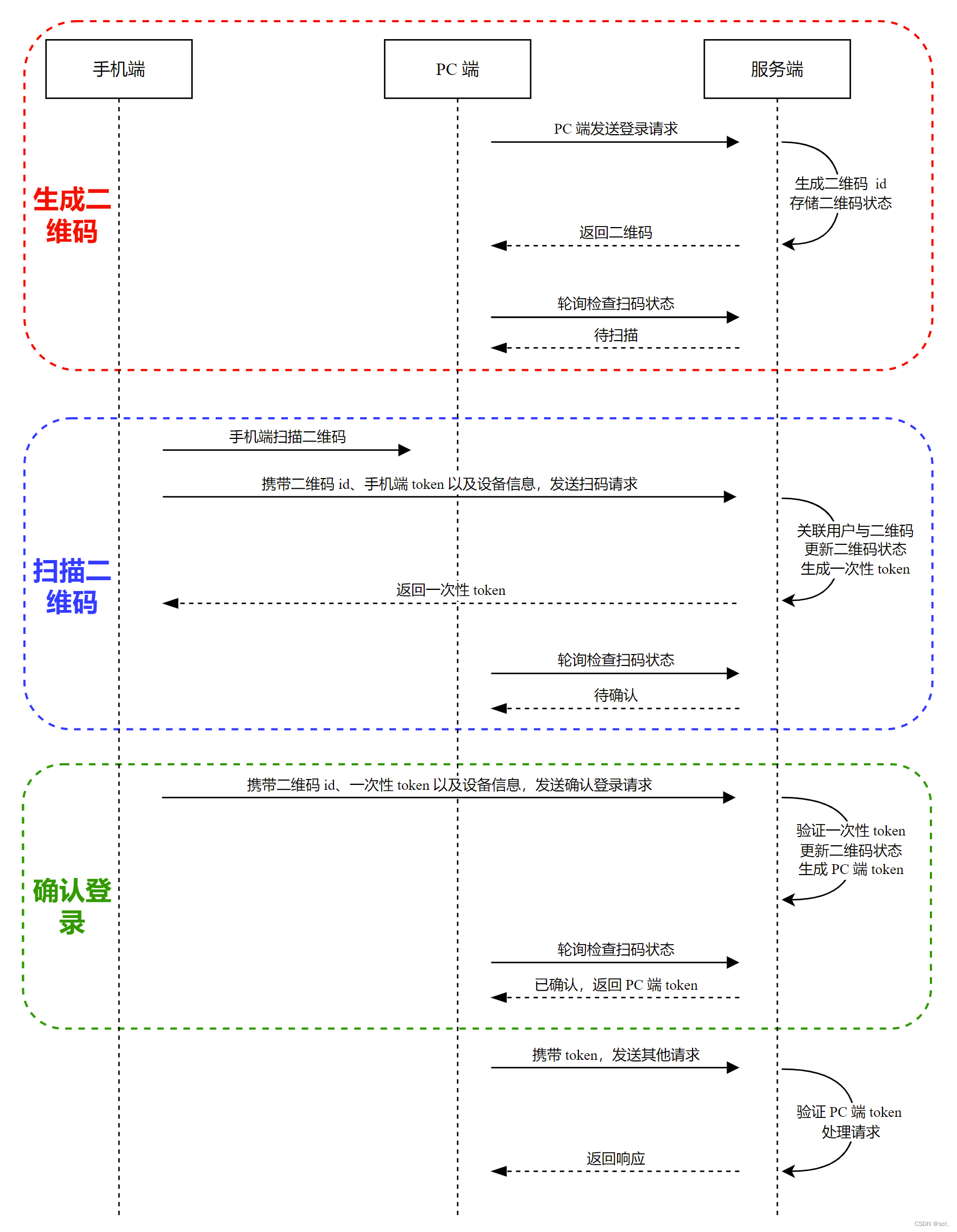
目录
什么是数据库?
数据库操作
表操作
数据库约束
表的设计
聚合查询
分组查询
联合查询 (多表查询)
索引
事务
JDBC
什么是数据库?
数据库是一类软件 , 它是用来组织、保存、管理数据的.组织这些数据也是为了后续进行增删查改.
MySQL 是一款开源免费的数据库. 是一个 " 客户端服务器 " 结构的程序 .
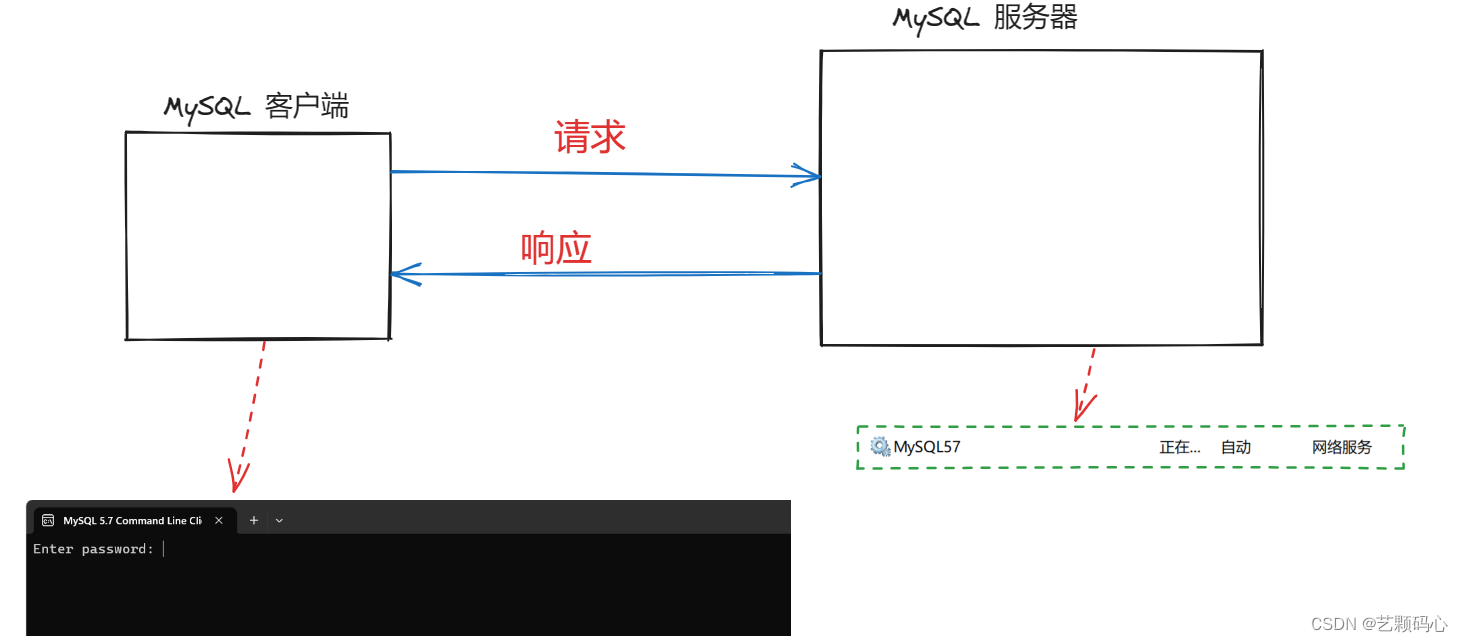
MySQL 服务器为了更好的组织数据 , 把要存的数据划分为多个数据集合 , 这些数据集合也称为 "数据库" , 每个数据库里 会存在许多" 表 " ,(这些表类似于 excle 表格 , 有许多行 列 , 有表头用来描述每一列是什么意思 ) , 每个表里有许多条记录 (record) , 每个记录也就是一行 (row) , 每一行这里又有很多列 (column) , 每个列也称为字段 (field) .

