edge will generate the suspend check.
return;
}
// 根据上面的HInstructionBuilder::Build函数可知,在Entry Block的处理中,会先添加一个HSuspendCheck IR
// 再添加一个HGoTo IR。由于HGoTo IR中也会添加检查点,因此这里的EntryBlock就不添加
if (block->IsEntryBlock() && instruction->GetNext()->IsGoto()) {
// The goto will generate the suspend check.
return;
}
// 生成检查点相关的机器码
GenerateSuspendCheck(instruction, nullptr);
codegen_->MaybeGenerateMarkingRegisterCheck(/* code= */ __LINE__);
}
在HGoTo IR中,也有HSuspendCheck的处理流程,这里针对循环回跳和Entry Block分别设置了检查点:
art/compiler/optimizing/code_generator_arm64.cc
void InstructionCodeGeneratorARM64::VisitGoto(HGoto* got) {
HandleGoto(got, got->GetSuccessor());
}
void InstructionCodeGeneratorARM64::HandleGoto(HInstruction* got, HBasicBlock* successor) {
if (successor->IsExitBlock()) {
DCHECK(got->GetPrevious()->AlwaysThrows());
return; // no code needed
}
HBasicBlock* block = got->GetBlock();
HInstruction* previous = got->GetPrevious();
HLoopInformation* info = block->GetLoopInformation();
// 针对循环回跳,设置一个检查点
if (info != nullptr && info->IsBackEdge(*block) && info->HasSuspendCheck()) {
codegen_->MaybeIncrementHotness(/* is_frame_entry= */ false);
GenerateSuspendCheck(info->GetSuspendCheck(), successor);
return;
}
// 针对Entry Block设置一个检查点
if (block->IsEntryBlock() && (previous != nullptr) && previous->IsSuspendCheck()) {
GenerateSuspendCheck(previous->AsSuspendCheck(), nullptr);
codegen_->MaybeGenerateMarkingRegisterCheck(/* code= */ __LINE__);
}
if (!codegen_->GoesToNextBlock(block, successor)) {
__ B(codegen_->GetLabelOf(successor));
}
}
再看看GenerateSuspendCheck()函数中生成SuspendCheck函数调用对应的指令的步骤,主要包括三个步骤:
- 创建一个
SuspendCheckSlowPathARM64对象; - 根据线程的
state_and_flag成员变量的偏移,并生成ldhr指令; - 生成cbnz或者cnd指令;
art/compiler/optimizing/code_generator_arm64.cc
void InstructionCodeGeneratorARM64::GenerateSuspendCheck(HSuspendCheck* instruction,
HBasicBlock* successor) {
SuspendCheckSlowPathARM64* slow_path =
down_cast<SuspendCheckSlowPathARM64*>(instruction->GetSlowPath());
if (slow_path == nullptr) {
slow_path =
new (codegen_->GetScopedAllocator()) SuspendCheckSlowPathARM64(instruction, successor);
instruction->SetSlowPath(slow_path);
codegen_->AddSlowPath(slow_path);
if (successor != nullptr) {
DCHECK(successor->IsLoopHeader());
}
} else {
DCHECK_EQ(slow_path->GetSuccessor(), successor);
}
UseScratchRegisterScope temps(codegen_->GetVIXLAssembler());
Register temp = temps.AcquireW();
// 生成机器码里,需要先获取线程的tls32.state_and_flag是否被设置,如果是,才执行SuspendCheck函数
__ Ldrh(temp, MemOperand(tr, Thread::ThreadFlagsOffset<kArm64PointerSize>().SizeValue()));
if (successor == nullptr) {
__ Cbnz(temp, slow_path->GetEntryLabel());
__ Bind(slow_path->GetReturnLabel());
} else {
__ Cbz(temp, codegen_->GetLabelOf(successor));
__ B(slow_path->GetEntryLabel());
// slow_path will return to GetLabelOf(successor).
}
}
再看看SuspendCheckSlowPathARM64这个类,检查点对应的机器码在这个类的EmitNativeCode函数生成:
class SuspendCheckSlowPathARM64 : public SlowPathCodeARM64 {
public:
SuspendCheckSlowPathARM64(HSuspendCheck* instruction, HBasicBlock* successor)
: SlowPathCodeARM64(instruction), successor_(successor) {}
void EmitNativeCode(CodeGenerator* codegen) override {
LocationSummary* locations = instruction_->GetLocations();
CodeGeneratorARM64* arm64_codegen = down_cast<CodeGeneratorARM64*>(codegen);
__ Bind(GetEntryLabel());
SaveLiveRegisters(codegen, locations); // Only saves live 128-bit regs for SIMD.
// 调用kQuickTestSuspend函数
arm64_codegen->InvokeRuntime(kQuickTestSuspend, instruction_, instruction_->GetDexPc(), this);
CheckEntrypointTypes<kQuickTestSuspend, void, void>();
RestoreLiveRegisters(codegen, locations); // Only restores live 128-bit regs for SIMD.
if (successor_ == nullptr) {
__ B(GetReturnLabel());
} else {
__ B(arm64_codegen->GetLabelOf(successor_));
}
}
vixl::aarch64::Label* GetReturnLabel() {return &return_label_; }
HBasicBlock* GetSuccessor() const { return successor_; }
private:
HBasicBlock* const successor_;
vixl::aarch64::Label return_label_;
};
kQuickTestSuspend定义在QuickEntrypointEnum这个枚举类中,这里使用了两层#define宏定义包裹:
art/runtime/entrypoints/quick/quick_entrypoints_enum.h
// Define an enum for the entrypoints. Names are prepended a 'kQuick'.
enum QuickEntrypointEnum { // NOLINT(whitespace/braces)
#define ENTRYPOINT_ENUM(name, rettype, ...) kQuick ## name,
#include "quick_entrypoints_list.h"
QUICK_ENTRYPOINT_LIST(ENTRYPOINT_ENUM)
#undef QUICK_ENTRYPOINT_LIST
#undef ENTRYPOINT_ENUM
};
kQuickTestSuspend对应的函数的声明在QuickEntryPoints结构体中,对应的函数名称是pTestSuspend,这里的QuickEntryPoints结构体,在thread.h中也被使用到:
class Thread {
...
QuickEntryPoints quick_entrypoints;
...
}
art/runtime/entrypoints/quick/quick_entrypoints.h
// Pointers to functions that are called by quick compiler generated code via thread-local storage.
struct PACKED(4) QuickEntryPoints {
#define ENTRYPOINT_ENUM(name, rettype, ...) rettype ( * p ## name )( __VA_ARGS__ );
#include "quick_entrypoints_list.h"
QUICK_ENTRYPOINT_LIST(ENTRYPOINT_ENUM)
#undef QUICK_ENTRYPOINT_LIST
#undef ENTRYPOINT_ENUM
};
以上两处,共同使用QUICK_ENTRYPOINT_LIST的宏定义:
art/runtime/entrypoints/quick/quick_entrypoints_list.h
// All quick entrypoints. Format is name, return type, argument types.
#define QUICK_ENTRYPOINT_LIST(V) \
V(AllocArrayResolved, void*, mirror::Class*, int32_t) \
V(AllocArrayResolved8, void*, mirror::Class*, int32_t) \
.....
V(TestSuspend, void, void) \
......
pTestSuspend函数在线程初始化时设置为art_quick_test_suspend函数的地址,进而调用到SuspendCheck函数,下文具体分析这个流程。
生成机器码结果
这里以一个非常简单的java方法为例,使用下面的命令编译出release apk的odex文件:
adb shell cmd package compile -m speed -f my-package
分析其编译后的机器码中的指令(Android10):

