1. 函数的分文件编写
在C++中,函数的分文件编写是一种让代码结构更加清晰的方法,通常可以分为以下几个步骤:
- 创建后缀名为
.h的头文件,在头文件中写函数的声明,以及可能用到的其他头文件或命名空间 - 创建后缀名为
.cpp的源文件,在源文件中写函数的定义,同时引入自定义头文件,将头文件与源文件绑定 - 在需要使用函数的地方,引入自定义头文件,然后直接调用函数,无需再写函数的实现
例如,如果要编写一个求两个数最大值的函数,可以这样做:
- 创建一个
max.h头文件,在其中写入以下内容:
#pragma once // 防止头文件重复包含
#include <iostream> // 引入输入输出流头文件
using namespace std; // 使用标准命名空间
// 函数声明
int max(int a, int b);
- 创建一个
max.cpp源文件,在其中写入以下内容:
#include "max.h" // 引入自定义头文件
// 函数定义
int max(int a, int b) {
return a > b ? a : b; // 三目运算符,返回最大值
}
- 在需要使用函数的地方,例如
main.cpp文件中,引入自定义头文件,并调用函数:
#include "max.h" // 引入自定义头文件
int main() {
int a = 10;
int b = 20;
cout << "The max of " << a << " and " << b << " is " << max(a, b) << endl; // 调用函数并输出结果
system("pause"); // 暂停程序
return 0;
}
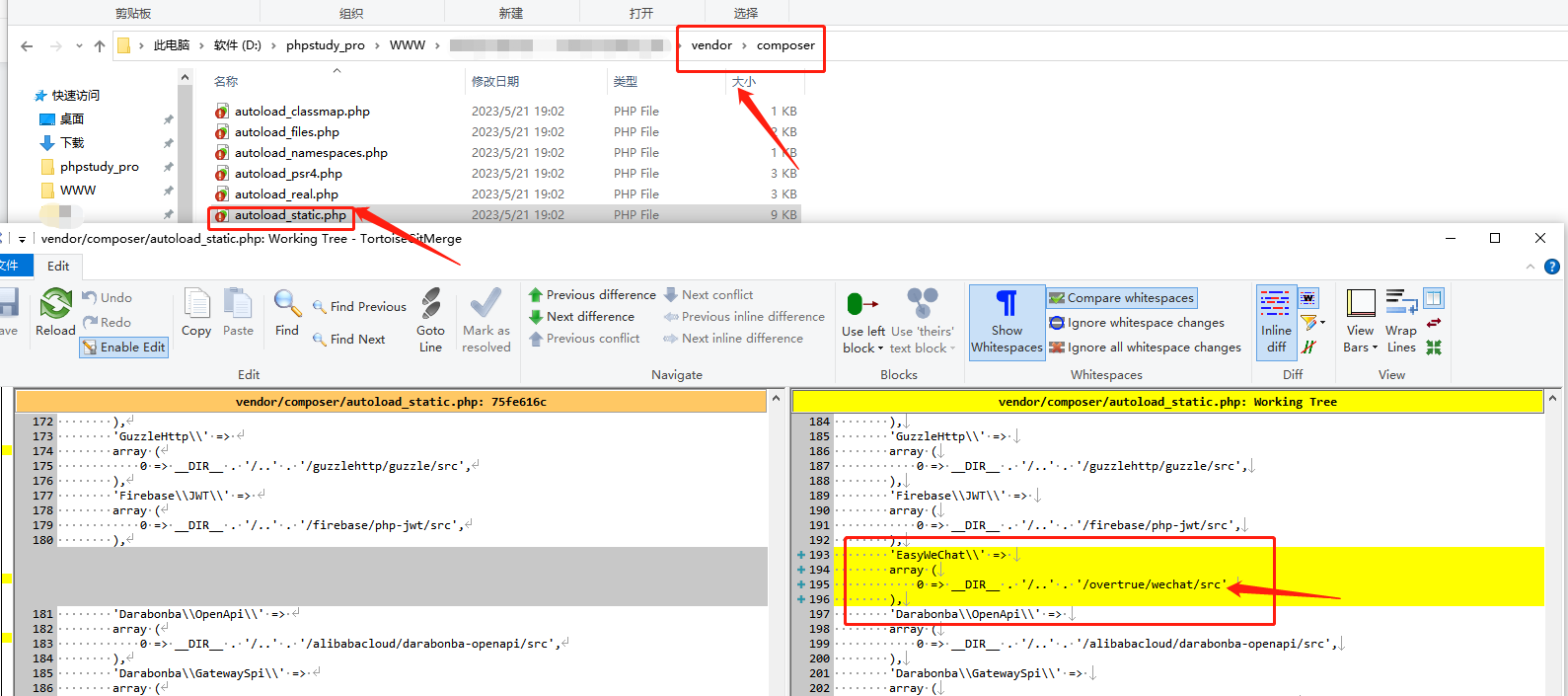
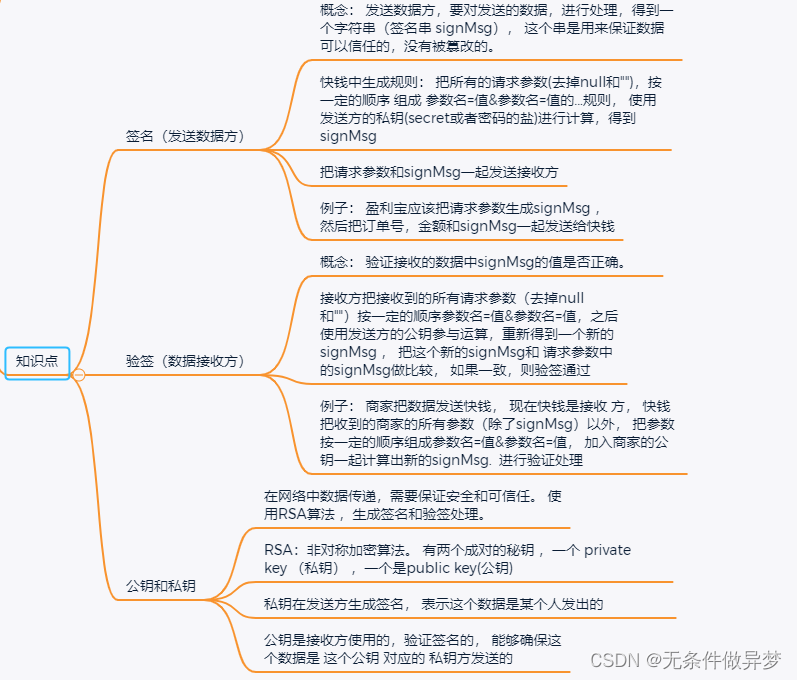
文件结构如图所示:
2. 头文件中不推荐直接定义函数
在头文件中直接写函数的定义是不推荐的,有以下几个原因:
- 在头文件中写函数的定义会导致重复定义的错误,如果这个头文件被多个源文件包含。因为每个源文件都会把头文件的内容复制过来,相当于在多个地方定义了同一个函数,这违反了单定义原则
- 在头文件中写函数的定义会增加编译的时间,如果这个头文件被频繁修改。因为每次修改头文件后,所有包含这个头文件的源文件都需要重新编译,这对于大型项目来说非常耗时
- 在头文件中写函数的定义会降低代码的可读性和可维护性,如果这个头文件包含了很多函数的定义。因为头文件的主要作用是提供函数的声明和接口,而不是实现细节。把函数的定义放在源文件中,可以让代码结构更清晰,也便于隐藏实现细节和保护数据
2.1 单定义原则
