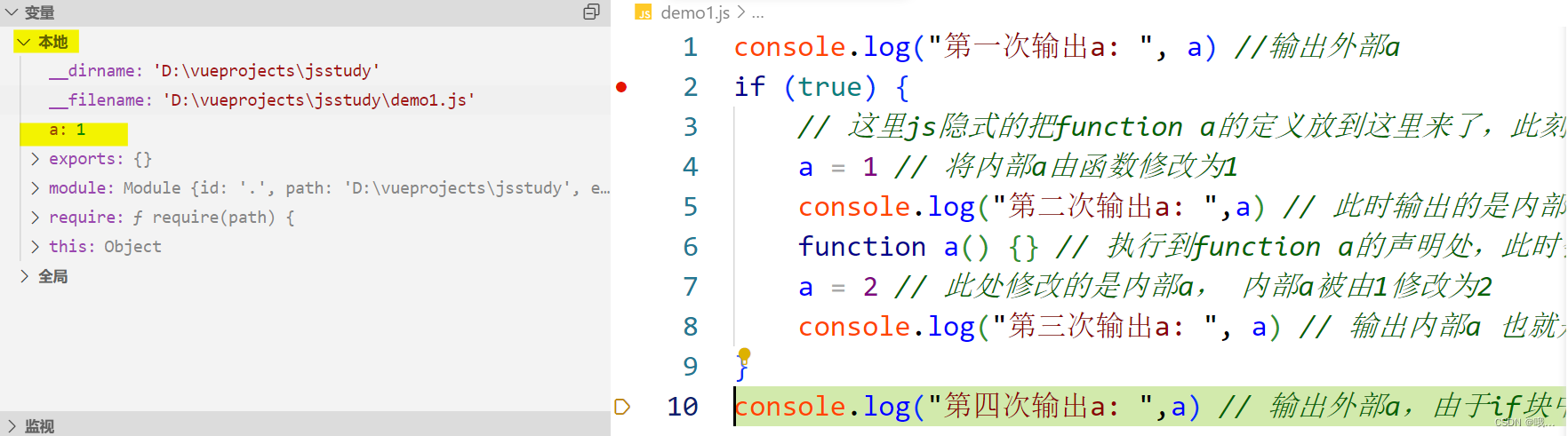
数据结构真题
1. A. Bills of Paradise
- 线段树+并查集
- 四个操作:
- D x。标记大于等于 x 的第一个未标记的 a i a_i ai;若没有,则不操作.
- F x。查询大于等于 x 的第一个未标记的 a i a_i ai;若没有,则输出 1 0 12 10^{12} 1012.
- R x。清除小于等于 x 的所有标记;若没有,则不操作。本操作次数不超过10次.
- C x。查询小于等于 x 的所有未标记数之和;若没有,则输出0.
- 我们先排序,这样子可以很快定位到x。
- 因为单点查询修改,都是大于等于x的第一个 a i a_i ai,因此我们可以用并查集往后连。p[i] 表示从 i 开始往后第一个未标记的结点的下标。一开始都是未标记的,所以是 p[i] = i。标记了 i 之后,unite(i, i + 1),把 i 开始的未标记下一个结点连到 p[i + 1] 上面。
- 至于 R, C 操作,区间操作用线段树。线段树一开始都是零,只保存标记的节点。每标记一个结点,就把对应的地方 += a[i]。线段树结点保留三个属性:l, r, sum.
- 易错点:
- 找下一个未标记节点的时候:pos = find(id),而不是 pos = find(id)
- query 函数一定要小心
if (r <= mid) return query(2 * u, l, r);,递归的时候不是query(2 * u, l, mid)! - 每个结尾千万不要忘记输出空格!
#include<iostream>
#include<algorithm>
#include<cstring>
typedef unsigned long long ll;
using namespace std;
const int maxn = 1000010;
const ll M = 1e12;
int p[maxn];
ll sum[maxn];
int find(int x){
if (p[x] == x) return x;
return p[x] = find(p[x]);
}
void unite(int a, int b) {
if (find(a) == find(b)) return;
p[a] = find(b);
}
unsigned long long k1, k2;
int N;
long long a[1000001];
unsigned long long xorShift128Plus() {
unsigned long long k3 = k1, k4 = k2;
k1 = k4;
k3 ^= k3 << 23;
k2 = k3 ^ k4 ^ (k3 >> 17) ^ (k4 >> 26);
return k2 + k4;
}
void gen() {
scanf("%d %llu %llu", &N, &k1, &k2);
for (int i = 1; i <= N; i++) {
a[i] = xorShift128Plus() % 999999999999 + 1;
}
}
struct node {
int l, r;
ll sum;
}tr[maxn * 4];
void pushup(int u) {
tr[u].sum = tr[2 * u].sum + tr[2 * u + 1].sum;
}
void build(int u, int l, int r) {
if (l == r) tr[u] = { l, l, 0 };
else {
tr[u].l = l, tr[u].r = r;
int mid = (l + r) / 2;
build(2 * u, l, mid), build(2 * u + 1, mid + 1, r);
//pushup(u);
}
}
node query(int u, int l, int r) {
if (l <= tr[u].l && tr[u].r <= r) return tr[u];
int mid = (tr[u].l + tr[u].r) / 2;
if (r <= mid) return query(2 * u, l, r);
else if (l > mid) return query(2 * u + 1, l, r);
else {
node left = query(2 * u, l, r);
node right = query(2 * u + 1, l, r);
node res;
res.sum = left.sum + right.sum;
return res;
}
}
void modify(int u, int x, ll v) { // a[x] = v;
if (tr[u].l == x && tr[u].r == x) tr[u].sum = v;
else {
int mid = (tr[u].l + tr[u].r) / 2;
if (x <= mid) modify(2 * u, x, v);
else modify(2 * u + 1, x, v);
pushup(u);
}
}
int main() {
gen();
sort(a + 1, a + N + 1);
//for (int i = 1; i <= N; i++) printf("%llu ", a[i]);
for (int i = 1; i <= N; i++) {
sum[i] = sum[i - 1] + a[i];
}
int Q;
scanf("%d", &Q);
build(1, 1, N);
for (int i = 1; i <= N + 1; i++) {
p[i] = i;
}
while (Q--) {
char op[5];
ll x;
scanf("%s%llu", op, &x);
if (op[0] == 'D') { // 标记>=x的第一个未被标记的a[i]
int id = lower_bound(a + 1, a + N + 1, x) - a;
int pos = find(id);
if (pos == N + 1) continue;
unite(pos, pos + 1);
modify(1, pos, a[pos]);
}
if (op[0] == 'F') { // 查询>=x的第一个未被标记的a[i]
int id = lower_bound(a + 1, a + N + 1, x) - a;
int pos = find(id);
if (pos == N + 1) printf("%llu\n", M);
else {
printf("%llu\n", a[pos]);
}
}
if (op[0] == 'R') { // <=x的标记全部清零
int id = upper_bound(a + 1, a + N + 1, x) - a - 1;
if (id == 0) continue;
for (int i = 1; i <= id; i++) {
p[i] = i;
modify(1, i, 0);
}
}
if (op[0] == 'C') { //查询小于等于 x 的所有未标记数之和;若没有,则输出0。
int id = upper_bound(a + 1, a + N + 1, x) - a - 1;
if (id == 0) printf("0\n");
else {
printf("%llu\n", sum[id] - query(1, 1, id).sum);
}
}
}
return 0;
}
2. C. Caesar Cipher
-
给出一个长度为 n 的序列,接下来有 m 次操作,每次操作分为下列两种类型:
- 1 l r:区间 [ l , r ] 内的所有数都加 1 并对 65536 取模,也就是 i ∈ [ l , r ] ,有 a[ i ] =( a[ i ] + 1 ) % 65536
- 2 x y len:查询两段区间 [ x , x + len - 1 ] 和 [ y , y + len - 1 ] 内的序列是否相同
-
这个题确实有几个可圈可点的地方
- 首先,他让每个数增加到到 2 16 2^{16} 216 变为0,相当于又引入了一个模数。而之前的字符串哈希是自然溢出取模,然而 2 16 2^{16} 216 与 2 64 2^{64} 264 并不互质,因此这样子会错。字符串哈希不仅要保证 base 和 mod 互质,还要保证取模的数也要互质。
- 这道题用字符串哈希第二种方法最简单,即 c 1 p + c 2 p 2 + . . . + c m p m c_1p+c_2p^{2}+...+c_mp^m c1p+c2p2+...+cmpm 表示字符串的哈希值。
