C语言指针面试题
- 一.指针和数组
- 1.一维数组
- 2.字符数组
- 3.二维数组
- 二.指针
一.指针和数组
1.一维数组
int a[] = {1,2,3,4};
(1)printf("%d\n",sizeof(a));// 16
(2)printf("%d\n",sizeof(a+0));// 4/8
(3)printf("%d\n",sizeof(*a));// 4
(4)printf("%d\n",sizeof(a+1)); // 4/8
(5)printf("%d\n",sizeof(a[1]));// 4
(6)printf("%d\n",sizeof(&a));// 4/8
(7)printf("%d\n",sizeof(*&a));// 16
(8)printf("%d\n",sizeof(&a+1));// 4/8
(9)printf("%d\n",sizeof(&a[0]));// 4/8
(10)printf("%d\n",sizeof(&a[0]+1));// 4/8
解析:
(1)sizeof(数组名):计算的是整个数组的大小,单位是字节.
(2)&数组名计算的是整个数组的地址.
(3)其他情况数组名均为首元素的地址
(4)sizeof()是一个操作符,不会计算表达式的值,只会在编译期间判断值的类型,也不会去访问内存
(1) printf(“%d\n”,sizeof(a))
sizeof(a)计算的是整个数组的大小,a数组有四个int类型的元素,所以整个数组大小为4*4=16个字节
(2) printf(“%d\n”,sizeof(a+0))
a没有单独放在sizeof内部代表首元素的地址,首元素的地址+0,仍然是首元素的地址,是地址就是4/8个字节
(3) printf(“%d\n”,sizeof(*a))
a没有单独放在sizeof内部代表首元素的地址,首元素的地址解引用就是首元素,即a[0],a[0]是int类型,所以sizeof(int)就是4个字节
(4) printf(“%d\n”,sizeof(a+1))
a没有单独放在sizeof内部代表首元素的地址,首元素的地址+1,就指向第二个元素的地址,是地址就是4/8个字节
(5) printf(“%d\n”,sizeof(a[1]))
a[1]就是第二个元素,元素是int类型,相当于sizeof(int),一个int占4个字节,所以答案为4个字节
(6) printf(“%d\n”,sizeof(&a))
&a取出的是整个数组的地址,是地址就是4/8个字节
(7) printf(“%d\n”,sizeof(*&a))
&a取出的是整个数组的地址,在解引用*&a,*&两者抵消,就剩下a,所以和sizeof(a)一样,计算整个数组的大小,答案是16个字节
(8) printf(“%d\n”,sizeof(&a+1))
&a代表整个数组的大小,+1跳过了整个数组,指向了一个未知的地址,既然是地址,那大小就是4/8个字节
(9) printf(“%d\n”,sizeof(&a[0]))
a[0]就是第一个元素,取出第一个元素的地址再计算大小,既然是地址,那大小就是4/8个字节
(10) printf(“%d\n”,sizeof(&a[0]+1))
a[0]就是第一个元素,取出第一个元素的地址再+1,代表第二个元素即a[1]的地址,既然是地址,那大小就是4/8个字节
2.字符数组
//字符数组 sizeof()
char arr[] = {'a','b','c','d','e','f'};
(1)printf("%d\n", sizeof(arr));// 6
(2)printf("%d\n", sizeof(arr+0));// 4/8
(3)printf("%d\n", sizeof(*arr));// 1
(4)printf("%d\n", sizeof(arr[1]));// 1
(5)printf("%d\n", sizeof(&arr));// 4/8
(6)printf("%d\n", sizeof(&arr+1));// 4/8
(7)printf("%d\n", sizeof(&arr[0]+1));// 4/8
(1) printf(“%d\n”, sizeof(arr))
sizeof(arr),sizeof(数组名),计算的是整个数组的大小,一个char类型占一个字节,所以答案是6个字节
(2) printf(“%d\n”, sizeof(arr+0))
arr没有单独在sizeof内部,代表的是首元素的地址,首元素的地址+0还是首元素的地址,是地址就是4/8个字节
(3) printf(“%d\n”, sizeof(*arr))
arr没有单独在sizeof内部,代表的是首元素的地址,首元素的地址解引用就是首元素,首元素是char类型,所以答案是1个字节
(4) printf(“%d\n”, sizeof(arr[1]))
arr[1]代表首元素,首元素是char类型,所以答案是1个字节
(5) printf(“%d\n”, sizeof(&arr))
&arr取出的是整个数组的地址,是地址就是4/8个字节
(6) printf(“%d\n”, sizeof(&arr+1))
&arr取出的是整个数组的地址,+1跳过了整个数组,但仍然是一个地址,是地址就是4/8个字节
(7) printf(“%d\n”, sizeof(&arr[0]+1))
&arr[0]取出的是首元素的地址,+1就是第二个元素的地址,是地址就是4/8个字节
//字符数组 strlen()
char arr[] = {'a','b','c','d','e','f'};
(1)printf("%d\n", strlen(arr));// 随机值
(2)printf("%d\n", strlen(arr+0));// 随机值
(3)printf("%d\n", strlen(*arr));// 错误,非法访问
(4)printf("%d\n", strlen(arr[1]));// 错误,非法访问
(5)printf("%d\n", strlen(&arr));// 随机值
(6)printf("%d\n", strlen(&arr+1));// 随机值
(7)printf("%d\n", strlen(&arr[0]+1));// 随机值
注意
(1) strlen()是计算字符串的长度的函数,遇到\0停止,参数只能传递地址,否则程序会报错(非法访问).
