文章目录
- 数值稳定性、模型初始化、激活函数
- 1.数值稳定性
- 1.1举例
- 1.2数值稳定性的常见两个问题
- 1.3梯度爆炸
- 1.4梯度消失
- 1.5打破对称性
- 2.模型初始化
- 2.1让训练更加稳定
- 2.2权重初始化
- 2.3Xavier初始
- 3.激活函数
数值稳定性、模型初始化、激活函数
学习视频:数值稳定性 + 模型初始化和激活函数【动手学深度学习v2】
官方笔记:数值稳定性和模型初始化
到目前为止,我们实现的每个模型都是根据某个预先指定的分布来初始化模型的参数。 有人会认为初始化方案是理所当然的,忽略了如何做出这些选择的细节。甚至有人可能会觉得,初始化方案的选择并不是特别重要。 相反,初始化方案的选择在神经网络学习中起着举足轻重的作用, 它对保持数值稳定性至关重要。 此外,这些初始化方案的选择可以与非线性激活函数的选择有趣的结合在一起。 我们选择哪个函数以及如何初始化参数可以决定优化算法收敛的速度有多快。 糟糕选择可能会导致我们在训练时遇到梯度爆炸或梯度消失。 本节将更详细地探讨这些主题,并讨论一些有用的启发式方法。 这些启发式方法在整个深度学习生涯中都很有用。
1.数值稳定性
1.1举例
神经网络的梯度

1.2数值稳定性的常见两个问题
- 梯度爆炸
- 梯度消失
举例


1.3梯度爆炸

如果d - t很大,代表层数很多,不断累积的乘法会使得大于1的梯度累乘出现一个非常大的梯度
梯度爆炸出现的问题:
-
值超出值域
- 对于16位浮点数尤为严重(数值区间6e5-6e4)
-
对学习率敏感
- 如果学习率太大—>大参数值—>更大的梯度
