- 一般假设训练集和测试集是独立同分布的,才能保证在训练集上表现良好的模型同样适用于测试集。当训练集和测试集不同分布时,就发生了dataset shift
- data shift类型:
- 协变量偏移(covariate shift):
- 协变量,隐变量可以理解为数据中的x及对应标签y
- 协变量的变化,比如模型应用场景中环境、位置的变化等(协变量,假设我们要拟合方程 y=wx,对于一个数据对(x,y):y为因变量,w为自变量,x为协变量。)
- 先验概率偏移:因变量的变化,比如根据月份预测销售额的模型,用平时月份训练的模型预测销售高峰月份的销售额。输入仍然为月份没有变化,但训练集和实际场景中的因变量完全不一样(一般月份和销售高峰月份的销售额本就不一样)。
- 概念偏移:自变量和因变量之间的关系发生了改变。
- 最常遇到的应该是Covariate Shift
- 协变量偏移(covariate shift):
- 当训练集和测试集差异较大时,训练往往是徒劳的。
- 如果数据发生了Covariate Shift的数据,那么理论上可以通过一个分类器以一个较高的准确率将原始数据和测试数据区分开(毕竟分布不同)。
- 检验步骤:
- 在训练集和测试集中随机采样(注意训练集和测试集的采样数量需要一致),然后将采样数据混合到一起形成新的训练数据,对数据增加一个新维度标签,取值取决于数据来源(比如训练集标识1,测试集标识0)。
- 得到了一个新的训练集. 将这个训练集的一部分数据(如80%)用来训练模型(KNN, SVM等), 剩下的数据(如20%)用来测试模型的性能。
- 计算模型在测试集上的AUC-ROC,如果指标较大(比如大于0.8),便可判定发生了Covariate Shift。(计算AUC-ROC,本质上就是为了衡量二元分类质量。还可以采用MCC(Matthews correlation coefficient)来衡量。一般MCC阈值可以设置为0.2。MCC>0.2说明出现了covariate shift的现象,反之亦然):
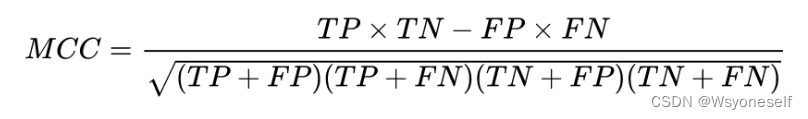 TP(True Positive):真实为1,预测为1 FN(False Negative):真实为1,预测为0 FP(False Positive):真实为0,预测为1 TN(True Negative):真实为0,预测为0
TP(True Positive):真实为1,预测为1 FN(False Negative):真实为1,预测为0 FP(False Positive):真实为0,预测为1 TN(True Negative):真实为0,预测为0
- 解决covariate shift的方法:
- 去除产生covariate shift现象的特征(Dropping of drifting features):
- 去除产生偏移的且不重要的特征。
- 具体:
- 逐个特征分类分析,找到产生偏移的特征
- 然后通过对比找出产生偏移的且不重要的特征去除掉
- 使用密度比的重要性加权(Importance weight using Density Ratio Estimation)。特征重要性评估方法:
- Mean decrease impurity 原理其实就是Tree-Model进行分类、回归的原理:特征越重要,对节点的纯度增加的效果越好。而纯度的判别标准有很多,如GINI、信息熵、信息熵增益。(sklearn中的树模型提供了feature_importances_采用的就是这种方法计算得到的)
- Mean decrease accuracy:看某个特征对模型精度的影响。把一个变量的取值变为随机数,随机森林预测准确性的降低程度。该值越大表示该变量的重要性越大。
- 去除产生covariate shift现象的特征(Dropping of drifting features):
- AUC-ROC:
- 当涉及分类问题时,可以使用AUC-ROC曲线进行评价
- ROC是概率曲线,AUC表示可分离的程度或测度,它告诉我们多少模型能够区分类别。AUC越高,模型在将0预测为0,将1预测为1时越好。
- AUC和ROC曲线中使用的术语
- TPR (真阳性率) / 召回 /敏感度 =TP/(TP+FN)
- 特异性=TN/(TN+FP)
- FPR=1-特异性=FP/(TN+FP)
- 出色的模型的AUC接近1,这意味着它具有良好的可分离性度量,较差的模型的AUC接近于0,这意味着它的可分离性度量最差。实际上,这意味着它正在回报结果。它预测0s但其实它是1s,1s但其实它是0s,当AUC为0.5时,表示模型没有类别分离能力。
data shift--学习笔记
news2026/2/11 5:36:46
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/75773.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

