此前,由 InfoQ 中国举办的 QCon 全球软件开发大会在广州圆满落幕。本次大会有近百位国内外技术大咖现场分享前沿技术案例与创新实践,共有十二个专题,近五十余场分享。Databend Cloud 联合创始人张雁飞受邀参与了此次技术盛宴,并在新型数据库专场进行了一次主题为《 Databend: 大模型时代的 Cloud Warehouse 设计探索 》的演讲。
演讲嘉宾:张雁飞 Databend: GitHub - datafuselabs/databend: A modern cloud data warehouse focusing on reducing cost and complexity for your massive-scale analytics needs. Open source alternative to Snowflake. Also available in the cloud: https://app.databend.com 🧠
嘉宾介绍:Databend Cloud 联合创始人 ,前阿里云数据库内核组早期成员、前青云数据库团队负责人。开源 Databend 项目主要负责人。
本次分享聚焦于大模型时代下的 Cloud Warehouse 设计探索,分析如何利用开源与商业 LLMs 提升 Cloud Warehouse 的能力,实现更智能、自动化的数据分析。本次分享主要分为两个部分:
-
现代的数仓如何设计
-
数仓如何与 AI 结合
为什么需要现代云数仓
当用户想要进行大数据分析时,心里所期望的基本是:
我要进行一次分析,希望这个分析尽可能快地完成,同时,我只希望为实际使用的资源付费。
成本 = 实际资源用量 * 使用时间
下面我们来探讨下数据仓库应该如何满足这个需求。首先我们看看传统数仓架构在满足这个需求上存在哪些问题。
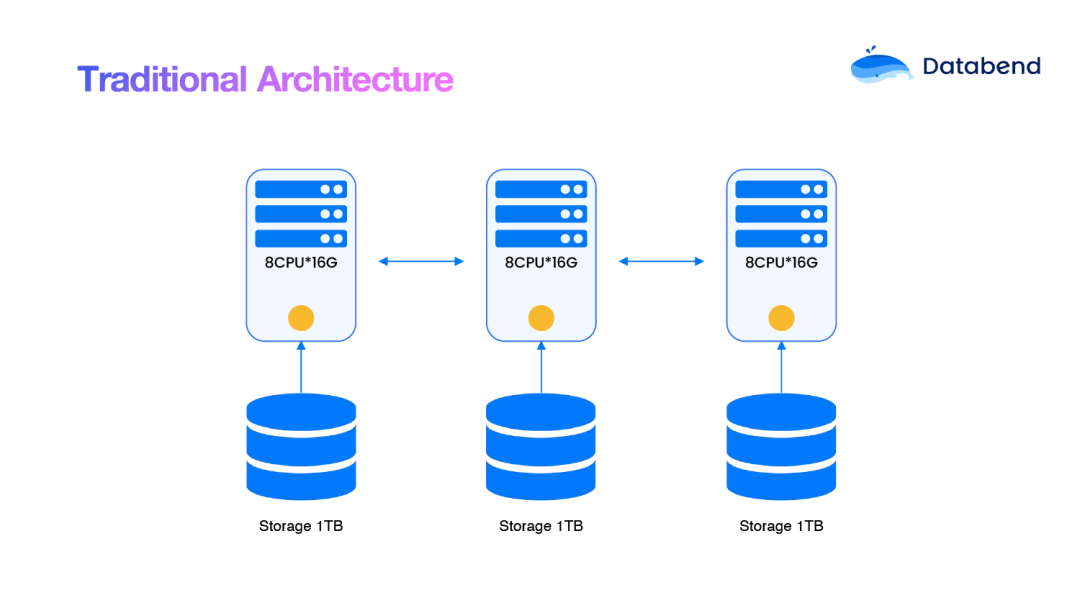
在传统数据仓库架构中,一般采用的是 share-nothing 架构,CPU、内存和存储紧密绑定,这种设计一般被称为南北向设计,它需要依靠数据分区来实现计算任务的拆分。然而,在这种架构中,往往会产生大量的冗余副本,造成资源的浪费。当我们需要添加新的节点时,就会面临数据的迁移和均衡问题,导致资源交付不是很及时。

所以在传统架构下,用户数据和计算完全耦合在一起,整体的成本相对较高:
传统数仓架构的成本 = 资源 * 开机时间
那么 Databend 新一代云原生架构是如何满足这种需求的呢?