- 如果学习率太小—>训练无进展
- 我们可能需要在训练过程不断调整学习率
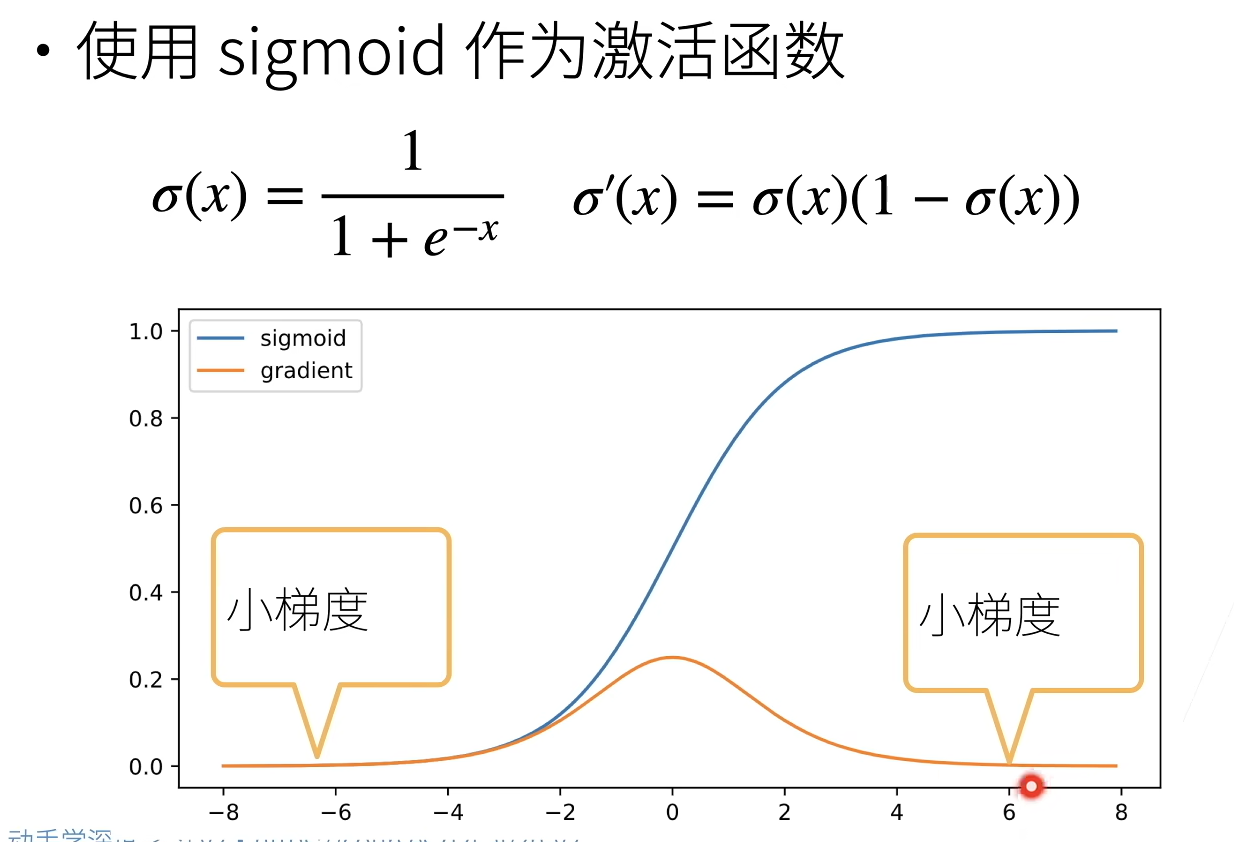
1.4梯度消失
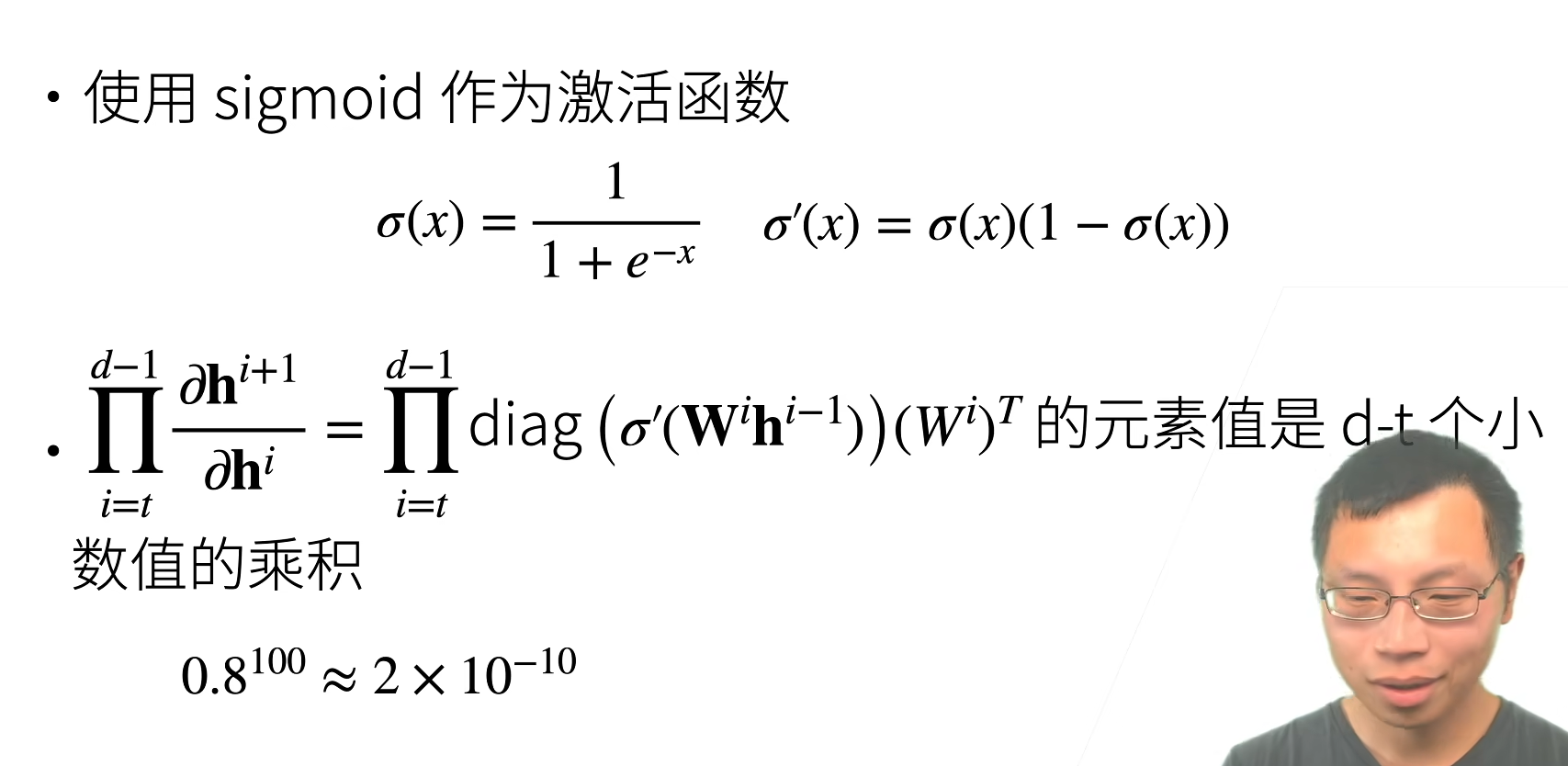
%matplotlib inline
import torch
from d2l import torch as d2l
x = torch.arange(-8.0,8.0,0.1,requires_grad = True)