- 小心三个地方,第一个是modify的时候小心,在要修改完整;第二个是取模的时候,出现减法,一定要 + mod 再 % mod,防止出现负数;第三个是,字符串哈希,对一段区间加上某一个数时,是加 base 幂的区间和 s u m p [ r ] − s u m p [ l − 1 ] sump[r] - sump[l-1] sump[r]−sump[l−1],而不是 p [ r ] − p [ l − 1 ] p[r] - p[l - 1] p[r]−p[l−1].
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
typedef long long ll;
const ll mod = 1e9 + 7, P = 131;
const int maxn = 500010;
ll p[maxn], a[maxn], sump[maxn];
struct node {
int l, r;
ll Hash, mmax, add;
}tr[maxn * 4];
void pushup(int u) {
tr[u].Hash = (tr[2 * u].Hash + tr[2 * u + 1].Hash) % mod;
tr[u].mmax = max(tr[2 * u].mmax, tr[2 * u + 1].mmax);
}
void pushdown(int u) {
auto& rt = tr[u], & l = tr[2 * u], & r = tr[2 * u + 1];
if (rt.add) {
//出现减法一定要 + mod 再 % mod
l.add += rt.add, l.Hash = (l.Hash + (sump[l.r] - sump[l.l - 1]) * rt.add % mod + mod) % mod, l.mmax += rt.add;
r.add += rt.add, r.Hash = (r.Hash + (sump[r.r] - sump[r.l - 1]) * rt.add % mod + mod) % mod, r.mmax += rt.add;
rt.add = 0;
}
}
void build(int u, int l, int r) {
if (l == r) tr[u] = { l, r, a[l] * p[l] % mod, a[l], 0 };
else {
tr[u].l = l, tr[u].r = r;
int mid = (l + r) / 2;
build(2 * u, l, mid), build(2 * u + 1, mid + 1, r);
pushup(u);
}
}
void modify(int u, int l, int r) {
if (l <= tr[u].l && tr[u].r <= r) {
//这里的 Hash 别忘修改, 出现减法一定要 + mod 再 % mod
tr[u].Hash = (tr[u].Hash + sump[tr[u].r] - sump[tr[u].l - 1] + mod) % mod;
tr[u].add++;
tr[u].mmax++;
}
else {
pushdown(u);
int mid = (tr[u].l + tr[u].r) / 2;
if (l <= mid) modify(2 * u, l, r);
if (r > mid) modify(2 * u + 1, l, r);
pushup(u);
}
}
void modify_mod(int u) {
if (tr[u].mmax < 65536) return;
if (tr[u].l == tr[u].r) {
tr[u].mmax %= 65536;
tr[u].Hash = tr[u].mmax * p[tr[u].l] % mod;
}
else {
pushdown(u);
modify_mod(2 * u), modify_mod(2 * u + 1);
pushup(u);
}
}
ll query(int u, int l, int r) {
if (l <= tr[u].l && tr[u].r <= r) return tr[u].Hash;
pushdown(u);
int mid = (tr[u].l + tr[u].r) / 2;
ll sum = 0;
if (l <= mid) sum = (sum + query(2 * u, l, r)) % mod;
if (r > mid) sum = (sum + query(2 * u + 1, l, r)) % mod;
return sum;
}
bool check(int x, int y, int L) {
if (x > y) swap(x, y);
ll q1 = query(1, x, x + L - 1) * p[y - x] % mod;
ll q2 = query(1, y, y + L - 1);
if (q1 == q2) return true;
return false;
}
int main() {
int N, Q;
scanf("%d%d", &N, &Q);
p[0] = sump[0] = 1;
for (int i = 1; i <= N; i++) {
scanf("%lld", &a[i]);
p[i] = p[i - 1] * P % mod;
sump[i] = (sump[i - 1] + p[i]) % mod;
}
build(1, 1, N);
while (Q--) {
/*for (int i = 1; i <= N; i++) {
printf("%lld ", query(1, i, i));
}
printf("\n");*/
int op;
scanf("%d", &op);
if (op == 1) {
int l, r;
scanf("%d%d", &l, &r);
modify(1, l, r);
modify_mod(1);
}
else {
int x, y, L;
scanf("%d%d%d", &x, &y, &L);
if (check(x, y, L)) printf("yes\n");
else printf("no\n");
}
}
/*for (int i = 1; i <= N; i++) {
printf("%lld %lld\n", p[i], sump[i]);
}*/
return 0;
}
3. B. Bin Packing Problem
- 题意:n个物品,第i个物品的容量是 a[i] ,有无限个箱子,每个箱子的容量是 c ,问按照一下两种放法,最少需要几个箱子。
第一种:每次都选择最前面的可以放在物品的箱子,若不存在就增加一个箱子。
第二种:每次都选择剩余容量最小的且可以容纳物品的箱子,若不存在就增加一个箱子。
问两种方法各需要多少个箱子 - 第一个:是在数组中找到第一个大于等于x的数,这个用线段树,维护区间最大值,先一直往左找,找不到的话往右找。
- 第二种:找到一个动态有序序列中第一个大于等于x的数,平衡树嘛。不过,这个题用map就挺好的,需要记录重复的数据(虽然说map是红黑树但是这不重要)。
#include<iostream>
#include<cstring>
#include<algorithm>
#include<map>
using namespace std;
const int maxn = 1000010;
int a[maxn];
struct node {
int l, r, maxc;
}tr[maxn * 2];
int N, C;
void pushup(int u) {
tr[u].maxc = max(tr[2 * u].maxc, tr[2 * u + 1].maxc);
}
void build(int u, int l, int r) {
if (l == r) {
tr[u] = { l, r, C };
}
else {
tr[u].l = l, tr[u].r = r;
int mid = (l + r) / 2;
build(2 * u, l, mid), build(2 * u + 1, mid + 1, r);
pushup(u);
}
}
bool modify(int u, int x) {
//printf("***\n");
if (tr[u].l == tr[u].r) {
tr[u].maxc -= x;
return true;
}
else {
if (tr[2 * u].maxc >= x && modify(2 * u, x)) {
pushup(u);
return true;
}
if (tr[2 * u + 1].maxc >= x && modify(2 * u + 1, x)) {
pushup(u);
return true;
}
return false;
}
}
int query(int u, int id) {
if (tr[u].l == tr[u].r) return tr[u].maxc;
int mid = (tr[u].l + tr[u].r) / 2;
if (id <= mid) return query(2 * u, id);