(2) 非法访问:访问了不属于你自己的内存空间
(1) printf(“%d\n”, strlen(arr))
计算arr字符串的长度,但因为不知道\0在哪个位置,所以是一个随机值
(2) printf(“%d\n”, strlen(arr+0))
arr是首元素的地址,arr+0还是首元素的地址,所以从首元素开始往后找,因为不知道\0在哪个位置,所以是一个随机值
(3) printf(“%d\n”, strlen(*arr))
arr代表首元素的地址,解引用代表首元素,但strlen()需要传递地址,所以这是错误的,非法访问
(4) printf(“%d\n”, strlen(arr[1]))
arr[1]代表首元素,但strlen()需要传递地址,所以这是错误的,非法访问
(5) printf(“%d\n”, strlen(&arr))
&arr代表整个数组的地址,整个数组的地址,也是指向首元素的地址,所以从首元素开始往后找,因为不知道\0在哪个位置,所以是一个随机值
(6) printf(“%d\n”, strlen(&arr+1))
&arr代表整个数组的地址,+1跳过了整个数组,从数组结尾的下一个位置开始找因为不知道\0在哪个位置,所以是一个随机值
(7)printf(“%d\n”, strlen(&arr[0]+1))
&arr[0]代表首元素的地址,+1代表第二个元素的位置,所以从第二个元素开始往后找因为不知道\0在哪个位置,所以是一个随机值
char arr[] = "abcdef";
(1)printf("%d\n", sizeof(arr));// 7
(2)printf("%d\n", sizeof(arr+0));// 4/8
(3)printf("%d\n", sizeof(*arr));// 1
(4)printf("%d\n", sizeof(arr[1]));// 1
(5)printf("%d\n", sizeof(&arr));// 4/8
(6)printf("%d\n", sizeof(&arr+1));// 4/8
(7)printf("%d\n", sizeof(&arr[0]+1));// 4/8
(1) printf(“%d\n”, sizeof(arr))
sizeof(arr)计算的是整个数组的大小,因为上述初始化方式数组最后会隐含一个\0,所以答案是7个字节
(2) printf(“%d\n”, sizeof(arr+0))
arr没有单独在sizeof内部代表数组首元素的地址,+0还是代表首元素的地址,是地址就是4/8个字节
(3) printf(“%d\n”, sizeof(*arr))
arr没有单独在sizeof内部代表数组首元素的地址,首元素的地址解引用代表首元素,首元素是char类型,所以答案是1个字节
(4) printf(“%d\n”, sizeof(arr[1])
arr[1]是第二个位置的元素,所以答案是1个字节
(5) printf(“%d\n”, sizeof(&arr))
&arr代表取出整个数组的地址,是地址就是4/8个字节
(6) printf(“%d\n”, sizeof(&arr+1))
&arr代表取出整个数组的地址,+1跳过了整个数组,但仍然是一个地址,是地址就是4/8个字节
(7) printf(“%d\n”, sizeof(&arr[0]+1))
&arr[0]代表首元素的地址,首元素的地址+1就是第二个元素的地址,是地址就是4/8个字节
char arr[] = "abcdef";
(1)printf("%d\n", strlen(arr));// 6
(2)printf("%d\n", strlen(arr+0));// 6
(3)printf("%d\n", strlen(*arr));// 错误非法访问
(4)printf("%d\n", strlen(arr[1]));// 错误非法访问
(5)printf("%d\n", strlen(&arr));// 6
(6)printf("%d\n", strlen(&arr+1));// 随机值
(7)printf("%d\n", strlen(&arr[0]+1));// 5
(1) printf(“%d\n”, strlen(arr))
arr代表首元素的地址,所以从第一个位置开始,因为这样初始化字符串结尾会自带一个\0,所以答案是6
(2) printf(“%d\n”, strlen(arr+0))
arr代表首元素的地址,+0还是首元素的地址,所以从第一个位置开始,因为这样初始化字符串结尾会自带一个\0,所以答案是6
(3) printf(“%d\n”, strlen(*arr))