y = torch.sigmoid(x)
y.backward(torch.ones_like(x))
d2l.plot(x.detach().numpy(), [y.detach().numpy(), x.grad.numpy()],
legend=['sigmoid', 'gradient'], figsize=(4.5, 2.5))
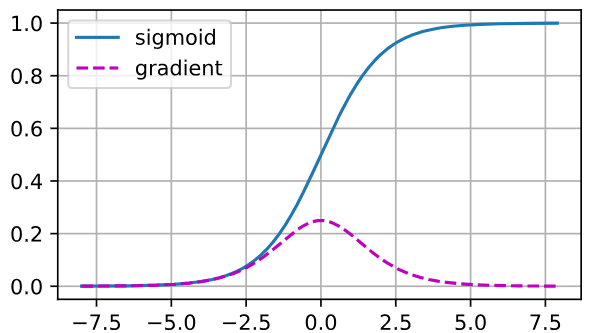
正如上图,当sigmoid函数的输入很大或是很小时,它的梯度都会消失。 此外,当反向传播通过许多层时,除非我们在刚刚好的地方, 这些地方sigmoid函数的输入接近于零,否则整个乘积的梯度可能会消失。 当我们的网络有很多层时,除非我们很小心,否则在某一层可能会切断梯度。 事实上,这个问题曾经困扰着深度网络的训练。 因此,更稳定的ReLU系列函数已经成为从业者的默认选择(虽然在神经科学的角度看起来不太合理)。
梯度消失的问题:
-
梯度值变为0
- 对16位浮点数尤为严重
-
训练没有进展
- 不管如何选择学习率
