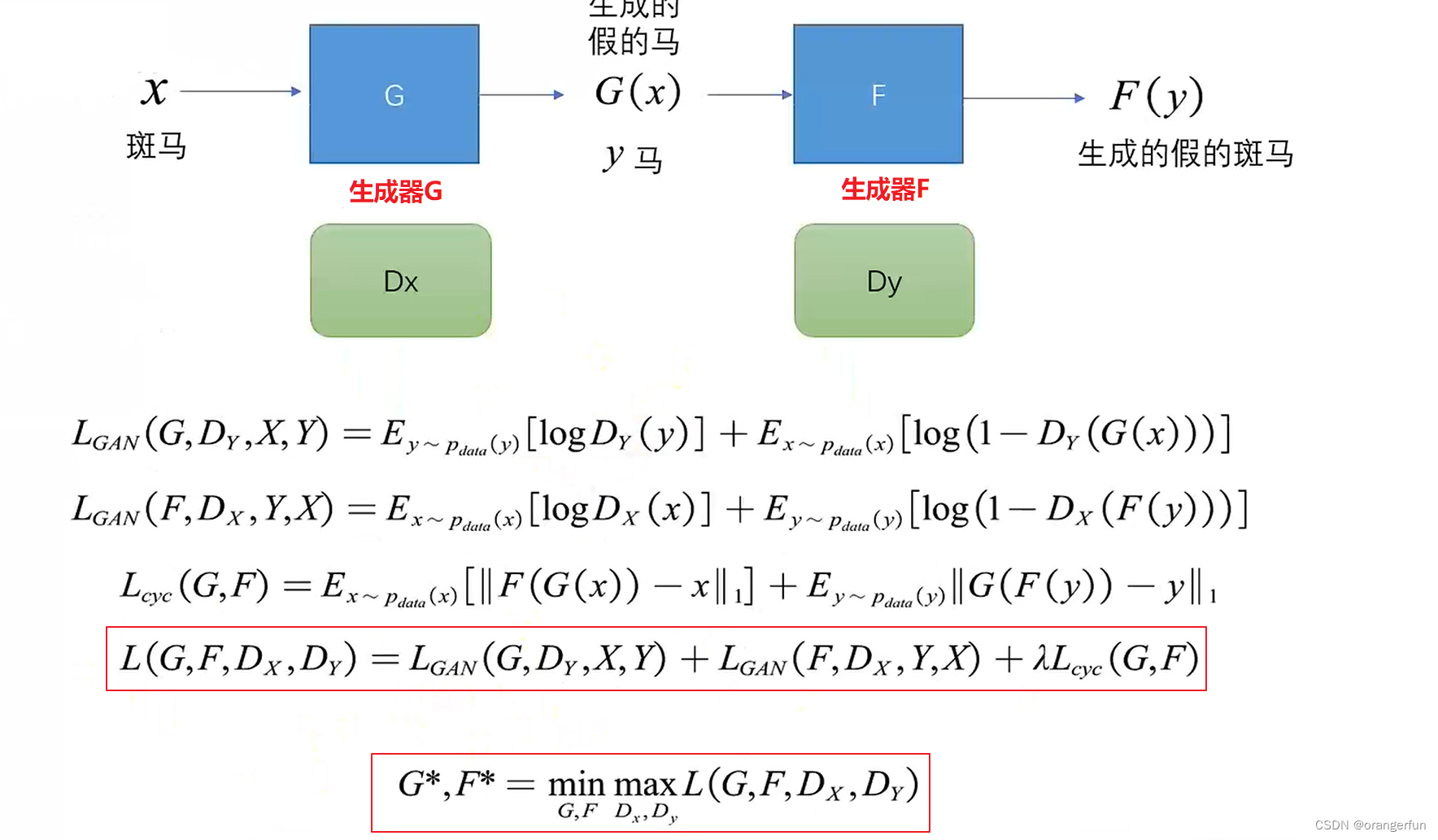
背景
最近在调优的过程中,发现了left outer join比full outer join快很多的情况,
具体的sql如下:
from
db.baseTb1 base
join db.tb1 a on base.id = a.id
full outer join db.tbl2 b on a.id = b.id
full outer join db.tbl3 c on b.id = c.id
full outer join db.tbl4 d on c.id = d.id
full outer join db.tbl5 e on d.id = e.id
-----