在头文件中写函数的定义会导致重复定义的错误,如果这个头文件被多个源文件包含。比如,假设有一个头文件 max.h,其中定义了一个求两个数最大值的函数:
// max.h
#pragma once
#include <iostream>
using namespace std;
int max(int a, int b) {
return a > b ? a : b;
}
然后,有两个源文件 main1.cpp 和 main2.cpp,都包含了这个头文件,并且都调用了这个函数:
// main1.cpp
#include "max.h"
int foo() {
cout << "The max of 10 and 20 is " << max(10, 20) << endl;
return 0;
}
// main2.cpp
#include "max.h"
int main() {
cout << "The max of 30 and 40 is " << max(30, 40) << endl;
return 0;
}
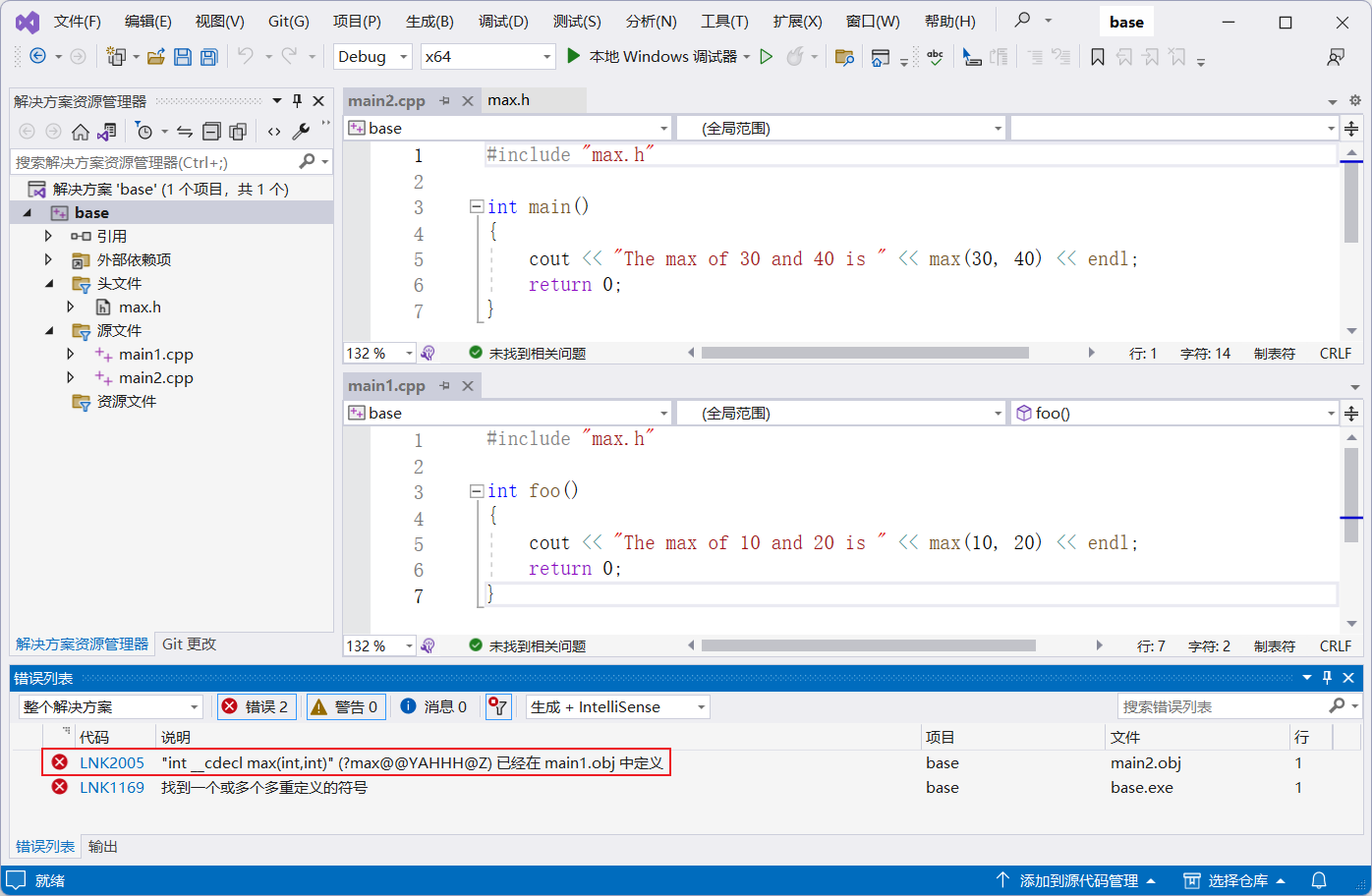
看到这里可能会有个疑问,编译的时候
main1.cpp调用max.h中的函数,但是main2.cpp中的主函数中没有调用main1.cpp中的函数,为什么还是会编译不通过呢?两个不同的文件定义同一个函数也会冲突吗?即使其中一个文件和另一个文件没有任何关系?
