linux开发工具
- 前言
- Linux项目自动化构建工具(make/makefile)
- makefile文件的组成
- 如何使用make
- .PHONY关键字
- 项目清理
- gdb调试器
- 背景
- 使用
- list(l)调试命令
- break(b):设置断点
- info break: 查看断点信息
- run (r) : 运行程序,到第一个断点中止
- 单条执行与单步执行
- 各种关于运行控制的命令
- 关于查看变量信息的命令
- 对断点的各种操作
- quit(q):退出gdb
- 总结
前言
想要在linux系统中进行开发,我们用vim编写代码,用gcc,g++来编译代码,但是除了这两个东西还不够,代码调试工具和自动化构建工具也尤为重要,所以本篇博客的目的就是为了带大家了解这两样东西.
Linux项目自动化构建工具——make/makefile
Liunx调试器——gdb
Linux项目自动化构建工具(make/makefile)
- 俗话说,会不会写nakefile,从侧面说明了一个人是否具备完成大型工程的能力
- 一个工程的源文件有很多,按照器类型,功能,模块放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作。
- makefile带来的好处就是——“自动化编译”,一旦写好makefile文件,只需要一个make命令,整个工程弯曲按自动编译,极大的提高了开发的效率。
这里需要注意的是,make是一条命令,makefile是一个文件(需要我们自己编写的),两个搭配使用才完成了项目自动化构建。
那么,到底该如何使用这个工具呢,接下来我们就用一个最简单的例子来讲解。
假设有一个源文件test.c,我们想用gcc编译生成一个文件名为test的可执行程序,我们想使用make,首先需要在当前文件夹下创建一个名为makefile,或者Makefile、GNUmakefile(三选一)的文件,然后编写makefile文件。
makefile文件的组成
那么如何编写makefile文件呢?我们首先要知道,makefile文件内由两个东西构成,分别是依赖关系和依赖方法。
看下面一个makefile文件:

上面标识的就是依赖关系,上面的意思是mycode文件时根据mycode.c文件生成的,