简约而不简单!分布式锁入门级实现主动续期-自省
一、背景
一个分布式锁应具备的功能特点中有避免死锁这一条: 如果某个客户端获得锁之后处理时间超过最大约定时间,或者持锁期间内发生了故障导致无法主动释放锁,其持有的锁也能够被其他机制正确释放,并保证后续其它客户端也能加锁…

Unity 3D 刚体(Rigidbody)|| Unity 3D 刚体实践案例
Unity 3D 中的 Rigidbody 可以为游戏对象赋予物理特性,使游戏对象在物理系统的控制下接受推力与扭力,从而实现现实世界中的物理学现象。
我们通常把在外力作用下,物体的形状和大小(尺寸)保持不变,而且内部…

Vue3 —— Pinia 的学习指南以及案例分享
文章目录 前言一、什么是pinia?二、为什么要使用Pinia?三、Pinia对比Vuex四、具体使用方法 1.安装2.创建一个store五、state 1.访问state2.重置状态3.修改state4.批量修改state5.替换state六、getters 1.访问getters2.getters传参3.写为普通函数可调用this4.访问其他的store中…

可见光热红外图像融合算法设计
本设计方式中对于多源图像融合算法采用以下三个步骤进行:
多源图像目标特征提取;多源图像配准;多源图像融合。
1.多源图像目标特征提取 多源图像的目标特征提取中,优先对目标图像进行预处理,对于可见光图像…

品牌势能铸就非凡经典,凯里亚德与郁锦香酒店亮相品牌沙龙会烟台站
近日,汇聚国内众多投资人的锦江酒店(中国区)品牌沙龙会烟台站顺利举行。本次沙龙活动以“齐风鲁韵 锦绘未来”为主题,锦江酒店(中国区)旗下众多优秀品牌共同亮相。凯里亚德酒店与郁锦香酒店在本次活动中向投资人展示了在如今复杂多变的酒店市场中如何以强…

Java面向对象:继承
面向对象三大特征之二:继承
目录
面向对象三大特征之二:继承
1.继承是什么:
2.继承的好处 继承概述的总结
1.什么是继承?继承有什么好处?
2.继承的格式是什么样的?
3.继承后子类的特点是什么&#x…
Docker介绍及项目部署
安装Docker
关闭SELINUX服务
SELINUX是CentOS系统捆绑的安全服务程序,因为安全策略过于严格,所以建议搭建关闭这项服务
修改/etc/selinux/config文件,设置SELINUXdisabled
vim /etc/selinux/config
# 设置SELINUXdisabled# 设置完成后重启…
![[附源码]计算机毕业设计姜太公渔具销售系统Springboot程序](https://img-blog.csdnimg.cn/35541b594a5342e68916a5d93e39ba84.png)
[附源码]计算机毕业设计姜太公渔具销售系统Springboot程序
项目运行
环境配置:
Jdk1.8 Tomcat7.0 Mysql HBuilderX(Webstorm也行) Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。 项目技术:
SSM mybatis Maven Vue 等等组成,B/S模式 M…

Crane如何做到利用率提升3倍稳定性还不受损?
作为云平台用户,我们都希望购买的服务器物尽其用,能够达到最大利用率。然而要达到理论上的节点负载目标是很的,计算节点总是存在一些装箱碎片和低负载导致的闲置资源。下图展示了某个生产系统的CPU资源现状,从图中可以看出&#x…