数据库操作
通过SQL语句来操作数据库.
在写 sql 时 , sql 的关键字大小写是不敏感的 , 不论是 大写 还是 小写就是可以的.
查看数据库
SQL语句 : show databases;

16 rows in set (0.07 sec) : 16 行 在 这个集合中 . 花费了 0.07秒 (注意 ! 这个速度对于计算机来说是非常慢的.)
创建数据库
SQL命令 : create database 数据库名;
在创建数据库的时候也可以设置字符集 : create database 数据库名 charset utf8;
注意 ! 数据库命名规则 不可以使 sql 中的关键字 . 如果想要使用 关键字作为数据库名 可以使用 反引号 ` 将数据库名引起来 .

选中数据库
use 数据库名;

删除数据库
drop database 数据库名;

表操作
在对表操作时 首先要先选中数据库 .
查看数据库中的表
show tables;

创建表
create table 表名(列名 类型,列名 类型........);

数据类型 :
数值类型 :
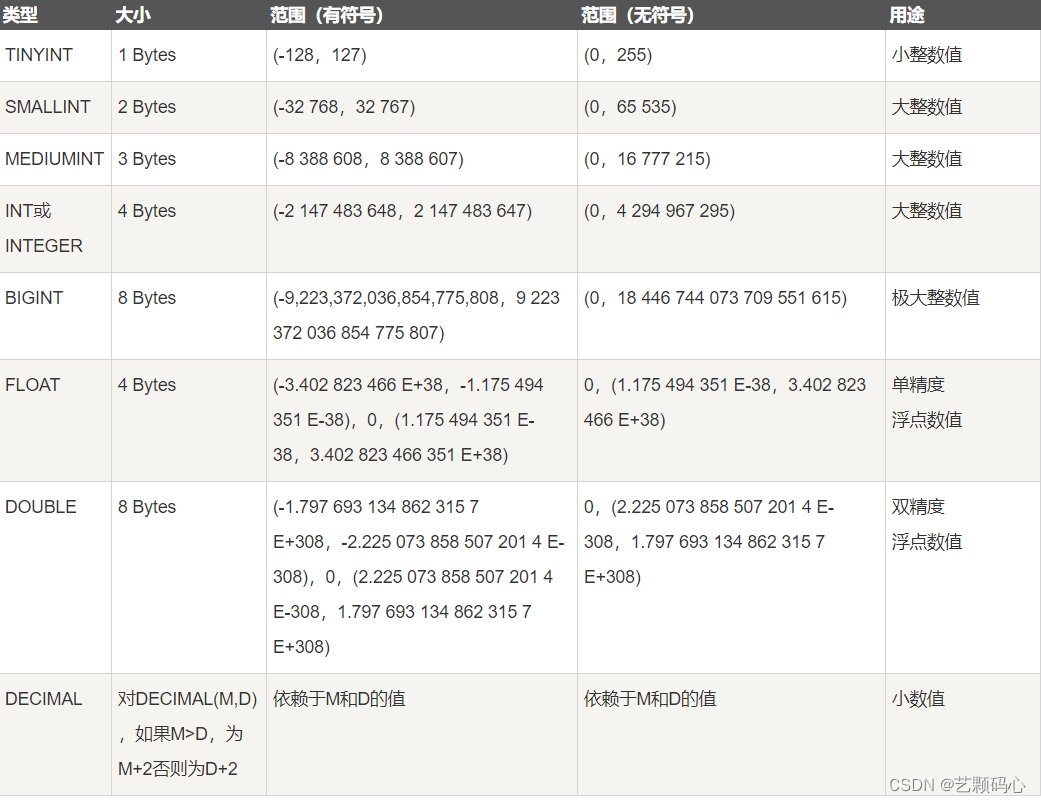
注意 float 和 double 在存储小数时是有误差的 , 不能精确表示 . 因此使用 decimal 会更好.
附加 : 当我们要去设置一个类型表示前钱的时候 , 可以使用 int .来表示分 , 然后转换成元 .
日期类型 :

字符串类型 :
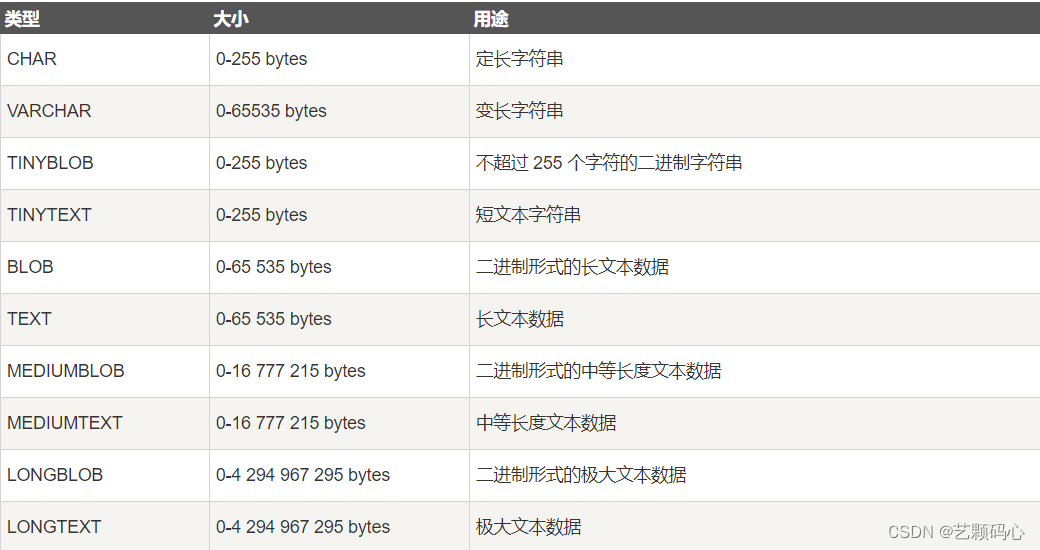
varchar(size) : size 指定的是最大长度 , 单位是字符 .
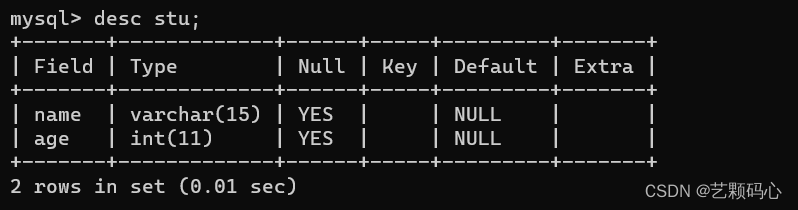
查看指定的表结构
desc 表名;

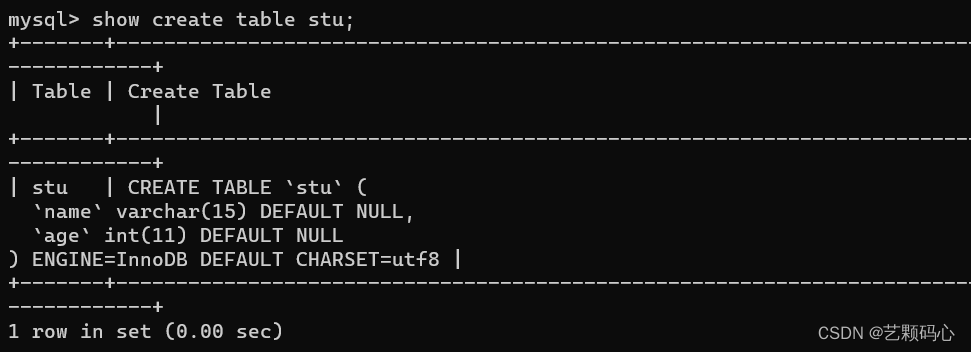
也可以使用: show create table 表名;
删除表
drop table 表名;

创建注释

IF [NOT] EXISTS
if exists : 表示如果存在则执行 .
if not exists : 表示如果不存在则执行 .