编译时,每个源文件会生成一个目标文件,然后链接生成可执行文件。即使 main2.cpp 没有调用 main1.cpp 的函数,但 main1.cpp 中包含了 max.h,相当于在 main1.cpp 中定义了max函数,与 main2.cpp 中的max函数冲突。当链接时,如果出现同名的函数,就会出现重复定义的错误。因此,每个函数应该只在一个源文件中定义,或者使用命名空间或静态修饰符来避免冲突
为了解决这个问题,我们应该把函数的定义放在另一个源文件 max.cpp 中,然后在头文件中只声明函数:
// max.h
#pragma once
#include <iostream>
using namespace std;
int max(int a, int b); // 函数声明
// max.cpp
#include "max.h"
int max(int a, int b) { // 函数定义
return a > b ? a : b;
}
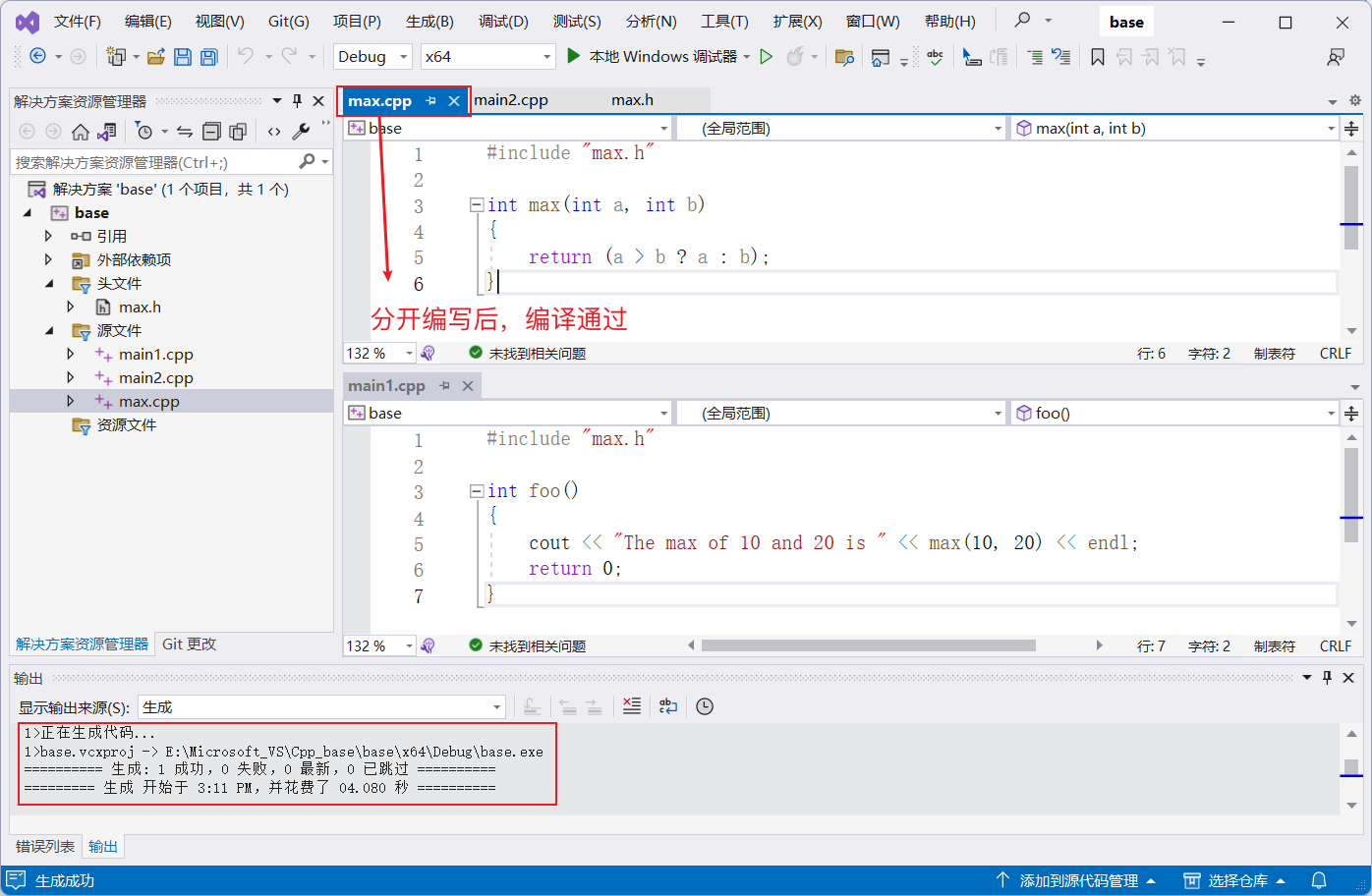
这样就可以避免重复定义的错误了
2.2 减少编译时间
在头文件中写函数的定义会增加编译的时间,如果这个头文件被频繁修改。比如,假设有一个头文件 math.h,其中定义了一些数学相关的函数:
// math.h
double sin(double x) {
// some code to calculate sin(x)
}
double cos(double x) {
// some code to calculate cos(x)
}
double tan(double x) {
// some code to calculate tan(x)
}
然后,有很多源文件都包含了这个头文件,并且都调用了这些函数。如果我们想要修改或添加某个函数的实现细节,比如改进 sin 函数的算法,那么我们就需要修改头文件 math.h。但是这样一来,所有包含了这个头文件的源文件都需要重新编译,因为它们都依赖于头文件的内容。这对于大型项目来说非常耗时。为了解决这个问题,我们应该把函数的定义放在另一个源文件 math.cpp 中,然后在头文件中只声明函数:
// math.h