else if (id > mid) return query(2 * u + 1, id);
}
int main() {
int T;
scanf("%d", &T);
while (T--) {
scanf("%d%d", &N, &C);
build(1, 1, N);
for (int i = 1; i <= N; i++) {
scanf("%d", &a[i]);
}
map<int, int> mp;
int res1 = 0, res2 = 0;
for (int i = 1; i <= N; i++) {
modify(1, a[i]);
auto p = mp.lower_bound(a[i]);
if (p != mp.end()) {
--p->second;
++mp[p->first - a[i]];
if (p->second == 0) mp.erase(p);
}
else {
++mp[C - a[i]];
++res2;
}
}
for (int i = 1; i <= N; i++) {
//printf("$$$ %d\n", query(1, i));
if (query(1, i) == C) {
res1 = i - 1;
break;
}
if (i == N) {
res1 = N;
}
}
printf("%d %d\n", res1, res2);
}
return 0;
}
4. E. Easy DP Problem
- 题意:给你这么一个dp的方程,然后给出 l, r, k。即选择 a[l ~ r] 作为 b 数组,问
d
p
(
r
−
l
+
1
,
k
)
dp(r - l + 1, k)
dp(r−l+1,k) 这个数是多少。

- 多输入几个无序的序列,然后分析分析,可以看出来,题目问的是, ∑ i = 1 m i 2 \sum\limits_{i=1}^mi^2 i=1∑mi2 加上 a[l ~ r + 1] 这些数中的前 k 个大的数。这就需要主席树了。感觉省赛题确实比CCPC区域赛在思维上要简单一点。
#include<iostream>
#include<algorithm>
#include<cstring>
#include<vector>
#include<functional>
using namespace std;
const int maxn = 100010;
typedef long long ll;
int N, M, a[maxn];
ll sum2[maxn];
vector<int> nums;
struct node {
int l, r;
int cnt;
ll sum;
}tr[maxn * 4 + maxn * 17];
//空间开到 4N + N * log(N)
int root[maxn], idx;
int find(int x) {
return lower_bound(nums.begin(), nums.end(), x, greater<int>()) - nums.begin();
}
int build(int l, int r) {
int p = ++idx;
tr[p] = { l, r };
if (l == r) return p;
int mid = (l + r) / 2;
tr[p].l = build(l, mid), tr[p].r = build(mid + 1, r);
return p;
}
//p 为原来的线段树的结点,q 为复制的线段是的结点
int insert(int p, int l, int r, int x) {
int q = ++idx;
tr[q] = tr[p];
if (l == r) {
tr[q].cnt++;
tr[q].sum += nums[x];
return q;
}
int mid = (l + r) / 2;
if (x <= mid) tr[q].l = insert(tr[p].l, l, mid, x);
else tr[q].r = insert(tr[p].r, mid + 1, r, x);
tr[q].cnt = tr[tr[q].l].cnt + tr[tr[q].r].cnt;
tr[q].sum = tr[tr[q].l].sum + tr[tr[q].r].sum;
return q;
}
ll query(int q, int p, int l, int r, int k) {
//这个地方要小心,因为有重复数字的话,需要这样处理,不然结果会偏大。
if (l == r) return (tr[q].sum - tr[p].sum) / (tr[q].cnt - tr[p].cnt) * k;
int cnt = tr[tr[q].l].cnt - tr[tr[p].l].cnt;
int mid = (l + r) / 2;
if (k <= cnt) return query(tr[q].l, tr[p].l, l, mid, k);
else return tr[tr[q].l].sum - tr[tr[p].l].sum + query(tr[q].r, tr[p].r, mid + 1, r, k - cnt);
}
int main() {
for (ll i = 1; i <= 100000; i++) {
sum2[i] = i * i + sum2[i - 1];
}
int T;
scanf("%d", &T);
while (T--) {
//看看如何初始化的
nums.clear();
for (int i = 0; i <= idx; i++) {
tr[i] = { 0, 0, 0, 0 };
}
fill(root, root + N + 1, 0);
idx = 0;
scanf("%d", &N);
for (int i = 1; i <= N; i++) {
scanf("%d", &a[i]);
nums.push_back(a[i]);
}
sort(nums.begin(), nums.end(), greater<int>());
nums.erase(unique(nums.begin(), nums.end()), nums.end());
root[0] = build(0, nums.size() - 1);
for (int i = 1; i <= N; i++) {
root[i] = insert(root[i - 1], 0, nums.size() - 1, find(a[i]));
}
scanf("%d", &M);
while (M--) {
int l, r, k;
scanf("%d%d%d", &l, &r, &k);
int m = r - l + 1;
printf("%lld\n", sum2[m] + query(root[r], root[l - 1], 0, nums.size() - 1, k));
}
}
return 0;
}
4. I. Incredible photography
- 题意:给你一段序列,以某点为起点,你的移动规则是找到一个你能看到的高度严格大于你的点,然后你可以移动到那个点,之后又可以以相同的规则进行移动。求出以每个点为起点时能移动的最长距离。
- 很显然是单调栈+拓扑图最长路径。但是有一个关键的问题,就是这个找的是每个数向左看,和比他大的数第一个数相等的,且距离离他最远数。那么这个其实很简单,就是在维护单调栈的时候,如果出现
a[stk[tt]] == a[i]的情况,就把这个 stk[tt] 记录下来。后面往单调栈里面推入数字的时候,不推入 i 而推入 stk[tt]。这样子,就算出现 5 3 5 5 3 5 这样子的东西,就算中间数字不是连续的,也是可以正确的找到离他最远的符合要求的那个数字。
#include<iostream>
#include<cstring>
#include<algorithm>
#include<queue>
using namespace std;
typedef long long ll;
const int maxn = 100010, maxm = 200010;
int h[maxn], e[maxm], ne[maxm], w[maxm], idx;
int a[maxn], N, stk[maxn];
int din[maxn];
ll f[maxn];
void add(int a, int b, int c) {
swap(a, b);
din[b]++;
e[idx] = b, ne[idx] = h[a], w[idx] = c, h[a] = idx++;
}
void build1() {
int tt = 0;
for (int i = 1; i <= N; i++) {
bool flag = false;
//小心 id 别设置成 bool 类型喽
int id;
while (tt && a[stk[tt]] < a[i]) tt--;
//小心别写成 tt & a[stk[tt]] == a[i] !!!