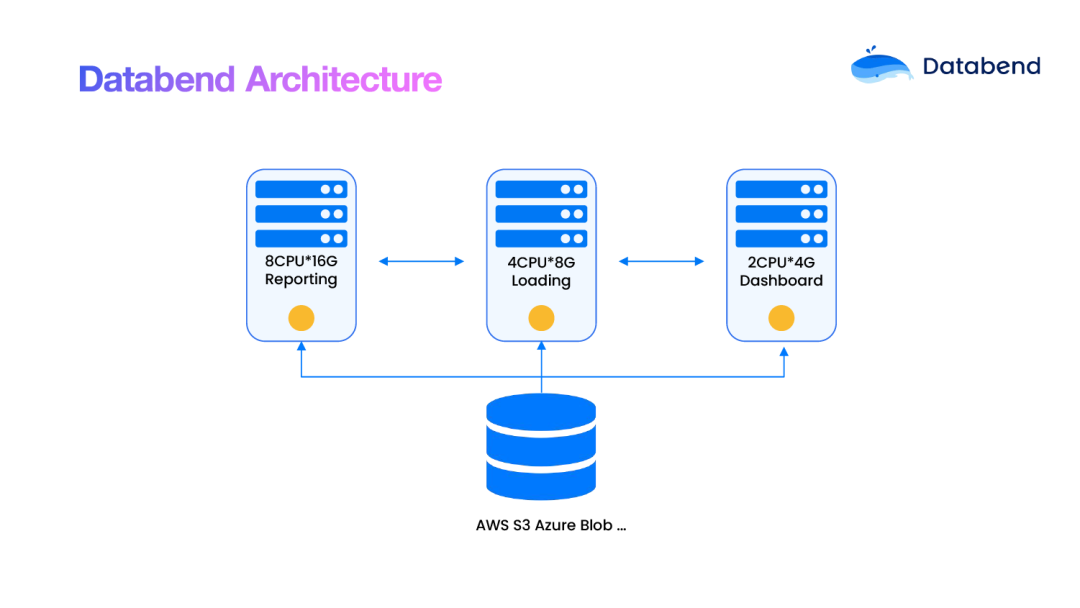
Databend 的架构在设计上做了很多改进:
-
基于共享存储的设计: Databend 支持多种对象存储,包括 Amazon S3, Azure Blob, OSS, COS 等。这种设计模式允许存储按使用量付费,具有高度的弹性。当计算节点需要扩展时,数据无需进行任何移动。
-
存储和计算分离的架构: 在此架构下,计算节点可以根据需求进行动态启动。当业务处于空闲状态时,计算节点会自动进入休眠,从而有效节省资源。
-
面向对象存储的调度器设计: 由于对象存储存在多种限制并且易于抖动,其并非专为数据仓库设计。因此,Databend 的调度器和优化器针对对象存储进行了大量优化。例如,调度器上的存储和计算在运行时具有双向感压特性,同时在执行 GroupBy shuffle 时,传输的是文件地址而非数据。
-
高度的弹性伸缩性: 借助 Kubernetes(k8s)的能力,Databend 能够快速进行弹性伸缩,以适应各种业务需求和负载变化。

在设计 Databend 时,我们借鉴了目前市场上一些优秀的数仓设计。例如,我们参考了 Clickhouse 的向量化设计,以提高单机的性能。同时,我们也借鉴了 Snowflake 的集群优点,以增强分布式计算能力。综合了这些优点后,我们选择了 Rust 语言进行重新研发和实现。Databend 还有一个重大的的改进,我们把每一个功能层都做了微服务化,这样它的架构大概是:
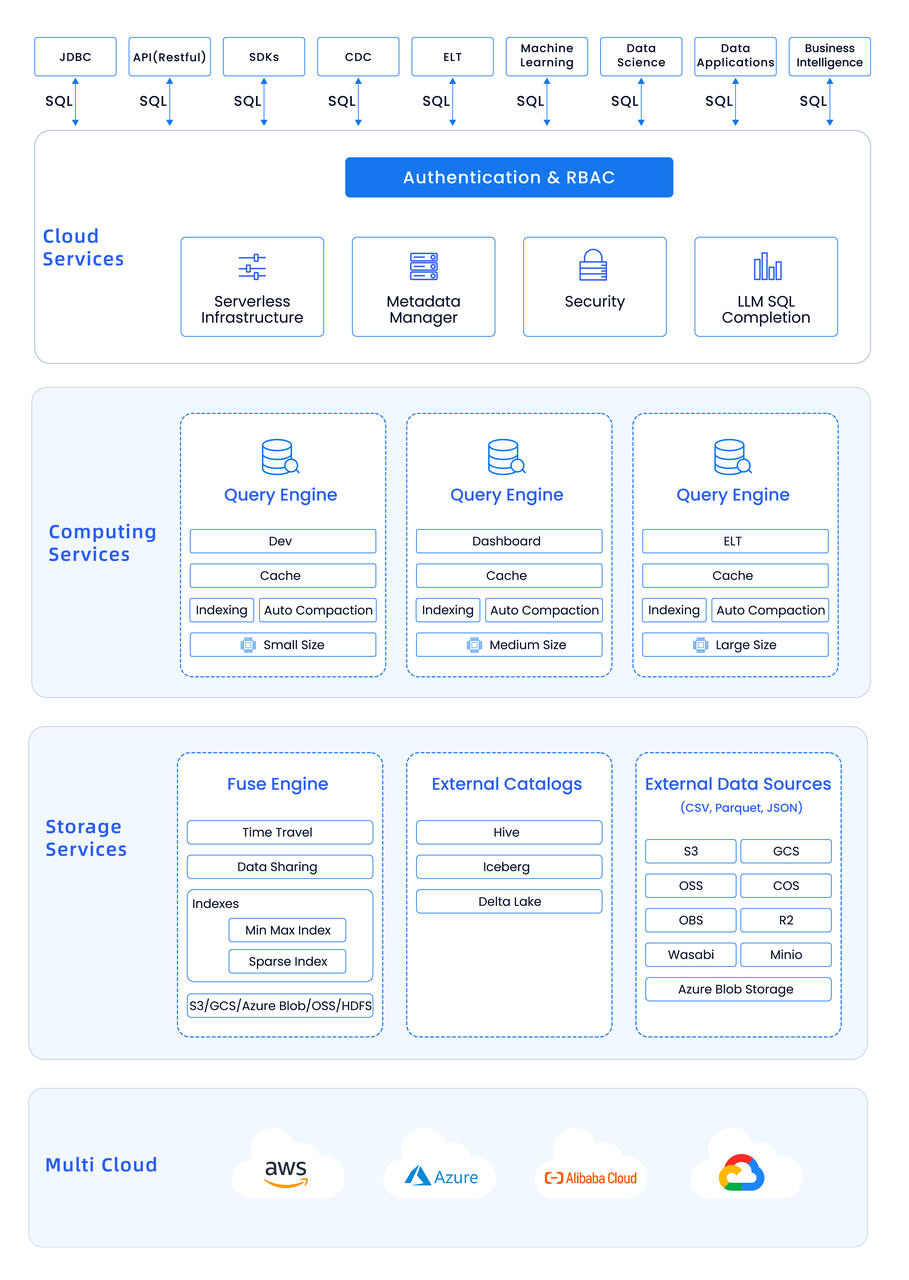
然而,Databend 的设计过程中也充满了挑战,因为云原生数仓的设计与传统数仓的设计有着显著的差异。主要的挑战主要体现在以下几个方面:
1️⃣ 大规模数据写入的网络流量费用
在处理大规模数据写入时,可能会在云端产生显著的网络流量费用。
2️⃣ 基于对象存储的设计问题
由于对象存储本身并非专为数仓设计,因此,在平衡 CPU、网络 IO、本地 IO 的延迟和带宽上限时,可能会遇到各种挑战。
3️⃣ 提升 Databend 云数据仓库的智能化程度
我们希望设计一个能够自动处理智能索引的系统,以提高查询效率。
4️⃣ 数据仓库与数据湖(Data Lake)的整合问题
尽管将二者结合可能带来新的设计挑战,但我们坚信 Lake-First 是未来的发展趋势。因此,Databend 采用 Catalog 的便捷方式来支持读取 Hive、Iceberg 等的数据。
在过去的两年中,我们主要致力于研究并解决上述挑战。目前,Databend 已经发布了 v1.2 版本,成功解决了上面遇到的主要挑战。当然,仍有许多优化的空间等待我们去探索。目前,Databend 已经被多家企业在生产环境中采用。