方法开头的一些指令是进行栈溢出检测,开辟栈空间以及保存寄存的操作。
看红框中的指令,读取了x19寄存器(tr)中的值到w16寄存器中,x19寄存器中保存的是当前线程的地址,thread指针偏移为0出的成员变量刚好就是thread的state_and_flags,从源码中可以看出:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RAuA1Hvs-1689525091862)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/fcf517377ff34dfb8a7abcb6add6c6be~tplv-k3u1fbpfcp-zoom-1.image)]
红框中这两条指令:
0x0059232c: 79400270 ldrh w16, [tr] ; state_and_flags
0x00592330: 35000670 cbnz w16, #+0xcc (addr 0x5923fc)
意思就是,当前线程的state_and_flags的值不为0,就跳转到地址0x5923fc执行。
地址0x5923fc处的指令如下:

红框中的指令,读取x19寄存器中地址偏移1352处的内容到lr寄存器中,然后跳转到这个地址中执行。
x19寄存器保存的是当前线程的地址,当前线程偏移1352处刚好就是当前线程pTestSuspend成员变量。(PS: 在Android12及以上版本编译后的机器码中,此处已改成直接跳转到目标函数。)
线程的pTestSuspend成员变量的赋值是在线程初始化的流程中进行的:
[art/runtime/thread.h]

[art/runtime/thread.cc]

在线程的初始化流程中的注册了EntryPoints,pTestSuspend这个成员变量设置了函数art_quick_test_suspend的地址,这是一个纯汇编实现的函数,arm64中实现如下:
[art/runtime/arch/arm64/quick_entrypoints_arm64.S]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s6MQCh6e-1689525091863)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/10b480c569ae4063ace51598ec444ba5~tplv-k3u1fbpfcp-zoom-1.image)]
直接跳转到了函数artTestSuspendFromCode中:
[art/runtime/entrypoints/quick/quick_thread_entrypoints.cc]