MySQL 表中的增删改查
CRUD : 增删改查
C : create 增加
R : retrieve 查询
U : update 更新
D : delete 删除
插入 / 新增数据 : insert into 表名 values(值,值......);
在插入时也可以指定列进行插入 : insert into 表名(字段名,字段名....) values (值,值...); 此时其他列将会采用默认值.
一次还可以插入多条数据 : insert into 表名 values (值,值...),(值,值...),(值,值...);
(而且一次插入多条数据比一次插入一条数据效率更高一些 , 原因是 MySQL 是一个"客户端服务器"结构的程序 , 从客户端输入命令, 这个请求就交给了服务器, 服务器处理好之后就会返回给客户端.因此一次插入命令就要进行一次客户端和服务器的交互)
在插入时 , 括号中的值要与表头的结构匹配.
表示字符串时 使用 ' ' 或者 " " 都是可以的.

附加 : 可能会出现这样的情况 :
错误信息表示这不是一个正确的 value 值.
原因是 : SQL 默认的字符集是 拉丁文. 因为我们输入的字符和数据库的字符集不匹配 .
解决方法是 需要在创建数据库的时候 , 设置字符集 charset utf8; 或者是 设置为 charset gbk.

时间日期类型的插入 :
插入时间的时候 , 是通过特定格式的字符串来表示时间日期的 .
例如 : "2023-7-16 21:21:00"

通过使用sql提供的 now() 函数 ; 可以直接获取到当前的时间 .

查找操作 : select * from 表名; 查询整个表的全部行和列.

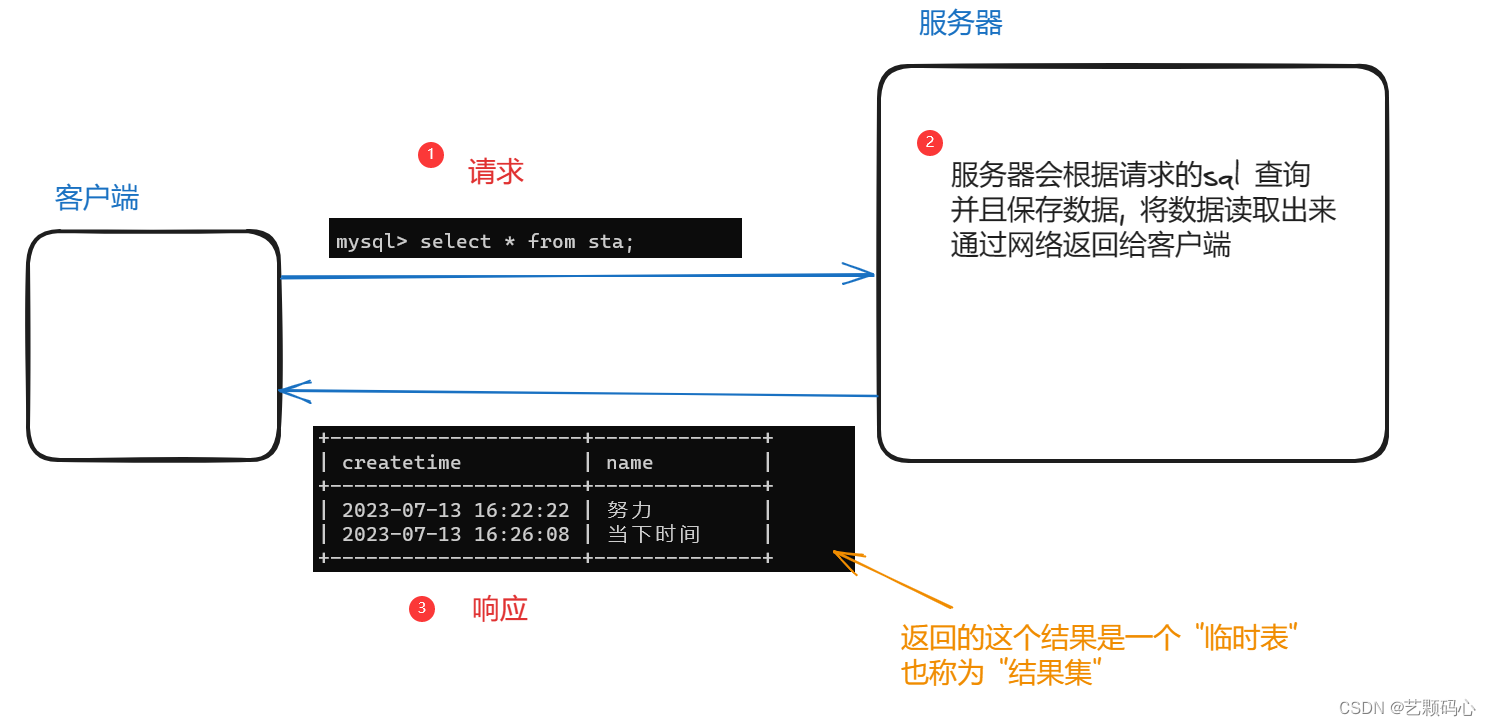
注意 ! 数据特别庞大的时候不建议这样使用 !!!!!!
假如 数据量有 几亿, 这时不就可以再使用 select * from ...; 原因是 由于服务器要返回的数据实在太多 , 会瞬间吃满硬盘带宽和网络带宽 , 这就可能导致其他程序无法使用硬盘或者使用网络 .
直接列查询 : select 列名,列名 ... from 表名;

查询时可以配合一些表达式 :
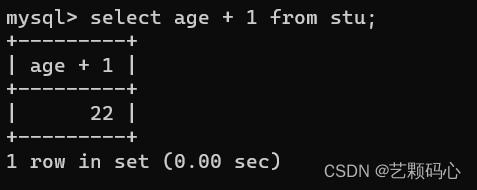
例如 : select age + 1 from stu; ( 查询出来的结果 age 字段都加1 )
这样的操作并不会影响到 数据库中的表 , 这个操作是在临时表上进行操作的.(临时表就是昙花一现,使用一下就没了)
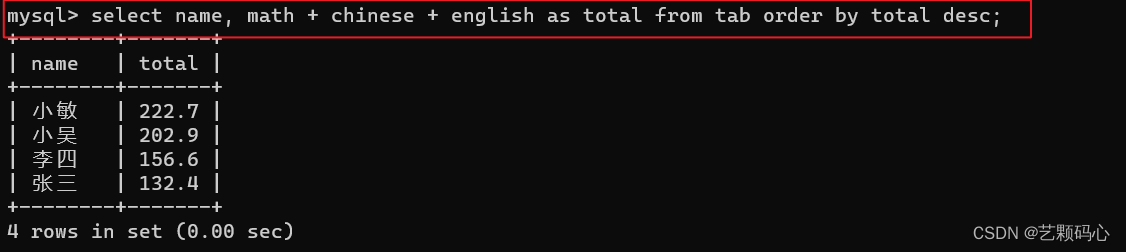
使用 as 可以进行起别名