from
db.baseTb1 base
left join db.tb1 a on base.id = a.id
left outer join db.tbl2 b on a.id = b.id
left outer join db.tbl3 c on a.id = c.id
left outer join db.tbl4 d on a.id = d.id
left outer join db.tbl5 e on a.id = e.id
结论
先说结论:left join中4个join会在同一个Stage执行,也就是说会在同一个Task执行4个join,而full join每个join都是在单独的Stage中执行,是串行的, left join如下:

如果在语意允许的情况下,选择left join可以大大加速任务运行,笔者遇到的情况就是 left join 运行了1个小时,而full join运行了6个小时
分析
对于full outer join的情况,运行的物理计划如下:
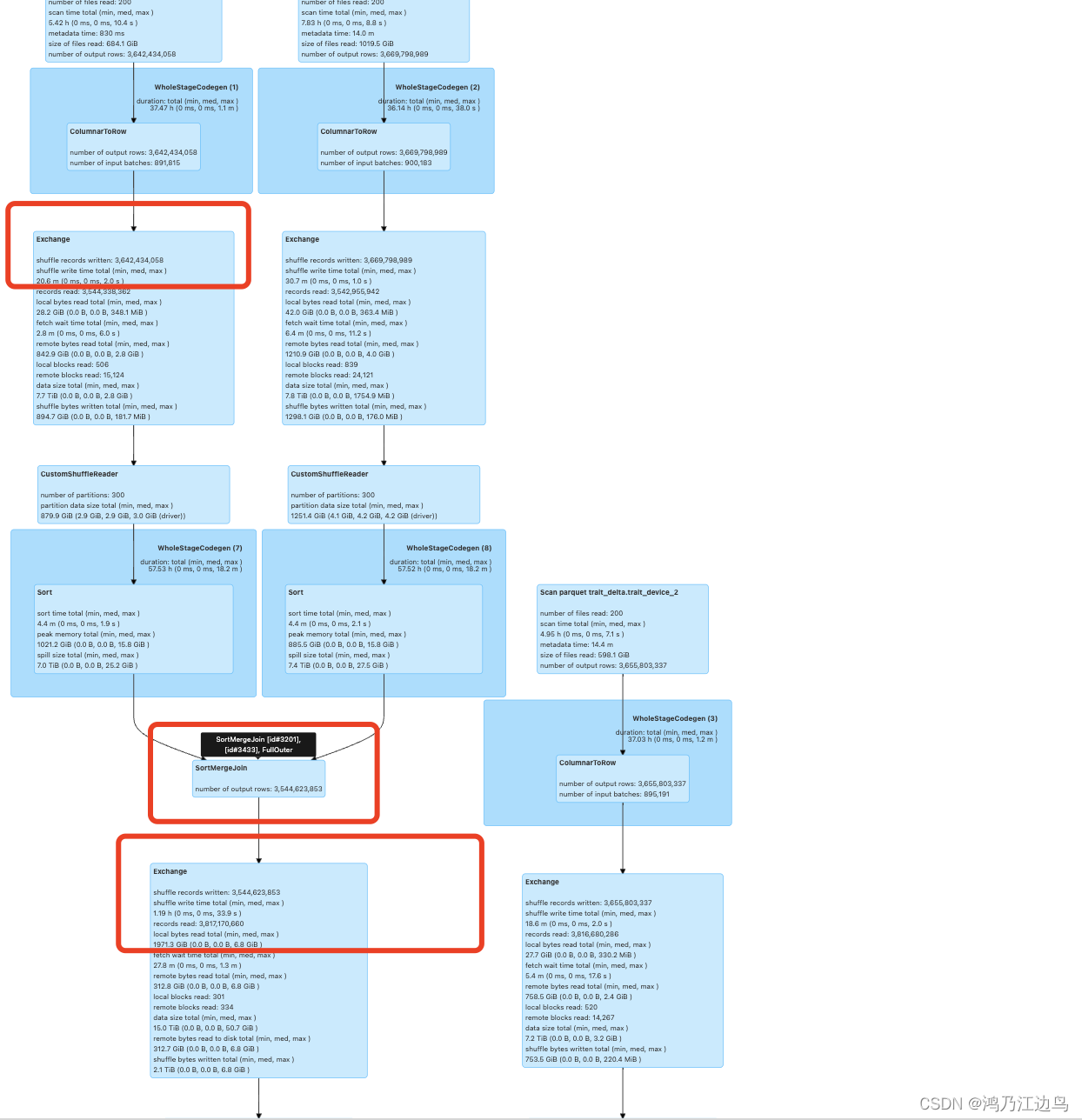
对于每个SortMergeJoin完后都会有一个Exchange的shuffle操作。
对于left outer join的情况,运行的物理计划如下:
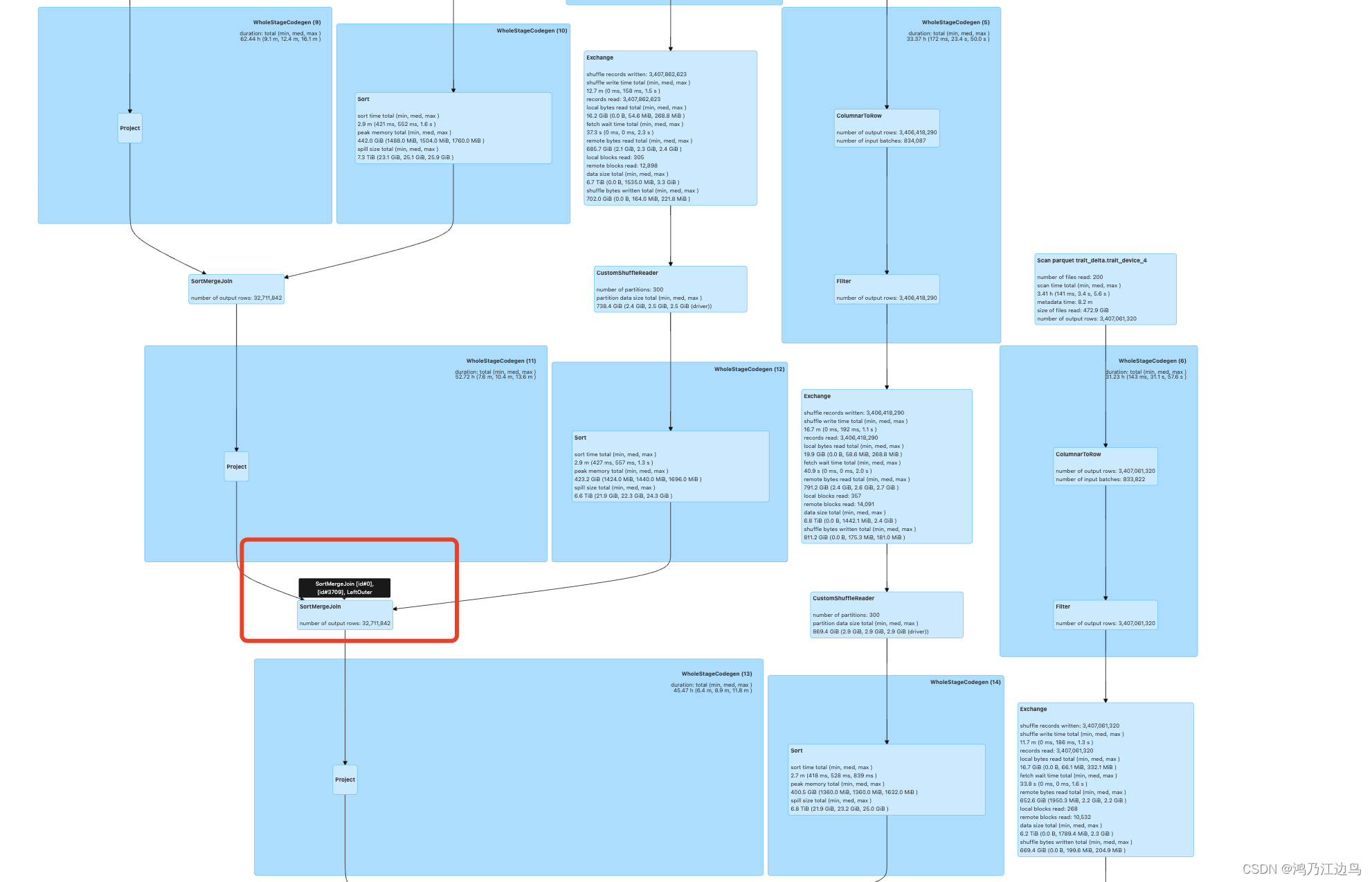
只有在读取source文件完之后才会有Exchange的shuffle的操作。
这是为什么呢?