最终也是执行了线程的CheckSuspend()函数。
另外,在jni函数的调用结束时,也加入了检查点。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H9OvtqYa-1689525091864)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/4703c8a9648b42398e9ecddef95594ca~tplv-k3u1fbpfcp-zoom-1.image)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Il029pWv-1689525091864)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/4df9fe21dc944a08b9c050149530916a~tplv-k3u1fbpfcp-zoom-1.image)]
普通的jni方法调用时,会将线程状态切换到kNative,执行完成切换回kRunnable,因此这个流程不需要检查点。
但FastNative注解的jni方法,由于不会切换线程状态,因此,方法执行完成,会调用一次CheckSuspend()。
至此,总结完解释执行和机器码执行中的checkPoint点的设置流程。
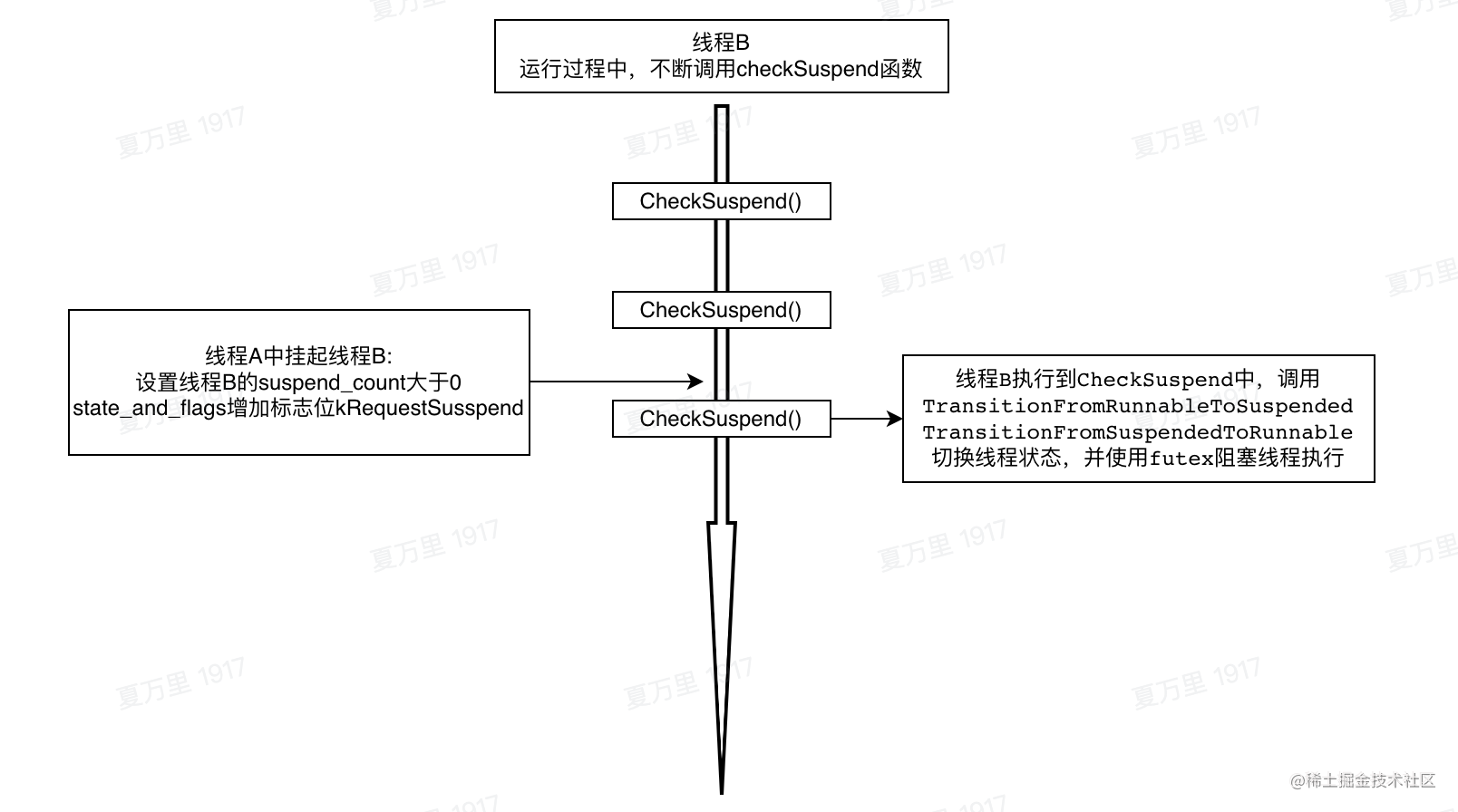
线程CheckPoint机制流程图
线程CheckPoint机制的整体流程图如下:
总结
ART虚拟机的Check Point机制主要为了实现两个功能:
- 线程运行时执行Check Point闭包任务;
- 挂起和恢复线程的执行;
虚拟机为了实现这两个功能,在Java线程对应的Native类中添加了state_and_flag变量,通过设置kSuspendRequest或者kCheckpointRequest来通知线程需要执行挂起任务还是闭包任务。具体执行任务的时机是在CheckSuspend函数中,这函数(检查点)被插入到了解释执行和机器码执行的多个流程中,这样,Runnable状态的线程就能快速执行到检查点,完成线程挂起或者执行闭包任务。
参考
- Android Source Code
- 《深入理解Android Java虚拟机ART》邓凡平 著