去重操作 : distinct 针对指定列进行去重 (把重复的行只保留一个)

针对查询结果进行排序 : order by 字句, 指定某些列来进行排序 . 排序可以是升序也可以是降序.
升序 : order by 字句 asc;
降序 : order by 字句 desc;
如果不设置 asc / desc 默认情况下就是 asc.
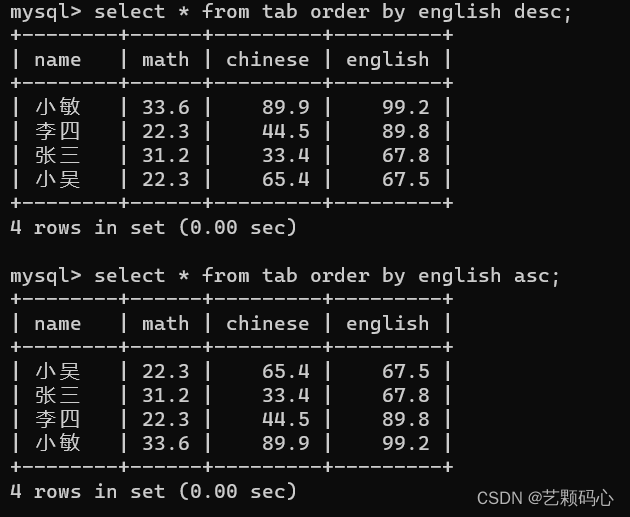
排序时也可以指定多个列来进行排序. 多个列之间使用 , 分割 .
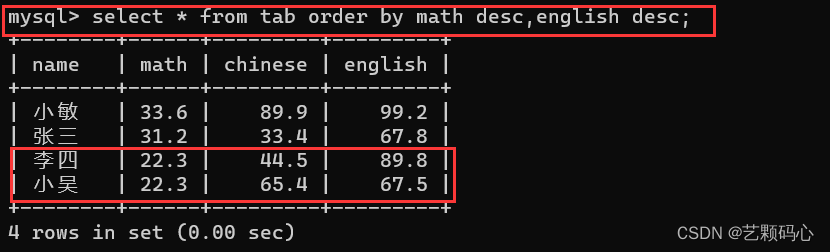
如上 , 当 math 中有两个分数相同时 , 那么就会根据第二列来进行排序 .
条件查询 : 目的就是筛选出我们想要的结果 .
sql 通过一些运算符来表示条件 .

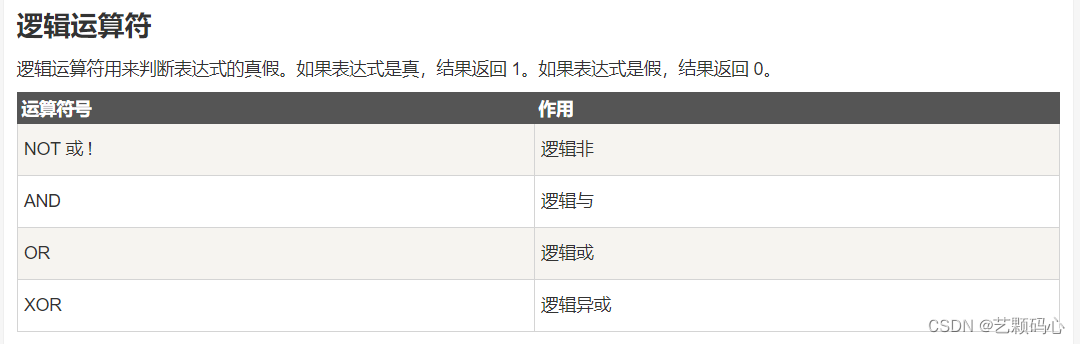
通过 where 字句 , 搭配上述运算符组成表达式 , 就可以完成条件查询 .
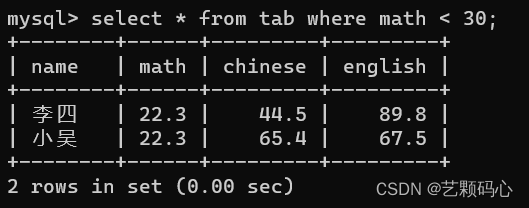
在服务器中 , 会根据要求对数据库中的表进行遍历 , 取出每一行数据 , 把数据代入到条件中 , 看条件是否符合 , 如果是 (符合)真 , 这个记录就保留, 作为结果集的一部分 .
注意 ! musql 中的语法规定 , 此处的别名 total 不能作为 where 条件 , 原因是sql的执行顺序是从后往前 .

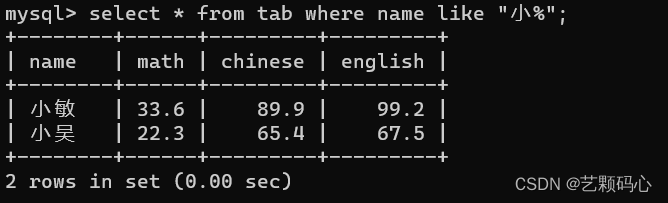
模糊匹配 : LIKE
通过特殊符号来描述一个字符串的特征 , 来匹配字符串 .
LIKE 的使用方法 :
规定 : 1 . 使用 % 代表任意 0 个字符或者 N 个字符 2 . 使用 _ 代表任意 1 个字符
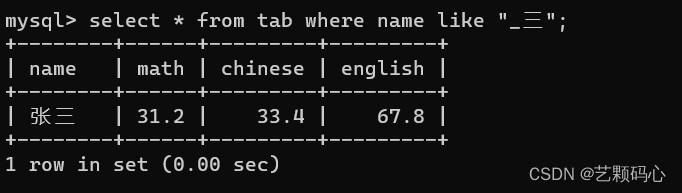
空值判断 :
在 sql 中 不可以使用 列名 = null 来判断 符合 和 不符合
可以使用 列名 <=> null 或者 列名 is null 来判断 .
分页查询 LIMIT
获取前两条数据 :
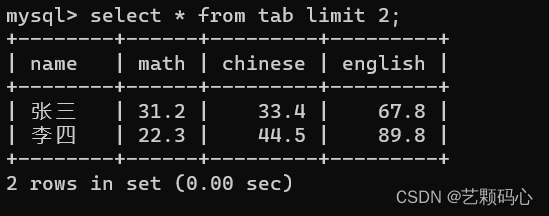
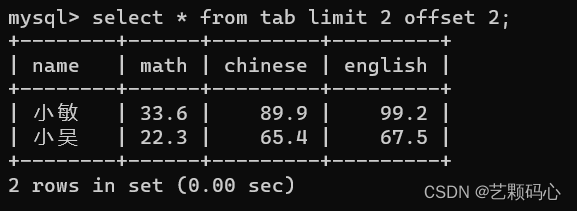
搭配 offset : 从第几条数据开始查
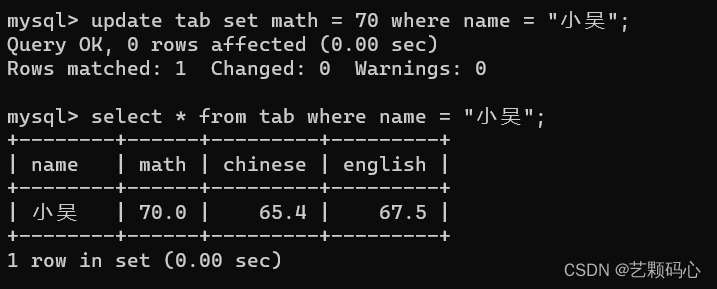
修改 update
update 表名 set 列名 = 值, 列名 = 值 ..... where 条件 ;
删除操作 delete

