货币计算坑:

这段代码你认为结果是多少? 我们期望的结果是0.4,也应该是这个数字,但是打印出来的却是0.40000000000000036,这是为什么呢?
这是因为在计算机中浮点数有可能(注意是可能)是不准确的,它只能无限接近准确值,而不能完全精确。为什么会如此呢?可以这样理解,在十进制的世界里没有办法准确表示1/3,那在二进制世界里当然也无法准确表示1/5(如果二进制也有分数的话倒是可以表示),在二进制的世界里1/5是一个无限循环小数。
- 使用BigDecimalBigDecimal是专门为弥补浮点数无法精确计算的缺憾而设计的类,并且它本身也提供了加减乘除的常用数学算法。特别是与数据库Decimal类型的字段映射时,BigDecimal是最优的解决方案。
- 使用整型把参与运算的值扩大100倍,并转变为整型,然后在展现时再缩小100倍,这样处理的好处是计算简单、准确,一般在非金融行业(如零售行业)应用较多。此方法还会用于某些零售POS机,它们的输入和输出全部是整数,那运算就更简单。
类型静默转换:
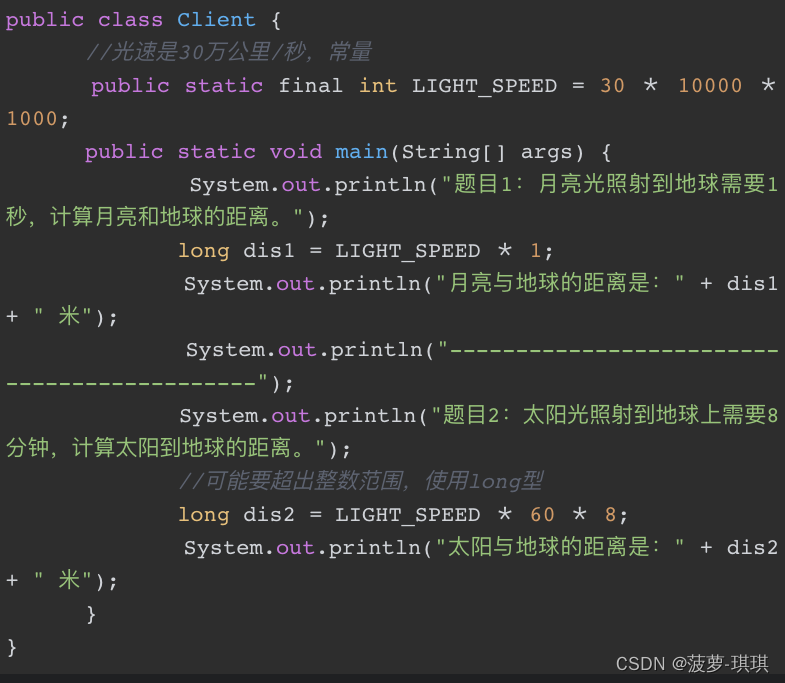
最终dis2输出是负值,dis2不是已经考虑到int类型可能越界的问题,并使用了long型吗,为什么还会出现负值呢?