而下面的编译指令就是依赖方法,为方便书写,依赖方法在makefile文件内也可以按下面的方式书写:
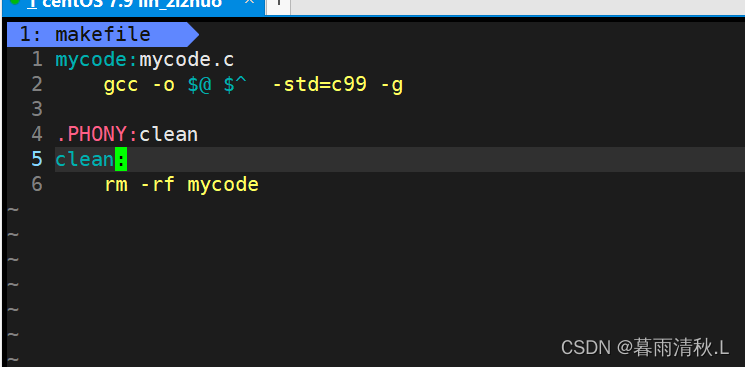
再执行make指令时,编译器会自动用:左边的名字替换$@ , 用 :右边的文件名替换 $^,关于下面的.PHONY关键字,我们稍后再进行解释。
如何使用make
当编写完makefile文件后,我们就可以使用make了,直接输入make指令,编译器就会直接执行第一个具有依赖关系的依赖方法,也就是说,上面的例子直接输入make就会执行mycode可执行文件的依赖方法,如下:

make的原理如下:
- make会在当前目录下找名字叫“Makefile”或“makefile”的文件。
- 如果找到,它会找文件中的第一个目标文件(target),在上面的例子中,他会找到“mycode”这个文件, 并把这个文件作为最终的目标文件。
- 如果mycode文件不存在,或是mycode所依赖的后面的mycode.c文件的文件修改时间要比mycode这个文件新(可 以用 touch 测试),那么,他就会执行后面所定义的命令来生成mycode这个文件。
要理解这一点,我们需要先了解文件的acm时间属性,
- a(access):最新文件访问时间
- c(change):最新文件属性修改时间
- m(modify):最新文件内容修改时间
那么,为什么要知道这个时间呢?首先我们可以先测试一下当我们需要生成的文件已经存在的情况下再进行make会发生什么情况。

可以看到,这里make不会产生作用,并且提示当前文件已经是最新版,那么为什么会提示呢?原因就是make在执行时会先检查目标文件和依赖文件的修改时间,如果目标文件的修改时间更新,那么make就不会执行,我们可以用stat指令查看两个文件的modify时间。
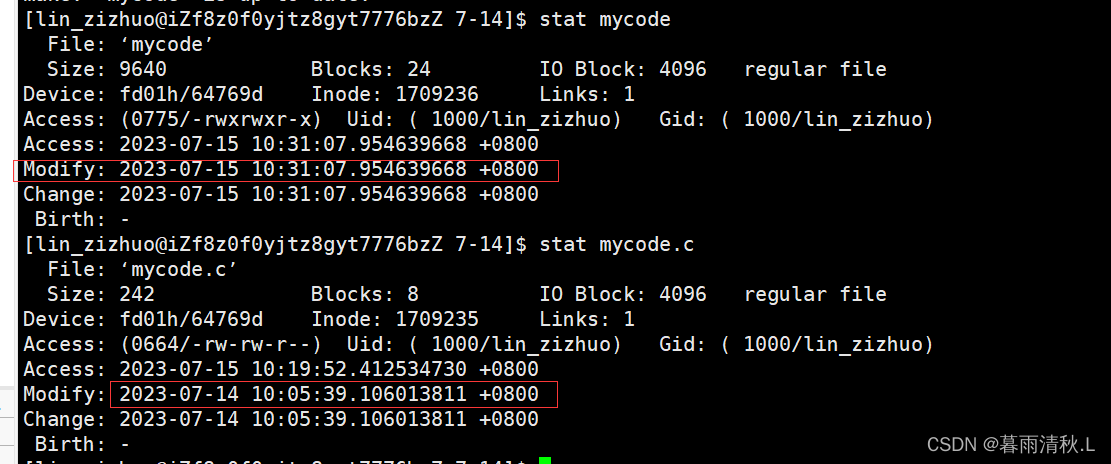
为了验证这个原理,我们可以用touch指令修改mycode.c的文件最新修改时间,然后再make看看能否执行。
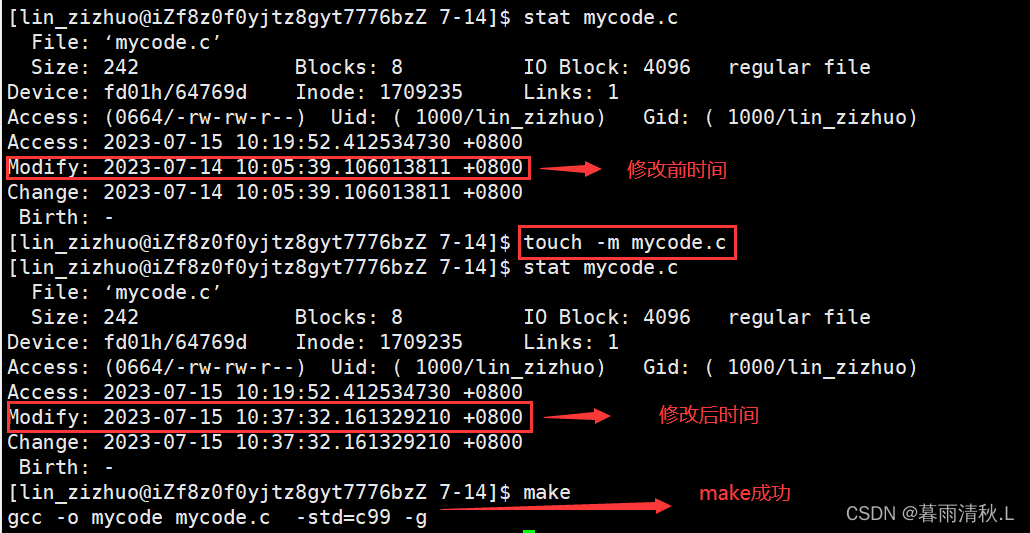
可以看到,在更新了源文件mycode.c的modify时间后,make又可以成功执行了,从而证明了这一点。
那么,如果想要忽略这个时间的新旧问题强制执行,有没有办法呢?
