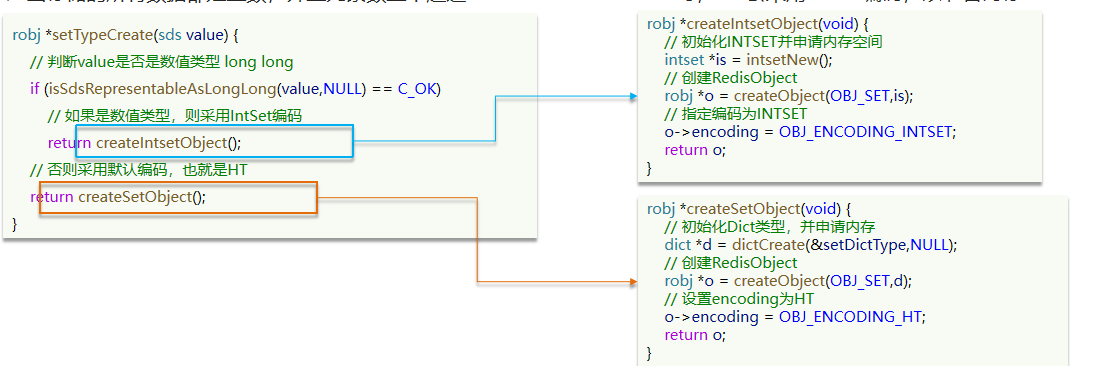
目标文件的学习
1.什么是目标文件以及格式
目标文件为编译器编译后生成的文件,就是window下的.obj,linux下的.o文件。与可执行文件格式几乎一样,因为只是缺少链接过程。所以可执行文件,动态链接库,静态链接库,目标文件广义上都可以算是一个格式,即可执行文件的格式
2.目标文件是怎么样的
目标文件很明显包含编译后的机器指令代码,数据,还包含了链接需要的符号表,调试信息,字符串等等。我们通常以段分隔。
代码段(.code .text):机器指令
数据段(.data):全局变量和局部静态变量
bss段(.bss):未初始化的全局变量和局部静态变量
还有一个部分,文件头
描述整个文件的文件属性,是否可以执行,是静态还是动态链接,目标硬件,目标操作系统等信息。还包括一个段表,描述各个段的数组,各个段在文件中的偏移地址以及段的属性。(这里的段就是指的是代码,数据,bss等段)
(目标文件通常是ELF结构)
3.为什么目标文件需要分段
1.将代码与数据分开,数据和代码被映射到不同的虚拟内存中,可以给其设置不同的权限,保护代码段指令不被修改。
2.缓存在现代计算机地位非常重要,分段能提高缓存的命中概率。
3.增加了存储空间利用率,共享数据。能将系统中运行多个同样的程序只用保存一份指令,数据能够共享。window系统中超过一半是共享部分。
4.以一个程序来讲解各段细节
程序
simply.c
#include<stdio.h>
int global_init_var = 84;
int global_uninit_var;
void func1(int i)
{
printf("%d\n", i );
}
int main()
{
static int static_var = 85;
static int static_var2;
int a = 1;
int b;
func1(static_var+static_var2+a+b);
return a;
}
经过gcc -c simply.c 得到simply.o
通过objdump工具可以查看.o文件的内容结构
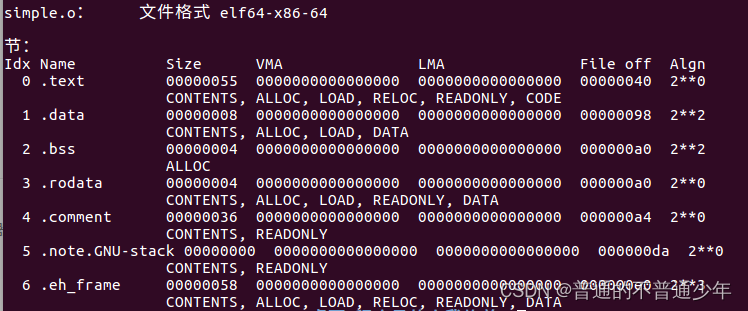
objdump -h simply.o
得到内容(参数-h是将elf文件各个段基本信息打印),很明显分成了.text,.data,.bss,.rodata,.comment,.note.GNU-stack等段,分别为代码,数据,bss,只读数据,注释信息,堆栈提示段。
size为大小,file off起始位置这两行最为重要的信息。,每个段底下的第二行表示段的属性,CONTENTS表示该段在文件中存在等等。
那么实际存在的段为.text,.data,.rodata,.comment(.note段存在但是大小为0)
size命令可以获取各个段的大小
size simply.o
其中dec3个段长度的十进制,hex16进制

5.代码段
以上面程序为例子
-s将所有段的内容以16进制打印。-d将所有包含指命的段反汇编
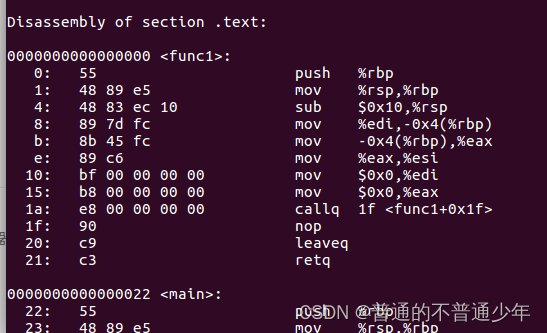
objdump -s -d
结果可以很明显的看出反汇编的结构.text包含的正是funch1和main函数的指令
6.数据段与只读数据段
.data段保存的是那些已经初始化的全局变量和局部静态变量
根据程序可以知道为global_init_var与static_var。两个变量都为int类型,故共8个字节。
.rodata存放只读数据,例如printf函数中的%d\n是一种只读数据,就是const修饰的和字符串常量。
由下图.data区内容0x54与0x55刚好对应84与85,就是上面两个变量的值
.rodata区中的25640a00对应ascil表就是%d\n
(注意是16进制,然后我用的是ubunte系统为小端模式)

7.bss段
bss段放置的是位初始化的全局变量和静态局部变量
上面程序代码中static_var2与global_uninit_var就是
这里不做多解释,通常c语言有一个步骤叫bss段清零,所以放入bss段的变量初值都是0,如果定义全局变量或静态局部变量值=0,同样放入bss段。
8.其它的段
