目录
1 RabbitMQ
1.1 工作原理
1.2 名词解释
1.3 交换机的几种类型
2 Kafka
2.1 工作原理
2.2 基本概念
3 RocketMQ
3.1 工作原理
3.2 基本概念
4 RabbitMQ & Kafka & RocketMQ的差异
5 参考文档
1 RabbitMQ
1.1 工作原理

1.【消息生产】生产者(Producer)可以通过AMQP协议与Broker建立连接,并创建Channel通道。每个Channel通道可以独立地进行消息的生产和消费,可以提高系统的并发性和可靠性。
2.【消息存储】生产者将消息Push到交换机(Exchange)后,消息首先被存储到内存中的Exchange中。此时如果消息无法被路由到任何一个队列,消息将被丢弃。如果消息被成功路由到一个/多个队列中,消息将被存储到队列(Queue)中,待消费者进行消费。(当消息数量超过一定的值,或者Broker发生故障,消息将被持久化到磁盘)。
3.【消息消费】消息到达队列(Queue)后,消费者需要显式的向Rabbitmq发送请求,从而获取到消息。(这种模式可以灵活地控制消息的消费速度和顺序,同时还可以避免消息的重复消费和丢失。)
1.2 名词解释
▎Broker(RabbitMQ服务器)
简单理解Broker就是RabbitMQ服务器,他是接收和分发消息的应用。
▎VHost(虚拟主机)
每一个Broker可以开设多个虚拟主机,其中每一个vhost本质上是一个mini版的RabbitMQ服务器,拥有自己的Exchange(交换机)、Binding(绑定)、Queue(队列),也有自己的权限机制。
▎Exchange(交换机 )
交换机的核心作用是接受消息,并把消息路由到对应的队列上。
▎Routing key(路由键)
路由键是供交换机查看,并根据其值能够能够决定如何分发消息的健,用来指定消息的路由规则。
▎Queue(队列)
用于存储生产者生产的消息。
▎Binding(绑定)
绑定时一个动词,他是指通过路由规则(Binding Key)把交换机和队列关联起来。
▎Binding Key(绑定键)
在生产者和消费者Binding时,一般会指定一个Binding Key。当生产者发送Message给Exchange时,消息头上会携带Routing Key,当Routing Key与Binding Key匹配时,消息会被路由到对应的Queue中去
1.3 交换机的几种类型
▎Fanout
在Fanout模式下,生产者会把消息发送到Exchange,Exchange把消息路由到所有的队列中,一个消息可以被多个消费者消费。

▎Direct
在Direct模式下,生产者会把消息发送到Exchange,Exchange只会把消息路由到名字完全匹配的队列。(这里也支持两个队列使用同样的Binding Key与Exchange进行绑定)

▎Topic
在Topic模式下,生产者会把消息发送到Exchange,Exchange会通过通配符模糊路由到不同的队列中。
交换机和队列的Binding key用通配符来表示,有两种语法:
* 可以替代一个单词;
# 可以替代 0 或多个单词;
例如:lazy.orange.rabbit可以匹配到lazy.#,也可以匹配到*.orange.*。

