大概发生了八步的事情:
URL解析->DNS解析->服务器建立连接->发送HTTP请求->服务器处理请求->服务器响应->接收和渲染页面->关闭连接
URL解析
URL,统一资源定位符,是用来表示从互联网上得到的资源位置和访问这些资源的方法,俗称网址!互联网上的所有资源,都有一个唯一确定的URL。
URL的一般形式由一下四个部分组成:
<协议>://<主机>:<端口>/<路径>
URL的第一部分是最左边的<协议>。这里的<协议>就是指出使用什么协议来获取万维网文档。现在最常用的协议就是http(超文本传输协议HTTP),其次就是ftp(文件传输协议FTP)。
在协议后面的:// 是规定的格式。它的右边是第二部分<主机>,它指出这个万维网文档是在哪一台主机上。这里的<主机>就是指该主机在互联网上的域名 。在后面是第三部分和第四部分<端口>和<路径>,有时可以省略。
如果是采用http协议访问万维网文档,如果省略端口,走会访问默认端口80,如果省略路径,则URL就指到互联网上的某个主页(home page)。
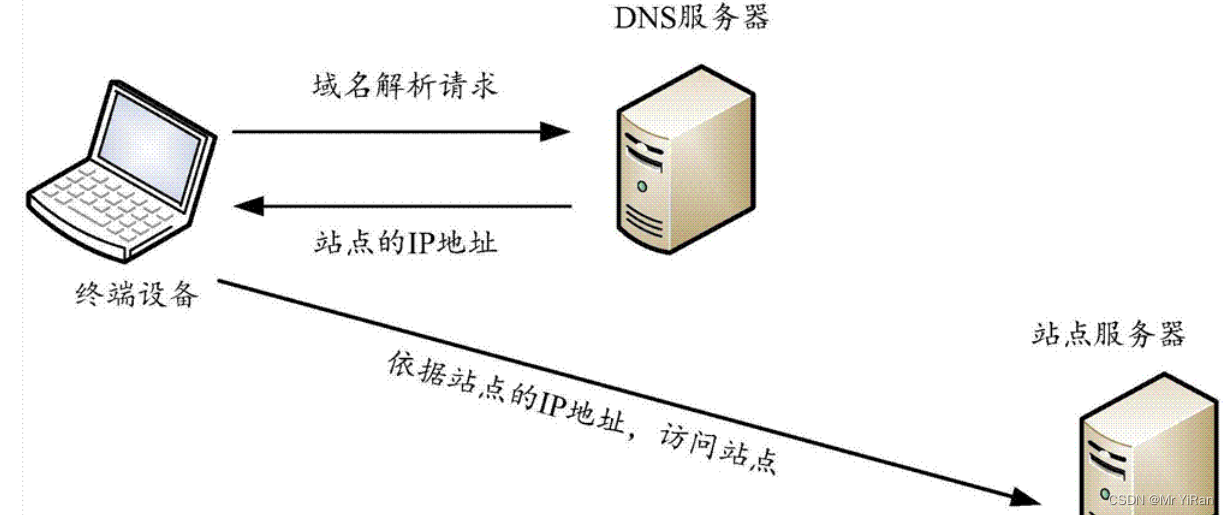
而URL解析,就是当用户输入URL并回车后,浏览器对拿到的URL进行识别,抽取出域名字段,比如https://www.baidu.com,它的域名就是www.baidu.com,拿到域名后,就会顺利进行第二步了,就是DNS域名解析!
DNS域名解析
域名系统DNS(Domain Name System)是互联网使用的命名系统,用来把便于人们使用的机器名转换为IP地址。
用户与互联网上的某台主机通信时,必须要知道对方的IP地址。然而用户很难记住长达32位的二进制主机地址。及时是点分十进制IP地址也并不容易记忆。但是在应用层为了方便用户记忆各种网络应用,连接在互联网上的主机不仅有IP地址,而且还有便于用户记忆的主机名字(域名)。域名系统DNS能够把互联网上的主机名字转换为IP地址。
既然互联网上的每一台主机都有主机名字,那么为什么机器在处理IP数据报的时候要使用IP地址而不是用域名呢?