编译器设计(十二)——指令选择
文章目录一、简介二、代码生成三、扩展简单的树遍历方案四、通过树模式匹配进行指令选择4.1 重写规则4.2 找到平铺方案五、通过窥孔优化进行指令选择5.1 窥孔优化5.2 窥孔变换程序六、高级主题6.1 学习窥孔模式6.2 生成指令序列七、小结和展望一、简介
指令选择(in…
java面试题-并发
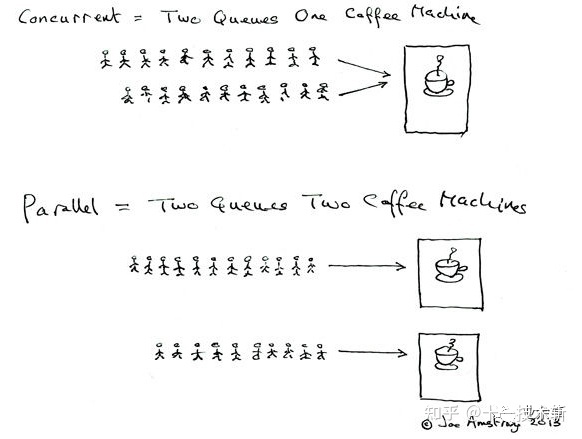
1. 并行和并发有什么区别?
并行:多个处理器或多核处理器同时处理多个任务。并发:多个任务在同一个 CPU 核上,按细分的时间片轮流(交替)执行,从逻辑上来看那些任务是同时执行。
如下图: 并发 两个队列和一…

从功能测试到自动化测试,待遇翻倍,我整理的超有用工作经验分享~
我想应该有很多测试人员应该有这样的疑虑,自动化测试要怎么去做,现在我把自己的一些学习经验分享给大家,希望对你们有帮助,有说的不好的地方,还请多多指教! 对于测试人员来说,不管进行功能测试还…

