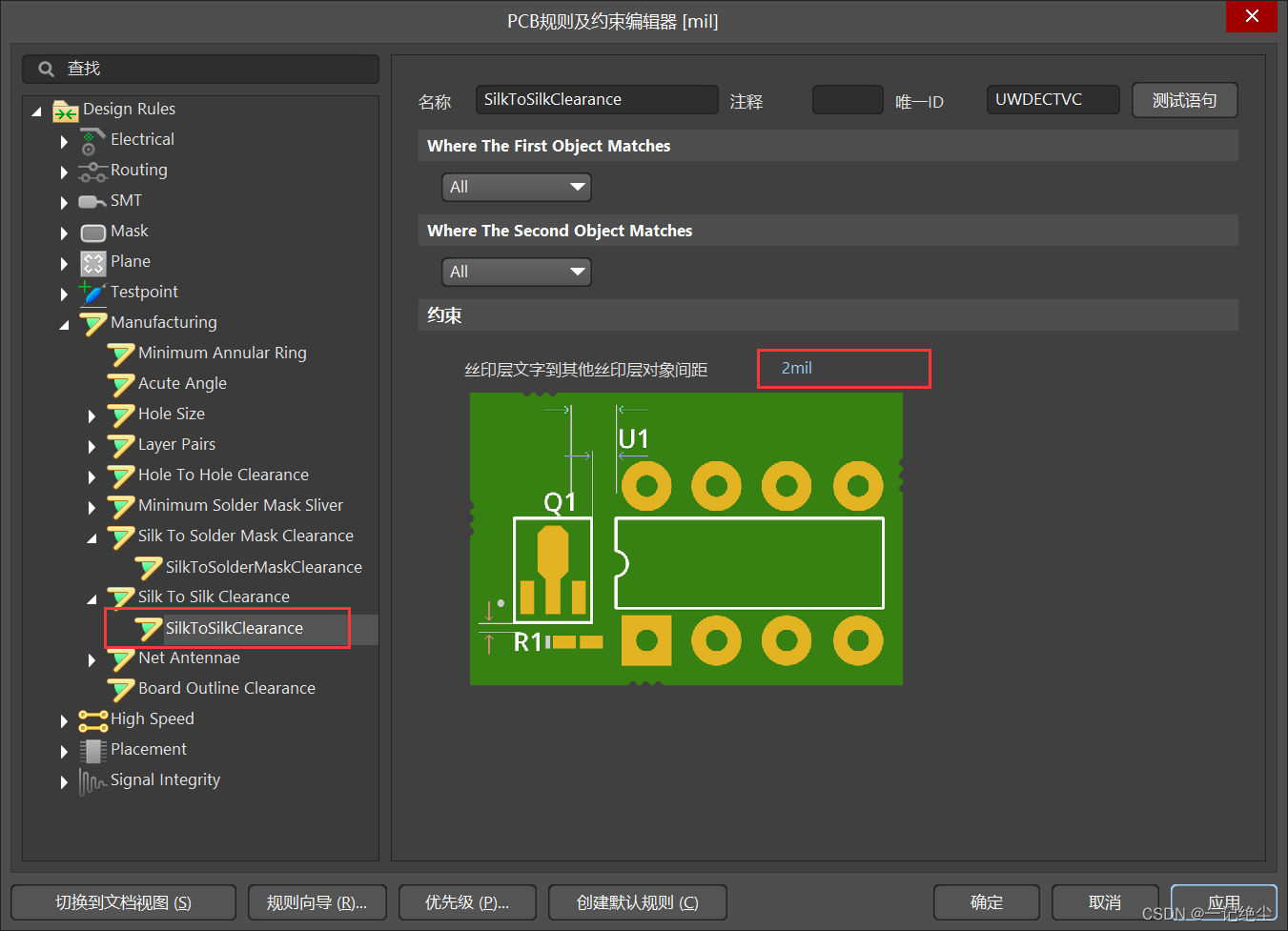
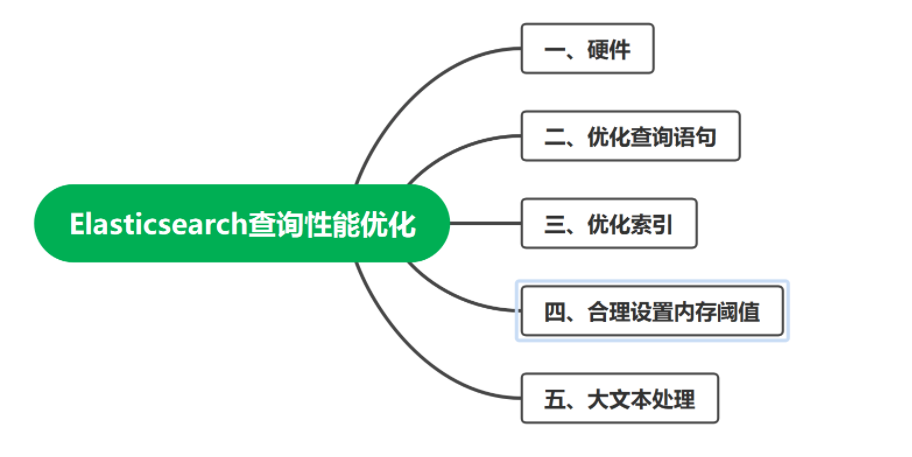
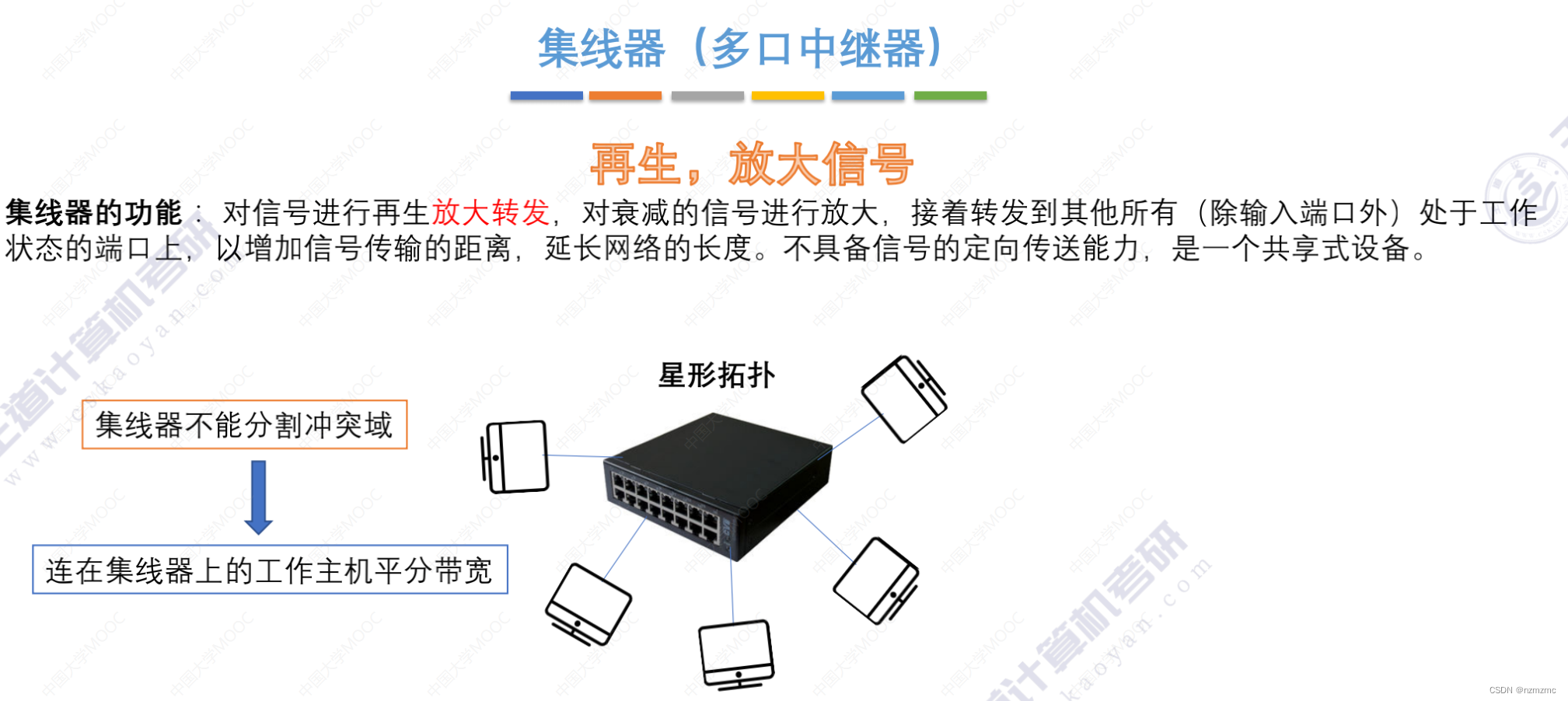
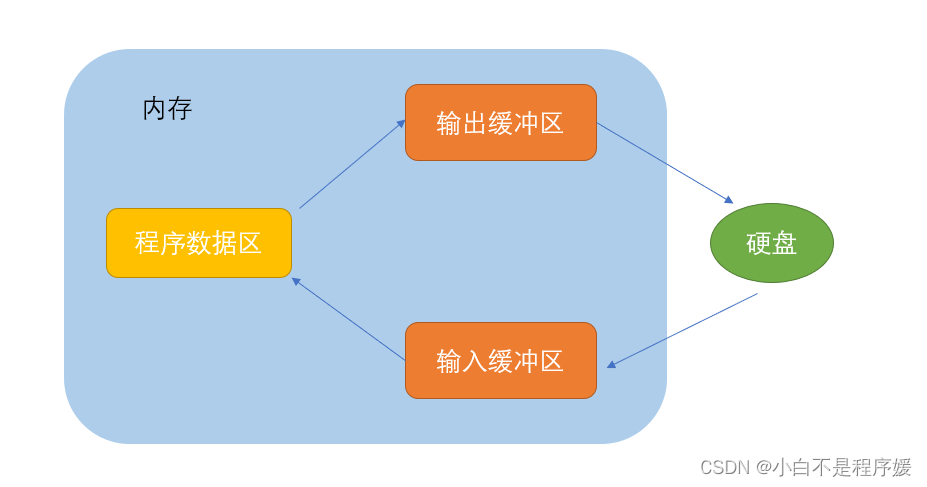
Redis分区是指将数据分散到不同的Redis实例,降低单个Redis实例内存和高并发请求的压力。
为什么要做分区:
目前来说前面所学知识都是基于Redis单实例上进行的,及时是哨兵模式也只是保证了单个Redis实例的可用性。