那是因为Java是先运算然后再进行类型转换的,具体地说就是因为disc2的三个运算参数都是int类型,三者相乘的结果虽然也是int类型,但是已经超过了int的最大值,所以其值就是负值了(为什么是负值?因为过界了就会从头开始),再转换成long型,结果还是负值。
包装类的坑
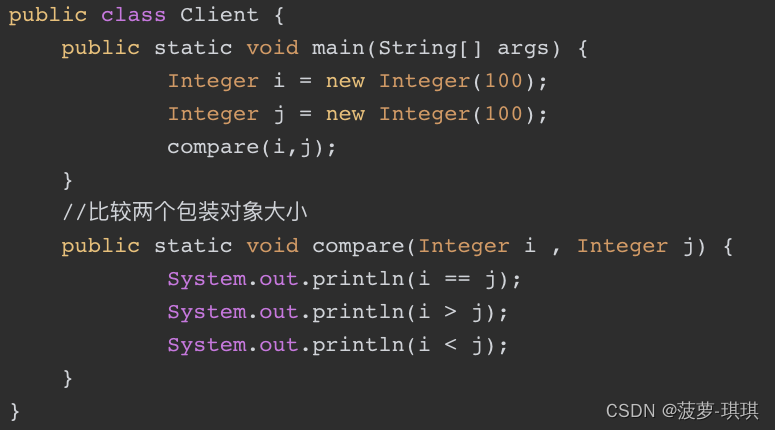
代码很简单,产生了两个Integer对象,然后比较两者的大小关系,既然基本类型和包装类型是可以自由转换的,那上面的代码是不是就可打印出两个相等的值呢?让事实说话,运行结果如下:
在Java中,“>”和“<”用来判断两个数字类型的大小关系,注意只能是数字型的判断,对于Integer包装类型,是根据其intValue()方法的返回值(也就是其相应的基本类型)进行比较的(其他包装类型是根据相应的value值来比较的,如doubleValue、floatValue等),那很显然,两者不可能有大小关系的。问题清楚了,修改总是比较容易的,直接使用Integer实例的compareTo方法即可
随机种子乱用坑 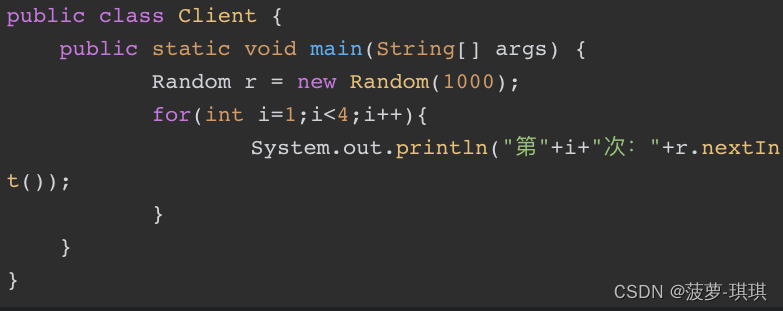
上面使用了Random的有参构造,运行结果如下:
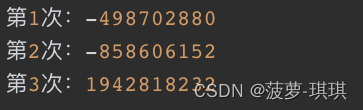
计算机不同输出的随机数也不同,但是有一点是相同的:在同一台机器上,甭管运行多少次,所打印的随机数都是相同的,也就是说第一次运行,会打印出这三个随机数,第二次运行还是打印出这三个随机数,只要是在同一台硬件机器上,就永远都会打印出相同的随机数,似乎随机数不随机了,问题何在?
new Random(1000)显式地设置了随机种子为1000,运行多次,虽然实例不同,但都会获得相同的三个随机数。所以,除非必要,否则不要设置随机种子。