简单来说,这是因为IP地址的长度是固定的32位(如果是IPv6地址,那就是固定的128位,也是定长的),而域名的长度并不是固定的,机器处理起来比较困难。
注意,可以在浏览器中输入域名得出网页内容,也可以输入对应的IP地址得到网页内容。虽然得出的内容是一样的,但调用的过程不一样,输入IP地址是直接从主机上调用内容,输入域名是通过对应的域名解析服务器指向对应的主机IP地址,在从主机中调用网址的内容。
建立TCP连接(三次握手)
第一次握手:客户端向服务器发送请求(SYN=1)等待服务器响应;
第二次握手:服务器收到请求并确认,回复一个指令(SYN=1,ACK=1)
第三次握手:客户端收到服务器回复的指令并返回确认(ACK=1)。
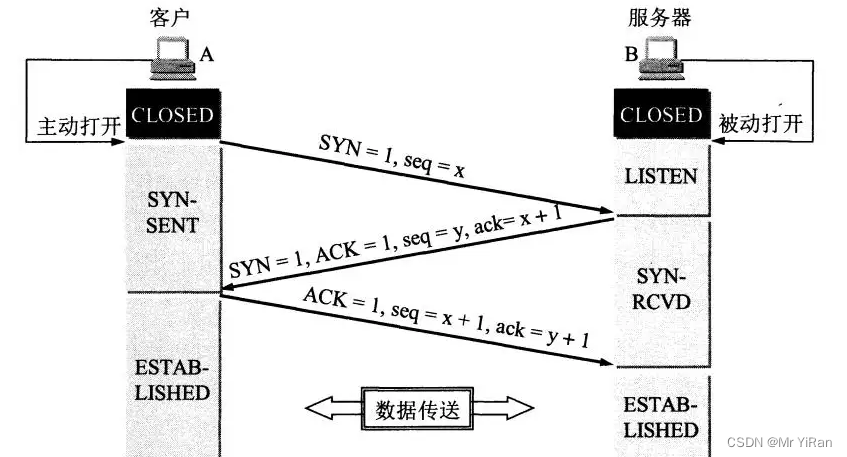
为什么A最后还要发送一次确认呢?请读者稍加思考一下!
这主要是为了防止已失效的连接请求报文段突然又传送到了B,因而产生错误!
所谓的已失效的请求报文段是这样产生的。考虑一种正常情况,A发出连接请求,但因连接请求报文丢失而未收到确认。于是A在重传一次连接请求。后来收到了来自服务器的连接请求确认,建立了连接。数据传输完毕后,就通过四次挥手释放了连接。在该过程中,A共发出了两个连接请求报文段,其中第一个丢失,第二个达到了B,没有已失效的连接请求报文段。
现假定出现一种异常情况,即A发出的第一个连接请求报文段并没有丢失,而是在某些网络结点长时间滞留了,以致延误到连接释放以后的某个时间才达到B。本来这是一个早已失效的报文段,但B收到此失效的连接请求报文段后,就误认为是A又发出了一次新的连接请求。于是就想A发出确认连接报文段,同意建立连接。假定不采用三次握手,那么只要B发出确认,新的连接就建立了。
由于现在A并没有发出建立连接的请求,因此不会理睬B的确认,也不会向B发送数据。但B却认为新的运输连接已经建立了,并一直等待A发送数据。于是B的资源就这样白白浪费了。
发送HTTP请求
HTTP协议定义了浏览器怎样向万维网服务器请求万维网文档,以及服务器怎样把文档传送给浏览器。从层次的角度看,HTTP是面向事务的应用层协议。
HTTP有两类报文:
(1)请求报文——从客户端向服务器发送请求报文。如下图所示。