if (tt && a[stk[tt]] == a[i]) {
flag = true, id = stk[tt];
tt--;
}
if (tt) add(i, stk[tt], i - stk[tt]);
if (flag) {
stk[++tt] = id;
}
else stk[++tt] = i;
}
}
void build2() {
int tt = 0;
for (int i = N; i >= 1; i--) {
bool flag = false;
int id;
while (tt && a[stk[tt]] < a[i]) tt--;
if (tt && a[stk[tt]] == a[i]) {
flag = true, id = stk[tt];
tt--;
}
if (tt) add(i, stk[tt], stk[tt] - i);
if (flag) {
stk[++tt] = id;
}
else stk[++tt] = i;
}
}
void toposort() {
queue<int> que;
for (int i = 1; i <= N; i++) {
if (din[i] == 0) {
que.push(i);
}
}
while (que.size()) {
int u = que.front(); que.pop();
for (int i = h[u]; i != -1; i = ne[i]) {
int v = e[i];
f[v] = max(f[v], f[u] + w[i]);
if (--din[v] == 0) que.push(v);
}
}
}
int main() {
memset(h, -1, sizeof h);
scanf("%d", &N);
for (int i = 1; i <= N; i++) scanf("%d", &a[i]);
build1();
build2();
toposort();
for (int i = 1; i <= N; i++) {
printf("%lld%c", f[i], i == N ? '\n' : ' ');
}
return 0;
}
5. J. Just Another Game of Stones
- 吉老师线段树,复杂度是 O ( n log 2 n ) . O(n\log^2 n). O(nlog2n).
- 吉司机线段树主要是用来解决序列区间上满足部分满足一定性质的修改操作的,比方说把区间中小于x的数改成x,大于x的数改成x,甚至是区间取并和区间取或(实际上也就是区间中的每个数的每一位进行类似小于x改成x那种操作)下面主要说一下怎么处理区间中把小于x 的数改成x,其他的可以类比来做;
- 首先要记一个中间量,也就是次小值;然后再把线段树上每一个区间的最小值及其个数记录下来;
- 对于每次修改,设要和x进行对比;
- 如果当前找到的区间的最小值>=x,那么肯定没必要再往下处理了;
- 如果x>最小值但x<次小值(注意x严格小于次小值)那么只需要把最小值改成x,记录的最小值的数目都不需要改,这样线段树上维护的其他信息也可以很方便的修改(例如区间和一类的信息)
- 如果x>=次小值,那递归处理左右子区间再合并信息回来;
- 题意。有一个线段树,维护两个操作
- 1 l r:对于所有 i ∈ [ l , r ] i \in [l, r] i∈[l,r] 执行 a i = m a x ( a i , x ) a_i = max(a_i, x) ai=max(ai,x)
- 2 l r x:对于区间 [ l , r ] [l, r] [l,r] 内的 a i a_i ai 加上 x 这一共 r − l + 2 r - l + 2 r−l+2 个数进行尼姆游戏,问先手必胜的情况下第一次能有多少种不同的取石子方案。
- 根据尼姆游戏,我们知道,我们先把所有值取异或得到 res,然后记 res 最高位1是第 k 位,查一下有多少个 a i a_i ai 的第 k 位是1.
- 对于第一个操作。我们记录这个区间最小值、次小值、最小值的个数。那么,如果传进来的x >= 最小值,那么什么都不变;如果最小值 < x < 次小值,那么就把次小值变成 x,其他的不用变;如果 x >= 次小值,那么就递归处理两个儿子。
- 对于第二个操作,因为是取异或,且需要知道位的信息,所以我们对每一位维护一个信息。而该位异或的结果取决于该位的个数。
- 数组一定要开大一点,千万别吝惜。因为有时候会出现莫名其妙的错误。就比如这道题,把sum数组从30变成35后就不出现段错误了。
#include<iostream>
#include<algorithm>
#include<cstring>
#include<cmath>
using namespace std;
const int maxn = 200010;
struct node {
int l, r;
int mmin, se_min, num; //最小值,次小值,最小值个数
int sum[35];
}tr[maxn * 4];
int res_sum[35];
int w[maxn];
void change(int u, int pre, int cur) {
for (int i = 0; i < 30; i++) {
if ((pre >> i) & 1) tr[u].sum[i] -= tr[u].num;
if ((cur >> i) & 1) tr[u].sum[i] += tr[u].num;
}
}
void pushup(int u) {
tr[u].num = 0;
int left = 2 * u, right = 2 * u + 1;
for (int i = 0; i < 30; i++)
tr[u].sum[i] = tr[left].sum[i] + tr[right].sum[i];
tr[u].mmin = min(tr[left].mmin, tr[right].mmin);
tr[u].se_min = min(tr[left].se_min, tr[right].se_min);
//下面修改 tr[u].num的值,顺便更新 tr[u].se_min 的值
if (tr[u].mmin == tr[left].mmin) {
tr[u].num += tr[left].num;
}
else {
tr[u].se_min = min(tr[u].se_min, tr[left].mmin);
}
if (tr[u].mmin == tr[right].mmin) {
tr[u].num += tr[right].num;
}
else {
tr[u].se_min = min(tr[u].se_min, tr[right].mmin);
}
}
void pushdown(int u) {
//改变mmin和sum
int left = 2 * u, right = 2 * u + 1;
if (tr[u].mmin > tr[left].mmin) {
change(left, tr[left].mmin, tr[u].mmin);
tr[left].mmin = tr[u].mmin;
}
if (tr[u].mmin > tr[right].mmin) {
change(right, tr[right].mmin, tr[u].mmin);
tr[right].mmin = tr[u].mmin;
}
}
void build(int u, int l, int r) {
if (l == r) {
tr[u].l = l, tr[u].r = r;
tr[u].mmin = w[l], tr[u].se_min = 2e9, tr[u].num = 1;
change(u, 0, w[l]);
}
else {
tr[u].l = l, tr[u].r = r;
int mid = (l + r) / 2;
build(2 * u, l, mid), build(2 * u + 1, mid + 1, r);
pushup(u);
}
}
void modify(int u, int l, int r, int x) {
if (x <= tr[u].mmin) return;
if (l <= tr[u].l && tr[u].r <= r && x < tr[u].se_min) {
//因为 x < tr[u].se_min,因此更新后最小值的数目不变。
change(u, tr[u].mmin, x);
tr[u].mmin = x;
return;
}
pushdown(u);