多用静态内部类设计提高模型可读性:
Java中的嵌套类(Nested Class)分为两种:静态内部类(也叫静态嵌套类,Static Nested Class)和内部类(Inner Class)。内部类我们介绍过很多了,现在来看看静态内部类。什么是静态内部类呢?是内部类,并且是静态(static修饰)的即为静态内部类。只有在是静态内部类的情况下才能把static修复符放在类前,其他任何时候static都是不能修饰类的。静态内部类的形式很好理解,但是为什么需要静态内部类呢?那是因为静态内部类有两个优点:加强了类的封装性和提高了代码的可读性,我们通过一段代码来解释这两个优点,如下所示:
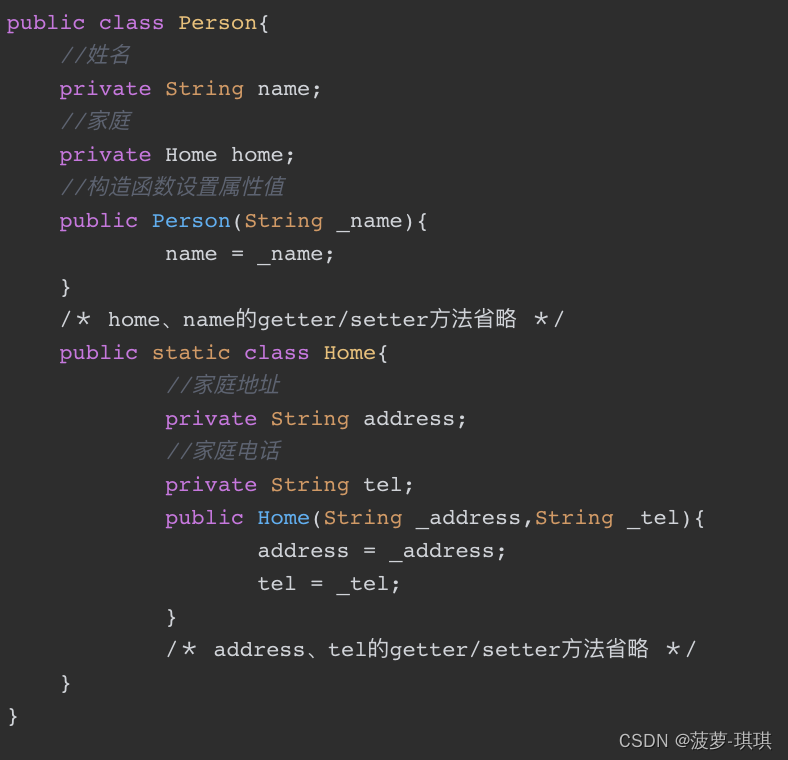
其中,Person类中定义了一个静态内部类Home,它表示的意思是“人的家庭信息”,由于Home类封装了家庭信息,不用在Person类中再定义homeAddre、homeTel等属性,这就使封装性提高了。同时我们仅仅通过代码就可以分析出Person和Home之间的强关联关系,也就是说语义增强了,可读性提高了
多重继承真的可以
在Java中一个类可以多重实现,但不能多重继承,也就是说一个类能够同时实现多个接口,但不能同时继承多个类。但有时候我们确实需要继承多个类,比如希望拥有两个类的行为功能,就很难使用单继承来解决问题了(当然,使用多层继承是可以解决的)。幸运的是Java中提供的内部类可以曲折地解决此问题,我们来看一个案例,定义一个父亲、母亲接口,描述父亲强壮、母亲温柔的理想情形,代码如下:

其中strong和kind的返回值表示强壮和温柔的指数,指数越高强壮度和温柔度也就越高,这与在游戏中设置人物的属性值是一样的。我们继续来看父亲、母亲这两个实现: 外部类继承了父亲的能力,实现了母亲的能力,内部类继承母亲的能力,这样就完成的多重继承
外部类继承了父亲的能力,实现了母亲的能力,内部类继承母亲的能力,这样就完成的多重继承
 让工具类不可实例化:
让工具类不可实例化:
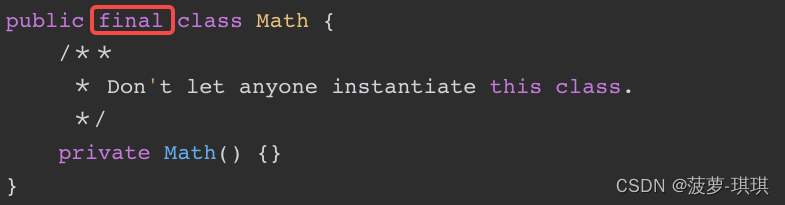
我就是一个工具类,我只想要其他类通过类名来访问,我不想你通过实例对象访问。这在平台型或框架型项目中已经足够了。不需要被子类继承重写
 如果你一定要通过反射方式实例化,那么更严谨的工具类就加上如上代码
如果你一定要通过反射方式实例化,那么更严谨的工具类就加上如上代码
避免浅拷贝:
我们知道一个类实现了Cloneable接口就表示它具备了被拷贝的能力,如果再覆写clone()方法就会完全具备拷贝能力。拷贝是在内存中进行的,所以在性能方面比直接通过new生成对象要快很多,特别是在大对象的生成上,这会使性能的提升非常显著。但是对象拷贝也有一个比较容易忽略的问题:浅拷贝(Shadow Clone,也叫做影子拷贝)存在对象属性拷贝不彻底的问题
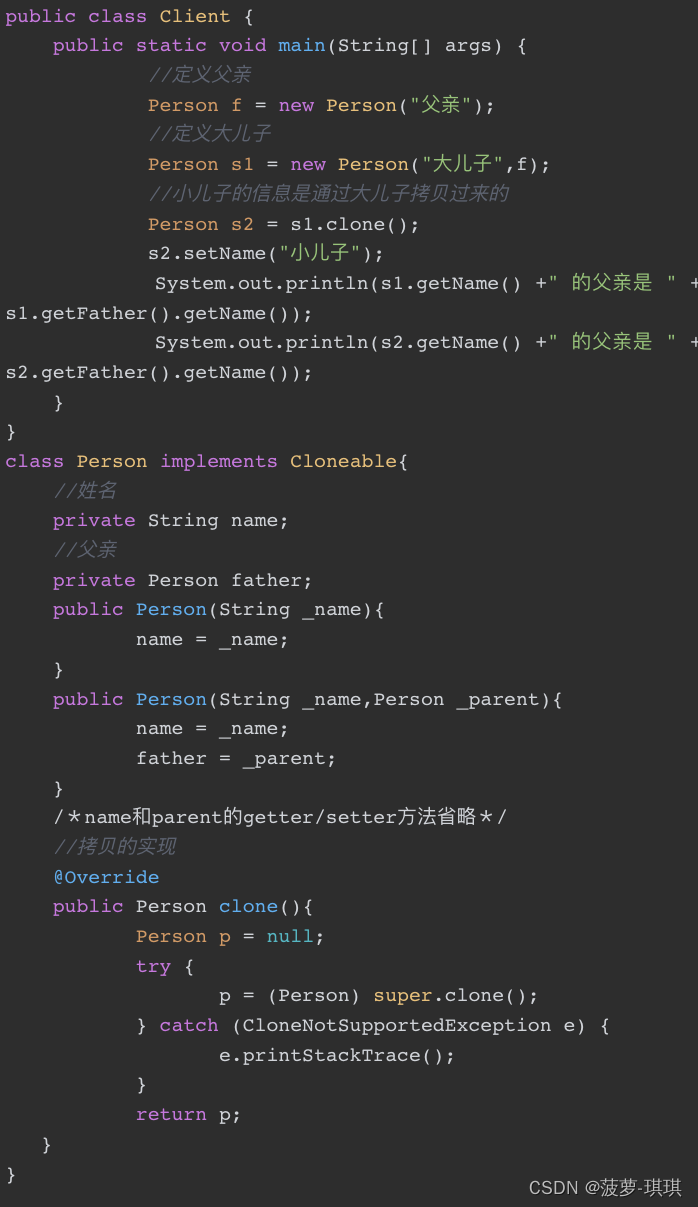
如果改变S1的值,那么S2被拷贝对象也会被改变,这是个不可预期的结果,很容易进坑,我们一般需要的是S1拷贝给S2后,S1/S2就是独立对象不会互相影响,但是浅拷贝会互相影响
如果变量是一个实例对象,则拷贝地址引用,也就是说此时新拷贝出的对象与原有对象共享该实例变量,不受访问权限的限制。这在Java中是很疯狂的,因为它突破了访问权限的定义:一个private修饰的变量,竟然可以被两个不同的实例对象访问,这让Java的访问权限体系情何以堪!