(2)响应报文——从服务器到客户端的回答。
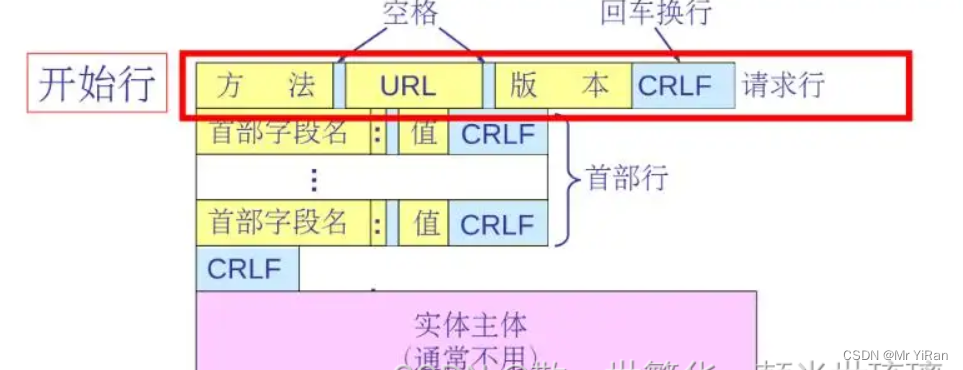
HTTP请求报文有三部分组成,即请求行,首部行和实体主体三部分组成。
请求报文的第一行,请求行只有三个内容,即方法,请求资源的URL以及HTTP的版本。
这里的方法就是对所请求的对象进行操作这些方法实际上也就是一些命令。下图给出了请求报文常见的几种方法。
| 方法(操作) | 方法(操作) |
|---|---|
| OPTION | 请求一些选项的信息 |
| GET | 请求读取由URL所标志的信息 |
| HEAD | 请求读取由URL所标志的信息的首部 |
| POST | 给服务器添加信息 |
| PUT | 在指明的URL下存储一个文档 |
| DELETE | 删除指明的URL所标志的资源 |
| TRACE | 用来进行环回测试的请求报文 |
| CONNECT | 用于代理服务器 |
下面是一个HTTP的请求报文的开始行的格式,由方法,域名以及HTTP的版本构成。注意(方法与域名之间含空格,域名与HTTP版本之间也含空格)。
GET http://www.xyz.edu.cn/dir/index.html HTTP/1.1
服务器处理相关的请求
接受HTTP报文后,会对连接进行处理,对HTTP协议进行解析(请求方法、域名、路径等),并且进行一些验证:
验证是否配置虚拟主机
验证虚拟主机是否接受此方法
验证该用户可以使用该方法(根据 IP 地址、身份信息等)
重定向
假如服务器配置了 HTTP 重定向,就会返回一个 301永久重定向响应,浏览器就会根据响应,重新发送 HTTP 请求(重新执行上面的过程)。
URL 重写
然后会查看 URL 重写规则,如果请求的文件是真实存在的,比如图片、html、css、js文件等,则会直接把这个文件返回。
否则服务器会按照规则把请求重写到 一个 REST 风格的 URL 上。
然后根据动态语言的脚本,来决定调用什么类型的动态文件解释器来处理这个请求。
具体流程如下所示:
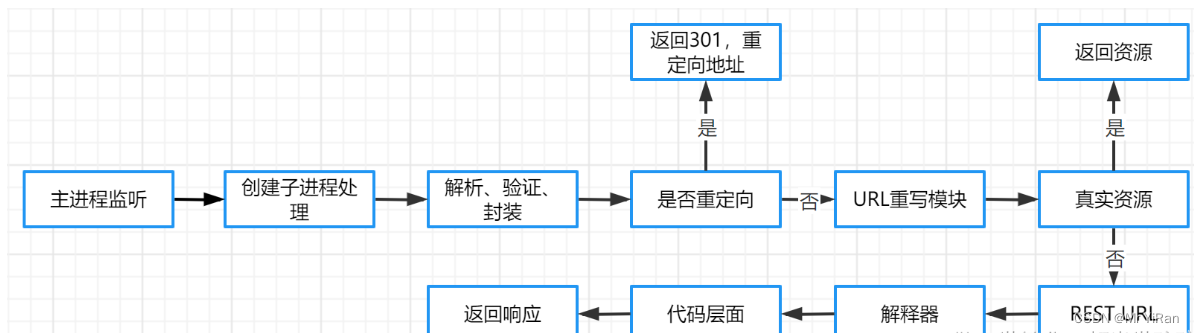
返回响应的结果
服务器每收到一个请求报文后,对应的都会回复一个响应报文。