👨🏻💻 接下来,我们来看看 Databend 新一代架构在实际生产环境中的表现。以下数据均源自用户在真实场景下的反馈:
-
在替换 Trino/Presto 场景中,节省了75%的成本。
-
在替换 Elasticsearch 的场景中,节省了90%的成本。
-
在数据归档的低频查询场景中,节省了95%的成本。
-
在日志存储及分析场景中,节省了75%的成本。
-
每天有超过1PB+ 的数据通过 Databend 进行存储和分析,每个月为用户 节省了数百万美元 的成本。
这些数据说明,Databend 能够显著降低用户成本,充分体现了新一代云原生数据仓库架构所带来的巨大价值。

数据仓库与AI
我们目前正处在大数据与 AI 的黄金时期。在前面的部分,我们已经讨论了大数据分析的相关内容,接下来,我们聊聊 AI。
当我们提及 AI,以下几个主题往往会首先浮现在脑海中::
-
LLM (Large Language Model)语言大模型
-
神经网络
-
内容生成
-
智能问答
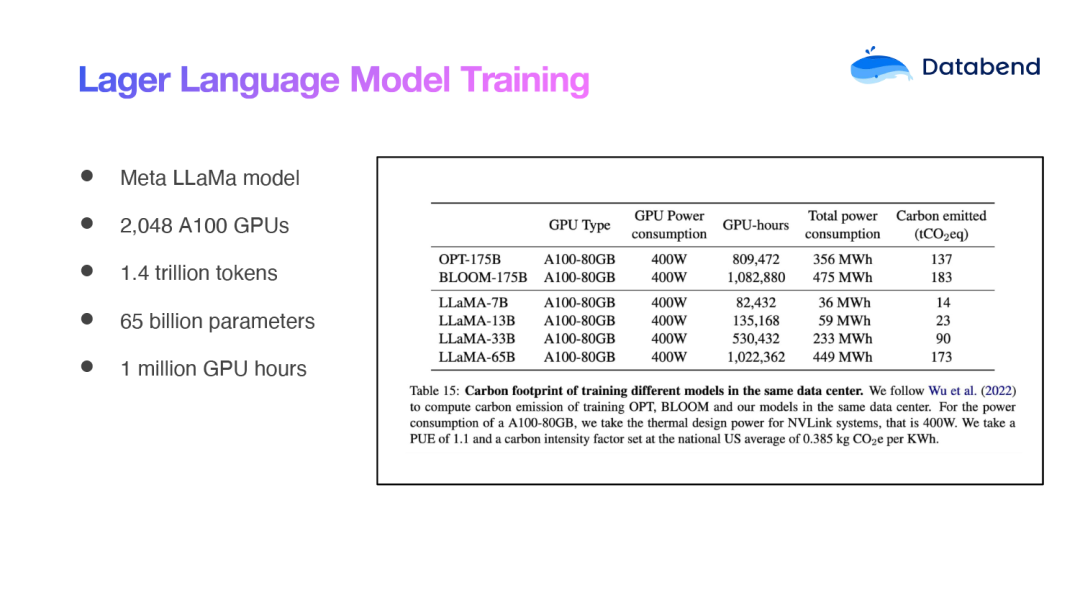
然而,从零开始训练一个大型模型,例如 Meta 的 LLaMa 模型,面临的挑战是巨大的,尤其是在成本方面。公开数据显示,他们训练一次该模型可能需要花费数百万美元。