2 Kafka
2.1 工作原理

1. 【消息生产】Producer从集群获取分区Leader,然后Producer将以Push的模式把消息写入Leader副本。Leader副本将消息写入本地,同时Follower主动从Leader副本Pull消息。Follower副本Pull消息完成后会给Leader副本一个ACK,最后Leader副本会向Producer进行ACK。
2.【消息存储】Partition就是以文件的形式存储,每个Partition下面会有多组segment文件,每组segment文件包括:.index文件、.log文件、.timeindex文件,其中.log文件就实际是存储message的地方,而.index和.timeindex文件为索引文件,用于检索消息。文件的命名是以该segment最小offset来命名的,kafka就是以这种分段+索引的方式来解决查询效率问题。
3.【消息消费】消息存储到.log文件后,消费者会主动去kafka拉消息,这里消费者也是从Leader副本拉取消息(消费者数可以小于分区数,这样可能存在一个消费者消费多个分区的情况)。
2.2 基本概念
▎Broker(Kafka集群实例)
Kafka集群的每一个服务器节点都是一个实例,用于存储和处理消息。
▎Topic(主题)
Topic是一个逻辑概念,是对消息的分类和归档。一个Topic可以被认为是一个消息的容器,所有的消息都被发布到一个Topic中,并且消费者可以订阅一个或多个Topic来接收消息。
▎Partition(分区)
分区是一个独立的有序队列,每个Topic可以被划分为多个分区。他的主要作用是提升Kafka的并发度,实现Kafka的高性能。
▎Replication(副本)
副本是指一个Partition的备份,每个Partition可以有多个副本。当主分区(Leader)故障的时候会选择一个副本(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,Follower和Leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
▎Consumer Group(消费组)
消费组(Consumer Group)是一组消费者的集合,它们共同消费一个或多个Topic中的消息。消费组中的每个消费者都会独立地从Kafka中读取消息,并进行处理。消费组的作用是实现消息的负载均衡和高可用性。
▎Offset(偏移量)
Offset是Kafka中的消息偏移量,用于标识消息在Partition中的位置。
3 RocketMQ
3.1 工作原理
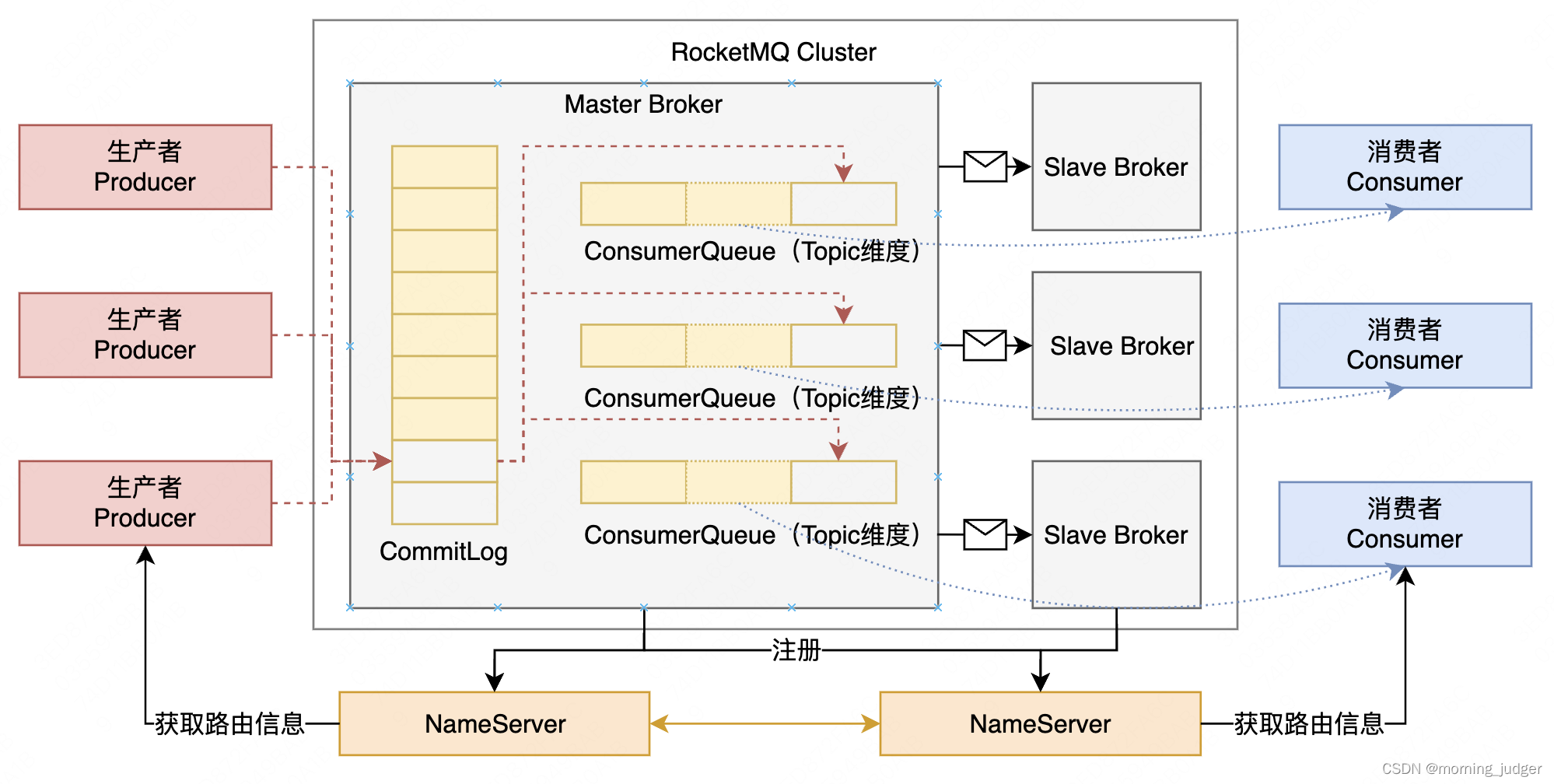
1.【消息生产】Producer发送消息,启动时先跟NameServer集群中的其中一台建立长连接,并从NameServer中获取路由信息,即当前发送的Topic消息的Queue与Broker的地址(IP + Port)的映射关系。然后根据算法策略从队选择一个Queue,与队列所在的Broker建立长连接从而向Broker发消息。在获取到路由信息后,Producer会首先将路由信息缓存到本地,再每30秒从NameServer更新一次路由信息。
2.【消息存储】Broker将消息存储到磁盘中,并维护Consumer的消费状态。Broker持久化的方案包括同步刷盘、异步刷盘。同步刷盘是指在消息发送时,将消息先写入操作系统的页缓存中,然后等待操作系统将页缓存中的数据刷入磁盘中,再返回ACK确认消息给Producer。异步刷盘是指在消息发送时,将消息先写入操作系统的页缓存中,然后立即返回ACK确认消息给Producer,同时将数据异步刷入磁盘中。
3.【消息消费】Consumer跟Producer类似,跟其中一台NameServer建立长连接,获取其所订阅Topic的路由信息,然后根据算法策略从路由信息中获取到其所要消息的Queue,然后直接跟Broker建立长连接,开始消费其中的消息。Consumer在获取到路由信息后,同样也会每30秒从NameServer更新一次路由信息。不同于Producer的是:Consumer还会向Broker发送心跳,以确保Broker的存活状态。
3.2 基本概念
▎Broker(RocketMQ集群实例)
主要负责消息的存储、查询消费,支持主从部署,一个 Master 可以对应多个 Slave,Master 支持读写,Slave 只支持读。Broker 会向集群中的每一台 NameServer 注册自己的路由信息。