当内存数据越来越多时单个Redis实例将会面临内存问题,同时在高并发场景下的执行压力(因为所有的请求都直接聚焦到单个Redis实例上)。
总结:1、分散数据存储,减少单个Redis实例的存储空间,同时也提高了Redis执行效率。
2、分散请求指令,减少单个Redis实例的并发压力,从CPU、网络等多方面都有性能提升。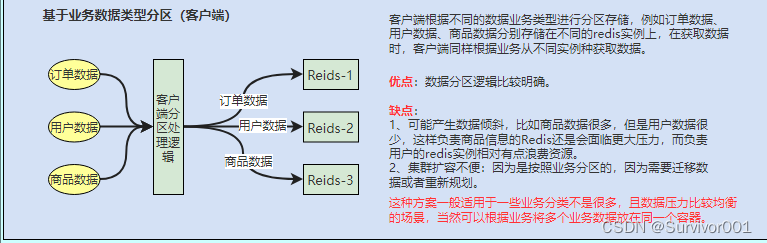
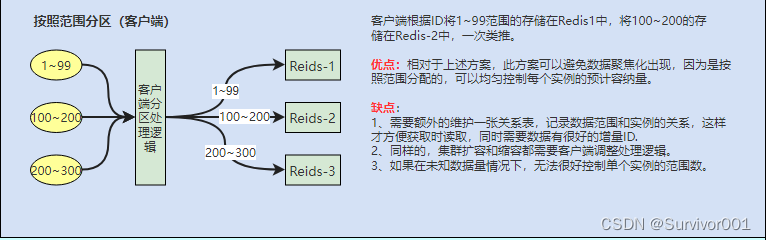
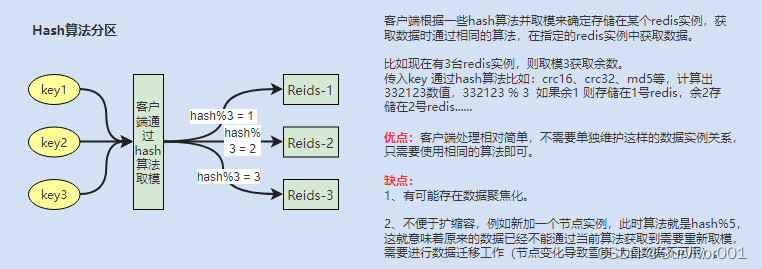