arr代表首元素的地址,对首元素的地址解引用就是首元素,但strlen需要的是一个地址,它会将97(a的码值)当作地址,从而产生错误非法访问
(4) printf(“%d\n”, strlen(arr[1]))
arr[1]代表的是首元素但strlen需要的是一个地址,它会将97当作地址,从而产生错误非法访问
(5) printf(“%d\n”, strlen(&arr))
&arr代表整个数组的大小,在值上和首元素的地址相同,所以还是从第一个位置开始,直到\0结束,所以答案是6
(6) printf(“%d\n”, strlen(&arr+1))
&arr代表整个数组的大小,+1跳过整个数组,从数组最后一个元素的下一个位置开始,什么时候遇到\0不清楚,所以是一个随机值
(7) printf(“%d\n”, strlen(&arr[0]+1))
&arr[0]取出的是首元素的地址,+1代表第二个元素的地址,所以从第二个元素开始,直到\0,所以答案是5
char *p = "abcdef";
(1)printf("%d\n", sizeof(p));// 4/8
(2)printf("%d\n", sizeof(p+1));// 4/8
(3)printf("%d\n", sizeof(*p));// 1
(4)printf("%d\n", sizeof(p[0]));// 1
(5)printf("%d\n", sizeof(&p));// 4/8
(6)printf("%d\n", sizeof(&p+1));// 4/8
(7)printf("%d\n", sizeof(&p[0]+1));// 4/8
注意: 这种初始化方式*p中存放的是字符a的地址,即字符串首字母的地址,但p本身也有自己的地址,&p取得是指针 char *的地址,如果要存放就要放在一个二级指针中
(1) printf(“%d\n”, sizeof§)
p中存放的是首字母的地址,既然是地址那就是4/8个字节
(2) printf(“%d\n”, sizeof(p+1))
p没有单独在sizeof中,所以p代表首元素的地址,+1就是第二个字母的地址,既然是地址那就是4/8个字节
(3) printf(“%d\n”, sizeof(*p))
p中存放的是首字母的地址,p解引用代表首字母,首字母是char类型,所以答案是1个字节
(4) printf(“%d\n”, sizeof(p[0]))
p[0]代表首字母。首字母是char类型,所以答案是1个字节
(5) printf(“%d\n”, sizeof(&p))
&p代表的是指针p的地址,既然是地址就是4/8个字节
(6) printf(“%d\n”, sizeof(&p+1))
&p代表的是指针p的地址,+1指针p向后移动一个char*的距离,指向一个未知的地址,既然是地址就是4/8个字节
(7) printf(“%d\n”, sizeof(&p[0]+1))
&p[0]取出的是首字母的地址,+1就是第二个字母的地址,既然是地址就是4/8个字节
char *p = "abcdef";
(1)printf("%d\n", strlen(p));// 6
(2)printf("%d\n", strlen(p+1));// 5
(3)printf("%d\n", strlen(*p));// 错误,非法访问
(4)printf("%d\n", strlen(p[0]));// 错误,非法访问
(5)printf("%d\n", strlen(&p));// 随机值
(6)printf("%d\n", strlen(&p+1));// 随机值
(7)printf("%d\n", strlen(&p[0]+1));// 5
(1) printf(“%d\n”, strlen( p))
p是一个char*的指针变量,存放的是首字母的地址,所以从首字母开始,直到\0,这样初始化,在字符串的结尾会有一个默认的\0,所以答案是6
(2) printf(“%d\n”, strlen(p+1))
p是一个char*的指针变量,存放的是首字母的地址,+1就是第二个字母的地址,所以从第二个字母开始直到\0,所以答案是5
(3) printf(“%d\n”, strlen(*p))
p是一个char*的指针变量,存放的是首字母的地址,对p解引用就是首字母,而strlen()需要的是地址,将首字母的码值作为地址,导致非法访问,程序崩溃
(4) printf(“%d\n”, strlen(p[0]))
p[0]代表的是首元素,而strlen()需要的是地址,将首元素的码值作为地址,导致非法访问,程序崩溃
(5) printf(“%d\n”, strlen(&p))