▎Tag(标签)
标签(Tag)可以看作子主题,它是消息的第二级类型,用于为用户提供额外的灵活性。使用标签,同一业务模块不同目的的消息就可以用相同 Topic 而不同的 Tag 来标识。
▎NameServer(命名服务)
Name Server是RocketMQ的命名服务,它维护Topic和Broker的关系,当生产者发送消息时,它需要向Name Server查询Topic所在的Broker,然后将消息发送到对应的Broker中。
▎CommitLog(日志文件)
消息主体以及元数据的存储主体。Producer 发送的消息就存放在 commitlog 里面。
▎ConsumeQueue(消息消费队列)
消息消费队列,引入的目的主要是提高消息消费的性能,由于 RocketMQ 是基于主题 topic 的订阅模式,消息消费是针对主题进行的,如果要遍历 commitlog 文件中根据 topic 检索消息是非常低效的。
▎IndexFile(索引文件)
IndexFile(索引文件)提供了一种可以通过key或时间区间来查询消息的方法。
4 RabbitMQ & Kafka & RocketMQ的差异
▎架构模型差异
Kafka采用发布-订阅模型,消息被发布到Topic中,多个Consumer可以订阅同一个Topic中的消息。RabbitMQ和RocketMQ采用消息队列模型,消息被发送到队列中,多个Consumer可以从队列中消费消息。
▎消息传输方式
Kafka和RocketMQ采用基于TCP协议的自定义二进制协议进行消息传输,而RabbitMQ采用AMQP协议进行消息传输。
▎消息消费模式
消费模式分为推(push)模式和拉(pull)模式。push模式是broker端推送消息到consumer端,实时性高,但是需要进行流量控制以防止consumer端被压垮;pull模式是broker端去broker拉取消息,实时性较推模式差,但是可以根据自身的处理能力而控制拉取的消息量。其中Kafka是Pull模型,RabbitMQ、RocketMQ都可以支持Pull模式和Push模式。(RocketMQ的Push模式,本质是注册一个消费监听器,当监听器触发后进行Pull消息)
▎消息持久化
Kafka和RocketMQ采用基于磁盘的消息持久化方式,消息被写入磁盘中,以保证消息的可靠性和持久性。而RabbitMQ采用基于内存的消息持久化方式,消息被写入内存中,当RabbitMQ重启时,消息会丢失。
▎性能和吞吐量
Kafka和RocketMQ都是高吞吐量、低延迟的消息队列系统,可以支持每秒百万级别的消息处理。而RabbitMQ的性能和吞吐量相对较低,适合处理低延迟、高可靠性的消息传输场景。
5 参考文档
RabbitMQ介绍及部署(超详细讲解)_rabbitmq服务器_char1otte的博客-CSDN博客
rabbitMQ的详细介绍_雨会停rain的博客-CSDN博客
RabbitMQ 内部结构原理介绍_rabbitmq原理和架构_·梅花十三的博客-CSDN博客
干货:RabbitMQ核心概念及工作原理
RabbitMQ详解(7大架构原理图解)
RabbitMQ--架构原理_51CTO博客_rabbitmq原理
消息队列原理和选型:Kafka、RocketMQ 、RabbitMQ 和 ActiveMQ - 知乎
RabbitMQ的工作模式及其原理(一)_rabbitmq broker_班乃的博客-CSDN博客
为什么要使用RabbitMQ? - 知乎
分布式消息队列RocketMQ工作原理_编程小飞侠的博客-CSDN博客
Kafka与Rocketmq的区别_rocketmq和kafka区别_aasoga的博客-CSDN博客
RocketMQ 基本概念与工作原理_rocketmq工作原理(四个组件)_Cimbala的博客-CSDN博客
Kafka史上最详细原理总结(一)_kafka index 和log原理_徐小慧_Blog的博客-CSDN博客
RocketMQ之原理深入讲解 - 简书
RocketMQ 架构简介_rocketmq副本机制_XP-Code的博客-CSDN博客
RocketMQ之 CommitLog_不能放弃治疗的博客-CSDN博客
Kafka、RocketMQ、RabbitMQ的比较总结_kafka rabbitmq rocketmq_【江湖】三津的博客-CSDN博客
RabbitMQ学习(四)——RabbitMQ的运行流程_rabbitmq消费流程_再小的帆也能远航啊的博客-CSDN博客