HTTP的响应报文由状态行,首部行以及实体主体组成,一般用开始行是请求行还是状态行来区分是请求报文还是响应报文! 具体的响应报文格式如下:
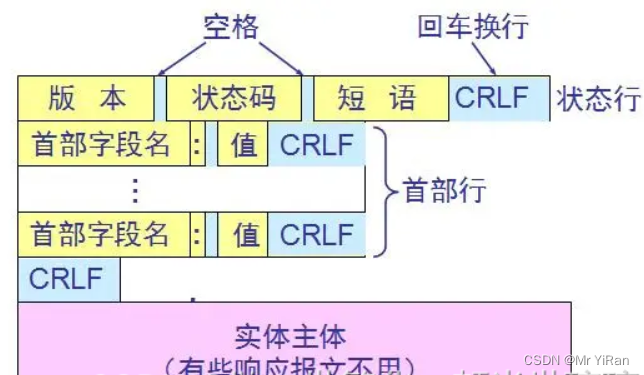
响应报文的第一行就是状态行,状态行包括版本,状态码以及短语组成。
状态码都是三位数字构成的,分为5大类,原先有33种,后来又增加了几种。这5大类的状态码都是以不同的数字开头的。
| 状态码 | 意义 |
|---|---|
| 1xx | 表示通知信息,如请求收到了或正在进行处理 |
| 2xx | 表示成功,如接受或知道了 |
| 3xx | 表示重定向,如要完成请求还必须采取进一步的行动 |
| 4xx | 表示客户的差错,如请求中有错误的语法或不能完成 |
| 5xx | 表示服务器的错误,如服务器失效无法完成请求 |
下面是响应报文中经常见到的
HTTP/1.1 202 Accepted {接受}
HTTP/1.1 400 Bad Request {错误的请求}
HTTP/1.1 404 Not Found {找不到}
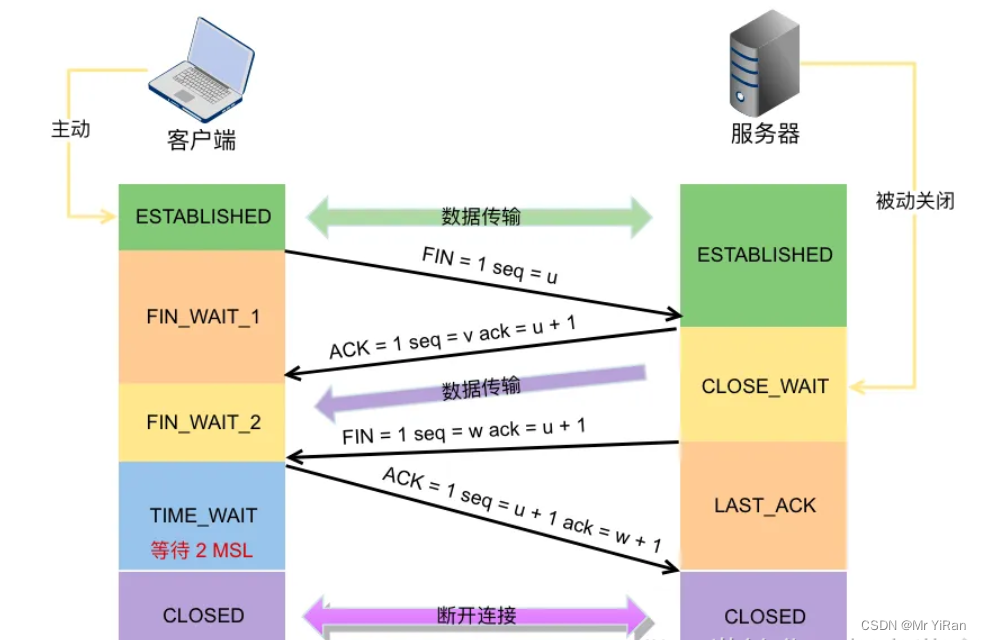
关闭TCP连接(四次挥手)
第一次挥手:客户端向服务器发送连接释放报文段(FIN=1),等待服务器响应;
第二次挥手:服务器收到连接释放报文文段并发出确认(ACK=1),客户端到服务器的连接关闭,此时TCP处于半关闭状态,需要等到服务器向客户端发送数据结束;
第三次挥手:服务器向客户端发送连接释放报文段(FIN=1,ACK=1),并等待客户端的确认;
第四次挥手:客户端收到服务器的连接释放报文段并给出确认(ACK=1),连接释放。
HTML解析与页面渲染
HTML解析与页面渲染的过程如下所示
HTMl解析与页面渲染的过程如下所示:
1.浏览器获取到 html 资源后开始解析 html (dom tree)
2.解析到 css 后根据 css 生成 css 规则树 (style rules)
3.在 dom 树和 css 规则树都生成完后,通过 dom 树和 css 规则树生成渲染树( render tree )
4.渲染树构建完成后,浏览器开始计算元素的大小和位置( layout )