根据我们对市场上各种商业和开源模型的测试,OpenAI 的 GPT 模型在商业化条件下表现优秀(截止到 2023 年 5 月)。特别是在智能客服系统中,我们非常看重模型根据内容片段和提示词(Prompt)进行推理的能力。
这里有一个来自 lmsys.org(LMSYS Org) 的模型能力排名供大家参考:

目前,我比较关注的 AI 应用方向主要是:
-
智能问答(Question and Answering)
-
全自动式大数据分析(AutoInsights)
能问答系统(Question and Answering)
首先,让我们了解一下智能问答系统的工作原理,然后再探讨我们如何在数仓中实现这一功能。
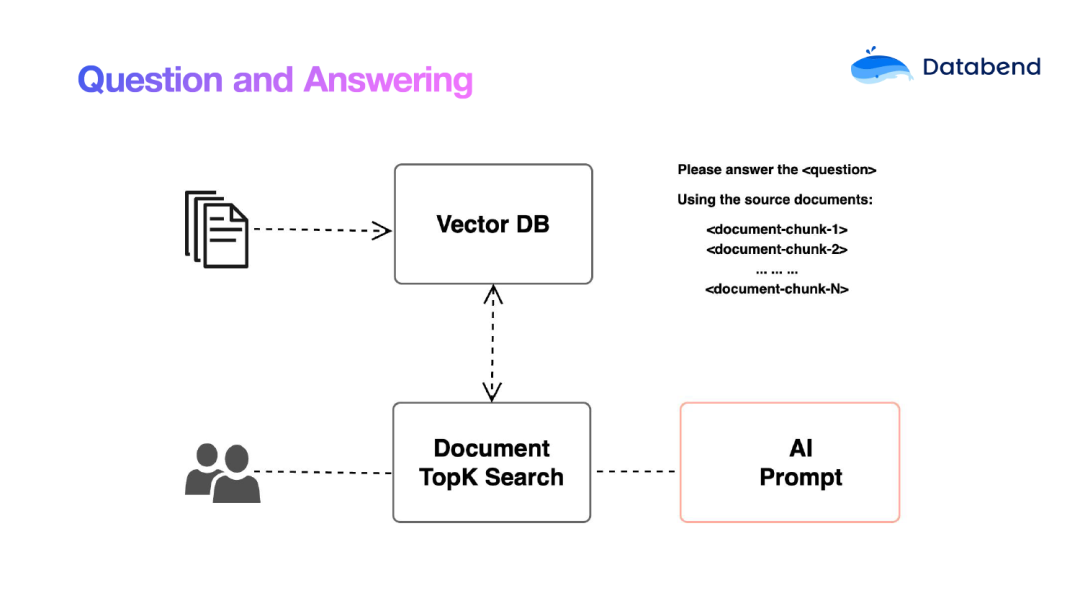
由于大模型每次处理的输入有限制,我们需要将大量的文本拆分为小片段,并将其向量化存储在向量数据库(Vector Database)中。这种设计使得智能问答系统的工作原理可以简化为以下四个步骤:
-
将输入的问题进行向量化处理,得到问题向量 QV。
-
利用向量数据库进行相似度检索,从而找出与 QV 最相似的文档片段集合(Documents)。
-
根据已给出的提示词(Prompt),将找到的文档片段进行 AI 生成式处理。
-