&p取得是指针char的地址,所以从char所对应的地址开始,直到\0,但不知道\0在哪,所以是一个随机值
(6) printf(“%d\n”, strlen(&p+1))
&p取得是指针char的地址,+1就是从char所对应的地址的下一个开始直到\0,但不知道\0在哪,所以是一个随机值
(7) printf(“%d\n”, strlen(&p[0]+1))
&p[0]取得是第一个元素的地址,+1代表第二个元素的地址,所以从第二个元素开始,直到\0,所以答案是5
3.二维数组
注意: 二维数组的首元素是一个一维数组
int a[3][4] = {0};
(1)printf("%d\n",sizeof(a));// 48
(2)printf("%d\n",sizeof(a[0][0]));// 4
(3)printf("%d\n",sizeof(a[0]));// 16
(4)printf("%d\n",sizeof(a[0]+1));// 4/8
(5)printf("%d\n",sizeof(*(a[0]+1)));// 4
(6)printf("%d\n",sizeof(a+1));// 4/8
(7)printf("%d\n",sizeof(*(a+1)));// 16
(8)printf("%d\n",sizeof(&a[0]+1));// 4/8
(9)printf("%d\n",sizeof(*(&a[0]+1)));// 16
(10)printf("%d\n",sizeof(*a));// 16
(11)printf("%d\n",sizeof(a[3]));// 16
(1) printf(“%d\n”,sizeof(a))
sizeof(a)计算的是整个数组的大小,所以答案是12*4=48个字节
(2) printf(“%d\n”,sizeof(a[0][0]))
a[0][0]指的是首元素,所以答案是4个字节
(3) printf(“%d\n”,sizeof(a[0]))
a[0]代表的是第一行的数组名,数组名单独放在sizeof()中代表的是整个数组的大小,所以答案是4*4=16个字节
(4) printf(“%d\n”,sizeof(a[0]+1))
a[0]代表的是第一行的数组名,a[0]并未单独放在sizeof()内部,所以代表的是第一行首元素的地址,即a[0][0]的地址,+1代表a[0][1]的地址,是地址就是4/8个字节
(5) printf(“%d\n”,sizeof(*(a[0]+1)))
a[0]代表的是第一行的数组名,a[0]并未单独放在sizeof()内部,所以代表的是第一行首元素的地址,即a[0][0]的地址,+1代表a[0][1]的地址,解引用就代表a[0][1]这个元素,所以答案是4个字节
(6) printf(“%d\n”,sizeof(a+1))
a并未单独放在sizeof()内部,所以a代表二维数组的首地址,+1代表二维数组第二个元素的地址,第二个元素是a[1]这个一维数组,但因为是地址所以是4/8个字节
(7) printf(“%d\n”,sizeof(*(a+1)))
a并未单独放在sizeof()内部,所以a代表二维数组的首地址,+1代表二维数组第二个元素的地址,第二个元素是a[1]这个一维数组,解引用代表第二个一维数组,所以答案是4*4=16个字节
(8) printf(“%d\n”,sizeof(&a[0]+1))
&a[0]取出的是第一个一维数组的地址,+1代表的是第二个一维数组的地址,是地址就是4/8个字节
(9) printf(“%d\n”,sizeof(*(&a[0]+1)))
&a[0]取出的是第一个一维数组的地址,+1代表的是第二个一维数组的地址,解引用之后就是第二行的大小,即4*4=16个字节
(10) printf(“%d\n”,sizeof(*a))
a代表二维数组首元素的地址,即第一个一维数组的地址,解引用就是第一个一维数组的大小,即4*4=16个字节
(11) printf(“%d\n”,sizeof(a[3]))
a[3]看似越界,但别忘了,sizeof()是一个操作符,他只在编译期间看类型,其余无所谓,因为a[3]的类型是(int*)[4],是第四行的地址,又因为将第四行的地址单独放在sizeof()内部,计算的是整个这一行的数组大小,即4*4=16
二.指针
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int *ptr = (int *)(&a + 1);
printf( "%d,%d", *(a + 1), *(ptr - 1));
return 0;
}
//程序的结果是什么?