因为在RuleEnsureRequirements中,会对于不匹配的计划之间加上shuffle Exchange物理计划,具体代码如下:
private def ensureDistributionAndOrdering(operator: SparkPlan): SparkPlan = {
val requiredChildDistributions: Seq[Distribution] = operator.requiredChildDistribution
val requiredChildOrderings: Seq[Seq[SortOrder]] = operator.requiredChildOrdering
var children: Seq[SparkPlan] = operator.children
assert(requiredChildDistributions.length == children.length)
assert(requiredChildOrderings.length == children.length)
// Ensure that the operator's children satisfy their output distribution requirements.
children = children.zip(requiredChildDistributions).map {
case (child, distribution) if child.outputPartitioning.satisfies(distribution) =>
child
case (child, BroadcastDistribution(mode)) =>
BroadcastExchangeExec(mode, child)
case (child, distribution) =>
val numPartitions = distribution.requiredNumPartitions
.getOrElse(conf.numShufflePartitions)
ShuffleExchangeExec(distribution.createPartitioning(numPartitions), child)
}
- child.outputPartitioning.satisfies(distribution)这块代码就是判断下游的输出分区是否满足当前计划所要求的分布
我们分析第一个join的时候,也就是:
FileSourceScanExec FileSourceScanExec
\ /
\/ \/
SortMergeJoin
这里SortMergeJoin的requiredChildDistribution为ClusteredDistribution(leftKeys) :: ClusteredDistribution(rightKeys)
SortMergeJoin的child的outputPartitioning为FileSourceScanExec.outputPartitioning,即UnknownPartitioning
所以会引入Exchange,形成如下的物理计划:
FileSourceScanExec FileSourceScanExec
\ /
\/ \/
Exchange Exchange
\ /
SortMergeJoin
而最终经过AQE以后会形成如下的物理计划:
FileSourceScanExec FileSourceScanExec
\ /
\/ \/
Exchange Exchange
| |
CustomShuffleReader CustomShuffleReader
\ /
SortMergeJoin
而对于接下来的第二个join,full join和left join的情况就不一样了:
- 对于left join:
FileSourceScanExec FileSourceScanExec
\ /
\/ \/
Exchange Exchange
| |
CustomShuffleReader CustomShuffleReader
\ /
SortMergeJoin FileSourceScanExec
|
| Exchange
| |
| CustomShuffleReader
| /
SortMergeJoin(left outer join)
因为第二个SortMergeJoin的requiredChildDistribution为ClusteredDistribution(leftKeys) :: ClusteredDistribution(rightKeys)
SortMergeJoin 的child的outputPartitioning为第一个SortMergeJoin.outputPartitioning,具体的代码如下:
override def outputPartitioning: Partitioning = joinType match {
case _: InnerLike =>
PartitioningCollection(Seq(left.outputPartitioning, right.outputPartitioning))
case LeftOuter => left.outputPartitioning
case RightOuter => right.outputPartitioning
case FullOuter => UnknownPartitioning(left.outputPartitioning.numPartitions)
case LeftExistence(_) => left.outputPartitioning
case x =>
throw new IllegalArgumentException(
s"ShuffledJoin should not take $x as the JoinType")
}
所以是CustomShuffleReader.outputPartitioning,w为Exchange.outputPartitioning即HashPartitioning,则能匹配satisfied上,所以不会引入额外的shuffle
- 对于full outer join:
FileSourceScanExec FileSourceScanExec
\ /
\/ \/
Exchange Exchange
| |
CustomShuffleReader CustomShuffleReader
\ /
SortMergeJoin FileSourceScanExec
|
| Exchange
| |
| CustomShuffleReader
| /
SortMergeJoin(left outer join)
其他的都是left outer join一样,唯一不一样的是SortMergeJoin 的child的outputPartitioning是 第一个SortMergeJoin.outputPartitioning ,根据以上代码:
走的就是FullOuter的逻辑,也就是UnknownPartitioning,所以是不满足,得引入shuffle Exchange。
其实从逻辑上来说,full join后如果不重新shuffle,会导致一个任务中会有id为null值的存在,会导致join的结果不正确
而对于left join来说就不一样了,task join完后id还是保持原来的就不会变,所以就不必重新shuffle
![[Arduino] ESP32开发 - UDP收发数据](https://img-blog.csdnimg.cn/a6f98b505b2c485a9aac5c4778d534bb.png)