asList方法产生的List对象不可更改:

直接new了一个ArrayList对象返回,难道ArrayList不支持add方法?不可能呀!可能,问题就出在这个ArrayList类上,此ArrayList非java.util.ArrayList,而是Arrays工具类的一个内置类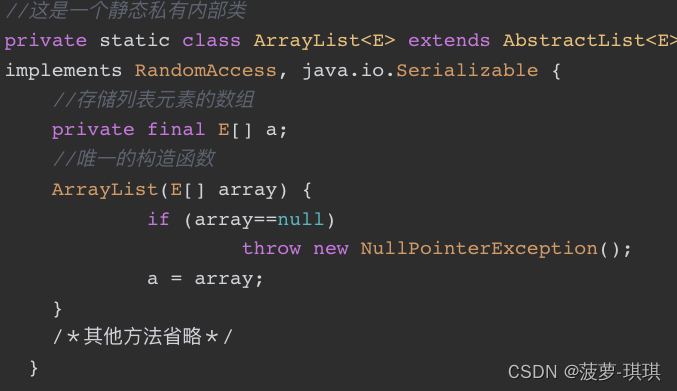
List循环禁用foreach:
因为ArrayList数组实现了RandomAccess接口(随机存取接口),这也就标志着ArrayList是一个可以随机存取的列表。在Java中,RandomAccess和Cloneable、Serializable一样,都是标志性接口,不需要任何实现,只是用来表明其实现类具有某种特质的,实现了Cloneable表明可以被拷贝,实现了Serializable接口表明被序列化了,实现了RandomAccess则表明这个类可以随机存取,对我们的ArrayList来说也就标志着其数据元素之间没有关联,即两个位置相邻的元素之间没有相互依赖和索引关系,可以随机访问和存储。Java中的foreach语法是iterator(迭代器)的变形用法,也就是说对于ArrayList,需要先创建一个迭代器容器,然后屏蔽内部遍历细节,对外提供hasNext、next等方法。问题是ArrayList实现了RandomAccess接口,已表明元素之间本来没有关系,可是,为了使用迭代器就需要强制建立一种互相“知晓”的关系,比如上一个元素可以判断是否有下一个元素,以及下一个元素是什么等关系,这也就是通过foreach遍历耗时的原因。
List操作你知道吗:
两个集合的交集
list1.retainAll(list2);集合的差集
list1.removeAll(list2);switch带来的空值异常:
public static void doSports(Season season) {
switch (season) {
case Spring:
System.out.println("春天放风筝");
break;
case Summer:
System.out.println("夏天游泳");
break;
case Autumn:
System.out.println("秋天捉知了");
break;
case Winter:
System.out.println("冬天滑冰");
break;
default:
System.out.println("输入错误!");
break;
}
}我们就传递一个null值进去看看有没有问题
Exception in thread "main" java.lang.NullPointerException
at Client.doSports(Client.java:9)
at Client.main(Client.java:5)switch语句是先计算season变量的排序值,然后与枚举常量的每个排序值进行对比的。在我们的例子中season变量是null值,无法执行ordinal方法,于是报空指针异常了
@Override不同版本的区别:
interface Foo {
public void doSomething();
}
class Impl implements Foo {
@Override
public void doSomething() {
}
}这是一个简单的@Override示例,接口中定义了一个doSomething方法,实现类Impl实现此方法,并且在方法前加上了@Override注解。这段代码在Java 1.6版本上编译没有任何问题,虽然doSomething方法只是实现了接口定义,严格来说并不能算是覆写,但@Override出现在这里可以减少代码中可能出现的错误。可如果在Java 1.5版本上编译此段代码,就会出现如下错误:
The method doSomething() of type Impl must override a superclass method Client.java注意,这是个错误,不能继续编译。原因是1.5版中@Override是严格遵守覆写的定义:子类方法与父类方法必须具有相同的方法名、输入参数、输出参数(允许子类缩小)、访问权限(允许子类扩大),父类必须是一个类,不能是一个接口,否则不能算是覆写。而这在Java 1.6就开放了很多,实现接口的方法也可以加上@Override注解了,可以避免粗心大意导致方法名称与接口不一致的情况发生。在多环境部署应用时,需要考虑@Override在不同版本下代表的意义,如果是Java 1.6版本的程序移植到1.5版本环境中,就需要删除实现接口方法上的@Override注解。
不使用stop方法停止线程:
线程启动完毕后,在运行时可能需要终止,Java提供的终止方法只有一个stop,但是我不建议使用这个方法,因为它有以下三个问题:
- stop方法是过时的从Java编码规则来说,已经过时的方法不建议采用。
- stop方法会导致代码逻辑不完整stop方法是一种“恶意”的中断,一旦执行stop方法,即终止当前正在运行的线程,不管线程逻辑是否完整,这是非常危险的。
- stop方法会破坏原子逻辑,多线程为了解决共享资源抢占的问题,使用了锁概念,避免资源不同步,但是正因此原因,stop方法却会带来更大的麻烦:它会丢弃所有的锁,导致原子逻辑受损。
让多线程齐步走:
思考这样一个案例:两个工人从两端挖掘隧道,各自独立奋战,中间不沟通,如果两人在汇合点处碰头了,则表明隧道已经挖通。这描绘的也是在多线程编程中,两个线程独立运行,在没有线程间通信的情况下,如何解决两个线程汇集在同一原点的问题。Java提供了CyclicBarrier(关卡,也有翻译为栅栏)工具类来实现
static class Worker implements Runnable {
// 关卡
private CyclicBarrier cb;
public Worker(CyclicBarrier _cb) {
cb = _cb;
}
public void run() {
try {
Thread.sleep(new Random().nextInt(1000));
System.out.println(Thread.currentThread().getName() + "-到达汇合点");
// 到达汇合点
cb.await();
} catch (Exception e) {
// 异常处理
}
}
}
public static void main(String[] args) throws Exception {
// 设置汇集数量,以及汇集完成后的任务
CyclicBarrier cb = new CyclicBarrier(2, new Runnable() {
public void run() {
System.out.println("隧道已经打通!");
}
});
// 工人1挖隧道
new Thread(new Worker(cb), "工人1").start();
// 工人2挖隧道
new Thread(new Worker(cb), "工人2").start();
}在这段程序中,定义了一个需要等待2个线程汇集的CyclicBarrier关卡,并且定义了完成汇集后的任务(输出“隧道已经打通!”),然后启动了2个线程(也就是2个工人)开始执行任务。代码逻辑如下:1)2个线程同时开始运行,实现不同的任务,执行时间不同。2)“工人1”线程首先到达汇合点(也就是cb.await语句),转变为等待状态。3)“工人2”线程到达汇合点,满足预先的关卡条件(2个线程到达关卡),继续执行。此时还会额外的执行两个动作:执行关卡任务(也就是run方法)和唤醒“工人1”线程。4)“工人1”线程继续执行。CyclicBarrier关卡可以让所有线程全部处于等待状态(阻塞),然后在满足条件的情况下继续执行,这就好比是一条起跑线,不管是如何到达起跑线的,只要到达这条起跑线就必须等待其他人员,待人员到齐后再各奔东西,CyclicBarrier关注的是汇合点的信息,而不在乎之前或之后做何处理。CyclicBarrier可以用在系统的性能测试中,例如我们编写了一个核心算法,但不能确定其可靠性和效率如何,我们就可以让N个线程汇集到测试原点上,然后“一声令下”,所有的线程都引用该算法,即可观察出算法是否有缺陷。
让接口的职责保持单一:
很多开发人员会为了开发简单化,会针对不同场景通过动态SQL参数来完成不同场景数据展现,这个造成的结果就是根本无法维护和更改,星云的标签列表接口就是一个典型的案例
职责是一个接口(或类)要承担的业务含义,或是接口(或类)表现出的意图,例如一个User类可以包含写入用户信息到数据库、删除用户、修改用户密码等职责,而一个密码工具类则可以包含解密职责和加密职责。明白了什么是类的职责单一,再来看看它有什么好处。单一职责有以下三个优点:
- 类的复杂性降低职责单一,在实现什么职责时都有清晰明确的定义,那么接口(或类)的代码量就会减少,复杂度也就会减少。当然,接口(或类)的数量会增加上去,相互间的关系也会更复杂,这就需要适当把握了。
- 可读性和可维护性提高职责单一,会让类中的代码量减少,我们可以一眼看穿该类的实现方式,有助于提供代码的可读性,这也间接提升了代码的可维护性。
- 降低变更风险变更是必不可少的,如果接口(或类)的单一职责做得好,一个接口修改只对相应的实现类有影响,对其他的接口无影响,那就会对系统的扩展性、维护性都有非常大的帮助。