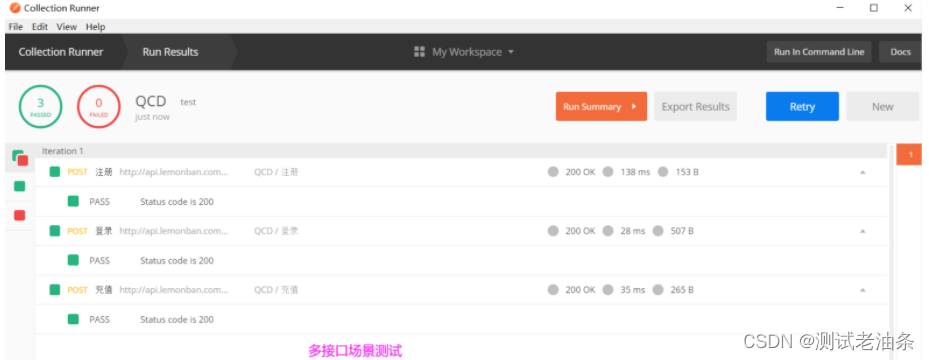
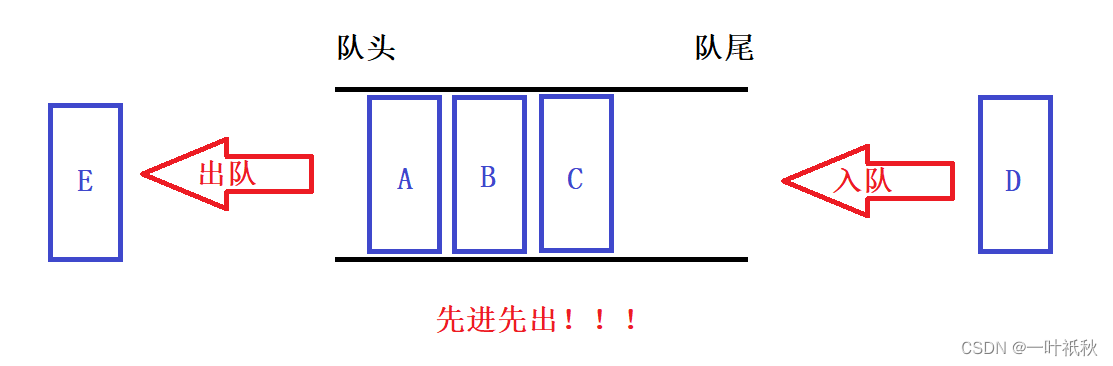
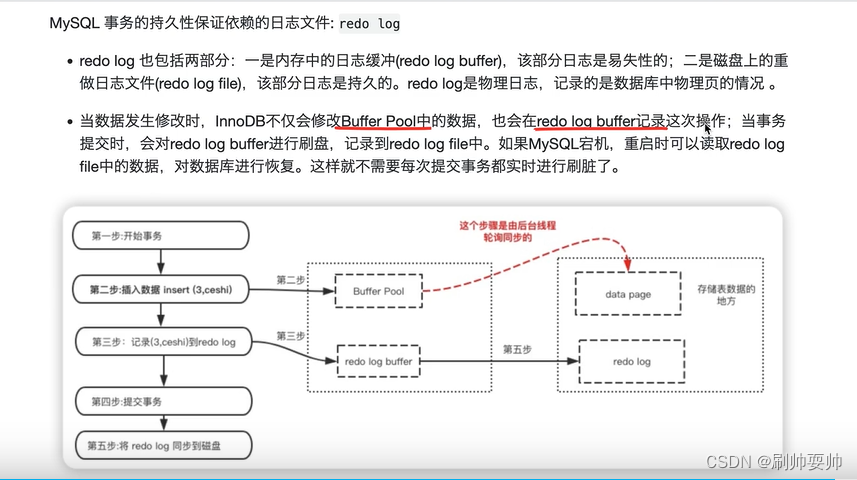
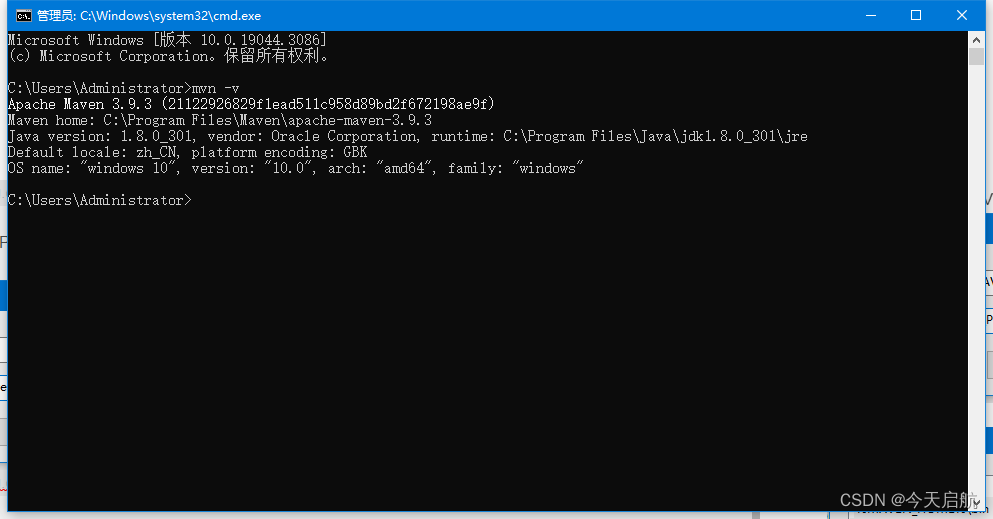
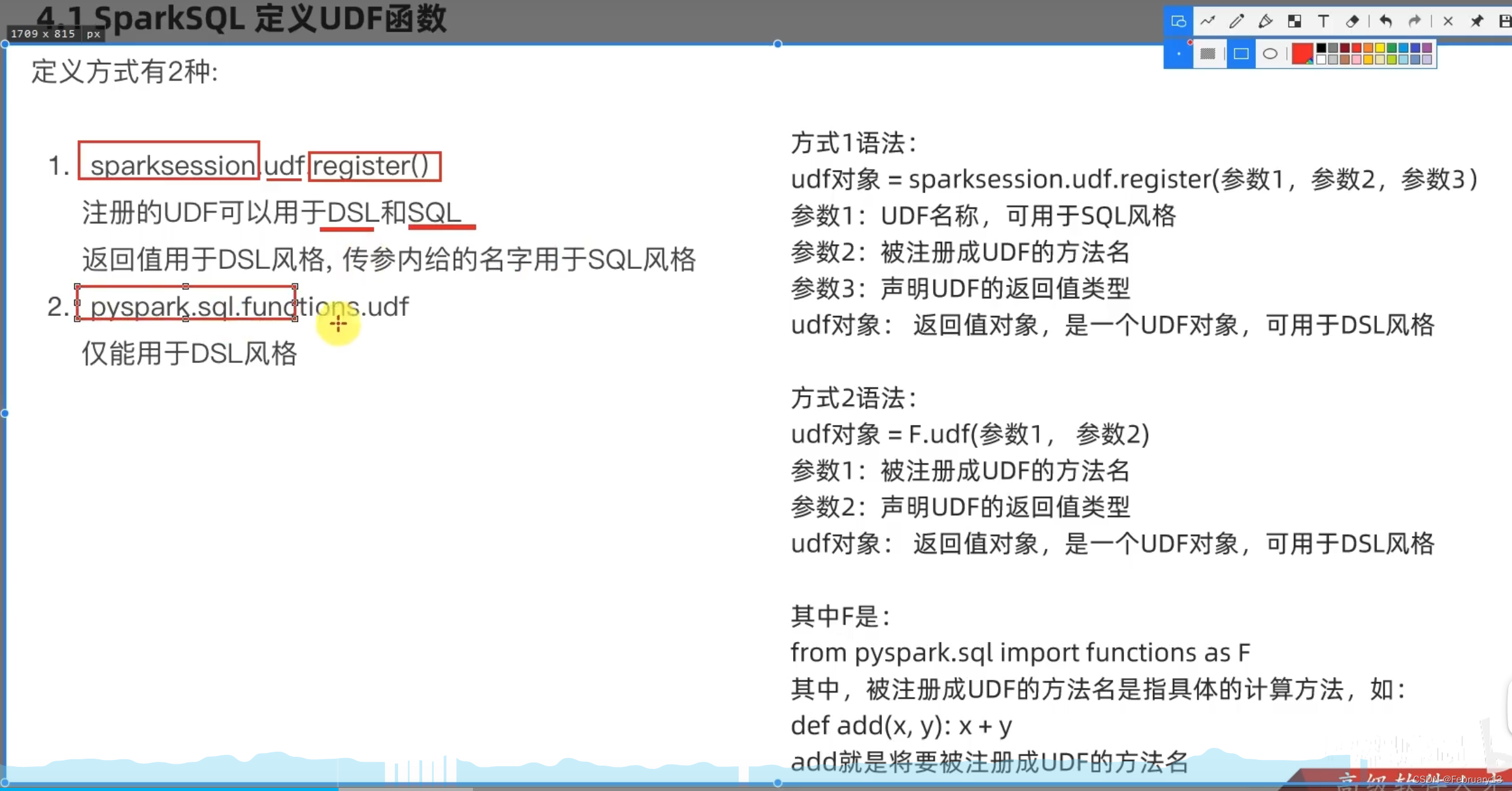
sparksql只能创建UDF,使用 SparkSession.udf.register()
def num_count(num):
return num*10
#自定义方法名,调用的函数(包含逻辑),返回值
udf2 = spark.udf.register("udf1",num_count,IntegerType())
#第二个参数是udf的处理逻辑,是一个独立的方法
#sql风格使用UDF
df.selectExpr("udf1(num)").show()
注册一个返回值是数组的UDF:
udf2= spark.udf.register("udf1",user_count,ArrayType(StringType()))
spark.sql("select udf1(name) from t").show()
注册一个返回值为字典的UDF:
udf3 = spark.udf.register("udf1",user_count,StructType().add("num",IntegerType(),nullable=True).\
add("letters",StringType(),nullable=True))
df.selectExpr("udf1(name)").show()
使用 repartition(1)和mapPartitions()实现UDAF:
rdd = sc.parallelize([1,2,3,4,5]).repartition(1)
df = rdd.toDF(["NUM"])
指定一个schema,df说白了是一个二维数组