-
对于底层尤为严重
- 仅仅顶部层训练的较好
- 无法让神经网络更深
总结:
- 当数值过大或过小会导致数值问题
- 常发生在深度模型中,因为其会对n个数累乘
1.5打破对称性

2.模型初始化
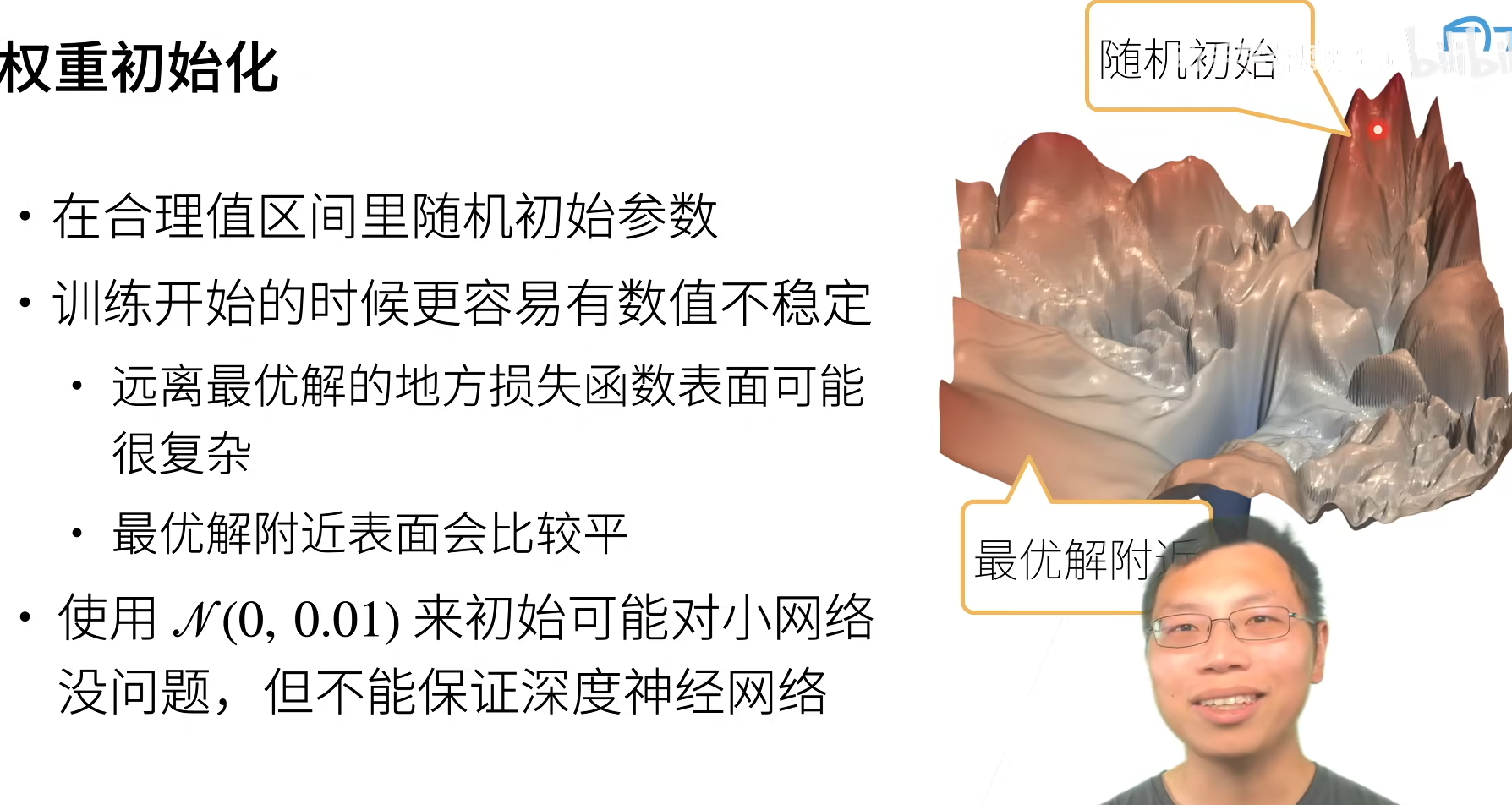
2.1让训练更加稳定

让每层的方差是一个常数

2.2权重初始化
举例
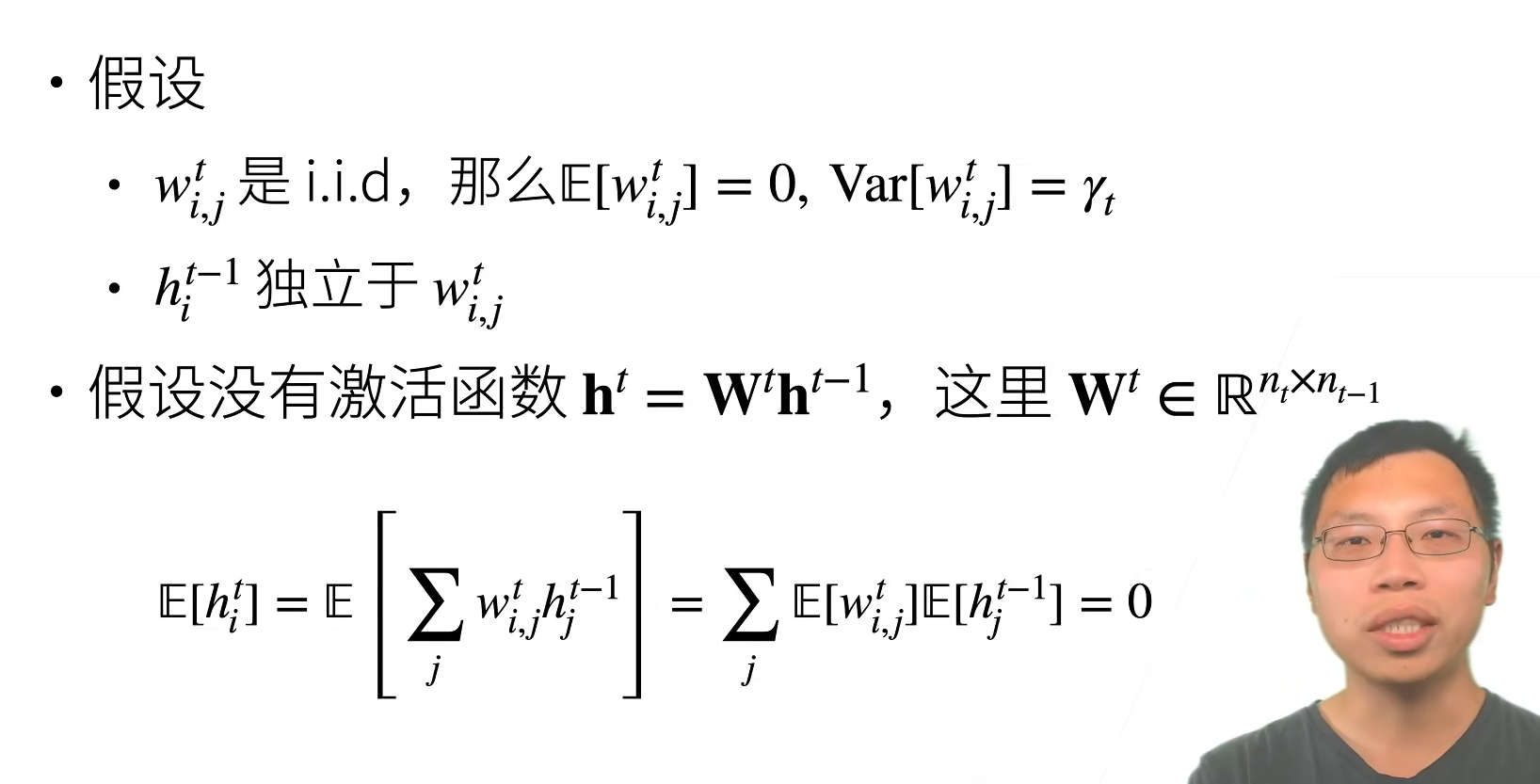
正向方差