int mid = (tr[u].l + tr[u].r) / 2;
if (l <= mid) modify(2 * u, l, r, x);
if (r > mid) modify(2 * u + 1, l, r, x);
pushup(u);
}
void query(int u, int l, int r) {
if (l <= tr[u].l && tr[u].r <= r) {
for (int i = 0; i < 30; i++) {
res_sum[i] += tr[u].sum[i];
}
return;
}
pushdown(u);
int mid = (tr[u].l + tr[u].r) / 2;
if (l <= mid) query(2 * u, l, r);
if (r > mid) query(2 * u + 1, l, r);
}
int main() {
int N, Q;
scanf("%d%d", &N, &Q);
for (int i = 1; i <= N; i++) scanf("%d", &w[i]);
build(1, 1, N);
while (Q--) {
int op, l, r, x;
scanf("%d%d%d%d", &op, &l, &r, &x);
if (op == 1) {
modify(1, l, r, x);
}
else {
memset(res_sum, 0, sizeof res_sum);
query(1, l, r);
int res = x;
for (int i = 0; i < 30; i++) {
if (res_sum[i] & 1) res ^= (1 << i);
}
if (!res) {
printf("0\n");
continue;
}
int h = log2(res);
printf("%d\n", res_sum[h] + ((x >> h) & 1));
}
}
return 0;
}
J题实际上是本场唯一的一个套路题,前半考察对nim游戏的基础理解,后半考察Segment Beats。我组题会偏向于在比赛中设置这么一个题目,可以说是给那些有准备的队伍一个糖果。而实际上我之所以选用Segment Beats就是因为在不久前ccpc网络赛中就出现过一个,可以理解为我在考察大家平时的补题情况。
6. I. Stock Analysis
- 给一个序列 ( n ≤ 2000 ) (n\le 2000) (n≤2000),给 Q ( Q ≤ 20000 ) Q(Q\le20000) Q(Q≤20000) 组询问 ( l , r , u ) (l, r, u) (l,r,u),问在 ( l , r ) (l, r) (l,r) 内,不大于 u u u 的最大连续子段和是多少?
- 一开始用线段树套平衡树,后来发现不对。因为树套树只能维护一段一段的区间。如果某个区间横跨线段树的维护的两个区间,答案也是横跨了结点的两个区间,这样的答案是查询不到的。
- 有一个思路是,所有区间和总共也只有 2e6 个。因此预处理出所有区间和,再读入所有询问。然后按照值排序。这样子的话,大于 U 的区间和只会在 U 之后出现,这样子的话,就可以转化为求小矩形最大值的问题。
- 但是,不会求小矩形最大值。
- 看不懂的二维树状数组写法
#include<iostream>
#include<cstring>
#include<algorithm>
#include<vector>
using namespace std;
typedef long long ll;
const ll INF = 1e18;
const int maxn = 2010, maxm = 200010;
struct node {
int l, r, id;
ll val;
};
vector<node> q;
ll w[maxn], tr[maxn][maxn], ans[maxm];
int lowbit(int x) {
return x & -x;
}
bool cmp(const node& u, const node& v) {
return u.val < v.val || u.val == v.val && u.id < v.id;
}
int N, M;
void update(int x, int y, ll v) {
while (x) {
int z = y;
while (z <= N) {
tr[x][z] = max(tr[x][z], v);
z += z & -z;
}
x -= x & -x;
}
}
ll query(int x, int y) {
ll res = -INF;
while (x <= N) {
int z = y;
while (z) {
res = max(res, tr[x][z]);
z -= z & -z;
}
x += x & -x;
}
return res;
}
int main() {
scanf("%d%d", &N, &M);
for (int i = 1; i <= N; i++) {
fill(tr[i], tr[i] + N + 1, -INF);
}
for (int i = 1; i <= N; i++) {
scanf("%lld", &w[i]);
w[i] += w[i - 1];
}
for (int i = 1; i <= N; i++) {
for (int j = i; j <= N; j++) {
q.push_back({ i, j, 0, w[j] - w[i - 1] });
}
}
for (int i = 1; i <= M; i++) {
int l, r;
ll x;
scanf("%d%d%lld", &l, &r, &x);
q.push_back({ l, r, i, x });
}
sort(q.begin(), q.end(), cmp);
for (auto p : q) {
int l = p.l, r = p.r, id = p.id;
ll val = p.val;
if (!id) update(l, r, val);
else ans[id] = query(l, r);
}
for (int i = 1; i <= M; i++) {
if (ans[i] != -INF) printf("%lld\n", ans[i]);
else printf("NONE\n");
}
return 0;
}
7. K. Kth Query
- 今天算法设计与分析课刚讲了用快速排序求第 k 个小数。下面来一道
变形题目:
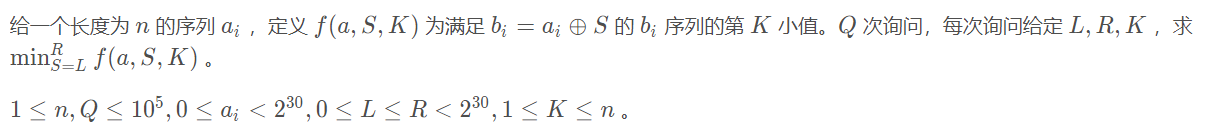
- 讲解很详细
- 代码很好
- 剩下补充的解释都在批注里面了。
#include<iostream>
#include<cstring>
#include<algorithm>
#include<vector>
using namespace std;
const int maxn = 100010, maxm = 30 * maxn;
int w[maxn], sz[maxm], son[maxm][2], idx;
int N, M;
const int lg = 29, INF = (1 << 30);
vector<vector<int>> kth;
void insert(int x) {
int p = 0;
for (int i = lg; i >= 0; i--) {
sz[p]++;
int u = ((x >> i) & 1);
if (!son[p][u]) son[p][u] = ++idx;
p = son[p][u];
}
sz[p]++;
}
void dfs(int u, int d) {
int l = son[u][0], r = son[u][1];
if (!l && !r) {
kth[u][1] = 0;
return;
}
if (l) dfs(l, d - 1);
if (r) dfs(r, d - 1);
for (int i = 1; i <= sz[u]; i++) {
kth[u][i] = INF;
//如果当前的 S 的第 d 位是 0。
if (sz[l] >= i) kth[u][i] = min(kth[u][i], kth[l][i]);
//那么答案就在右子树里面
else kth[u][i] = min(kth[u][i], (1 << d) ^ kth[r][i - sz[l]]);
//如果当前的 S 的第 d 位是 1.