.PHONY关键字
当然是有的,那就是**.PHONY伪目标关键字,加上.PHONY关键字后,make在执行时就会忽略文件的修旧问题。
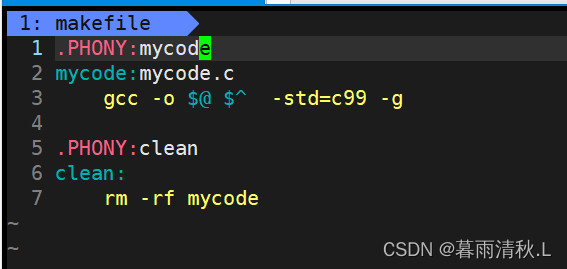
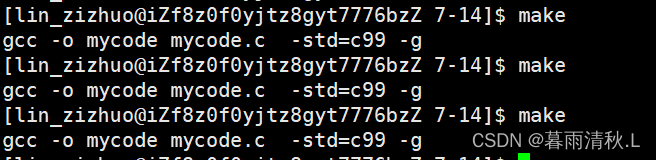
可以看到,在加入了.PHONY**关键字后,多次执行make就不会提示了,但是需要注意的是,对于项目来说一般还是需要关注一下时间问题的,所以不会加上该关键字。
- 如果一个目标文件所依赖的文件不存在,那么make会在当前文件中找目标为该文件的依赖性,如果 找到则再根据那一个规则生成文件。(这有点像一个堆栈的过程)
- 这就是整个make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文 件。
- 在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错, 而对于所定义的命令的错误,或是编译不成功,make根本不理。
- make只管文件的依赖性,即,如果在我找了依赖关系之后,冒号后面的文件还是不在,那么对不起, 我就不工作啦
项目清理
工程项目是需要清理的。
- 像clean这种,没有被第一个目标文件直接或间接关联,那么它后面所定义的命令将不会被自动执行, 不过,我们可以显示要make执行。即命令——“make clean”,以此来清除所有的目标文件,以便重编 译。
- 但是一般我们这种clean的目标文件,我们将它设置为伪目标,用 .PHONY 修饰,伪目标的特性是,总是被 执行的。
以上就是关于make/makefile的自动化构建工具的简单讲解。
那么,知道了如何写工程之后,我们最后就只需要知道如何调试了,接下来就来讲解一下linux下如何调试c/c++程序。
gdb调试器
现在,对于在linux下进行开发,我们只剩下调试工具还没有学习了,接下来,博主就带大家简单的讲解linux中gdb的使用。