double sin(double x); // 函数声明
double cos(double x); // 函数声明
double tan(double x); // 函数声明
// math.cpp
#include "math.h"
double sin(double x) { // 函数定义
// some code to calculate sin(x)
}
double cos(double x) { // 函数定义
// some code to calculate cos(x)
}
double tan(double x) { // 函数定义
// some code to calculate tan(x)
}
这样就可以减少编译的时间了,因为只有修改或添加了函数的源文件才需要重新编译
简单来说,分为两种情况
第一种:在头文件中定义函数。如果有很多源文件都引用了这个头文件,那么当头文件修改后,所有引用头文件的源文件都要重新编译,对于大型项目非常耗时
第二种:把函数的定义和声明放在不同的文件中。这样做可以使得当源文件中定义的函数发生修改时,只需要重新编译被修改的源文件就可以了,不需要所有引用这个头文件的源文件重新编译,节省了非常多的时间
为什么在头文件中定义的函数发生改变时,所有包含该头文件的源文件需要重新编译?
还是借用以上的例子,我的猜想是这样的
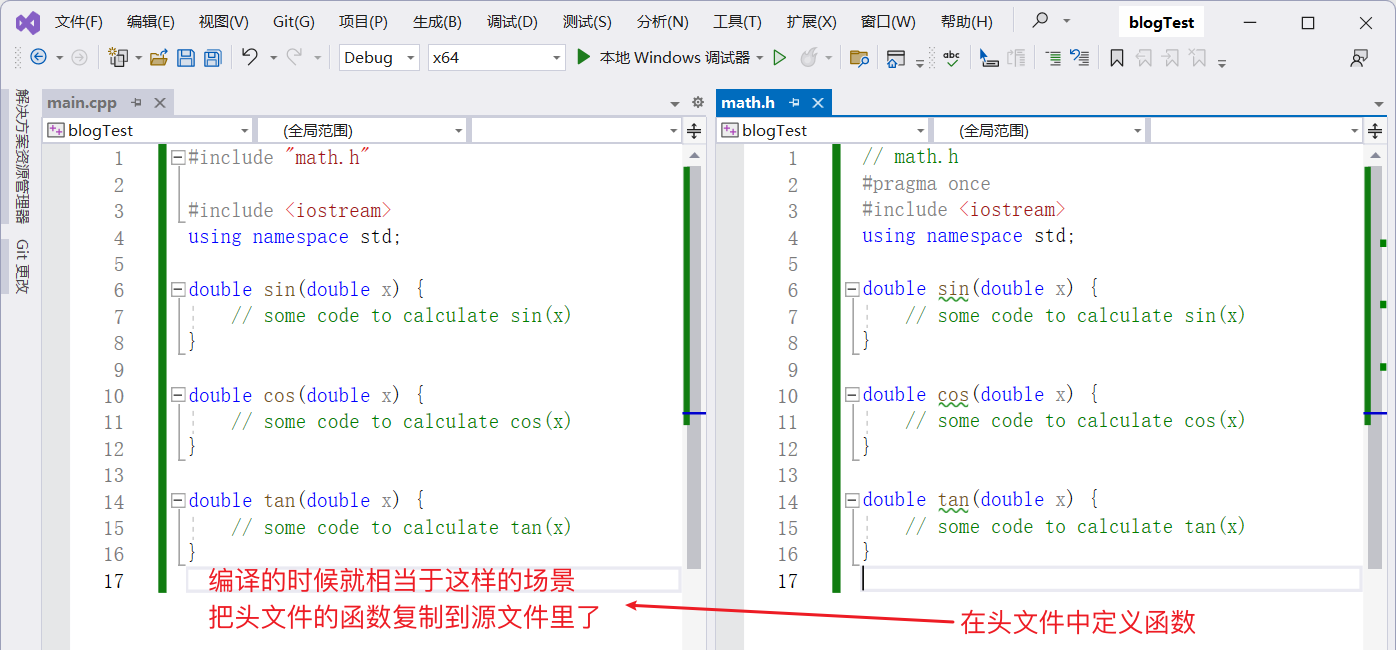
假如在 main.cpp 源文件中引用 math.h 头文件,相当于把头文件中的内容复制到了源文件里
那么如果 math.h 头文件中定义函数,并且 main.cpp 源文件中引用了 math.h 头文件,则相当于把 math.h 中的定义的函数复制到 main.cpp 源文件里,一旦头文件中的函数发生改变,那么就相当于源文件发生了改变
因此所有包含 math.h 头文件的源文件都需要重新编译
此外,多个源文件包含同一个定义函数的头文件,会导致重定义的错误。这里只是举个例子假设编译器允许这样的操作,实际上编译不会通过
调用函数时的索引顺序:
在源文件中调用函数的时候,是先到头文件里找声明的函数,然后再通过链接的过程找到对应的源文件里的函数