数据库约束
约束就是为了提高效率 , 提高准确性 .
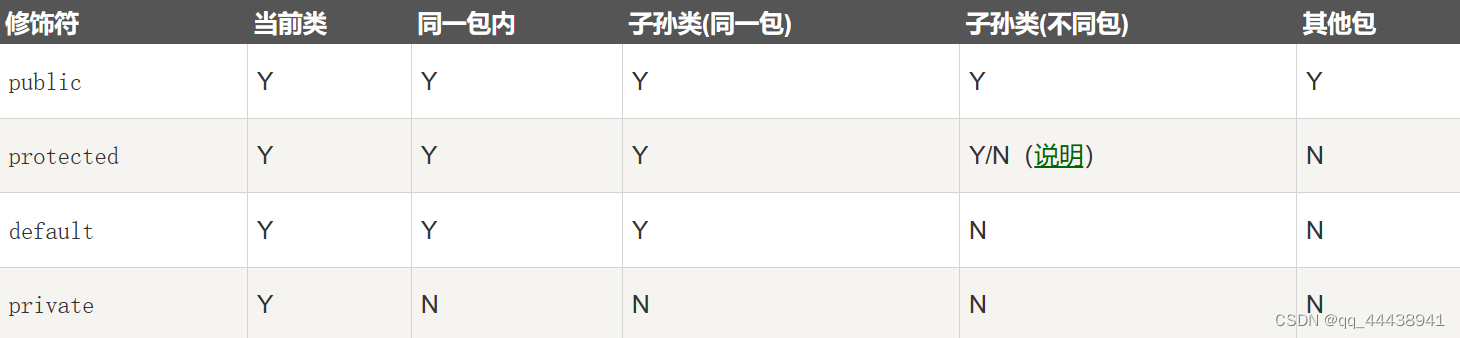
NOT NULL : 表示某列不能为 null , 也就意味着这是必填项.
UNIQUE : 表示此列的值是唯一的
DEFAULT : 默认值
PRIMARY KEY : 主键
FOREIGN KEY : 外键
创建表的时候给字段加上 not null 约束之后 , 之后就不可以给该字段插入 null 值了.
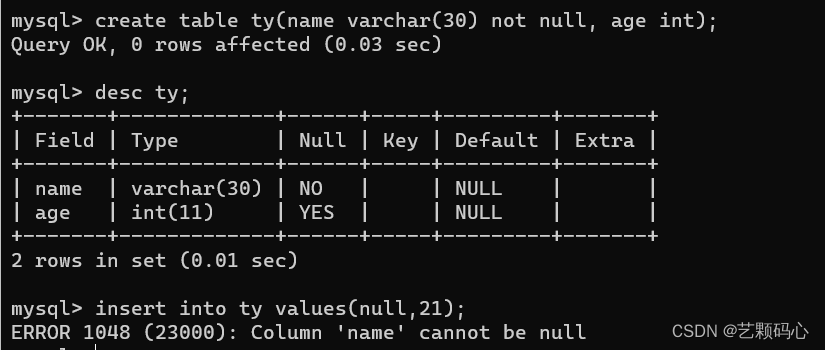
unique : 插入值的时候如果已经存在那么就会报错. (因为设置了unique ,所以在插入值的时候 , 服务器会先进行一次查询操作 来确保当前要插入的值存不存在).
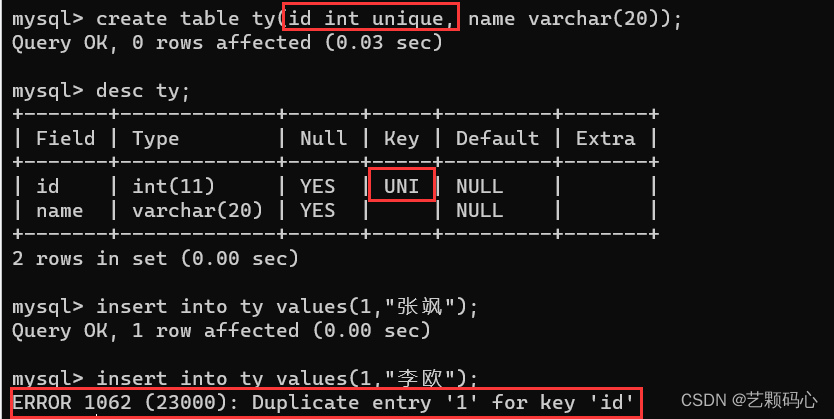
default : 默认值

PRIMARY KEY : 主键
mysql 中 要求一个表中 , 只能有一个主键 .

自增主键 primary key auto_increment
给自增主键插入数据的时候 , 可以手动指定一个值 , 也可以让 mysql 自己分配 , 如果将值设为null,自增主键就会自动赋值 .


外键 foreign key
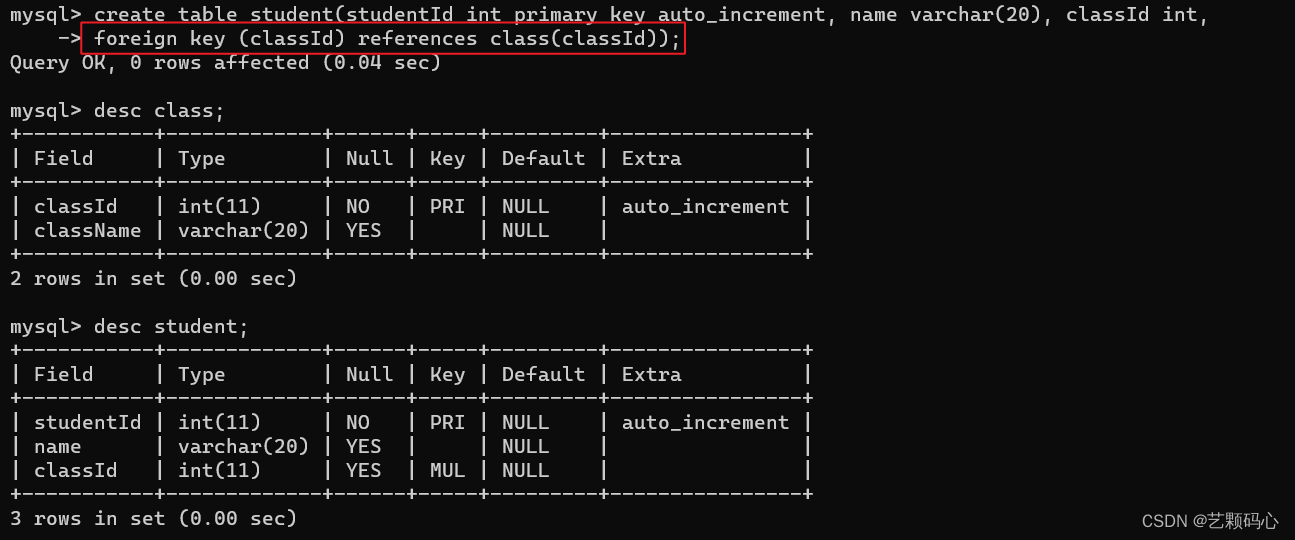
将 class 表中的 classId 作为 student 表中classId 的外键 .那么 student 表中的每个记录的 classId 都要在 class 表中的 classId 中存在 .
student 受到 class 的约束 , 就把 class 叫做 student 的父表 , student 就是 class 的子表.