//2,5
&a代表整个数组的大小,+1跳过整个数组,所以ptr指向该数组最后一个元素的下一个位置,所以 ptr - 1 指向最后一个元素的地址,* (ptr - 1)就是5,a代表首元素的地址,+1指向第二个元素的位置, *(a + 1)就是第二个元素,即2
//假设p 的值为0x100000。 如下表表达式的值分别为多少?
//已知,结构体Test类型的变量大小是20个字节
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
int main()
{
printf("%p\n", p + 0x1); // 0x100014
printf("%p\n", (unsigned long)p + 0x1);// 0x100001
printf("%p\n", (unsigned int*)p + 0x1);// 0x100004
return 0;
}
(1)p是一个结构体指针,题目上说该结构体的大小是20个字节,所以该指针+1移动20个字节,又因为p的地址是0x100000,所以 p + 0x1=0x100014
(2)(unsigned long)p + 0x1,将p转为一个无符号长整形,p的值由地址变为一个16进制数,给这个16进制数+0x1得到0x100001,再将这个值以地址的形式输出还是这个值
(3)(unsigned int*)p + 0x1,将p转为一个无符号整型的指针,导致p每次+1只移动4个字节,所以答案是0x100004
int main()
{
int a[4] = { 1, 2, 3, 4 };
int *ptr1 = (int *)(&a + 1);
int *ptr2 = (int *)((int)a + 1);
printf( "%x,%x", ptr1[-1], *ptr2);// 4,02000000
return 0;
}
&a代表的是整个数组的大小,+1跳过了整个数组,所以ptr1指向了数组的最后一个元素的下一个,又因为ptr1[-1]等于*(ptr1-1),所以 ptr1[-1]的值为数组最后一个元素即4
a代表数组的首地址,将数组首地址转为一个整形的数字再+1,相当于地址向后移动了一个字节,因为我们把部分的计算机在存储地址的时候用的都是小端存储,即低位在低地址处存储,所以数组a中的1,2,3,4在内存中的存储如下图,后移一个字节再转为(int*)也就是访问四个字节,所以答案为02 00 00 00