背景
在学习gdb之前,我们首先要知道一些程序发布方式方面的背景知识。
- 程序发布方式有两种,debug模式和release模式
- linux gcc/g++出来的二进制程序,默认是release模式
- 要开始gdb调试,必须使用debug模式,在源代码生成二进制程序的时候,要加上-g选项。
使用
接下来,我们就通过刚才的mycode文件来演示各种常见gdb的操作
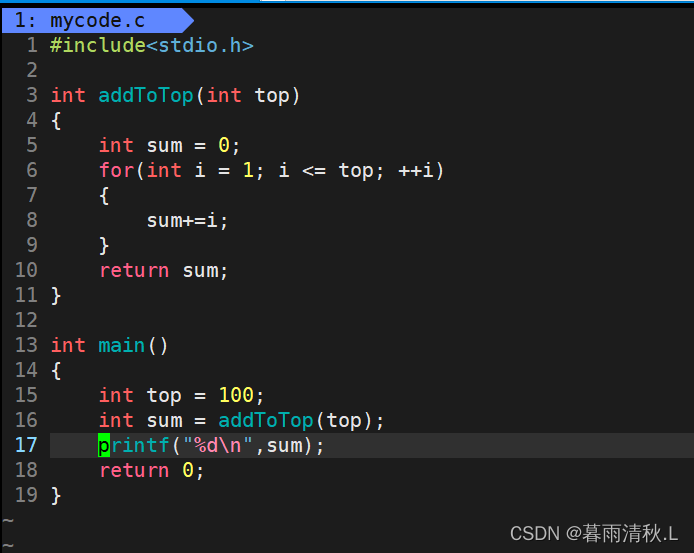
这是我们编写的mycode.c文件内容:
生成可执行程序之后,要进行调试,我们只需要输入指令 gdb mycode就可以进入调试模式:
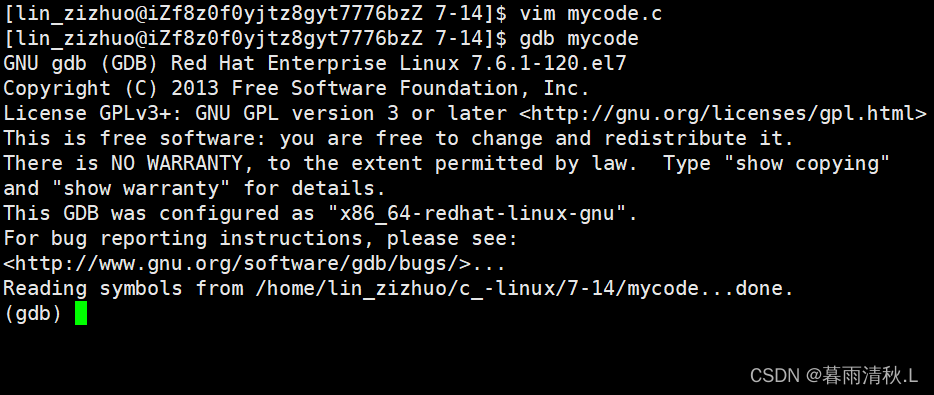
当我们看见done时,就可以进行调试操作了。
这里首先现说一下,gdb是可以记录上一条的指令的,所以如果我们想进行相同的操作,只需要直接回车即可。接下来讲解各种操作。
list(l)调试命令
- list/l 行号 :显示源代码,接着上次的位置往下列,每次列10行。
- list/l 函数名:列出某个函数的源代码
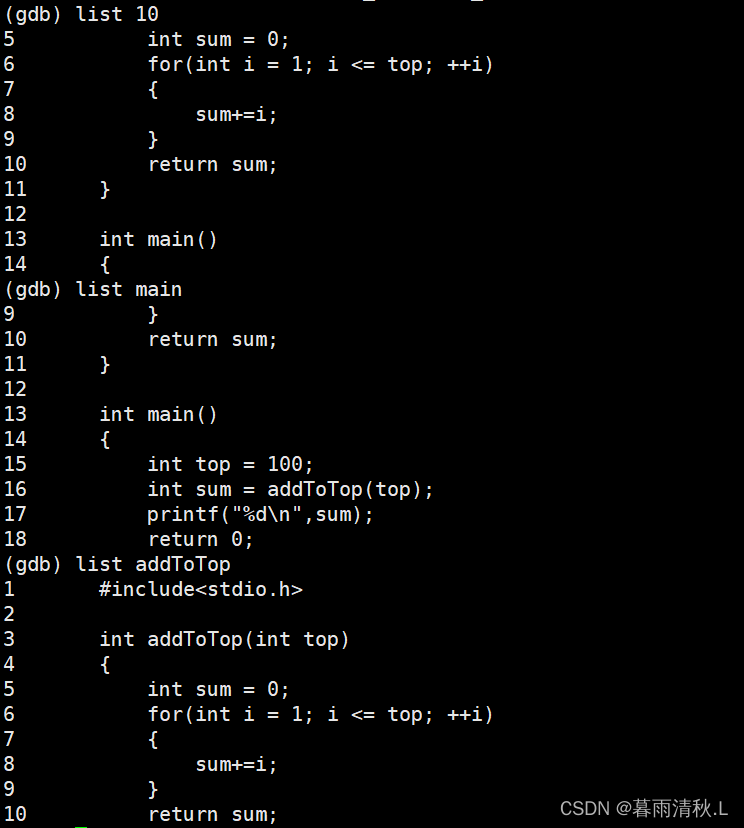
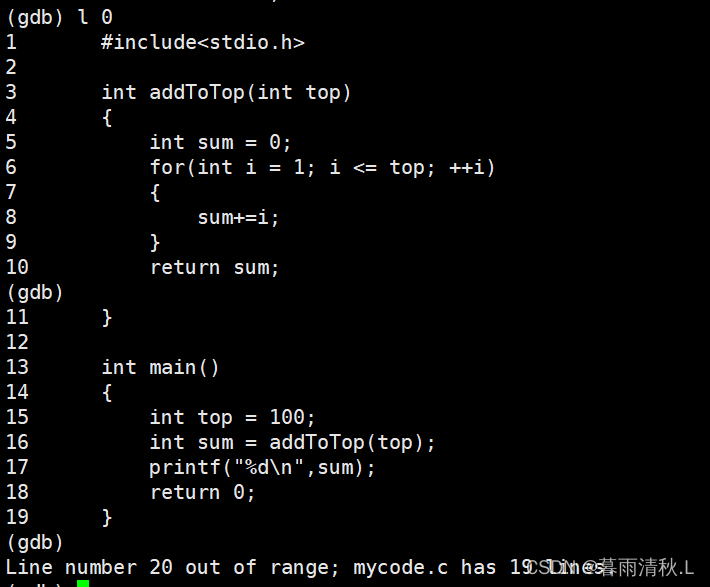
如果我们想查看所有代码,可以先输入list/l 0,然后不断回车即可。
break(b):设置断点
- b 行号 : 在某一行设置断点
- b 函数名:在某一个函数开头设置断点

info break: 查看断点信息

run (r) : 运行程序,到第一个断点中止

单条执行与单步执行
- next(n): 单步执行,不进入函数调用
- step(s): 单条执行,会进入函数调用
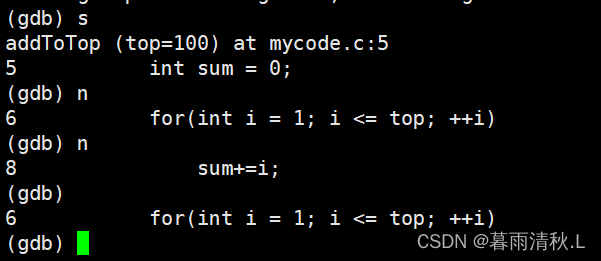
各种关于运行控制的命令
- finish :执行到当前函数返回,然后等待命令
- until 行号:跳至该行