上述报错的原因是 : 父表中并没有 classId 为 3 的记录. (也就是 mysql 服务器会在父表中查找一下这个值存不存在 , 不存在则报错!)
附加 :
可以将查询语句和插入语句相结合
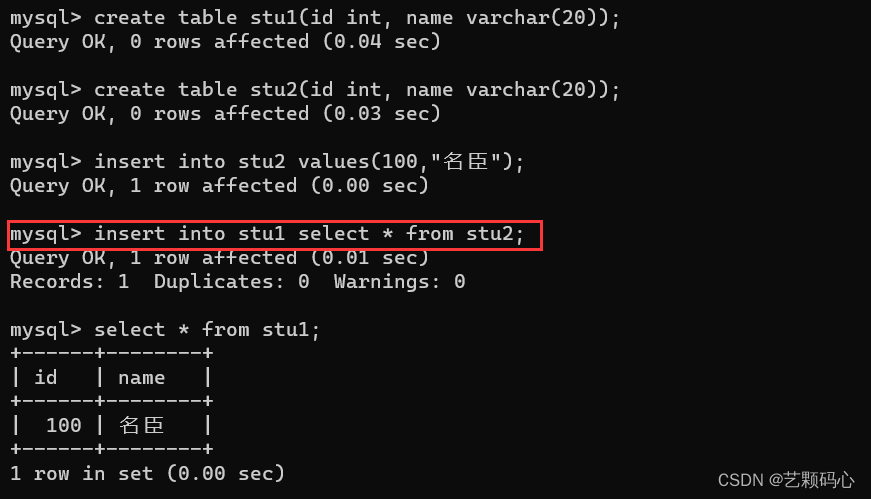
需要保证的是 : 从 stu2 中 查询出来结果 的类型和列数 要和 stu1 表匹配.
表的设计
根据实体与实体之间的关系来设计表.
一对一关系
比如 人 与 身份证 的关系就是一对一的 , 一个身份证对应到一个人 , 并且一个人只能有一个身份证.
方法一 : 可以创建一张表包含 人的信息 和 身份证的信息.
方法二 : 创建两个表分别是关于人的和关于身份证的 , 在 关于人的表上设置 身份证号码 字段用来关联身份证表 .
一对多关系
比如 学生 和 班级 之间的关系 . 一个班级里有许多学生 , 但是一个学生只属于一个班级 .
student 表 (学号,年龄,姓名...所在班级(classId)) 使用所在班级来表示学生和班级的关系.
class 表 (班级编号, 班级名称...)
多对多关系
例如 选课 , 一个学生可以选择多门课 , 一门课又可以有多个学生 .
学生表 (学号,姓名,年龄...)
课程表 (名称,课程编号....)
使用一个关联表将 学生表和课程表关联起来 : 学生-课程 表 (学号,课程编号).
聚合查询
聚合查询 : 使用 SQL 提供的库函数来操作 行与行之间的运算.
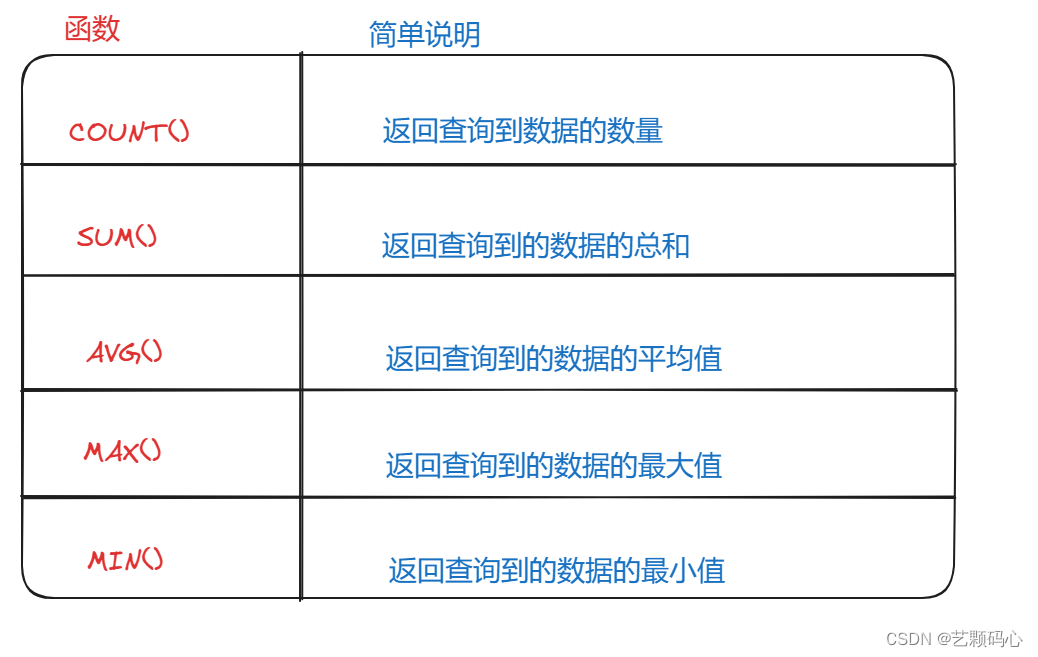
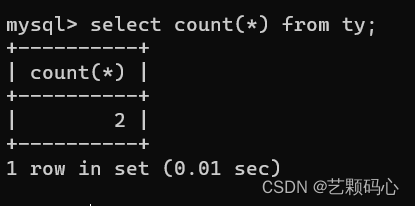
分组查询
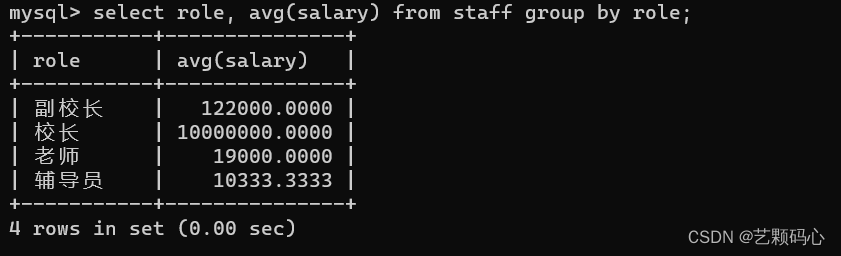
分组聚合 : 按照指定的字段 , 把记录分成若干组 , 每一组分别使用聚合函数 .