#include <stdio.h>
int main()
{
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int *p;
p = a[0];
printf( "%d", p[0]); // 1
return 0;
}
此题的陷阱在于二维数组初始化的方式是利用的小括号而不是中括号,小括号是逗号表达式,即结果是最后一个表达式的值,所以int a[3][2]={{1,3},{5,0},{0,0}},因此将a[0]赋给指针变量p之后,p[0]为1
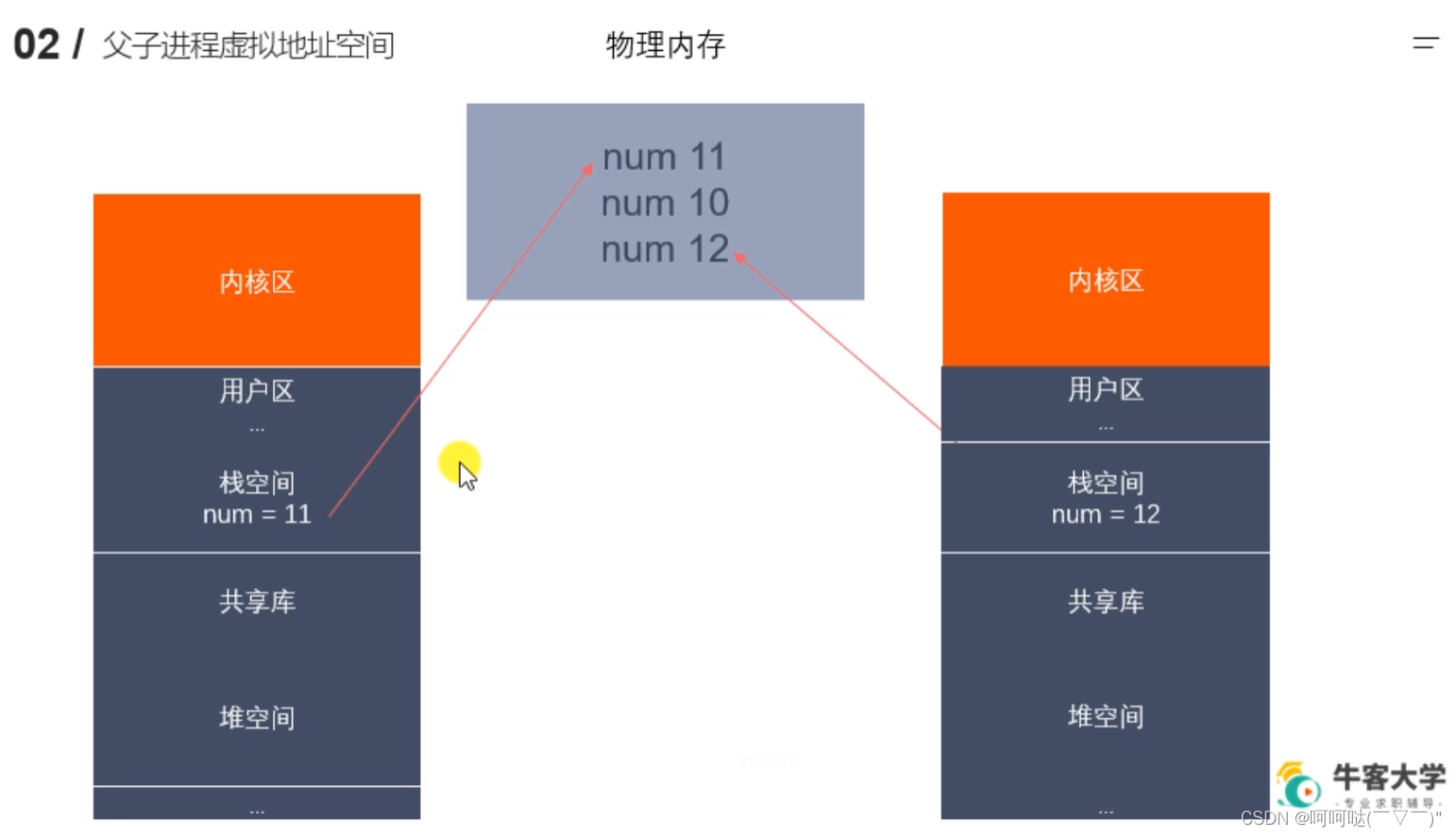
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
// FFFFFFFC,-4
return 0;
}
p是一个数组指针,指向的是大小为4的整型数组,我们画出二维数组a的内存布局找到a[4][2]的位置,同时我们可以将数组指针想成一个二维数组,这个二维数组有许多列,但每一列只能有四个元素,这样我们就能找到p[4][2]的位置,因为数组从左到右是低地址到高地址所以此时&p[4][2] - &a[4][2]相减的值为-4,-4的补码对应的16进制数就是地址即FFFFFFFC
int main()
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int *ptr1 = (int *)(&aa + 1);
int *ptr2 = (int *)(*(aa + 1));
printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1));// 10,5
return 0;
}
(1)&aa取的是整个二维数组的地址,+1跳过了整个二维数组,ptr1 - 1指向了二维数组的最后一个元素的地址,解引用就是最后一个元素即10
(2)aa代表二维数组首元素的地址,即第一个一维数组的地址+1,代表第二个一维数组的地址,解引用就是第二个一维数组的首地址,ptr2 - 1就是第一个一维数组的最后一个元素,即5
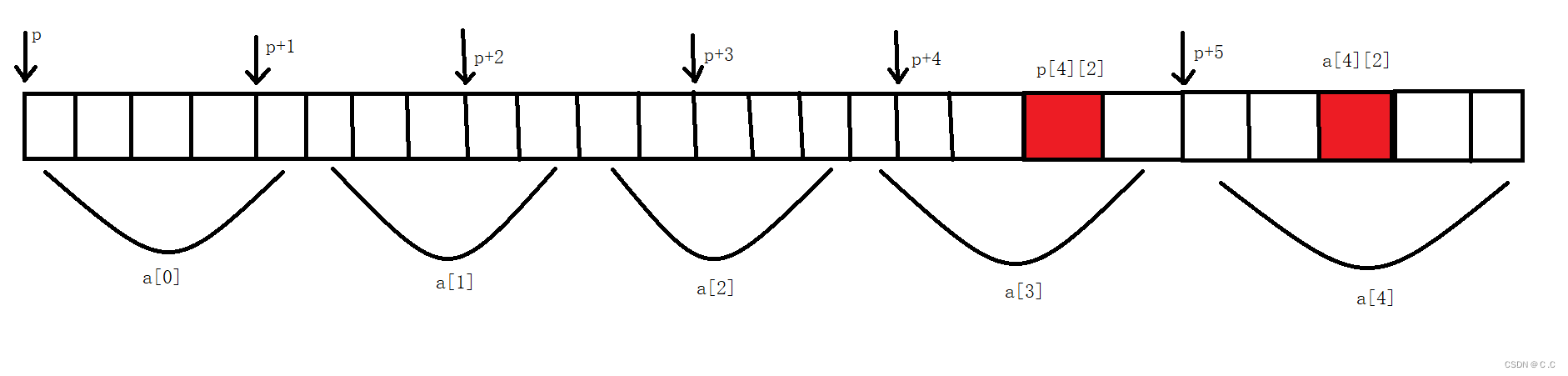
#include <stdio.h>
int main()
{
char *a[] = {"work","at","alibaba"};
char**pa = a;
pa++;