if (sz[r] >= i) kth[u][i] = min(kth[u][i], kth[r][i]);
else kth[u][i] = min(kth[u][i], (1 << d) ^ kth[l][i - sz[r]]);
}
}
void build() {
//用resize,防止爆空间。
for (int i = 1; i <= N; i++) {
insert(w[i]);
}
kth.resize(idx + 1);
for (int i = 0; i <= idx; i++) {
kth[i].resize(sz[i] + 1);
}
for (int i = 0; i <= N; i++) {
kth[0][i] = INF;
}
dfs(0, lg);
}
int walk(int& p, int& k, int t) {
if (son[p][t] && sz[son[p][t]] >= k) {
p = son[p][t];
return 0;
}
else {
if (son[p][t]) k -= sz[son[p][t]];
p = son[p][1 ^ t];
return 1;
}
}
int query(int x, int lim, int k, int flag) {
int p = 0, S = 0, res = INF;
for(int i = lg; i >= 0; i--){
int t = ((x >> i) & 1);
//L的第lim的位置一定是0,R第lim的位置一定是1.
//我们让第lim的位置仍然贴合下界(上界)
//因此,从第 lim - 1 的位置,就可以0和1随便填了。
if(i < lim && t == flag){
//t==flag,比如L这一位是0的时候,那么S的这一位可以填1也可以填0
//当L这一位是1的时候,S的这一位只能填1. 因为要贴合下界。对于R也是同理
int tp = p, ts = S, tk = k;
//这一步表示不贴和下界的情况,由于后面的数可以随意填,res 就是当前的S,后面拼上 t^1,然后再拼上 kth[p的儿子][k].
if(walk(tp, tk, t ^ 1)) ts ^= (1 << i);
res = min(res, ts ^ kth[tp][tk]);
}
//这一步表示贴合下界(上界)的情况。
if(walk(p, k, t)) S ^= (1 << i);
}
//S贴合下界的情况要在最后一步更写一下答案。
res = min(res, S ^ kth[p][k]);
return res;
}
int main() {
scanf("%d%d", &N, &M);
for (int i = 1; i <= N; i++) scanf("%d", &w[i]);
build();
while (M--) {
int L, R, K;
scanf("%d%d%d", &L, &R, &K);
int p = lg;
while (p >= 0 && ((L >> p) & 1) == ((R >> p) & 1)) p--;
printf("%d\n", min(query(L, p, K, 0), query(R, p, K, 1)));
}
return 0;
}
8. H. Sequence
- 动态维护一个序列(带修改),找到最小值为 a x a_x ax 的连续子序列的数量。
- 核心内容就是如何找到左边第一个比它小的数和右边第一个比它小的数。
- 以找到右边第一个比它小的数举例:
法一:
- 可以二分搜索,在 [x, N] 找到最小值是否小于x(线段树维护)。我们对查询的区间长度二分 (lb = 0, ub = N - x + 1). 如果当前长度找到比它小的数,就缩短查询区间长度;如果当前长度找到比它小的数,就扩大区间长度。
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
const int maxn = 100010;
int w[maxn];
typedef long long ll;
struct node
{
int l, r, mmin;
}tr[maxn * 4];
int N, M;
void pushup(int u)
{
tr[u].mmin = min(tr[2 * u].mmin, tr[2 * u + 1].mmin);
}
void build(int u, int l, int r)
{
tr[u] = {l, r};
if(l == r){
tr[u].mmin = w[l];
}
else{
int mid = (l + r) / 2;
build(2 * u, l, mid), build(2 * u +1, mid +1, r);
pushup(u);
}
}
int query(int u, int L, int R)
{
if(L <= tr[u].l && tr[u].r <= R){
return tr[u].mmin;
}
int res = (1LL << 30) - 1;
int mid = (tr[u].l + tr[u].r) / 2;
if(L <= mid) res = query(2 * u, L, R);
if(R > mid) res = min(res, query(2 * u + 1, L, R));
return res;
}
void update(int u, int x, int y)
{
if(tr[u].l == x && tr[u].r == x){
tr[u].mmin = y;
return;
}
int mid = (tr[u].l + tr[u].r) / 2;
if(x <= mid) update(2 * u, x, y);
else update(2 * u +1, x, y);
pushup(u);
}
int main()
{
scanf("%d%d", &N, &M);
for(int i = 1; i <= N; i++){
scanf("%d", &w[i]);
}
build(1, 1, N);
while(M--){
int opt, x, y;
scanf("%d", &opt);
if(opt == 1){
scanf("%d%d", &x, &y);
w[x] = y;
update(1, x, y);
}
else{
scanf("%d", &x);
int lb = 1, ub = N - x + 1;
while(ub > lb){
int mid = (lb + ub + 1) / 2;
if(query(1, x, x + mid - 1) >= w[x]) lb = mid;
else ub = mid - 1;
}
int ans1 = lb;
lb = 1, ub = x;
while(ub > lb){
int mid = (lb + ub + 1) / 2;
if(query(1, x - mid + 1, x) >= w[x]) lb = mid;
else ub = mid - 1;
}
int ans2 = lb;
//printf("*** %d %d\n", ans1, ans2);
printf("%lld\n", (ll)ans1 * (ll)ans2);
}
}
return 0;
}
法二:
具体做法:只考虑求 a x a_x ax左边的值,右边类似
1.因为要尽量离 a x a_x ax近,那么贪心的检查右子树中是否含 x x x。有 并且 区间最小值 a x a_x ax 的话. 那么右边可能存在答案(1.2为什么说可能,因为可能存在 唯一 一个 v a l < a x val < a_x val<ax,其位置 > x > x >x. 这样答案就不存在,但是我们还是会往右子树走.)
2.如果右子树不符合要求,自然就往左子树看。若左子树最小值 < a x < a_x <ax. 那就往左子树搜索(这个时候答案是一定存在的).
根据:只要往左走,那么答案就一定存在。考虑其生成树的样子。要么是一直往右走。要么只能往左拐一下就直接找到答案。那么单次查询最差也就两条链。即 O ( 2 log n ) O(2\log n) O(2logn) 的复杂度.