求出上述表每个职位的平均薪资 .
分组查询 : group by 指定一个列, 就会把指定列里相同的值分到同一组中 .

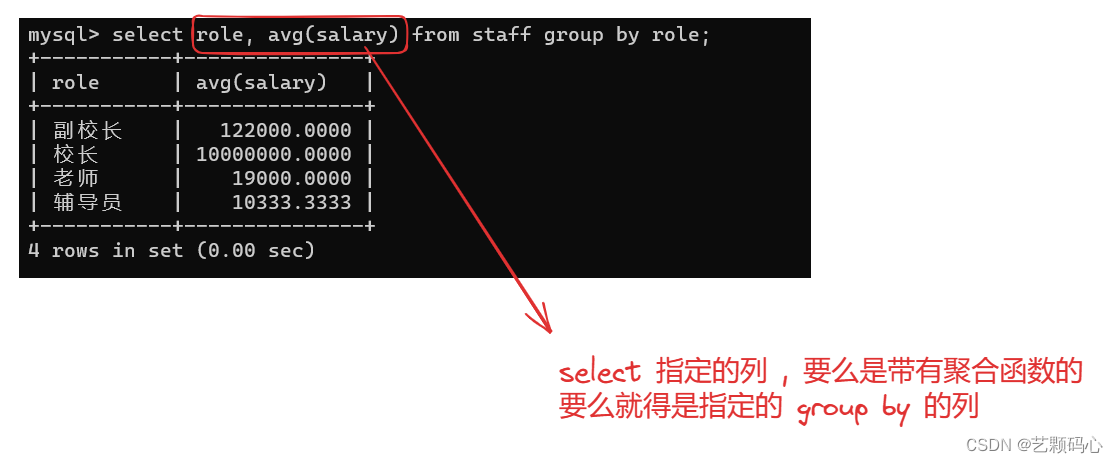
搭配 where , 可以实现分组前 筛选 .

分组后筛选 : having

联合查询 (多表查询)
笛卡尔积 : 联合查询就是基于这个运算
将多个表联合到一起进行查询 , 简单来说
多表查询时步骤 :
1 . 分析需求都涉及到哪些表. 2. 针对这些表进行笛卡尔积 . 3. 筛选出其中的有效数据 (使用表与表之间有关联的字段) 4. 结合需求的条件 , 进一步加强条件 .
例 : 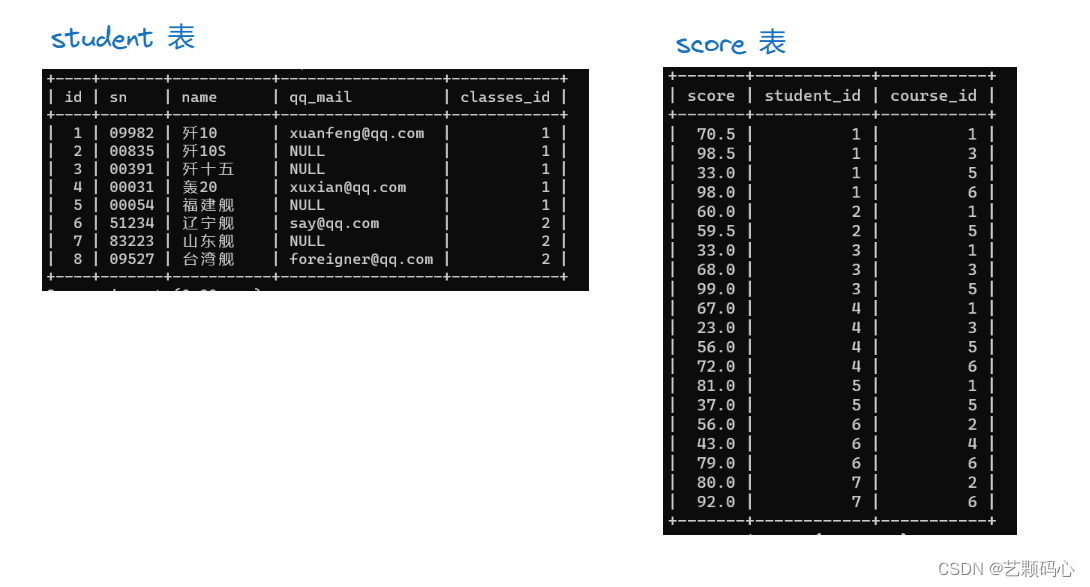
将上述两张表进行笛卡尔积
select * from 表名 , 表名....;
select * from 表名 join 表名....;

...........
![]()
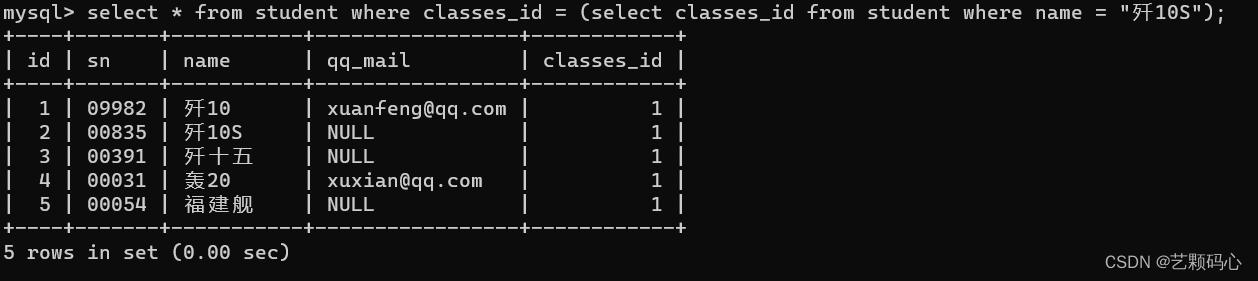
找出 歼10 的成绩 :
select score from student,socre where score.student_id and student.name = "歼10";
select score from student join score on score.student_id and student.name = "歼10";

内连接与外连接
内连接 : 表名 join 表名 on ......; 内连接的结果就是两个表中都有体现的数据.
外连接 : 当两个表中的数据不对应时 , 可以使用左外连接和右外连接.
左外连接 : 表名1 left join 表名2 on ......; 这以左侧的表为准 , 左侧表中的所有数据都能体现出来.
右外连接 : 表名1 right join 表名2 on .......; 这以右侧的表为准 , 右侧表中的所有数据都能体现出来.
自连接操作
自已与自己进行笛卡尔积 , 目的是将行转变为列.
select * from score as s1, score as s2 where......; 由于是两张相同的表 , 因此要起别名.
子查询
将多个查询语句合并成一个
合并查询
union 关键字

union 的使用区别于 or :
or 只能针对一个表 , union 可以把多个表的查询结果合并 (要求多个结果列必须对应) .
union 会自动去重 , union all 不会自动去重 .
索引
索引 index , 可以将索引想象成书中的目录 .
索引存在的意义就是为了加快查找的速度 . 不用再去遍历表.
当然 , 任何事都是两面向 , 索引的缺点 :
1. 需要付出额外的空间代价来保存索引数据 .
2. 索引可能会拖慢新增,删除,修改的速度 .
查看索引 show index from 表名 ;