5.根据计算好的节点信息将内容绘制到屏幕上( painting )
因此当你输入URL并按下回车后,具体过程如下:
- URL解析:浏览器会解析输入的URL,将其分解为不同的组成部分。例如协议(通常是HTTP或HTTPS),域名(例如www.example.com),以及可选的端口号,路径和查询参数等。
- DNS解析:浏览器需要将域名解析为IP地址,以便能够与服务器进行通信。它会首先检查浏览器缓存中是否有与该域名对应的IP地址。如果没有,则向DNS服务器发送查询请求,以获取该域名对应的IP地址。一旦找到IP地址,浏览器就可以建立与服务器的连接。
- 建立连接:浏览器使用HTTP或HTTPS协议与服务器建立TCP连接,以便在服务器和浏览器之间传输数据。这个过程会进入一些握手和验证的步骤,以确保连接的安全性和稳定性。
- 发送HTTP请求:一旦连接建立好,浏览器会发送一个HTTP请求到指定的服务器。这个请求中包含了请求的方法(GET,POST等),路径,请求头部和可选的请求体等信息。
- 服务器处理请求:服务器收到浏览器发送的请求后,会根据请求中的信息来处理请求。服务器可能会执行一些操作,例如查找请求的资源,执行服务器端的逻辑,查询数据库等。
- 服务器响应:一旦服务器处理完请求,就会生成一个HTTP响应并返回给浏览器。这个响应中包含了响应的状态码,响应头部和响应体等信息。常见的状态码有200表示成功,404表示资源未找到,500表示服务器内部错误等。
- 接收和渲染页面:浏览器接收到服务器返回的响应后,会根据响应的内容进行解析和渲染。如果响应是一个HTML页面,浏览器会解析HTML,CSS和JavaScript,并将其渲染成可视化的页面。同时,浏览器还会发送其他的请求来获取页面中引用的其他资源,例如图片,样式表,JavaScript文件等。
- 关闭连接:一旦浏览器完成对页面的渲染,它会关闭与服务器的连接,释放网络资源。





![Yocto系列讲解[技巧篇]92 - armv8 aarch64兼容armv7 32位程序运行环境](https://img-blog.csdnimg.cn/f64e1f114d7045eaa57a680daec4395b.png)