printf("%s\n", *pa);// at
return 0;
}
a是一个指针数组,将a的地址赋给二级指针pa,pa++就指向了at的地址,解引用之后就是at
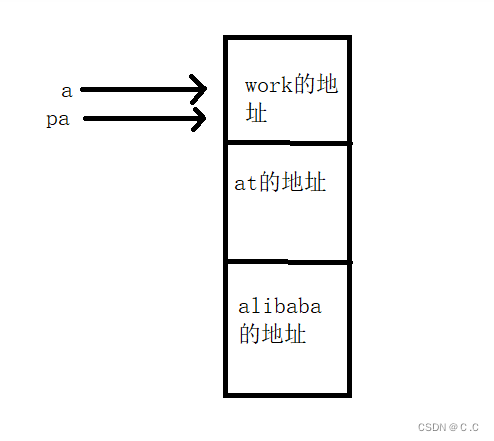
int main()
{
char *c[] = {"ENTER","NEW","POINT","FIRST"};
char**cp[] = {c+3,c+2,c+1,c};
char***cpp = cp;
printf("%s\n", **++cpp);// POINT
printf("%s\n", *--*++cpp+3);// ER
printf("%s\n", *cpp[-2]+3);// ST
printf("%s\n", cpp[-1][-1]+1); // EW
return 0;
}
做这道题之前要先清楚*,++,-- 和+的优先级,优先级由高到低是++或- -其次是*,最后是+,还要清楚指针数组在内存中的布局,如下图
(1) printf(“%s\n”, **++cpp)
因为自增运算优先级大于解引用所以cpp会先++指向下标为1的位置,即C+2的位置,再通过一次解引用得到地址C+2,此时指向C数组中下标为2的元素,再解引用得到字符串POINT
(2) printf(“%s\n”, * --*++cpp+3)
因为自增自减优先级大于加法,所以先执行左边,最后+3,因为上一次cpp自增过一次,所以这次cpp还是指向下标为1的位置.这次cpp先++指向下标为2的位置,即C+1,在解引用得到C+1,指向C数组中下标为1的位置,在执行减减操作,指向C数组中下标为0的位置,再+3得到字符串ER
(3) printf(“%s\n”, *cpp[-2]+3)
cpp[-2]等于*(cpp-2),所以*cpp[-2]就等于 ((cpp-2)),由于上次cpp指向下标为2的位置,所以cpp-2就指向下标为0的位置,即C+3,再通过解引用找到C数组中下标为3的位置,再解引用找到字符串FIRST,再+3得到ST
(4) printf(“%s\n”, cpp[-1][-1]+1)
cpp[-1][-1]等价于*(*(cpp-1)-1),这里注意上面的cpp[-2]不会改变cpp的位置,只有自增和自减才会改变位置所以cpp此时指向的还是下标为2的位置即C+1,cpp-1指向C+2的位置解引用指向C数组中下标为2的位置,然后再减1,指向C数组中下标为1的位置在解引用+1得到字符串EW