创建索引 create index 索引名 on 表名 (列名);
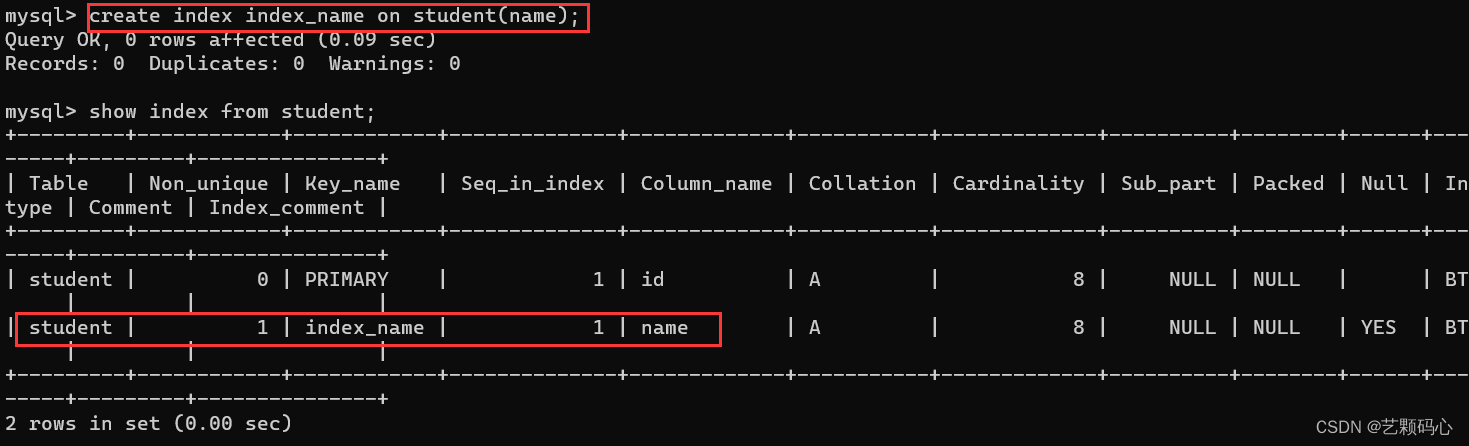
创建索引操作 , 也会有一定危险操作 ! 如果表里的数据很大, 这个建立索引的开销也会很大!
删除索引 drop index 索引名 on 表名;

索引底层使用的数据结构是 B+树
B+ 树的特点 :
1 . 一个节点, 可以存储 N 个key 划分出了 N个区间
2 . 每个节点中的 key 的值 , 都会在子节点中存在 (同时该 Key 是子节点的最大值)
3 . B + 树的叶子节点, 是首位相连 , 类似于一个链表 .
优点 :
1. 当前一个节点保存更多的 key, 最终树的高度是相对更矮的, 查询的时候减少了 IO 访问次数
2 . 所有的查询最终都会落到叶子节点上 . (查询任何一个数据,经过的IO访问次数,都是一样的)
3 . B+ 树的所有的叶子节点 , 构成链表, 此时比较方便进行范围查询 .
4 . 由于数据都在叶子结点上 , 非叶子节点只存储 key,因此非叶子节点,占用空间是比较小的 .
这些非叶子节点就可能在内存中缓存 (或者缓存一部分) , 又进一步减少了 IO 次数 !
事务
事务是什么? 事务是用来干什么的?
举个栗子 :
现在有个转账操作 : A 转 B 1000
首先扣除A的1000 : update account set balance = balance - 1000 where name = "A";
再者就是给B添加一千 : update account set balance = balance + 1000 where name = "B";
但假如 A 的1000 扣完之后 , 数据库崩了 , 还没来得及给B加1000 . 这就很危险了!
事务就是为了解决上述问题的 .
事务的本质就是把多个 sql 语句打包成一个整体(原子性 atom), 要么全部执行, 要么都不执行 (实际上,是执行了一半出错了,这时就会进行"回滚"操作), 这样就不会出现上述的问题执行了一半另一半来不及执行.
事务的使用
开启事务 : start transaction;
提交事务 : commit;
回滚事务 : rollback;
事务的特性
1 . 原子性 (最核心的特性) (要么执行,要么都不执行)
2 . 一致性 (事务执行前后,数据得是靠谱的) (例如 转账 我转出去了100 他收到了500 , 这是不行的)
3 . 持久性 (事务修改的内容是写到硬盘上的,持久存在的)
4 . 隔离性 (隔离性是为了解决"并发"执行事务引起的问题. 当有多个客户端给服务器提交事务,服务器就要同时处理多个客户端的请求,这就是"并发")
当多个客户端同时对同一张表进行操作时, 就很有可能把数据整乱了 . 而隔离性就是为了解决这个问题 .
并发处理事务可能引起的问题 :
一 . 脏读问题
一个事务A正在对数据进行修改的过程中 , 还没提交之前, 另外一个事务B也对同一个数据进行了读取, 此时B的读操作就称为 "脏读" , 读到的数据也称为"脏数据" .
为了解决脏读问题 , mysql引入"写操作加锁" 这样的机制. (写操作的时候不可以有读操作) .
二. 不可重复读
事务1 提交数据 , 事务2开始读数据 , 在读取过程中 , 事务3又提交了新的数据 .此时意味着同一个事务2之内,多次读数据,读出来的结果是不相同的. 称为"不可重复读" .
为了解决不可重复读的问题, 可以通过给读加锁 , 来提高事务的隔离性 .
三 . 幻读
在读加锁和写加锁的前提下 , 一个事务两次读取同一个数据, 发现读取的数据值是一样的,但是结果集不一样了.
为了解决幻读问题 , 数据库采用"串行化" 这样的方式来解决幻读 , 彻底放弃并发处理事务 , 一个接一个的串行的处理事务 .
JDBC
下载驱动包 (版本号要与MySQL的版本号匹配)

public class main {
public static void main(String[] args) throws SQLException {
// JDBC 实现步骤
// 1. 创建并初始化一个数据源
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource)dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8&useSSL=false");
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("111111");
// 2. 和数据库服务器建立连接
Connection connection = dataSource.getConnection();
// 3. 构造 SQL 语句
String sql = "insert into stu values ('苗条俊',21)";
PreparedStatement statement = connection.prepareStatement(sql); // 对sql字符串进行预编译
// 4. 执行 SQL 语句
int ret = statement.executeUpdate();
System.out.println("ret = " + ret);
// 5. 释放必要的资源
statement.close();
connection.close();
}
}


查询操作
public class main {
public static void main(String[] args) throws SQLException {
// JDBC 实现步骤
// 1. 创建并初始化一个数据源
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource)dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8&useSSL=false");
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("111111");
// 2. 和数据库服务器建立连接
Connection connection = dataSource.getConnection();
// 3. 构造 SQL 语句
String sql = "select * from stu";
PreparedStatement statement = connection.prepareStatement(sql); // 对sql字符串进行预编译
// 4. 执行 SQL 语句
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()) {
String name = resultSet.getString("name");
int age = resultSet.getInt("age");
System.out.println("name = " + name + ", age = " + age);
}
// 5. 释放必要的资源
resultSet.close();
statement.close();
connection.close();
}
}
End...