从股票市场选择配对的股票:理论联系实际
我们有了计算距离的方法,即共同因子相关系数的绝对值就是衡量协整性的一个好方法。现在看一些实际应用中会遇到的问题。 整合的特定回报的平稳性(Stationarity of Integration Specific Returns)
两个时间序列协整的必要条件是整合的特定回报时序是平稳…
k8s安装3节点集群Fate v1.7.2
采用k8s,而非minikube, 在3个centos系统的节点上安装fate集群。
集群配置信息
3节点配置信息如下图:
当时kubefate最新版是1.9.0,依赖的k8s和ingress-ngnix版本如下: Recommended version of dependent software: Kubernetes:…
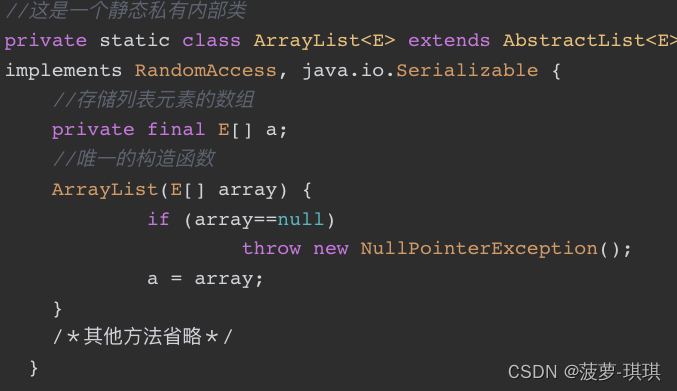
Java编码的坑你知多少?
货币计算坑: 这段代码你认为结果是多少? 我们期望的结果是0.4,也应该是这个数字,但是打印出来的却是0.40000000000000036,这是为什么呢?
这是因为在计算机中浮点数有可能(注意是可能࿰…
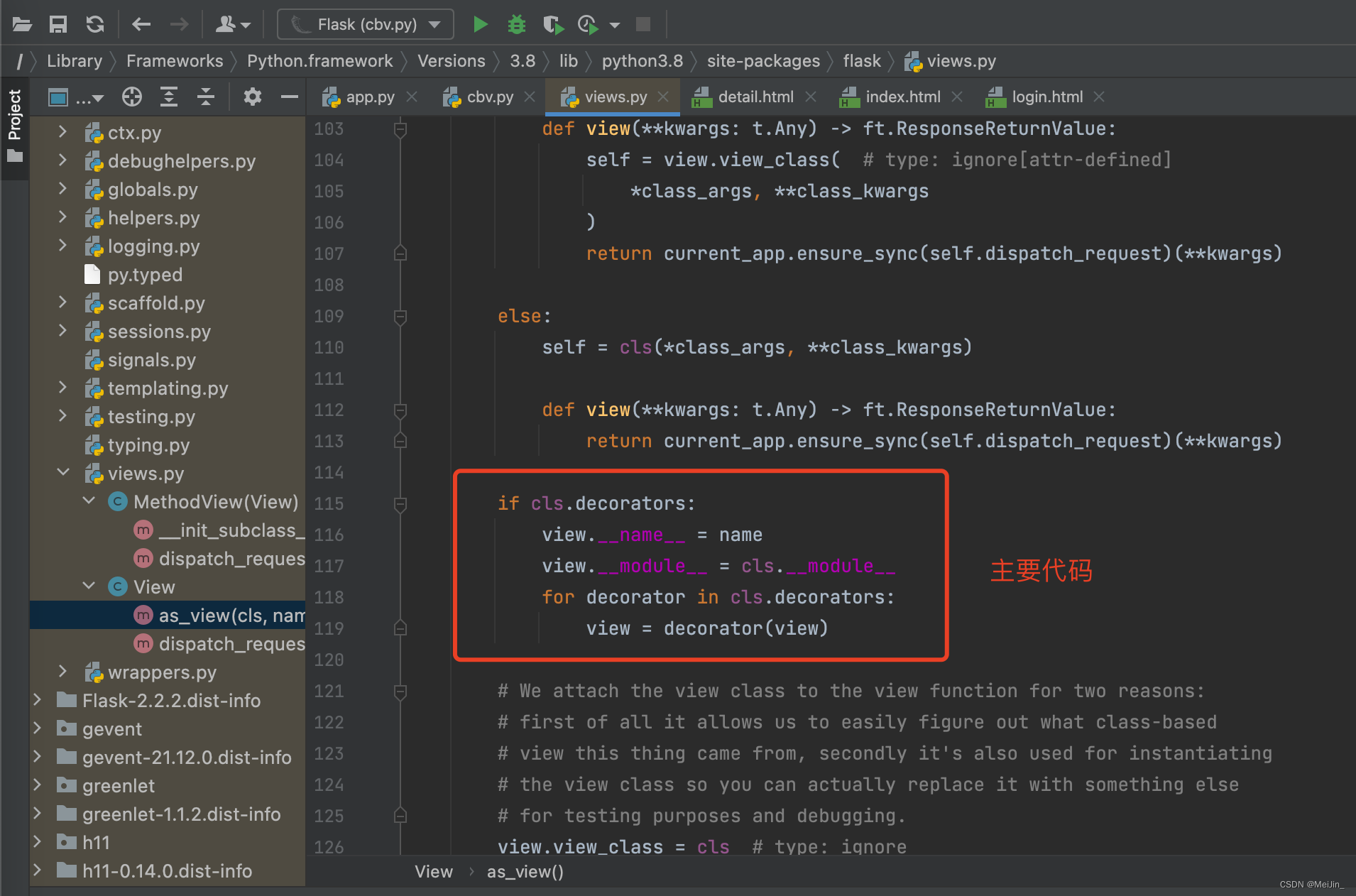
Flask从入门到放弃(介绍、模版语法案例、配置文件、路由本质、CBV整体流程)
文章目录一、Flask介绍二、Flask快速使用三、Flask展示用户信息案例四、Flask配置文件五、路由系统1)路由系统2)路由本质3)Add_url_rule的参数六、Flask的CBV1)CBV的写法2)CBV添加装饰器3)as_view的执行流程…
排名前十的仓库管理系统大盘点(真实测评)!
通过本篇文章,您将了解以下问题:1、国内适合企业的仓库管理系统软件有哪些,排名怎么样?2、企业在选择仓库管理系统时应考虑哪些因素?
目前市场上有多种仓库管理系统,不同的仓库管理系统由于目标市场的不同…

dumi 如何使用?一文教你使用,高效写出你的博客、组件库文档
文章目录一、dumi介绍二、使用 dumi 的两种方式(着重在已成型项目中使用dumi)2.1、基于 dumi 官网带有的脚手架去进行开发2.2、在已成型的项目中引用 dumi 插件,运行项目2.3、dumi中使用scss2.4、如何在组件内写 tsx | md 文档2.4.1、button/…

DataX 二次开发支持 Oracle 更新数据
文章目录1、原理2、源码修改2.1 OracleWriter注释对writeMode的限制2.2 WriterUtil,增加oracle逻辑2.3 CommonRdbmsWriter.Task修改2.4 测试前文回顾: 《DataX 及 DataX-Web 安装使用详解》 《DataX 源码调试及打包》 《DataX-Web 源码调试及打包》
目前…
2022年四川建筑八大员(土建施工员)考试试题及答案
百分百题库提供建筑八大员(土建)考试试题、建筑八大员(土建)考试预测题、建筑八大员(土建)考试真题、建筑八大员(土建)证考试题库等,提供在线做题刷题,在线模拟考试&…