————————————————
版权声明:本文为CSDN博主「Implicit_」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_35577488/article/details/109923150
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
const int maxn = 100010;
int w[maxn];
typedef long long ll;
struct node
{
int l, r, mmin;
}tr[maxn * 4];
int N, M;
void pushup(int u)
{
tr[u].mmin = min(tr[2 * u].mmin, tr[2 * u + 1].mmin);
}
void build(int u, int l, int r)
{
tr[u] = {l, r};
if(l == r){
tr[u].mmin = w[l];
}
else{
int mid = (l + r) / 2;
build(2 * u, l, mid), build(2 * u +1, mid +1, r);
pushup(u);
}
}
void update(int u, int x, int y)
{
if(tr[u].l == x && tr[u].r == x){
tr[u].mmin = y;
return;
}
int mid = (tr[u].l + tr[u].r) / 2;
if(x <= mid) update(2 * u, x, y);
else update(2 * u +1, x, y);
pushup(u);
}
int query1(int u, int L, int R)
{
if(tr[u].l == tr[u].r){
if(tr[u].mmin >= w[R]) return 0;
return tr[u].l;
}
int mid = (tr[u].l + tr[u].r) / 2;
if(R > mid && tr[2 * u + 1].mmin < w[R]){
int res = query1(2 * u + 1, L, R);
if(res != 0) return res;
}
if(L <= mid && tr[2 * u].mmin < w[R]){
return query1(2 * u, L, R);
}
return 0;
}
int query2(int u, int L, int R)
{
if(tr[u].l == tr[u].r){
if(tr[u].mmin >= w[L]) return N + 1;
return tr[u].l;
}
int mid = (tr[u].l + tr[u].r) / 2;
if(L <= mid && tr[2 * u].mmin < w[L]){
int res = query2(2 * u, L, R);
if(res != N + 1) return res;
}
if(R > mid && tr[2 * u + 1].mmin < w[L]){
return query2(2 * u + 1, L, R);
}
return N + 1;
}
int main()
{
scanf("%d%d", &N, &M);
for(int i = 1; i <= N; i++){
scanf("%d", &w[i]);
}
build(1, 1, N);
while(M--){
int opt, x, y;
scanf("%d", &opt);
if(opt == 1){
scanf("%d%d", &x, &y);
w[x] = y;
update(1, x, y);
}
else{
scanf("%d", &x);
ll ans1 = x - query1(1, 1, x), ans2 = query2(1, x, N) - x;
printf("%lld\n", ans1 * ans2);
}
}
return 0;
}
9. E. Phone Network
- 题意:一个长度n的数组,每个数在[ 1,m ]区间内,保证了每个数(在[ 1 , m ])至少出现过一次。对于每个 i ∈ [ 1 , m ],分别输出在原数列中,包含了 [ 1 , i ] 的所有种类数字的最短区间长度。
- 别人的题解
#include<bits/stdc++.h>
using namespace std;
const int maxn = 200010, INF = 1e9;
struct node
{
//mi[i] 表示从i开始,包含 1~x的最短区间,的右端点。
int l, r;
int mi, len, lazy;
}tr[maxn * 4];
int N, M;
vector<int> w[maxn];
void pushup(int u)
{
tr[u].mi = min(tr[2 * u].mi, tr[2 * u + 1].mi);
tr[u].len = min(tr[2 * u].len, tr[2 * u + 1].len);
}
void pushdown(int u)
{
int t = tr[u].lazy;
if(t){
tr[2 * u].mi = tr[2 * u].lazy = t, tr[2 * u].len = t - tr[2 * u].r + 1;
tr[2 * u + 1].mi = tr[2 * u + 1].lazy = t, tr[2 * u + 1].len = t - tr[2 * u + 1].r + 1;
tr[u].lazy = 0;
}
}
void build(int u, int l, int r)
{
tr[u].l = l, tr[u].r = r, tr[u].len = INF;
tr[u].mi = tr[u].lazy = 0;
if(l == r) return;
int mid = (l + r) / 2;
build(2 * u, l, mid), build(2 * u + 1, mid + 1, r);
}
void modify(int u, int l, int r, int c)
{
//if(tr[u].r < l || tr[u].l > r) return;
if(l <= tr[u].l && tr[u].r <= r){
tr[u].mi = tr[u].lazy = c;
tr[u].len = c - tr[u].r + 1;
return;
}
pushdown(u);
int mid = (tr[u].l + tr[u].r) / 2;
if(l <= mid) modify(2 * u, l, r, c);
if(r > mid) modify(2 * u + 1, l, r, c);
pushup(u);
}
//找到 [l, r] 中小于 last 的最大位置。
//即 如果mi[k]<p(i),表示x+1未被包含在这个区间,所以右端点要移到p(i),即mi[k]=p(i)
//因为last - mi[k] + 1 作为以 i 为左端点len,只能作为在 [pre, cnt] 的答案。
int find(int u, int l, int r, int last)
{
if(tr[u].mi >= last) return -1;
if(tr[u].l == tr[u].r) return tr[u].l;
pushdown(u);
int mid = (tr[u].l + tr[u].r) / 2;
int tmp = -1;
tmp = find(2 * u + 1, l, r, last);
if(tmp == -1 && l <= mid) tmp = find(2 * u, l, r, last);
return tmp;
}
int main()
{
scanf("%d%d", &N, &M);
for(int i = 1, x; i <= N; i++){
scanf("%d", &x);
w[x].push_back(i);
}
build(1, 1, N);
for(int i = 1; i <= M; i++){
int pre = 1, sz = w[i].size();
for(int j = 0; j < sz; j++){
int last = w[i][j];
int cnt = find(1, pre, last, last);
if(cnt != -1) modify(1, pre, cnt, last);
pre = last + 1;
}
if(w[i].back() + 1 <= N) modify(1, w[i].back() + 1, N, INF);
printf("%d ", tr[1].len);
}
return 0;
}
10. C. Data Structure Problem
- 题意:

- 题解:

- 线段树维护b数组的区间和, a i − s i a_i - s_i ai−si 的最大值,以及懒标记(下面会解释)。
- 如果是第一个操作,那么就单点修改 a i − s i a_i - s_i ai−si 的值。
- 如果是第二个操作,先单点修改 b 数组的值(同时维护区间和的信息),然后从 x x x 到 N N N 区间每个 a i − s i a_i - s_i ai−si 都减去 b x b_x bx 增大的值。
- 第三个操作查询即可。即 s x + m a x ( 0 , m a x { a i − s i ∣ x ≤ i ≤ n } ) s_x + max(0, max\{a_i - s_i | x \le i \le n\}) sx+max(0,max{ai−si∣x≤i≤n}).