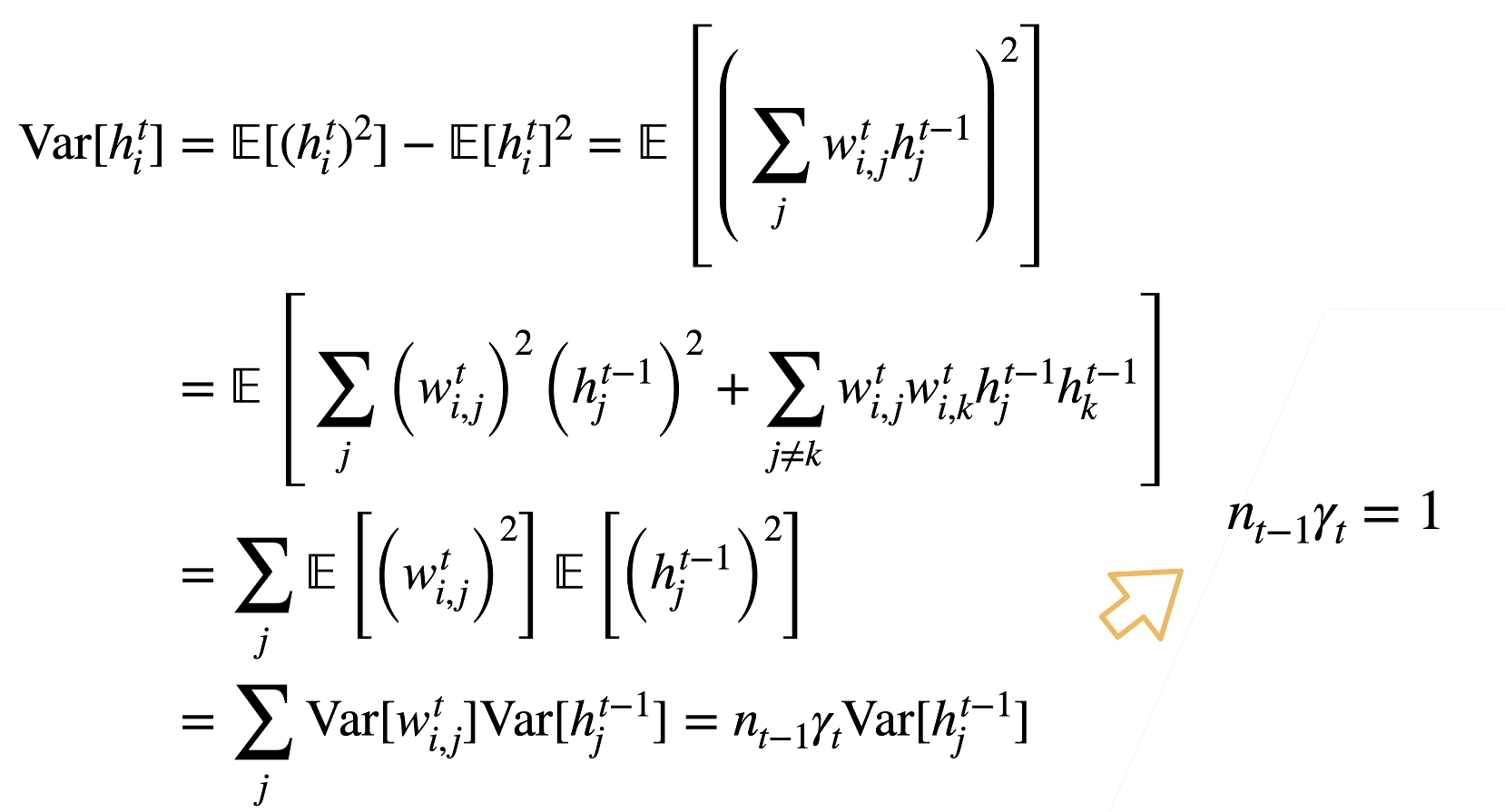
反向均值和方差

2.3Xavier初始



3.激活函数
假设线性的激活函数
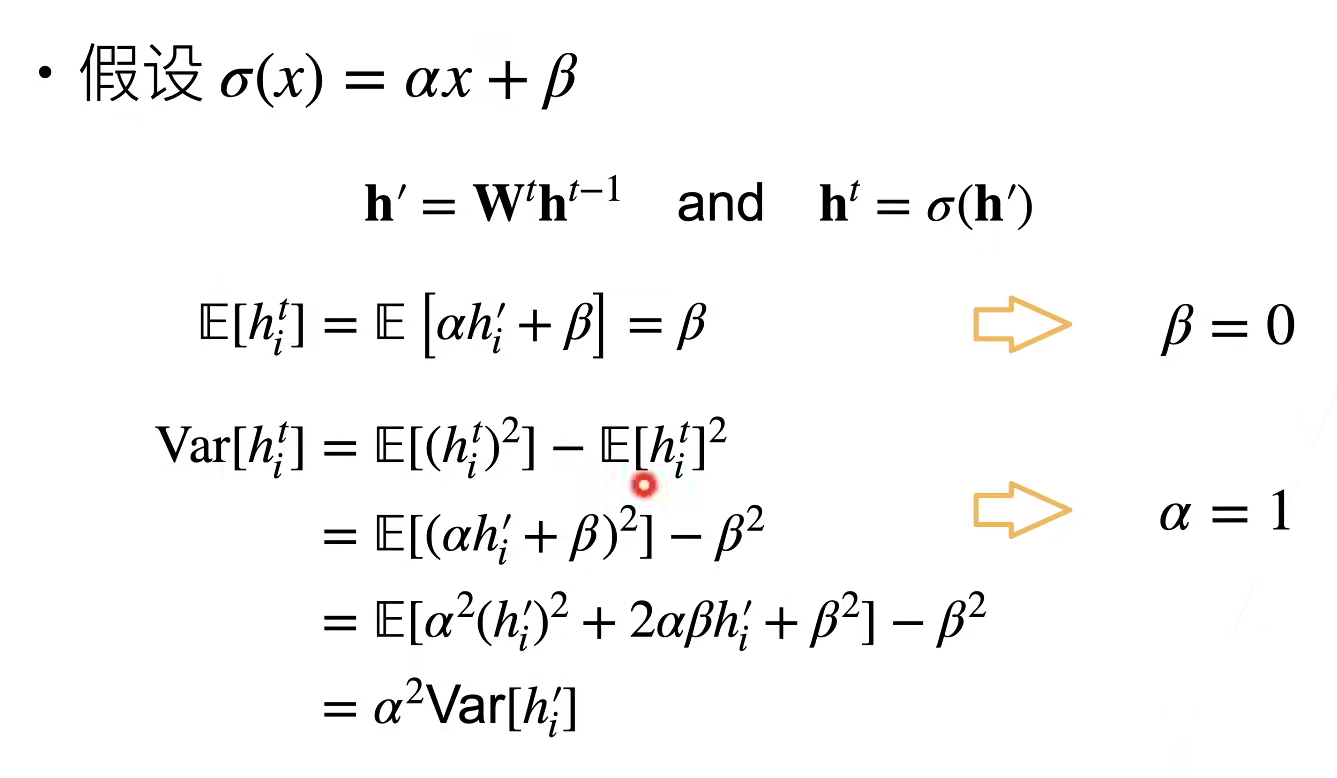
反向
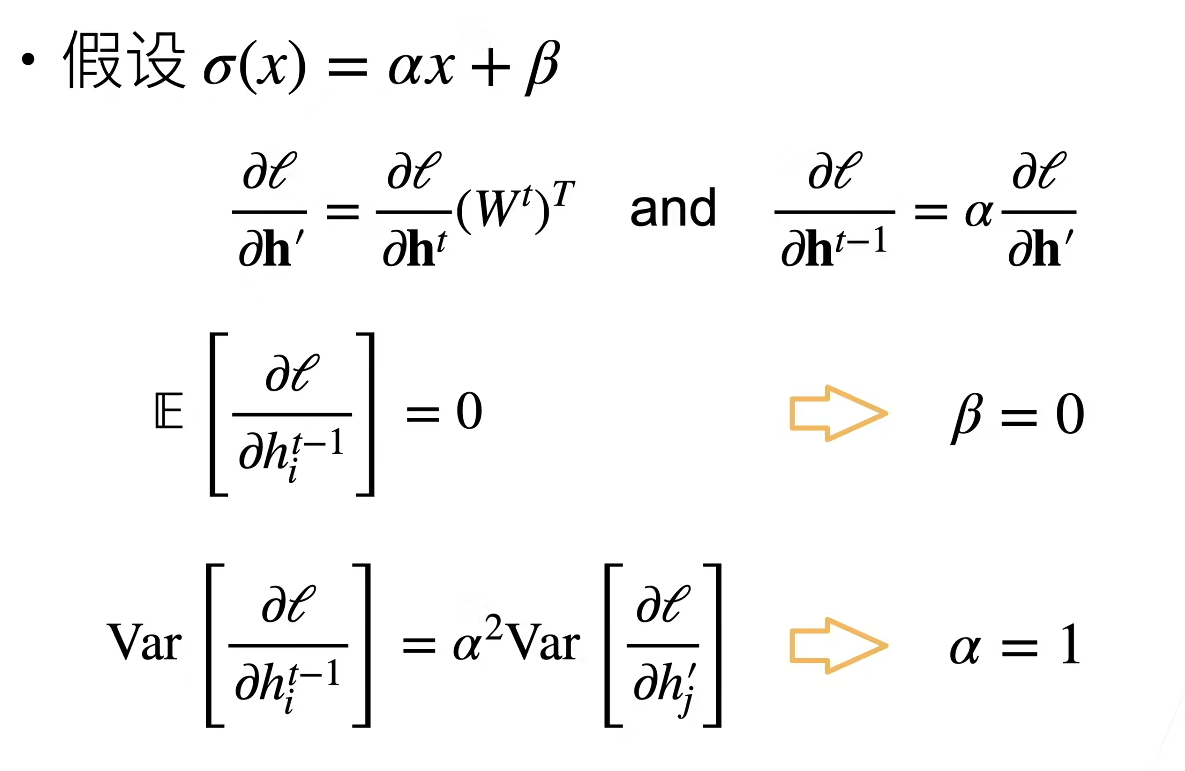
常用的激活函数
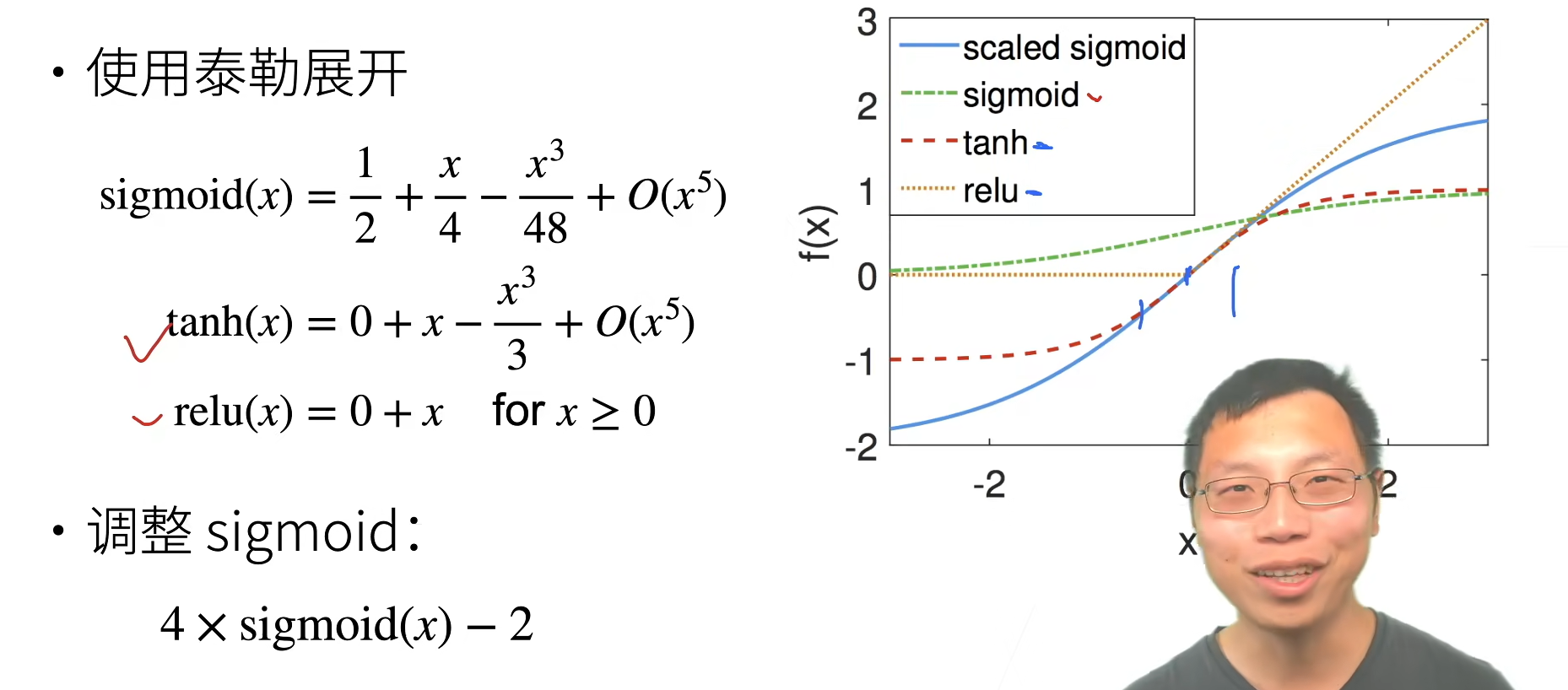
总结:合理的权重初始值和激活函数的选取可以提升数值稳定性