Elasticsearch是一种流行的搜索引擎和分布式文档存储解决方案,它的高效性能和可伸缩性使其成为许多应用程序的首选存储引擎。在工作中,优化Elasticsearch的检索性能是一个非常重要的任务,可以大大提高应用程序的响应速度和用户体验。下面我们将讨论如何优化Elasticsearch的检索性能,以及如何处理大文本文档。
一、确保良好的硬件和网络性能
Elasticsearch的性能受到硬件和网络等多个因素的影响。因此,在优化检索性能之前,要确保服务器硬件和网络性能足够好。尽可能使用高速的网络连接和SSD硬盘,这样可以显著减少搜索响应时间。
二、优化Elasticsearch的查询语句
Elasticsearch的查询语句是影响性能的关键因素之一。查询语句越复杂,性能就越低。因此,可以通过以下几种方式来优化查询语句:
-
尽量使用简单的查询语句,避免使用复杂的正则表达式、通配符查询等。
-
使用过滤器查询(
filter query)替代普通查询(bool query),可以显著提高性能。 -
将查询结果限制为必要的字段,避免返回不必要的数据。
-
避免使用远程互联网数据,提高查询速度。
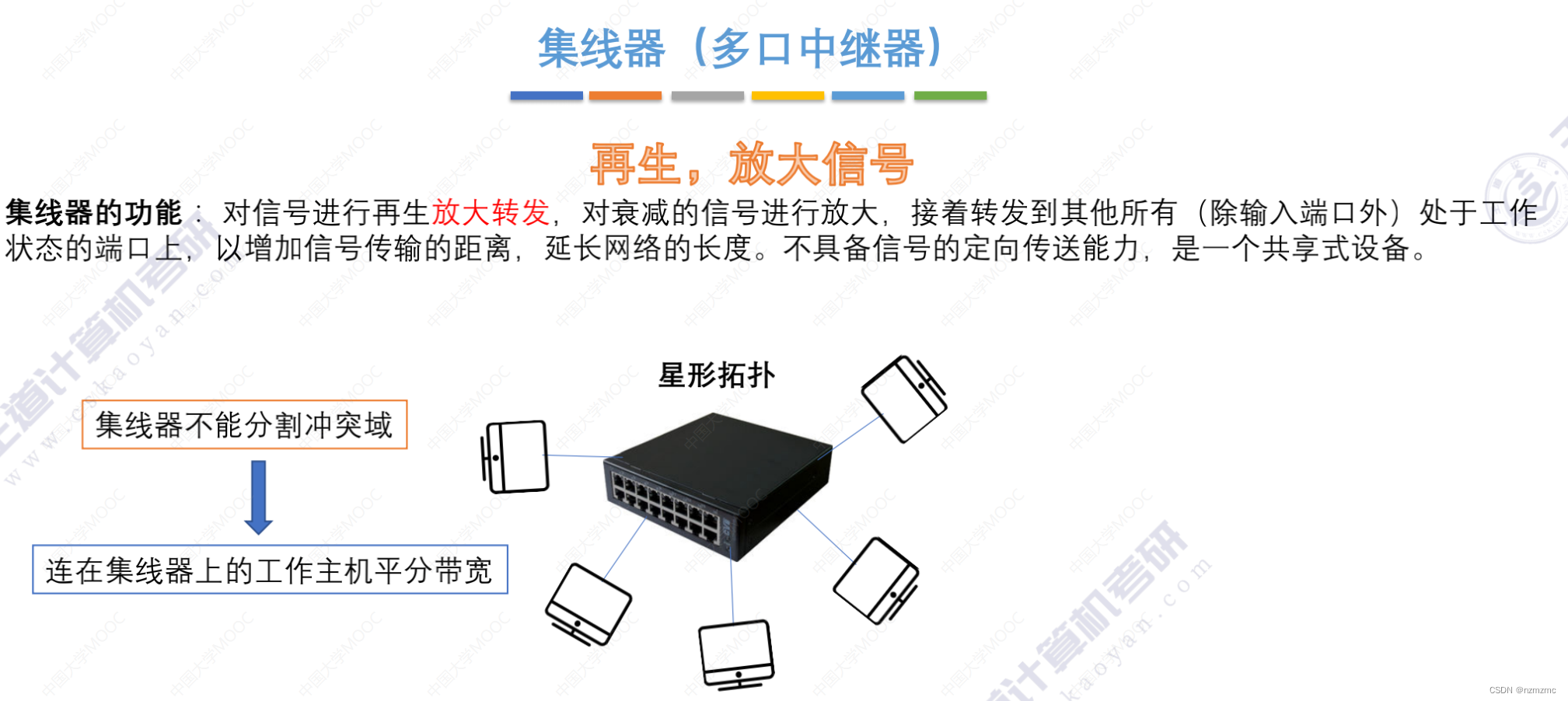
三、优化Elasticsearch的索引
Elasticsearch的索引是另一个影响性能的关键因素。以下是一些优化索引的方法:
-
将索引设置为只读,可以提高索引的读取速度。
-
合理设置分片和副本,可以提高索引的并行性和可靠性。
-
只为必要的字段创建索引,避免创建不必要的索引。
-
定期合并段(
merge segments)来减少磁盘碎片和优化索引性能。
四、合理设置Elasticsearch的内存阈值
Elasticsearch使用Java虚拟机(JVM)来运行,因此可以通过设置JVM内存大小来优化性能。一般来说,将JVM内存设置为可用物理内存的一半比较合适,但是如果内存阈值设置过大,可能会导致JVM崩溃或性能下降。如果遇到内存阈值超过设置的情况,Elasticsearch会默认将大文本文档拆分为多个小文档进行索引和查询,以避免内存溢出和性能下降问题。
综上所述,优化Elasticsearch的检索性能需要综合考虑硬件、网络、查询语句、索引和内存等多个因素。通过优化这些因素,可以显著提高Elasticsearch的检索性能和响应速度,从而提高应用程序的用户体验。
五、大文件处理
现在有这么个场景,我有一个文件,大小2g,我读取这2g的文本内容保存到elasticsearch的一个content字段中,这个content字段是text类型
当将Elasticsearch的JVM内存最大设置为4GB时,就可以将整个2GB的文本内容读取到内存中,然后将其存储到Elasticsearch的content字段中。由于JVM内存设置为4GB,Elasticsearch可以使用的最大内存为4GB,在索引和查询过程中都可以充分利用这4GB的内存来提高性能。