返回处理后的答案。
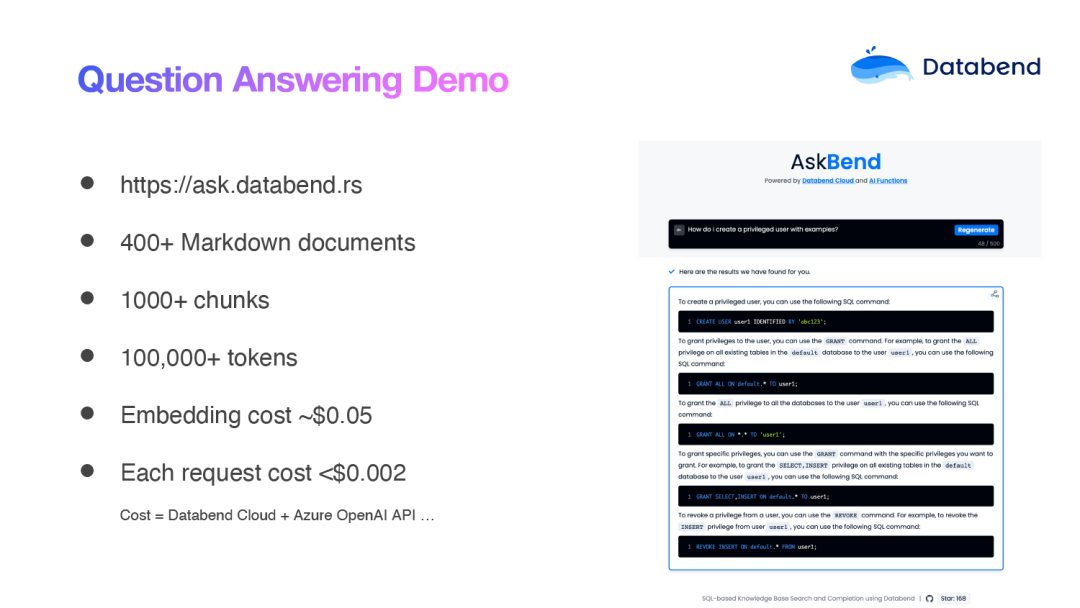
想要了解智能问答系统的朋友,我推荐你们访问这个链接:https://ask.databend.rs 这是一个以Databend 文档为基础的智能问答系统,它完全基于 Databend 构建。
在 Databend 中,我们实现了诸如文本向量化(Embedding)、向量数据库(Vector Database)、相似度检索等功能,还引入了 AI 生成式处理(润色)等技术。
通过 Databend 提供的一系列 SQL 函数(AI Functions),用户可以非常方便地利用这些函数来创建自己的智能问答系统。这不仅大大简化了智能问答系统的构建过程,同时也为大数据的利用提供了更多可能性。Databend 使你能够在同一套系统中进行 OLAP 和向量数据的处理,同时可以对接各种大模型,进一步拓展大数据的边界。
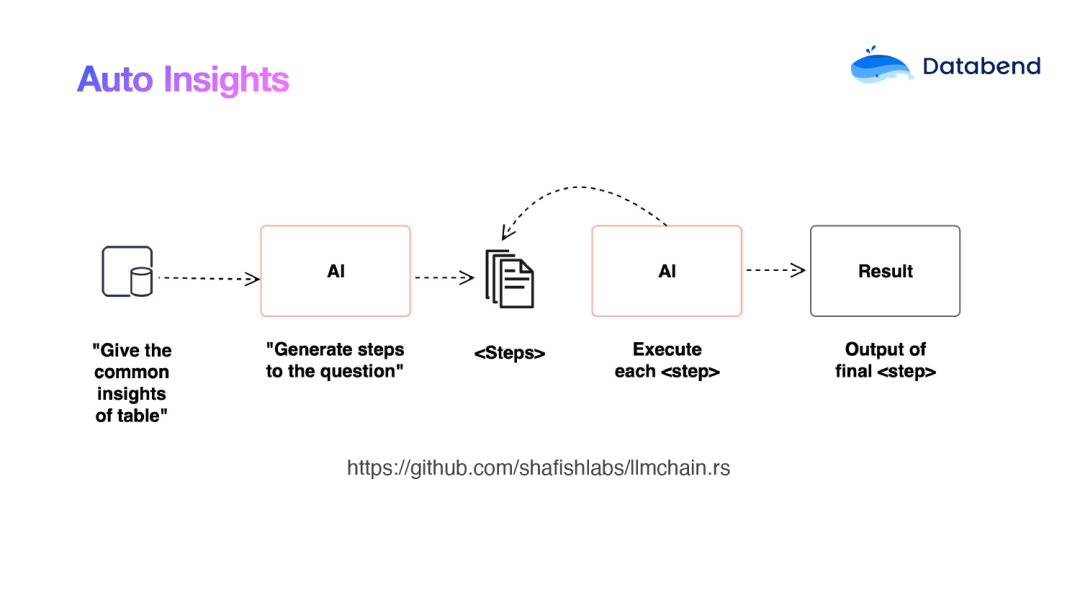
全自动式分析 (AutoInsights)

SQL 分析通常较为复杂,对用户而言,快速编写 SQL 是一项巨大的挑战。我们是否可以简化这个步骤,让 AI 直接基于表结构和数据摘要自动生成 SQL 呢?答案是肯定的。目前,Databend Cloud 已上线该功能。