#include<iostream>
using namespace std;
const int maxn = 200010;
typedef long long ll;
ll a[maxn], b[maxn], s[maxn];
int N, M;
struct node
{
int l, r;
ll sum, a_s, add;
}tr[maxn * 4];
void pushup(int u)
{
tr[u].a_s = max(tr[2 * u].a_s, tr[2 * u + 1].a_s);
tr[u].sum = tr[2 * u].sum + tr[2 * u + 1].sum;
}
void pushdown(int u)
{
auto & rt = tr[u], &left = tr[2 * u], & right = tr[2 * u + 1];
if(rt.add){
left.add += rt.add, left.a_s -= rt.add;
right.add += rt.add, right.a_s -= rt.add;
rt.add = 0;
}
}
void build(int u, int l, int r)
{
tr[u] = {l, r};
tr[u].add = 0;
if(l == r){
tr[u].sum = b[l], tr[u].a_s = a[l] - s[l];
}
else{
int mid = (l + r) / 2;
build(2 * u, l, mid), build(2 * u + 1, mid + 1, r);
pushup(u);
}
}
void modify1(int u, int x, int add)
{
if(tr[u].l == x && tr[u].r == x){
tr[u].a_s += add;
}
else{
pushdown(u);
int mid = (tr[u].l + tr[u].r) / 2;
if(x <= mid) modify1(2 * u, x, add);
else modify1(2 * u + 1, x, add);
pushup(u);
}
}
void modify2(int u, int x, int y)
{
if(tr[u].l == x && tr[u].r == x){
tr[u].sum = y;
}
else{
pushdown(u);
int mid = (tr[u].l + tr[u].r) / 2;
if(x <= mid) modify2(2 * u, x, y);
else modify2(2 * u + 1, x, y);
pushup(u);
}
}
void modify3(int u, int l, int r, int add)
{
if(l <= tr[u].l && tr[u].r <= r){
tr[u].a_s -= add;
tr[u].add += add;
}
else{
pushdown(u);
int mid = (tr[u].l + tr[u].r) / 2;
if(l <= mid) modify3(2 * u, l, r, add);
if(r > mid) modify3(2 * u + 1, l, r, add);
pushup(u);
}
}
ll query1(int u, int l, int r)
{
if(l <= tr[u].l && tr[u].r <= r) return tr[u].sum;
pushdown(u);
int mid = (tr[u].l + tr[u].r) / 2;
ll sum = 0;
if(l <= mid) sum += query1(2 * u, l, r);
if(r > mid) sum += query1(2 * u + 1, l, r);
return sum;
}
ll query2(int u, int l, int r)
{
if(l <= tr[u].l && tr[u].r <= r){
return tr[u].a_s;
}
pushdown(u);
int mid = (tr[u].l + tr[u].r) / 2;
ll res = -1e18;
if(l <= mid) res = max(res, query2(2 * u, l, r));
if(r > mid) res = max(res, query2(2 * u + 1, l, r));
return res;
}
int main()
{
while(cin >> N >> M){
for(int i = 1; i <= N; i++){
scanf("%lld", &a[i]);
}
for(int i = 1; i <= N; i++){
scanf("%lld", &b[i]);
s[i] = b[i] + s[i - 1];
}
build(1, 1, N);
while(M--){
int op, x;
ll y;
scanf("%d", &op);
if(op == 1){
scanf("%d%lld", &x, &y);
modify1(1, x, y - a[x]);
a[x] = y;
}
else if(op == 2){
scanf("%d%lld", &x, &y);
modify2(1, x, y);
modify3(1, x, N, y - b[x]);
b[x] = y;
}
else{
scanf("%d", &x);
ll s_x = query1(1, 1, x);
//printf("Im here01\n");
ll a_s = query2(1, 1, x);
ll res = max(s_x, s_x + a_s);
//printf("Im here02\n");
printf("%lld\n", res);
}
}
}
return 0;
}
11. Problem - D - Codeforces
- 题意:

- 几个数的乘积等于他们的LCM,等价于这几个数字两两互质。
- 那么,我们可以看他们的每一个质因数,用 r [ i ] r[i] r[i] 表示 [ i , r [ i ] ) [i, r[i]) [i,r[i]) 之间所有数字两两互质。那么 i 开始的 r [ i ] r[i] r[i] 表示下一个区间的位置。
- 找 r [ i ] r[i] r[i] 可以这样子:找到所有 a [ i ] a[i] a[i] 的质因数,看看下一个质因数的位置在哪里,然后和 r [ i + 1 ] r[i + 1] r[i+1] 这些数中取一个最小值。
- 这样子,我们可以一直
u = r[r[r[i]]];。可以联想最近公共祖先。用树上倍增的方法快速寻找。 - 把这个 r [ i ] r[i] r[i] 想象成一个树,根节点在 n + 1 n+1 n+1,子节点向父节点连边。
#include<bits/stdc++.h>
using namespace std;
const int N = 100010;
int prime[N], cnt;
int st[N], r[N], fa[N][17], depth[N], a[N];
vector<int> ps[N], divisors[N];
void sieve(int n)
{
for(int i = 2; i <= n; i++){
if(!st[i]) prime[cnt++] = st[i] = i;
for(int j = 0; prime[j] <= N / i; j++){
st[prime[j] * i] = prime[j];
if(i % prime[j] == 0) break;
}
}
for(int i = 2; i <= n; i++){
int x = i;
while(x > 1){
int v = st[x];
divisors[i].push_back(v);
while(x % v == 0) x /= v;
}
}
}
int main()
{
sieve(N - 1);
int n, q;
scanf("%d%d", &n, &q);
for(int i = 1; i <= n; i++){
scanf("%d", &a[i]);
}
for(int i = 1; i <= n; i++){
for(auto p : divisors[a[i]]) {
//printf("*** %d %d %d\n", p, a[i], i);
ps[p].push_back(i);
}
}
for(int i = 0; i < cnt; i++){
int p = prime[i];
ps[p].push_back(n + 1);
}
//根节点在 n + 1,根节点所有祖先都置为 n + 1.
r[n + 1] = fa[n + 1][0] = n + 1;
for(int i = 1; i <= 16; i++) fa[n + 1][i] = n + 1;
for(int i = n; i; i--){
r[i] = r[i + 1];
for(auto p : divisors[a[i]]){
r[i] = min(r[i], *upper_bound(ps[p].begin(), ps[p].end(), i));
}
fa[i][0] = r[i], depth[i] = depth[r[i]] + 1;
for(int k = 1; k <= 16; k++) fa[i][k] = fa[fa[i][k - 1]][k - 1];
}
while(q--){
int L, R;
scanf("%d%d", &L, &R);
int u = L;
for(int k = 16; k >= 0; k--){
if(fa[u][k] <= R){
u = fa[u][k];
}
}
printf("%d\n", depth[L] - depth[u] + 1);
}
//for(int i = 1; i <= n; i++) printf("%d ", r[i]);
//cout << endl;
//for(int i = 0; i <= 16; i++) printf("%d %d\n", i, fa[3][i]);
return 0;
}





![[Linux笔记]常见命令(持续施工)](https://img-blog.csdnimg.cn/880deb62f4704ccba141f5827eef335e.png)