- continue(c):继续运行直到下一个断点
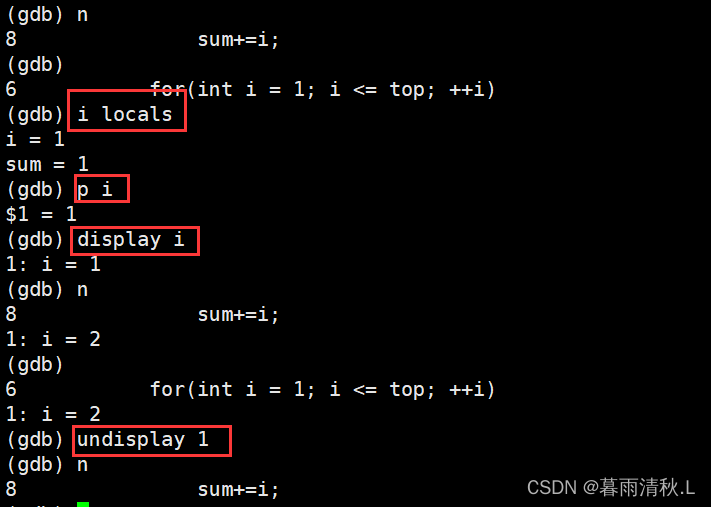
关于查看变量信息的命令
p 变量: 打印变量的值set var 变量: 修改变量的值display 变量: 追踪查看一个变量,每次停下来显示值undisplay 变量编号:取消对该变量的追踪
注意这里undisplay输入的是变量的编号,而不是变量名
breaktrace(bt):查看当前各级调用函数及参数info(i) locals: 查看当前栈帧局部变量的值
对断点的各种操作
delete breakpoints: 删除所有断点delete breakpoints n:删除序号为n的断点
和
undisplay相同,这里输入的是编号不是行号
disable breakpoints(b):禁用所有断点disable b n:禁用编号为n的断点enable b n:启用编号为n的断点
quit(q):退出gdb
总结
在这篇博客中,带领大家认识了linux下开发所需的自动化构建工具make以及调试工具gdb,但是只是带领大家简单了解,如果想要继续深入,还需要大家多多练习使用,并且查阅更多相关资料哦!
![[STL] vector 模拟实现详解](https://img-blog.csdnimg.cn/8230506d2aaf4a1ca9053af8348ae435.png)







![[MySQL]MySQL表中数据的增删查改(CRUD)](https://img-blog.csdnimg.cn/img_convert/ba2e4dc649d1a8c5aef073f6099bc986.png)
![IAR编译报错:Error[Pe065: expected a “.“ and Error[Pe007]:unrecognized token](https://img-blog.csdnimg.cn/c5816c72a91d4bd79266f9c631d10cb7.png)