当将Elasticsearch的JVM内存最大设置为2GB时,就不能将整个2GB的文本内容读取到内存中。在将文本内容存储到Elasticsearch的content字段中时,Elasticsearch会将文本内容分成多个小块进行索引和存储,每个小块的大小取决于Elasticsearch的分片大小、文档段大小等因素。因此,在查询时,Elasticsearch需要从多个小块中读取数据并进行组合,这可能会影响查询性能。如果文本内容的块数太多,查询性能可能会显著下降。
-
分片大小和文档段大小
文本内容在Elasticsearch中被拆分成多个小块的大小取决于两个因素:分片大小和文档段大小。
分片大小是指在创建索引时将一个索引分成多个分片,每个分片可以存储一部分文档。默认情况下,Elasticsearch会将索引分成5个分片。每个分片都是一个独立的Lucene索引,可以在不同的节点上分布式存储。如果索引较大,可以增加分片数以提高查询性能和可伸缩性。
文档段大小是指在Lucene中,每个分片都被划分为多个文档段(segment),每个文档段都是一个独立的倒排索引文件。默认情况下,Elasticsearch每隔30分钟就会合并一次文档段,以减少磁盘碎片和优化索引性能。文档段的大小可以通过调整合并策略来控制。
-
拆分块的处理
在Elasticsearch中,文本内容被拆分成多个小块并不是保存在磁盘中的,而是保存在内存中的。每个小块是一个独立的Lucene文档,可以通过分片和文档段来存储和管理。当对文本内容进行查询时,Elasticsearch会从多个小块中读取数据并进行组合,以返回查询结果。
对于一个大小为2GB的文本,当将Elasticsearch的JVM内存最大设置为2GB时,Elasticsearch无法将整个文本读入到内存中,因此会将文本拆分为多个小块,并将它们存储在磁盘上的多个Lucene文档中。当进行查询时,Elasticsearch会从磁盘中读取这些小块,并在内存中对它们进行排序、过滤和组合,然后返回查询结果。由于在查询过程中,Elasticsearch需要将多个小块读入内存并进行组合,因此查询性能可能会受到一定的影响。
当Elasticsearch需要读取多个小块进行查询时,它并不会一次性将所有的小块全部加入内存中,而是采用分批读取的方式,以避免内存不足的情况发生。具体来说,当进行查询时,Elasticsearch会首先从磁盘中读取一部分小块到内存中,以进行排序、过滤和组合等操作,然后将处理过的结果再与后面的小块进行组合。这样,Elasticsearch可以在不占用过多内存的情况下完成查询操作。
假如1000个文本块,在合并到800个文本块时,Elasticsearch在查询过程中发现内存不足时,会根据查询优先级和内存使用情况等因素自动进行GC(垃圾回收),以释放一部分内存。如果GC之后仍然无法满足查询的内存需求,Elasticsearch会将查询暂停,等待内存空间释放后再继续执行查询操作。
本文由 mdnice 多平台发布