如下图所示,main.cpp 调用函数时,先到 math.h 中找到声明的函数,然后再通过链接的过程找到对应的源文件 math.cpp 里的函数
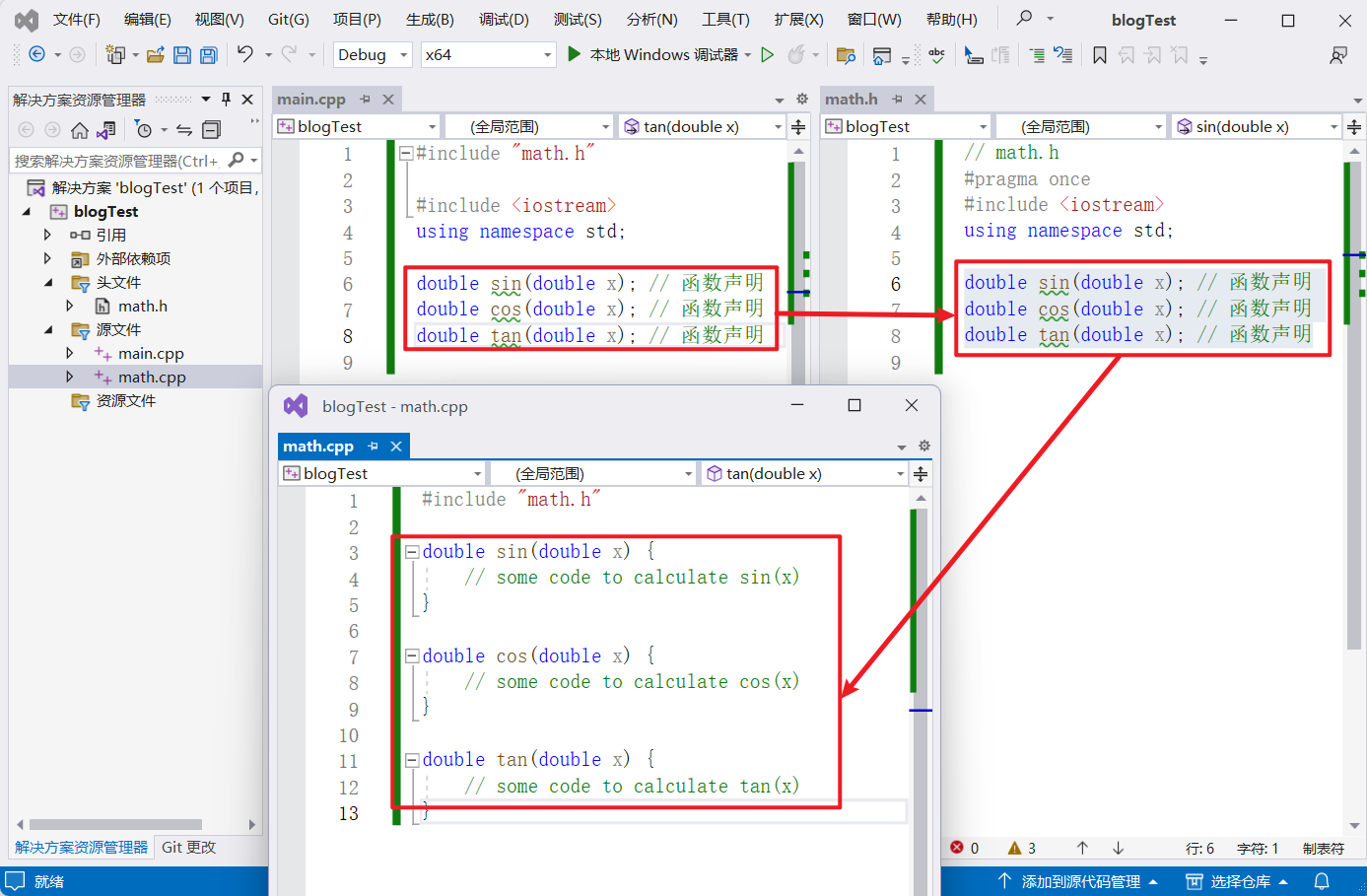
这个过程可以看作是查字典,头文件相当于目录,对应着每个函数所在的位置
2.3 可读性与安全性
在头文件中写函数的定义会降低代码的可读性和可维护性,如果这个头文件包含了很多函数的定义。比如,假设有一个头文件 utils.h,其中定义了一些工具类的函数:
// utils.h
#include <string>
#include <vector>
using namespace std;
string trim(string s) {
// some code to trim the whitespace of s
}
vector<string> split(string s, char delim) {
// some code to split s by delim
}
string join(vector<string> v, char delim) {
// some code to join v by delim
}
bool is_number(string s) {
// some code to check if s is a number
}
int to_int(string s) {
// some code to convert s to int
}
string to_string(int x) {
// some code to convert x to string
}
这个头文件包含了很多函数的定义,这会让代码看起来很冗长,也不容易找到想要的函数。而且,如果我们想要修改或添加某个函数的实现细节,比如改进 trim 函数的效率,那么我们就需要修改头文件 utils.h。但是这样会影响到所有包含了这个头文件的源文件,也会增加代码的复杂度和出错的风险。为了解决这个问题,我们应该把函数的定义放在另一个源文件 utils.cpp 中,然后在头文件中只声明函数:
// utils.h
#include <string>
#include <vector>
using namespace std;
string trim(string s); // 函数声明
vector<string> split(string s, char delim); // 函数声明
string join(vector<string> v, char delim); // 函数声明
bool is_number(string s); // 函数声明
int to_int(string s); // 函数声明
string to_string(int x); // 函数声明
// utils.cpp
#include "utils.h"
string trim(string s) {
// some code to trim the whitespace of s
}
vector<string> split(string s, char delim) {
// some code to split s by delim
}
string join(vector<string> v, char delim) {
// some code to join v by delim
}
bool is_number(string s) {
// some code to check if s is a number
}
int to_int(string s) {
// some code to convert s to int
}
string to_string(int x) {
// some code to convert x to string
}
ctor<string> v, char delim) {
// some code to join v by delim
}
bool is_number(string s) {
// some code to check if s is a number
}
int to_int(string s) {
// some code to convert s to int
}
string to_string(int x) {
// some code to convert x to string
}