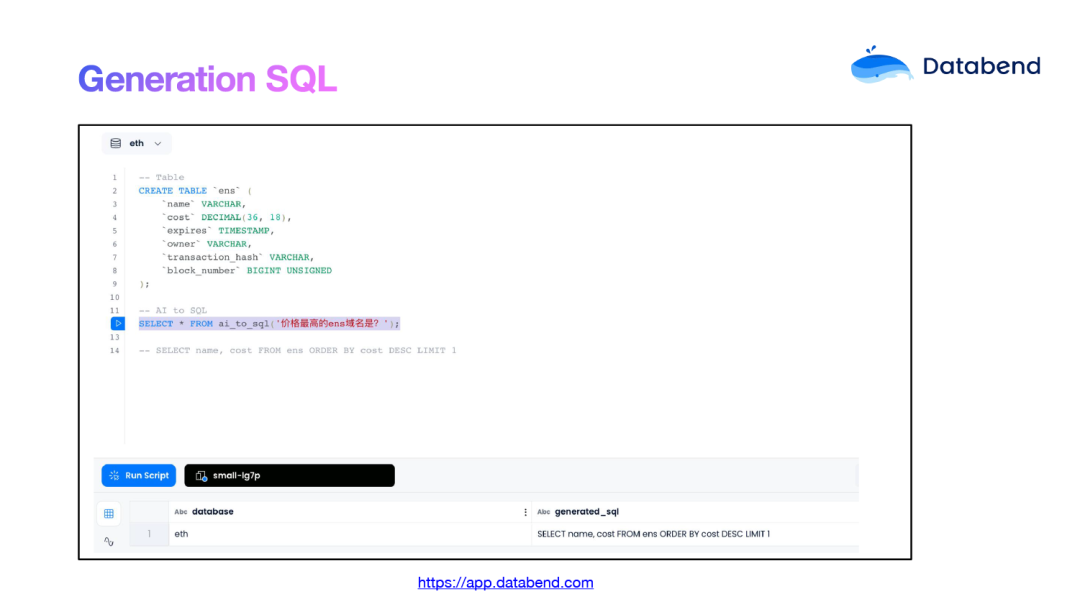
在 Databend 中,大部分列都已经建立了索引,再结合优化器的良好设计,生成的 SQL 可以在无需人工干预的情况下快速执行。
这样,我们的自动化分析可以拆解为以下步骤:
-
获取表结构
-
让 AI 根据表结构提几个最关注的问题
-
把这几个问题转换为 SQL
-
Databend 执行 SQL 并生成结果
-
根据结果自动化生成分析报告
整个流程基本为:
总结
我们正在经历一个 Data + AI 的黄金时期,AI 已在大数据领域展现出巨大的潜力,比如 OpenAI 最近推出的 ChatGPT Code Interpreter,这都标志着 AI 可以帮助我们以更创新的方式挖掘数据的价值。
Databend 在设计之初就充分考虑到这种智能化的需求,因此我们研发了 AI Functions。这使得 Databend 不仅是一个数据仓库,更是一个 Large Language Model(LLM)的入口,可以通过 SQL 来表达 AI 的能力,未来 AI 将是每个数据仓库的标配。
我们坚信,Databend 将继续引领数仓的创新,为用户带来更多的价值。Databend 不仅可以帮助你降低成本,提高效率,还可以借助 AI 的能力挖掘更大的数据价值,使大数据分析的门槛进一步降低。