除了.text,.data,.rodata,.bss这些常见的段,还有一些比较特殊的段,还有被遗弃(不使用了)的段
.comment 编译器版本信息
.debug 调试信息
.dynamic 动态链接信息
.hash 符号哈希表
.line 调试的行号表O
.note 额外的编译器信息
.strtab 存储elf结构用到的各种字符串
.symtab 符号表
.shstrtab 段名表
.plt .got 动态链接的跳转表和全局入口表
.init.fini 程序初始化和终结代码段
这些段都是.开头的,我们也可以自定义段,例如定义music段存放音乐信息,但是不能以.开头
9.ELF文件结构描述
上面我们已经讲了各个段的作用,接下来讲述这些段在ELF怎么放置,还有ELF结构还有那些内容
1.整体结构
ELF Header
.text
.data
.bss
…
other sections
section header table (段表)
string tables
symbol tables
首先是文件头,描述了整个文件的基本属性,如elf文件版本号,目标机器型号,程序入口地址等。
然后接下来是各个段的内容,其中与段有关的重要结构体就是段表,该表描述了所有段的信息,例如段命,长度,文件偏移,读写权限等
10.段表
我们之前使用的命令只是打印重要的段,例如.text,.data等等
我们现在使用这个命令将会打印段表的信息,即打印所有段的信息
readelf -S simply.c
结果
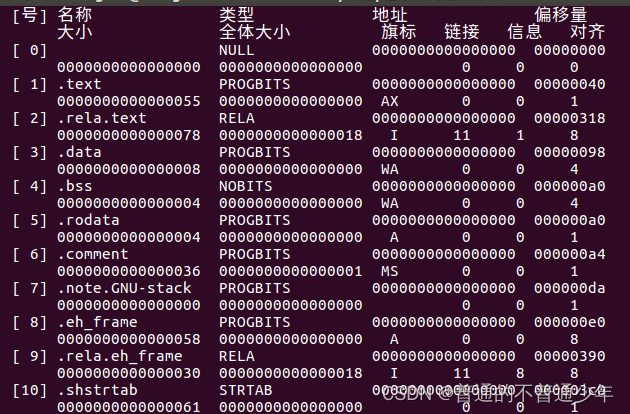
由图可以知道,该程序总共10个段,
段表描述了段的信息有10个重要信息
sh_name
段命
sh_type
段的类型
sh_flags
段的标志位
sh_addr
段虚拟地址
sh_offset
段偏移
sh_size
段大小
sh_link
段的链接信息
sh_info
段的链接信息
sh_addralign
段对齐长度
sh_entsize
项的长度
10.重定位表
就是目标程序中有哪些部位需要重定位,就是代码段和数据段内需要重定位的函数或变量
这些重定位信息都记录在.rel.text或.rel.data内
由于我们的程序变量都是存在该程序内,所以没有.rel.data段
但是我们使用了printf函数,是需要在链接的时候重定位的,故存在.rel.text段
(为什么需要重定位,因为一些函数或变量就不存在在主程序中,绝对地址无法调用,需要调用其它.h或.c文件内的变量和函数,我们就需要其定位到正确的位置,去调用,才能正常使用。
11.字符串表
为什么需要字符串表,因为ELF结构里面有太多的字符串变量了,段命,变量名等等,而且大小不定,难以定义,我们可以直接定义一块大的空间,只用给下标,遇到\0就放回字符串,将普通的字符串通通保存,只有给下标直接可以访问。
12.链接的接口-符号
链接的本质就是将多个目标文件之间互相粘到一起,合为一个整体,能够互相使用对方需要的函数与变量,功能模块等。
按正常思考,我们要用一个函数和变量,底层该如何去找到,肯定是要靠地址。无法使用,肯定就是地址不对或没有该函数的地址,故其实本质上就是目标文件之间地址的引用,我找不到,我就问你要,因为你有这个函数或变量的地址。
我们将函数和变量称为符号,函数名与变量名称为符号名。故为什么需要引用的函数和变量一定不能重名,否则报错,就是因为符号重名会导致链接混乱。(这里要注意C++有其特殊性,函数重载,函数可以重名,但参数不能相同)
最后我们每一个目标文件都有符号表,记录了目标文件中使用到的所有符号,每个符号有一个符号值,就是符号的地址,也就是函数或变量的地址。
(我们最关心的是全局符号,因为这些符号最有可能被其它目标文件使用)
13.符号重复的问题
由于C语音和C++语言非常的庞大,我们可能定义一个函数就会导致符号重复,故为了防止重定义,C语言规定了定义一个函数或变量后,都在其前面加‘_’,形成新的符号名,这样就可以简单而原始的解决用户与C库的符号冲突。但程序一但很大,仍然有很大可能重复,故C++考虑到了这个问题,增加名称空间的方法来解决。
上面讲到了函数重载,还有一个情况就是不同类可以有同名同参数函数。
处理其实很简单,函数和变量会根据所处的类和返回值,函数参数不同会先生成一个函数签名,很容易知道,不同的类,函数签名肯定不同,在经过修饰,那么修饰后的符号肯定是不同的,在符号表肯定不会冲突的。