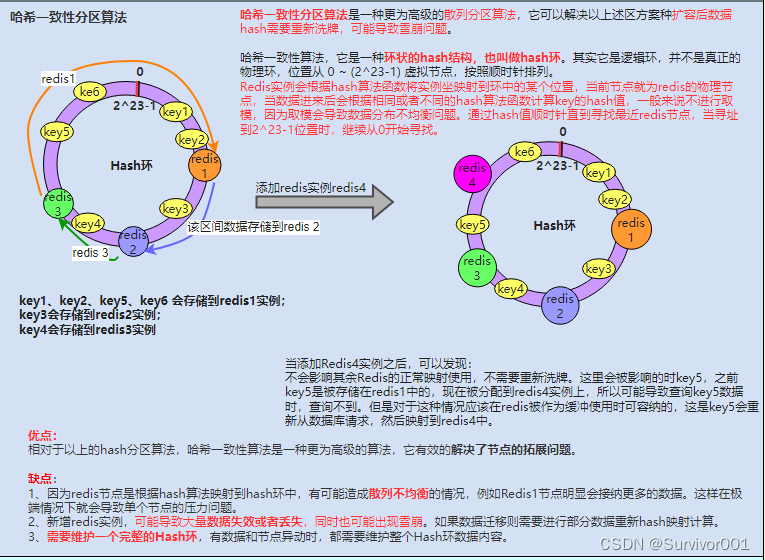
 以上所说分区算法可以适用在不同的架构层:
以上所说分区算法可以适用在不同的架构层:
客户端分区:在客户端自己实现算法分区、Jedis等。大多数客户端已经实现了客户端分区。
代理分区:使用代理工具实现分区,比如predixy、towmproxy代理都是通过一致性hash算法来实现的分区。查询路由(Query routing) : 意思是客户端随机地请求任意一个redis实例,然后由Redis将请求转发给正确的Redis节点。而Redis再此基础上提出了哈希槽的概念:如下
哈希槽
在Redis中提出了哈希槽的概念,可以理解为它是将hash环变成 了一个 拥有0~16383个物理槽位(slots)的逻辑环,redis通过redis节点的个数的均匀的分配不同的槽位给redis节点,当有key进来时,通过哈希算法CRC16将key映射到对应的哈希槽位,负责该槽位的redis节点进行管理。Redis的集群Cluster就是通过哈希槽来实现的分区。

为什么是16384个槽位?
因为在Cluster中结点之前是通过PTP , 流言模式进行交流的,需要一定的网络IO开销,16384是Redis开发者衡量的一个较可靠数量,通知官方也建议实例数不要超过1000。
原图地址: